判别分析与聚类分析方法
- 格式:pdf
- 大小:495.25 KB
- 文档页数:8



「聚类分析与判别分析」聚类分析和判别分析是数据挖掘和统计学中常用的两种分析方法。
聚类分析是一种无监督学习方法,通过对数据进行聚类,将相似的样本归为一类,不同的样本归入不同的类别。
判别分析是一种有监督学习方法,通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
本文将对聚类分析和判别分析进行详细介绍。
聚类分析是一种数据探索技术,其目标是在没有任何先验知识的情况下,将相似的样本聚集在一起,形成互相区别较大的样本群。
聚类算法根据样本的特征,将样本分为若干个簇。
常见的聚类算法有层次聚类、k-means聚类和密度聚类。
层次聚类是一种自下而上或自上而下的层次聚合方法,通过测量样本间的距离或相似性,不断合并或分裂簇,最终形成一个聚类树状结构。
k-means聚类将样本划分为k个簇,通过优化目标函数最小化每个样本点与其所在簇中心点的距离来确定簇中心。
密度聚类基于样本点的密度来判断是否属于同一簇,通过划定一个密度阈值来确定簇的分界。
聚类分析在很多领域中都有广泛的应用,例如市场分割、医学研究和社交网络分析。
在市场分割中,聚类分析可以将消费者按照其购买行为和偏好进行分组,有助于企业制定更精准的营销策略。
在医学研究中,聚类分析可以将不同患者分为不同的亚型,有助于个性化的治疗和药物开发。
在社交网络分析中,聚类分析可以将用户按照其兴趣和行为进行分组,有助于推荐系统和社交媒体分析。
相比之下,判别分析是一种有监督学习方法,其目标是通过学习已知类别的样本,构建分类模型,然后应用模型对未知样本进行分类预测。
判别分析的目标是找到一个决策边界,使得同一类别内的样本尽可能接近,不同类别之间的样本尽可能远离。
常见的判别分析算法有线性判别分析(LDA)和逻辑回归(Logistic Regression)。
LDA是一种经典的线性分类方法,它通过对数据进行投影,使得同类样本在投影空间中的方差最小,不同类样本的中心距离最大。
逻辑回归是一种常用的分类算法,通过构建一个概率模型,将未知样本划分为不同的类别。

SPSS统计分析第八章聚类分析与判别分析聚类分析与判别分析是SPSS统计分析中非常重要的两个方法。
聚类分析是寻找数据之间的相似性,将相似的数据划分为一个簇,从而实现对数据的归类和分组。
判别分析则是寻找数据之间的差异性,帮助我们理解不同因素对于数据的影响程度,从而实现对数据的分类预测。
首先,我们来介绍聚类分析。
聚类分析是根据数据之间的相似性进行归类的一种方法,通过度量数据之间的相似性,将相似的数据归为一类。
它在寻找数据内在组织结构和特点上具有很大的作用。
在SPSS中进行聚类分析的步骤如下:1.载入数据集:在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行聚类分析的数据集。
2.选择聚类变量:在"分析"->"分类"->"聚类"中,选择需要进行聚类分析的变量。
可以选择一个或多个变量作为聚类变量,决定了聚类的维度。
3.设置聚类参数:在设置参数的对话框中,可以选择使用不同的距离测度和聚类算法。
距离测度可以选择欧氏距离、曼哈顿距离、切比雪夫距离等,而聚类算法可以选择层次聚类、K均值聚类等。
根据具体的数据特点,选择合适的参数。
4.进行聚类分析:点击"确定"按钮,SPSS会自动进行聚类分析,并生成聚类的结果。
聚类结果可以通过树状图、散点图等形式展示,便于我们对数据的理解和分析。
接下来,我们来介绍判别分析。
判别分析是一种通过建立数学模型,根据不同的预测变量对数据进行分类和预测的方法。
判别分析可以帮助我们理解不同因素对于数据分类的重要性,从而进行有针对性的分析和预测。
在SPSS中进行判别分析的步骤如下:1.载入数据集:同样,在SPSS软件中,选择"文件"->"打开"->"数据",选择需要进行判别分析的数据集。


第一节聚类分析统计思想一、聚类分析的基本思想1.什么是聚类分析俗语说,物以类聚、人以群分。
当有一个分类指标时,分类比较容易。
但是当有多个指标,要进行分类就不是很容易了。
比如,要想把中国的县分成若干类,可以按照自然条件来分:考虑降水、土地、日照、湿度等各方面;也可以考虑收入、教育水准、医疗条件、基础设施等指标;对于多指标分类,由于不同的指标项对重要程度或依赖关系是相互不同的,所以也不能用平均的方法,因为这样会忽视相对重要程度的问题。
所以需要进行多元分类,即聚类分析。
最早的聚类分析是由考古学家在对考古分类中研究中发展起来的,同时又应用于昆虫的分类中,此后又广泛地应用在天气、生物等方面。
对于一个数据,人们既可以对变量(指标)进行分类(相当于对数据中的列分类),也可以对观测值(事件,样品)来分类(相当于对数据中的行分类)。
2.R型聚类和Q型聚类对变量的聚类称为R型聚类,而对观测值聚类称为Q型聚类。
这两种聚类在数学上是对称的,没有什么不同。
聚类分析就是要找出具有相近程度的点或类聚为一类;如何衡量这个“相近程度”?就是要根据“距离”来确定。
这里的距离含义很广,凡是满足4个条件(后面讲)的都是距离,如欧氏距离、马氏距离…,相似系数也可看作为距离。
二、如何度量距离的远近:统计距离和相似系数1.统计距离距离有点间距离好和类间距离2.常用距离统计距离有多种,常用的是明氏距离。
3.相似系数当对个指标变量进行聚类时,用相似系数来衡量变量间的关联程度,一般地称为变量和间的相似系数。
常用的相似系数有夹角余弦、相关系数等。
夹角余弦:相关系数:对于分类变量的研究对象的相似性测度,一般称为关联测度。
第二节如何进行聚类分析一、系统聚类1.系统聚类的基本步骤2.最短距离法3.最长距离法4.重心法和类平均法5.离差平方和法二、SPSS中的聚类分析1、事先要确定分多少类:K均值聚类法;2、事先不用确定分多少类:分层聚类;分层聚类由两种方法:分解法和凝聚法。
聚类分析及判别分析案例⼀、案例背景随着现代⼈⼒资源管理理论的迅速发展,绩效考评技术⽔平也在不断提⾼。
绩效的多因性、多维性,要求对绩效实施多标准⼤样本科学有效的评价。
对企业来说,对上千⼈进⾏多达50~60个标准的考核是很常见的现象。
但是,⽬前多标准⼤样本⼤型企业绩效考评问题仍然困扰着许多⼈⼒资源管理从业⼈员。
为此,有必要将当今国际上最流⾏的视窗统计软件SPSS应⽤于绩效考评之中。
在分析企业员⼯绩效⽔平时,由于员⼯绩效⽔平的指标很多,各指标之间还有⼀定的关联性,缺乏有效的⽅法进⾏⽐较。
⽬前较理想的⽅法是⾮参数统计⽅法。
本⽂将列举某企业的具体情况确定适当的考核标准,采⽤主成分分析以及聚类分析⽅法,⽐较出各员⼯绩效⽔平,从⽽为企业绩效管理提供⼀定的科学依据。
最后采⽤判别分析建⽴判别函数,同时与原分类进⾏⽐较。
聚类分析⼆、绩效考评的模型建⽴1、为了分析某企业绩效⽔平,按照综合性、可⽐性、实⽤性和易操作性的选取指标原则,本⽂选择了影响某企业绩效⽔平的成果、⾏为、态度等6个经济指标(见表1)。
2、对某企业,搜集整理了28名员⼯2009年第1季度的数据资料。
构建1个28×6维的矩阵(见表2)。
3、应⽤SPSS数据统计分析系统⾸先对变量进⾏及主成分分析,找到样本的主成分及各变量在成分中的得分。
去结果中的表3、表4、表5备⽤。
表 5成份得分系数矩阵a成份1 2Zscore(X1) .227 -.295Zscore(X2) .228 -.221Zscore(X3) .224 -.297Zscore(X4) .177 -.173Zscore(X5) .186 .572Zscore(X6) .185 .587提取⽅法 :主成份。
构成得分。
a. 系数已被标准化。
4、从表3中可得到前两个成分的特征值⼤于1,分别为3.944和1.08,所以选取两个主成分。
根据累计贡献率超过80%的⼀般选取原则,主成分1和主成分2的累计贡献率已达到了83.74%的⽔平,表明原来6个变量反映的信息可由两个主成分反映83.74%。



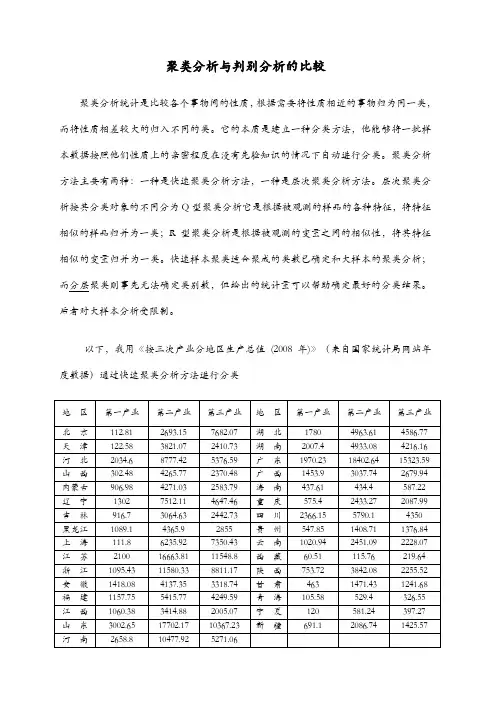
聚类分析与判别分析的比较聚类分析统计是比较各个事物间的性质,根据需要将性质相近的事物归为同一类,而将性质相差较大的归入不同的类。
它的本质是建立一种分类方法,他能够将一批样本数据按照他们性质上的亲密程度在没有先验知识的情况下自动进行分类。
聚类分析方法主要有两种:一种是快速聚类分析方法,一种是层次聚类分析方法。
层次聚类分析按其分类对象的不同分为Q型聚类分析它是根据被观测的样品的各种特征,将特征相似的样品归并为一类;R型聚类分析是根据被观测的变量之间的相似性,将其特征相似的变量归并为一类。
快速样本聚类适合聚成的类数已确定和大样本的聚类分析;而分层聚类则事先无法确定类别数,但给出的统计量可以帮助确定最好的分类结果。
后者对大样本分析受限制。
以下,我用《按三次产业分地区生产总值(2008年)》(来自国家统计局网站年度数据)通过快速聚类分析方法进行分类结果分析:从输出结果可以看出,当样本层次聚类分析成3个类时,样本的类归属情况:第一类包括7个省:北京、上海、安徽、福建、湖南、湖北、四川;第二类包含17个省:天津、山西、内蒙古、吉林、黑龙江、江西、广西、海南、重庆、贵州、云南、西藏、陕西、甘肃、青海、宁夏、新疆;第三类包含4省:河北、辽宁、浙江、河南;第四类包含3个省:江苏、山东、广东判别分析是另一种处理分类分体的统计方法。
它是先根据已知类别的事物的性质,建立函数式,然后对未知类别的新事物进行判断以将之归入已知的类别中。
判别分析的内容十分丰富,按照已知分类的多少,分成两组判别喝多组判别;按照判别方法分为逐步判别和序贯判别;按照判别则分为距离判别、贝叶斯判别和费歇判别等。
通过聚类分析我们已经知道以上31个省的分类情况,现在将福建、江西、山东、河南四个省的聚类结果删除掉。
然后进行判别分析。
得出结果如上图,福建,江西,山东,河南四省的判别结果与之前分类结果一样。
典型判别式函数系数函数1 2 3第一产业.000 .002 .001第二产业.001 -.001 .000第三产业.000 .001 .000(常量) -3.744 -1.017 -.516非标准化系数由此图得出三个函数(X1,X2,X3分别为第一产业、第二产业、第三产业)D1=-3.744+0.001X2D2==1.017+0.002X1-0.001X2+0.001X3D3=-0.516+0.001X1通过聚类分析和判别分析,我们得到了31省的分类结果。
判别分析(Discriminant Analysis)一、概述:判别问题又称识别问题,或者归类问题。
判别分析是由Pearson于1921年提出,1936年由Fisher首先提出根据不同类别所提取的特征变量来定量的建立待判样品归属于哪一个已知类别的数学模型。
根据对训练样本的观测值建立判别函数,借助判别函数式判断未知类别的个体。
所谓训练样本由已知明确类别的个体组成,并且都完整准确地测量个体的有关的判别变量。
训练样本的要求:类别明确,测量指标完整准确。
一般样本含量不宜过小,但不能为追求样本含量而牺牲类别的准确,如果类别不可靠、测量值不准确,即使样本含量再大,任何统计方法语法弥补这一缺陷。
判别分析的类别很多,常用的有:适用于定性指标或计数资料的有最大似然法、训练迭代法;适用于定量指标或计量资料的有:Fisher二类判别、Bayers多类判别以及逐步判别。
半定量指标界于二者之间,可根据不同情况分别采用以上方法。
类别(有的称之为总体,但应与population的区别)的含义——具有相同属性或者特征指标的个体(有的人称之为样品)的集合。
如何来表征相同属性、相同的特征指标呢?同一类别的个体之间距离小,不同总体的样本之间距离大。
距离是一个原则性的定义,只要满足对称性、非负性和三角不等式的函数就可以称为距绝对距离马氏距离:(Manhattan distance)设有两个个体(点)X与Y(假定为一维数据,即在数轴上)是来自均数为μ,协方差阵为∑的总体(类别)A的两个个体(点),则个体X与Y的马氏距离为(,)X与总体(类别)A的距离D X Y=(,)为D X A=明考斯基距离(Minkowski distance):明科夫斯基距离欧几里德距离(欧氏距离)二、Fisher两类判别一、训练样本的测量值A类训练样本编号 1x 2xm x1 11A x 12A x 1A m x 221A x22A x2A m xA n1A An x 2A An xA An m x 均数1A x2A xAm xB 类训练样本编号 1x 2x m x1 11B x 12B x 1B m x 221B x22B x2B m xB n1B Bn x 2B Bn x B Bn m x 均数1B x2B xBm x二、建立判别函数(Discriminant Analysis Function)为:1122m m Y C X C X C X =+++其中:1C 、2C 和m C 为判别系数(Discriminant Coefficient ) 可解如下方程组得判别系数。