
第12卷 第5期太赫兹科学与电子信息学报Vo1.12,No.5 2014年10月 Journal of Terahertz Science and Electronic Information Technology Oct.,2014 文章编号:2095-4980(2014)05-0726-05
一种基于词袋模型的图像分类方法
杨晓敏,严斌宇*,李康丽,苏冰山
(四川大学电子信息学院,四川成都 610064)
摘要:采用词袋模型(BoW)对图像进行分类,并针对传统词袋模型存在的不足进行了改进,提出了一种特征软量化的方式。软赋值量化通过将局部显著特征量化(SIFT)为与其距离最近
的若干个视觉单词,并对其进行加权,由此保存特征空间中的距离信息,从而解决硬赋值量化造
成的特征空间信息损失问题。通过在Caltech 101数据库进行实验,验证了本文方法的有效性,实
验结果表明,该方法能够大幅度提高图像分类的性能。
关键词:词袋模型;视觉词典;图像分类
中图分类号:TN911.73;TP391.4文献标识码:A doi:10.11805/TKYDA201405.0726
An image classification method based on bag of words model
YANG Xiao-min,YAN Bin-yu*,LI Kang-li,SU Bing-shan
(College of Electronics and Information Engineering,Sichuan University,Chengdu Sichuan 610064,China)
Abstract:The Bag of Words(BoW) model is applied to object classification. An improved algorithm based on soft quantification is proposed. This algorithm quantifies the Scale-Invariant Feature Transform
(SIFT) descriptor into several nearest visual words and performs weighting on them, which can conserve
the space information. Therefore, it can avoid the information loss of eigen space caused by hard
quantification. The experiments are carried out on Caltech 101 database. Experimental results show that
the proposed method performs better than traditional method on image classification.
Key words:Bag of Words model;visual words;image classification
近年来,图像数量的大量激增给图像识别、检索以及分类等问题带来了巨大的挑战。如何在浩瀚的数据中准确获得用户所需信息并进行处理,成为该领域亟待解决的问题之一。词袋模型最初应用于文档处理领域,将文档表示成顺序无关的关键词的组合,通过统计文档中关键词出现的频率来进行匹配。近几年来,计算机视觉领域的研究者们成功地将该模型的思想移植到图像处理领域[1–2],词袋模型(BoW)将图像库看成文档库,将一幅图像看作一篇文档。提取图像特征后,用其生成“视觉单词”,即生成字典,统计每幅图像的视觉单词出现频率,即可完成图像的词袋描述。为了进一步提高该模型的性能,使其在图像识别和分类领域得到更好的应用,研究者们一直致力于对模型的实现过程进行改进和优化[3–8]。
传统局部显著特征的量化就是计算每个局部显著特征与词典中所有视觉单词的最小距离,并将该局部特征用距离它最近的视觉单词进行量化[9–10]。这种方式下局部显著特征的量化仅仅是局部特征之间真实距离的一种粗糙的近似,局部特征在量化过程之中会损失空间信息。处于量化边界两侧的点,虽然实际距离很近,但是量化后其距离就会较大;而处于量化边界同侧的点,虽然实际距离可能很远,但是量化后距离很近。实际上,图像的噪声、场景光照变化、遮挡等因素,导致同一个物体某一区域在不同的图像中,局部显著特征会存在较大差异。在量化时,有可能被量化为不同的视觉单词。因此这种硬赋值方式的量化就会造成检索的错误。本文在传统词袋模型基础上,针对局部显著特征的量化算法进行研究,建立新的量化方式,保存局部显著特征的空间信息,以解决量化赋值带来的信息损失问题。实验结果表明本文方法能够提高图像检索的性能。
收稿日期:2014-07-08;修回日期:2014-08-13
基金项目:中国科学院数字地球重点实验室开放基金资助项目(No.2012LDE016);武汉大学测绘遥感信息工程国家重点实验室开放基金(No.12R03);高等学校博士学科点专项科研基金资助项目(20130181120005);四川省科技支撑计划资助项目(No.2014GZ0005);博士后基金资助项目(No.2014M552357);南京邮电大学江苏省图像处理与图像通信重点实验室开放基金资助项目(No.LBEK2013001).
*通信作者:严斌宇 email:yby@https://www.doczj.com/doc/056028857.html,
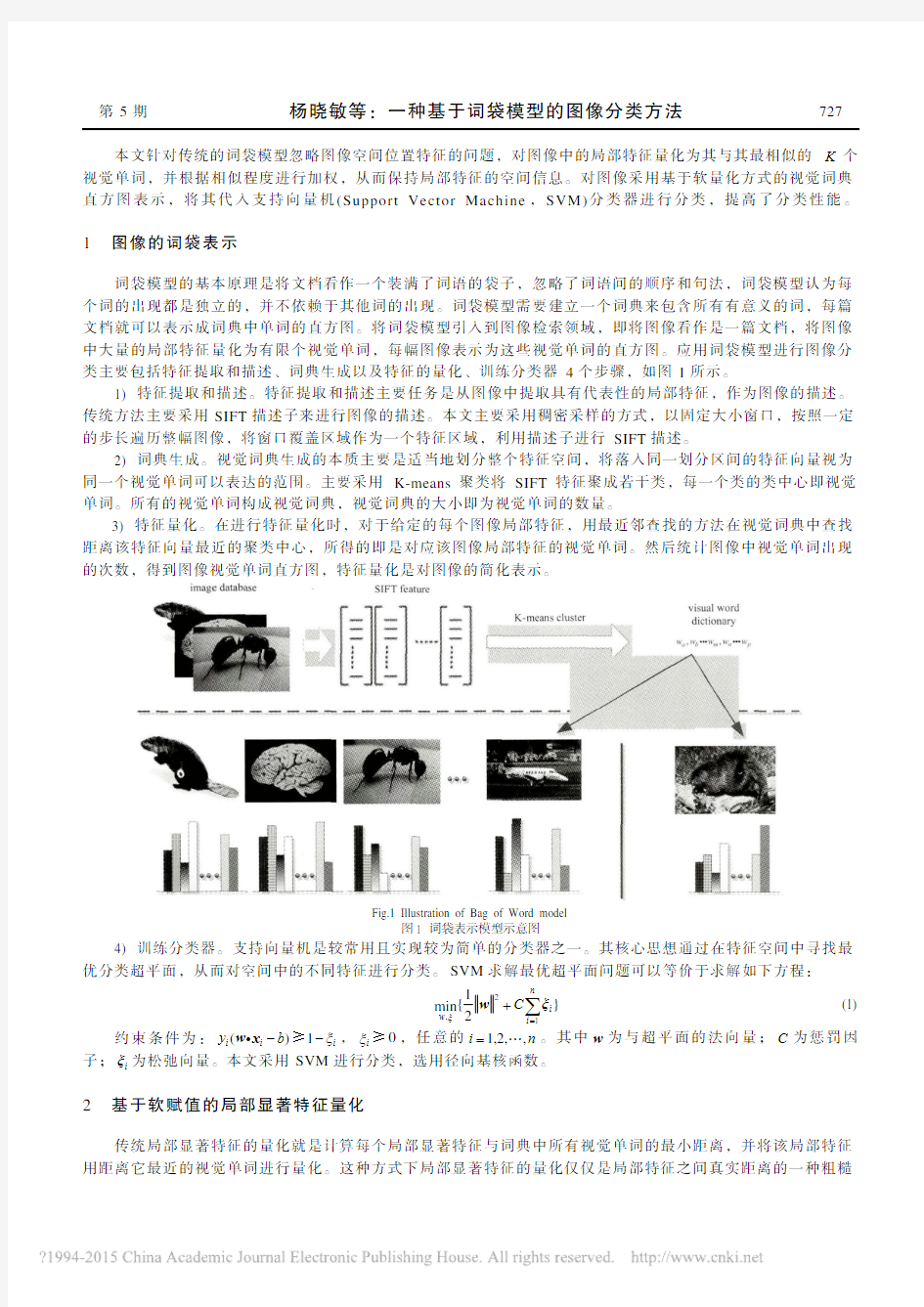
第5期 杨晓敏等:一种基于词袋模型的图像分类方法 727 本文针对传统的词袋模型忽略图像空间位置特征的问题,对图像中的局部特征量化为其与其最相似的K 个视觉单词,并根据相似程度进行加权,从而保持局部特征的空间信息。对图像采用基于软量化方式的视觉词典直方图表示,将其代入支持向量机(Support Vector Machine ,SVM)分类器进行分类,提高了分类性能。 1 图像的词袋表示
词袋模型的基本原理是将文档看作一个装满了词语的袋子,忽略了词语间的顺序和句法,词袋模型认为每个词的出现都是独立的,并不依赖于其他词的出现。词袋模型需要建立一个词典来包含所有有意义的词,每篇文档就可以表示成词典中单词的直方图。将词袋模型引入到图像检索领域,即将图像看作是一篇文档,将图像中大量的局部特征量化为有限个视觉单词,每幅图像表示为这些视觉单词的直方图。应用词袋模型进行图像分类主要包括特征提取和描述、词典生成以及特征的量化、训练分类器4个步骤,如图1所示。
1) 特征提取和描述。特征提取和描述主要任务是从图像中提取具有代表性的局部特征,作为图像的描述。传统方法主要采用SIFT 描述子来进行图像的描述。本文主要采用稠密采样的方式,以固定大小窗口,按照一定的步长遍历整幅图像,将窗口覆盖区域作为一个特征区域,利用描述子进行SIFT 描述。
2) 词典生成。视觉词典生成的本质主要是适当地划分整个特征空间,将落入同一划分区间的特征向量视为同一个视觉单词可以表达的范围。主要采用K-means 聚类将SIFT 特征聚成若干类,每一个类的类中心即视觉单词。所有的视觉单词构成视觉词典,视觉词典的大小即为视觉单词的数量。
3) 特征量化。在进行特征量化时,对于给定的每个图像局部特征,用最近邻查找的方法在视觉词典中查找距离该特征向量最近的聚类中心,所得的即是对应该图像局部特征的视觉单词。然后统计图像中视觉单词出现的次数,得到图像视觉单词直方图,特征量化是对图像的简化表示。
4) 训练分类器。支持向量机是较常用且实现较为简单的分类器之一。其核心思想通过在特征空间中寻找最优分类超平面,从而对空间中的不同特征进行分类。SVM 求解最优超平面问题可以等价于求解如下方程:
2,1
1{}min 2n i w i C ξ=+∑w ξ (1) 约束条件为:()1i i i y b ξ??w x i ≥,0i ξ≥,任意的1,2,,i n = 。其中w 为与超平面的法向量;C 为惩罚因子;i ξ为松弛向量。本文采用SVM 进行分类,选用径向基核函数。
2 基于软赋值的局部显著特征量化
传统局部显著特征的量化就是计算每个局部显著特征与词典中所有视觉单词的最小距离,并将该局部特征用距离它最近的视觉单词进行量化。这种方式下局部显著特征的量化仅仅是局部特征之间真实距离的一种粗糙
Fig.1 Illustration of Bag of Word model 图1 词袋表示模型示意图
728 太赫兹科学与电子信息学报 第12卷 的近似,局部特征在量化过程之中会损失空间信息。如图2所示,图中A,B,C,D,E 为构造好的视觉单词,1,2,3,4为局部显著特征。在传统硬赋值量化方式下,特征3和特征4
量化为[A :1],[C :1],尽管它们距离很近,但是经过硬赋值量化后它们将属于不同的视觉单词。此外,在硬赋值方式下,特征1,2,3同时被
量化为视觉单词[A :1],无法记录特征2-3的距离比1-3距离近的这种空间信息。处于量化边界两侧的点,虽然实际距离很近,但是量化后其距离就会较大;而处于量化边界同侧的点,虽然实际距离可能很
远,但是量化后距离很近。实际上,由于图像的噪声、场景光照变化、遮挡等因素,同一个物体某一区域在不同的图像中,局部显著特征会存在较大差异。在量化时,有可能被量化为不同的视觉单词。因
此这种硬赋值方式的量化就会造成检索的错误。硬赋值方式与软赋值
方式示意图如图3所示。
针对这一问题,本课题拟采用软赋值方式对局部特征进行赋值。
即将局部显著特征量化为距离其最近的n 个视觉单词,并为每一个视
觉单词进行加权,权值如式(2)所示:
22exp 2d w σ??=?????
(2) 式中:d 为局部显著特征与视觉单词在特征空间中的距离;参数σ为设定参数。软赋值量化通过将局部显著特征量化为与其距离最近的n 个视觉单词,并对其进行加权,由此保存特征空间中的距离信息,从而解决硬赋值量化造成的特征空间信息损失问题。可以看出,采用软赋值方式,局部特征1,2,3,4将被赋值为与之距离最近的n 个视觉单词(若n =3),分别为:
21,A 221,D 221,D 2A:exp 21B:exp 2C:exp 2d d d σσσ?????????????????????→????????????????????????????,22,A 222,B 222,C 2A:exp 22B:exp 2C:exp 2d d d σσσ?????????????????????→????????????????????????????,23,A 223,B 223,C 2A:exp 23B:exp 2C:exp 2d d d σσσ?????????????????????→???????????????????????????
?,24,A 224,B 224,C 2A:exp 24B:exp 2C:exp 2d d d σσσ?????????????????????→???????????????????????????? 在软赋值量化的方式下,特征3与特征4不再量化为不同的视觉单词,同时也可以记录特征2-3的距离比1-3距离近的这种空间信息,解决了硬赋值量化方式下的信息损失问题。硬赋值量化与软赋值量化之间的关系如图3所示。 3 本文算法流程
训练过程:
1) 提取训练样本,采用稠密采样的方式提取图片的SIFT 特征。
2) 对上一步提取出的所有SIFT 特征,采用K-means 方式进行聚类,得到若干个聚类中心矢量,即为视觉单词。
3) 对每一幅训练图中的SIFT 特征进行量化,然后将每幅图采用软量化方式表示成视觉单词的直方图,然后用直方图表示训练图像。
4) 采用SVM 对训练样本进行训练。单独训练每个类的分类模型,每类的训练样本包括正负样本。正样本为包含这类对象的图像视觉单词直方图,负样本随机选取不包含这类对象的图像视觉单词直方图。正负样本个数相等。
分类过程:
1) 对于测试图像,采用稠密采样的方式提取图片的SIFT 特征。
2) 对测试图像的SIFT 特征进行软量化,计算测试图像的视觉单词直方图。
3) 用训练好的SVM 分类器进行分类,得到分类结果。 A B C
D E 1 2 3 4 Fig.2 Quantitative examples of SIFT features 图2 局部特征量化示例 Fig.3 Relationship between hard and soft assignment quantification 图3 硬赋值量化与软赋值量化之间的关系
第5期杨晓敏等:一种基于词袋模型的图像分类方法729 4 实验结果与分析
在本文的研究中,采用图像分类和识别任务中较为经典的数据库Caltech 101进行实验验证。Caltech 101数据库具有图像数据庞大、图像种类多、对象类内变化多样等特点,具有一定的代表性。该图像数据集分为101类,共9 146幅视觉物体图像,包括动物、交通工具、花等类别的物体,具有明显形状变异,如图4所示。每个类别包含的图像数量从40到80不等,每幅图像大约300×200像素,属于中等分辨率。
Fig.4 Some samples of the Caltech 101 image database
图4 部分Caltech 101数据库图像
随机抽取10类进行实验,然后再分别选取10,15,20,25幅图像作为训练数据,其余的则作为测试数据。其中软量化中,紧邻个数n=10。将全部训练图像稠密提取SIFT描述子,图5为部分样本稠密提取SIFT描述子示意图。用这些描述子构造长度为500的码书(使用K-means聚类,其中k=1 000)。所有程序都在Windows XP操作系统,2 GB内存,Matlab 7.0环境下运行,SVM分类器采用台湾大学林智仁开发的LIBSVM。对已有的图像集,选取其中质量不等的字符图像进行训练。每一类图像取10个训练样本,分别对参数C和δ取不同的值进行测试,最后发现当取C =100, δ= 0.3或δ= 0.4时效果较好,实验结果如表1所示。
从表1中可以看出,随着每类训练样本数的增加,本文算法与传统词袋算法的分类性能都得到了提高。从总体上看,本文算法的分类准确率高于传统词袋算法。此外,本文还针对视觉单词软量化时近邻的个数选择进行了分析,分别选取近邻个数n=5,10,15,20,试验结果如图6所示。结果表明,分类正确率会随着近邻个数的增长而增长,但到达一定数量时就会下降。
Fig.5 Illustration of extracting dense SIFT descriptor 图5 样本稠密提取SIFT描述子示意图Fig.6 Effect of the nearest neighbor numbers on classification accuracy
图6 近邻个数对分类准确率的影响
730 太赫兹科学与电子信息学报第12卷
表1 本文方法与传统词袋算法的准确率比较
Table1 Comparison of accuracies
training
sample
numbers 10 15 20 25 30 accuracy of the proposed algorithm/(%) 53.2 53.8 54.1 54.3 54.6 accuracy of the traditional bag of word model/(%) 50.6 51.3 51.9 52.2 52.7
5 结论
本文对传统的词袋模型进行了改进。传统词袋模型下,由于量化误差、噪声的缘故,特征空间中距离相近的特征有可能被量化成不同的视觉单词,导致系统分类准确率下降。为此本文提出了一种软量化的方式,将局部显著特征量化为与其距离最近的若干个视觉单词,并对其进行加权,由此保存特征空间中的距离信息,从而解决硬赋值量化造成的特征空间信息损失问题。实验证明,本文算法可以提高图像分类的准确性,且与现有方法相比具有优越性。
参考文献:
[1]WU L,HOI S C H,YU N H. Semantics-preserving bag-of-words models and applications[J]. IEEE Transactions on Image
Processing, 2010,19(7):1908-1920.
[2]谢昭,高隽. 基于高斯统计模型的场景分类及约束机制新方法[J]. 电子学报, 2009,37(4):733-738. (XIE Zhao,GAO
Jun. A novel method for scene categorization with constraint mechanism based on Gaussian statistical model[J]. Acta Electronica Sinica, 2009,37(4):733-738.)
[3]Chum O,Philbin J,Sivic J,et al. Total recall: automatic query expansion with a generative feature model for object
retrieval[C]// Proceedings of IEEE Computer Vision and Pattern Recognition(CVPR), 2009. [S.l.]:IEEE, 2009.
[4]Perdoch M,Chum O,Matas J. Efficient representation of local geometry for large scale object retrieval[C]// Proceedings of
IEEE Computer Vision and Pattern Recognition(CVPR), 2009. [S.l.]:IEEE, 2009.
[5]WANG G,Forsyth D. Object image retrieval by exploiting online knowledge resources[C]// Proceedings of IEEE Computer
Vision and Pattern Recognition(CVPR), 2008. [S.l.]:IEEE, 2008.
[6]刘硕研,须德,冯松鹤,等. 一种基于上下文语义信息的图像块视觉单词生成算法[J]. 电子学报, 2010,38(5):1156-
1161. (LIU Shuo-yan,XU De,FENG Song-he,et al. A novel visual words definition algorithm of image patch based on contextual semantic information[J]. Acta Electronica Sinica, 2010,38(5):1156-1161.)
[7]贾世杰,孔祥维,付海燕,等. 基于互补特征与类描述的商品图像自动分类[J]. 电子与信息学, 2010,32(10):2294-2300.
(JIA Shi-jie,KONG Xiang-wei,FU Hai-yan,et al. Auto classification of product images based on complementary features and class descriptor[J]. Journal of Electronics & Information Technology, 2010,32(10):2294-2300.)
[8]LI F F,Liva A O. Fifteen scene categories[DB/OL]. [2014-07-08].https://www.doczj.com/doc/056028857.html,/poncegrp/data/.
[9]丁建睿,黄剑华,刘家锋,等. 局部特征与多示例学习结合的超声图像分类方法[J]. 自动化学报, 2013,39(6):861-867.
(DING Jian-rui,HUANG Jian-hua,LIU Jia-feng,et al. Combining local features and multi-instance learning for ultrasound image classification[J]. Acta Automatica Sinica, 2013,39(6):861-867.)
[10] 吕清秀,李弼程,高毫林. 基于距离度量学习的DCT域JPEG图像检索[J]. 太赫兹科学与电子信息学报, 2014,12(1):
112-118. (LV Qing-xiu,LI Bi-cheng,GAO Hao-lin. JPEG images retrieval in DCT domain based on Distance Metric Learning[J].
Journal of Terahertz Science and Electronic Information Technology, 2014,12(1):112-118.)
作者简介:
杨晓敏(1980-),女,四川省广安市人,博士,副教授,主要研究方向计算机视觉.email: arielyang@https://www.doczj.com/doc/056028857.html,.
严斌宇(1975-),男,河北省保定市人,博士,讲师,主要研究方向计算机视觉.email: yby@https://www.doczj.com/doc/056028857.html,.
李康丽(1990-),女,河南省南阳市人,在读硕士研究生,主要研究方向为计算机视觉.
苏冰山(1989-),男,河南省焦作市人,在读硕士研究生,主要研究方向为计算机视觉.
第12卷 第5期太赫兹科学与电子信息学报Vo1.12,No.5 2014年10月 Journal of Terahertz Science and Electronic Information Technology Oct.,2014 文章编号:2095-4980(2014)05-0726-05 一种基于词袋模型的图像分类方法 杨晓敏,严斌宇*,李康丽,苏冰山 (四川大学电子信息学院,四川成都 610064) 摘要:采用词袋模型(BoW)对图像进行分类,并针对传统词袋模型存在的不足进行了改进,提出了一种特征软量化的方式。软赋值量化通过将局部显著特征量化(SIFT)为与其距离最近 的若干个视觉单词,并对其进行加权,由此保存特征空间中的距离信息,从而解决硬赋值量化造 成的特征空间信息损失问题。通过在Caltech 101数据库进行实验,验证了本文方法的有效性,实 验结果表明,该方法能够大幅度提高图像分类的性能。 关键词:词袋模型;视觉词典;图像分类 中图分类号:TN911.73;TP391.4文献标识码:A doi:10.11805/TKYDA201405.0726 An image classification method based on bag of words model YANG Xiao-min,YAN Bin-yu*,LI Kang-li,SU Bing-shan (College of Electronics and Information Engineering,Sichuan University,Chengdu Sichuan 610064,China) Abstract:The Bag of Words(BoW) model is applied to object classification. An improved algorithm based on soft quantification is proposed. This algorithm quantifies the Scale-Invariant Feature Transform (SIFT) descriptor into several nearest visual words and performs weighting on them, which can conserve the space information. Therefore, it can avoid the information loss of eigen space caused by hard quantification. The experiments are carried out on Caltech 101 database. Experimental results show that the proposed method performs better than traditional method on image classification. Key words:Bag of Words model;visual words;image classification 近年来,图像数量的大量激增给图像识别、检索以及分类等问题带来了巨大的挑战。如何在浩瀚的数据中准确获得用户所需信息并进行处理,成为该领域亟待解决的问题之一。词袋模型最初应用于文档处理领域,将文档表示成顺序无关的关键词的组合,通过统计文档中关键词出现的频率来进行匹配。近几年来,计算机视觉领域的研究者们成功地将该模型的思想移植到图像处理领域[1–2],词袋模型(BoW)将图像库看成文档库,将一幅图像看作一篇文档。提取图像特征后,用其生成“视觉单词”,即生成字典,统计每幅图像的视觉单词出现频率,即可完成图像的词袋描述。为了进一步提高该模型的性能,使其在图像识别和分类领域得到更好的应用,研究者们一直致力于对模型的实现过程进行改进和优化[3–8]。 传统局部显著特征的量化就是计算每个局部显著特征与词典中所有视觉单词的最小距离,并将该局部特征用距离它最近的视觉单词进行量化[9–10]。这种方式下局部显著特征的量化仅仅是局部特征之间真实距离的一种粗糙的近似,局部特征在量化过程之中会损失空间信息。处于量化边界两侧的点,虽然实际距离很近,但是量化后其距离就会较大;而处于量化边界同侧的点,虽然实际距离可能很远,但是量化后距离很近。实际上,图像的噪声、场景光照变化、遮挡等因素,导致同一个物体某一区域在不同的图像中,局部显著特征会存在较大差异。在量化时,有可能被量化为不同的视觉单词。因此这种硬赋值方式的量化就会造成检索的错误。本文在传统词袋模型基础上,针对局部显著特征的量化算法进行研究,建立新的量化方式,保存局部显著特征的空间信息,以解决量化赋值带来的信息损失问题。实验结果表明本文方法能够提高图像检索的性能。 收稿日期:2014-07-08;修回日期:2014-08-13 基金项目:中国科学院数字地球重点实验室开放基金资助项目(No.2012LDE016);武汉大学测绘遥感信息工程国家重点实验室开放基金(No.12R03);高等学校博士学科点专项科研基金资助项目(20130181120005);四川省科技支撑计划资助项目(No.2014GZ0005);博士后基金资助项目(No.2014M552357);南京邮电大学江苏省图像处理与图像通信重点实验室开放基金资助项目(No.LBEK2013001). *通信作者:严斌宇 email:yby@https://www.doczj.com/doc/056028857.html,
上次课主要内容 4.4简单自然地物可识别性分析 4.5复杂地物识别概率(重点理解) ①要素t 的价值②要素总和(t 1,t 2,…,t m )t 的价值 K -K E ∑ = ③复杂地物识别概率的计算理解p70~71例子
第五章遥感图像特征和解译标志 5.1 解译标志的定义和分类 5.2 遥感图像特征与解译标志的关系 5.3 遥感图像的时空特性 5.4 遥感图像中的独立变量 5.5 地物统计特征的构造
第五章遥感图像特征和解译标志 地物特征 电磁波特性 影像特征 遥感图像记录过程 n 图像解译就是建立在研究地物性质、电磁波性质 及影像特征三者的关系之上 n 图像要素或特征,分“色”和“形”两大类:?色:色调、颜色、阴影、反差; ?形:形状、大小、空间分布、纹理等。“形”只有依靠“色”来解译才有意义。
第五章遥感图像特征和解译标志 5.1 解译标志的定义和分类 n两个定义: ?解译标志定义:遥感图像光谱、辐射、空间和时间特征决定 图像的视觉效果、表现形式和计算特点,并导致物体在图像上 的差别。 l给出了区分遥感图像中物体或现象的可能性; l解译标志包括:色调与色彩、形状、尺寸、阴影、细部(图 案)、以及结构(纹理)等; l解译标志是以遥感图像的形式传递的揭示标志; ?揭示标志定义:在目视观察时借以将物体彼此分开的被感知 对象的典型特征。 l揭示标志包括:形状、尺寸、细部、光谱辐射特性、物体的阴 影、位置、相互关系和人类活动的痕迹; l揭示标志的等级决定于物体的性质、他们的相对位置及与周围 环境的相互作用等;
第五章遥感图像特征和解译标志 5.1 解译标志的定义和分类 n解译标志和揭示标志的关系: ?解译标志是以遥感图像的形式传递的揭示标志; ?虽然我们是通过遥感图像识别地物目标的,但是大多数情况 下,基于遥感图像识别地物并作出决定时,似乎并不是利用解 译标志,而是利用揭示标志。 例如,很多解译人员刚看到图像就差不多在脑海中形成地物的形象, 然后仅仅分析这个形象就能作出一定的决定。实际上,有经验的解译人 员,在研究图像的解译标志并估计到传递信息的传感系统的影响以后, 思想中就建立起地物的揭示标志,并在这些标志的基础上识别被感知物 体。解译人员在实地或图像上都没见过的地物或现象是例外。 n解译标志和揭示标志可以按两种方式进行划分:?直接标志和间接标志; ?永久标志和临时标志;
实验四遥感图像分类 一、背景知识 图像分类就是基于图像像元的数据文件值,将像元归并成有限几种类型、等级或数据集的过程。常规计算机图像分类主要有两种方法:非监督分类与监督分类,本实验将依次介绍这两种分类方法。 非监督分类运用ISODATA(Iterative Self-Organizing Data Analysis Technique)算法,完全按照像元的光谱特性进行统计分类,常常用于对分类区没有什么了解的情况。使用该方法时,原始图像的所有波段都参于分类运算,分类结果往往是各类像元数大体等比例。由于人为干预较少,非监督分类过程的自动化程度较高。非监督分类一般要经过以下几个步骤:初始分类、专题判别、分类合并、色彩确定、分类后处理、色彩重定义、栅格矢量转换、统计分析。 监督分类比非监督分类更多地要用户来控制,常用于对研究区域比较了解的情况。在监督分类过程中,首先选择可以识别或者借助其它信息可以断定其类型的像元建立模板,然后基于该模板使计算机系统自动识别具有相同特性的像元。对分类结果进行评价后再对模板进行修改,多次反复后建立一个比较准确的模板,并在此基础上最终进行分类。监督分类一般要经过以下几个步骤:建立模板(训练样本)分类特征统计、栅格矢量转换、评价模板、确定初步分类图、检验分类结果、分类后处理。由于基本的非监督分类属于IMAGINE Essentials级产品功能,但在IMAGINE Professional级产品中有一定的功能扩展,非监督分类命令分别出现在Data Preparation菜单和Classification菜单中,而监督分类命令仅出现在Classification菜单中。 二、实验目的 理解并掌握图像分类的原理,学会图像分类的常用方法:人工分类(目视解译)、计算机分类(监督分类、非监督分类)。能够针对不同情况,区别使用监督分类、非监督分类。理解计算机分类的常用算法实现过程。熟练掌握遥感图像分类精度评价方法、评价指标、评价原理,并能对分类结果进行后期处理。 三、实验内容(6课时) 1.非监督分类(Unsupervised Classification); 2.监督分类(Supervised Classification); 3.分类精度评价(evaluate classification); 4.分类后处理(Post-Classification Process); 四、实验准备 实验数据: 非监督分类文件:germtm.img 监督分类文件:tm_860516.img 监督模板文件:tm_860516.sig 五、实验步骤、方法 1、非监督分类(Unsupervised Classification)
龙源期刊网 https://www.doczj.com/doc/056028857.html, 遥感图像分类方法综述 作者:胡伟强鹿艳晶 来源:《中小企业管理与科技·下旬刊》2015年第08期 摘要:对传统图像监督分类方法和非监督分类方法在遥感图像分类中的应用进行总结, 对基于人工神经网络、模糊理论、小波分析、支持向量机等理论的新的遥感图像分类方法进行了介绍,并对遥感图像分类方法研究的发展趋势做了展望。 关键词:遥感图像;监督分类;分类精度 1 概述 遥感就是远离地表,借助于电磁波来收集、获取地表的地学、生物学、资源环境等过程和现象的科学技术。遥感技术系统由四部分组成:遥感平台、传感器、遥感数据接收及处理系统、分析系统。遥感数据就是用遥感器探测来自地表的电磁波,通过采样及量化后获得的数字化数据。 2 传统遥感图像分类方法 2.1 非监督分类方法 非监督分类方法也称为聚类分析。进行非监督分类时,不必对遥感图像影像地物获取先验类别知识,仅依靠遥感图像上不同类别地物光谱信息进行特征提取,根据图像本身的统计特征的差别来达到分类的目的。主要的算法有:K-均值聚类(K-means)算法和迭代自组织数据分析法(Iterative Self-organizing Data Analysis Techniques A, ISODATA)等。 2.2 监督分类方法 对于监督分类,训练区的选择要求有代表性,训练样本的选择要考虑到遥感图像的地物光谱特征,而且样本数目应能够满足分类的要求,否则,一旦样本数目超过一定的阈值时,分类器的精度便会下降。主要的算法有:最大似然分类(Maximum Likelihood classification,MLC)、最小距离分类、K-近邻分类等。 3 基于新理论的遥感图像分类方法 3.1 基于人工神经网络的遥感图像分类 在遥感图像的分类处理中,人工神经网络的输入层神经元表征遥感图像的输入模式。每一个输入层神经元对应于一个光谱波段,每一个输出层神经元则对应于一种土地覆盖类型。其
LDA(主题模型)算法 &&概念: 首先引入主题模型(Topic Model)。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说,我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。 LDA可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。 LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生 注:每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。 备注: 流程(概率分布):→→ 许多(单)词某些主题一篇文档 /**解释:LDA生成过程 *对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess): *1.对每一篇文档,从主题分布中抽取一个主题; *2.从上述被抽到的主题所对应的单词分布中抽取一个单词; *3.重复上述过程直至遍历文档中的每一个单词。 **/ 把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
&&深入学习: 理解LDA,可以分为下述5个步骤: 1.一个函数:gamma函数 2.四个分布:二项分布、多项分布、beta分布、Dirichlet分布 3.一个概念和一个理念:共轭先验和贝叶斯框架 4.两个模型:pLSA、LDA(在本文第4 部分阐述) 5.一个采样:Gibbs采样 本文便按照上述5个步骤来阐述,希望读者看完本文后,能对LDA有个尽量清晰完整的了解。同时,本文基于邹博讲LDA的PPT、rickjin的LDA数学八卦及其它参考资料写就,可以定义为一篇学习笔记或课程笔记,当然,后续不断加入了很多自己的理解。若有任何问题,欢迎随时于本文评论下指出,thanks。 1 gamma函数 整体把握LDA 关于LDA有两种含义,一种是线性判别分析(Linear Discriminant Analysis),一种是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),本文讲后者(前者会在后面的博客中阐述)。 另外,我先简单说下LDA的整体思想,不然我怕你看了半天,铺了太长的前奏,却依然因没见到LDA的影子而显得“心浮气躁”,导致不想再继续看下去。所以,先给你吃一颗定心丸,明白整体框架后,咱们再一步步抽丝剥茧,展开来论述。 按照wiki上的介绍,LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。 LDA的这三位作者在原始论文中给了一个简单的例子。比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习的方式,获取每个主题Topic对应的词语。如下图所示:
一、BMP格式 BMP格式是Windows操作系统中的标准图像文件格式,能够被多种Windows应用程序所支持。特点是包含的图像信息较丰富,几乎不进行压缩。缺点是占用磁盘空间过大。所以,目前BMP在单机上比较流行。 二、GIF格式 特点是压缩比高,磁盘空间占用较少,所以这种图像格式迅速得到了广泛的应用。 此外,考虑到网络传输中的实际情况,GIF图像格式还增加了渐显方式。目前Internet上大量采用的彩色动画文件多为这种格式的文件。 但GIF有个小小的缺点,即不能存储超过256色的图像。尽管如此,这种格式仍在网络上大行其道应用,这和GIF图像文件短小、下载速度快、可用许多具有同样大小的图像文件组成动画等优势是分不开的。 三、JPEG格式 JPEG文件的扩展名为.jpg或.jpeg,其压缩技术十分先进,它用有损压缩方式去除冗余的图像和彩色数据,获取得极高的压缩率的同时能展现十分丰富生动的图像,换句话说,就是可以用最少的磁盘空间得到较好的图像质量。 同时JPEG还是一种很灵活的格式,具有调节图像质量的功能,允许你用不同的压缩比例对这种文件压缩,当然我们完全可以在图像质量和文件尺寸之间找到平衡点。 它的应用也非常广泛,特别是在网络和光盘读物上,肯定都能找到它的影子。目前各类浏览器均支持JPEG这种图像格式,因为JPEG格式的文件尺寸较小,下载速度快,使得Web页有可能以较短的下载时间提供大量美观的图像,JPEG同时也就顺理成章地成为网络上最受欢迎的图像格式。 四、JPEG2000格式 JPEG 2000具备更高压缩率以及更多新功能的新一代静态影像压缩技术。 JPEG2000 与JPEG不同的是,JPEG2000 同时支持有损和无损压缩,而JPEG 只能支持有损压缩。无损压缩对保存一些重要图片是十分有用的。JPEG2000的一个极其重要的特征在于它能实现渐进传输,这一点与GIF的"渐显"有异曲同工之妙,即先传输图像的轮廓,然后逐步传输数据,不断提高图像质量,让图象由朦胧到清晰显示,而不必是像现在的JPEG 一样,由上到下慢慢显示。 此外,JPEG2000还支持所谓的"感兴趣区域"特性,你可以任意指定影像上你感兴趣区域的压缩质量,还可以选择指定的部份先解压缩。 JPEG2000可应用于传统的JPEG市场,如扫描仪、数码相机等,亦可应用于新兴领域,如网路传输、无线通讯等等 五、TIFF格式 TIFF的特点是图像格式复杂、存贮信息多。正因为它存储的图像细微层次的信息非常多,图像的质量也得以提高,故而非常有利于原稿的。
摘要 遥感图像分类一直是遥感研究领域的重要内容,如何解决多类别的图像的分类识别并满足一定的精度,是遥感图像研究中的一个关键问题,具有十分重要的意义。 遥感图像的计算机分类是通过计算机对遥感图像像素进行数值处理,达到自动分类识别地物的目的。遥感图像分类主要有两类分类方法:一种是非监督分类方法,另一种是监督分类方法。非监督分类方法是一个聚类过程,而监督分类则是一个学习和训练的过程,需要一定的先验知识。非监督分类由十不能确定类别属性,因此直接利用的价值很小,研究应用也越来越少。而且监督分类随着新技术新方法的不断发展,分类方法也是层出不穷。从传统的基十贝叶斯的最大似然分类方法到现在普遍研究使用的决策树分类和人工神经网络分类方法,虽然这些方法很大程度改善了分类效果,提高了分类精度,增加了遥感的应用能力。但是不同的方法有其不同优缺点,分类效果也受很多因素的影响。 本文在对国内外遥感图像分类方法研究的进展进行充分分析的基础上,应用最大似然分类法、决策树分类法对TM影像遥感图像进行了分类处理。在对分类实现中,首先对分类过程中必不可少的并影响分类效果的步骤也进行了详细地研究,分别是分类样本和分类特征;然后详细介绍两种方法的分类实验;最后分别分析分类结果图,采用混淆矩阵和kappa系数对两种方法的分类结果进行精度评价。 关键词:TM遥感影像,图像分类,最大似然法,决策树 题目:遥感图像几种分类方法的比较...................................... 错误!未定义书签。摘要.. (1) 第一章绪论 (3)
1.1遥感图像分类的实际应用及其意义 (4) 1.2我国遥感图像分类技术现状 (5) 1.3遥感图像应用于测量中的优势及存在的问题 (6) 1.3.1遥感影像在信息更新方面的优越性 (6) 1.3.2遥感影像在提取信息精度方面存在的问题 (6) 1.4研究内容及研究方法 (8) 1.4.1研究内容 (8) 1.4.2 研究方法 (8) 1.5 论文结构 (9) 第二章遥感图像的分类 (9) 2.1 监督分类 (9) 2.1.1 监督分类的步骤 (9) 2.1.2 最大似然法 (11) 2.1.3 平行多面体分类方法 (12) 2.1.4 最小距离分类方法 (13) 2.1.5监督分类的特点 (13) 2.2 非监督分类 (14) 2.2.1 K-means算法 (14) K-均值分类法也称为 (14) 2.2.2 ISODATA分类方法 (15) 2.2.3非监督分类的特点 (17) 2.4遥感图像分类新方法 (17) 2.4.1基于决策树的分类方法 (17) 2.4.2 人工神经网络方法 (19) 2.4.3 支撑向量机 (20) 2.4.4 专家系统知识 (21) 2.5 精度评估 (22) 第三章研究区典型地物类型样本的确定 (24) 3.1 样本确定的原则和方法 (24) 3.2 研究区地物类型的确定 (24) 3.3样本区提取方案 (25) 3.4 各个地物类型的样本的选取方法 (25) 3.4.1 建立目视解译标志 (25) 3.4.2 地面实地调查采集 (26) 3.4.3 利用ENVI遥感图像处理软件选取样本点 (26) 第四章遥感图像分类实验研究 (26) 4.1遥感影像适用性的判定 (26) 4.2分类前的预处理 (28) 4.2.1空间滤波的处理 (28) 4.2.2 频域滤波处理 (28) 4.3利用ENVI软件对影像按照不同的分类方法进行监督分类 (30) 4.3.1监督分类 (30) 4.3.2 决策树 (33) 4.4分类后的处理 (35)
图像分类学习笔记:词袋模型和空间金字塔匹配 Image Classification Framework: Bag-of-Words &Spatial Pyramid Matching 一、基础:词袋模型(Bag of Words ) Bag-of-Words (词袋、词包)模型,或称Bag of Features 模型,源于文本分类技术。在信息检索中,假定对于一个文本,忽略其词序和语法、句法。将其仅仅看作是一个词的集合,每个词都是彼此概率独立的。这样可以通过文档中单词出现的频率来对文档进行描述与表达。Csurka 等[1]于2004年将其引入计算机视觉领域。 其核心思想在于,图像可以视为一种文档对象,图像中不同的局部区域或其特征可看作构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,可以把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。理论对应关系如下:文档单词字典图像特征聚类中心特征聚类集合 用词袋模型生成对一张图像的描述向量的处理步骤: 1、局部特征提取 通过兴趣点检测、密集采样或随机采集,结合图割区域、 显著区域等方式获得图像各处的局部特征。常用的是 SIFT 特征和Dense SIFT 特征。 2、构建视觉词典 在整个训练集上提取局部特征后,使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心可以看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看作一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),词典中所含词的个数反映了词典的大小。
遥感图像分类方法的国内外研究现状与发展趋势
遥感图像分类方法的研究现状与发展趋势 摘要:遥感在中国已经取得了世界级的成果和发展,被广泛应用于国民经济发展的各个方面,如土地资源调查和管理、农作物估产、地质勘查、海洋环境监测、灾害监测、全球变化研究等,形成了适合中国国情的技术发展和应用推广模式。随着遥感数据获取手段的加强,需要处理的遥感信息量急剧增加。在这种情况下,如何满足应用人员对于大区域遥感资料进行快速处理与分析的要求,正成为遥感信息处理面临的一大难题。这里涉及二个方面,一是遥感图像处理本身技术的开发,二是遥感与地理信息系统的结合,归结起来,最迫切需要解决的问题是如何提高遥感图像分类精度,这是解决大区域资源环境遥感快速调查与制图的关键。 关键词:遥感图像、发展、分类、计算机 一、遥感技术的发展现状 遥感技术正在进入一个能够快速准确地提供多种对地观测海量数据及应用研究的新阶段,它在近一二十年内得到了飞速发展,目前又将达到一个新的高潮。这种发展主要表现在以下4个方面: 1. 多分辨率多遥感平台并存。空间分辨率、时间分辨率及光谱分辨率普遍提高目前,国际上已拥有十几种不同用途的地球观测卫星系统,并拥有全色0.8~5m、多光谱3.3~30m的多种空间分辨率。遥感平台和传感器已从过去的单一型向多样化发展,并能在不同平台
上获得不同空间分辨率、时间分辨率和光谱分辨率的遥感影像。民用遥感影像的空间分辨率达到米级,光谱分辨率达到纳米级,波段数已增加到数十甚至数百个,重复周期达到几天甚至十几个小时。例如,美国的商业卫星ORBVIEW可获取lm空间分辨率的图像,通过任意方向旋转可获得同轨和异轨的高分辨率立体图像;美国EOS卫星上的MOiDIS-N传感器具有35个波段;美国NOAA的一颗卫星每天可对地面同一地区进行两次观测。随着遥感应用领域对高分辨率遥感数据需求的增加及高新技术自身不断的发展,各类遥感分辨率的提高成为普遍发展趋势。 2. 微波遥感、高光谱遥感迅速发展微波遥感技术是近十几年发展起来的具有良好应用前景的主动式探测方法。微波具有穿透性强、不受天气影响的特性,可全天时、全天候工作。微波遥感采用多极化、多波段及多工作模式,形成多级分辨率影像序列,以提供从粗到细的对地观测数据源。成像雷达、激光雷达等的发展,越来越引起人们的关注。例如,美国实施的航天飞机雷达地形测绘计划即采用雷达干涉测量技术,在一架航天飞机上安装了两个雷达天线,对同一地区一次获取两幅图像,然后通过影像精匹配、相位差解算、高程计算等步骤得到被观测地区的高程数据。高光谱遥感的出现和发展是遥感技术的一场革命。它使本来在宽波段遥感中不可探测的物质,在高光谱遥感中能被探测。高光谱遥感的发展,从研制第一代航空成像光谱仪算起已有二十多年的历史,并受到世界各国遥感科学家的普遍关注。但长期以来,高光谱遥感一直处在以航空为基础的研究发展阶段,且主要
杭州师范大学《遥感原理与应用》实验报告 题目:遥感图像的监督分类与处理实验姓名:赵文彪 学号: 2014212425 班级:地信141 学院:理学院
1实验目的 运用envi软件对自己家乡的遥感影像经行分类和分类后操作。 2概述 分类方法:监督分类和非监督分类 监督分类——从遥感数据中找到能够代表已知地面覆盖类型的均质样本区域(训练样区),然后用这些已知区域的光谱特征(包括均值、标准差、协方差矩阵和相关矩阵等)来训练分类算法,完成影像剩余部分的地面覆盖制图(将训练样区外的每个像元划分到具有最大相似性的类别中)。 非监督分类——依据一些统计判别准则将具有相似光谱特征的像元组分分为特定的光谱类;然后,再对这些光谱类进行标识并合并成信息类。 光谱特征空间 同名地物点在丌同波段图像中亮度的观测量将构成一个多维的随机向量X,称为光谱特征向量。而这些向量在直角坐标系中分布的情况为光谱特征空间。 同类地物在光谱特征空间中不可能是一个点,而是形成一个相对聚集的点群。丌同地物的点群在特征空间内一般具有不同的分布。 特征点集群的分布情况: 理想情况:至少在一个子空间中可以相互区分 典型情况:任一子空间都有相互重叠,总的特征空间可以区分 一般情况:任一子空间都存在重叠现象 监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。在分类乊前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决凼数迚行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决凼数去对其他待分数据迚行分类。使每个像元和训练样本做比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。 3实验步骤 3.1遥感影像图的剪切 用envi打开下载的遥感影像图,剪切出一个地貌信息丰富的区域(因为一景遥感影像太大,分类时间较长,故而采用剪切的方法,剪切一个地貌丰富的遥感影像图。既便于分类也使得分类种数不至于减小的太多) 以下为剪切出来的遥感影像
JPEG/BMP/TIF/PNG四种图像格式有什么不同? 一、BMP格式BMP是英文Bitmap(位图)的简写,它是Windows操作系统中的标准图像文件格式,能够被多种Windows应用程序所支持。随着Windows操作系统的流行与丰富的Windows应用程序的开发,BMP位图格式理所当然地被广泛应用。这种格式的特点是包含的图像信息较丰富,几乎不进行压缩,但由此导致了它与生俱生来的缺点--占用磁盘空间过大。所以,目前BMP在单机上比较流行。 二、GIF格式GIF是英文Graphics Interchange Format(图形交换格式)的缩写。顾名思义,这种格式是用来交换图片的。事实上也是如此,上世纪80年代,美国一家著名的在线信息服务机构CompuServe针对当时网络传输带宽的限制,开发出了这种GIF图像格式。GIF格式的特点是压缩比高,磁盘空间占用较少,所以这种图像格式迅速得到了广泛的应用。最初的GIF只是简单地用来存储单幅静止图像(称为GIF87a),后来随着技术发展,可以同时存储若干幅静止图象进而形成连续的动画,使之成为当时支持2D动画为数不多的格式之一(称为GIF89a),而在GIF89a图像中可指定透明区域,使图像具有非同一般的显示效果,这更使GIF风光十足。目前Internet上大量采用的彩色动画文件多为这种格式的文件,也称为GIF89a格式文件。此外,考虑到网络传输中的实际情况,GIF图像格式还增加了渐显方式,也就是说,在图像传输过程中,用户可以先看到图像的大致轮廓,然后随着传输过程的继续而逐步看清图像中的细节部分,从而适应了用户的"从朦胧到清楚"的观赏心理。目前Internet上大量采用的彩色动画文件多为这种格式的文件。但GIF有个小小的缺点,即不能存储超过256色的图像。尽管如此,这种格式仍在网络上大行其道应用,这和GIF图像文件短小、下载速度快、可用许多具有同样大小的图像文件组成动画等优势是分不开的。三、JPEG格式JPEG也是常见的一种图像格式,它由联合照片专家组(Joint Photographic Experts Group)开发并以命名为"ISO 10918-1",JPEG仅仅是一种俗称而已。JPEG文件的扩展名为.jpg或.jpeg,其压缩技术十分先进,它用有损压缩方式去除冗余的图像和彩色数据,获取得极高的压缩率的同时能展现十分丰富生动的图像,换句话说,就是可以用最少的磁盘空间得到较好的图像质量。同时JPEG还是一种很灵活的格式,具有调节图像质量的功能,允许你用不同的压缩比例对这种文件压缩,比如我们最高可以把1.37MB 的BMP位图文件压缩至20.3KB。当然我们完全可以在图像质量和文件尺寸之间找到平衡点。由于JPEG 优异的品质和杰出的表现,它的应用也非常广泛,特别是在网络和光盘读物上,肯定都能找到它的影子。目前各类浏览器均支持JPEG这种图像格式,因为JPEG格式的文件尺寸较小,下载速度快,使得Web页有可能以较短的下载时间提供大量美观的图像,JPEG同时也就顺理成章地成为网络上最受欢迎的图像格式。 四、JPEG2000格式JPEG 2000同样是由JPEG 组织负责制定的,它有一个正式名称叫做"ISO 15444",与JPEG相比,它具备更高压缩率以及更多新功能的新一代静态影像压缩技术。JPEG2000 作为JPEG的升级版,其压缩率比JPEG高约30%左右。与JPEG不同的是,JPEG2000 同时支持有损和无损压缩,而JPEG 只能支持有损压缩。无损压缩对保存一些重要图片是十分有用的。JPEG2000的一个极其重要的特征在于它能实现渐进传输,这一点与GIF的"渐显"有异曲同工之妙,即先传输图像的轮廓,然后逐步传输数据,不断提高图像质量,让图象由朦胧到清晰显示,而不必是像现在的JPEG 一样,由上到下慢慢显示。此外,JPEG2000还支持所谓的"感兴趣区域"特性,你可以任意指定影像上你感兴趣区域的压缩质量,还可以选择指定的部份先解压缩。JPEG 2000 和JPEG 相比优势明显,且向下兼容,因此取代传统的JPEG格式指日可待。JPEG2000可应用于传统的JPEG市场,如扫描仪、数码相机等,亦可应用于新兴领域,如网路传输、无线通讯等等。 五、TIFF格式TIFF(Tag Image File Format)是Mac中广泛使用的图像格式,它由Aldus和微软联合开发,最初是出于跨平台存储扫描图像的需要而设计的。它的特点是图像格式复杂、存贮信息多。正因为它存储的图像细微层次的信息非常多,图像的质量也得以提高,故而非常有利于原稿的复制。该格式有压缩和非压缩二种形式,其中压缩可采用LZW无损压缩方案存储。不过,由于TIFF格式结构较为复杂,兼容性较差,因此有时你的软件可能不能正确识别TIFF文件(现在绝大部分软件都已解决了这个问题)。目前在Mac和PC机上移植TIFF文件也十分便捷,因而TIFF现在也是微机上使用最广泛的图像文件格式之一。
第2期,总第64期国 土 资 源 遥 感No.2,2005 2005年6月15日RE MOTE SENSI N G F OR LAND&RES OURCES Jun.,2005 遥感图像分类方法研究综述 李石华1,王金亮1,毕艳1,2,陈姚1,朱妙园1,杨帅3,朱佳1 (1.云南师范大学旅游与地理科学学院,昆明 650092;2.云南省寄生虫病防治所,思茅 665000; 3.云南开远市第一中学,开远 661600) 摘要:综述了遥感图像监督分类和非监督分类中的各种方法,介绍了各种方法的优缺点、适用领域和应用情况,并作了简单评述,最后,展望了遥感图像分类方法研究发展方向和研究热点。 关键词:遥感;图像分类;分类方法 中图分类号:TP751 文献标识码:A 文章编号:1001-070X(2005)02-0001-06 0 引言 随着卫星遥感和航空遥感图像分辨率的不断提 高,人们可以从遥感图像中获得更多有用的数据和 信息。由于不同领域遥感图像的应用对遥感图像处 理提出了不同的要求,所以图像处理中重要的环 节———图像分类也就显得尤为重要,经过多年的努 力,形成了许多分类方法和算法。本文较全面地综 述了这些分类方法和算法,为遥感图像分类提供理 论指导。 1 遥感图像分类研究现状 在目前遥感分类应用中,用得较多的是传统的 模式识别分类方法,诸如最小距离法、平行六面体 法、最大似然法、等混合距离法(I S OM I X)、循环集群 法(I S ODAT A)等监督与非监督分类法。其分类结果 由于遥感图像本身的空间分辨率以及“同物异谱”、 “异物同谱”现象的存在,往往出现较多的错分、漏分 现象,导致分类精度不高[1]。随着遥感应用技术的 发展,傅肃性等对P.V.Balstad(1986)利用神经网络 进行遥感影像分类的研究情况以及章杨清等在利用 分维向量改进神经网络在遥感模式识别中的分类精 度问题作了阐述[2], 孙家对M.A.Friedl(1992)和 C.E.B r odley(1996)研究的大量适用于遥感图像分类的决策树结构作了阐述[3],尤其是近年来针对高光谱数据的广泛应用,各种新理论新方法相继涌现,对传统计算机分类方法提出了新的要求[4,5]。 2 基于统计分析的遥感图像分类方法 2.1 监督分类 监督分类是一种常用的精度较高的统计判决分类,在已知类别的训练场地上提取各类训练样本,通过选择特征变量、确定判别函数或判别规则,从而把图像中的各个像元点划归到各个给定类的分类方法[2,3,6,7]。常用的监督分类方法有:K邻近法(K-Nearest Neighbor)、决策树法(Decisi on Tree Classifi2 er)和贝叶斯分类法(Bayesian Classifier)。主要步骤包括:①选择特征波段;②选择训练区;③选择或构造训练分类器;④对分类精度进行评价。 最大似然分类法(MLC)是遥感分类的主要手段之一。其分类器被认为是一种稳定性、鲁棒性好的分类器[8]。但是,如果图像数据在特征空间中分布比较复杂、离散,或采集的训练样本不够充分、不具代表性,通过直接手段来估计最大似然函数的参数,就有可能造成与实际分布的较大偏差,导致分类结果精度下降。为此,不少学者提出了最大似然分类器和神经网络分类器。改进的最大似然分类器多采用Gauss光谱模型作为条件概率密度函数模型,其中最简单的是各类先验概率相等的分类器(即通常所说的最大似然分类器),复杂的有Ediri w ickre ma等提出的启发式像素分类估计先验概率法。Mclachlang J 收稿日期:2004-11-23;修订日期:2005-03-15 基金项目:国家重点基础研究发展计划(973计划)项目(2003CB41505-11)、国家自然科学基金项目(40361007)和云南省自然科学基金项目(2002D0036M和2003C0030Q)资助。
envi遥感图像监督分类 监督分类,又称训练分类法,用被确认类别的样本像元去识别其他未知类别像元的过程。它就是在分类之前通过目视判读和野外调查,对遥感图像上某些样区中影像地物的类别属性有了先验知识,对每一种类别选取一定数量的训练样本,计算机计算每种训练样区的统计或其他信息,同时用这些种子类别对判决函数进行训练,使其符合于对各种子类别分类的要求,随后用训练好的判决函数去对其他待分数据进行分类。使每个像元和训练样本作比较,按不同的规则将其划分到和其最相似的样本类,以此完成对整个图像的分类。 遥感影像的监督分类一般包括以下6个步骤,如下图所示: 详细操作步骤 第一步:类别定义/特征判别 根据分类目的、影像数据自身的特征和分类区收集的信息确定分类系统;对影像进行特征判断,评价图像质量,决定是否需要进行影像增强等预处理。这个过程主要是一个目视查看的过程,为后面样本的选择打下基础。
启动ENVI5.1,打开待分类数据:can_tmr.img。以R:TM Band 5,G: TM Band 4,B:TM Band 3波段组合显示。 通过目视可分辨六类地物:林地、草地/灌木、耕地、裸地、沙地、其他六类。 第二步:样本选择 (1)在图层管理器Layer Manager中,can_tmr.img图层上右键,选择"New Region Of Interest",打开Region of Interest (ROI) Tool面板,下面学习利用选择样本。 1)在Region of Interest (ROI) Tool面板上,设置以下参数: ROI Name:林地 ROI Color: 2)默认ROIs绘制类型为多边形,在影像上辨别林地区域并单击鼠标左键开始绘制多边形样本,一个多边形绘制结束后,双击鼠标左键或者点击鼠标右键,选择Complete and Accept Polygon,完成一个多边形样本的选择; 3)同样方法,在图像别的区域绘制其他样本,样本尽量均匀分布在整个图像上; 4)这样就为林地选好了训练样本。 注:1、如果要对某个样本进行编辑,可将鼠标移到样本上点击右键,选择Edit record是修改样本,点击Delete record是删除样本。 2、一个样本ROI里面可以包含n个多边形或者其他形状的记录(record)。 3、如果不小心关闭了Region of Interest (ROI) Tool面板,可在图层管理器Layer Manager上的某一类样本(感兴趣区)双击鼠标。 (2)在图像上右键选择New ROI,或者在Region of Interest (ROI) Tool面板上,选择工具。重复"林地"样本选择的方法,分别为草地/灌木、耕地、裸地、沙地、其他5类选择样本; (3)如下图为选好好的样本。
、 扩展名,用于和地位图()格式,文件几乎不压缩,由于无法压缩,因此缺点是文件容量太大,使用于壁纸等方面.个人收集整理勿做商业用途 特点:占用磁盘空间较大,它地颜色存储格式有位、位、位及位.开发环境下地软件时,格式是最不容易出问题地格式,并且与环境下地图像处理软件都支持该格式,因此,该格式是当今应用比较广泛地一种格式.但缺点是该格式文件比较大,所以只能应用在单机上,不受网络欢迎.个人收集整理勿做商业用途 全名,扩展名,是有损高压缩地图像压缩格式.在存储时能够将人眼无法分辨地资料删除,以节省存储空间,但这些被删除地资料无法在解压时还原,所以文件并不适合放大观看,输出成印刷品时品质也会受到影响,这种类型地压缩格式,称为[失真()压缩]或[破坏性压缩]个人收集整理勿做商业用途 特点:压缩率高,占用空间小,适合网络传输或上载.最高支持真色彩.可包含信息.地有标准、精细和特精细等种,分辨率下占用空间分别 个人收集整理勿做商业用途 与 全名,扩展名; 全名,扩展名; 是无损无压缩地图像格式.他们格式都包含两个部份,第一部份是屏幕显示地低解析度影像,方便影像处理时地预览和定位,而另一部份包含各分色地单独资料.常被用于彩色图像地扫描,它是以地全彩模式存储.而文件是以地形式存储,文件中包含四种颜色地单独资料,可以直接输出四色网片.个人收集整理勿做商业用途 特点:可压缩或无压缩,通常压缩比最高到:.支持最高真色彩,同时支持、等多种色彩模式.占用空间大,适用于印刷、冲印输出.可包含信息.地格式,分辨率下占用空间最大,达到.个人收集整理勿做商业用途 全名,扩展名,是一种失真有损地压缩个人收集整理勿做商业用途 格式,在压缩过程中能保证图像地像素资料,但丢失图像地色彩 公司开放使用权限,所以广受应用. 特点:只能存储色,但它地格式,能存储成背景透明化地形式,并且可以将数张图存成一个文件,形成动画效果.适用于各种主机平台,各种软件皆有支持,普遍用于网络传输.占用空间极小.无该格式.个人收集整理勿做商业用途 扩展名公司开发地图像处理软件中自建地标准文件格式就是格式,在该软件所支持地各种格式中,其存取速度比其它格式快很多,功能也很强大.由于软件越来越广泛地应用,所以这个格式也逐步流行起来.格式是地专用格式,里面可以存放图层、通道、遮罩等多种设计草稿.以便于下次打开文件可以修改上一次地设计个人收集整理勿做商业用途 扩展名,是一种无损压缩格式.数据是没有经过相机处理地原文件,因此它地大小要比格式略小.所以,当上传到电脑之后,要用图像软件地界面直接导入成格式才能处理.个人收集整理勿做商业用途 特点:能保持最完整地细节,可支持地专用调节工具,可调曝光范围~档,可增加地相对宽容度,是一个高档比较流行地专业图像格式,可转成无损地格式,或压缩成格式.地,由于优化了压缩方式,分辨率下占用空间只有地一半,.推荐使用.个人收集整理勿做商业用途