生物信息数据库(二)
- 格式:ppt
- 大小:1.56 MB
- 文档页数:51

生物信息学数据库分类整理汇总生物信息学数据库是存储和管理生物学领域的大量数据的重要工具和资源,对于生物信息学研究、基因组学、蛋白质组学、转录组学等领域的研究具有重要的意义。
本文将对生物信息学数据库进行分类整理和汇总,方便生物信息学研究者更好地使用和了解这些数据库。
1.基因组数据库:- GenBank:美国国家生物技术信息中心(NCBI)维护的基因序列数据库,包含已知基因的核酸序列。
- Ensembl:英国恩格斯尔基因组项目维护的一个综合性基因组数据库,包含多种物种的基因组数据。
- UCSC Genome Browser:加利福尼亚大学圣克鲁兹分校开发的一个基因组浏览器,提供多种物种的基因组序列和注释信息。
2.蛋白质数据库:- UniProt:一个综合性的蛋白质数据库,集成了多个蛋白质序列和注释信息资源。
- Protein Data Bank (PDB):存储大量已解析的蛋白质结构数据的数据库,提供原子级别的结构信息。
- Protein Information Resource (PIR):收集和整理蛋白质序列、结构和功能信息的数据库。
3.转录组数据库:- NCBI Gene Expression Omnibus (GEO):存储和共享大量的高通量基因表达数据的数据库。
- ArrayExpress:欧洲生物信息学研究所(EBI)开发的一个基因表达数据库,包含多种生物组织和疾病的表达数据。
4.疾病数据库:- Online Mendelian Inheritance in Man (OMIM):记录人类遗传疾病和相关基因的数据库。
- Orphanet:收集和整理罕见疾病和相关基因的数据库。
5.代谢组数据库:- Human Metabolome Database (HMDB):一个综合性的人类代谢物数据库,包括代谢产物的结构和功能信息。
- Kyoto Encyclopedia of Genes and Genomes (KEGG):包含多种生物体代谢途径的数据库。


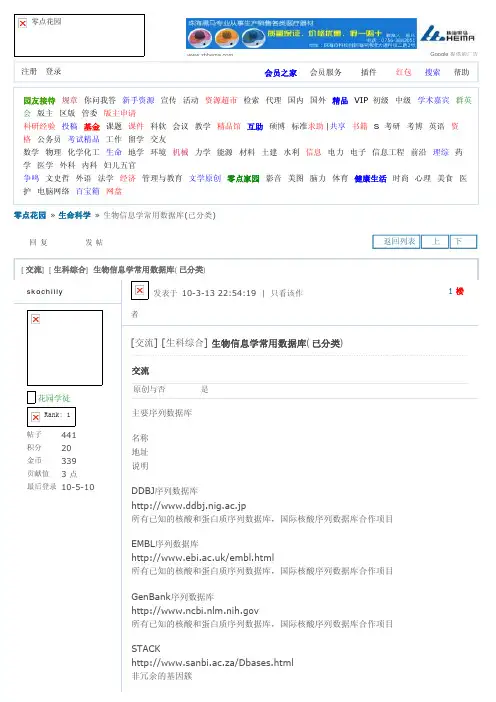






常用的生物数据库(二)引言概述:生物数据库是生物信息学领域的重要工具,可以帮助研究人员存储、管理和共享生物数据。
本文将介绍常用的生物数据库(二),以便研究人员更好地利用这些资源进行生物学研究。
正文内容:一、蛋白质相互作用数据库1. STRING数据库:提供蛋白质相互作用预测和注释功能。
2. IntAct数据库:收集整理蛋白质相互作用数据,提供数据检索和分析工具。
3. BioGRID数据库:整合多种物种的蛋白质相互作用数据,并提供丰富的功能注释。
二、基因组数据库1. GenBank数据库:包含大量的序列数据,包括基因组、转录本和蛋白质序列等。
2. ENSEMBL数据库:集成了各种生物信息学工具,提供全面的基因组注释信息。
3. UCSC数据库:基于人类基因组构建的浏览器,提供详细的基因组注释和可视化功能。
三、表达谱数据库1. GEO数据库:收集了大量的基因表达谱数据,可进行数据检索和分析。
2. ArrayExpress数据库:包含了来自各种高通量技术的表达谱数据,提供数据下载和分析工具。
3. TCGA数据库:整合了多种癌症的基因表达数据,可进行差异表达和生存分析等研究。
四、突变数据库1. dbSNP数据库:记录了常见的单核苷酸多态性(SNP)数据,是研究遗传变异的重要资源。
2. COSMIC数据库:专注于癌症相关的突变数据,包含了大量的突变谱系和功能注释信息。
3. ClinVar数据库:整合了与人类疾病相关的遗传变异数据,提供临床相关的注释信息。
五、药物数据库1. DrugBank数据库:收录了大量的药物信息,包括结构、作用机制和药理学数据等。
2. PubChem数据库:提供了大量的小分子化合物数据,可进行化学结构搜索和药物筛选等研究。
3. ChEMBL数据库:整合了化合物活性数据和药物靶点信息,可用于药物发现和优化。
总结:生物数据库为生物学研究提供了丰富的数据资源和分析工具。
蛋白质相互作用数据库、基因组数据库、表达谱数据库、突变数据库和药物数据库是常用的生物数据库之一。
■一、选择题:1.以下哪一个是mRNA条目序列号: A. J01536■. NM_15392 C. NP_52280D. AAB1345062.确定某个基因在哪些组织中表达的最直接获取相关信息方式是:■. Unigene B.Entrez C. LocusLink D. PCR3.一个基因可能对应两个Unigene簇吗?■可能 B. 不可能4.下面哪种数据库源于mRNA信息:■dbEST B. PDB C. OMIM D.HTGS5.下面哪个数据库面向人类疾病构建: A. EST B. PDB ■. OMIMD. HTGS6.Refseq和GenBank有什么区别: A. Refseq包括了全世界各个实验室和测序项目提交的DNA序列B. GenBank提供的是非冗余序列■. Refseq源于GenBank,提供非冗余序列信息D. GenBank源于Refseq7.如果你需要查询文献信息,下列哪个数据库是你最佳选择: A. OMIM B. Entrez■PubMed D. PROSITE8.比较从Entrez和ExPASy中提取有关蛋白质序列信息的方法,下列哪种说法正确:A. 因为GenBank的数据比EMBL更多,Entrez给出的搜索结果将更多B. 搜索结果很可能一样,因为GenBank和EMBL的序列数据实际一样■搜索结果应该相当,但是ExPASy 中的SwissProt记录的输出格式不同9.天冬酰胺、色氨酸和酪氨酸的单字母代码分别对应于:■N/W/Y B. Q/W/YC. F/W/YD. Q/N/W10.直系同源定义为:■不同物种中具有共同祖先的同源序列B. 具有较小的氨基酸一致性但是有较大的结构相似性的同源序列C. 同一物种中由基因复制产生的同源序列D. 同一物种中具有相似的并且通常是冗余的功能的同源序列11.下列那个氨基酸最不容易突变: A. 丙氨酸 B. 谷氨酰胺 C. 甲硫氨酸■半胱氨酸12.PAM250矩阵定义的进化距离为两同源序列在给定的时间有多少百分比的氨基酸发生改变: A. 1% B. 20%■. 80% D. 250%13.下列哪个句子最好的描述了两个序列全局比对和局部比对的不同:A. 全局比对通常用于比对DNA序列,而局部比对通常用于比对蛋白质序列B. 全局比对允许间隙,而局部比对不允许C. 全局比对寻找全局最大化,而局部比对寻找局部最大化■全局比对比对整体序列,而局部比对寻找最佳匹配子序列14.假设你有两条远源相关蛋白质序列。
生物信息学数据库的种类1.引言1.1 概述生物信息学数据库是由生物学和计算机科学相结合的一个重要领域。
随着高通量测序技术的快速发展, 生物学研究已经进入了“大数据”时代。
生物信息学数据库的出现, 解决了这些海量生物信息的存储和管理问题, 为生命科学研究提供了重要的工具和资源。
生物信息学数据库可以存储和管理各种类型的生物信息数据, 对于科学家和研究人员来说, 这些数据库包含了大量的基因组序列、蛋白质序列、基因表达数据等重要信息。
通过对这些数据的分析和挖掘, 科学家们可以更深入地研究生物体的组成、功能和进化等方面。
在当前的生物信息学数据库中, 可以根据数据类型进行分类。
常见的生物信息学数据库包括序列数据库、结构数据库、基因表达数据库、蛋白质互作数据库、药物数据库、多样性数据库、基因组数据库、疾病数据库和转录因子数据库等。
每种类型的数据库都有其独特的特点和应用领域。
随着生物学研究的不断深入和技术的不断进步, 生物信息学数据库也在不断发展。
未来的数据库将更加注重数据的互联互通, 提供更完整、准确和可靠的生物信息。
同时, 数据分析和挖掘的算法和工具也将不断更新和完善, 为科学家们的研究提供更加强大的支持。
总之, 生物信息学数据库是生物学研究中不可或缺的重要工具和资源。
通过这些数据库, 科学家们可以更加高效地存储、管理和分析生物信息,推动生命科学领域的发展。
未来, 随着生物学研究的不断进步, 生物信息学数据库将不断发展和完善, 为科学家们带来更多的可能性和突破。
1.2 文章结构本文将分为三个部分来详细介绍生物信息学数据库的种类。
首先,在引言部分,我们将提供对本文的概述,介绍生物信息学数据库的基本概念和作用,并说明文章的目的。
接下来,在正文部分,我们将详细介绍九种不同类型的生物信息学数据库,包括序列数据库、结构数据库、基因表达数据库、蛋白质互作数据库、药物数据库、多样性数据库、基因组数据库、疾病数据库和转录因子数据库。
1.生物信息学(bioinformatics):是一门综合运用生物学、数学、物理学、信息科学以及计算机科学等诸多学科的理论方法,以互联网为媒介、数据库为载体、利用数学和计算机科学对生物学数据进行储存、检索和处理分析,并进一步挖掘和解读生物学数据。
2.Genom基因组:某一物种的一套完整染色体组中的所有遗传物质。
其大小一般以其碱基对总数表示的表格。
3.数据库查询(database query):是指对序列、结构以及各种二次数据中的注释信息进行关键词匹配查找检索。
4.数据库搜索(database search):在分子生物信息学中有特定含义,它是指通过特定的序列相似性比对算法,找出核酸或蛋白质序列数据库中与检测序列具有一定程度相似性的序列。
Entrez检索系统:是NCBI开发的核心检索系统,集成了NCBI的各种数据库,具有链接的数据库多,使用方便,能够进行交叉索引等特点。
5.BLAST:基本局部比对搜索工具,用于相似性搜索的工具,对需要进行检索的序列与数据库中的每个序列做相似性比较。
6.Alignment:比对,从核酸以及氨基酸的层次去分析序列的相同点和不同点,以期能够推测它们的结构、功能以及进化上的联系。
7.表达序列标签(EST):某个基因cDNA克隆测序所得的部分序列片段,长度约为200-600bp。
EST可以定位出基因在genome上的位置。
8.开放阅读框(ORF):开放阅读框是基因序列的一部分,包含一段可以编码蛋白的碱基序列。
In Silico Cloning电子克隆:利用种子序列从EST及UniGene数据库中搜索相似性序列,进行拼装、检索、分析等,以此获得目标基因的全称cDNA,在此基础上也能够实现基因作图定位。
9.Contig:即重叠群,把含有STS序列标签位点的基因片段分别测序后,重叠分析就可以得到完整的染色体基因组序列。
10.Homology modeling同源建模:是目前最为成功且实用的蛋白质结构预测方法,它的前提是已知一个或多个同源蛋白质的结构。
生物信息学(bioinformatics):是一门交叉学科,它包含了生物信息的获取,处理,存储,分发,分析和解释等在内的所以方面,它综合运用数学,计算机科学和生物学的各种工具,来阐明和理解大量数据所包含的生物学意义。
目的:揭示"基因组信息结构的复杂性及遗传语言的根本规律",解释生命的遗传语言。
方法:主要有创建一切适用于基因组信息分析的新方法,改进现有的理论分析方法,发展有效的能支持大尺度作图与测序需要的软件、数据库以及若干数据库工具等。
应用:生物信息的存储与获取,序列比对,测序与拼接,基因预测,生物进化与系统发育分析,蛋白质结构预测,RNA结构预测,分子设计与药物设计,代谢网络分析,基因芯片,DNA计算等。
1.1.3生物信息学的研究内容1、序列比对(Alignment)。
2、结构比对。
基本问题是比较两个或两个以上蛋白质分子空间结构的相似性或不相似性。
已有一些算法。
3、蛋白质结构预测,包括2级和3级结构预测,是最重要的课题之一。
4、计算机辅助基因识别(仅指蛋白质编码基因)。
5、非编码区分析和DNA语言研究,是最重要的课题之一。
6、分子进化和比较基因组学,是最重要的课题之一。
7、序列重叠群(Contigs)装配。
8、遗传密码的起源。
9、基于结构的药物设计。
10、其他。
如基因表达浦分析,代谢网络分析;基因芯片设计和蛋白质组学数据分析等,逐渐成为生物信息学中新兴的重要研究领域。
这里不再赘述。
3、开放式阅读框(ORF):是基因的起始密码子开始到终止密码子为止的一个连续编码的序列。
5、中心法则:包括DNA的自我复制,转录形成RNA并翻译成蛋白质,RNA的自我复制和逆转录的过程。
6序列比对(alignment):为确定两个或多个序列之间的相似性以至于同源性,而将它们按照一定的规律排列。
6、算法分析:评价一个算法的优劣,通过时间复杂度和空间复杂度来确定。
7、数据库管理系统:(database management system,DBMS)对DB进行管理的系统工程,提供DB的建立、查询、更新以及各种数据控制能。