xml复习文档
- 格式:docx
- 大小:1.15 MB
- 文档页数:10

习题第2章良构的XML1.XML文档分成几类?2.举例说明什么是标签与元素?3.说明一下Tag与Markup的异同?4.良构的XML文档对元素有什么要求?5.CDATA标记用在什么地方?6.XML声明有哪些属性?7.XML中常用的字符集有哪些?哪些支持中文?8.空白符包括什么?XML解析器如何处理空白符?9. 什么是串行化?10.XML文档的逻辑模型有哪三种?11.有哪些主要的信息项?每个信息项有哪些属性?第3章命名空间1.为什么使用“命名空间”?2.什么是QName ?3.如何在元素中声明一个命名空间?4.如何在元素中声明一个默认的命名空间?5.有哪些常用的命名空间?6.何时使用命名空间?何时不用命名空间?第4章 DTD1. 什么是有效的(valid)XML文档?2.DTD包括哪些声明(定义)?3.在DTD中,元素的内容模型是哪四种?4.如何声明一个空元素?5.如何声明一个纯文本元素?6.如何声明有序的子元素?7.如何声明互斥的子元素?8.如何声明无序的子元素?9.如何声明混合内容的元素?10.如何定义基数?11.如何声明枚举类型的属性?12.ID类型与IDREF类型的属性有什么作用?13.如何定义实体及引用实体?第5章 XML Schema1.XML Schema同DTD相比,有哪些优势?2.XML Schema的根元素<schema> 有哪些属性,起什么作用?3.当声明一个targetNamespace 属性时,为什么一定要插入一个相匹配的命名空间声明?4.如何定义元素,复杂类型用于定义什么样的元素?5.简单类型指的什么?有什么作用?6.在Schema中,如何声明有序的子元素?7.在Schema中,如何声明互斥的子元素?8.在Schema中,如何声明无序的子元素?9.在Schema中,如何声明混合内容的元素?10.在Schema中,如何声明空元素?11.在Schema中,如何声明附带属性的纯文本内容的元素?12.在Schema中,如何声明枚举类型的属性?第6章 RELAX NG1.如何通过样式(patterns )定义元素与属性?第7章 XML 路径语言1.XPath数据模型有哪些结点类型?2.根结点是根元素吗?3.文本结点有名字吗?4.XPath数据模型中的结点关系有哪些?5.路径表达式起什么作用?6. 路径表达式由什么组成?7. 说明路径表达式中“步”的组成?8. 有哪些常用的轴,各是什么意思?9. 在XPath路径表达式中,有哪些常用的“结点测试”?10.在XPath路径表达式中,有哪些常用的“限定谓词”?第8章 XSLT1.对XML文档而言,XSLT有哪两个主要作用?2.画图说明XSLT处理器的工作过程分几步?3.<xsl:template> 元素有什么属性,其取什么值?4.如何在模板之间进行调用?5. 如何使用<value-of>从源树中取值?6. <copy>元素与<copy-of>元素有什么不同?7.在实际应用中,XSLT有几种转换方式?(客户端转换与服务器端转换:批量转换与实时转换)第9章 XQuery1.doc()函数的输入与输出分别是什么?2.举例说明,XQuery 中有哪两种元素构造器。


《XML基础及应用开发》复习提纲◆考试题型一、选择题(每小题2分,共40分)二、填空题(每空1分,共10分)三、简答题(6小题,共25分)四、设计题(3小题,共25分)◆复习内容一、英文缩写的中文全称XML:可扩展标记语言SGML:标准通用标记语言HTML:超文本标记语言DTD:文档类型定义XSL:可扩展样式表语言CSS:级联样式表或层叠样式表二、XML基本语法1、XML文档声明P.181.XML文档主要由两部分组成:文档序文和文档根元数。
2.根据XML规范,每个正规的XML文档都要由一个XML文档声明开始,不允许在其前面有其他任何的字符、空格以及注释。
3.XML声明的基本语法格式为:<?xml version=”1.0”encoding=”gb2312”standalone=”yes”?>4.version=”1.0”:说明使用的XML版本为1.0。
5. 默认使用UTF-8。
2、XML元素的定义P.22-251.元素的基本形式:1.开始标记和结束标记必须成对出现。
2.XML元素的开始标记和结束标记必须同名,但要在结束标记前面加上一个斜杆。
3.各个元素的开始标记和结束标记可以嵌套使用,但不能交叉使用。
4.空元素标记可以省略结束标记,但必须以“/”结束。
2.元素的命名规则1.英文名称必须以英文字母或下划线“_ ”开头,中文名称可以以汉字开头或下划线“_ ”开头。
2.元素名称前不能出现空格。
3. 在英文元素名称在,元素名称应该区分大小写。
元素的嵌套4. 一个XML文档只有一个根元素,它是XML文档的入口,代表文档本身。
3、XML元素属性的定义P.27元素中属性声明的语法格式:空元素<标记名属性名1=“属性值1”属性名2=“属性值2”····>元素内容</标记名>非空元素<标记名属性名1=“属性值1”属性名2=“属性值2”····/>定义:1.属性的命名规则与元素的命名规则相同,属性名区分大小写。
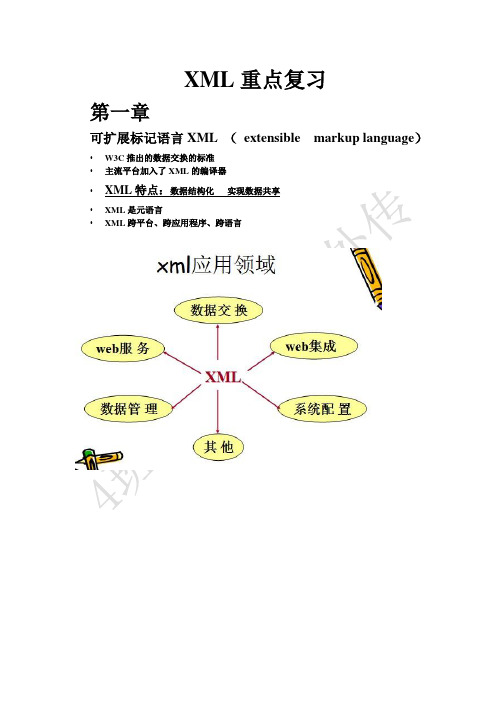
XML重点复习第一章可扩展标记语言XML (extensible markup language)•W3C推出的数据交换的标准•主流平台加入了XML的编译器•XML特点:数据结构化实现数据共享•XML是元语言•XML跨平台、跨应用程序、跨语言第二章实验例题,XML文档编写五个实体:内部一般实体,外部一般实体,参数实体,不可解释实体(好像缺一个,自己查书)五个特殊的符号XML文档可以分为标记和内容两部分。
XML用如下规则区分其标记与内容:•标记的开始由“<”或“&”来识别;•三个其它字符也可以被当成标记字符,它们是大于号“>” 、单引号“ ' ”、双引号” “ ”;•需要避免直接将上述符号作为普通字符输入;•其它部分则看成内容。
将上面规则中提到的字符称为“标记字符”。
XML解析器会将这些字符当作标记进行处理,即使它是出现在XML的内容中。
将标记字符作为普通字符:实体第三章建立XML文档的步骤1.对相关信息项进行命名,将其映射为相应的元素或属性。
2.确定XML文档的层次结构,即各元素之间的嵌套关系。
3.根据DTD编写相应的XML文档4.子元素类型元素可以包含一系列的子元素,子元素内容模型用于指定某个元素可以包含哪些子元素.根据子元素间的关系,子元素内容模型可以有两种可能的结构:序列和选择。
1.序列:其所有子元素必须出现且只能出现一次,并且按顺序出现。
<!ELEMENT message(header,body,footer)>注意:序列中不能出现#PCDATA子元素还可以包含其他子元素。
元素出现次数指示符(Element occurrence indicator)•?字符:它说明元素可以出现0次或1次。
•* 字符:它说明元素可以不出现,或出现1次或多次。
•+ 字符:它说明元素必须出现至少一次,或者说可以出现一到多次实体:1、一般实体(General):文档内容中使用的实体。

6、XML 文档中语句<!DOCTYPE dlib SYSTEM “mydtd. dtd〃>中SYSTEM 的作用是(C )A、指定运行的操作系统B、打开系统文件C、连接外部DTD文件四、根据下面内部DTD文档,完成后继的xml文档。
(15分)1.什么是XML? XML的特点有哪些?答案:XML (extensible Markup Language,可扩展标记语言),是由万维网联盟(World Wide Web Consortium, W3C)定义的一种数据交换的规范,是Web上的数据通用语言,使用一系列简单的标记描述数据。
XML的特点有:(1)XML是一种简单、与平台无关并被广泛采用的标准,可用于Internet上的各种应用。
(2)XML兼容SGML,所以多数SGML应用可转化为XML。
(3)XML文件同HTML文件一样易于创建。
(4)XML文件内容、结构简单,可以更加灵活地进行编程,减少了服务器的工作量。
(5)XML文件结构严谨,可以轻松被计算机程序解析。
(6)XML相对于HTML的优点是它将用户界面少结构化数据分隔开来。
这种数据与显示的分离使得集成來自不同源的数据成为可能。
2.简述XML与HTML的区别。
答案:(1)HTML语言是用来格式化\vcb数据的语言,冇固定的标记,每一个标记都冇其固定的用法。
XML允许自定义标记,用户可以自己定义标记来描述口己领域的信息。
(2)HTML的语法也相当宽松,标记不一定要配对使用,名称不区分大小写。
XMI.语言冇其严格的语法规则,标记必须成对使用,严格区分名称的大小写。
(3)不能够很好的描述数据的结构,本质上是一种格式显示语言。
XML语言的特点就是将信息的内容和它们的显示样式区分开来,焦点是数据的内容。
3.简述XMI.解析器的种类及解析步骤。
答案:XML的解析器分成两大类:综合的解析器和专用的解析器。
综合的解析器又分为:基于DOM 的解析器和基于事件的解析器。

第1讲1、XML的用途功能:从HTML中分离数据;交换、共享和存储数据;充分利用数据;创建新的语言2、应用:对于Internet 和大型企业;Intranet 环境十分有价值;格式标准、灵活、开放;提供了协同工作能力可以更快地构建应用3、概念XML(eXtensible Markup Language),可扩展标记语言。
“可扩展”,即用户可以自定义标记。
4、XML是一种元语言。
<?xml version=“1.0”?> 书写xml文件应注意:xml声明语句必须作为文件的第一行。
5、其<职员>中:“<?”与“xml”<姓名>张三</姓名> 之间不能有空格,“? ”与“>”之间不能有空格6、xml有且仅有一个跟标记,其他标记必须封装在根标记中,文件的标记必须形成树状结构。
7、规范的XML: 符合W3C制定的规则;XML文件分为有效的XML:符合W3C规则符合额外的约束判断:有效的XML文件与规范的8、xml和HTML的主要区别①HTML的标记是固定的,预定义的,不可扩展的;而XML 的标记是可扩展的,是可以由用户自定义的。
②HTML的标记说明了信息的显示格式;而XML标记表示了数据的逻辑结构及语义9、XML与HTML的区别:–语法要求不同–标记不同–HTML只是显示信息,并不能说明信息是什么–XML主要存放内容,目标是在于如何更好地从逻辑和结构等方面来描述信息的内容第2讲1、字符集(Charset):一组抽象字符的集合。
其中字符(Character)是文字与符号的总称,包括文字、图形符号、数学符号等。
英文字符集、繁体汉字字符集、日文汉字字符集被编码过的字符集(Coded Character Set) :每种编码都限定了一个明确的字符集合2、ASCII:美国信息交换标准码;ISO 8859,全称ISO/IEC 8859: ISO8859-13、Unicode:UTF-8,Unicode转换格式(Unicode Translation Format,简称UTF)4、汉字编码:GB2312、BIG5 ANSI:美国国家标准局5、Unicode 的实现方式不同于编码方式。
<一>选择题知识点1)xml(eXtensible Markup language),可扩展标记语言,源于SGML,于1998年,xml公布了1.0版本2)XML文档的格式,第一条语句为<?xml version=”1.0”endcoding=”Unicode”standalone=”yes/no”?>3)XML文档的特点:a.标签必须成对的出现b.标签对大小写敏感c.必须正确的嵌套d.文档必须有且只有一个根e。
属性须加引号母或下划线或者:开头3。
元素名称首字符之后可以接一个或多个字母、数字、破折号、下划线、句号。
在置标中不能使用空格,xml对大小写敏感4。
空置标也必须关闭,比如<br>必须以<br/>代替。
5。
置标在使用时允许嵌套但不允许重叠。
xmlElement root=doc.DocumentElement; XmlNodeList nl=root.SelectNodes(“条件”); Foreach(XmlNode xn in nl){Console.WriteLine(+”:”+xn.InnerText); }XmlElement xe1=doc.CreateElement(“价格”);xe1.InnerText=”20.00”;xe1.setAttribute(“货币单位:”,“人民币”);Root.AppendChild(xe1);<二>大题XSD(schema)1、为以下XML文件编写一个XSD文件,该XML文件能够通过该XSD的有效性验证。
(1) 先创建一下XML文件,存为Commodity.xml<?xml version="1.0" encoding="UTF-8"?><商品系列><商品货号="_01"><品名生产商="11">111</品名><价格会员打折="0.5" 货币单位="11">555</价格><存货数量单位="1">111</存货数量></商品><商品货号="_02"><品名生产商="11">111</品名><价格会员打折="0.5" 货币单位="11">555</价格><存货数量单位="1">111</存货数量></商品></商品系列><?xml version="1.0" encoding="UTF-8"?><xsd:schema xmlns:xsd="/2001/XMLSchema"><xsd:elememt name="商品系列"><xsd:complexType name="商品"><xsd:attribute name="货号" type="xsd:string" use="required"/><xsd:sequence><xsd:elemnt name="品名" type="xsd:string"><xsd:attribute name="生产商" type="xsd:string" use="required"/> </xsd:elemnt><xsd:elemnt name="价格" type="xsd:string"><xsd:attribute name="会员打折" type="xsd:string" use="required"/><xsd:attribute name="货币单位" type="xsd:string" use="required"/> </xsd:elemnt><xsd:elemnt name="存货数量" type="xsd:string"><xsd:attribute name="单位" type="xsd:string" use="required"/></xsd:elemnt></xsd:sequence></xsd:complexType></xsd:elememt></xsd:schema>XSL:<?xml version="1.0" encoding="UTF-8"?><xsl:stylesheet version="1.0" xmlns:xsl="/1999/XSL/Transform"> <xsl:template match="/"><h2>My CD Collection</h2><table><tbody><tr bgcolor="green"><th>country</th><th>Price</th><th>Artist</th></tr><xsl:for-each select="catalog/cd"><xsl:choose><xsl:when test="country='USA'and price >= 9.90"><tr><td><xsl:value-of select="country"></xsl:value-of></td><td><xsl:value-of select="price"></xsl:value-of></td><td bgcolor="pink"><xsl:value-of select="artist"></xsl:value-of></td></tr></xsl:when></xsl:choose></xsl:for-each></tbody></table></xsl:template></xsl:stylesheet><?xml version="1.0" encoding="utf-8"?><xsl:stylesheet version="1.0" xmlns:xsl="/1999/XSL/Transform"> <xsl:template match="/"><html><body><table border="1"><th>姓名</th><th>地址</th><th>电话</th><th>电子邮件</th><th>录入日期</th><xsl:apply-templates select="通讯录/记录"/></table></body></html></xsl:template><xsl:template match="记录"><tr><td><xsl:value-of select="姓名" /></td><td><xsl:value-of select="地址"/></td><td><xsl:value-of select="电话"/></td><td><xsl:value-of select="电子邮件"/></td><td><xsl:value-of select="@录入日期"/></td></tr></xsl:template></xsl:stylesheet>3.XQUREY类型1、根据以上给出的XML文件books.xml,用XQuery的FLWOR表达式,(1)提取属性category的值为CHILDREN的book节点的所有内容,如下所示:<book category="CHILDREN"><title lang="en">Harry Potter</title><author>J K. Rowling</author><year>2005</year><price>29.99</price></book>xquery version "1.0";for $b in doc("books.xml")/bookstore/bookwhere $b/@category="CHILDREN"return $b(2) 提取每个year节点值是2003的book节点的author值,并用列表显示。
1、XML文档的组成部分人:①序言、主体、尾声三部分;②文档序文与文档根元素两部分2、XML文档类型定义中元素是用什么来声明的?<!ELEMENT 元素名(类型)>3、像素是什么长度测量单位?相对长度4、Schema与DTD的相同之处?A、功能相同:验证XML文档有效性5、实体引用必须使用什么符号?A、XML文档中的通用实体引用: &实体名;B、DTD中参数实体引用:%实体名;实体声明的格式:⑴通用实体:<!ENTITY 实体名“文本内容”> <!ENTITY 实体名 SYSTEM 文件路径>⑵参数实体:<!ENTITY %实体名“文本内容”>6、处理指令的格式:<? ?>7、XML文档的根元素前面命令行统成为序言。
8、如何判断XML文档是正确和有效的?A、XML文档必须满足是well-formed;B、XML文档必须满足是根据DTD来设计的文档,且这个文档的DTD语法正确。
9、XML文档的英文全称和文件的扩展名?A、全称:Extensible Markup LanguageB、文件扩展名:.xml10、可扩展文件样式单的扩展名是什么?.XSL11 、关键字CDATA表示元素包含可分析的数据。
12、比较DTD、CSS、XSL之间的区别和联系?A、区别:DTD是为验证XML文档的有效性而引入的验证机制,CSS和XSL是为了显示XML文档的显示样式而引入的,但是XSL比CSS功能更强大,更灵活,同时XSL扩展样式语言是按照XML的规则来定义的,也就是说XSL本身就是一个XML文档。
B、联系:DTD与CSS、XSL它们共同弥补,相互兼容,保证了一个XML文档的特定样式。
13、预定实体是什么?有哪些?A、概念:预定义实体指的是:系统自己已经定义好了的,开发人员可以直接引用的实体;B、常见的实体:&(&) <(<) >(>) '(‘) "(“)14、XSL文档的模版是什么?<xsl:template match=”/”></xsl:template>15、DOM文档的节点类型?Document、Element、Text、Attribute、Comment、ProcessingInstruction、CDATASection、DocumentType、Entity、Notation16、DOM创建一个元素节点的语法是什么?document.createElement("节点名")17、HTML SGML XML之间的区别和联系?A、区别:HTML是中超文本标记语言,SGML是一种结构化、可扩展的语言,是一种通用的文档结构描述置标语言;XML是中可扩展的标记语言;HTML不具有扩展性、HTML只能应用在信息的显示;而SGML和XML是可扩展的语言B、联系:HTML是SGML的一种具体应用,XML语言是SGML的子集、继承了SGML,XML语言的写法和HTML差不多,他们之间相互兼容,XML弥补了HTML标记的不足之处18、XML 是不是HTML的一个子集?(不是)19、当我们创建一个表格数据单元的宽度是不固定的。
《XML基础》复习资料1.XML标记名必须由英文字母、下划线开始,可以由英文字母、数字、下划线组成。
2.良好的XML文档要求的是有符合规范的声明语句、每个元素有正确的起始、结束标记、元素正确嵌套,没有交叉现象出现。
3.在W3C XML Schema文档中,choice元素用来声明只有一个相容元素必须出现,用于互斥情况。
4.为定义一个XML文档的结构,开发者可以使用的XML技术有DTD。
5.XML声明 <?xml version="1.0" encoding="UTF-8"?>6.Document是XML提供的编程接口,表示XML文档的根节点,代表XML本身。
7.Xml是区分大小写的,正确的xml标记如<book></book>8.W3C XML Schema文档中可以直接将其指向另一个元素定义模块,避免在文档中多次定义同一元素的元素属性是ref。
9.统一资源标识符简称为URI。
10.使用CSS,要隐藏元素,应选用display: none显示方式。
11.在CSS中,当对margin设置四个值时分别表示上、右、下、左四边的值。
12.如果需要在XML文件中显示简体中文,那么encoding的值为GB2312。
13.XML Schema中,< complexType >标签用于定义复合类型。
14.对于代码:<xs:attribute name= " age " type= " xs:integer " use= " optional " />,在xml中创建age属性时,age属性是可选的。
15.< 对应的实体是< > 对应的实体是>16.在XML文档的第一条声明语句中,能够使用的属性有version、encoding、standalone。
判断题1、下面两个元素因为所属的命名空间的前缀不一样,使得它们的合法名称也不相同。
<cust:客户xmlns:cust="/dtd/customer.dtd" /><customer:客户xmlns:customer="/dtd/customer.dtd" />2、XML文档里的元素可以嵌套,因此XML文档里的注释也能嵌套。
3、DTD对XML文档来说是必须的。
4、下面是一个格式良好的XML片断:<中国><成都>成都是一个来了就不想走的城市</成都></中国>5、最早的计算机标记语言是IBM公司研究员发明的通用标记语言(GML)。
6、XSLT 不支持编程流程控制指令,如<xsl:if>、<xsl:for-each>、<xsl:choose>等等。
7、在一个XML文档中,元素就是整个XML文档的骨架,因此在一个XML文档里可以有多个根元素和子元素。
8、空元素指的是元素没有内容,但可以有属性。
9、判断以下的XML片断是否正确。
①<Close_screen>This element used to close the screen ()</ Close_screen>②<Open_screen>This element used to open the screen ()</OPEN_SCREEN>③<enter_color “red”/> ()④<exit_color content=“blue”/> ()10、判断下面的XML名称规范是否正确。
①、_myadd ()②、12345 ()③、X_119 ()④、大家好()⑤、$mydda ()⑥、OK%789 ()⑦、xml ()⑧、中国&台湾()11、判断如下XML片断是否格式良好。
GML->SGML->XMLXML将文档看成元素的集合,每个元素由包裹着内容的标签来表示,即:XML文档=元素+标签。
分析元素:●分析元素的数量,寻找出一共要哪些元素。
这个任务通常通过观察排版格式与内容来获得,如题目、作者、段落等。
●把握元素间关系,体现XML元素层次结构化的特点。
文档结构的限制:对不同类型的文档,业界对元素出现的位置、顺序、次数等有约定XML。
对结构的约束有两套方案:DTD与XML Schema。
二者的区分在于DTD的语法与XML不同,DTD相对简单一些。
XML文档的规范性与有效性对XML文档的称呼有:规范的、合法的、有效的、结构完整的。
其实XML本身就是规范文件构造的标准。
•规范的XML文档:符合W3C制定的XML基本语法规则的文档称为规范的XML文档,也称为结构良好/完整的(well-formed)XML文档。
能够被XML解析器正确地解析,但不一定能够良好地展示数据的层次、结构、关联和含义。
•有效的XML文档:规范的XML文档再符合额外的一些约束才能称为有效的(valid)XML 文档。
很显然,“有效”比“规范”要求高。
符合XML基本语法的XML文档只是基本合格,还应在数据层次结构上作必要的约束才能更好地解析其中的数据,体现数据的层次和内容。
这种约束交给DTD或XML Schema完成。
换言之,一个规范的XML文件如果与某个DTD或XML Schema文档相挂钩,并遵守该文档约定的限制条件,那这个规范的XML文件同时也是一个有效的XML文档,或称合法的XML文档。
因此,有效=实用。
<?xml version=”1.0” encoding=”utf-8”?> -----xml声明有效的XML文档由五个部分构成•XML声明(prolog)•文档类型声明•元素•注释•处理指令名称空间:标识不同来源的数据源解决同一XML文档内部或不同XML文档出现相同标记问题。
例:只有一个根元素XML的注释以<!--注释内容-->形式标记。
注意:注释不能出现在声明前,不允许出现在标记内,不能出现连续的连字符(如---),也不能嵌套与交叉使用。
《《《《实验》》》DTD声明格式:认识DTD的基本格式<!DOCTYPE root_node[<!--DTD定义的内容-- >]>DTD的元素声明《--最有用的是子元素模式--》它是声明XML元素的语法,包括元素标记、内含子元素和元素内容数据,同时也是声明XML文档的元素架构。
1、元素类型的声明(ETD-element type definition)ETD基本格式为:<!ELEMENT 元素名元素内容模式)>元素名不得取XML保留字。
元素内容模式是指元素构成的方式与结构形态,一共有四种:空模式、任意模式、混合模式和子元素模式。
空模式(关键字EMPTY)指标记间没有任何数据,用关键字EMPTY来声明,例如:<!ELEMENT image(EMPTY) >在相应的XML文档中对应为:<image/>空元素的作用是通过存放属性提供的额外信息,它不影响XML数据的正确性。
(#PCDATA|子元素1+|子元素2*..|子元素n?)*回答:不正确,因为子元素不能加次数约束条件。
<!ELEMENT 应聘者(姓名,(本科|硕士|博士),(奖励|处分)*,(男|女))>正确否?回答:正确。
属于子元素定义集模式,<!ELEMENT message(header,body,signature,footer)>//message元素包含四个子元素,依次是header、body、signature和footer元素。
元素间的选择可以进行如下声明: <!ELEMENTelem(subelem1|subelem2|subelem3)>//将子元素用竖线进行分隔,表明elem元素的子元素为subelem1、subelem2和subelem3三者之一,但不能同时包含其中的两个或三个子元素。
混合类型若某元素既包含子元素又包含已编译的字符数据,则该元素具有混合内容。
其声明如下:<!ELEMENT music (#PCDATA | 子元素| 子元素)* >为避免产生错误,混合内容元素的声明必须遵循这一格式。
即采用单一的一组可选项,以#PCDATA开始,后面是混合内容中可能出现的子元素类型,每种只需声明一次。
除此之外,“*”必须放在右括号之后。
子元素之间的“|”符号与后面的“*”符号一起表示这些子元素出现的次数与顺序都不受限制。
混合模式中只能出现上述情况下的*。
其他的符号可以出现在子模式情况下子元素模式(没有关键字)能够实现对子元素数量、顺序和层次关系的有效约束,是DTD中最常用的方法。
子元素模式由括号、逗号、次数限制符来综合定义。
例如:<?xml version="1.0" encoding="GB2312"?><!ELEMENT 书籍列表(计算机书籍)*><!ELEMENT计算机书籍(书名,作者+,价格,简要介绍?)><!ELEMENT 书名(#PCDATA)><!ELEMENT 作者(#PCDATA)><!ELEMENT 价格(#PCDATA)><!ELEMENT 简要介绍(#PCDATA)>此DTD严格限制了书名、作者、价格与简要介绍的顺序,作者允许多个,简要介绍可有一次或没有,其它元素必须且只能出现一次。
下面是组合子元素的示例:DTD属性不能单独存在,必须依附于元素。
声明格式如下:<!ATTLIST 元素名属性名属性类型属性默认值>其中,属性类型共有十种,默认值有三种。
例:<!ATTLIST 姓名性别(男|女)#REQUIRED>这种类型属于属性列表<姓名性别=“男”>第四章schema看书和自己实验,把实验抄下来Schema分为简单类型和复杂类型只有元素才可能是复杂类型,属性只能是简单类型第5章:用css仅能控制游览器显示xml元素的文本内容,无法控制属性的显示样式1.外部引用式通过引用外部独立CSS文档来实现,格式如下:<?xml-stylesheet href=“样式表的URI” type=“text/css”? >URI如果是一个文件,则必须与XML在同一目录中。
如果是一个链接,该链接必须有效且可访问。
例如:文件方式:<?xml-stylesheet href=“show.css” type=“text/css”>链接方式:<?xml-stylesheet href=/show.csstype=“text/css”?>内嵌式<?xml-stylesheet type=“text/css”?><XML根元素xmlns:HTML=“URL”><HTML:STYLE><!-- CSS 内容--></HTML:STYLE><!-- XML 子元素-- >内联式该模式只对转换到HTML格式后的单个的标签有效,不影响整个文件XSL的基本组成与特点(实际上是一种转换)XSL实际上由三种语言、二大功能构成,三种语言是:XSLT(e X tensible S tylesheet L anguage Transformation)、XPath、XSL-FO,二大功能分别是转换与格式化。
XSL是专属XML的样式语言。
XSL的工作原理:将XML文档作为一个存储数据的树看待,称为源树;通过定义转换模板,将源树中的数据提取出来,组成一个新树,称为结果树。
值得注意:XSL在转换时并不是将被转换XML的根元素作为结果树的根元素,而是整个XML文档。
为什么呢?因为通常在一个XML文档中,在根元素之前还有处理指令(如XML文档的第一行)、版权声明和一些注释。
XSL不能遗漏这些元素。
结果树可以是带表现样式信息的可浏览文档,可以是HTML格式、FO格式或者其它面向表示方式描述的XML格式(SVG、SMIL、VRML等)。
结果树与源树独立存在,对结果树的操作不影响源树,实现数据与表示的分离。
对于FO,它是用于XSLT完成了文档转换之后,对结果树进行解释,格式化转换得到的文档。
XSL-FO当前的一个最主要应用就是将XML文档转换成PDF文档。
XSL采用的是一种转换的思想,是专门针对XML设计的。
Xsl是将一种不含显示信息的xml文档转换为另一种可以用某种游览器游览的文档,转换后的输出码或者存为一个新的文档,或者暂存于内存中,但不会修改源代码Xsl样式表结构也是一个树Xsl基本格式:Ppt一个XSL文档主要由一系列模板规则组成,一个模板规则由模式(pattern)与模板(template)组成,模式限定了需要从XML源树中哪些部位提取数据,又称匹配节点。
模板则规定了提取出的数据该如何处理。
具体而言,一个模板规则其实就是一个xs:template元素。
XSL处理器扫描XML文档时依次遍历每一棵子树,寻找与模式相匹配的子树(用template 元素中的match属性指明匹配的节点),如找到了,就将template元素内容中所包含模板规则作用于此子树。
Xpath:<可扩展路径>用于对文档中的元素、属性、文本和注释进行寻址,总是通过表达式形式出现。
Xpath的任务:描述xml文档中节点相对位置,挑选符合条件的节点与xslt密切配合完成xml的转换任务与xpointer配合实现节点定位功能Xpath是怎样定位的:(定位路径用于指定如何在XPath树结构中实现从一个节点到另一个节点地浏览(导航))定位路径是一个表达式,由定位步骤组成,每一个步骤又由一个“轴”、一个“节点测试”和一个可选的“谓词”组成。
由“轴”到“节点测试”再到“谓词”,是一个定位逐步精确的过程。
XPath中“步”的概念可以与文件管理中目录结构相比对轴(axis):概念轴定义了在XML文档中基于上下文节点的搜索范围。
XML文档在解析时当作节点树来处理,而轴总是以某个指定节点为起点,进而寻找节点树中的其它某些节点。
轴是XPath的表达式的前缀,表达式的书写方式就是以轴名开始,后跟两个冒号,即“: : ”,再跟表示节点的XPath表达式的其它内容。
例如:child::* 表示当前节点的所有子轴上的元素;child::a就表示当前节点子轴上所有的a元素;A/child::*表示A节点的所有子轴上的元素节点。
轴的分类按照导航路径,轴被分成13类。
下面是各个轴的简介:轴名称(大概了解一下名称的意义)1 前驱轴:preceding axis2 前驱兄弟轴:preceding-sibliing3 后继轴:following axis4 后继兄弟轴:following-sibling axis5 子轴:child axis6 父轴:parent axis7 属性轴:attribute axis8 后代轴:descedant axis9 祖先轴:ancestor axis10 本身轴:self axis11 后代或本身轴:descendant-or-self axis12 祖先或本身轴:ancestor-or-self axis13 名称空间轴:namespace axis谓词:根据轴和节点测试得到初步节点后,用谓词可做进一步的过滤。