分布式系统原理-时间和全局状态
- 格式:ppt
- 大小:390.50 KB
- 文档页数:62

seata原理Seata原理。
Seata是一款开源的分布式事务解决方案,它致力于提供高性能和简单易用的分布式事务服务。
Seata的设计理念是将分布式事务的处理过程进行抽象和封装,使得开发者可以更加方便地在分布式环境下进行事务管理。
Seata的原理主要包括三个核心模块,事务协调器(Transaction Coordinator)、事务管理器(Transaction Manager)和分支事务(Branch Transaction)。
下面我们将逐一介绍这三个模块的工作原理。
事务协调器是Seata的核心组件之一,它负责协调全局事务的提交和回滚。
当一个全局事务发起时,事务协调器会生成一个全局事务ID,并将这个ID传播到所有的参与者(包括事务管理器和分支事务)。
在全局事务执行过程中,事务协调器会不断地与各个参与者通信,确保全局事务的一致性和隔离性。
当全局事务需要提交或回滚时,事务协调器会根据参与者的反馈来决定最终的结果。
事务管理器是Seata的另一个核心组件,它负责管理全局事务的生命周期。
事务管理器包括全局事务的发起、提交和回滚等操作。
在全局事务发起时,事务管理器会向事务协调器注册全局事务,并在全局事务执行过程中负责监控各个分支事务的状态。
当全局事务需要提交或回滚时,事务管理器会通知事务协调器进行相应的操作。
分支事务是Seata中的一个重要概念,它代表了一个参与者对全局事务的一个分支操作。
在全局事务执行过程中,分支事务会不断地向事务协调器汇报自己的执行状态,并根据事务协调器的指令来进行提交或回滚操作。
分支事务的状态变化将直接影响全局事务的最终结果。
总的来说,Seata的原理是基于全局事务的协调和管理,通过事务协调器、事务管理器和分支事务三个核心模块的协同工作,实现了分布式事务的一致性和隔离性。
这种设计思想使得开发者可以更加方便地在分布式环境下进行事务管理,极大地提高了系统的稳定性和可靠性。
在使用Seata时,开发者需要按照Seata的规范来进行代码编写和配置,以确保分布式事务的正确执行。

分布式系统基础考试(答案见尾页)一、选择题1. 分布式系统的定义是什么?A. 由多个计算机组成的系统,这些计算机通过网络进行通信和协调B. 一个提供分布式服务的计算机系统C. 一种软件技术,使得应用程序可以跨多个硬件和操作系统运行D. 一种允许多个用户同时访问和操作的系统2. 分布式系统中的“分布式”一词的含义是什么?A. 多个系统独立运行B. 数据存储在多个位置C. 系统具有高可用性和容错性D. 所有节点都可以独立完成任务3. 分布式系统的核心特性是什么?A. 并发性B. 透明性C. 可伸缩性D. 容错性4. 分布式系统中的节点可以是哪种类型?A. 服务器B. 桌面电脑C. 移动设备D. 所有这些都可能5. 分布式系统中的通信协议有哪些?A. HTTPB. TCP/IPC. UDPD. 所有这些都可能6. 分布式系统中的数据一致性是指什么?A. 所有节点上的数据完全相同B. 所有节点上的数据保持同步更新C. 所有节点上的数据在某个时间点相同D. 所有节点上的数据可以不同7. 分布式系统中的负载均衡是什么?A. 将请求平均分配到多个服务器B. 将流量限制到单个服务器C. 将流量分散到多个服务器D. 将流量全部转发到单个服务器8. 分布式系统中的复制是什么?A. 在多个节点上创建数据的副本B. 将数据存储在远程位置C. 将数据加密D. 将数据存储在本地9. 分布式系统中的CAP理论指的是什么?A. 一致性、可用性和分区容错性之间的权衡B. 一致性、可用性和性能之间的权衡C. 一致性、可用性和可伸缩性之间的权衡D. 一致性、可用性和安全性之间的权衡10. 分布式系统中的分布式事务是什么?A. 一种需要在多个节点上同步执行的事务B. 一种可以在多个节点上并行执行的事务C. 一种不能在多个节点上同步执行的事务D. 一种可以在多个节点上同步执行但不需要一致性的事务11. 分布式系统的定义是什么?A. 一组独立的计算机通过网络进行通信和协作B. 一个硬件和软件的组合,能够在多个处理器上运行C. 一个提供分布式服务的互联网D. 一个由多个服务器组成的系统,每个服务器都有自己的资源12. 分布式系统中的“分布式”一词意味着什么?A. 多个系统组件位于不同的地理位置B. 多个系统组件共同工作以完成一项任务C. 多个系统组件独立地运行并相互通信D. 多个系统组件共享数据和资源13. 分布式系统中的节点可以是哪种类型?A. 主节点B. 从节点C. 客户端D. 所有类型的节点14. 分布式系统中的数据复制是为了什么目的?A. 提高系统性能B. 防止数据丢失C. 提高数据的可用性D. 保证数据的一致性15. 分布式系统中的负载均衡是一种什么技术?A. 将请求分配到多个服务器以优化性能B. 将流量限制到特定的服务器以避免拥塞C. 将客户端的请求直接路由到正确的服务器D. 使用一种算法来决定哪个服务器应该处理哪个请求16. 分布式系统中的共识算法是什么?A. 一种确保所有节点对数据的一致性达成一致的技术B. 一种用于同步不同节点之间的数据状态的技术C. 一种用于检测和处理网络延迟的技术D. 一种用于管理分布式系统中的故障的技术17. 分布式系统中的容错机制是什么?A. 一种确保系统在部分组件失败时仍能正常运行的技术B. 一种用于检测和修复系统错误的技术C. 一种用于保护系统免受恶意攻击的技术D. 一种用于限制系统中的用户数量的技术18. 分布式系统中的数据分片是什么?A. 将数据分割成小块以便于存储在不同的位置B. 将数据分割成小块以便于在不同的硬件设备上存储C. 将数据分割成小块以便于在不同的网络上进行传输D. 将数据分割成小块以便于在不同的时间点进行访问19. 分布式系统中的消息传递机制是什么?A. 一种用于在节点之间传递消息的技术B. 一种用于在节点之间同步数据的技术C. 一种用于在节点之间交换数据的技术D. 一种用于在节点之间协调任务的技术20. 分布式系统中的安全性是指什么?A. 保护系统免受未经授权的访问B. 保护系统免受未经授权的修改C. 保护系统免受未经授权的数据泄露D. 保护系统免受所有上述威胁21. 分布式系统的定义是什么?A. 一组计算机通过互联网进行通信和协调的系统B. 一个硬件和软件集合,能够在有限时间内处理大量数据C. 一个提供分布式服务的互联网系统D. 一种允许多个用户访问和共享资源的网络架构22. 分布式系统中的“分布式”一词意味着什么?A. 多个系统独立运行B. 数据存储在多个位置C. 系统具有高可用性和可扩展性D. 所有节点共同工作以完成特定任务23. 分布式系统的核心特性包括哪些?A. 可靠性B. 可用性C. 并发性D. 容错性24. 在分布式系统中,通常使用哪种通信协议?A. HTTPB. TCP/IPC. UDPD. ICMP25. 分布式系统中的“容错性”是什么意思?A. 系统在部分组件失败时仍能继续运行的能力B. 系统能够自动恢复丢失的数据或进程的能力C. 系统能够自我调整以避免单点故障的能力D. 系统能够确保所有节点之间的同步性26. 分布式数据库的概念是什么?A. 一个包含多个数据副本的数据库,以提高数据可用性和性能B. 一个只有一个数据副本的数据库C. 一个动态调整数据分布的数据库D. 一个支持实时数据更新的数据库27. 分布式系统的设计原则之一是什么?A. 高度集权B. 高度分散C. 高度可伸缩性28. 在分布式系统中,什么是“微服务”?A. 一种特定的编程风格或架构模式,其中应用程序被拆分成一系列小型服务B. 一种分布式系统的实现技术C. 一种单一的、集中的服务D. 一种特定的数据存储技术29. 分布式系统中的“同步”和“异步”有什么区别?A. 同步是指多个进程或线程在同一时间访问同一资源B. 异步是指多个进程或线程在不同的时间访问同一资源C. 同步通常用于需要数据一致性的场景D. 异步通常用于需要提高系统性能的场景30. 分布式系统的发展历程及其在不同领域中的应用有哪些?A. 分布式系统的发展始于20世纪80年代B. 分布式系统广泛应用于大数据处理、云计算、物联网等领域C. 分布式系统的发展受到了计算机网络技术的影响D. 分布式系统是现代计算机系统的基本组成部分31. 分布式系统的定义是什么?A. 一组通过网络进行通信的计算机系统B. 一个硬件和软件的组合,可以在多个位置进行数据处理和存储C. 一种允许多个服务器共享资源和数据的系统D. 一种设计用于处理大量数据并保证数据一致性的系统32. 分布式系统中的“分布式”一词意味着什么?A. 多个系统独立运行B. 资源共享C. 数据备份D. 所有这些都正确33. 分布式系统的核心特性是什么?B. 高可用性C. 任务无关性D. 资源共享34. 分布式系统中的“并发”是指什么?A. 同时执行多个任务B. 同时访问同一资源C. 同时处理多个数据流D. 同时修改数据库35. 以下哪个选项不是分布式系统中的常见同步问题?A. 机器之间的网络延迟B. 任务执行的先后顺序C. 共享资源的访问冲突D. 数据一致性问题36. 分布式系统中的“透明性”是指什么?A. 用户感觉好像所有的系统组件都在本地运行B. 系统管理员可以远程管理所有组件C. 应用程序的数据和代码在主机之间是可移植的D. 所有这些都正确37. 以下哪个分布式算法不是CAP定理中提到的?A. 客户端-服务器算法B. 一致性算法C. 分区容错算法D. 内容分发算法38. 分布式系统中的“分区容错”是什么意思?A. 在网络故障时,系统仍然可以运行B. 在网络分区时,系统能够继续运行C. 在网络拥堵时,系统仍然可以运行D. 在网络配置错误时,系统能够继续运行39. 以下哪个选项不是分布式系统中的常见性能指标?A. 响应时间B. 可扩展性C. 容错性D. 资源利用率40. 分布式系统与传统集中式系统的最大区别是什么?A. 可靠性更高B. 可伸缩性更好C. 无需依赖中央控制点D. 所有这些都正确二、问答题1. 什么是分布式系统?请简述其基本特性。


阿里seata原理什么是SeataSeata(Simple Extensible Autonomous Transaction Architecture)是一款分布式事务解决方案,由阿里巴巴开发,旨在提供高性能和高可靠性的分布式事务解决方案。
它为分布式系统提供强一致性的事务支持,简化了分布式事务的开发和管理。
Seata的核心组件Seata由三个核心组件组成,分别是事务协调器(TC)、事务管理器(TM)和资源管理器(RM)。
事务协调器(TC)事务协调器(TC)是Seata的核心模块之一,负责协调和管理全局事务。
当一个全局事务发起时,TC为其生成一个全局唯一的事务ID,并将其发送给事务参与者。
TC负责协调所有事务参与者的工作,并在事务完成时提交或回滚全局事务。
TC还负责记录全局事务的状态以及事务日志的持久化。
事务管理器(TM)事务管理器(TM)是Seata的核心模块之一,负责全局事务的开启、提交和回滚操作。
在一个全局事务中,TM为全局事务的发起者,负责调度和控制全局事务的生命周期。
它与TC进行通信,根据指令通知事务参与者执行相应的操作。
资源管理器(RM)资源管理器(RM)是Seata的核心模块之一,负责管理与本地资源的交互。
在一个分布式事务中,每个参与者都可以维护一个RM。
RM负责与TM通信,并执行TM指令要求的本地事务操作。
RM将本地事务的状态通知给TC,以便TC了解全局事务的执行情况。
Seata的工作原理Seata的工作原理可以分为三个阶段:事务开始阶段、事务执行阶段和事务提交或回滚阶段。
事务开始阶段当一个全局事务发起时,TM向TC申请一个全局事务ID。
TC为全局事务生成一个唯一ID,并将其发送给TM。
TM收到全局事务ID后,将其发送给所有的事务参与者(RM)。
事务参与者将全局事务ID与本地事务绑定。
事务执行阶段在事务执行阶段,TM会发送指令给各个事务参与者(RM),要求它们执行本地事务。
事务参与者执行本地事务,并将事务的执行结果返回给TM。

CAP、Base理论和分布式事务——2PC、3PC和TCC 原⽂作者: 原⽂地址:对于单机下的本地事务,很显然我们有已被实践证明的成熟 ACID 模型来保证数据的严格⼀致性。
但对于⼀个⾼访问量、⾼并发的分布式系统来说,如果我们期望实现⼀套严格满⾜ ACID 特性的分布式事务,很可能出现的情况就是在系统的可⽤性和严格⼀致性之间出现冲突——因为当我们要求分布式系统具有严格⼀致性时,很可能就要牺牲掉系统的可⽤性。
但⽏庸置疑的⼀点是,可⽤性⼜是⼀个所有⽤户不允许我们讨价还价的属性,⽐如像淘宝这样的⽹站,我们要求它 7x24 ⼩时不间断地对外服务。
因此,我们需要在可⽤性和⼀致性之间做⼀些取舍,围绕这种取舍,出现了两个经典的分布式理论——CAP 和 BASE,这两者也是所有分布式事务协议的基⽯。
⼀、CAP 定理CAP ⾸次在 ACM PODC 会议上作为猜想被提出,两年后被证明为定理,从此深深影响了分布式计算的发展。
CAP 理论告诉我们,⼀个分布式系统不可能同时满⾜⼀致性(Consistency)、可⽤性(Availability)和分区容错性(Partition tolerance)这三个基本需求,最多只能同时满⾜其中的两项。
⼀致性:数据在多个副本之间保持⼀致。
当有⼀个节点的数据发⽣更新后,其它节点应该也能同步地更新数据。
可⽤性:对于⽤户的每⼀个操作请求,系统总能在有限的时间内返回结果。
分区容错性:分布式系统中的不同节点可能分布在不同的⼦⽹络中,这些⼦⽹络被称为⽹络分区。
由于⼀些特殊原因导致⼦⽹络之间出现⽹络不连通的情况,系统仍需要能够保证对外提供⼀致性和可⽤性的服务。
CAP 定理告诉了我们同时满⾜这三项是不可能的,那么放弃其中的⼀项会是什么样的呢?放弃项放弃P : 如果希望能够避免出现分区容错性问题,⼀种较为简单的做法是将所有数据放在⼀个节点上。
这样肯定不会受⽹络分区影响。
但此时分布式系统也失去了意义。

seata工作原理Seata是一种开源的分布式事务解决方案,旨在解决分布式系统中的数据一致性问题。
Seata采用了三个核心组件:事务协调器(Transaction Coordinator)、全局事务管理器(Global Transaction Manager)和本地事务管理器(Branch Transaction Manager)。
下面将详细介绍Seata的工作原理。
1. 事务协调器(Transaction Coordinator)事务协调器是Seata的核心组件之一,负责全局事务的协调、管理和控制。
当一个分布式事务发起时,事务协调器会生成一个全局事务ID,并将该ID分发给各个参与者。
在事务执行的过程中,事务协调器会收集各个参与者的事务状态,并根据这些状态决定事务的提交或回滚。
2. 全局事务管理器(Global Transaction Manager)全局事务管理器是Seata的另一个核心组件,负责全局事务的管理和调度。
全局事务管理器与事务协调器协同工作,通过调用各个参与者的本地事务管理器来执行具体的数据库操作。
全局事务管理器还负责记录全局事务的执行日志,以便在发生故障时进行恢复。
3. 本地事务管理器(Branch Transaction Manager)本地事务管理器是Seata的第三个核心组件,负责管理和执行参与者的本地事务。
在分布式事务中,每个参与者都有一个本地事务管理器。
本地事务管理器负责与各个数据库进行交互,并执行具体的事务操作。
本地事务管理器会将事务的执行结果反馈给事务协调器,以便协调器做出事务提交或回滚的决策。
Seata的工作原理如下:1. 应用程序发起一个分布式事务请求,调用事务协调器的接口,生成一个全局事务ID。
2. 事务协调器将全局事务ID分发给各个参与者,并记录事务的状态为“开始”。
3. 参与者接收到全局事务ID后,调用本地事务管理器执行具体的数据库操作,并将事务的状态(成功或失败)反馈给事务协调器。

基于OODA环的分布式作战仿真时间管理算法鄢马也1,2,常天庆丨,范文慧2,李婕3,孔德鹏4(1.陆军装甲兵学院兵器与控制系,北京100072;2.清华大学自动化系,北京100084;3.解放军总医院京南医疗区杜家坎门诊部,北京100072;4.92942部队,北京100161)摘要:在信息化战争时代,OODA指挥控制环在军事仿真中的应用日益广泛,分布式仿真的灵活性及高效的并行性对作战仿真的发展提供了便利。
面对作战仿真的需求,对分布式仿真系统的核心技术——时间管理算法进行研究。
针对OODA指挥控制环的特点,提出了一种自适应移动时间窗算法。
算法根据模型自适应调整时间窗大小,可避免频繁同步并对内存进行精准清除。
为进一步优化时间管理算法,提出了一种改进全局虚拟时间算法,对全局虚拟时间同步计算中的阻塞过程进行改善。
详细分析该算法的步骤及原理,并通过实例进行验证。
结果表明,该算法可有效保证分布式仿真的运行,运行速度优于其他传统时间管理算法。
关键词:OODA环;时间管理;移动时间窗;全局虚拟时间中图分类号:TP391文献标识码:A DOI:10.16157/j.issn.0258-7998.211344中文引用格式:马也,常天庆,范文慧,等.基于OODA环的分布式作战仿真时间管理算法[J].电子技术应用,2021,47(5):86-91.英文弓I用格式:Ma Ye,Chang Tianqing,Fan Wenhui,et al.Time management algorithm of distributed combat simulation based on OODA loop[J].Application of Electronic Technique,2021,47(5):86-91.Time management algorithm of distributed combat simulation based on OODA loopMa Ye1,2,Chang Tianqing1,Fan Wenhui2,Li Jie3,Kong Depeng4(1.Department of Weapons and Control,Academy of Army Armored Force,Beijing100072,China;2.Department of Automation,Tsinghua University,Beijing100084,China;3.Jingnan Medical District Dujiakan Clinic,PLA General Hospital,Beijing100072,China;4.Unit of92942,Beijing100161,China)Abstract:In the information-based war era,OODA command and control loop is widely used in military simulation.The flexibility and efficient parallelism of distributed simulation promote the development of combat simulation.According to the requirement of combat simulation,this paper studies the core technology of distributed simulation system,which is time management algorithm. Based on the characteristics of OODA command and control loop,this paper proposes an adaptive moving time window algorithm. The algorithm adaptively adjusts the size of time window according to the model,which can avoid frequent synchronization and clear the memory accurately.In order to further optimize the time management algorithm,the author also proposes an improved global vir-tual time algorithm to improve the blocking process in global virtual time synchronization calculation.Through detailed analysis of the steps and principles of the algorithm,and verification by an example,the results show that the algorithm can effectively guaran-tee the running of distributed simulation,and the running speed is better than other traditional time management algorithms.Key words:OODA loop;time management;moving time window;global virtual time0引言OODA环理论是由BOYD J提出的军事作战中的战略决策理论[1],成为对作战中出现的冲突问题进行描述的一种科学方法。


分布式事务详解1. 什么是分布式事务1.1 事务严格意义上的事务实现应该是具备原⼦性、⼀致性、隔离性和持久性,简称 ACID。
通俗意义上来说,事务就是为了使得⼀些更新等操作要么都成功,要么都失败。
原⼦性(Atomicity):可以理解为⼀个事务内的所有操作要么都执⾏,要么都不执⾏。
⼀致性(Consistency):可以理解为数据是满⾜完整性约束的,也就是不会存在中间状态的数据,⽐如你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态。
隔离性(Isolation):指的是多个事务并发执⾏的时候不会互相⼲扰,即⼀个事务内部的数据对于其他事务来说是隔离的。
持久性(Durability):指的是⼀个事务完成了之后数据就被永远保存下来,之后的其他操作或故障都不会对事务的结果产⽣影响。
其中,原⼦性和持久性就是靠undo和redo⽇志来实现的。
在Mysql中,有许多⽇志⽂件,这2个⽂件就是与事务有关的。
1.2 undo⽇志undo⽇志:⽤于保证事务的原⼦性。
原理:1. 在操作任何数据之前,先将数据备份到Undo Log。
2. 然后进⾏数据的修改。
3. 若出现了错误或⽤户执⾏了ROLLBACK语句,系统就可以利⽤Undo Log中的备份数据恢复到事务开始之前的状态。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录B=2到undo log5. 修改B=46. 将undo log写到磁盘7. 将数据写到磁盘8. 事务提交1.3 redo⽇志redo⽇志:⽤于保证事务的持久性原理:1. redo log与undo log 相反,redo log记录的是新数据的备份,undo log记录的是旧数据的备份2. 在事务提交前只需要将redo log持久化即可。
流程举例:1. 事务开始2. 记录A=1到undo log3. 修改A=34. 记录A=3到redo log5. 记录B=2到undo log6. 修改B=47. 记录B=4到redo log8. 将undo log写到磁盘9. 将redo log写⼊磁盘10. 事务提交1.4 分布式事务分布式事务:顾名思义就是要在分布式系统中实现事务,它其实是由多个本地事务组合⽽成。

seata原理seata(SimpleExtensibleAutonomousTransactionArchitecture)是一个开源的分布式事务解决方案,它旨在为微服务架构提供完整的分布式事务解决方案。
它是一个可以被拓展且自治的事务架构,以服务器端架构(TC)为基础,它可以让分布式系统中的服务消费者和服务提供者实现无缝集成,从而实现数据一致性、容错性和高可用。
seata的架构分为通信层、分析层和持久层,它通过以下三步实现分布式事务:**1.服务消费者发起全局事务:**当服务消费者发起一个全局事务时,它首先将请求发送给SEATA 服务端,SEATA服务端注册该请求,并将全局事务的信息发送给每个参与事务的服务提供者,同时会返回一个XID(全局事务ID)给服务消费者。
**2.服务提供者参与全局事务:**当服务提供者收到全局事务登记请求时,它会检查请求是否来自服务消费者,如果确认是,它将获得一个XID(全局事务ID),同时将本地数据库的事务设置为挂起状态。
当服务消费者收到这个XID,它就可以将XID发送给服务提供者,以便服务提供者基于此ID执行相应的操作。
**3.提交或回滚事务:**当服务提供者完成相应的操作后,它会将结果发送给seata服务器,seata服务器根据收到的结果,将XID发送给服务消费者,服务消费者根据XID提交或回滚事务。
一旦服务消费者提交或回滚事务,服务提供者接收到服务消费者提交或回滚事务的消息,就会提交或回滚本地数据库事务。
seata的优势之一是其开放性,它支持多种数据库,支持多种框架,例如Spring Cloud、Dubbo等,此外,它还使用Atomikos事务及Netty作为服务器技术,因此能够提供快速、可靠、易于使用的分布式事务解决方案。
另外,seata也使用了严格的数据隔离(Isolation)级别,以保证全局事务在两个不同服务中的原子性,它提供了一致性、容错性和高可用性,不仅可以满足当前大规模企业的分布式事务需求,而且还可以满足未来其它应用场景的需求。
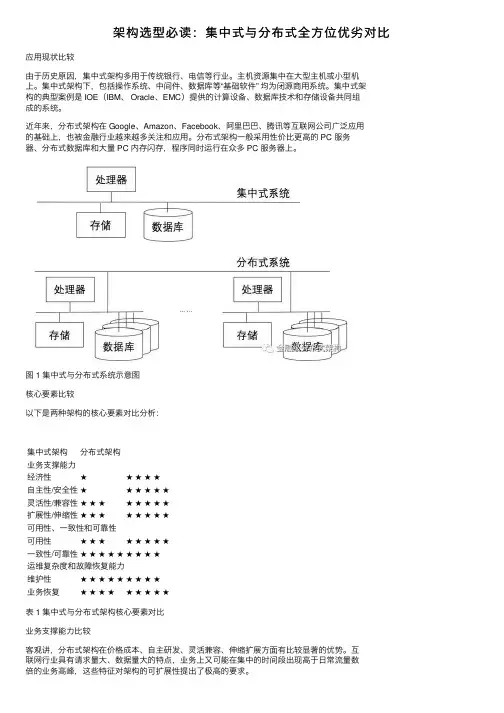
架构选型必读:集中式与分布式全⽅位优劣对⽐应⽤现状⽐较由于历史原因,集中式架构多⽤于传统银⾏、电信等⾏业。
主机资源集中在⼤型主机或⼩型机上。
集中式架构下,包括操作系统、中间件、数据库等“基础软件” 均为闭源商⽤系统。
集中式架构的典型案例是 IOE(IBM、 Oracle、EMC)提供的计算设备、数据库技术和存储设备共同组成的系统。
近年来,分布式架构在 Google、Amazon、Facebook、阿⾥巴巴、腾讯等互联⽹公司⼴泛应⽤的基础上,也被⾦融⾏业越来越多关注和应⽤。
分布式架构⼀般采⽤性价⽐更⾼的 PC 服务器、分布式数据库和⼤量 PC 内存闪存,程序同时运⾏在众多 PC 服务器上。
图 1 集中式与分布式系统⽰意图核⼼要素⽐较以下是两种架构的核⼼要素对⽐分析:集中式架构分布式架构业务⽀撑能⼒经济性★★★★★⾃主性/安全性★★★★★★灵活性/兼容性★★★★★★★★扩展性/伸缩性★★★★★★★★可⽤性、⼀致性和可靠性可⽤性★★★★★★★★⼀致性/可靠性★★★★★★★★★运维复杂度和故障恢复能⼒维护性★★★★★★★★★业务恢复★★★★★★★★★表 1 集中式与分布式架构核⼼要素对⽐业务⽀撑能⼒⽐较客观讲,分布式架构在价格成本、⾃主研发、灵活兼容、伸缩扩展⽅⾯有⽐较显著的优势。
互联⽹⾏业具有请求量⼤、数据量⼤的特点,业务上⼜可能在集中的时间段出现⾼于⽇常流量数倍的业务⾼峰,这些特征对架构的可扩展性提出了极⾼的要求。
在集中式架构下,为了应对更⾼的性能、更⼤的数据量,往往只能向上升级到更⾼配置的机器,如升级更强的 CPU、升级多核、升级内存、升级存储等,⼀般这种⽅式被称为 Scale Up。
但单机的性能永远都有瓶颈,随着业务量的增长,只能通过 Scale Out 的⽅式来⽀持,即横向扩展出同样架构的服务器。
在集中式架构下,由于单个服务器的造价昂贵,所以 Scale Out 的⽅式成本⾮常⾼,⽆法做到按需扩展。
分布式原理:一文了解Gossip 协议gossip 协议(gossip protocol)又称epidemic 协议(epidemic protocol),是基于流行病传播方式的节点或者进程之间信息交换的协议,在分布式系统中被广泛使用,比如我们可以使用gossip 协议来确保网络中所有节点的数据一样。
从gossip 单词就可以看到,其中文意思是八卦、流言等意思,我们可以想象下绯闻的传播(或者流行病的传播);gossip 协议的工作原理就类似于这个。
gossip 协议利用一种随机的方式将信息传播到整个网络中,并在一定时间内使得系统内的所有节点数据一致。
Gossip 其实是一种去中心化思路的分布式协议,解决状态在集群中的传播和状态一致性的保证两个问题。
gossip 优势可扩展性(Scalable)gossip 协议是可扩展的,一般需要O(logN)轮就可以将信息传播到所有的节点,其中N 代表节点的个数。
每个节点仅发送固定数量的消息,并且与网络中节点数目无法。
在数据传送的时候,节点并不会等待消息的ack,所以消息传送失败也没有关系,因为可以通过其他节点将消息传递给之前传送失败的节点。
系统可以轻松扩展到数百万个进程。
容错(Fault-tolerance)网络中任何节点的重启或者宕机都不会影响gossip 协议的运行。
健壮性(Robust)gossip 协议是去中心化的协议,所以集群中的所有节点都是对等的,没有特殊的节点,所以任何节点出现问题都不会阻止其他节点继续发送消息。
任何节点都可以随时加入或离开,而不会影响系统的整体服务质量(QOS)最终一致性(Convergent consistency)Gossip 协议实现信息指数级的快速传播,因此在有新信息需要传播时,消息可以快速地发送到全局节点,在有限的时间内能够做到所有节点都拥有最新的数据。
gossip 协议的类型。
数据并行的大模型分布式训练-概述说明以及解释1.引言1.1 概述数据并行的大模型分布式训练是一种在机器学习和深度学习领域中广泛应用的技术。
随着数据量的不断增长和模型复杂度的提高,传统的单机模型训练已经无法满足对高效、快速训练的需求。
因此,采用分布式训练来加速模型训练过程成为一种趋势。
概括而言,数据并行是一种将大型数据集切分成小的子数据集,在多个计算节点上同时进行训练的策略。
每个计算节点使用相同的模型参数,但操作的是不同的数据子集。
通过在每个节点上分别计算梯度,并进行梯度的聚合,可以快速更新全局的模型参数。
这种数据并行的方式能够显著提高训练速度,解决了单机训练时的瓶颈问题。
大型模型的分布式训练则是指在数据并行的基础上,对大规模模型进行训练的方法。
大型模型具有巨大的网络结构和参数量,因此需要更大的计算资源和存储空间来进行训练。
为了实现大模型的分布式训练,通常需要使用分布式存储系统和计算框架来支持数据的并行处理和模型的训练过程。
大模型的分布式训练不仅可以提高训练速度,还可以有效地利用集群资源,提升模型的性能和泛化能力。
同时,数据并行的优势也体现在其适用的广泛性。
从大规模机器学习任务到深度学习模型的训练,数据并行都发挥着重要的作用。
接下来,本文将从数据并行的概念和原理出发,详细介绍大模型的分布式训练方法。
同时,还将探讨数据并行和大模型分布式训练在实际应用中所面临的挑战,并提出相应的解决方案。
文章结构部分的内容可以如下编写:"1.2 文章结构":本文主要分为三个部分,即引言、正文和结论。
在引言部分,将首先概述数据并行的概念和原理,并介绍大模型的分布式训练的背景和意义。
随后,说明本文的目的,即探讨数据并行在大模型分布式训练中的应用和挑战。
接下来的正文部分将详细介绍数据并行的概念和原理。
首先,将阐述数据并行的基本概念以及其实现的原理和方法。
然后,将探讨大模型的分布式训练,从理论和实践两个方面来分析大模型的分布式训练的优势和挑战。
时间戳合并算法摘要:一、时间戳合并算法简介1.定义及背景2.应用场景二、时间戳合并算法原理1.基本概念2.算法流程三、时间戳合并算法优缺点分析1.优点2.缺点四、时间戳合并算法在实际应用中的案例1.案例介绍2.案例分析五、时间戳合并算法的发展趋势与展望1.发展趋势2.展望正文:一、时间戳合并算法简介时间戳合并算法是一种将多个时间戳合并为一个时间戳的方法,广泛应用于分布式系统、数据库系统等领域。
通过时间戳合并算法,可以有效地解决分布式系统中的数据一致性问题,保证数据的一致性和完整性。
二、时间戳合并算法原理1.基本概念时间戳合并算法是基于分布式系统中的多个节点产生的时间戳进行合并的。
每个节点都会产生一个时间戳,代表该节点在某一时刻的数据状态。
将这些时间戳进行合并,可以得到一个更高层次的时间戳,用于表示整个分布式系统在某一时刻的数据状态。
2.算法流程时间戳合并算法通常包括以下几个步骤:(1)获取各个节点的时间戳(2)对时间戳进行排序(3)选择排序后的中间时间戳作为合并结果三、时间戳合并算法优缺点分析1.优点(1)简单易懂:时间戳合并算法实现简单,容易理解和实现。
(2)高效性:算法的时间复杂度较低,适用于实时性要求不高的场景。
(3)可扩展性:时间戳合并算法可以很容易地扩展到更大的分布式系统中。
2.缺点(1)实时性差:由于需要对各个节点的时间戳进行排序,算法的实时性较差,不适合实时性要求较高的场景。
(2)分布式系统节点数量受限:当分布式系统节点数量较大时,时间戳合并算法的性能会受到影响。
四、时间戳合并算法在实际应用中的案例1.案例介绍在分布式数据库系统中,为了保证数据的一致性,需要对多个节点上的数据进行同步。
此时,可以利用时间戳合并算法,将各个节点上的数据时间戳进行合并,得到一个全局一致的时间戳,用于表示整个分布式数据库系统在某一时刻的数据状态。
2.案例分析通过时间戳合并算法,分布式数据库系统可以有效地解决数据一致性问题,保证各个节点上的数据一致性和完整性。