快速获取汉字任意输入码的方法与实现
- 格式:pdf
- 大小:89.33 KB
- 文档页数:3

获取汉字首字母的函数获取汉字首字母的函数是一种非常常见的需求,尤其是在中文搜索和排序等场景中。
在这篇文章中,我们将介绍几种获取汉字首字母的函数,并对它们的优缺点进行比较。
方法一:使用Unicode编码Unicode编码是一种国际标准,它为世界上所有的字符都分配了一个唯一的编码。
在Unicode编码中,每个汉字都有一个唯一的编码,因此我们可以通过获取汉字的Unicode编码来获取它的首字母。
具体实现方法如下:```pythondef get_first_letter(string):letter = ''for s in string:if '\u4e00' <= s <= '\u9fff':letter += chr(ord('a') + ord(s) - ord('\u4e00'))else:letter += sreturn letter```这个函数的实现方法非常简单,它遍历了字符串中的每个字符,如果是汉字,则将它的Unicode编码转换为对应的小写字母,否则直接将字符添加到结果中。
这种方法的优点是实现简单,而且可以处理任何汉字,缺点是它只能处理汉字,对于其他字符无法处理。
方法二:使用拼音库拼音库是一种将汉字转换为拼音的工具库,它可以将汉字转换为拼音,并且可以获取拼音的首字母。
因此,我们可以使用拼音库来获取汉字的首字母。
具体实现方法如下:```pythonimport pypinyindef get_first_letter(string):letter = ''for s in string:if '\u4e00' <= s <= '\u9fff':letter += zy_pinyin(s)[0][0]else:letter += sreturn letter```这个函数的实现方法比较简单,它使用了拼音库中的lazy_pinyin函数将汉字转换为拼音,并且获取拼音的首字母。

用ALT键加小键盘数字键输入文字--汉字编码经常在论坛里见到,按住Alt键,在用小键盘输入某某数字,就出来一个什么什么难写的字。
实在是看得太多了,这里给大家讲讲原理。
首先说说汉字的几种编码。
计算机处理汉字信息的前提条件是对每个汉字进行编码,这些编码统称为汉字编码。
其实就是用一个数字和一个汉字进行一一对应。
计算机内常用的编码有国标码,区位码和机内码。
国标码是一个四位十六进制数,它将一个汉字用两个字节表示,每个字节只有7位,与ASCII码相似。
区位码一个四位的十进制数,它将GB 2312—80的全部字符集组成一个94×94的方阵,每一行称为一个“区”,编号为01~94;每一列称为一个“位”,编号为01~94,这样得到GB 2312—80的区位图,用区位图的位置来表示的汉字编码,称为区位码。
机内码:为了避免ASCII码和国标码同时使用时产生二义性问题,大部分汉字系统都采用将国标码每个字节高位置1作为汉字机内码。
这样既解决了汉字机内码与西文机内码之间的二义性,又使汉字机内码与国标码具有极简单的对应关系。
汉字机内码、国标码和区位码三者之间的关系为:区位码(十进制)的两个字节分别转换为十六进制后加20H 得到对应的国标码;机内码是汉字交换码(国标码)两个字节的最高位分别加1,即汉字交换码(国标码)的两个字节分别加80H得到对应的机内码;区位码(十进制)的两个字节分别转换为十六进制后加A0H得到对应的机内码。
再回到用Alt键输入的问题。
实际上,按住Alt键,然后用小键盘敲入一串数字,就是输入了某个字的“机内码”。
比如,“喆”这个字的机内码为86B4(16进制),转换为10进制就是34484,因此大家按住Alt键,然后用小键盘输入34484,就可以出来“喆”字了。
最后,由于汉字和机内码是一一对应的,所以只要知道了机内码,任意一个汉字都可以用这种方式输入的。
除此之外,还有大量的符号,比如论坛里已经发了N次的心形符号,也是通过这个原理输入的。

五笔汉字输入方法五笔输入法是一种汉字输入方法,其原理是将汉字按照字根的部首以及笔画的顺序进行编码,通过输入这些编码来实现汉字的输入。
下面我将详细介绍五笔汉字输入方法。
五笔输入法是由中国台湾地区的铃木贤治先生于1980年代发明的。
其原理是根据汉字笔画的形状和构造,将所有汉字按照字根的部首以及笔画的顺序进行编码。
每一个汉字都有一个唯一的编码,通过输入这个编码,计算机能够识别出对应的汉字。
五笔码的基本单位是字根,字根是汉字的最小构成部分,它是组成汉字的基本形状。
每个字根都有一个唯一的编码,使用字根编码可以输入所有的字根。
字根的编码一般由两个部分组成:一个是字根的声母,另一个是字根的部首。
五笔码输入的第一步是选择字根的声母。
声母是字根所属的音节,通过选择声母可以缩小汉字的范围。
声母的编码通常是由字母和数字组成,每个声母都有一个唯一的编码。
选择声母后,计算机会显示出符合条件的字根列表供用户选择。
选择字根的部首是五笔码输入的第二步。
字根的部首是字根的构成部分,通过选择部首可以进一步缩小汉字的范围。
部首的编码一般由一个或多个符号组成,每个部首都有一个唯一的编码。
选择部首后,计算机会显示出符合条件的字根列表供用户选择。
选择字根之后,需要通过输入字根的笔画顺序来确定具体的汉字。
每个字根都有一个笔画顺序,根据这个笔画顺序输入可以得到对应的汉字。
五笔码中,每个字根的笔画都有一个唯一的数字编码,根据这个编码来输入笔画顺序。
输入笔画顺序时,可以使用数字键盘上的数字键或者字母键盘上的字母键。
除了字根以外,五笔输入法还提供了一些特殊的编码方式。
比如,一些常用的词语可以用特殊的编码来输入,这样可以提高输入速度。
此外,五笔输入法还提供了一些短语、句子的编码方式,用户可以通过输入这些编码来输入整个词语、短语或句子。
五笔输入法具有输入速度快、输入准确度高的特点。
由于每个汉字都有一个唯一的编码,不同的汉字之间没有重码的情况,因此可以避免一些拼音输入法中常见的重码问题。


使用正则表达式提取汉字在中文文本处理中,经常需要提取出其中的汉字。
使用正则表达式可以轻松实现这个功能。
首先,需要了解汉字的 Unicode 编码范围。
汉字的 Unicode 编码范围为 u4e00 到 u9fff。
因此,可以使用正则表达式[u4e00-u9fff]+ 来匹配一个或多个汉字。
下面是一个 Python 的示例代码,演示了如何使用正则表达式提取汉字。
```pythonimport retext = '这是一段中文文本,里面包含了一些汉字。
'pattern = '[u4e00-u9fff]+'result = re.findall(pattern, text)print(result)```输出结果为:```['这是一段中文文本', '里面包含了一些汉字']```可以看到,使用正则表达式成功提取出了文本中的汉字。
除了使用 Unicode 范围来匹配汉字,还可以使用 Unicode 字符属性。
例如,可以使用 p{Han} 来匹配汉字。
以下是示例代码:```pythonimport retext = '这是一段中文文本,里面包含了一些汉字。
'pattern = 'p{Han}+'result = re.findall(pattern, text, flags=re.UNICODE)print(result)```输出结果与上面的示例相同。
使用正则表达式提取汉字可以方便地处理中文文本。
在实际应用中,还可以结合分词等技术进一步处理。

汉字数符编码输入方法《汉字数符编码输入方法:改善文本输入效率的艺术》汉字数字编码输入方法汉字数字编码输入法是一种可以让用户快速输入和查找特定汉字的方法。
它能够通过数字、字母或其他图形符号快速输入汉字,并通过人机交互,帮助用户完成汉字输入。
一、历史沿革汉字数字编码输入技术可以追溯到1972年英国Loxity公司推出的FangXiang(方象)汉字输入法。
许多欧美专利使用了形似字法,将汉字的笔画转化为一系列的字母数字符号,进而输入汉字。
形似字输入法因其可以准确定位字形而深受欢迎,但仍有许多不足之处,如无法实现常用词缩写等。
此后,许多改进版本的汉字数字编码输入方法出现,如号码查字、微声输入、补全输入等,并受到广泛应用。
二、常用汉字数字编码输入方法1. 拼音输入法拼音输入法是常用的汉字数字编码输入方法。
它是通过输入汉字的拼音音节(或输入汉语拼音的缩写)来完成汉字输入的一种方法,是基于字母编码实现汉字输入的技术,可以非常简便的输入汉字。
2. 手写输入法手写输入法是使用特定键盘某种触摸笔进行演示,在手机或其他指定设备上将汉字输入系统通过触摸形式进行输入。
3. 补全输入法补全输入法是利用软件算法,在用户输入部分汉字时,该方法能够根据用户输入的笔画数和字形建议补全汉字输入,省去用户辛苦的输入过程。
4. 中文语音输入法中文语音输入法是通过用户发出声音来完成汉字输入的方法。
它可以准确的捕捉用户的语音,再根据汉字的读音进行汉字输入。
三、汉字数字编码输入技术的优势汉字数字编码输入技术的优势在于准确性。
由于不同语言不同习惯会对汉字拼音读音习惯产生差异,不同歧义也会影响汉字的输入,而汉字数字编码技术可以通过唯一的笔画配制将汉字准确的输入,满足用户不同对汉字编码需求。
另外,随着技术的不断更新,汉字数字编码输入技术也逐渐的进步,加速汉字数字输入的速度,满足用户的字输入需求。
四、汉字数字编码输入技术的发展趋势随着技术的不断发展,汉字数字编码输入技术也在不断提高。


五笔输入法(版)教程一、五笔输入法简介五笔输入法是一种基于汉字结构进行编码的输入方法,由王永民教授于1983年发明。
版五笔输入法因其发明时间为19年而得名,是目前最流行的五笔输入法版本之一。
它通过将汉字拆分成笔画和字根,然后将这些字根对应到键盘上的特定字母,实现了快速、高效的汉字输入。
二、五笔输入法的特点1. 重码率低:五笔输入法的编码规则独特,每个汉字都有唯一的编码,因此在输入过程中重码率极低,提高了输入速度。
2. 输入速度快:熟练掌握五笔输入法后,输入速度可达到每分钟上百字,非常适合专业打字员和文字工作者。
3. 适合盲打:五笔输入法的键位布局合理,有助于实现盲打,即在不看键盘的情况下快速输入。
三、五笔输入法的基本原理1. 汉字结构分析:五笔输入法将汉字分为笔画、字根和整字三个层次。
笔画是构成汉字的最基本元素,字根是由笔画组成的具有独立意义的汉字部分,整字则是由一个或多个字根组成的完整汉字。
2. 字根分类:五笔输入法将所有汉字字根分为五大类,分别对应键盘上的五个区域,每个区域包含五个字母键。
3. 编码规则:五笔输入法的编码规则是将汉字拆分成字根,然后将这些字根对应的字母组合起来,形成该汉字的五笔编码。
四、五笔输入法的键盘布局1. 键盘分区:五笔输入法将键盘分为五个区域,分别是横区、竖区、撇区、捺区和折区。
2. 字母键对应字根:每个区域的字母键分别对应不同的字根。
例如,横区的第一个字母键“G”对应字根“一”,第二个字母键“F”对应字根“丨”,以此类推。
3. 键位助记:为了方便记忆,每个字母键上的字根都有相应的助记词。
例如,横区的“G”键上的字根“一”可以助记为“工人”。
五、五笔输入法的学习方法1. 记忆字根:学习五笔输入法的第一步是记忆字根及其对应的键盘字母。
建议通过字根表进行学习,将每个字根与键盘上的字母键对应起来。
2. 练习拆字:掌握字根后,要学会将汉字拆分成字根。
可以通过练习拆字软件或查阅五笔拆字字典来提高拆字能力。

提取一串字符串中的数字和字母是在日常生活和工作中经常会遇到的需求,尤其在数据处理、文本处理、编程等领域中,提取数字和字母是一项基本且重要的操作。
为了方便快捷地实现这一目标,我们可以借助一些快捷键和工具来提高工作效率。
在文本编辑器中,我们经常需要从一串字符串中提取数字和字母。
以下是一些常见的快捷键和技巧:1. 使用Ctrl + F快捷键进行查找和替换操作。
在大部分文本编辑器中,Ctrl + F可以打开查找和替换功能,我们可以在查找框中输入正则表达式来匹配数字和字母,然后通过替换功能将其提取出来。
我们可以使用\d来匹配数字,使用\w来匹配字母,在替换框中输入$1可以提取出匹配的内容。
2. 使用正则表达式进行提取。
正则表达式是一种强大的文本匹配工具,我们可以通过编写简单的正则表达式来实现对数字和字母的提取。
使用\d+可以匹配一个或多个数字,使用\w+可以匹配一个或多个字母。
3. 使用专业的文本处理工具进行提取。
除了文本编辑器外,还有许多专业的文本处理工具可以帮助我们快速提取数字和字母。
Sublime Text、Notepad++、Visual Studio Code等工具提供了丰富的文本处理功能,可以通过快捷键或插件来实现快速提取数字和字母。
在编程领域,提取数字和字母同样是一项常见的操作。
以下是一些常见的快捷键和技巧:1. 使用正则表达式进行匹配和提取。
在编程中,我们经常会使用正则表达式来进行文本匹配和提取操作。
许多编程语言都提供了对正则表达式的支持,我们可以通过编写简单的正则表达式来实现对数字和字母的提取。
2. 使用字符串处理函数进行提取。
许多编程语言提供了丰富的字符串处理函数,包括对字符串的查找、替换、分割等操作。
我们可以通过调用这些函数来实现对数字和字母的提取。
除了常见的快捷键和技巧外,我们还可以借助一些工具来实现快速提取数字和字母。
以下是一些常见的工具和库:1. 使用Python中的re库进行正则表达式匹配。

一、实验目的1. 理解汉字编码的基本概念和原理;2. 掌握汉字编码的方法和过程;3. 熟悉汉字编码在实际应用中的重要性。
二、实验原理汉字编码是将汉字转换为计算机可识别的二进制代码的过程。
汉字编码的主要方法有区位码、国标码、机内码等。
1. 区位码:将汉字分为94个区,每个区包含94个位,区号和位号组成区位码。
2. 国标码:国标码是区位码的另一种表现形式,将汉字、图形符号组成一个94×94的方阵,每个汉字和图形符号占一个位置。
3. 机内码:机内码是计算机内部处理汉字时使用的编码,通常以国标码为基础,通过将每个字节的最高位加1得到。
三、实验内容1. 汉字国标码转区位码实验(1)设计要求:将汉字国标码转换为区位码。
(2)方案设计:① 设计思路:根据国标码的编码规则,通过计算得到区位码。
② 设计原理:将国标码的两个字节分别转换为十进制数,然后根据国标码的编码规则计算出区位码。
(3)实验步骤:① 在logisim软件中搭建电路,包括加法器、求补器等。
② 输入汉字国标码,通过电路计算得到区位码。
2. 汉字机内码获取实验(1)设计要求:将汉字国标码转换为机内码。
(2)方案设计:① 设计思路:根据国标码的编码规则,将每个字节的最高位加1得到机内码。
② 设计原理:将国标码的两个字节分别转换为十进制数,然后将每个字节的最高位加1得到机内码。
(3)实验步骤:① 在logisim软件中搭建电路,包括加法器、求补器等。
② 输入汉字国标码,通过电路计算得到机内码。
3. 海明编码电路设计与海明解码(1)设计要求:设计海明编码电路,实现海明编码和海明解码。
(2)方案设计:① 设计思路:根据海明编码的原理,设计电路实现编码和解码过程。
② 设计原理:海明编码是一种线性分组码,通过在数据中插入冗余位,实现对数据的纠错。
(3)实验步骤:① 在logisim软件中搭建电路,包括加法器、与门、或门等。
② 输入数据,通过电路实现海明编码和解码。
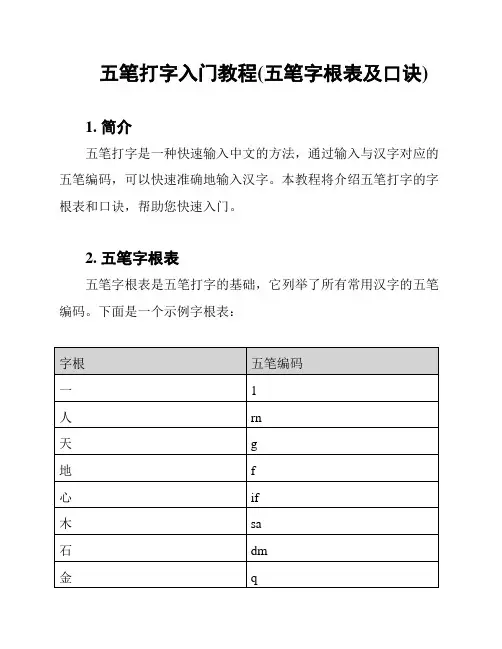
五笔打字入门教程(五笔字根表及口诀)1. 简介五笔打字是一种快速输入中文的方法,通过输入与汉字对应的五笔编码,可以快速准确地输入汉字。
本教程将介绍五笔打字的字根表和口诀,帮助您快速入门。
2. 五笔字根表五笔字根表是五笔打字的基础,它列举了所有常用汉字的五笔编码。
下面是一个示例字根表:每个字根对应一个五笔编码,通过组合字根的编码,可以输入相应的汉字。
3. 口诀五笔打字的口诀是帮助记忆字根编码的助记词或句子。
口诀可以根据个人喜好进行自定义,下面是一个示例口诀:1. 一对二,人人之间。
2. 天上天下,天地一家。
3. 心中有我,I love you。
4. 木立石头,大山托住。
5. 金鸡独立,门前流水。
6. 火红的天空,气温很高。
7. ...您可以根据口诀的内容编写自己的口诀,通过口诀记忆字根编码,提高打字速度。
4. 使用方法使用五笔打字的方法很简单:1. 找到要输入的汉字对应的字根编码。
2. 根据字根编码,在键盘上找到对应的按键。
3. 连续按下字根的对应按键。
4. 输入完所有字根后,按下空格键确定输入的汉字。
举个例子,如果要输入汉字"人",根据字根表可以知道它的五笔编码是"rn"。
那么在打字时,按下键盘上的"r"和"n"按键,然后按下空格键,即可输入汉字"人"。
5. 练与提高五笔打字需要一定的练和熟练度才能提高打字速度。
以下是一些提高五笔打字的方法:- 多做练,逐渐熟悉字根的位置和对应的编码。
- 利用在线打字练软件进行训练,提高打字准确性和速度。
- 多与其他五笔打字用户交流,分享经验和技巧。
通过持续的练和实践,您将能够在五笔打字方面取得进步,提高工作和研究效率。
结论五笔打字是一种快速输入中文的方法,通过字根表和口诀的帮助,您可以快速入门并提高打字速度。
持续练习和实践将使您在五笔打字方面成为专家。
祝您使用五笔打字更加顺利!。
汉字助记码,你会了吗?在编程中,我们经常会遇到汉字助记码的问题,笔者曾经为此多次发愁,现总结前辈的好东西,记录于此,希望能帮助到您,⽅法有多种,在此⽐较⼏种⽅案,简单剖析⼀下。
⾸先说明,什么是汉字助记码?所谓的汉字助记码就是⼀个汉字的拼⾳的⾸字母,如:张的汉字助记码为Z,湖北中医药⼤学的助记码为HBZYYDX。
下⾯通过程序⽤三种⽅法实现:⽅法⼀:表获取⽅法;表内容⼤致说明:实现核⼼代码——SQL标量值函数:1 ------------------------------------------------2 --作者:zhangbc3 --时间:2014-05-054 --功能:获取汉字拼⾳⾸字母5 ------------------------------------------------6 ALTER function [dbo].[fun_getMnemonic](@str nvarchar(4000))7 returns nvarchar(4000)8 as9 begin10 declare @zjm varchar(100),@tmp_char varchar(2),@tmp_zjm varchar(2), @i int,@length int11 set @zjm =''12 set @length = len(@str)13 set @i = 114 while @i<=@length15 begin16 set @tmp_char = substring(@str,@i,1)17 select @tmp_zjm =zjm from hz_zjm where hanzi=@tmp_char18 if @@rowcount=119 set @zjm = @zjm +Rtrim(@tmp_zjm)20 set @i = @i + 121 end22 return (@zjm)23 endView Code⽅法⼆:存储过程获取;实现核⼼代码——SQL存储过程:1 -- =============================================2 -- Author: zhangbc3 -- Create date: 2014-05-034 -- Description: 获取汉字拼⾳⾸字母5 -- =============================================6 ALTER PROCEDURE [dbo].[getMnemonic]7 @str varchar(4000)8 AS9 -- return char(4000)10 BEGIN11 declare @word nchar(1),@PY nvarchar(4000)12 set @PY=''13 while len(@str)>014 begin15 set @word=left(@str,1)16 --如果⾮汉字字符,返回原字符17 set @PY=@PY+(case when unicode(@word) between 19968 and 19968+2090118 then (select top 1 PY from (19 select 'A' as PY,N'驁' as word20 union all select 'B',N'簿'21 union all select 'C',N'錯'22 union all select 'D',N'鵽'23 union all select 'E',N'樲'28 union all select 'K',N'穒'29 union all select 'L',N'鱳'30 union all select 'M',N'旀'31 union all select 'N',N'桛'32 union all select 'O',N'漚'33 union all select 'P',N'曝'34 union all select 'Q',N'囕'35 union all select 'R',N'鶸'36 union all select 'S',N'蜶'37 union all select 'T',N'籜'38 union all select 'W',N'鶩'39 union all select 'X',N'鑂'40 union all select 'Y',N'韻'41 union all select 'Z',N'咗'42 ) T43 where word>=@word collate Chinese_PRC_CS_AS_KS_WS44 order by PY ASC) else @word end)45 set @str=right(@str,len(@str)-1)46 end47 select @PY48 ENDView Code⽅法三:标量值获取(算法和⽅法⼆⼀样,实现⽅式不同):代码如下:1 ------------------------------------------------2 --作者:zhangbc3 --时间:2014-03-194 --功能:获取汉字拼⾳⾸字母5 ------------------------------------------------6 ALTER function [dbo].[fun_getZjm](@str nvarchar(4000))7 returns nvarchar(4000)8 as9 begin10 declare @word nchar(1),@PY nvarchar(4000)11 set @PY=''12 while len(@str)>013 begin14 set @word=left(@str,1)15 --如果⾮汉字字符,返回原字符16 set @PY=@PY+(case when unicode(@word) between 19968 and 19968+2090117 then (select top 1 PY from (18 select 'A' as PY,N'驁' as word19 union all select 'B',N'簿'20 union all select 'C',N'錯'21 union all select 'D',N'鵽'22 union all select 'E',N'樲'23 union all select 'F',N'鰒'24 union all select 'G',N'腂'25 union all select 'H',N'夻'26 union all select 'J',N'攈'27 union all select 'K',N'穒'28 union all select 'L',N'鱳'29 union all select 'M',N'旀'30 union all select 'N',N'桛'31 union all select 'O',N'漚'32 union all select 'P',N'曝'33 union all select 'Q',N'囕'34 union all select 'R',N'鶸'35 union all select 'S',N'蜶'36 union all select 'T',N'籜'41 ) T42 where word>=@word collate Chinese_PRC_CS_AS_KS_WS43 order by PY ASC) else @word end)44 set @str=right(@str,len(@str)-1)45 end46 return @PY47 endView Code⽅法四:字符编码法;核⼼代码如下:1 public class getMnemonic2 {3 public getMnemonic()4 {56 }7 /// <summary>8 /// 字符编码的获取9 /// </summary>10 /// <param name="cnChar">字符</param>11 /// <returns>字符编码</returns>12 private static string getSpell(string cnChar)13 {14 byte[] arrCN = Encoding.Default.GetBytes(cnChar);15 if (arrCN.Length > 1)16 {17 int area = (short)arrCN[0];18 int pos = (short)arrCN[1];19 int code = (area << 8) + pos;20 int[] areacode = { 45217, 45253, 45761, 46318, 46826, 47010, 47297, 47614,21 48119, 48119, 49062, 49324, 49896,50371, 50614, 50622,22 50906, 51387, 51446, 52218, 52698, 52698, 52698, 52980, 53689, 54481 };23 for (int i = 0; i < 26; i++)24 {25 int max = 55290;26 if (i != 25)27 max = areacode[i + 1];28 if (areacode[i] <= code && code < max)29 return Encoding.Default.GetString(new byte[] { (byte)(65 + i)});30 }31 return "*";32 }33 else return cnChar;34 }35 /// <summary>36 /// 字符编码获取助记码37 /// </summary>38 /// <param name="str">汉字</param>39 /// <returns>助记码</returns>40 public string getChsSpell(string str)41 {42 string myStr = "";43 for (int i = 0; i < str.Length; i++)44 {45 myStr += getSpell(str.Substring(i, 1));46 }47 return myStr;48 }49 }View Code测试结果如下:图1-1图1-2图1-3图1-4⼩结:通过测试结果来看,字符编码(⽅法四)还是有点不完美,其实通过表获取的⽅法(⽅法⼀)也存在不⾜,汉字存储太少。
汉字的数字编码1. 汉字的数字编码简介1.1 什么是汉字的数字编码汉字的数字编码是将汉字用数字表示的一种方法。
由于汉字数量众多,人们需要一种简便的方式来进行输入、存储和传递。
汉字的数字编码通过将每个汉字映射到一个唯一的数字码来实现此目的。
1.2 为什么需要汉字的数字编码在计算机时代,使用汉字的数字编码可以方便地对汉字进行处理。
无论是在文本输入、搜索引擎、数据库存储还是机器翻译等领域,汉字的数字编码都发挥着重要的作用。
此外,汉字的数字编码也可以用于编写汉字排序规则、汉字输入法等。
2. 汉字的数字编码方法2.1 国际标准汉字编码(GBK)国际标准汉字编码(GBK)是中国自主发展的一种汉字编码系统。
它采用双字节表示每个汉字,其中第一个字节的范围是0xB0-0xF7,第二个字节的范围是0xA1-0xFE。
通过两个字节的组合,可以对21,334个常用汉字进行编码。
2.2 拼音首字母编码拼音首字母编码是将汉字的拼音首字母映射到一个唯一的编码。
常用的拼音首字母编码系统有多种,如郑码、拼音码等。
这种编码方法适用于对汉字进行首字母检索和排序,但无法直接识别汉字。
2.3 汉字的部首笔画编码汉字的部首笔画编码是根据汉字的偏旁部首和笔画数进行编码的方式。
部首笔画编码系统有多个版本,如康熙字典部首笔画查询法、四角号码法等。
这种编码方法适用于对汉字进行部首分析和笔画排序。
3. 汉字的数字编码的应用3.1 汉字输入法汉字输入法是将拼音或者汉字的部首和笔画输入转换为相应的汉字。
通过汉字的数字编码,输入法可以将用户输入的拼音或者部首笔画与汉字的编码进行匹配,从而提供候选词供用户选择。
3.2 汉字排序汉字的数字编码为汉字排序提供了便利。
通过将汉字转换为数字编码,可以对汉字进行快速的排序和查询。
这在字典、电话簿等场景中特别有用。
3.3 机器翻译在机器翻译中,汉字的数字编码可以被用来匹配对应的词汇或短语。
通过将汉字的数字编码作为词典的索引,机器可以根据输入的编码来查询并生成对应的翻译结果。