
图像分类学习笔记:词袋模型和空间金字塔匹配
Image Classification Framework:
Bag-of-Words &Spatial Pyramid Matching
一、基础:词袋模型(Bag of Words )
Bag-of-Words (词袋、词包)模型,或称Bag of Features 模型,源于文本分类技术。在信息检索中,假定对于一个文本,忽略其词序和语法、句法。将其仅仅看作是一个词的集合,每个词都是彼此概率独立的。这样可以通过文档中单词出现的频率来对文档进行描述与表达。Csurka 等[1]于2004年将其引入计算机视觉领域。
其核心思想在于,图像可以视为一种文档对象,图像中不同的局部区域或其特征可看作构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,可以把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。理论对应关系如下:文档单词字典图像特征聚类中心特征聚类集合
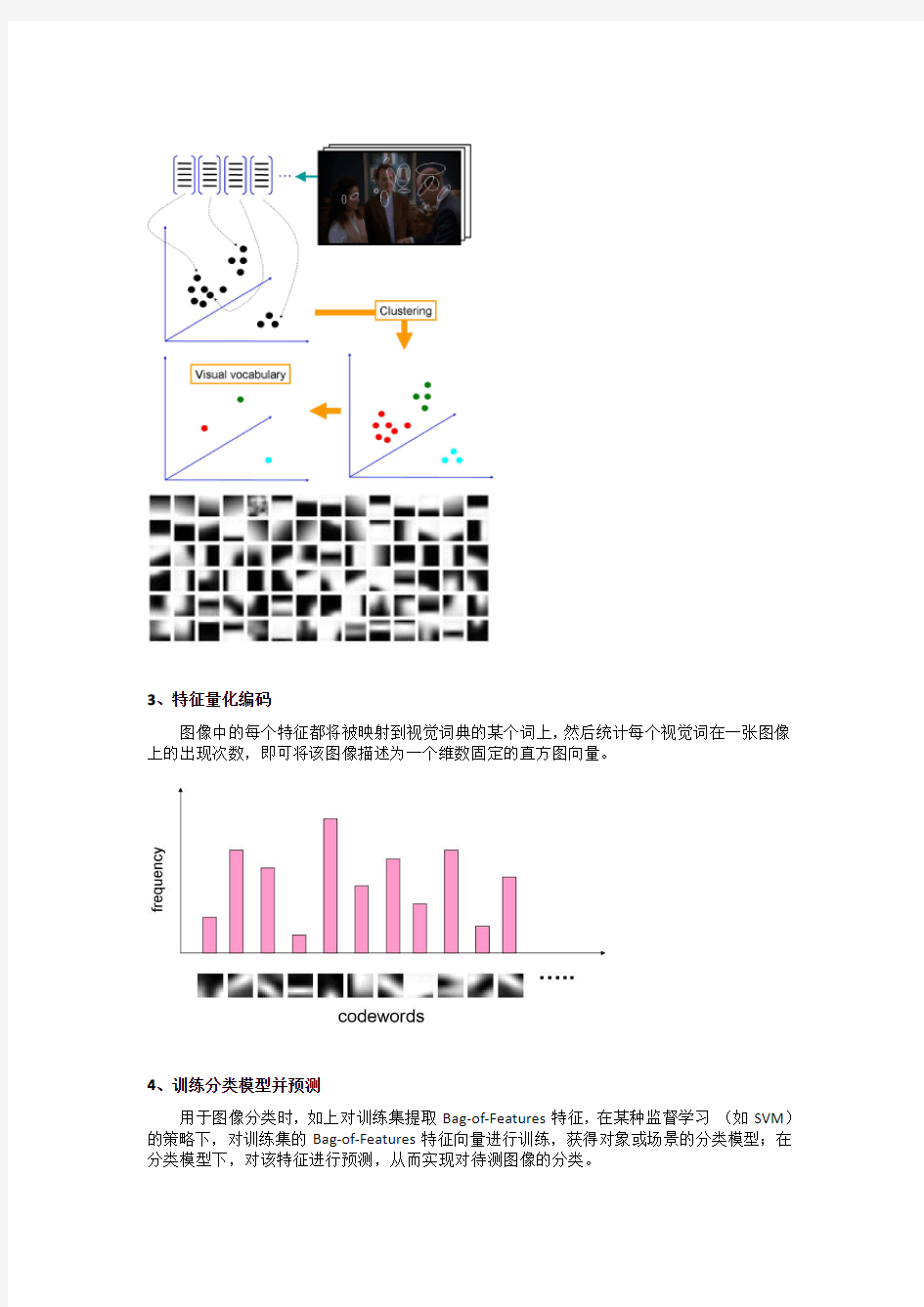
用词袋模型生成对一张图像的描述向量的处理步骤:
1、局部特征提取
通过兴趣点检测、密集采样或随机采集,结合图割区域、
显著区域等方式获得图像各处的局部特征。常用的是
SIFT 特征和Dense SIFT 特征。
2、构建视觉词典
在整个训练集上提取局部特征后,使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心可以看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看作一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),词典中所含词的个数反映了词典的大小。
3、特征量化编码
图像中的每个特征都将被映射到视觉词典的某个词上,然后统计每个视觉词在一张图像上的出现次数,即可将该图像描述为一个维数固定的直方图向量。
4、训练分类模型并预测
用于图像分类时,如上对训练集提取Bag-of-Features特征,在某种监督学习(如SVM)的策略下,对训练集的Bag-of-Features特征向量进行训练,获得对象或场景的分类模型;在分类模型下,对该特征进行预测,从而实现对待测图像的分类。
(示意图片来源于网络)
词袋模型中一些需要商榷的实现问题:
1、使用k-means聚类,除了其K和初始聚类中心选择的问题外,对于海量数据,输入矩阵的巨大将使得内存溢出及效率低下。训练集变化时重新聚类的代价也很高。
2、字典大小的选择也是问题,字典过大,单词缺乏一般性,对噪声敏感,计算量大,关键是图象投影后的维数高;字典太小,单词区分性能差,对相似的目标特征无法表示。
3、相似性测度函数用来将图象特征分类到单词本的对应单词上,其涉及线型核,塌方距离测度核,直方图交叉核等的选择。
4、将图像表示成一个无序局部特征集的特征包方法,丢掉了所有的关于空间特征布局的信息,在描述性上具有一定的有限性。为此,Lazebnik[2]提出了基于空间金字塔的Bag-of-Features,下面部分中将会详述。
此外,基于词袋模型的改进方法还有很多,见下一部分。
二、综述:基于词袋模型的图像分类方法框架
词袋模型提出后,图像分类领域大量的研究工作开始集中于该模型的相关研究,并逐渐形成了主要由以下四部分组成的图像分类方法框架:
1、底层特征提取(SIFT、Dense SIFT、多特征)
2、特征编码(硬量化编码、稀疏编码、fisher vector等)
3、特征汇聚(空间金字塔SPM)
4、分类器分类(SVM、Adaboost、Na?ve Bayes等)
其中第三部分的基础是Lazebnik等人[2]在CVPR2006上提出的空间金字塔(SPM)方法,在当前基于词袋模型的分类框架中几乎已成为标准步骤。该论文也是完整实现了以上框架的经典文章。后面有进一步的介绍。
(用于图像分类的另一主流框架:自从2006年Hinton教授于Science上发表文章,开启了深度学习在学术界和工业界的浪潮,深度学习框架也被大量应用于图像分类领域,并取得了更加优异的表现。此处不涉及。)
e.g,SIFT,HOG
VQ Coding Average Pooling (obtain histogram)
SVM Local Gradients Pooling (示意图来自于Kai Yu ,CVPR2012tutorial )
1、底层特征提取(describing )
词袋模型的基础就是图像局部特征提取,底层特征是图像分类检测框架的第一步。在此方面的改进主要包括局部特征描述方法的设计和采集方式的优化。目前常用的是SIFT 特征和Dense SIFT 特征。
特征采集方式主要包括兴趣点检测、密集采样或随机采集等。兴趣点检测通过某种准则选取一些像素点、角点等,可以在较小的开销下得到有一定意义的表达。常用兴趣点检测算子有Harris 角点、FAST 算子、高斯差分算子DoG 、高斯拉普拉斯算子LoG 等。密集采样则是用均匀网格划分图像,提取局部描述子向量。随机采样不必详述。
在诸多的局部图像特征描述子中,SIFT (Scale Invariant Feature Transform )是其中应用最广的。SIFT 算法包括兴趣点提取和局部描述两步。Dense-SIFT 则是用密集采样方法结合SIFT 的局部描述形成描述图像的一组特征向量。用于图像分类的PHOW 描述子[3]是Dense-SIFT 的变体,结合其他算法步骤在Caltech 数据集上可以取得很好的分类效果。
基于SIFT 改进的局部描述子还包括SURF 、PCA-SIFT 、Color-SIFT 等,一篇PAMI 2013的论文[4]提供了一个改进的p-sift 描述子。此外还有HOG 、LBP 、
MSER 等重要描述方法,以及近年来兴起的一系列二值特征描述子BRIEF 、ORB 、BRISK 、FREAK 等。
(上图:OpenCV 2.4.8支持的局部描述子)
此外,BOF 为基础的图像分类方法主要依赖于低级局部形状特征。而融合多种线索如颜色、纹理、形状的工作,足以提升分类准确度。采取多种特征融合的分类框架也都取得了不错的结果,如Fernando 等人[5](CVPR2012)。
2、特征编码(coding)
提取的底层特征中包含大量冗余和噪声,或者向量没有归一化,为提高特征表达的鲁棒性,使之适用于图像分类任务,需要对提取到的特征向量集合进行一定变换,获得更具有区分性的图像层级表达。这就是特征编码(coding)。这一步对识别性能具有至关重要的作用,因而大量的研究工作都集中在寻找更加强大的特征编码方法上。
硬编码与软编码:
Bag of Words模型使用的编码方式是向量量化编码,这种编码方式最为简单直观,只是利用量化的思想进行距离计算与聚合,因此又称为硬编码。作为一种改进,Gemert等人[6](ECCV2008)提出了软量化编码(核视觉词典编码),其思想是局部特征不再使用一个视觉单词描述,而是由距离最近的K个视觉单词加权后进行描述,可以有效解决视觉单词的模糊性问题。
稀疏编码:
2009年,Yang等人[7](CVPR2009,ScSPM)将稀疏编码应用到图像分类领域,用于替代向量量化等编码方法,得到一个高位的高度系数的特征表达,提高了特征表达的线性可分性,因此仅用线性分类器就可得到当时最佳的结果。在其上的改进包括局部线性约束编码[8](CVPR2010,LLCSPM)等。
Fisher vector、super vector向量编码:
Fisher向量[9-10]、超向量编码[11]是两种近年提出的性能最好的特征编码方法,它们都可以认为是编码局部特征与视觉单词的差。(出现于ECCV2010)。Fisher向量编码同时融合了产生式模型和判别式模型的能力,与传统的基于重构的特征编码方法不同,它记录了局部特征与视觉单词之间的一阶差分和二阶差分。超向量编码则直接使用局部特征与最近的视觉单词的差来替换之前简单的硬投票。这种特征编码方式得到的特征向量表达通常是传统基于重构编码方法的M倍(这里M是局部特征的维度)。尽管维数很高,这两种方法在许多数据集上取得了最先进的性能,被应用于图像分类、标注、检索等方面。
局部特征聚合描述符VLAD(vector of locally aggregated descriptors)也类似,方法是如同BOF先建立出含有K个visual word的codebook,而不同于BOF将一个local descriptor分类到最近的visual word中,VLAD所采用的是计算出local descriptor和每个visual word在每个分量上的差距,将每个分量的差距形成一个新的向量来代表图片。VLAD是CVPR2010的论文[12],其目标应用是图像检索领域。
其他:
显著性编码[13]引入了视觉显著性的概念,如果一个局部特征到最近和次近的视觉单词的距离差别很小,则认为这个局部特征是不“显著的”,从而编码后的响应也很小。显著性编码通过这样很简单的编码操作,在Caltech101/256,PASCAL VOC2007等数据库上取得了非常好的结果,而且由于是解析的结果,编码速度也比稀疏编码快很多。该思想出自Huang 等人的论文(CVPR2011),他们发现显著性表达配合最大值汇聚在特征编码中有重要的作用,并认为这正是稀疏编码、局部约束线性编码等之所以在图像分类任务上取得成功的原因。
概率密度函数(p.d.f)分布图[14]是一个较为新颖的思想,来自CVPR2013,基本思想是在词袋模型框架下,采取对特征概率密度图的方向梯度编码方法。该方法通过计算特征的pdf(概率密度函数)来获得特征的表达,其中计算pdf采用KDE(核密度估计)算法。这样一幅图像得到一个pdf,再套用HOG的计算模式表达一幅图像,也属于对特征的进一步加工,因此将其归类于编码方法。
3、特征汇聚(pooling)
主要是空间特征汇聚。空间金字塔匹配(Spatial Pyramid Matching,SPM)方法在当前基于词袋模型的分类框架中是极为常见的步骤。SPM在论文[2](Lazebnik等,CVPR2006)上被提出,截至本文落笔时在Google Scholar上的引用已高达4000余次。该论文完整实现了基于词袋模型的图像分类框架。如下图。
Image Classification
VQ Coding
Spatial Pooling
Classifier
(示意图来自于Kai Yu,CVPR2012tutorial)
下面简要介绍一下这篇论文的思想和实现。
Bag of Visual Words模型被大量地用在了图像表示中,但是BOVW模型完全缺失了特征点的位置信息。本文的提出即旨在解决此问题。
该论文所提出的分类方法大致包括三个方面的要点,一是提取Dense-SIFT特征并用矢量量化(VQ)方式进行编码;二是对硬编码之后的特征向量进行空间汇聚,采用直方图统计方法;三是用SVM分类时,采用histogram intersection核。
首先,密集采样提取局部特征点。用边长为8像素的均匀网格(grid)划分图像,在4个grid形成的patch上提取SIFT描述子。每个patch是16*16像素的矩形,包含4*4个bin,每个bin是4*4像素。在每个bin中计算8个方向的梯度信息,于是每个patch由4*4*8=128维向量表征。patch移动的步长是网格边长8像素,整张图像的表征维度是patch的个数乘以128维。
其次,空间汇聚方法。空间金字塔(spatial pyramid)是局部无序图像在不同空间分辨率上的聚集,相比图像分块再计算局部特征的直方图具有多分辨率的优势。作者采用了一种多尺度的分块方法,呈现出一种层次金字塔的结构,在Caltech数据集上一般采取1*1、2*2、4*4空间分块的三层金字塔。每层金字塔的提取方式和分块直方图类似:将图像分成若干块,分别统计每一子块的特征,最后将所有块的特征拼接起来,形成完整的特征。这样就有了空间信息(Spatial)。
最后,在分类器方面采取的直方图匹配方法,在SVM分类器中用直方图正交核进行分类。直方图匹配(Pyramid Matching)方法最初来自The Pyramid Match Kernel: Discriminative Classification with Sets of Image Features这篇论文,用来对特征构成的直方图进行相似度匹配。大致思想是在多分辨率的直方图上每层进行区间的匹配计算,每两个样本之间可以计算出一个匹配值,该值越高说明两样本越相似。整体得到一个样本数目为边长的匹配方阵,称为直方图正交核,用于SVM分类。
关于SPM方法的改进这里不做详述。
4、分类(classifying)
经过以上各个特征提取和汇聚的步骤后,最终要采取一种分类器完成分类。常见用于此任务的分类器有SVM、AdaBoost、Na?ve Bayes等。
许多方法采取非线性SVM分类器。分类核可以用常用的RBF核,也可以用上文提过的直方图正交核。采取直方图正交核的分类准确率更高。线性SVM分类器由于其自身的优势,也为许多研究者所采用。这具体涉及到各个方法所形成最终分类特征的线性可分性。
参考文献
[1]Csurka G,Dance C,Fan L,et al.Visual categorization with bags of keypoints:ECCV2004[C].
[2]Lazebnik S,Schmid C,Ponce J.Beyond bags of features:Spatial pyramid matching for recognizing natural scene categories:CVPR2006[C].
[3]A.Bosch,A.Zisserman,and X.Munoz.Image classifcation using random forests and ferns.In Proc.ICCV,2007.
[4]Seidenari L,Serra G,Bagdanov A,et al.Local pyramidal descriptors for image recognition[J]. PAMI2013,IEEE Transactions on Pattern Analysis and Machine Intelligence,2013.
[5]Fernando B,Fromont E,Muselet D,et al.Discriminative feature fusion for image classification:CVPR2012,2012[C].
[6]van Gemert J C,Geusebroek J,Veenman C J,et al.Kernel codebooks for scene categorization: ECCV2008,2008[C].Springer.
[7]Yang J,Yu K,Gong Y,et al.Linear spatial pyramid matching using sparse coding for image classification:CVPR2009[C].June.
[8]Wang J,Yang J,Yu K,et al.Locality-constrained Linear Coding for image classification:CVPR 2010[C].June.
[9]Perronnin F,Dance C.Fisher Kernels on Visual Vocabularies for Image Categorization:CVPR 2007,2007[C].June.
[10]Florent Perronnin,Jorge Sánchez,and Thomas Mensink.Improving the fisher kernel for large-scale image classification.ECCV2010,6314:143-156
[11]Zhou Xi,Yu Kai,Zhang Tong,and Thomas S.Huang.Image classification using super-vector coding of local image descriptors.ECCV2010:141–154
[12]HervéJégou,Matthijs Douze,Cordelia Schmid,Patrick Pérez.Aggregating local descriptors into a compact image representation.CVPR2010.
[13]Huang Y,Huang K,Yu Y,et al.Salient coding for image classification:CVPR2011, 2011[C].June.
[14]Kobayashi T.BOF Meets HOG:Feature Extraction Based on Histograms of Oriented p.d.f. Gradients for Image Classification:CVPR2013[C].June.
其他参考材料
[1]黄凯奇,任伟强,谭铁牛.图像物体分类与检测算法综述[J].计算机学报, 2014,37(6):1225-1240.
[2]Bag of Features之于图像检索[OL].https://www.doczj.com/doc/3516109332.html,/work/bag-of-features.html
[3]Kai Yu.CVPR12Tutorial on Deep Learning:Sparse Coding
第12卷 第5期太赫兹科学与电子信息学报Vo1.12,No.5 2014年10月 Journal of Terahertz Science and Electronic Information Technology Oct.,2014 文章编号:2095-4980(2014)05-0726-05 一种基于词袋模型的图像分类方法 杨晓敏,严斌宇*,李康丽,苏冰山 (四川大学电子信息学院,四川成都 610064) 摘要:采用词袋模型(BoW)对图像进行分类,并针对传统词袋模型存在的不足进行了改进,提出了一种特征软量化的方式。软赋值量化通过将局部显著特征量化(SIFT)为与其距离最近 的若干个视觉单词,并对其进行加权,由此保存特征空间中的距离信息,从而解决硬赋值量化造 成的特征空间信息损失问题。通过在Caltech 101数据库进行实验,验证了本文方法的有效性,实 验结果表明,该方法能够大幅度提高图像分类的性能。 关键词:词袋模型;视觉词典;图像分类 中图分类号:TN911.73;TP391.4文献标识码:A doi:10.11805/TKYDA201405.0726 An image classification method based on bag of words model YANG Xiao-min,YAN Bin-yu*,LI Kang-li,SU Bing-shan (College of Electronics and Information Engineering,Sichuan University,Chengdu Sichuan 610064,China) Abstract:The Bag of Words(BoW) model is applied to object classification. An improved algorithm based on soft quantification is proposed. This algorithm quantifies the Scale-Invariant Feature Transform (SIFT) descriptor into several nearest visual words and performs weighting on them, which can conserve the space information. Therefore, it can avoid the information loss of eigen space caused by hard quantification. The experiments are carried out on Caltech 101 database. Experimental results show that the proposed method performs better than traditional method on image classification. Key words:Bag of Words model;visual words;image classification 近年来,图像数量的大量激增给图像识别、检索以及分类等问题带来了巨大的挑战。如何在浩瀚的数据中准确获得用户所需信息并进行处理,成为该领域亟待解决的问题之一。词袋模型最初应用于文档处理领域,将文档表示成顺序无关的关键词的组合,通过统计文档中关键词出现的频率来进行匹配。近几年来,计算机视觉领域的研究者们成功地将该模型的思想移植到图像处理领域[1–2],词袋模型(BoW)将图像库看成文档库,将一幅图像看作一篇文档。提取图像特征后,用其生成“视觉单词”,即生成字典,统计每幅图像的视觉单词出现频率,即可完成图像的词袋描述。为了进一步提高该模型的性能,使其在图像识别和分类领域得到更好的应用,研究者们一直致力于对模型的实现过程进行改进和优化[3–8]。 传统局部显著特征的量化就是计算每个局部显著特征与词典中所有视觉单词的最小距离,并将该局部特征用距离它最近的视觉单词进行量化[9–10]。这种方式下局部显著特征的量化仅仅是局部特征之间真实距离的一种粗糙的近似,局部特征在量化过程之中会损失空间信息。处于量化边界两侧的点,虽然实际距离很近,但是量化后其距离就会较大;而处于量化边界同侧的点,虽然实际距离可能很远,但是量化后距离很近。实际上,图像的噪声、场景光照变化、遮挡等因素,导致同一个物体某一区域在不同的图像中,局部显著特征会存在较大差异。在量化时,有可能被量化为不同的视觉单词。因此这种硬赋值方式的量化就会造成检索的错误。本文在传统词袋模型基础上,针对局部显著特征的量化算法进行研究,建立新的量化方式,保存局部显著特征的空间信息,以解决量化赋值带来的信息损失问题。实验结果表明本文方法能够提高图像检索的性能。 收稿日期:2014-07-08;修回日期:2014-08-13 基金项目:中国科学院数字地球重点实验室开放基金资助项目(No.2012LDE016);武汉大学测绘遥感信息工程国家重点实验室开放基金(No.12R03);高等学校博士学科点专项科研基金资助项目(20130181120005);四川省科技支撑计划资助项目(No.2014GZ0005);博士后基金资助项目(No.2014M552357);南京邮电大学江苏省图像处理与图像通信重点实验室开放基金资助项目(No.LBEK2013001). *通信作者:严斌宇 email:yby@https://www.doczj.com/doc/3516109332.html,
品牌识别金字塔模型 品牌沟通和表现注定是要发展变化的。定位是将品牌的某一方面与顾客的期望、需要和要求联系起来的过程。当这些需求随时间而变化时,品牌也被迫跟随改变。因此,可口可乐开始以"渴"为诉求点,后来说"这就是真正的可乐",最后说"感觉",可口可乐本身的商业化诉求已经改变了。可口可乐的风格是很明确的,也容易识别,相当容易被其他品牌模仿。长期以来,除了产品的物理性质以外,可口可乐已成为一个理想模型,这是有目共睹的。自从一个世纪前它诞生之日起,它的价值系统就基本没有变化。其精神的源泉或者说延续下去的识别好像从来就没有被偏离过。 把品牌看作一个三维金字塔来进行管理,因此有必要,时间也可作为其中一维,如图所示。`` 品牌核心价 值 品牌 生命之源 ( 拟人化 ) 状态内涵风格 产品支撑点细分市场 技术及产品的更新适应市场的变化消费者生活形态的变化 环境变 迁 在金字塔的顶端是品牌的核心价值,其源泉来自品牌的激活,即品牌是一个活生生的人,会说话会行动,并形成品牌的遗传代码DNA。我们必须知晓品牌的核心点,但同时要使它不同于别人的所见、所说。它是品牌的深层次识别,是品牌的核心价值,它可以在很长的一段时间内保持不变。例如:波驰赛车的核心识别并非"跑得快的车"(虽然这的确是波驰宣传的主题,也是它作为产品的一个特性),形象地说,波
驰的核心标志是"英雄"。不是指现代意义上的英雄,而是体现着"英雄"的原始含义。同危险的驾驶联系在一起并不会损害品牌的形象,因为险恶的处境正是英雄所面临的命运。然而,应意识到如果公开宣称波驰赛车是为英雄们制造的,将会带来多么不利的影响。潜在的含义必须陷于表象之后才有积极的效用。品牌的核心点应隐藏在产品诉求之下。 在金字塔的中层,是品牌的风格、内涵及状态。从语学的角度来说,是通过尖尖的铁笔记录和留下它的记号和图印。如同一个人的签名,风格--品牌通过文字或图像传递的有特定意义的信息--是品牌核心识别的反映。因此,风格不能随意变动,但需要始终保持同品牌核心识别的联系。 健力士(Guinness)所有的广告都要经过检验,其高层管理层总会反过来提出这样一个问题:"这是Guinness吗?这种"感觉正确因素"用来衡量品牌的核心内容与其表现的形式是否相适应。风格会随着时代的改变而做适应性的小变动。然而,真实的发问是,品牌的标志正是在一系列的变动中显得鲜明起来。举例来说,按现代时尚,女性时装要么轻淡柔和,要么色泽艳丽,或长或短,或宽松或紧身。如果希望通过一种固定的服装模式来判断一位女士和特征,即等于要求她长期不变地穿一件浅色的长衫,即使其他的女性此时正穿着鲜艳的短装。事实上,女士们常常在追随时尚的潮流,用独特的、个性化的方式来反映他们的特点。她们年复一年,从一种时尚到另一种时尚的选择过程,表明在她们身上存在着一种标准,一些特定的观念。这些正是核心识别的体现。为了保持摩登(不落后于时代),品牌必须跟上时尚,但按它们自己的方式行事。 金字塔的下层是传播的主题,即品牌目前的广告话题。消费者是从金字塔的底部来了解品牌的。他们通过产品、传播主题、定位以及沟通风格等来了解品牌。对于品牌管理而言,如果希望塑造一个长期存在品牌,则必须清楚地理解品牌的核心点和源点。它从上至下地运作,风格及风格的变化不能违背品牌的核心识别。传播的主题和承诺必须落在品牌适应的范围内。 对于国际品牌管理,这种三层金字塔模型也极为重要。通常,在不同国家,同一品牌会处于不同的发展阶段,因此,它的广告主题和产品在全球范围内是不尽相同的。只要品牌的核心价值和风格在各国都保持一致,这绝不是问题,只有经过相当长的一段时间后,产品线广告才会趋向统一。 在识别的六个方面(识别棱柱)和金字塔模型之间有一种特定的关系(见图)。一项对广告主题的测试显示它们同产品的特征(物理特征)、消费者瓜或与消费者关系(特别是一些服务性品牌或儿童产品品牌)有关。它们是识别的外在方面,因此是外向交流的,它们属于物质性的东西,可以看得到。风格,如同一个人的字迹,反映了品牌的内在方面,即它的个性和消费者的自我形象。最后,基因代码作为品牌的
客户价值金字塔与客户细分 “二八法则”与客户价值金字塔 今天,多数的企业都了解客户价值分布是适合“二八法则”的,即20%的客户创造了80%的利润。但对每个企业而言,要洞察“究竟哪些客户才是最有价值的客户?”“这些客户在哪些方面的价值最大?”“他们有什么共同的特征?”却不是一件很容易的事。目前,多数企业的管理方式还停留在根据某一项或两项单一指标(如销售额或利润)来做的客户排行,无法进行多方位的综合的客户价值分析、管理。而要实现“以客户为中心”的CRM 理念,就必须建立一套全面的客户价值评估管理系统,并利用系统强大的数据分析、挖掘功能,快速地进行客户群价值细分管理,建立起客户价值金字塔。 客户价值金字塔可以说是CRM皇冠上的明珠,是CRM最核心功能。它通过设定全方位、多角度的客户价值指标,对企业现有的和潜在的客户进行可量化的价值评估,并将评估结果展现为可视化的“金字塔”型分层客户价值图。这种以客户价值为基础进行客户细分的方式,可最大限度地体现出CRM的核心理念,将客户,而非产品放在企业运营和决策分析的中心位置。利用这种直观的客户价值展现,企业管理者可以有效地将精力集中在最有价值或最有发展潜力的客户上,及时发现价值下降的客户,有效地提升企业的竞争力。用友TurboCRM 的客户价值金字塔功能正是按照这种思想,将领先的数据分析挖掘技术与CRM 的先进管理理念完美地结合起来,形成客户价值的可视化展现。 客户价值金字塔实现“一对一”的客户分析 客户价值金字塔的应用是根据价值指标和指标权重为每个客户计算出综合价值状况,然后按照价值等级将客户划分为价值金字塔的不同区段,并进行可视化展现,从而形成量化的客户价值体系。企业可以选择不同的价值指标定义多个价值金字塔模型,例如利润价值金字塔、模板价值金字塔、潜在价值金字塔等,从不同的视角评估自己的客户群和每一个客户,明晰客户的价值取向、价值分布及不同价值区间的客户构成特征等。 这种分析突破了在传统企业管理中的粗放的感性的“重点及非重点客户”的简单二分法则,而是可以根据指标的设定和量化的运算,将客户价值层级进行无穷细分,最后达到真正的“一对一”分析。企业管理者可以轻松了解每个客户的价值变动曲线,了解价值客户的实际生命周期,并可以根据分析的结果,进行有针对性的客户管理,包括: □对归属于不同价值层级的客户群体进行特征归集; □对低价值客户群体进行专门的批量接触,测试出可以提升客户价值的有效方式;
金字塔原理读后感 六月份我们将全员阅读《金字塔原理》这本书籍,作者是芭芭拉·明托。该书主要讲解写作逻辑与思维逻辑,全书分为四个部分。第一篇介绍如何利用金字塔原理构建结构。第二篇介绍如何 深入把握思维环节,使用的语句能够真实反映表达的思想要点。 第三篇主要介绍了如 六月份我们将全员阅读《金字塔原理》这本书籍,作者是芭芭拉?明托。该书主要讲解写作逻辑与思维逻辑,全书分为四个部分。第一篇介绍如何利用金字塔原理构建结构。第二篇介绍如何深入 把握思维环节,使用的语句能够真实反映表达的思想要点。第三 篇主要介绍了如何在解决问题过程中的不同阶段使用多种框架来 组织分析过程。第四篇介绍了一些演示技巧,以幻灯片等书面形 式演示具有金字塔结构的思想时,可感受到金字塔结构的存在。 芭芭拉明托的《金字塔原理》通过四大篇幅即表达的逻辑、思考的逻辑、解决问题的逻辑、演示的逻辑阐述了金字塔原理的内容。 Part1 金字塔原理是一种重点突出、逻辑清晰、层次分明、简单易 懂的思考方式、沟通方式。 它的结构为:结论先行,以上统下,归类分组,逻辑递进。 也就是先总结后具体,先框架后细节,先结论后原因,先结果后
过程,先论点后论据。 它的原则为:任何事情都能够归纳出一个中心论点,而此中 心论点可由下一级的多个论据支持,而下一级的论据本身也能够 是个论点,可又被再下一级的多个论据支持,如此延伸,构成了 金字塔形。 Part2 当我们领悟到本书核心内容后,最重要的是如何在实际工作 中能够运用和实践,比如: 1.当员工向部门负责人做工作总结或成果汇报,或开项目进 展会议的时候,先点明工作成果或阶段目标效果,此为金字塔第 一级的核心论点,读后感.再往下阐述第二级的多个论据,如果我 们的汇报时间或会议时间有限时,领导此时已经知晓结果和主要 论据事项,可不必往下延伸;当我们汇报或会议时间比较充足时,可再进行第三级阐述、解释及支持第二级的内容,由此延伸,这 样可以有效的提高我们的沟通效率。 Part3 《金字塔原理》这本书教的是技巧,而要想让自己通过这本书有所收获,关键还是要经常使用这些技巧,才能真正的转化成自 己的东西,运用自如,让自己的工作技能更胜一筹。
LDA(主题模型)算法 &&概念: 首先引入主题模型(Topic Model)。何谓“主题”呢?望文生义就知道是什么意思了,就是诸如一篇文章、一段话、一个句子所表达的中心思想。不过从统计模型的角度来说,我们是用一个特定的词频分布来刻画主题的,并认为一篇文章、一段话、一个句子是从一个概率模型中生成的。 LDA可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为易于建模的数字信息。 LDA(Latent Dirichlet Allocation)是一种文档主题生成模型,也称为一个三层贝叶斯概率模型,包含词、主题和文档三层结构。所谓生 注:每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。 备注: 流程(概率分布):→→ 许多(单)词某些主题一篇文档 /**解释:LDA生成过程 *对于语料库中的每篇文档,LDA定义了如下生成过程(generativeprocess): *1.对每一篇文档,从主题分布中抽取一个主题; *2.从上述被抽到的主题所对应的单词分布中抽取一个单词; *3.重复上述过程直至遍历文档中的每一个单词。 **/ 把各个主题z在文档d中出现的概率分布称之为主题分布,且是一个多项分布。把各个词语w在主题z下出现的概率分布称之为词分布,这个词分布也是一个多项分布。
&&深入学习: 理解LDA,可以分为下述5个步骤: 1.一个函数:gamma函数 2.四个分布:二项分布、多项分布、beta分布、Dirichlet分布 3.一个概念和一个理念:共轭先验和贝叶斯框架 4.两个模型:pLSA、LDA(在本文第4 部分阐述) 5.一个采样:Gibbs采样 本文便按照上述5个步骤来阐述,希望读者看完本文后,能对LDA有个尽量清晰完整的了解。同时,本文基于邹博讲LDA的PPT、rickjin的LDA数学八卦及其它参考资料写就,可以定义为一篇学习笔记或课程笔记,当然,后续不断加入了很多自己的理解。若有任何问题,欢迎随时于本文评论下指出,thanks。 1 gamma函数 整体把握LDA 关于LDA有两种含义,一种是线性判别分析(Linear Discriminant Analysis),一种是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),本文讲后者(前者会在后面的博客中阐述)。 另外,我先简单说下LDA的整体思想,不然我怕你看了半天,铺了太长的前奏,却依然因没见到LDA的影子而显得“心浮气躁”,导致不想再继续看下去。所以,先给你吃一颗定心丸,明白整体框架后,咱们再一步步抽丝剥茧,展开来论述。 按照wiki上的介绍,LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,是一种主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。 LDA的这三位作者在原始论文中给了一个简单的例子。比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习的方式,获取每个主题Topic对应的词语。如下图所示:
图像分类学习笔记:词袋模型和空间金字塔匹配 Image Classification Framework: Bag-of-Words &Spatial Pyramid Matching 一、基础:词袋模型(Bag of Words ) Bag-of-Words (词袋、词包)模型,或称Bag of Features 模型,源于文本分类技术。在信息检索中,假定对于一个文本,忽略其词序和语法、句法。将其仅仅看作是一个词的集合,每个词都是彼此概率独立的。这样可以通过文档中单词出现的频率来对文档进行描述与表达。Csurka 等[1]于2004年将其引入计算机视觉领域。 其核心思想在于,图像可以视为一种文档对象,图像中不同的局部区域或其特征可看作构成图像的词汇,其中相近的区域或其特征可以视作为一个词。这样,可以把每幅图像描述为一个局部区域/关键点(Patches/Key Points)特征的无序集合。理论对应关系如下:文档单词字典图像特征聚类中心特征聚类集合 用词袋模型生成对一张图像的描述向量的处理步骤: 1、局部特征提取 通过兴趣点检测、密集采样或随机采集,结合图割区域、 显著区域等方式获得图像各处的局部特征。常用的是 SIFT 特征和Dense SIFT 特征。 2、构建视觉词典 在整个训练集上提取局部特征后,使用某种聚类算法(如K-means)将局部特征进行聚类,每个聚类中心可以看作是词典中的一个视觉词汇(Visual Word),相当于文本检索中的词,视觉词汇由聚类中心对应特征形成的码字(code word)来表示(可看作一种特征量化过程)。所有视觉词汇形成一个视觉词典(Visual Vocabulary),词典中所含词的个数反映了词典的大小。
《金字塔原理》读书笔记及心得感悟1500 字 导读:读书笔记《金字塔原理》读书笔记及心得感悟1500字,仅供参考,如果觉得很不错,欢迎点评和分享。 《金字塔原理》读书笔记及心得感悟1500字: 《金字塔原理》这本书毕竟是写给咨询行业人员的,因此里边的案例也都以咨询业为背景。从这本书的标题可以看出作者意在通过金字塔原则,让思考、写作和解决问题更加条理清晰简洁、深入以及有针对性。 当我们面对诸多的信息时,条理清晰地表达以及写作的关键在于从这些信息中发现他们的逻辑关系,提炼出更高一层的信息,以此类推从而实现信息的整合。 这些逻辑顺序基本上有演绎顺序,时间顺序和找出与之类似的思想(归纳法)。” 对于行动性的思想,概括时应用明确具体的语言说明实施行动后的结果,根据完成这些行动将导致的明确结果修改各个行动不走的语言,使之更加明确。而对于描述性的思想,概括时应说明这些思想具有的共同点的含义。 另外一个问题在于我们常常在发现问题之前会进行大量的信息收集,而这些收集而来的信息最后与问题有直接相关的可能少于
50%。 在这里我并不是要反对对问题进行详细地了解,而是在时间紧迫的背景下需要克制对信息收集的偏好以及直面逃避思考的问题。 作者认为在信息收集之前进行结构化分析是十分必要的,虽然这与上文对问题意识的强调有相通之处,然而单独拿出来强调仍然是有必要的。 这本书的要求说起来也就是要把观点明确清晰地表达出来。观点来自于对问题的提出或者解决,因此要对情境和冲突有清晰明确的了解。 做到清晰明确的表达就发掘信息中的逻辑,具体地概括出其中的思想观点,从而做进一步的思考和表达。 这也就是目前我所理解的金字塔原则。 这本书对我之前写论文和表达时遇到的困难提供了相对较为直接以及具体的解答,即使里边的许多观点对我们都并不陌生,因此还是一本值得看的书。 Tips: 1.对于繁杂的信息点可以通过砍去修饰成分,只留下最本质的核心内容,然后找出其中的重复部分的方式来整理。 2.结构化分析的方法只有三种:划分结构、寻找因果关系和分类。这可能适用于公司等现实场景,对哲学写作用处并不大。 3.文中一个重要的分类原则是相互独立和穷尽(书里称作MECE)。作者:有师
金字塔原理:思考、表达和解决问题的逻辑 学习导航 通过学习本课程,你将能够: ●掌握金字塔结构的定义及作用; ●了解金字塔结构的原则; ●理解金字塔结构的重要意义; ●学会运用金字塔原理进行思考并解决问题。 金字塔原理:思考、表达和解决问题的逻辑 一、什么是金字塔结构 1.金字塔结构的定义 金字塔结构就是结论先行,以上统下,归类分组,逻辑递进,先重要后次要,先全局后细节,先总结性观点后具体数据,先论点后论据,先结论后原因,先结果后过程。这十句是金字塔结构重点突出、投其所好、逻辑清晰的基本原则。 2.金字塔结构的作用 一般来说,金字塔结构的作用主要包括: 帮助投其所好 人们都期望投其所好、取悦他人,要想达成这一目标,必须学会察言观色、揣摩人心。因此,要以受众为中心,把握受众的需求点、利益点、兴趣点和关注点。只有受众愿意听、愿意看,才能听得进去、看得进去,受众有绝对的决策权。要想让听众听、读者看,唯一的办法就是让受众愿意听、愿意看。听众是主角,说者是配角;读者是决策者,作者是服务者。 不同的工具适用不同的场合,没有万能的工具,但唯一不变的理念是,无论推广何种产品都必须以客户为中心。只有迎合受众才能打动受众,只有迎合领导才能打动客户。 达到沟通目的 学习金字塔原理,还能达到沟通的目的,使人们的观点鲜明、重点突出、逻辑清晰、层次分明。很多沟通都是为了达到沟通的第四个目的——让别人执行和操作自己的指令,要达到沟通的第四个目的,必须以沟通的前三个目的为基础,即:第一,对方愿意听、有兴趣;第二,对方能理解并接受说者的观点;第三,对方记得住说者的指令。 要点提示 沟通的四个目的:
①使受众愿意听、有兴趣; ②使受众能理解并接受说者的观点; ③使受众记得住说者的指令; ④让受众执行和操作自己的指令。 掌握结构化系统思维 学习金字塔原理,还能提高逻辑思维能力,提升沟通的效果和效率。掌握结构化系统思维,不仅对目前有好处,对未来的职业晋升也有好处,因为凡是得到提拔的人一定是条理、逻辑清晰的人,尤其是在政府、国有企业等大型企业中。 3.金字塔结构的三项实用技能 金字塔结构的三项实用技能包括: 先做人后做事 感性做人,理性做事;感性切入,理性回归;清晰思考,有效表达;攻心为上,攻城为下。只要是表达,受众都会有几个疑问:第一,想说什么,即观点、主张、信息;第二,想怎么说,即逻辑思路和结构;如果是向领导汇报,领导还有第三个疑问,即你的目的;如果是向客户讲话,客户会有第四个疑问,即好处是什么。因此,每次表达前都要想好观点主张、逻辑思路结构、目的以及好处四个问题的答案。 要话先说 时间管理的重要原则是要事先做,讲话也是同样的道理,重要的话要先说。 提供解决方案 大多数领导最喜欢做选择题和判断题,最讨厌的是问答题,也就是要让员工为老板打工,而不要老板为员工打工。员工可以向领导汇报面临的问题、挑战和困惑,其前提是必须提供三个解决方案,并按照自己的判断排出优先顺序。 4.金字塔的基本结构 金字塔思维保证条理清晰、层次分明,要先说中心思想,再说二级思想、三级思想、四级思想,逐层向下展开,最重要的内容先说。 任何一篇文章或者一次讲话,都是单一思想统领的金字塔结构,中心思想应当说听众想听的话,而不是讲话者想说什么听众就要听什么。 5.以受众为中心 一般来说,听众可以分为领导和专家两类。 领导 研究领导时,要研究超过50%的领导怎么想,研究大概率事件,研究群体、共性。通常领导都愿意这样听:先重要后其次,先全局后细节,先总结后具体,先论点后论据,先结论后原因,先结果后过程。 专家 对于专家而言,其听的顺序除了第一条外,其他五方面都与领导完全相反。专家最讨厌听结论,并会质疑对方结论的科学性和有效性。专家包括研究人员、科学家、医生、律师、技术人员和专家型领导。 无法判断听众时的切入点 人们要对两类人分别说不同的话,当无法判断听众类型时,有三种切入点可供选择:第一,我的主观结论; 第二,罗列详实的数据; 第三,精炼筛选支撑自己主张的主要数据。
《金字塔原理》读书心得 1.引言 在现实工作和生活中,人们都希望能够进行良好的沟通,以提供工作效率,维持良好的人际关系。但在现实状况中,经常存在说者答非所问,听着不知所云,以及升级之后的咆哮式沟通。这些情况的普遍存在说明沟通中存在着未被许多人掌握的规律。本文将揭示其中一项重要规律。 良好的沟通需要高效准确的表达,良好够沟通渠道,和高效准确的理解。在不考虑沟通渠道这种外在的客观条件的情况下,高效准确的理解是由信息接收者本身的知识背景、思维能力和信息发送者对信息描述的方式这两个因素决定的。因此,合理的描述信息是产生良好沟通效果的一个及其重要的因素。 衡量信息描述的质量,一个最重要的因素是信息的组织结构方式。如果信息的组织结构方式与信息接收者理解信息的思维方式相一致,则信息容易被理解。根据金字塔原理,人们是按照金字塔方式理解并储存信息的,因此,当信息发送者按照金字塔结构组织组织信息,其表达方式就可以和接收者的思维合拍,从而可以进行顺利的沟通。 本文首先叙述什么是金字塔原理,然后针对四种具体的沟通方式,对金字塔原理的应用进行介绍。 2.什么是金字塔原理 金字塔原理揭示了人们理解事物时,最容易的理解顺序是先了解主要的、抽象的思想,然后再了解次要的、为主要思想提供支持的思想,这种思想的组织结构称为金字塔结构。金字塔结构中包含了非常少的几种逻辑关系:纵向联系和横向联系。在进行沟通时,按照金字塔结构组织的信息能够使信息接收者更容易理解。 在金子塔原理有三条规则: 1. 纵向联系指信息结构中任一层次上的思想都必须是下一层思想的概括; 2. 横向联系是指同一层次上,每一组思想都属于同一范畴; 3. 每一组思想之间必须按照一定的逻辑顺序组织。这种横向的逻辑顺序包括:演绎顺序,时间顺序,结构顺序和重要性顺序。 想要进行良好的表达,关键是在开始表达只前将表达者的思想组织成金字塔结构,并按照逻辑关系的有关规则进行检查和修改。下面将从写作,思考,解决问题,演示几个方面分别介绍如何在实际的沟通中使用金字塔原理进行有效的表达。 3.写作的逻辑 写作时,文章条理不清是一个普遍的问题,它可能会导致作者在表达思想时采用的顺序与读者的理解力发生矛盾。对读者来说,最容易的理解顺序是先了解主要的、抽象的思想,然后再了解次要的、为主要思想提供支持的思想。所以,在写作的时候,我们应该以金字塔结构组织文章的结构。 自上而下的构建金字塔结构是一种较容易操作的写作方法。在写作前,首先确定写作的主题,主要的问题,和对问题的回答,然后开始着手写作。写作可分为序言和正文部分。 文章的开始,首先要通过序言引发读者的关注。序言开始按照讲故事的模式说明读者熟
金字塔原理学习笔记 1写作的逻辑 1.1 金字塔结构的定义 有一个总的思想(顶部)统领多个思想(底部)。每一个层次上的思想都是对下一层次思想的总结(纵向关系),多个思想应共同组成一个逻辑推断式而并列在一起(横向关系)。 读者看到主要思想是会产生疑问,下一层次的思想对此问题作出回答。通过不断的提问和回答读者可以了解文章中的所有思想。 每一层的分支不要超过7,否则读者记不住。 1.2 金字塔结构的规则 文章结构中任一层次上的思想都必须是其下一层次思想的概括。 每一组思想都必须属于同一范畴。 每一组中的思想都必须按照逻辑顺序组织。逻辑顺序基本上只有四种: 演绎顺序(大前提、小前提、结论) 时间顺序(第一、第二、第三)(归纳) 结构顺序(整体的不同组成部分)(归纳) 重要性顺序(最重要、次重要,等等)(归纳) 下一层的思想一定要能够导出上一层的思想,推导的方式只有两种――演绎和归纳 1.3 为什么要用金字塔结构 金字塔结构是容易被理解的结构,他和人的大脑组织信息的方式相同。 1.4 如何写序言 只有在序言中提出读者头脑中已经有的问题,或者读者读者对周围发生的事情做短暂的思考后可能会提出的问题,才能够引起读者的注意。问题的起源和发展必然以讲故事的形式出现,因此采用讲故事的形式。 讲清四点: 情境(Situation),故事的时间、地点等 冲突(Complication) 疑问(Question) 回答(Answer) 1.5 自上而下组织思想的步骤 列出准备讨论的主题 列出你准备回答的读者头脑中的问题 列出你的答案
列出“情境” 列出“冲突” 列出支持你答案的理由,并且在新的层次上进行“疑问/回答” 2思考的逻辑 2.1 确定逻辑的顺序 逻辑的顺序有三种:时间顺序(因果关系)、结构顺序(整体-部分关系)、重要性顺序(类似事物归一) 2.1.1时间顺序 前一个行动的输出(结果)是后一个行动的输入(原因)。 2.1.2结构顺序 结构顺序就是当你使用示意图、地图、图画或照片想象某事物时的顺序。 需要遵循MECE原则 对结构提出修改意见时可以按照新结构的位置顺序描述。 2.1.3重要性顺序 重要性的排序取决于你的问题,对问题最重要的答案排在前面。 面对一堆杂乱的思想,整理的步骤如下: 1.确定每一个思想的类型(可能需要有若干次反复) 2.将同一类型的思想归类 3.找出各类别思想之间的顺序 2.2 排序的步骤 遇到一组归纳性思想时: 1.快速浏览,看看有没有某种逻辑顺序(时间顺序,结构顺序,重要性顺序) 2.如果没有,能否发现分组的基础(过程、结构、类别) 3.如果没有,能否发现其中的共同点,根据这些共同点讲思想归纳为一些类别,让后再对 其采用逻辑顺序。
Pattern Recognition Term Project Report Using Visual Words for Image Classification u9562171, 雷禹恆 1.Abstract Visual words 近年來在image retrieval領域被大量使用。它是基於文字上的textual words,套用在影像上的類比,因此可將過去在text retrieval領域的技巧直接利用於image retrieval,也有助於large-scale影像搜尋系統的效率。Visual words的擷取大致上是將影像的SIFT features,在keypoint feature space上做K-means clustering的結果,以histogram來表示,是一種bag-of-features。除了可用於retrieval外,visual words也被用於image classification。本專題的目的就是將visual words作為影像特徵,並套用於multi-class image classification。 2.Introduction Visual words (簡稱VWs) 近年來在image retrieval領域被大量使用,其motivation其實是從text retrieval領域而來,是基於文字上的textual words,套用在影像上的類比。 如同於一篇文章是由許多文字 (textual words) 組合而成,若我們也能將一張影像表示成由許多 “visual words” 組合而成,就能將過去在text retrieval領域的技巧直接利用於image retrieval;而以文字搜尋系統現今的效率,將影像的表示法「文字化」也有助於large-scale影像搜尋系統的效率。 在文獻 [1] 有提到motivation of visual words的細節。首先我們先回顧text retrieval 的過程:1. 一篇文章被parse成許多文字,2. 每個文字是由它的「主幹(stem)」來表示的。例如以 ‘walk’ 這個字來說,‘walk’、‘walking’、‘walks’ 等variants同屬於 ‘walk’ 這個主幹,在text retrieval system裡被視為同一個字。3. 排除掉每篇文章都有的極端常見字,例如 ‘the’ 和 ‘an’。4. 一篇文章文章的表示法,即以每個字出現頻率的histogram vector來表示。5. 在此histogram中,對於每個字其實都有給一個某種形式weight,例如Google利用PageRank [2] 的方式來做weighting。6. 在執行文字搜尋時,回傳和此query vector最接近(以角度衡量)的文章。 下一節將解釋影像中VW的特徵擷取流程,及其與此段之1.、2.、4.的類比。 3.Construction of Visual words Visual words的建構流程可以用圖(1)來說明:
金字塔模型与沙漏模型 ADAE DEAF ①AB=AC=BC=AG 2 2 ②S△ADE:S△ABC=AF:AG 所谓的相似三角形,就是形状相同,大小不同的三角形(只要其形状不改变,不论大小怎样改变他们都相似),与相似三角形相关,常用的性质及定理如下: (1)相似三角形的一切对应线段的长度成比例,并且这个比例等于它们的相似 比; (2)相似三角形面积的比等于它们相似比的平方; (3)连接三角形两边中点的线段我们叫做三角形的中位线; 三角形中位线定理:三角形的中位线长等于他所对应的底边长的一半。 相似三角形 对应角相等、对应边成比例的两个三角形叫做相似三角形。如果三边分别对应A,B,C 和a,b,c:那么:A/a=B/b=C/c,即三边边长对应比例相同。 判定方法 定义 对应角相等,对应边成比例的两个三角形叫做相似三角形。 预备定理 平行于三角形一边的直线截其它两边所在的直线,截得的三角形与原三角形相似。(这 是相似三角形判定的定理,是以下判定方法证明的基础。这个引理的证明方法需要平行线与 线段成比例的证明) 1判定定理 常用的判定定理有以下6条: 判定定理1:如果一个三角形的两个角与另一个三角形的两个角对应相等,那么这两个 三角形相似。(简叙为:两角对应相等,两个三角形相似。)(AA) 判定定理2:如果两个三角形的两组对应边成比例,并且对应的夹角相等,那么这两 个三角形相似。(简叙为:两边对应成比例且夹角相等,两个三角形相似。)(SAS)判定定理3:如果两个三角形的三组对应边成比例,那么这两个三角形相似。(简叙为:三边对应成比例,两个三角形相似。)(SSS)
判定定理4:两个三角形三边对应平行,则个两三角形相似。(简叙为:三边对应平行, 两个三角形相似。) 判定定理5:如果一个直角三角形的斜边和一条直角边与另一个直角三角形的斜边和一条 直角边对应成比例,那么这两个直角三角形相似。(简叙为:斜边与直角边对应成比例,两个 直角三角形相似。)(HL) 判定定理6:如果两个三角形全等,那么这两个三角形相似(相似比为1:1)(简叙为:全等三角形相似)。 相似的判定定理与全等三角形基本相等,因为全等三角形是特殊的相似三角形。 一定相似 符合下面的情况中的任何一种的两个(或多个)三角形一定相似: 1.两个全等的三角形 全等三角形是特殊的相似三角形,相似比为1:1。 补充:如果△ABC∽△A‘B’C‘,∴AB/A’B‘=AC/A’C‘=BC/B'C’ =K 当K=1时,这两个三角形全等。(K为它们的比值)2.任意 一个顶角或底角相等的两个等腰三角形 两个等腰三角形,如果其中的任意一个顶角或底角相等,那么这两个等腰三 角形相似。 3.两个等边三角形 两个等边三角形,三个内角都是60度,且边边相等,所以相似。 4.直角三角形被斜边上的高分成的两个直角三角形和原三角形 由于斜边的高形成两个直角,再加上一个公共的角,所以相似。 2性质定理 (1)相似三角形的对应角相等。 (2)相似三角形的对应边成比例。 (3)相似三角形的对应高线的比,对应中线的比和对应角平分线的比都等于相似比。 (4)相似三角形的周长比等于相似比。 (5)相似三角形的面积比等于相似比的平方。[1] 由(5)可得:相似比等于面积比的算术平方根。 3定理推论 推论一:顶角或底角相等的两个等腰三角形相似。 推论二:腰和底对应成比例的两个等腰三角形相似。 推论三:有一个锐角相等的两个直角三角形相似。 推论四:直角三角形被斜边上的高分成的两个直角三角形和原三角形都相似。 推论五:如果一个三角形的两边和三角形任意一边上的中线与另一个三角形的对应部 分成比例,那么这两个三角形相似。 性质
客户营销的先行之路:客户金字塔 叶开 2003/05/08 客户关系管理 客户关系管理,简称CRM,从彼得.德鲁克开始成为世界经济管理的一个热点。在国外,客户关系管理被定义为: 每个公司的业务是争取客户、留住客户、使客户赢利率最大化。 在国内,客户关系管理的推动来源于软件厂商,它们将CRM挂在嘴边,过分的强调CRM系统的功能,而忽略了国内大部分企业薄弱的管理基础和CRM的管理思想,幻想着有朝一日中华大地上到处都在CRM着。而随之而来的不良反应和媒体的过分炒作,造成CRM人人害怕,人人怀疑,成为企业信息化的一个黑洞。 现在所谓的CRM,并不是客户关系管理的所有,它仅仅体现了作为管理信息系统的一部分,而另外一方面重要的思想和意识并没有体现。所以,我还是喜欢将我从事的称之为"客户关系管理",以和被企业用户引以为戒的CRM区别开来。 客户关系管理并不是一套软件,也不是在企业内部装一套CRM软件就可以实现,而应该以客户为导向,由"衡量客户从你的企业获得的价值"开始,建立起以客户为中心的企业经营战略和流程。思想和意识最重要,做客户关系管理不一定要上CRM系统,如果以客户为中心的企业文化已经深入到企业的方方面面,那么仅仅使用电子表格也足够实现客户关系管理。CRM系统只是一种管理工具,如果上了CRM系统则会做得更好,更加自动化。 客户营销的基础:客户 "谁是您的客户?" 在以产品为中心的企业经营中经常会犯这样一个错误,他们假设认为自己很了解客户,知道客户需要什么。这是很危险的,可能会导致一种主观的程式化的观点,使他们无法向客户提供恰当的解决方案。 在过去的CRM咨询项目中,我们经常企业用户进行客户金字塔测试,测试中企业各层次的人员对于客户的认识是模糊的、不统一的,对于最有价值的客户更是意见各异,而对于这些最有价值的客户的需求取向是什么更是空白。这说明大部分企业对于自己的客户金字塔都还是很模糊的,没有进行客户细分,而是作为一个"大客户群"的概念在笼统的进行统一的跟踪、统一的关怀和统一的服务。
《金字塔原理》笔记 《金字塔原理》是一本xx年由民主与建设出版社出版的图书,作者是巴巴拉·明托,王德忠、张珣译。下面是收集好的《金字塔原理》笔记,我们一起来看看吧! 书名:金字塔原理:思考、表达和解决问题的逻辑 作者:芭芭拉·明托译者:汪洱 出版社:南海出版社出版时间:xx年8月1日 本期读书会向大家推荐的是《金字塔原理》这本经典书,是麦肯锡40年经典的培训教材,金字塔原理提升思考表达和解决问题的逻辑能力。 本书作者是美国的芭芭拉名托,翻译是汪洱老师和高愉老师。 关于作者,毕业于哈佛大学、麦肯锡公司第一位女咨询顾问,传授金字塔原理40年,帮助政府、企业、高校等各界人士撰写商务文章,复杂报告和演示文稿。曾为美国、欧洲和亚洲众多企业及哈佛大学斯、坦福大学等讲授金字塔原理。金字塔原理畅销40余年不衰,广受欢迎,被译成多种文字,数次再版,常年名列各国畅销书排行榜前茅。 在国内,各大企业也是全面学习,为什么会出现这样的现象,主要原因之一是我们的教育对于思维训练出现了遗漏,在学校期间没有训练大家的逻辑思维。 金字塔原理:是一种重点突出、逻辑清晰、主次分明的逻辑思路,表达方式和规范动作。
金字塔原理的基本结构:中心思想明确,结论先行,以上统下,规律分组,逻辑递进,先重要后次要,先全局后细节、先结论后原因,先结果后过程。 那金字塔原理,究竟能帮助你解决哪些问题: 在思考层面:用全脑思维,提高结构化思维能力,思考全,准,快。 在书面表达和公文写作这方面:可以挖掘读者的关注点,兴趣点,需求点,利益点,用金字塔搭建逻辑清晰的框架结构。归类分组重点突出,逻辑清晰,主次分明,让人看得懂,愿意听记得住,缩短写作时间,减少修改次数。 在口头表达方面:说话演讲讲课能够使用金字塔的基本原则,回答听众最常用的4个问题:是什么?为什么?如何做?好不好?表达时重点突出,条理清晰,言简意赅,让听众有兴趣能理解记得住。 在你管理下属:分配任务用金字塔原理,思考周到全面严谨,不重叠无遗漏。 在培训开发课程和讲课的时:能快速搭建框架结构组织素材,逻辑清晰,通俗易懂。 金字塔原理,大家不要把它想得太复杂,从金字塔的视觉化就可以看到它是有塔尖和塔基的,要有一个论点,论据要充足,搭建这个框架,像一个金字塔,是正金字塔,只要你认真去思考,认真去学习,大家都能够掌握,难在哪里呢?在实践的过程中去应用,花精力花时间去练习,化为一种思维习惯。
相似三角形模型,就是形状相同,大小不同的三角形.金字塔模型是特殊的相似三角形. 1 . AD AE DE AF AB AC BC AG = == (对应线段之比等于相似比) 2.2 2::ADE ABC S S AF AG =(面积比等于相似比的平方) 3.连接三角形两边中点的线段叫做三角形的中位线.中位线长等于它所对应的底边的一半. 重难点:寻找平行线,进而找到金字塔模型,利用金字塔模型解决线段比例关系或图形的 几何第26讲_金字塔模型 F E D G C B A 金字塔模型
面积比例关系. 题模一:基础金字塔模型 例1.1.1如图所示,BC 与DE 平行.已知4AD =,5BD =,16DE =,则BC =__________. 例1.1.2如图所示,DE 与BC 平行,已知4AD =,5BD =,△ADE 的面积为32,则四边形DECB 面积为_________. 例1.1.3如图,DE 平行BC ,若:2:3AD DB =,那么:ADE ECB S S =△△________. 例 1.1.4如图, ABC △中,DE ,FG ,MN ,PQ ,BC 互相平行, AD DF FM MP PB ====,则 ::::ADE DEGF FGNM MNQP PQCB S S S S S = △四边形四边形四边形四边形___________. 题模二:金字塔综合应用 例1.2.1如图,已知三角形ADE 的面积为1平方厘米,D 、E 分别是AB 、AC 边的靠近A 点的三等分点.那么三角形OBC 的面积是_______平方厘米. A E D C B Q E G N M F P A D C B