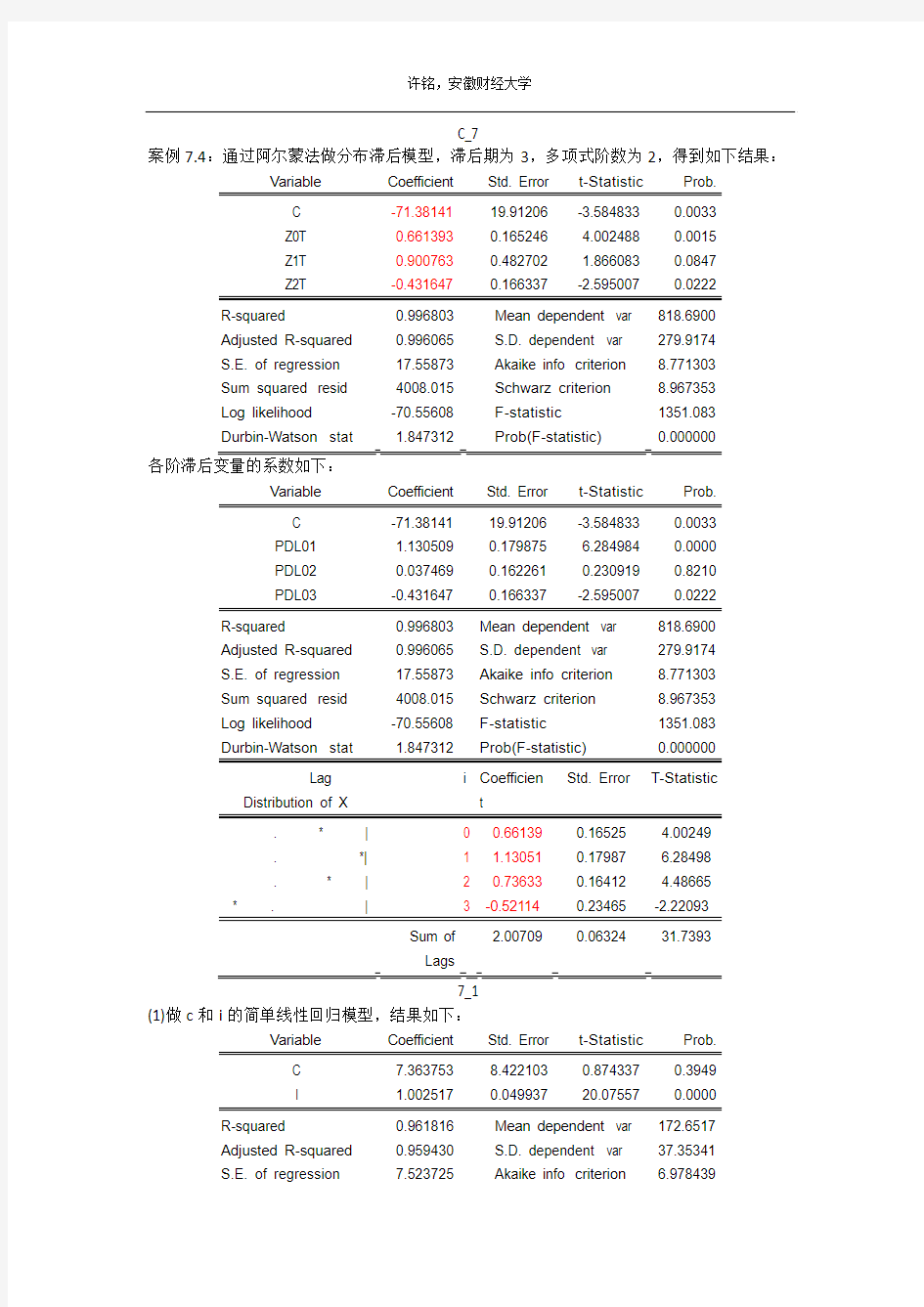

C_7
案例7.4:通过阿尔蒙法做分布滞后模型,滞后期为3,多项式阶数为2,得到如下结果:
C -71.38141 19.91206 -3.584833 0.0033
Z0T 0.661393 0.165246 4.002488 0.0015
Z1T 0.900763 0.482702 1.866083 0.0847
Z2T -0.431647 0.166337 -2.595007 0.0222 R-squared 0.996803 Mean dependent var 818.6900
Adjusted R-squared 0.996065 S.D. dependent var 279.9174
S.E. of regression 17.55873 Akaike info criterion 8.771303
Sum squared resid 4008.015 Schwarz criterion 8.967353
Log likelihood -70.55608 F-statistic 1351.083
Durbin-Watson stat 1.847312 Prob(F-statistic) 0.000000
Variable Coefficient Std. Error t-Statistic Prob.
C -71.38141 19.91206 -3.584833 0.0033
PDL01 1.130509 0.179875 6.284984 0.0000
PDL02 0.037469 0.162261 0.230919 0.8210
R-squared 0.996803 Mean dependent var 818.6900
Adjusted R-squared 0.996065 S.D. dependent var 279.9174
S.E. of regression 17.55873 Akaike info criterion 8.771303
Sum squared resid 4008.015 Schwarz criterion 8.967353
Log likelihood -70.55608 F-statistic 1351.083
Lag Distribution of X i Coefficien
t
Std. Error T-Statistic
. * | 0 0.66139 0.16525 4.00249
. *| 1 1.13051 0.17987 6.28498
. * | 2 0.73633 0.16412 4.48665
Sum of
Lags
2.00709 0.06324 31.7393
7_1
(1)做c和i的简单线性回归模型,结果如下:
C 7.363753 8.422103 0.874337 0.3949
R-squared 0.961816 Mean dependent var 172.6517
Adjusted R-squared 0.959430 S.D. dependent var 37.35341
S.E. of regression 7.523725 Akaike info criterion 6.978439
Sum squared resid 905.7030 Schwarz criterion 7.077369
Log likelihood -60.80595 F-statistic 403.0285
Durbin-Watson stat 1.168058 Prob(F-statistic) 0.000000
做e和i的一阶自回归模型,结果如下:
C 4.172912 10.53155 0.396230 0.6979
I 0.943596 0.236994 3.981521 0.0014
E(-1) 0.076357 0.220705 0.345968 0.7345 R-squared 0.953214 Mean dependent var 176.7389
Adjusted R-squared 0.946531 S.D. dependent var 34.10267
S.E. of regression 7.885697 Akaike info criterion 7.126763
Sum squared resid 870.5789 Schwarz criterion 7.273801
Log likelihood -57.57749 F-statistic 142.6190
Durbin-Watson stat 1.164644 Prob(F-statistic) 0.000000
调整后的可决系数都很好,模型拟合优度很高;两个模型都通过了F检验,但从T统计值可以看出,一阶自回归变量不显著,所以第一个模型更好。
(2)不会。
7_2
通过阿尔蒙法做滞后变量长度为4,多项式阶数为2的滞后变量模型,可得如下结果:Variable Coefficient Std. Error t-Statistic Prob.
C -35.49234 8.192884 -4.332093 0.0007
Z0 0.891012 0.174563 5.104248 0.0002
Z1 -0.669904 0.254447 -2.632783 0.0197
Z2 0.104392 0.062311 1.675338 0.1160 R-squared 0.984670 Mean dependent var 121.2322
Adjusted R-squared 0.981385 S.D. dependent var 45.63348
S.E. of regression 6.226131 Akaike info criterion 6.688517
Sum squared resid 542.7059 Schwarz criterion 6.886378
Log likelihood -56.19666 F-statistic 299.7429
Durbin-Watson stat 1.130400 Prob(F-statistic) 0.000000
各滞后变量的系数为:
C -35.49234 8.192884 -4.332093 0.0007
PDL01 -0.031228 0.123416 -0.253031 0.8039
PDL02 -0.252336 0.062441 -4.041182 0.0012
PDL03 0.104392 0.062311 1.675338 0.1160 R-squared 0.984670 Mean dependent var 121.2322
Adjusted R-squared 0.981385 S.D. dependent var 45.63348
S.E. of regression 6.226131 Akaike info criterion 6.688517
Sum squared resid 542.7059 Schwarz criterion 6.886378
Log likelihood -56.19666 F-statistic 299.7429
Durbin-Watson stat 1.130400 Prob(F-statistic) 0.000000
Lag Distribution of X i Coefficien
t
Std. Error T-Statistic
. *| 0 0.89101 0.17456 5.10425
. * | 1 0.32550 0.08998 3.61759
*. | 2 -0.03123 0.12342 -0.25303 * . | 3 -0.17917 0.08488 -2.11094
* . | 4 -0.11833 0.18034 -0.65616
Sum of
Lags
0.88778 0.03007 29.5262
7_4
二元线性模型:
C 6634.468 4386.179 1.512585 0.1412
X1 0.114627 0.028851 3.973071 0.0004
X2 0.264053 0.094841 2.784182 0.0094 R-squared 0.962177 Mean dependent var 54487.78
Adjusted R-squared 0.959569 S.D. dependent var 41135.13
S.E. of regression 8271.247 Akaike info criterion 20.96802
Sum squared resid 1.98E+09 Schwarz criterion 21.10543
Log likelihood -332.4883 F-statistic 368.8676
Durbin-Watson stat 1.339440 Prob(F-statistic) 0.000000 LM
F-statistic 3.120207 Probability 0.088229
Obs*R-squared 3.208417 Probability 0.073260
Test Equation:
Dependent Variable: RESID
Method: Least Squares
C 620.5725 4248.679 0.146062 0.8849
X1 -0.005707 0.028038 -0.203531 0.8402
X2 0.022716 0.092452 0.245709 0.8077 RESID(-1) 0.324749 0.183847 1.766411 0.0882 R-squared 0.100263 Mean dependent var -4.04E-12
Adjusted R-squared 0.003863 S.D. dependent var 7999.985
S.E. of regression 7984.519 Akaike info criterion 20.92487
Sum squared resid 1.79E+09 Schwarz criterion 21.10808
Log likelihood -330.7978 F-statistic 1.040069
Durbin-Watson stat 2.025054 Prob(F-statistic) 0.390106
由LM统计量可知,在0.1水平上认为存在自相关:
一阶自相关变换:
C 6624.700 4435.348 1.493614 0.1469
X1 0.047310 0.040494 1.168337 0.2529
X2 0.275070 0.092275 2.980997 0.0060
Y(-1) 0.405521 0.191717 2.115204 0.0438 R-squared 0.967014 Mean dependent var 55906.16
Adjusted R-squared 0.963349 S.D. dependent var 41011.93
S.E. of regression 7851.487 Akaike info criterion 20.89471
Sum squared resid 1.66E+09 Schwarz criterion 21.07974
Log likelihood -319.8680 F-statistic 263.8454
Durbin-Watson stat 2.123861 Prob(F-statistic) 0.000000
由DW统计量可知:通过局部调整变换,模型的自相关消除了。但是x1变量的显著性降低了。
指数模型:
C 1.681201 2.259708 0.743990 0.4629
LX1 0.393625 0.346647 1.135522 0.2655
R-squared 0.947194 Mean dependent var 10.66049
Adjusted R-squared 0.943552 S.D. dependent var 0.718655
S.E. of regression 0.170743 Akaike info criterion -0.608249
Sum squared resid 0.845447 Schwarz criterion -0.470837
Log likelihood 12.73199 F-statistic 260.0901
Durbin-Watson stat 0.885742 Prob(F-statistic) 0.000000
由DW
一阶自相关变换:
Variable Coefficient Std. Error t-Statistic Prob.
C 0.672511 1.707952 0.393753 0.6969
LX1 0.200421 0.260423 0.769597 0.4482
LX2 0.181201 0.157654 1.149359 0.2605
LY(-1) 0.534718 0.111899 4.778585 0.0001
R-squared 0.968926 Mean dependent var 10.70564
Adjusted R-squared 0.965474 S.D. dependent var 0.682843
S.E. of regression 0.126881 Akaike info criterion -1.171225
Sum squared resid 0.434665 Schwarz criterion -0.986195
Log likelihood 22.15399 F-statistic 280.6346
7_6
(1)OLS简单线性回归:
C 27.76594 7.945083 3.494733 0.0016
R-squared 0.978103 Mean dependent var 262.1725
Adjusted R-squared 0.977321 S.D. dependent var 159.3349
S.E. of regression 23.99515 Akaike info criterion 9.257921
Sum squared resid 16121.49 Schwarz criterion 9.351334
Log likelihood -136.8688 F-statistic 1250.713
Durbin-Watson stat 1.280986 Prob(F-statistic) 0.000000
由DW P较小,模型显著性很高;解释变量的T值得P很小,显著性很高。
(2)由LM统计量知:模型五阶自相关显著。
Breusch-Godfrey Serial Correlation LM Test:
F-statistic 2.881477 Probability 0.036623
Obs*R-squared 11.55445 Probability 0.041430
Test Equation:
Dependent Variable: RESID
Method: Least Squares
Date: 12/26/14 Time: 11:05
C -16.57916 11.27786 -1.470063 0.1551
X0.065162 0.037711 1.727929 0.0974
RESID(-1) 0.293607 0.215883 1.360030 0.1870
RESID(-2) -0.587604 0.236665 -2.482854 0.0208
RESID(-3) -0.406778 0.333805 -1.218607 0.2353
RESID(-4) -0.109083 0.496525 -0.219692 0.8280
R-squared 0.385148 Mean dependent var -1.16E-14
Adjusted R-squared 0.224752 S.D. dependent var 23.57781
S.E. of regression 20.75983 Akaike info criterion 9.104881
Sum squared resid 9912.326 Schwarz criterion 9.431827
Log likelihood -129.5732 F-statistic 2.401231
Durbin-Watson stat 2.059016 Prob(F-statistic) 0.059903
建立五阶滞后变量的滞后模型,结果如下:可决系数很大,拟合优度很高;F统计值很大,模型拟合很显著;T统计值的P很小,滞后变量很显著;但模型显现出较强的正自相关;
Variable Coefficient Std. Error t-Statistic Prob.
C 7.934911 6.635650 1.195800 0.2440
Z 0.961111 0.019777 48.59655 0.0000
R-squared 0.990355 Mean dependent var 289.8652
Adjusted R-squared 0.989936 S.D. dependent var 160.5350
S.E. of regression 16.10517 Akaike info criterion 8.472776
Sum squared resid 5965.661 Schwarz criterion 8.570286
Log likelihood -103.9097 F-statistic 2361.624
通过广义差分法建立库伊克模型模型,并用工具变量法估计被解释变量的滞后一阶值,结果见下:
C -9.065093 6.580133 -1.377646 0.1801
X0.284272 0.065911 4.312948 0.0002
YF(-1) 0.785678 0.097739 8.038555 0.0000 R-squared 0.993621 Mean dependent var 268.0696
Adjusted R-squared 0.993130 S.D. dependent var 158.7886
S.E. of regression 13.16101 Akaike info criterion 8.090091
Sum squared resid 4503.516 Schwarz criterion 8.231536
Log likelihood -114.3063 F-statistic 2024.925
T检验值的P很小,各个变量都具有很强的显著性。
计量经济学题库 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C)。 A.统计学 B.数学 C.经济学 D.数理统计学 2.计量经济学成为一门独立学科的标志是(B)。 A.1930年世界计量经济学会成立B.1933年《计量经济学》会刊出版 C.1969年诺贝尔经济学奖设立 D.1926年计量经济学(Economics)一词构造出来 3.外生变量和滞后变量统称为(D)。 A.控制变量 B.解释变量 C.被解释变量 D.前定变量4.横截面数据是指(A)。 A.同一时点上不同统计单位相同统计指标组成的数据B.同一时点上相同统计单位相同统计指标组成的数据 C.同一时点上相同统计单位不同统计指标组成的数据D.同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C)。 A.时期数据 B.混合数据 C.时间序列数据 D.横截面数据6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是( A )。 A.内生变量 B.外生变量 C.滞后变量 D.前定变量7.描述微观主体经济活动中的变量关系的计量经济模型是( A )。 A.微观计量经济模型 B.宏观计量经济模型 C.理论计量经济模型 D.应用计量经济模型 8.经济计量模型的被解释变量一定是( C )。 A.控制变量 B.政策变量 C.内生变量 D.外生变量9.下面属于横截面数据的是( D )。 A.1991-2003年各年某地区20个乡镇企业的平均工业产值 B.1991-2003年各年某地区20个乡镇企业各镇的工业产值 C.某年某地区20个乡镇工业产值的合计数 D.某年某地区20个乡镇各镇的工业产值 10.经济计量分析工作的基本步骤是( A )。 A.设定理论模型→收集样本资料→估计模型参数→检验模型B.设定模型→估计参数→检验模型→应用
计量经济学思考题答案 第一章绪论 1.1怎样理解产生于西方国家的计量经济学能够在中国的经济理论研究和现代 化建设中发挥重要作用? 答:计量经济学的产生源于对经济问题的定量研究,这是社会经济发展到一定阶段的客观需要。计量经济学的发展是与现代科学技术成就结合在一起的,它反映了社会化大生产对各种经济因素和经济活动进行数量分析的客观要求。经济学从定性研究向定量分析的发展,是经济学逐步向更加精密、更加科学发展的表现。我们只要坚持以科学的经济理论为指导,紧密结合中国经济的实际,就能够使计量经济学的理论与方法在中国的经济理论研究和现代化建设中发挥重要作用。 1.2理论计量经济学和应用计量经济学的区别和联系是什么? 答:计量经济学不仅要寻求经济计量分析的方法,而且要对实际经济问题加以研究,分为理论计量经济学和应用计量经济学两个方面。 理论计量经济学是以计量经济学理论与方法技术为研究内容,目的在于为应用计量经济学提供方法论。所谓计量经济学理论与方法技术的研究,实质上是指研究如何运用、改造和发展数理统计方法,使之成为适合测定随机经济关系的特殊方法。 应用计量经济学是在一定的经济理论的指导下,以反映经济事实的统计数据为依据,用计量经济方法技术研究计量经济模型的实用化或探索实证经济规律、分析经济现象和预测经济行为以及对经济政策作定量评价。 1.3怎样理解计量经济学与理论经济学、经济统计学的关系? 答:1、计量经济学与经济学的关系。联系:计量经济学研究的主体—经济现象和经济关系的数量规律;计量经济学必须以经济学提供的理论原则和经济运行规律为依据;经济计量分析的结果:对经济理论确定的原则加以验证、充实、完善。区别:经济理论重在定性分析,并不对经济关系提供数量上的具体度量;计量经济学对经济关系要作出定量的估计,对经济理论提出经验的内容。 2、计量经济学与经济统计学的关系。联系:经济统计侧重于对社会经济现象的描述性计量;经济统计提供的数据是计量经济学据以估计参数、验证经济理论的基本依据;经济现象不能作实验,只能被动地观测客观经济现象变动的既成事实,只能依赖于经济统计数据。区别:经济统计学主要用统计指标和统计分析方法对经济现象进行描述和计量;计量经济学主要利用数理统计方法对经济变量间的关系进行计量。 1.4在计量经济模型中被解释变量和解释变量的作用有什么不同? 答:在计量经济模型中,解释变量是变动的原因,被解释变量是变动的结果。被解释变量是模型要分析研究的对象。解释变量是说明被解释变量变动主要原因的变量。 1.5一个完整的计量经济模型应包括哪些基本要素?你能举一个例子吗? 答:一个完整的计量经济模型应包括三个基本要素:经济变量、参数和随机误差项。例如研究消费函数的计量经济模型:Y=α+βX+u 其中,Y为居民消费支出,X为居民家庭收入,二者是经济变量;α和β为参数;u是随机误差项。
《 期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使 ∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 )(达到最小值 D.使∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. B. % C. 2 D. % 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) ~ A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(2 2R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2 i )V ar(u i σ= C. 0)u E(u j i ≠ ) D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2 i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( )
数量经济学复习试题 一.对于模型:n i X Y i i i ,,1 =++=εβα 从10个观测值中计算出; 20,200,26,40,822=====∑∑∑∑∑i i i i i i Y X X Y X Y , 请回答以下问题: (1)求出模型中α和β的OLS 估计量; (2)当10=x 时,计算y 的预测值。 (3) 求出模型的2R ,并作出解释; (4)对模型总体作出检验; (5)对模型系数进行显著性检验; 二.根据我国1978——2000年的财政收入Y 和国生产总值X 的统计资料,可建立如下的计量经济模型: ?516.64770.0898t t Y X =+ (1) (2.5199) (0.005272) 2 R =0.9609,E S .=731.2086,F =516.3338,W D .=0.2174 1、 模型(1)斜率项是显著的吗?它有什么经济意义已知(048.2)28(025.0=t ) 2、检验该模型的误差项是否存在自相关。 (已知在23,1%,5===n k α条件下,489.1,352.1==U L d d ) 3、如果存在自相关,请您用广义差分法来消除自相关问题。 4、根据下面的信息,检验回归方程(1)的误差项是否存在异方差。如果存在异方差的话,请写出异方差的形式 。表1:此表为Eviews 输出结果。
RE 为模型(1)中残差的平方 5、我们通常用什么方法解决异方差问题,在这里,你建议使用什么方法修正模型?如何修正(要求写出修正后的模型)? 三、设货币需求方程式的总体模型为 t t t t t RGDP r P M εβββ+++=)ln()ln()ln( 210 其中M 为广义货币需求量,P 为物价水平,r 为利率,RGDP 为实际国生产总值。假定根据 容量为n =19的样本,用最小二乘法估计出如下样本回归模型; 1 .09 .0) 3() 13()ln(54.0)ln(26.003.0)ln( 2==++-=DW R e RGDP r P M t t t t t 其中括号的数值为系数估计的t 统计值,t e 为残差。 (1)从经济意义上考察估计模型的合理性; (2)在5%显著性水平上.分别检验参数21,ββ的显著性; (3)在5%显著性水平上,检验模型的整体显著性。 四、计量经济学研究工作中的重要方面是研究对古典模型假定违背的经济计量问题,通常包括异方差性问题、序列相关问题、多重共线性问题、解释变量的随机性问题等等。请回答:(30分) 1)异方差性的含义是什么?产生异方差的原因是什么? 2)模型产生异方差问题时将有什么危害? 3)叙述戈德非尔特—夸特(Goldfeld —Quandt )检验的过程 4)若异方差形式为i i X u E 22)(σ=,试写出解决此异方差问题的方法。 五、已知消费模型:t y =10αα+t x 1+2αt x 2+t μ 其中:t y =消费支出;t x 1=个人可支配收入;t x 2=消费者的流动资产; 0)(=t E μ;
1、已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X (45.2)(1.53) n=30 R 2=0.31 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题: (1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 答:(1)系数的符号是正确的,政府债券的价格与利率是负相关关系,利率的上升会引起政府债券价格的下降。 (2)i Y 代表的是样本值,而i ?Y 代表的是给定i X 的条件下i Y 的期望值,即?(/)i i i Y E Y X =。此模型是根据样本数据得出的回归结果,左边应当是i Y 的期望值,因此是i ?Y 而不是i Y 。 (3)没有遗漏,因为这是根据样本做出的回归结果,并不是理论模型。 (4)截距项101.4表示在X 取0时Y 的水平,本例中它没有实际意义;斜率项-4.78表明利率X 每上升一个百分点,引起政府债券价格Y 降低478美元。 2、有10户家庭的收入(X ,元)和消费(Y ,百元)数据如下表: 10户家庭的收入(X )与消费(Y )的资料 X 20 30 33 40 15 13 26 38 35 43 Y 7 9 8 11 5 4 8 10 9 10 若建立的消费Y 对收入X 的回归直线的Eviews 输出结果如下: Dependent Variable: Y var Adjusted R-squared 0.892292 F-statistic 75.55898 (1)说明回归直线的代表性及解释能力。 (2)在95%的置信度下检验参数的显着性。(0.025(10) 2.2281t =,0.05(10) 1.8125t =,0.025(8) 2.3060t =,0.05(8) 1.8595t =) (3)在95%的置信度下,预测当X =45(百元)时,消费(Y )的置信区间。(其
2.已知一模型的最小二乘的回归结果如下: i i ?Y =101.4-4.78X 标准差 () () n=30 R 2 = 其中,Y :政府债券价格(百美元),X :利率(%)。 回答以下问题:(1)系数的符号是否正确,并说明理由;(2)为什么左边是i ?Y 而不是i Y ; (3)在此模型中是否漏了误差项i u ;(4)该模型参数的经济意义是什么。 13.假设某国的货币供给量Y 与国民收入X 的历史如系下表。 某国的货币供给量X 与国民收入Y 的历史数据 根据以上数据估计货币供给量Y 对国民收入X 的回归方程,利用Eivews 软件输出结果为: Dependent Variable: Y Variable Coefficient Std. Error t-Statistic Prob. X C R-squared Mean dependent var Adjusted R-squared . dependent var . of regression F-statistic Sum squared resid Prob(F-statistic) 问:(1)写出回归模型的方程形式,并说明回归系数的显著性() 。 (2)解释回归系数的含义。 (2)如果希望1997年国民收入达到15,那么应该把货币供给量定在什么水平 14.假定有如下的回归结果 t t X Y 4795.06911.2?-= 其中,Y 表示美国的咖啡消费量(每天每人消费的杯数),X 表示咖啡的零售价格(单位:美元/杯),t 表示时间。问: (1)这是一个时间序列回归还是横截面回归做出回归线。 (2)如何解释截距的意义它有经济含义吗如何解释斜率(3)能否救出真实的总体回归函数 (4)根据需求的价格弹性定义: Y X ?弹性=斜率,依据上述回归结果,你能救出对咖啡需求的价格弹性吗如果不能,计算此弹性还需要其他什么信息 15.下面数据是依据10组X 和Y 的观察值得到的: 1110=∑i Y ,1680 =∑i X ,204200=∑i i Y X ,315400 2=∑ i X ,133300 2 =∑i Y 假定满足所有经典线性回归模型的假设,求0β,1β的估计值; 16.根据某地1961—1999年共39年的总产出Y 、劳动投入L 和资本投入K 的年度数据,运用普通最小二乘法估计得出了下列回归方程: ,DW= 式下括号中的数字为相应估计量的标准误。 (1)解释回归系数的经济含义; (2)系数的符号符合你的预期吗为什么 17.某计量经济学家曾用1921~1941年与1945~1950年(1942~1944年战争期间略去)美国国内消费C和工资收入W、非工资-非农业收入
计量经济学考试复习题 计量经济学练习题 1、经济计量学的研究步骤有哪些 一、模型设定:依据一定的经济理论或经验,先验地用一个或一组数学方程式表示被研究系统内经济变量之间的关系。 1、研究有关经济理论; 2、确定变量以及函数形式; 3、统计数据的收集与整理 二、参数估计:参数估计的方法主要有一般最小平方法(OLS)及其拓展形式(GLS、WLS、2Stage LS 等)、最大似然估计法、数值计算法等。 三、模型检验 1、经济意义准则; 2、统计检验准则; 3、计量经济检验准则 四、模型应用 1、检验经济理论; 2、结构分析(乘数分析、弹性分析); 3、政策评价 4、预测 ( 2、简述经济计量模型的检验准则有哪三方面 (1)经济意义准则;(2)统计检验准则;(3)计量经济检验准则 3、经济计量模型中的随机干扰项来自哪些方面 1、变量的省略。 由于人们认识的局限不能穷尽所有的影响因素或由于受时间、费用、数据质量等制约而没有引入模型之中的对被解释变量有一定影响的自变量。 2、统计误差。 数据搜集中由于计量、计算、记录等导致的登记误差;或由样本信息推断总体信息时产生的代表性误差。 3、模型的设定误差。 ( 如在模型构造时,非线性关系用线性模型描述了;复杂关系用简单模型描述了;此非线性关系用彼非线性模型描述了等等。 4、随机误差。 被解释变量还受一些不可控制的众多的、细小的偶然因素的影响。若相互依赖的变量间没有因果关系,则称其有相关关系。 4、多元线性回归模型随机干扰项的假定有哪些 (1)随机误差项的条件期望值为零。
(2)随机误差项的条件方差相同。 (3)随机误差项之间无序列相关。 (4)自变量与随机误差项独立无关。 (5)随机误差项服从正态分布。 ; (6)各解释变量之间不存在显著的线性相关关系。 5、简述选择解释变量的逐步回归法 逐步回归的基本思想是“有进有出”。 具体做法是将变量一个一个引入,引入变量的条件是t统计量经检验是显著的。即每引入一个自变量后,对已经被选入的变量要进行逐个检验,当原引入的变量由于后面变量的引入而变得不再显著时,要将其剔除。引入一个变量或从回归方程中剔除一个变量,为逐步回归的一步,每一步都要进行t检验,以确保每次引入新的变量之前回归方程中只包含显著的变量。 6、对于非线性模型如何进行参数估计 一、解释变量可以直接替换的非线性回归模型 1、多项式函数模型 (1)多项式函数形式 ! 令原模型可化为线性形式,即可利用多元线性回归分析的方法处理了。(2)利用Eviews应用软件进行回归分析 在主窗口的命令栏内,直接键入ls y c x x^2 x^3,回车即可得到输出结果 (3)利用SPSS应用软件进行回归分析 在SPSS中,依次点击Analyze / Regression / Curve Estimation,打开对话窗口。在Models 选项组中,共有11种曲线可供选择:Linear(直线)、Quadratic(二次曲线)、Compound (复合曲线)、Growth(增长曲线)、Logarithmic(对数曲线)、Cubic(三次曲线)、S(S 曲线)、Exponential(指数曲线)、Inverse(倒数曲线)、Power(Power曲线)、Logistic (逻辑斯蒂曲线)。 * 2、双曲线(倒数)模型 令原模型可化为线性形式,即可利用一元线性回归分析的方法处理。
计量经济学练习题 第一章导论 一、单项选择题 ⒈计量经济研究中常用的数据主要有两类:一类是时间序列数据,另一类是【 B 】 A 总量数据 B 横截面数据 C平均数据 D 相对数据 ⒉横截面数据是指【 A 】 A 同一时点上不同统计单位相同统计指标组成的数据 B 同一时点上相同统计单位相同统计指标组成的数据 C 同一时点上相同统计单位不同统计指标组成的数据 D 同一时点上不同统计单位不同统计指标组成的数据 ⒊下面属于截面数据的是【 D 】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C 某年某地区20个乡镇工业产值的合计数 D 某年某地区20个乡镇各镇工业产值 ⒋同一统计指标按时间顺序记录的数据列称为【 B 】 A 横截面数据 B 时间序列数据 C 修匀数据 D原始数据 ⒌回归分析中定义【 B 】 A 解释变量和被解释变量都是随机变量 B 解释变量为非随机变量,被解释变量为随机变量 C 解释变量和被解释变量都是非随机变量 D 解释变量为随机变量,被解释变量为非随机变量 二、填空题 ⒈计量经济学是经济学的一个分支学科,是对经济问题进行定量实证研究的技术、方法和相关理论,可以理解为数学、统计学和_经济学_三者的结合。
⒉现代计量经济学已经形成了包括单方程回归分析,联立方程组模型,时间序列分 析三大支柱。 ⒊经典计量经济学的最基本方法是回归分析。 计量经济分析的基本步骤是:理论(或假说)陈述、建立计量经济模型、收集数据、计量经济模型参数的估计、检验和模型修正、预测和政策分析。 ⒋常用的三类样本数据是截面数据、时间序列数据和面板数据。 ⒌经济变量间的关系有不相关关系、相关关系、因果关系、相互影响关系和恒 等关系。 三、简答题 ⒈什么是计量经济学它与统计学的关系是怎样的 计量经济学就是对经济规律进行数量实证研究,包括预测、检验等多方面的工作。计量经济学是一种定量分析,是以解释经济活动中客观存在的数量关系为内容的一门经济学学科。 计量经济学与统计学密切联系,如数据收集和处理、参数估计、计量分析方法设计,以及参数估计值、模型和预测结果可靠性和可信程度分析判断等。可以说,统计学的知识和方法不仅贯穿计量经济分析过程,而且现代统计学本身也与计量经济学有不少相似之处。例如,统计学也通过对经济数据的处理分析,得出经济问题的数字化特征和结论,也有对经济参数的估计和分析,也进行经济趋势的预测,并利用各种统计量对分析预测的结论进行判断和检验等,统计学的这些内容与计量经济学的内容都很相似。反过来,计量经济学也经常使用各种统计分析方法,筛选数据、选择变量和检验相关结论,统计分析是计量经济分析的重要内容和主要基础之一。 计量经济学与统计学的根本区别在于,计量经济学是问题导向和以经济模型为核心的,而统计学则是以经济数据为核心,且常常是数据导向的。典型的计量经济学分析从具体经济问题出发,先建立经济模型,参数估计、判断、调整和预测分析等都是以模型为基础和出发点;典型的统计学研究则并不一定需要从具体明确的问题出发,虽然也有一些目标,但可以是模糊不明确的。虽然统计学并不排斥经济理论和模型,有时也会利用它们,但统计学通常
《计量经济学》要点 一、单项选择题 知识点: 第一章 若干定义、概念 时间序列数据定义 横截面数据定义 1.同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据 B、时间序列数据 C、修匀数据 D、原始数据 2.同一时间,不同单位相同指标组成的观测数据称为( B ) A.原始数据B.横截面数据 C.时间序列数据D.修匀数据 变量定义(被解释变量、解释变量、内生变量、外生变量) 单方程中可以作为被解释变量的是(控制变量、内生变量、外生变量); 3.在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 什么是解释变量、被解释变量? 从变量的因果关系上,模型中变量可分为解释变量(Explanatory variable)和被解释变量(Explained variable)。 在模型中,解释变量是变动的原因,被解释变量是变动的结果。 被解释变量是模型要分析研究的对象,也常称为“应变量”(Dependent variable)、“回归子”(Regressand)等。 解释变量也常称为“自变量”(Independent variable)、“回归元”(Regressor)等,是说明应变量变动主要原因的变量。 因此,被解释变量只能由内生变量担任,不能由非内生变量担任。 4.单方程计量经济模型中可以作为被解释变量的是( C ) A、控制变量 B、前定变量 C、内生变量 D、外生变量 5.单方程计量经济模型的被解释变量是(A ) A、内生变量 B、政策变量 C、控制变量 D、外生变量 6.在回归分析中,下列有关解释变量和被解释变量的说法正确的有(C) A、被解释变量和解释变量均为随机变量 B、被解释变量和解释变量均为非随机变量 C、被解释变量为随机变量,解释变量为非随机 变量 D、被解释变量为非随机变量,解释变量为随机 变量 双对数模型中参数的含义; 7.双对数模型 01 ln ln ln Y X ββμ =++中,参数1 β的含义是(D ) A .X的相对变化,引起Y的期望值绝对量变化 B.Y关于X的边际变化 C.X的绝对量发生一定变动时,引起因变量Y 的相对变化率 D.Y关于X的弹性 8.双对数模型μ β β+ + =X Y ln ln ln 1 中,参数1 β的含义是( C ) A. Y关于X的增长率 B .Y关于X的发展速度 C. Y关于X的弹性 D. Y关于X 的边际变化 计量经济学研究方法一般步骤 四步12点 9.计量经济学的研究方法一般分为以下四个步骤( B ) A.确定科学的理论依据、模型设定、模型修定、模型应用 B.模型设定、估计参数、模型检验、模型应用C.搜集数据、模型设定、估计参数、预测检验D.模型设定、检验、结构分析、模型应用 对计量经济模型应当进行哪些方面的检验? 经济意义检验:检验模型估计结果,尤其是参数
计量经济学(第四版)习题参考答案 潘省初
第一章 绪论 1.1 试列出计量经济分析的主要步骤。 一般说来,计量经济分析按照以下步骤进行: (1)陈述理论(或假说) (2)建立计量经济模型 (3)收集数据 (4)估计参数 (5)假设检验 (6)预测和政策分析 1.2 计量经济模型中为何要包括扰动项? 为了使模型更现实,我们有必要在模型中引进扰动项u 来代表所有影响因变量的其它因素,这些因素包括相对而言不重要因而未被引入模型的变量,以及纯粹的随机因素。 1.3什么是时间序列和横截面数据? 试举例说明二者的区别。 时间序列数据是按时间周期(即按固定的时间间隔)收集的数据,如年度或季度的国民生产总值、就业、货币供给、财政赤字或某人一生中每年的收入都是时间序列的例子。 横截面数据是在同一时点收集的不同个体(如个人、公司、国家等)的数据。如人口普查数据、世界各国2000年国民生产总值、全班学生计量经济学成绩等都是横截面数据的例子。 1.4估计量和估计值有何区别? 估计量是指一个公式或方法,它告诉人们怎样用手中样本所提供的信息去估计总体参数。在一项应用中,依据估计量算出的一个具体的数值,称为估计值。如Y 就是一个估计量,1 n i i Y Y n == ∑。现有一样本,共4个数,100,104,96,130,则 根据这个样本的数据运用均值估计量得出的均值估计值为 5.1074 130 96104100=+++。 第二章 计量经济分析的统计学基础 2.1 略,参考教材。
2.2请用例2.2中的数据求北京男生平均身高的99%置信区间 N S S x = =45 =1.25 用α=0.05,N-1=15个自由度查表得005.0t =2.947,故99%置信限为 x S t X 005.0± =174±2.947×1.25=174±3.684 也就是说,根据样本,我们有99%的把握说,北京男高中生的平均身高在170.316至177.684厘米之间。 2.3 25个雇员的随机样本的平均周薪为130元,试问此样本是否取自一个均值为120元、标准差为10元的正态总体? 原假设 120:0=μH 备择假设 120:1≠μH 检验统计量 () 10/25X X μσ-Z == == 查表96.1025.0=Z 因为Z= 5 >96.1025.0=Z ,故拒绝原假设, 即 此样本不是取自一个均值为120元、标准差为10元的正态总体。 2.4 某月对零售商店的调查结果表明,市郊食品店的月平均销售额为2500元,在下一个月份中,取出16个这种食品店的一个样本,其月平均销售额为2600元,销售额的标准差为480元。试问能否得出结论,从上次调查以来,平均月销售额已经发生了变化? 原假设 : 2500:0=μH 备择假设 : 2500:1≠μH ()100/1200.83?X X t μσ-= === 查表得 131.2)116(025.0=-t 因为t = 0.83 < 131.2=c t , 故接受原假 设,即从上次调查以来,平均月销售额没有发生变化。
第十一章练习题及参考解答 11.1 考虑以下凯恩斯收入决定模型: βββββ-=++=+++=++1011120212212t t t t t t t t t t t C Y u I Y Y u Y C I G 其中,C =消费支出,I =投资指出,Y =收入,G =政府支出;t G 和1t Y -是前定变量。 (1)导出模型的简化型方程并判定上述方程中哪些是可识别的(恰好或过度)。 (2)你将用什么方法估计过度可识别方程和恰好可识别方程中的参数。 练习题11.1参考解答: 1011120212212112122112102012221112111211121112110111121(1)1 1111t t t t t t t t t t t t t t t t t t t t t t t Y C I G Y u Y Y u G Y Y Y G u u u u Y Y G Y G v βββββββββββββββββββπππ----=++=+++++++=++++++++=+++ --------=+++ 102012221011111121112111211121 1011211110201122 111211121 111211111211121101021112011 ()1111(1)()11()111t t t t t t t t t t t u u C Y G u Y u u G u βββββββββββββββββββββββββββββββββββββ--++=+++++----------++= ++ ----++++-----+=-11212111122111121112111211121 20211222111t t t t t t t t u u u Y G Y G v ββββββββββββπππ--+-+++-------=+++ 10201222202111121112111211121 2212201121211020212221 1112111211121 211222 111211121 1 () 1111(1)()111()11t t t t t t t t t t t t u u I Y G Y u Y G u u Y βββββββββββββββββββββββββββββββββββ----++=++++--------++--++= +++ ------++++----220201120211021202122211112111211121 211211222 1112111213031132311111t t t t t t t t t t u Y G u u u Y Y G v ββββββββββββββββββββββββπππ-----++=+++ ------+-++----=+++
计量经济学题库(超完整版)及答案 一、单项选择题(每小题1分) 1.计量经济学是下列哪门学科的分支学科(C )。 A .统计学 B .数学 C .经济学 D .数理统计学 2.计量经济学成为一门独立学科的标志是(B )。 A .1930年世界计量经济学会成立 B .1933年《计量经济学》会刊出版 C .1969年诺贝尔经济学奖设立 D .1926年计量经济学(Economics )一词构造出来3.外生变量和滞后变量统称为(D )。 A .控制变量 B .解释变量 C .被解释变量 D .前定变量 4.横截面数据是指(A )。 A .同一时点上不同统计单位相同统计指标组成的数据 B .同一时点上相同统计单位相同统计指标组成的数据 C .同一时点上相同统计单位不同统计指标组成的数据 D .同一时点上不同统计单位不同统计指标组成的数据 5.同一统计指标,同一统计单位按时间顺序记录形成的数据列是(C )。 A .时期数据 B .混合数据 C .时间序列数据 D .横截面数据 6.在计量经济模型中,由模型系统内部因素决定,表现为具有一定的概率分布的随机变量,其数值受模型中其他变量影响的变量是()。 A .内生变量 B .外生变量 C .滞后变量 D .前定变量 7.描述微观主体经济活动中的变量关系的计量经济模型是()。 A .微观计量经济模型 B .宏观计量经济模型 C .理论计量经济模型 D .应用计量经济模型 8.经济计量模型的被解释变量一定是()。 A .控制变量 B .政策变量 C .内生变量 D .外生变量 9.下面属于横截面数据的是()。 A .1991-2003年各年某地区20个乡镇企业的平均工业产值 B .1991-2003年各年某地区20个乡镇企业各镇的工业产值 C .某年某地区20个乡镇工业产值的合计数 D .某年某地区20个乡镇各镇的工业产值10.经济计量分析工作的基本步骤是()。 A .设定理论模型→收集样本资料→估计模型参数→检验模型 B .设定模型→估计参数→检验模型→应用模型 C .个体设计→总体估计→估计模型→应用模型 D .确定模型导向→确定变量及方程式→估计模型→应用模型 11.将内生变量的前期值作解释变量,这样的变量称为()。 A .虚拟变量 B .控制变量 C .政策变量 D .滞后变量 12.()是具有一定概率分布的随机变量,它的数值由模型本身决定。 A .外生变量 B .内生变量 C .前定变量 D .滞后变量 13.同一统计指标按时间顺序记录的数据列称为()。 A .横截面数据 B .时间序列数据 C .修匀数据 D .原始数据 14.计量经济模型的基本应用领域有()。 A .结构分析、经济预测、政策评价 B .弹性分析、乘数分析、政策模拟 C .消费需求分析、生产技术分析、 D .季度分析、年度分析、中长期分析 15.变量之间的关系可以分为两大类,它们是()。 A .函数关系与相关关系 B .线性相关关系和非线性相关关系
一、单项选择题 Ch1 : 1、相关关系是指【】 A变量间的严格的依存关系C变量间的函数关系 B变量间的因果关系 D变量间表现出来的随机数学关系 A B C D 2、横截面数据是指【】 同一时点上不同统计单位相同统计指标组成的数据同一时点上相同统计单位相同统计指标组成的数据同一时点上相同统计单位不同统计指标组成的数据同一时点上不同统计单位不同统计指标组成的数据 3、下面属于截面数据的是【】 A 1991-2003年各年某地区20个乡镇的平均工业产值 B 1991-2003年各年某地区20个乡镇的各镇工业产值 C某年某地区20个乡镇工业产值的合计数 D某年某地区20个乡镇各镇工业产值 4、同一统计指标按时间顺序记录的数据列称为【A 横截面数据B时间序列数据C修匀数据】 D原始数据 5、计量经济模型是指A投入产出模型 C包含随机方程的经济数学模型】 B数学规划模型D模糊数学模型 6、设C为消费,Y为收入水平,消费函数为: a应为正值,b应为负值B a应为负值,b应为负值D C= a+ bY+u,根据经济理论,有【: a 应为正值, a应为正值,b应为正值且大于1 b应为正值且小于1 7、回归分析中定义【】 A解释变量和被解释变量都是随机变量 B解释变量为非随机变量,被解释变量为随机变量C解释变量和被解释变量都是非随机变量D解释变量为随机变量,被解释变量为非随机变量 &在模型的经济意义检验中,不包括检验下面的哪一项【A参数估计量的符号B参数估计量的大小C参数估计量的相互关系D参数估计量的显著性 A Var( p )=0 Ch2: 9、参数3的估计量具备有效性是指【 】 B 为最小 10、产量(x,台)与单位产品成本(y,元/台)之间的回归方程为y= 356 —1.5x,这说明【】
Ch1 一、单选题 1-15 DBBCA CCCCD CCBBC 二、多选题 1、CD 2、AB 3、ABCD 4、ABCD 5、ABCD Ch2 一、 1-10 DBAAC CADAB 11-20 DCCAB BADCD 21-25 DCDCC 二、 1-5 ACD ABCDE ABE AC BE 6-10 CDE ABCDE CDE ABDE ABDE 11-17 ABCDE ABCDE ABCDE BCE ACDE BCD BC Ch3 1-10 DDCBA CCCBC 11-20 CDAAC DDABA 21-27 BDDBA AC Ch4 1-25 DCABC CADBB CBBED DACDA ACABC Ch5 1-23 ADAAD ABBAA BBADE BADBC ADA Ch6 1-25 DBADD ACDBB DBBDB EAAAC DDCDA Ch7 1-20 ADCBC BDCAC ADDDD BADBC 21-22 ABCD ABC Ch8 1-20 ABBBB CBBDA BCAAA CBBBD 21-22 ABCD BCE Ch9 1-15 DDCDA BBAAA CCADB Ch10 1-14 ABCAD ADABC ADDD Ch11 1-14 DBBAB ADBCB BADD 15-18 ABCD ABCDE ABCD ACDE 一、计算题 1、(1)
(2)可决系数为:R 2=ESS/TSS=35965/36042=0.99786 修正的可决系数: 997507.0360427731511512=?--- =-R (3)322.2802417 .65.17982==F 可得F>89.3=αF 这说明两个解释变量 2X 和.3X 联合起来对被解释变量有很显著的影响,但是还不能确定两个解释变量2X 和.3X 各自对Y 都有显著影响。 2、( (2) 982.038.10858.1062=== TSS ESS R 980.01719)982.01(11)1(122=--=----=k n n R R (3)可以利用F 统计量检验2X 和3X 对Y 的联合影响。 736.502106.029.5317/2/===RSS ESS F (或 )/()1()1/(22k n R k R F ---=) 因为45.4=>αF F ,2X 和3X 对Y 的联合影响是显著的。 3、(1)2321946.80.7096453670 ESS R TSS = == (2)221141(1)1(10.7096)0.630411n R R n k -=--=--=- (3)?109.4296σ=== (4)/(1)107315.68.9618/()11974.84 ESS k F RSS n k -===- 4、(1)因为总变差的自由度为12=n-1,所以样本容量:n=12+1=13 因为 TSS=RSS+ESS 残差平方和RSS=TSS-ESS=382-365=17 回归平方和的自由度为:k-1=3-1=2 残差平方和RSS 的自由度为:n-k=13-3=10 (2)可决系数为:R 2=ESS/TSS=365/382=0.9555
期中练习题 1、回归分析中使用的距离是点到直线的垂直坐标距离。最小二乘准则是指( ) A .使∑=-n t t t Y Y 1)?(达到最小值 B.使∑=-n t t t Y Y 1达到最小值 C. 使 ∑=-n t t t Y Y 1 2 ) (达到最小值 D.使 ∑=-n t t t Y Y 1 2)?(达到最小值 2、根据样本资料估计得出人均消费支出 Y 对人均收入 X 的回归模型为 ?ln 2.00.75ln i i Y X =+,这表明人均收入每增加 1%,人均消费支出将增加 ( ) A. 0.75 B. 0.75% C. 2 D. 7.5% 3、设k 为回归模型中的参数个数,n 为样本容量。则对总体回归模型进行显著性检验的F 统计量与可决系数2 R 之间的关系为( ) A.)1/()1()/(R 2 2---=k R k n F B. )/(1)-(k )R 1/(R 22k n F --= C. )/()1(22k n R R F --= D. ) 1()1/(22R k R F --= 6、二元线性回归分析中 TSS=RSS+ESS 。则 RSS 的自由度为( ) A.1 B.n-2 C.2 D.n-3 9、已知五个解释变量线形回归模型估计的残差平方和为 8002=∑t e ,样本容量为46,则随机误 差项μ的方差估计量2 ?σ 为( ) A.33.33 B.40 C.38.09 D. 20 1、经典线性回归模型运用普通最小二乘法估计参数时,下列哪些假定是正确的( ) A.0)E(u i = B. 2i )Var(u i σ= C. 0)u E(u j i ≠ D.随机解释变量X 与随机误差i u 不相关 E. i u ~),0(2i N σ 2、对于二元样本回归模型i i i i e X X Y +++=2211???ββα,下列各式成立的有( ) A.0 =∑i e B. 0 1=∑i i X e C. 0 2=∑i i X e D. =∑i i Y e E. 21=∑i i X X 4、能够检验多重共线性的方法有( ) A.简单相关系数矩阵法 B. t 检验与F 检验综合判断法 C. DW 检验法 D.ARCH 检验法 E.辅助回归法
第一章绪论复习题 二、选择题 2、在同一时间不同统计单位的相同统计指标组成的数据组合,是(D ) A、原始数据 B、时点数据 C、时间序列数据 D、截面数据 3、计量经济模型的被解释变量一定是(C ) A、控制变量 B、政策变量 C、内生变量 D、外生变量 4、在一个计量经济模型中可作为结实变量的有( D ) A、政策变量 B、控制变量 C、内生变量 D、外生变量 E、滞后变量 5、下列模型中属于线性模型的有( B ) 6、同一统计指标按时间顺序记录的数据称为( B )。 A、横截面数据 B、时间序列数据 C、修匀数据 D、原始数据 7、模型中其数值由模型本身决定的变量是( B ) A、外生变量 B、内生变量 C、前定变量 D、滞后变量 11、在回归分析中,下列有关解释变量和被解释变量的说法正确的有( C ) A.被解释变量和解释变量均为随机变量 B.被解释变量和解释变量均为非随机变量C.被解释变量为随机变量,解释变量为非随机变量 D.被解释变量为非随机变量,解释变量为随机变量 一、单项选择题 1、将内生变量的前期值作解释变量,这样的变量称为( D )。 A.虚拟变量 B. 控制变量 C.政策变量 D. 滞后变量 2、把反映某一总体特征的同一指标的数据,按一定的时间顺序和时间间隔排列起来,这样的数据称为( B )。 A.横截面数据 B. 时间序列数据 C.修匀数据 D. 原始数据 3、在简单线性回归模型中,认为具有一定概率分布的随机数量是( A )。 A.内生变量 B. 外生变量 C.虚拟变量 D. 前定变量 9、同一时间,不同单位相同指标组成的观测数据称为( B )。 A.原始数据 B. 横截面数据 C.时间序列数据 D. 修匀数据 A.解释变量X1t对Yt的影响是显著的 B.解释变量X2t对Yt的影响是显著的 C.解释变量X1t和X2t对Yt的联合影响是显著的 D.解释变量X1t和X2t对Yt的影响是均
第一章绪论 一、填空题: 1.计量经济学是以揭示经济活动中客观存在的__________为内容的分支学科,挪威经济学家弗里希,将计量经济学定义为__________、__________、__________三者的结合。 2.数理经济模型揭示经济活动中各个因素之间的__________关系,用__________性的数学方程加以描述,计量经济模型揭示经济活动中各因素之间__________的关系,用__________性的数学方程加以描述。 3.经济数学模型是用__________描述经济活动。 4.计量经济学根据研究对象和内容侧重面不同,可以分为__________计量经济学和__________计量经济学。 5.计量经济学模型包括__________和__________两大类。 6.建模过程中理论模型的设计主要包括三部分工作,即__________、____________________、____________________。 7.确定理论模型中所包含的变量,主要指确定__________。 8.可以作为解释变量的几类变量有__________变量、__________变量、__________变量和__________变量。 9.选择模型数学形式的主要依据是__________。 10.研究经济问题时,一般要处理三种类型的数据:__________数据、__________数据和__________数据。 11.样本数据的质量包括四个方面__________、__________、__________、__________。 12.模型参数的估计包括__________、__________和软件的应用等内容。 13.计量经济学模型用于预测前必须通过的检验分别是__________检验、__________检验、__________检验和__________检验。 14.计量经济模型的计量经济检验通常包括随机误差项的__________检验、__________检验、解释变量的__________检验。 15.计量经济学模型的应用可以概括为四个方面,即__________、__________、__________、__________。 16.结构分析所采用的主要方法是__________、__________和__________。 二、单选题: 1.计量经济学是一门()学科。 A.数学 B.经济