基因定位的遗传实验设计与分析
- 格式:ppt
- 大小:1.06 MB
- 文档页数:18

正向遗传学定位基因文献正向遗传学定位基因文献在现代医学领域中,有很多疾病都是由基因突变或者基因组变异引起的。
这些基因突变或者基因组变异会导致身体出现某种异常现象,从而引起相应的疾病。
因此,寻找这些基因突变或者基因组变异,对于研究疾病的发生、预测、干预和治疗具有极其重要的意义。
正向遗传学是一种新兴的遗传学研究方法,它可以对人类基因组进行全面系统的突变分析,评估对疾病易感性的影响,从而为疾病的预测和治疗提供有价值的信息。
正向遗传学的核心思想是将人类基因组的整个区域进行扫描,寻找与疾病发生相关的基因,从而发现疾病的致病基因。
目前,正向遗传学定位基因的研究已经涵盖了多个疾病,例如自闭症、帕金森病、多发性硬化症等等。
下面,我们将以自闭症为例,介绍正向遗传学定位基因研究的基本流程和一些有代表性的文献。
正向遗传学定位基因研究的基本流程自闭症是一种神经发育失调疾病,该病主要由基因突变和基因组变异引起。
正向遗传学分析可以帮助寻找与自闭症发生相关的基因。
正向遗传学定位基因研究的基本流程如下:1. 设计研究方案:确定研究的对象、样本数量、实验流程等重要因素。
2. 提取DNA:将研究对象的DNA提取出来,作为后续实验的基础。
3. 基因层数组分析:通过基因芯片进行全基因组的快速移除基因层分析,并确定可疑区域。
4. 高通量测序:对可疑区域进行测序,并对数据进行分析。
确定与自闭症发生有关的基因。
5. 功能研究:对可疑基因进行进一步的功能研究,包括分析基因表达、信号途径、代谢通路等方面。
6. 确认分析:用其他的工具和方法(比如PCR、DNA 鉴定等)对结果进行验证和确认。
自闭症相关文献1. "Identification of new autism candidate genes using human - and chick- based whole-genome screens."(Nicholas Katsanis, April Barnby, Dalila Francks, Sabine A. E. Vulpe, et al., 2009)文章介绍了通过全基因组扫描方法,研究了个体中数千个基因与自闭症之间的关系。

生物界的许多性状是以数量性状为基础的,该类性状的发生不是决定于一对等位基因,而是受到两对或更多对等位基因的控制,每对等位基因彼此之间没有显性与隐性的区别,而是共显性。
这些等位基因对该遗传性状形成的作用微小,所以也称为微效基因(minor gene),它们在染色体上的位置称为数量性状基因座(quantitative trait loci, QTL)。
数量性状就是由许多对微效基因的联合效应造成的一类具有正态分布特性的性状,具有这种性状的个体在正态分布中的位置决定于它们所具有的微效基因的多少。
数量性状之所以复杂,是因为这种性状与基因型之间没有一一对应的关系,并且环境因素对它有显着的影响[1]。
1961年,Thoday首次利用一对侧翼标记定位一个QTL[2],随后QTL的研究得到飞速发展。
现已证明,只要是控制连续分布性状的数量性状基因座,就能在实验群体或远交群体中定位[3] 。
在整个QTL的研究中,可分为发现QTL,QTL的定位估计和精细定位[4]。
Glazier 认为可分成四个步骤:连锁和关联分析,精细定位,序列分析和候选基因的功能检测[5]。
在模式生物小鼠的QTL研究,已描述的实验步骤更为详细[6]:第一,把QTL定位到染色体的区段上。
典型的QTL定位方法须对几百个杂交后代进行恰当的表型检测;利用覆盖整个基因组的75-100个遗传标记进行基因组扫描,遗传标记的平均跨度为15-20个厘摩(cM);准确基因分型,然后对性状和遗传标记之间进行连锁和关联分析;计算QTL与某标记位点靠近的可能性大小。
这种方法即使经过成百上千次的表型和基因型的分析,定位的QTL在染色体上还是一个较大的区间。
第二,把一个QTL的作用与其它QTL的作用分开。
通常在同源系(congenic strain)中进行,这样就把多基因遗传的性状转化成单基因性状进行研究。
目标QTL与其它有作用的QTL 分离后,仍须具有可测量的表型效应,否则达不到分离目的。

案例四“基因在染色体上”的教学设计案例和点评一、教学设计的指导思想1.课程标准指出“教师要善于引导学生从生活经验中发现和提出问题,创造条件让学生参与调查、观察、实验和制作等活动,体验科学家探索生物生殖、遗传和进化的奥秘的过程”。
在“遗传的分子基础”部分的具体内容标准中还提到“总结人类对遗传物质的探索过程”,“阐明基因的分离规律和自由组合规律”。
在人类对遗传物质的探索过程中,萨顿和摩尔根都做出了杰出的贡献。
他们有独到的研究方法,有缜密的思考,有严谨的推理,并得出了科学的结论。
二、教学内容分析(本节课在本章的本节的位置)1.本节课内容是人教版义务教育课程标准教科书《生物学》高二年级必修二第二章。
第2节,是在第1节《减数分裂和受精作用》的基础上共同探索“环境与生物的相互关系,基因在染色体上”这个主题。
在教材编排上,注重了学生的主动参与获取知识,重视了学生探究意识的培养,并为下一节伴性遗传打下基础。
2.教学重点:一是科学的过程和方法;二是在染色体和基因水平上阐明分离规律和自由组合规律。
3.教学难点:运用类比推理的方法解释基因位于染色体上;基因位于染色体上的证据三、学情分析通过上节课《减数分裂和受精作用》同学们已经认识到细胞内染色体的行为变化,为本节课的学习打下基础。
由于本节课内容具有较深的抽象性,故在教学中,通达启发式教学,设置大量的问题情境,来激发学生的学习兴趣和进一步培养他们的分析、归纳、概括能力。
四、教学目标设计1.知识目标(1)说出基因位于染色体上的理论假说和试验证据。
(2)概括孟德尔遗传规律的现代解释2.技能目标(1)运用有关基因与染色体的知识阐明孟德尔遗传规律的实质。
(2)尝试运用类比推理的方法,解释基因位于染色体上3.情感目标认同科学研究需要丰富的想象力,大胆质疑和勤奋实践的精神,以及对科学的热爱参与类比推理的过程,提出与萨顿假说相似的观点,体验成功的喜悦。
五、教学方法设计教学策略整节课设计为一次在教师引导下的探究。


遗传实验设计专题主讲教师: 毕诗秀一、遗传学常用的研究方法1.动植物杂交实验法2.假说演绎法提出→作出(理论解释)→设计(演绎推理)→验证→得出3.数学统计法计算遗传概率以及进行基因定位4.调查法群体调查——调查某种遗传病的率家系调查——调查某种病的方式二、典型例题1. 以孟德尔的一对相对性状遗传研究为例, 写出杂交实验法的过程和思路:⑴选择杂交, 获得F1, 结果;⑵让 , 结果;⑶为了解释上述现象, 孟德尔提出假设的核心是;⑷验证假设: 设计了实验, 即;⑸预期结果:。
孟德尔设计测交实验的意义是通过的比例来反映的比例;⑹实施实验方案, 得到的_______ __与_____ ____相符, 由此得出结论。
2. 科学家从某植物突变植株中获得了显性高蛋白植株(纯合子)。
为验证该性状是否由一对基因控制, 请参与实验设计并完善实验方案:①步骤1: 选择和杂交。
预期结果: 。
②步骤2: 。
预期结果: 。
③观察实验结果, 进行统计分析:如果与相符, 可证明该性状由一对基因控制。
3.⑴在一块高杆(显性纯合体)小麦田中, 发现了一株矮杆小麦。
请设计实验方案探究该性状出现的可能的原因(简要写出所用方法、结果和结论)⑵大部分普通果蝇身体呈褐色(YY), 具有纯合隐性等位基因yy的个体呈黄色。
但是, 即使是纯合的YY品系, 如果用含有银盐的食物饲养, 长成的成体也为黄色, 这称为“表型模拟”, 是由环境造成的类似于某种基因型所产生的表现型。
若有一只黄色的果蝇, 你如何判断它是属于纯合yy还是“表型模拟”?方法步骤:第一步: 用该未知基因型黄色果蝇与交配;第二步: 将孵化出的幼虫用饲养, 其他条件适宜;第三步: 观察。
结果预测: 如果后代出现了色果蝇, 则所检测果蝇为“表型模拟”;如果子代全为色, 说明所测黄色果蝇的基因型是 , 不是“表型模拟”。
4.某植物(2n=10)花蕊的性别分化受两对独立遗传的等位基因控制, 显性基因B和E共同存在时, 植株开两性花, 表现为野生型;仅有显性基因E存在时, 植株的雄蕊会转化成雌蕊, 成为表现型为双雌蕊的可育植物;只要不存在显性基因E, 植物表现为败育。


第43卷 第2期2024年 3月Vol.43 No.2Mar. 2024,85~92华中农业大学学报Journal of Huazhong Agricultural University玉米籽粒发育突变体emp35的表型分析与基因定位刘津1,2,汤艳芳3,杜何为1,张祖新21.长江大学生命科学学院,荆州434023;2.华中农业大学作物遗传改良全国重点实验室,武汉430070;3.湖北中医药大学检验学院,武汉430065摘要 为解析玉米籽粒形成的遗传基础,探究Emp35基因在玉米籽粒发育中的作用,对籽粒缺陷突变体empty pericarp35(emp35)进行表型鉴定、胚乳细胞显微观察、胚乳贮藏物质含量测定及图位克隆。
结果显示:突变体籽粒发育缓慢,明显小于同期发育的正常籽粒,成熟籽粒干瘪呈空皮状;胚乳细胞显微观察发现emp35的胚和胚乳发育严重滞后,胚乳细胞中线粒体结构异常;淀粉和蛋白质积累减少;F 2代分离果穗上正常籽粒与发育缺陷籽粒呈3∶1分离,表明籽粒缺陷表型由单个隐性核基因突变所致。
采用集团分离分析法(bulked segregant analysis , BSA ) 将Emp35定位于第8染色体 127.90~163.36 Mb 区间,在该区间内开发了4个InDel 标记,连锁作图将Emp35精细定位于139 571 117~146 176 858区间。
关键词 玉米(Zea mays L .); 籽粒发育; 集团分离分析法; 基因定位; 表型鉴定中图分类号 S513.3 文献标识码 A 文章编号 1000-2421(2024)02-0085-08玉米籽粒产量由单位面积穗数、每穗粒数和籽粒质量3个因素构成。
籽粒质量由籽粒库容和胚乳充实程度所决定[1],籽粒发育与充实程度影响籽粒产量。
玉米籽粒发育包括胚胎发育、胚乳细胞分化和贮藏物质积累3个关键过程,每个发育过程都受众多基因调控。
目前,研究者已经克隆了百余个控制籽粒发育进程的基因[2]。
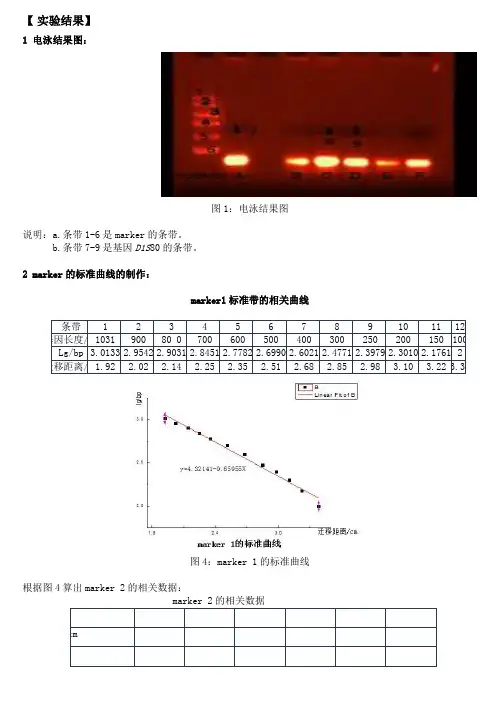
【实验结果】1 电泳结果图:图1:电泳结果图说明:a.条带1-6是marker的条带。
b.条带7-9是基因D1S80的条带。
2 marker的标准曲线的制作:marker1标准带的相关曲线图4:marker 1的标准曲线根据图4算出marker 2的相关数据:离度所以可以估算出条带1’~6’的标准分子量大概为2400、1700、1000、700、400、200。
将这一组数据应用到实验结果中marker标准曲线的绘制上,显然会给实验结果带来很大的影响。
但又不可避免。
marker标准条带的相关数据图2 marker的标准曲线3成员A、C、D的D1S80的计算:根据marker的标准曲线知表2:4结果记录表:表3:结果记录表【实验分析及讨论】A从图1可知小组成员里只有A、C、D有正常的条带,而且全是纯合体,而B、E、F并没有出现正确的条带,分析可能原因:a在取样时取得太少了,致使提取的DNA浓度过低,在该实验的PCR条件下30个循环不能得到正确的DNA分子拷贝。
b取样不合适,可能在去口腔上皮时并没有在适合的位置取,导致取出来的并不是口腔上皮。
c在操作过程中一些错误的步骤导致没有提出正确的DNA分子。
B图1中最下面的有一排亮亮的条带。
据分析是PCR体系里引物的条带。
但是我们可以发现与B、E、F相比,A、C、D对应的条带最亮最宽,说明引物的含量较多,但是偏偏 A、C、D有正确的条带。
这似乎说不通,但是进一步的分析可以推测有以下两种原因:a在向Pcr小管里加入体系时,由于移液枪不准造成的加入体系不同,但这种概率较小。
b在向胶孔加入样品时由于加入量不同造成的结果。
这个显然比第一种出现的概率要大得多。
C原理中我们指出人类1号染色体上的VNTR D1S80,核心序列由16个核苷酸组成,拷贝数在14~41个之间,已知29种不同的等位基因。
但是我们的实验结果里D的拷贝数为13,却小于14,由于两者比较接近所以将D的拷贝数应该认为是14,而出现这种偏差的原因可能在于:a marker标准的分子量我们是用的周五晚上组的图估算出来的(如图3),并不是说明书上标准的,所以marker的标准曲线与实际的可能有一定的差距,这样就会导致最后的结果也会有一定的差距。

基因工程的基本过程介绍基因工程是一项重要的生物技术领域,它利用DNA重组技术,对生物体的基因信息进行修改和重新组合,实现改变生物体性状的目的。
基因工程的基本过程包括基因定位、基因克隆、基因表达和基因转导等步骤。
本文将详细介绍基因工程的基本过程。
一、基因定位基因定位是基因工程的第一步,通过确定目标基因在染色体上的位置,为后续的基因克隆提供准确的目标。
基因定位可以通过物理方法、遗传方法和分子生物学方法等多种手段来实现。
1. 物理方法物理方法主要包括荧光原位杂交(FISH)和比较基因组杂交(CGH)等。
其中,荧光原位杂交可以通过标记特定探针并与目标基因序列进行杂交,从而在染色体上检测到目标基因的位置。
比较基因组杂交可以通过将目标基因与参考基因组进行杂交,通过比较两者的杂交强度,确定目标基因在染色体上的位置。
2. 遗传方法遗传方法主要包括连锁分析和关联分析等。
连锁分析是利用基因在染色体上的连锁关系,通过研究特定遗传标记和目标基因之间的连锁程度,来确定目标基因在染色体上的位置。
关联分析则是通过研究染色体多态性和目标基因之间的关联程度,来确定目标基因与某个特定区域的关系。
3. 分子生物学方法分子生物学方法主要包括PCR、Southern blotting和DNA测序等。
PCR可以通过目标基因的序列信息,设计特定引物并进行扩增,从而实现对目标基因的定位。
Southern blotting可以通过转移DNA片段到膜上,并进行测序等。
二、基因克隆基因克隆是基因工程的关键步骤,它通过将目标基因从来源生物体中分离出来,并进行扩增,得到足够多的DNA材料用于后续的实验。
1. DNA提取DNA提取是基因克隆的第一步,它可以通过细胞裂解、溶解和沉淀等步骤将DNA从生物体中提取出来。
常用的DNA提取方法包括酚-氯仿法、盐析法和商业DNA提取试剂盒等。
2. PCR扩增PCR扩增是基因克隆的关键技术,它可以通过DNA聚合酶的作用,将目标基因序列进行扩增。

基因定位方法及优缺点作者:蒋兰兰蒋国庆来源:《今日湖北·中旬刊》2013年第08期摘要基因定位是遗传学研究中的重要环节。
在遗传学的早期研究中并未发现果蝇等生物的基因在染色体上的位置和生理功能有什么关系。
但以后发现一些有类似表型效应的基因是紧密连锁的。
此外,测定了某一基因在某一染色体上的位置以后,便可以用这一基因作为所属染色体或其一部分的标记,追踪并研究染色体的行为。
关键词基因定位优点缺点基因定位和基因图对遗传学、医学和人类及生物进化的研究都有十分重要的意义。
它可提供遗传病和其他疾病的诊断的遗传信息,可以指导对这些疾病的致病基因的克隆和对病症病因的分析与认识,这些又取决于遗传图和物理图的相互依赖关系。
通过多态位点标记进行连锁分析获得物理图的位置有助于遗传作图,同时通过连锁分析(部分有减数分裂的交换)又能指导物理作图,使基因定位更为精细。
两点测验和三点测验是基因定位所采用的主要方法。
两点测验:先用3次杂交,再用3次测交(隐性纯合亲本)来分别测定两对基因间是否连锁,然后再根据其交换值确定它们在同一染色体上的位置。
三点测验:利用三对连锁基因杂合体,通过一次杂交和一次测定,同时确定3对基因在染色体上的位置。
(1)体细胞杂交法体细胞是生物体除生殖细胞外的所有细胞。
将从身体分离的体细胞做组织培养进行遗传学研究的学科称为体细胞遗传学。
体外培养细胞可人为控制或改变环境条件,并可建立细胞株,长期保存,进行各种正常和病理研究。
与基因定位有关的是体细胞杂交。
细胞杂交又称细胞融合,是将来源不同的两种细胞融合成一个新细胞。
大多数体细胞杂交是用人的细胞与小鼠、大鼠或仓鼠的体细胞进行杂交。
这种新产生的融合细胞称为杂种细胞,含有双亲不同的染色体。
杂种细胞有一个重要的特点是在其繁殖传代过程中出现保留啮齿类一方染色体而人类染色体则逐渐丢失,最后只剩一条或几条,其原因至今不明。
这种仅保留少数甚至一条人染色体的杂种细胞正是进行基因连锁分析和基因定位的有用材料。

课标专用5年高考3年模拟A版2021高考生物:专题13 伴性遗传和人类遗传病探考情悟真题【考情探究】分析解读本专题内容包括伴性遗传和人类遗传病两个考点。
两个考点在高考试题中考查较频繁。
从近年高考情况来看,本专题知识主要结合表格和遗传系谱图等材料,考查遗传方式的判断、遗传病监测与预防、患病概率的计算等。
另外,该专题内容还常与孟德尔遗传定律、可遗传变异等知识相联系,考查考生分析问题和实验探究的能力。
在复习时应多归纳总结遗传方式的判定方法和遗传概率计算的技巧,通过强化训练提升推理能力和综合分析能力。
【真题探秘】破考点练考向考点一基因在染色体上和伴性遗传【考点集训】考向1 基因在染色体上1.(2020届安徽蚌埠田家炳中学月考,18,2分)下列关于科学研究方法及技术的叙述正确的是( )A.摩尔根利用假说—演绎法证明了基因在染色体上B.萨顿利用假说—演绎法证明了基因和染色体存在平行关系C.孟德尔利用类比推理法得出了遗传学两大定律D.沃森、克里克构建出DNA分子结构的数学模型答案 A2.(2020届贵州贵阳摸底,13,2分)下列叙述中,不能说明真核生物中“基因和染色体行为存在平行关系”的是( )A.基因发生突变而染色体没有发生变化B.非等位基因随非同源染色体的自由组合而自由组合C.二倍体生物形成配子时基因和染色体数目均减半D.等位基因一个来自父方,一个来自母方,同源染色体也如此答案 A3.(2019黑龙江哈六中第二次月考,46,1分)如图是科学家对果蝇一条染色体上的基因测定的结果,下列有关该图说法正确的是( )A.控制朱红眼与深红眼的基因是等位基因B.控制白眼和朱红眼的基因在遗传时遵循基因的分离定律C.黄身和白眼基因的区别是碱基的种类不同D.该染色体上的基因在果蝇的每个细胞中不一定都能表达答案 D考向2 性别决定与伴性遗传1.(2020届安徽合肥一中月考,18,2分)某种家禽(2n=78,性别决定为ZW型)幼体雌雄不易区分,其眼型由Z染色体上的正常眼基因(B)和豁眼基因(b)控制,雌禽中豁眼个体产蛋能力强。
作物学报ACTA AGRONOMICA SINICA 2008, 34(2): 207−211 /zwxb/ ISSN 0496-3490; CODEN TSHPA9E-mail: xbzw@DOI: 10.3724/SP.J.1006.2008.00207一个新的棉花MYB类基因(GhTF1)的克隆及染色体定位分析房栋吕俊宏郭旺珍*张天真(南京农业大学作物遗传与种质创新国家重点实验室, 江苏南京210095)摘要: MYB类转录因子是指含有MYB结构域的一类转录因子, 广泛参与植物发育和代谢调节。
含2个MYB结构域的R2R3类MYB转录因子在植物体内主要参与次生代谢的调节和控制细胞的形态发生。
从优质材料7235不同发育时期的棉纤维混合cDNA文库中克隆了一个棉花MYB转录因子基因GhTF1(GenBank登录号: EF651783)。
该cDNA序列长1 115 bp, 其开放读码框长度为771 bp, 编码256个氨基酸。
表达特征分析表明, 该基因在陆地棉7235不同组织中均表达, 但表达量不同, 特别在开花前1 d, 开花后8 d和11 d的纤维细胞中优势表达。
该基因在二倍体棉种非洲棉和雷蒙德氏棉中开放读码框区的序列较保守, 但在非编码区差异较大, 在内含子区存在大片段插失和碱基替换现象。
Southern杂交结果表明该基因在陆地棉基因组中存在2个拷贝, 推测A、D亚组中各有1个拷贝。
利用海7124和TM-1两亲本配置的BC1作图群体, 将GhTF1定位在染色体10上。
关键词: 棉花; MYB基因; 克隆; 表达; 基因定位Cloning and Mapping of a New MYB Transcription Factor (GhTF1) in CottonFANG Dong, LÜ Jun-Hong, GUO Wang-Zhen*, and ZHANG Tian-Zhen(State Key Laboratory of Crop Genetics & Germplasm Enhancement, Nanjing Agricultural University, Nanjing 210095, Jiangsu, China)Abstract: Plant MYB transcription factors are characterized by containing a structurally conserved MYB domain, they play important roles in the regulation of plant development and metabolism. Of them, the R2R3 MYB proteins with two MYB domains are involved in regulating secondary metabolism and cellular morphogenesis. Cotton fibers are single-celled seed trichomes. So far, the molecular process of fiber initiation is poorly understood. However, some transcriptional factors such as MYB genes are responsible to fiber cell initiation. Just like in Arabidopsis, leaf trichome formation is mediated through positive and negative regulators such as GL1 and GL2 encoding MYB transcription factors.In cotton, several MYB transcription factors have been cloned. Expression of type I genes (GhMYB1, 2, and 3) was detected in all tissues tested, while type II genes (GhMYB4, 5, and 6) process involving many other pathways such as signal transduction and transcriptional regulation. Moreover, GhMYB109, a gene encoding a R2R3 MYB transcription factor, was expressed specifi-cally in fiber initials and elongating fibers. And over-expression of GaMYB2 complemented gl1 phenotype as well as induced seed trichome development in Arabidopsis, suggesting a role of MYB-like transcription factors in cotton fiber cell differentiation. The objective of the study was to clone new MYB genes, further put a foundation to illustrate these genes function in cotton fiber developmental stages. In this paper, a MYB transcription factor gene, GhTF1 was isolated from developmentally different cotton fiber pools of elite material 7235 library. GhTF1 (GenBank No.: EF651783) is a 1 115 bp cDNA, its open reading frame is 771 bp, and encodes a polypeptide containing 256 amino acids. GhTF1 was expressed constitutively in every tissue with different expres-sion levels, e.g. with higher levels in fiber cells at initiation and elongations stages. GhTF1 had conserved coding region in A and D diploid cotton species, G. herbaceum and G. raimondii, however, there existed a large DNA fragment insertion/deletion and base substitutions in their corresponding intron region. Southern blotting analysis showed that there were two copies of GhTF1 in the基金项目:国家自然科学基金项目(30471104); 国家重点基础研究发展计划(973计划)项目(2002CB111303); 教育部新世纪优秀人才支持计划项目(NCET-04-0500); 教育部长江学者和创新团队发展计划项目(IRT0432)作者简介:房栋(1981– ), 男, 硕士。
减数第一次分裂时,
染色体分离
阅读分析基因与染色体的关系:杂交过程中
指导学生学会基因的表示方法:
常染色体性染色体3对:ⅡⅡ,ⅢⅢ,ⅣⅣ
雌性同型:XX
雄性异型:XY
假设二:控制白眼的基因在X 、假设三:控制白眼的基因在X 染色体上,而不含有它的等位基因。
引导学生回顾本节课复习的内容,把核心概念形成概念图,如下:色体上,只有位于非同源染色体上的非等位基因才能自由组合。
作业布置
Homework
2.2基因在染色体上作业案
板书设计Blackboard Designs 1、萨顿假说
2、摩尔根假说演绎法证明基因在染色体上
3.孟德尔遗传规律的现代学解释
教学反思Teaching Reflections 本节课内容相对简单,重点把握假说演绎法证明基因在染色体上。
联系孟德尔的假说演绎法,进一步学习位于X染色体上的基因的遗传图解。
课件名称或课件网址
Name or Website of CaseWare
2.2基因在染色体上。
判断基因在染色体上的位置的方法基因是DNA分子上的一个特定段,它们负责控制生物的遗传特征。
在细胞分裂的过程中,基因会被复制并传递给下一代。
为了更好地了解基因如何传递和表达,科学家需要研究基因如何在染色体上定位。
本文将介绍10条判断基因在染色体上位置的方法。
1. 遗传连锁分析法遗传连锁分析法是通过检测两个或多个遗传标记(即基因)在一定数量的家庭成员中的共同遗传来确定其在染色体上的位置。
通过检测一些遗传标记和某种疾病之间的联系,科学家可以确定这些遗传标记与疾病的相关区域。
这种方法需要大量的家族基因数据和分析技能,因此通常用于遗传病的研究。
2. 遗传连锁破裂法这种方法是通过生物体中染色体交换的过程来确定基因在染色体上的位置。
这种方法需要研究多个家族成员的基因型,并对某些人种间的交叉策略进行研究,以找出基因重组的位置。
这种方法需要大量的基因数据和复杂的计算工具,因此仅在一些基因家族研究中使用。
3. 突变法染色体的突变可以揭示基因在染色体上的位置。
染色体的突变包括缺失、重复、翻转和倒位。
这些突变通常是自然发生的,但有时也可以通过化学和放射性等物质的影响引发。
由于每个位点的突变是随机的,这种方法主要用于确定较小区域上的基因。
4. 染色体分析法通过每个染色体上的特定位点(常用的是Sanger测序法)来确定染色体上的基因位点。
这种方法对于染色体异常和结构变化的检测非常有效,例如染色体异常,例如三体或四体染色体,因为它可以对每个染色体上的特定位置进行分析。
5. DNA杂移法这种方法通过将已知位置的DNA片段与未知位点的DNA片段混合,以确定未知位点与已知位点之间的距离和方向。
双杂合点是DNA杂交的结果。
这种方法依赖于适当的DNA引物和酶切酶的使用,因此需要复杂的实验设计和数据分析。
这种方法通常用于物种间的基因笛片测序,是一种确定线虫、果蝇等物种基因位置的有效方法。
6. 荧光原位杂交法这种技术使用荧光探针定位基因的位置。
黄瓜白色果皮基因遗传规律及定位研究董邵云;苗晗;张圣平;刘苗苗;王烨;顾兴芳【摘要】Inbred line 1507(dark green fruit skin) and inbred line 1508(white fruit skin) were used as the experiment materials for genetic analysis and gene mapping of white fruit skin in cucumber in this study. Genetic analysis showed that a single recessive nuclear gene,w, dominates the white fruit skin trait in cucumber. Bulked segregate analysis (BSA) and simple sequence repeat (SSR) technologies were employed to map w gene in F2 population, w was mapped to a linkage group with 14 SSR markers, corresponding to chromosome 3 of cucumber. The flanking markers SSR23517 and SSR23141 were linked to the w gene with genetic distances of 4. 9 and 1. 9 cM, respectively. The physical distance between SSR23517 and SSR23141 was 1 150 kb based on the whole genome sequence of cucumber,and there are 500 candidate genes in this region. These results will benefit fine-mapping of w gene and marker-assisted selection (MAS) in fruit skin color cucumber breeding program.%以黄瓜嫩果深绿色果皮自交系1507 (P1)和白色果皮自交系1508 (P2)为亲本,构建6世代遗传群体(P1、P2、F1、F2、BC1P1、BC1P2),对黄瓜嫩果白色果皮基因(w)进行遗传规律分析和基因定位研究.结果表明,黄瓜白色果皮性状由隐性单基因(w)控制,深绿色对白色为显性.利用F2群体,结合分离群体分组分析法筛选得到了14个与w基因相关的SSR标记,构建了该基因的SSR连锁群,将其定位到黄瓜3号染色体上,两侧的标记为SSR23517和SSR23141,遗传距离分别为4.9 cM和1.9cM.侧翼标记之间的物理距离为1 150 kb,在该区域中共预测了500个候选基因.该研究对w基因的初步定位,为该基因精细定位及分子标记辅助选择育种奠定了良好的基础.【期刊名称】《西北植物学报》【年(卷),期】2012(032)011【总页数】5页(P2177-2181)【关键词】黄瓜;白色果皮;遗传分析;SSR标记;基因定位【作者】董邵云;苗晗;张圣平;刘苗苗;王烨;顾兴芳【作者单位】中国农业科学院蔬菜花卉研究所,北京100081;中国农业科学院蔬菜花卉研究所,北京100081;中国农业科学院蔬菜花卉研究所,北京100081;中国农业科学院蔬菜花卉研究所,北京100081;中国农业科学院蔬菜花卉研究所,北京100081;中国农业科学院蔬菜花卉研究所,北京100081【正文语种】中文【中图分类】Q343.1+7黄瓜(Cucumis sativus L.)是世界十大蔬菜之一,因其风味清香、口感脆爽、营养丰富,深受各国消费者的喜爱。