第2章 双变量回归分析:一些基本概念
- 格式:ppt
- 大小:676.50 KB
- 文档页数:25




第二讲 双变量回归模型及其估计问题双变量回归分析基本概念四、 正态性假定:经典正态线性回归模型 五、 双变量回归的区间估计七、 回归分析的应用:预测问题 八、 双变量线性回归模型的延伸回归分析的基本性质三、 双变量回归分析估计问题六、 双变量回归的假设检验 4、第一节回归分析的性质•、回归释义回归分析是关于研究一个叫应变量的变量对另一个或几个中解释变量的变量的依赖关系,其目的在于通过后者的已知值或设定值去估计和预测前者的数值。
二、统计关系与确定关系统计关系处理的是随机变量,而确定关系处理的是确定性的变量。
三、回归与因果关系回归分析研究的是一个变量对另一个或几个称为解释变量的依赖关系,却不一定是因果关系。
四、回归与相关相关分析的主要目的在于研究变量之间统计线性关联的程度,将变量均视为随机变量。
回归分析的主要目的在于研究变量之间统计关联的形式,目的在于揭示被解释变量如何依赖解释变量的变化而变化的规律,将解释变量视为确定性的,而将被解释变量视为随机变量。
第二节双变量回归分析的基本概念(1)•、一个人为的例子例:假定一个总体由60户家庭组成。
为了研 究每周家庭消费支出Y 与每周税后可支配收入 X 的关系,将他们划分为10组。
第二节二、总体回归函数(PRF)E(Y\X)=f(X)E(Y\X) = + 卩?X三、线性的含义对变量为线性E(Y\X) = fij + fi2X对参数为线性E(Y\X) = /3j + /32lnX1、总体回归函数的随机设定u = y-E(KIX)Y=E(Y\X)+ u系统变化部分非系统变化部分四、随机干扰项的意义干扰项“是从模型中省略下来的而又集体地影响着F的全部变量的替代物。
1.理论的含糊性 5.糟糕的替代变量2.数据的欠缺 6.节省原则3.核心变量与周边变量7.错误的函数形式4.人为行为的内在随机性五、样本回归函数(SRF)E(YIX)二Q + QX/V /v /VY =氏+卩字Y 仝 +£I =B\+B/+狂i i残差第三节双变量回归模型的估计问题•、普通最小二乘法通过样本数据按照残差平方和最小的原则来估计总体回归模型中的参数的方法叫普通最小二乘法,又称最小平方法。




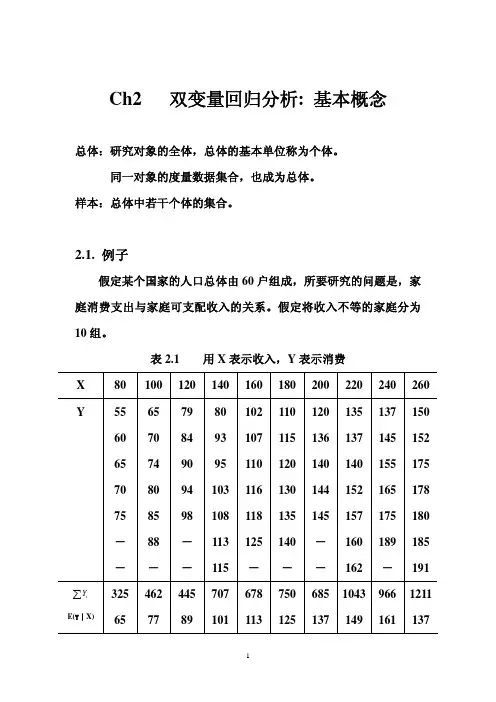
Ch2 双变量回归分析: 基本概念总体:研究对象的全体,总体的基本单位称为个体。
同一对象的度量数据集合,也成为总体。
样本:总体中若干个体的集合。
2.1. 例子假定某个国家的人口总体由60户组成,所要研究的问题是,家庭消费支出与家庭可支配收入的关系。
假定将收入不等的家庭分为10组。
表2.1 用X 表示收入,Y 表示消费X80 100 120 140 160 180 200 220 240 260Y 55 65 79 80 102 110 120 135 137 150 60 70 84 93 107 115 136 137 145 152 65 74 90 95 110 120 140 140 155 175 70 80 94 103 116 130 144 152 165 178 75 85 98 108 118 135 145 157 175 180 - 88 - 113 125 140 - 160 189 185-- - 115 - - -162-191iY ∑E(Y︱X)325 65462 77445 89707 101678 113750 125685 1371043 149966 1611211137条件概率与条件期望。
p(Y=60/X=80)=1/5p(Y=65/X=80)=1/5,p(Y=70/X=80)=1/5 p(Y=75/X=80)=1/5进而根据条件概率,我们可计算条件期望(均值),即1()55(1/5)60(1/5)65(1/5)70(1/5)75(1/5)65E Y X X ==++++=图2.1 总体回归直线对应X 的不同水平,Y 的条件期望(均值)的变化,由于Y 的条件均值是对于给定X 的值而对于相应的所有Y 的值求条件均值,因此称为总体回归直线(PRL )。
2.2. PRL 函数Y 的条件均值为函数,因此将Y 的条件均值表述为i X )()(i i X f X Y E = (2.1)称(2.1)为双变量总体回归函数。


[计量经济学] 第二章:双变量线性回归分析§1 经典正态线性回归模型(CNLRM)一、一些基本概念1、一个例子条件分布:以X取定值为条件的Y的条件分布条件概率:给定X的Y的概率,记为P(Y|X)。
例如,P(Y=55|X=80)=1/5;P(Y=150|X=260)=1/7。
条件期望(conditional Expectation):给定X的Y的期望值,记为E(Y|X)。
例如,E(Y|X=80)=55×1/5+60×1/5+65×1/5+70×1/5+75×1/5=65总体回归曲线(Popular Regression Curve)(总体回归曲线的几何意义):当解释变量给定值时因变量的条件期望值的轨迹。
2、总体回归函数(PRF)E(Y|X i)=f(X i)当PRF的函数形式为线性函数,则有,E(Y|X i)=β1+β2X i其中β1和β2为未知而固定的参数,称为回归系数。
β1和β2也分别称为截距和斜率系数。
上述方程也称为线性总体回归函数。
3、PRF的随机设定将个别的Y I围绕其期望值的离差(Deviation)表述如下:u i=Y i-E(Y|X i)或Y i=E(Y|X i)+u i其中u i是一个不可观测的可正可负的随机变量,称为随机扰动项或随机误差项。
4、“线性”的含义“线性”可作两种解释:对变量为线性,对参数为线性。
本课“线性”回归一词总是指对参数β为线性的一种回归(即参数只以它的1次方出现)。
模型对参数为线性?模型对变量为线性?是不是是LRM LRM不是NLRM NLRM注:LRM=线性回归模型;NLRM=非线性回归模型。
5、随机干扰项的意义随机扰动项是从模型中省略下来的而又集体地影响着Y 的全部变量的替代物。
显然的问题是:为什么不把这些变量明显地引进到模型中来?换句话说,为什么不构造一个含有尽可能多个变量的复回归模型呢?理由是多方面的: (1)理论的含糊性 (2)数据的欠缺(3)核心变量与周边变量 (4)内在随机性 (5)替代变量 (6)省略原则(7)错误的函数形式6、样本回归函数(SRF ) (1)样本回归函数iY ˆ=1ˆβ+2ˆβi X 其中Y ˆ=E(Y|X i )的估计量;1ˆβ=1β的估计量;2ˆβ=2β的估计量。
第二章回归分析中的几个基本概念1. 回归模型(Regression Model):回归模型是回归分析的基础,用来描述两个或多个变量之间的关系。
回归模型通常包括一个或多个自变量和一个或多个因变量。
常用的回归模型有线性回归模型和非线性回归模型。
线性回归模型是最简单的回归模型,其中自变量和因变量之间的关系可以用一条直线来表示。
线性回归模型的表达式为:Y=β0+β1*X1+β2*X2+...+βn*Xn+ε其中,Y表示因变量,X1、X2、…、Xn表示自变量,β0、β1、β2、…、βn表示回归系数,ε表示误差项。
2. 回归系数(Regression Coefficients):回归系数是回归模型中自变量的系数,用来描述自变量对因变量的影响程度。
回归系数可以通过最小二乘法估计得到,最小二乘法试图找到一组系数,使得模型的预测值和实际观测值的误差平方和最小。
回归系数的符号表示了自变量与因变量之间的方向关系。
如果回归系数为正,表示自变量的增加会使因变量增加,即存在正向关系;如果回归系数为负,表示自变量的增加会使因变量减少,即存在负向关系。
3. 拟合优度(Goodness-of-fit):拟合优度是用来评估回归模型对样本数据的拟合程度。
通常使用R方(R-squared)来度量拟合优度。
R 方的取值范围在0到1之间,越接近1表示模型对数据的拟合程度越好。
R方的解释是,回归模型中自变量的变异能够解释因变量的变异的比例。
例如,如果R方为0.8,表示模型中自变量解释了因变量80%的变异,剩下的20%可能由其他未考虑的因素引起。
4. 显著性检验(Significance Test):显著性检验用于判断回归模型中自变量的系数是否显著不为零,即自变量是否对因变量有显著影响。
常用的方法是计算t值和p值进行检验。
t值是回归系数除以其标准误得到的统计量。
p值是t值对应的双侧检验的概率。
如果p值小于给定的显著性水平(通常是0.05),则可以拒绝原假设,即认为回归系数显著不为零,即自变量对因变量有显著影响。