语音信号处理_考试参考题(修订版)(1)
- 格式:doc
- 大小:277.00 KB
- 文档页数:5

语音信号处理重点、考点、考试题一、填空题:(共7小题,每空2分,共20分)A卷1、矢量量化系统主要由编码器和组成,其中编码器主要是由搜索算法和构成。
2、基于物理声学的共振峰理论,可以建立起三种实用的共振峰模型:级联型、并联型和。
3、语音编码按传统的分类方法可以分为、和混合编码。
4、对语音信号进行压缩编码的基本依据是语音信号的和人的听觉感知机理。
5、汉语音节一般由声母、韵母和三部分组成。
6、人的听觉系统有两个重要特性,一个是耳蜗对于声信号的时频分析特性;另一个是人耳听觉的效应。
7、句法的最小单位是,词法的最小单位是音节,音节可以由构成。
二、判断题:(共3小题,每小题2分,共6分)1、预测编码就是利用对误差信号进行编码来降低量化所需的比特数,从而使编码速率大幅降低。
()2、以线性预测分析-合成技术为基础的参数编码,一般都是根据语音信号的基音周期和清/浊音标志信息来决定要采用的激励信号源。
()3、自适应量化PCM就是一种量化器的特性,能自适应地随着输入信号的短时能量的变化而调整的编码方法。
()三、单项选择题:(共3小题,每小题3分,共9分)1、下列不属于衡量语音编码性能的主要指标是()。
(A)编码质量(B)矢量编码(C)编码速率(D)坚韧性2、下列不属于编码器的质量评价的是()(A)MOS (B)DAM(C)DRT(D)ATC3、限词汇的语音合成技术已经比较成熟了,一般我们是采用()作为合成基元。
(A)词语(B)句子(C)音节(D)因素四、简答题:(共2小题,每小题12分,共24分)1、画出矢量量化器的基本结构,并说明其各部分的作用。
2、试画出语音信号产生的离散时域模型的原理框图,并说明各部分的作用。
五、简答题:(共5小题,前三小题,每题5分,后两小题,每题10分,共35分)1、线性预测分析的基本思想是什么?2、隐马尔可夫模型的特点是什么?3、矢量量化器的所谓最佳码本设计是指什么?4、针对短时傅里叶变换Ⅹn(ejw)的定义式,请从两个角度对其进行物理意义的分析。

人耳能听到的声音,频率范围在16Hz-16kHz ___-之间,年轻人的上限可以延伸至_20kHz__,老年人则衰退到_10kHz___。
短时分析技术的基本概念:语音信号的频率越低,相应的能量越高。
1、频域编码的两个基本原则(1)通过合适的滤波或变换,在频域上得到数目较少、相关性较小的分量,从而提高编码效率;(2)接受者所感知的失真信息是用来提高语音编码的性能。
2、语音识别的两个步骤:第一步是学习或训练;第二步是识别。
3、汉语的特点是:(1)汉语的特点为自然单位是音节、每一个字都是单音节字,即汉语的一个音节就是一个字的音,字是独立的发音单位;再由音节字构成词,最后由词构成句子。
每一个音节字由声母和韵母拼音而成;在音节中,声母较简单,而韵母比较复杂。
(2)汉语语音的另一个特点是它具有声调。
(3)汉语的特点还有音素少、音节少的特点。
4、矢量量化器最佳设计的两个条件是:最佳划分和最佳码书。
5、编码器的质量评价方法,包括主观评价法和客观评价法。
6、语音合成的三种基本方法:波形合成法、参数合成法和规则合成法。
1、海明窗与直角窗(矩形窗)对浊音语音的频谱分析比较它们在基音谐波、共振峰结构以及频谱具有相似性,但其频谱间也具有差别。
(1)是基音谐波尖锐度增加,这是因为矩形窗频率分辨率较高;(2)矩形窗较高的旁瓣产生了一个类似于噪声的频谱。
因此,在语音频谱分析中极少采用矩形窗。
2、简述如何利用听觉掩蔽效应。
(1)听觉掩蔽:人类听觉中存在一种现象,即两个音同时存在时,一个声音有可能受到另一个声音的干扰或压制,即一个音被另一音掩盖,这称为听觉掩蔽。
(2)应用:听觉掩蔽现象在语音处理中得到了广泛的应用。
在语音编码中,利用听觉掩蔽效应改善输出语音质量已取得很大效益。
3、简述语音信号的频谱和功率谱的作用。
频谱是对动态信号在频率域内进行分析对动态信号在频率域内进行分析对动态信号在频率域内进行分析对动态信号在频率域内进行分析,分析的结果是以频率为横坐标的各种物理量的谱线和曲线,即各种幅值以频率为变量的频谱函数F(ω)。
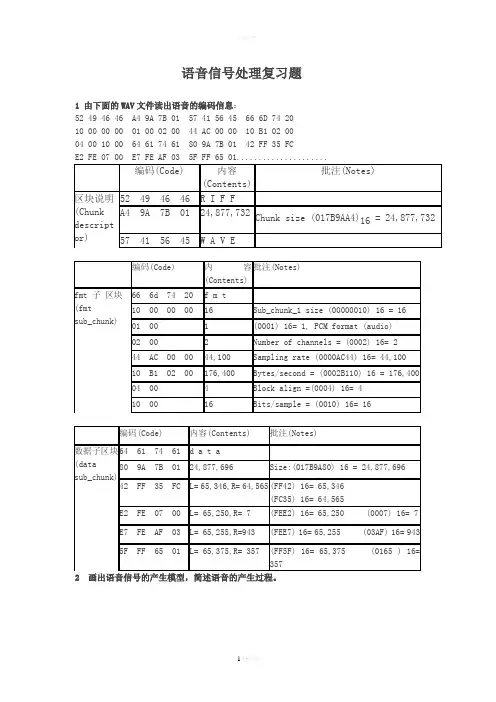
语音信号处理复习题1 由下面的WAV文件读出语音的编码信息:52 49 46 46 A4 9A 7B 01 57 41 56 45 66 6D 74 2010 00 00 00 01 00 02 00 44 AC 00 00 10 B1 02 0004 00 10 00 64 61 74 61 80 9A 7B 01 42 FF 35 FCE2 FE 07 00 E7 FE AF 03 5F FF 65 01.....................2 画出语音信号的产生模型,简述语音的产生过程。
语音的形成过程—空气由肺部排入喉部,经过声带进入声道,最后由嘴辐射出声波,形成语音。
3 为生么语音信号要进行“短时〞分析。
答:语音信号特性是随时间变化的,是一个非平稳的随机过程,但在一个短时间范围内其特性根本保持不变,即语音信号具有“短时平稳性〞,因而可将语音信号看成准平稳过程,对其进行短时分析.4 语音信号的时域分析方法有那些?答:短时能量,短时平均过零率,短时自相关函数5 语音信号频率范围是多少?答:语音信号的频率大约在20Hz~20KHz。
6 什么是浊音的基音频率(F0)?男性、女性和儿童的F0大致分布在什么范围。
答:浊音的基音频率(F0):声带张开和闭合一次的时间的倒数。
由声带的尺寸、特性和声带所受张力决定。
F0的大小决定了声音的上下,称为音高。
男性的F0大致分布在:60-200Hz,女性和儿童的F0大致分布在:200-450Hz7 可以认为多长的时间范围内,语音信号是平稳信号。
答:10-30ms8 语音的采样率为8kHz;纯语音在进行计算机录入时,一般采样率在15kHz~20kHz左右;音乐的采样率可以高达44kHz。
9 如何利用语音信号的时域分析方法进行清、浊判断。
答:1、短时能量分析依据:是基于语音信号幅度随时间变化】清音段幅度小,其能量集中高频段;浊音段幅度较大,其能量集中低频段;2、平均幅度分析的依据:清音段幅度小,浊音段幅度较大。

语⾳信号处理之(⼀)动态时间规整(DTW)语⾳信号处理之(⼀)动态时间规整(DTW)这学期有《语⾳信号处理》这门课,快考试了,所以也要了解了解相关的知识点。
呵呵,平时没怎么听课,现在只能抱佛脚了。
顺便也总结总结,好让⾃⼰的知识架构清晰点,也和⼤家分享下。
下⾯总结的是第⼀个知识点:DTW。
因为花的时间不多,所以可能会有不少说的不妥的地⽅,还望⼤家指正。
谢谢。
Dynamic Time Warping(DTW)诞⽣有⼀定的历史了(⽇本学者Itakura提出),它出现的⽬的也⽐较单纯,是⼀种衡量两个长度不同的时间序列的相似度的⽅法。
应⽤也⽐较⼴,主要是在模板匹配中,⽐如说⽤在孤⽴词语⾳识别(识别两段语⾳是否表⽰同⼀个单词),⼿势识别,数据挖掘和信息检索等中。
⼀、概述在⼤部分的学科中,时间序列是数据的⼀种常见表⽰形式。
对于时间序列处理来说,⼀个普遍的任务就是⽐较两个序列的相似性。
在时间序列中,需要⽐较相似性的两段时间序列的长度可能并不相等,在语⾳识别领域表现为不同⼈的语速不同。
因为语⾳信号具有相当⼤的随机性,即使同⼀个⼈在不同时刻发同⼀个⾳,也不可能具有完全的时间长度。
⽽且同⼀个单词内的不同⾳素的发⾳速度也不同,⽐如有的⼈会把“A”这个⾳拖得很长,或者把“i”发的很短。
在这些复杂情况下,使⽤传统的欧⼏⾥得距离⽆法有效地求的两个时间序列之间的距离(或者相似性)。
例如图A所⽰,实线和虚线分别是同⼀个词“pen”的两个语⾳波形(在y轴上拉开了,以便观察)。
可以看到他们整体上的波形形状很相似,但在时间轴上却是不对齐的。
例如在第20个时间点的时候,实线波形的a点会对应于虚线波形的b’点,这样传统的通过⽐较距离来计算相似性很明显不靠谱。
因为很明显,实线的a点对应虚线的b点才是正确的。
⽽在图B中,DTW就可以通过找到这两个波形对齐的点,这样计算它们的距离才是正确的。
也就是说,⼤部分情况下,两个序列整体上具有⾮常相似的形状,但是这些形状在x轴上并不是对齐的。


语⾳信号处理_考试参考题(修订版)(1)⼀、填空题:(每空1 分,共60分)1、语⾳信号的频率范围为(300-3400kHz),⼀般情况下采样率为(8kHz )。
书上22页2、语⾳的形成是空⽓由(肺部)排⼊(喉部),经过(声带)进⼊声道,最后由()辐射出声波,这就形成了语⾳。
书上11页。
肺中的通过(稳定)的⽓流或声道中的⽓流激励(喉头⾄嘴唇的器官的各种作⽤)⽽产⽣。
当肺中的⽓流通过声门时,声门由于其间⽓体压⼒的变化⽽开闭,使得⽓流时⽽通过,时⽽被阻断,从⽽形成⼀串周期性脉冲送⼊声道,由此产⽣的语⾳是(浊⾳)。
如果声带不振动,声门完全封闭,⽽声道在某处收缩,迫使⽓流⾼速通过这⼀收缩部位⽽发⾳,由此产⽣的语⾳是(清⾳)。
3、语⾳信号从总体上是⾮平稳信号。
但是,在短时段(10~30)ms中语⾳信号⼜可以认为是平稳的,或缓变的。
书上24页4、语⾳的四要素是⾳长,⾳强,⾳⾼和⾳质,它们可从时域波形上反映出来。
其中⾳长特性:⾳长(长),说话速度必然慢;⾳长(短),说话速度必然快。
⾳强的⼤⼩是由于声源的(震动幅度)⼤⼩来决定。
5、声⾳的响度是⼀个和(振幅)有密切联系的物理量,但并不就是⾳强。
6、⼈类发⾳过程有三类不同的激励⽅式,因⽽能产⽣三类不同的声⾳,即(浊⾳)、(清⾳)和(爆破⾳)。
7、当⽓流通过声门时声带的张⼒刚好使声带发⽣较低频率的张弛振荡,形成准周期性的空⽓脉冲,这些空⽓脉冲激励声道便产⽣浊⾳如果声道中某处⾯积很⼩,⽓流⾼速冲过此处时⽽产⽣湍流,当⽓流速度与横截⾯积之⽐⼤于某个门限时(临界速度)便产⽣摩擦⾳,即(清⾳)。
8、如果声道某处完全闭合建⽴起⽓压,然后突然释放⽽产⽣的声⾳就是(爆破⾳)。
9、在⼤多数语⾳处理⽅案中,基本的假定为语⾳信号特性随时间的变化是(平稳随机)的。
这个假定导出各种(线性时不变)处理⽅法,在这⾥语⾳信号被分隔为⼀些短段再加以处理。
10、⼀个频率为F。
的正弦形信号以Fs速率抽样,正弦波的⼀周内就有(Fs/F0)个抽样。

二、问答题(每题5分,共20 分)1、语音信号处理主要研究哪几方面的内容?语音信号处理是研究用数字信号处理技术对语言信号进行处理的一门学科,语音信号处理的理论和研究包括紧密结合的两个方面:一方面,从语言的产生和感知来对其进行研究,这一研究与语言、语言学、认知科学、心理、生理等学科密不可分;另一方面,是将语音作为一种信号来进行处理,包括传统的数字信号处理技术以及一些新的应用于语音信号的处理方法和技术。
2、语音识别的研究目标和计算机自动语音识别的任务是什么?语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
计算机自动语音识别的任务就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
3、语音合成模型关键技术有哪些?语音合成是实现人机语音通信,建立一个有听和讲能力的口语系统所需的两项关键技术,该系统主要由三部分组成:文本分析模块、韵律生成模块和声学模块。
1.如何取样以精确地抽取人类发信的主要特征,2.寻求什么样的网络特征以综合声道的频率响应,3.输出合成声音的质量如何保证。
4、语音压缩技术有哪些国际标准?二、名词解释(每题3分,共15分)端点检测:就从包含语音的一段信号中,准确的确定语音的起始点和终止点,区分语音信号和非语音信号。
共振峰:当准周期脉冲激励进入声道时会引起共振特性,产生一组共振频率,称为共振峰频率或简称共振峰。
语谱图:是一种三维频谱,它是表示语音频谱随时间变化的图形,其纵轴为频率,横轴为时间,任一给定的频率成分在给定时刻的强弱用相应点的灰度或色调的浓淡来表示。
码本设计:就是从大量信号样本中训练出好的码本,从实际效果出发寻找好的失真测度定义公示,用最少的搜素和计算失真的运算量。
语音增强:语音质量的改善和提高,目的去掉语音信号中的噪声和干扰,改善它的质量三、简答题(每题6分,共30分)1、简述如何利用听觉掩蔽效应。


1 研究语音信号处理的目的是什么?人类的通信有哪三种方式,从而说明语音信号处理有哪三个学科分支?它的目的一是要通过处理得到一些反映语音信号重要特征的语音参数以便高效的传输或储存语音信号信息;二是要通过处理的某种运算以达到某种用途的要求。
1.什么叫做语言学?什么叫做语音学?言语过程可分为哪五个阶段?语音中各个音的排列由一些规则所控制,对这些规则及其含义的研究学问称为语言学;另一个是对语音中各个音的物理特征和分类的研究称为语音学。
人的说话过程如图2-1所示,可以分为五个阶段:(1)想说阶段:(2)说出阶段:(3)传送阶段:(4)接收阶段:(5)理解阶段:3、有哪几种描述声道特性的数学模型?请说明声管模型流图是如何得出的?有几种共振峰模型?各有什么特点和适用情况?声道的数学模型有两种观点:1)声管模型将声道看为由多个不同截面积的管子串联而成的系统。
在“短时”期间,声道可表示为形状稳定的管道。
另一种观点是把声道视为一个谐振腔,按此推导出的叫“共振峰模型”。
共振峰模型,把声道视为一个谐振腔。
共振峰就是这个腔体的谐振频率。
由于人耳听觉的柯替氏器官的纤毛细胞就是按频率感受而排列其位置的,所以这种共振峰的声道模型方法是非常有效的。
一般来说,一个元音用前三个共振峰来表示就足够了;而对于较复杂的辅音或鼻音,大概要用到前五个以上的共振峰才行。
基于物理声学的共振峰理论,可以建立起三种实用的共振峰模型:级联型、并联型和混合型。
(1)级联型声道模型这时认为声道是一组串联的二阶谐振器。
从共振峰理论来看,整个声道具有多个谐振频率和多个反谐振频率,所以它可被模拟为一个零极点的数学模型;但对于一般元音,则用全极点模型就可以了。
它的传输函数可分解表示为多个二阶极点的网络的串联:N=10,M=5时的声道模型如下图所示:(2)并联型声道模型对于非一般元音以及大部分辅音,必须考虑采用零极点模型。
此时,模型的传输函数如下:通常,N>R ,且设分子与分母无公因子及分母无重根,则上式可分解为如下部分分式之和的形式:这就是并联型的共振峰模型。


《语音信号处理》期末考试复习资料(涉及考点的教材课后复习题)授课教师:薛雅娟老师整理人:通信161班梁雨(第2-5章)通信161班左自睿(第6-10章)根据成都信息工程大学通信工程学院选修课《语音信号处理》期末考试范围,整理成期末考试的复习资料以供学弟学妹们参考。
所有权归属成都信息工程大学。
在此衷心感谢薛老师平时悉心地教育指导。
整理人均系在读本科学生,水平有限,错误与不足之处在所难免,敬请大家见谅,欢迎批评、斧正。
第二章:语音信号处理的基础知识人耳听觉的掩蔽效应分为哪几种?掩蔽效应的存在对我们研究语音信号处理系统有什么启示?答:分为同时掩蔽和短时掩蔽。
同时掩蔽是指同时存在的一个弱信号和一个强信号频率接近时,强信号会提高弱信号的听阈,当弱信号的听阈被升高到一定程度时就会导致这个弱信号变得不可闻。
当A声和B声不同时出现时也存在掩蔽作用,称为短时掩蔽。
短时掩蔽分为前向掩蔽和后向掩蔽。
语音信号的数学模型包括哪些子模型?激励模型是怎样推导出来的?辐射模型又是怎样推导出来的?它们各属于什么性质的滤波器?答:①激励模型②声道模型③辐射模型④完整的语音信号的数学模型激励模型一般分成浊音激励和清音激励。
浊音激励:发浊音时,声激励是一个准周期的单位脉冲串,Av为增益参数;为了使浊音的激励信号具有声门振动气流脉冲的实际波形,需将冲激序列通过一个声门脉冲模型滤波器(实际上是一个斜三角波形)G(z)。
最后形成一个以基音周期为周期的斜三角波形。
清音激励模拟为随机噪声,实际中一般使用均值为0、方差为1的白噪声。
辐射模型:从声道模型射出的是速度波ul(n),而语音信号是声压波pl(n),二者之倒比称为辐射阻抗Zl。
在语音信号参数分析前为什么要进行预处理,有哪些预处理过程?答:预滤波的目的有两个:一是抑制输入信号各频域分量中频率超出fs/2的所有分量(fs为采样频率),以防止混叠干扰;二是抑制50Hz的电源工频干扰。
预处理过程:预加重、加窗和分帧。
语音操作考试题目和答案一、单项选择题(每题2分,共20分)1. 在语音识别系统中,将语音信号转换为数字信号的过程称为()。
A. 语音采集B. 语音编码C. 语音解码D. 语音合成答案:A2. 语音识别技术中,用于提取语音特征的算法不包括()。
A. MFCC(梅尔频率倒谱系数)B. LPC(线性预测编码)C. FFT(快速傅里叶变换)D. HMM(隐马尔可夫模型)答案:D3. 在语音合成技术中,以下哪种方法不属于文本到语音(TTS)的范畴?()A. 规则方法B. 单元选择方法C. 波形拼接方法D. 语音识别方法答案:D4. 语音信号处理中,以下哪种方法不用于降低背景噪声?()A. 谱减法B. Wiener滤波C. 谱增强法D. 语音编码答案:D5. 语音识别系统中,用于提高识别准确率的技术不包括()。
A. 声学模型训练B. 语言模型训练C. 特征提取D. 语音增强答案:C6. 在语音识别中,端点检测的主要作用是()。
A. 确定语音信号的起始和结束位置B. 提高语音信号的信噪比C. 降低语音信号的采样率D. 增强语音信号的特征答案:A7. 语音信号处理中,以下哪种算法主要用于语音信号的压缩?()A. LPC(线性预测编码)B. CELP(码激励线性预测)C. DFT(离散傅里叶变换)D. HMM(隐马尔可夫模型)答案:B8. 在语音合成中,以下哪种方法不依赖于预先录制的语音数据?()A. 单元选择方法B. 波形拼接方法C. 参数合成方法D. 规则方法答案:D9. 语音识别系统中,用于处理不同说话人语音特征差异的技术是()。
A. 特征归一化B. 说话人适应C. 端点检测D. 语音增强答案:B10. 语音信号处理中,以下哪种方法不用于语音信号的分割?()A. 基于阈值的分割B. 基于频谱的分割C. 基于能量的分割D. 语音编码答案:D二、多项选择题(每题3分,共15分)11. 语音识别系统中,以下哪些因素会影响识别准确率?()A. 说话人的口音B. 环境噪声C. 语音信号的采样率D. 识别算法的复杂度答案:A, B, D12. 语音合成技术中,以下哪些方法属于参数合成方法?()A. PSOLA(脉冲串叠加和重叠加法)B. HMM(隐马尔可夫模型)C. LPC(线性预测编码)D. DFT(离散傅里叶变换)答案:B, C13. 在语音信号处理中,以下哪些算法可以用于语音信号的特征提取?()A. MFCC(梅尔频率倒谱系数)B. LPC(线性预测编码)C. FFT(快速傅里叶变换)D. HMM(隐马尔可夫模型)答案:A, B, C14. 语音识别系统中,以下哪些技术可以用于提高识别准确率?()A. 端点检测B. 说话人适应C. 特征归一化D. 语音增强答案:A, B, C, D15. 语音信号处理中,以下哪些方法可以用于降低背景噪声?()A. 谱减法B. Wiener滤波C. 谱增强法D. 语音编码答案:A, B, C三、判断题(每题2分,共20分)16. 语音识别技术可以应用于智能助手和自动客服系统。
第一章绪论1.语音信号处理是以语音语言学和数字信号处理为基础而形成的一门涉及面很广的综合性的学科。
p1d32.语音信号处理的应用技术列举:语音编码、语音识别、语音合成、说话人识别和语种辨识、语音转换和语音隐藏(语音信息伪装、语音数字水印技术)、语音增强等p4d33.当前语音信号处理应用的3个主流技术:矢量量化技术、隐马尔可夫模型技术、人工神经网络技术。
p4d3第二章语音信号处理基础知识1.语音是组成语言的声音,是声音(Acoustic)和语言(Language)的组合体。
p5d22.语音的基本声学特性包括音色,音调,音强、音长。
p7d2➢音色:也叫音质,是一种声音区别于另一种声音的基本特征。
➢音调:是指声音的高低,它取决于声波的频率。
➢音强:声音的强弱,它由声波的振动幅度决定。
➢音长:声音的长短,它取决于发音时间的长短。
3. 说话时一次发出的,具有一个响亮的中心,并被明显感觉到的语音片段叫音节(Syllable)。
一个音节可以由一个音素(Phoneme)构成,也可以由几个音素构成。
音素是语音发音的最小单位。
p7d34.任何语言都有语音的元音(V owel)和辅音(Consonant)两种音素。
p7d38.当声带振动发出的声音气流从喉腔、咽腔进入口腔从唇腔出去时,这些声腔完全开放,气流顺利通过,这种音称为元音。
p7d39.呼出的声流,由于通路的某一部分封闭起来或受到阻碍,气流被阻不能畅通,而克服发音器官的这种阻碍而产生的音素称为辅音。
p7d37.发辅音时由声带是否振动引起浊音和清音的区别,声带振动的是浊音,声带不振动的是清音。
p7d38.元音构成音节的主干(因为无论从长度还是能量看,元音在音节中都占主要部分。
)p7d39.元音的一个重要声学特性是共振峰(Formant)。
共振峰参数是区别不同元音的重要参数,它一般包括共振峰频率(Formant Frequency)的位置和频带宽度(Formant Bandwidth)。
语音信号处理复习资料8预加重和去加重的理解7线性预测编码特点和定义5隐马尔可夫差数特点计算以上三题没有老师画的其他的重点为红色标记的(注意:仅供参考)一、语音、语音信号处理的名词解释1、语音:是语言的声学表现,是声音和意义的结合体,是相互传递信息的重要手段,是人类最重要、最有效、最常用和最方便的交换信息的形式。
2、语音信号处理:是研究用数字信号处理技术对语音信号进行处理的一门学科,它是一门新兴的学科,同时又是综合性的多学科领域和涉及很广的交叉学科。
它与语音学、语言学、声学、认知科学、生理学、心理学有密切关系。
二、语音学的名词解释语音学:是研究言语过程的一门科学,它包括三个研究内容:发音器官在发音过程中的运动和语音的音位特性;语音的物理特性;以及听觉和语言感知。
§.2语音信号处理的发展概况1、语音编码:语音编码技术是伴随着语音信号的数字化而产生的,目前主要应用在数字语音通信领域。
2、语音合成:语音合成的目的是使计算机能像人一样说话。
3、语音识别:语音识别是使计算机判断出所说的话得内容。
§.2语音产生的过程一、语音、清音、浊音1、语音:声音是一种波,能被人耳听到,振动频率在20Hz-20kHz之间。
语音是声音的一种,它是由人的发音器官发出的、具有一定语法和意义的声音。
语音的振动频率最高可达15kHz左右。
2、浊音、清音:语音由声带振动或不经声带振动来产生,其中由声带振动产生的音统称为浊音,而不由声带振动产生的音统称为清音。
浊音中包括所有的元音和一些辅音,清音包括另一部分辅音。
二、语音的产生过程:空气从肺部排出形成气流。
空气通过声带时,如果声带是紧绷的,则声带将产生张弛振动,即声带周期性地开启和闭合。
声带开启时,空气流从声门喷射出来,形成一个脉冲;声带闭合时相应于脉冲序列的间歇期。
语言交际:通过连接说话人大脑的一连串心理、生理、和物理的转换过程实现的。
这个过程包括:发音-传递-感知。
语音信号处理考试试题一、简答题1. 请解释什么是语音信号处理?语音信号处理指的是对语音信号进行数字信号处理的过程。
它涉及到声音的采集、编码、分析、合成和识别等一系列处理技术,旨在提高语音通信和语音识别系统的性能。
2. 请列举一些常见的语音信号处理应用。
常见的语音信号处理应用包括语音通信、语音识别、语音合成、语音增强、语音压缩等。
3. 请简要描述语音信号处理系统的基本框架。
语音信号处理系统的基本框架包括声音的采集、预处理、特征提取、模型训练和解码等步骤。
首先,声音信号通过麦克风采集,并进行预处理,如去除噪声、归一化等。
然后,从预处理的信号中提取出特征,如音频频谱、共振峰等信息。
接下来,使用这些特征进行模型的训练,以建立语音信号的模型。
最后,通过解码器将输入的语音信号与训练好的模型进行匹配,从而实现语音的识别或合成。
4. 请列举一些常用的语音信号处理算法或技术。
常用的语音信号处理算法或技术包括数字滤波、时域和频域特征提取、自动语音识别(ASR)、线性预测编码(LPC)、傅里叶变换(FFT)、Mel频谱倒谱系数(MFCC)、隐藏马尔可夫模型(HMM)等。
5. 请解释什么是Mel频谱倒谱系数(MFCC)算法。
Mel频谱倒谱系数(MFCC)算法是一种常用的语音信号处理算法,主要用于语音特征提取。
它模拟了人类听觉系统的工作原理,通过对语音信号进行分帧、加窗、傅里叶变换等处理,提取出与人耳感知的频率特征相关的Mel频率倒谱系数。
MFCC算法具有较好的语音信号特征提取效果,广泛应用于语音识别等领域。
二、计算题1. 对下述数字信号进行离散傅里叶变换(DFT):x(n) = [1, 2, 3, 4]首先,对x(n)进行零填充,得到长度为N的信号x'(n) = [1, 2, 3, 4, 0, 0, 0, 0]。
然后,对x'(n)进行DFT计算,得到频谱X(k)。
X(k) = [10, -2+2j, -2, -2-2j, 0, 0, 0, 0]2. 对下述频谱进行逆离散傅里叶变换(IDFT):X(k) = [10, -2+2j, -2, -2-2j]首先,对X(k)进行逆DFT计算,得到时域信号x(n)。
第 1 页 共 1 页 内蒙古科技大学2012/2013学年第一学期 《语音信号处理》B 卷 考试试题 课程号:67118305 考试方式:闭卷 使用专业、年级:信息2009 任课教师:杨立东 考试时间:120分钟 备 注: 一、填空题(共10空,每空2分,共20分) 1. 人类听觉系统具有 效应。
2. 利用参数编码实现语音通信的设备通常称为 。
3. Mel 频率尺度的值大体上对应于实际频率的 分布关系 4. 语音信号具有 特性,所以可以将其看作是一个准稳态过程。
5. 语音识别方法一般有模板匹配法、 和 三种。
6. VQ 中采用的距离测度必须具备对称性、 、 和有高效算法等性质。
7. 不能通过一个信号的倒谱还原原始信号,因为在计算倒谱过程中丢失了 信息。
8. 50Hz 交流电源哼声属于 噪声。
二、判断题(共5题,每题2分,共10分) 1. 在DM 编码中造成的颗粒噪声,可以通过减小量化阶距来去除。
( ) 2. 语音合成系统是一个单向系统,由机器到人。
( ) 3. FSVQ 是一种无记忆的矢量量化。
( ) 4. 人在说话的时候由于呼吸所引入的噪声称之为周期噪声 ( ) 5. 预加重的目的是提升低频部分,使信号的频谱变得平坦。
( )三、简答题(共5题,每题8分,共40分) 1. 简述LPC 的基本思想。
2. 简述端点检测过程中遇到的实际困难。
3. 简述HMM 的三个基本问题。
4. 简述语音信号分析过程中进行预滤波的目的。
5. 简述共振峰估计的过程中存在的困难。
四、计算题(共3题,每题10分,共30分) 1. 已知序列[][][][][][]0.110.4110.2820.0334h k k k k k k δδδδδ=+-+-+-+-,求()H z 及其倒序多项式4()R H z 。
2. 已知一个HMM 如下图所示,从S 1开始,S 4结束,每个状态有三个输出符号a,b ,c ,求利用该模型输出abcb 的概率。
一、填空题:(每空1 分,共60分)1、语音(speech)300-3400kHz,采样率为(8kHz )宽带语音(wide-band speech),带宽7kHz (50-7k),采样率为(14k Hz )带宽20kHz(20-20k),采样率一般为(40k Hz )2、语音由肺中的通过(稳定)的气流或声道中的气流激励(喉头至嘴唇的器官的各种作用)而产生。
当肺中的气流通过声门时,声门由于其间气体压力的变化而开闭,使得气流时而通过,时而被阻断,从而形成一串周期性脉冲送入声道,由此产生的语音是(浊音)。
如果声带不振动,声门完全封闭,而声道在某处收缩,迫使气流高速通过这一收缩部位而发音,由此产生的语音是(清音)。
3、语音信号从总体上是非平稳信号。
但是,在短时段(10~30)ms中语音信号又可以认为是平稳的,或缓变的。
4、语音的四要素是音长,音强,音高和音质,它们可从时域波形上反映出来。
其中音长特性:音长(长),说话速度必然慢;音长(短),说话速度必然快。
音强的大小是由于声源的(震动幅度)大小来决定。
5、声音的响度是一个和(振幅)有密切联系的物理量,但并不就是音强。
6、人类发音过程有三类不同的激励方式,因而能产生三类不同的声音,即(浊音)、(清音)和(爆破音)。
7、当气流通过声门时声带的张力刚好使声带发生较低频率的张弛振荡,形成准周期性的空气脉冲,这些空气脉冲激励声道便产生浊音如果声道中某处面积很小,气流高速冲过此处时而产生湍流,当气流速度与横截面积之比大于某个门限时(临界速度)便产生摩擦音,即(清音)。
8、如果声道某处完全闭合建立起气压,然后突然释放而产生的声音就是(爆破音)。
9、在大多数语音处理方案中,基本的假定为语音信号特性随时间的变化是(平稳随机)的。
这个假定导出各种(线性时不变)处理方法,在这里语音信号被分隔为一些短段再加以处理。
10、一个频率为F。
的正弦形信号以Fs速率抽样,正弦波的一周内就有(Fs/F0)个抽样。
每一周内有两次过零,所以过零的长时间平均率是(2 Fs/F0)过零率/抽样。
因此,平均过零率就是一个估计正弦波频率的适当方法。
11、如果过零率(高),语音信号就是清音。
如果过零率(低),语音信号就是浊音。
语音流由(音位)结合而成的最小单位,同时也是(音节)的最小单位,其英语对应词是phoneme,一个音节由(元音)和(辅音)构成,其英语对应词是Vowel和Consonant。
12、语音信号的最重要持征表现在它的“短时频谱”上。
如果从语音流中利用加窗的方法取出其中的一个短段,再对其进行(傅立叶)变换,就可以得到该段语音的(短时)谱。
13、人类听觉系统具有(掩蔽效应),大致是一个单音的声级越(高),对其周围频率声音的掩蔽作用越强。
人耳对不同频段声音的敏感程度(不同)。
人耳对语音信号的(低频率和高频率)变化不敏感。
14、响度较(大)的频率成分的存在会影响响度较(小)的频率成分的感受,使其变得不容易察觉。
15、浊音的声带振动基频称为(基音频率)。
16、分析综合技术就是通过对信源分析,提取其中具有本质意义的参数,编码仅对这些参数进行。
接受端借助一定的规则和模型,结合一定的算法将这些参数再综合成逼近(原语音)。
17、高、低子带信号能量相互混叠的现象也称为(频谱混叠)。
18、声音的掩蔽效应,说明一个声音的存在会影响人耳对另一个声音的听觉能力。
掩蔽效应与两个声音的(频率和相对音量)有关。
利用掩蔽效应可以用有用声音信号去掩蔽无用声音信号,即将不需要的声音在主观感觉上降低或消除。
19、语音可以用一个(语音生成)系统的输出来表示,该系统具有随时间(变化)的性质。
这把我们引向语音分析的一项基本原理,该原理指出,如果我们研究语音信号的每一短段,则以准周期脉冲串或随机噪声信号激励一个()系统所产生的输出信号作为每一段的模型是有效的。
20、语音分析的问题在于估计语音模型的参数并且测量它们随时间的变化。
因为一个线性时不变系统的激励信号及其冲激响应是按(级联)方式结合起来的,语音分析问题可以看作是将()的问题。
这个问题通常称为()。
21、语音增强的一个主要目标是从带噪语音信号中提取尽可能纯净的原始语音。
对于非加性噪声,有些可以通过变换而转变为()。
22、语音的发声过程可以模型化为激励源作用于一个线性时变滤波器,激励源可以分(浊音激励)和(清音激励)两类,浊音由气流通过声带产生。
时变滤波器则是()的模型。
通常认为声道模型是一个(全极点)滤波器,滤波器参数可以通过线性预测分析得到,但若考虑到鼻腔的共鸣作用,采用()模型更为合适。
23、CELP 体制用保存在激励码本中的码矢量或自适应产生的矢量作为激励,以语音()作为声道模型,产生语音信号。
24、将(综合器)引入编码器,和语音分析器结合,在编码端产生与解码端一样的合成语音,与原始语音在感知加权域内相比较,选择适当的语音编码参数值,使得比较的误差最小。
25、按发音方式,可分为(单个特定讲话人)、(多讲话人)发音识别系统及(与讲话人无关)三种识别系统。
26、按识别对象,可分为(孤立词、连接词、连续语音识别系统)及(语音理解和会话系统)识别系统;27、按词汇表的大小,可分为小词汇表(1~20词)、中等词汇表(20 —1000词)、大词汇表(1000词)以上和无限词汇表识别系统,理想的语音识别系统应该是非特定人无限词汇的连续语音识别系统。
二、问答题(每题5分,共20 分)1、语音信号处理主要研究哪几方面的内容?语音信号处理是研究用数字信号处理技术对语言信号进行处理的一门学科,语音信号处理的理论和研究包括紧密结合的两个方面:一方面,从语言的产生和感知来对其进行研究,这一研究与语言、语言学、认知科学、心理、生理等学科密不可分;另一方面,是将语音作为一种信号来进行处理,包括传统的数字信号处理技术以及一些新的应用于语音信号的处理方法和技术。
2、语音识别的研究目标和计算机自动语音识别的任务是什么?语音识别技术,也被称为自动语音识别Automatic Speech Recognition,(ASR),其目标是将人类的语音中的词汇内容转换为计算机可读的输入,例如按键、二进制编码或者字符序列。
计算机自动语音识别的任务就是让机器通过识别和理解过程把语音信号转变为相应的文本或命令的高技术。
3、语音合成模型关键技术有哪些?语音合成是实现人机语音通信,建立一个有听和讲能力的口语系统所需的两项关键技术,该系统主要由三部分组成:文本分析模块、韵律生成模块和声学模块。
1.如何取样以精确地抽取人类发信的主要特征,2.寻求什么样的网络特征以综合声道的频率响应,3.输出合成声音的质量如何保证。
4、语音压缩技术有哪些国际标准?三、列举工农业生产、人民生活中的 5 种语音信号处理应用技术或产品。
简述其工作原理?(共20 分)语音压缩, 语音合成语音识别语音增强语音理解语音识别的应用领域非常广泛,常见的应用系统有:语音输入系统,相对于键盘输入方法,它更符合人的日常习惯,也更自然、更高效;语音控制系统,即用语音来控制设备的运行,相对于手动控制来说更加快捷、方便,可以用在诸如工业控制、语音拨号系统、智能家电、声控智能玩具等许多领域:智能对话査询系统,根据客户的语音进行操作.为用户提供自然、友好的数据库检索服务,例如家庭服务、宾馆服务、旅行社服务系统、订票系统、医疗服务、银行服务、股票査询服务等等。
我们把声音心理学也列为语音信号处理的关键技术之一。
①声音心理学人的大脑处理听觉信息有一些特性,产生了一些客观存在的效应,如屏蔽效应。
声的响度不仅取决于自身的强度和频率,而且也依同时出现的其它声音而定。
各种声音可以互相掩蔽,一种声音的出现可能使得另一种声音难于听清。
它分为听觉屏蔽、频谱屏蔽和瞬态屏蔽。
频谱屏蔽是高电平音调使附近频率的低电平声音不能被人耳听到。
声音的屏蔽特性可以用于声音特别是语音信号的压缩。
一、填空题(每空2分,共15分)二、名词解释(每题3分,共15分)端点检测:就从包含语音的一段信号中,准确的确定语音的起始点和终止点,区分语音信号和非语音信号。
共振峰:当准周期脉冲激励进入声道时会引起共振特性,产生一组共振频率,称为共振峰频率或简称共振峰。
语谱图:是一种三维频谱,它是表示语音频谱随时间变化的图形,其纵轴为频率,横轴为时间,任一给定的频率成分在给定时刻的强弱用相应点的灰度或色调的浓淡来表示。
码本设计:就是从大量信号样本中训练出好的码本,从实际效果出发寻找好的失真测度定义公示,用最少的搜素和计算失真的运算量。
语音增强:语音质量的改善和提高,目的去掉语音信号中的噪声和干扰,改善它的质量三、简答题(每题6分,共30分)1、简述如何利用听觉掩蔽效应。
一个较弱的声音(被掩蔽音)的听觉感受被另一个较强的声音(掩蔽音)影响的现象称为人耳的“掩蔽效应”。
人耳的掩蔽效应一个较弱的声音(被掩蔽音)的听觉感受被另一个较强的声音(掩蔽音)影响的现象称为人耳的“掩蔽效应”。
被掩蔽音单独存在时的听阈分贝值,或者说在安静环境中能被人耳听到的纯音的最小值称为绝对闻阈。
实验表明,3kHz—5kHz绝对闻阈值最小,即人耳对它的微弱声音最敏感;而在低频和高频区绝对闻阈值要大得多。
在800Hz--1500Hz范围内闻阈随频率变化最不显著,即在这个范围内语言可储度最高。
在掩蔽情况下,提高被掩蔽弱音的强度,使人耳能够听见时的闻阈称为掩蔽闻阈(或称掩蔽门限),被掩蔽弱音必须提高的分贝值称为掩蔽量(或称阈移)。
2、简述时间窗长与频率分辨率的关系。
采样周期Ts=1/fs、窗口长度N和频率分辨率△f之间存在下列关系:△f = 1 / (N*Ts) 可见,采样周期一定时,△f随窗口宽度N的增加而减少,即频率分辨率相应得到提高,但同时时间分辨率降低;如果窗口取短,频率分辨率下降,而时间分辨率提高,因而二者是矛盾的。
3、简述时域分析的技术(最少三项)及其在基因检测中的应用。
P(35-41)时域分析通常用于最基本的参数分析及应用,如语音的分割、预处理、大分类等。
这种分析方法的特点是:①表示语音信号比较直观、物理意义明确。
②实现起来比较简单、运算量少。
③可以得到语音的一些重要的参数。
④只使用示波器等通用设备,使用较为简单等。
1.短时能量及短时平均幅度分析2短时过零率分析3短时相关分析4、简述语音信号的频谱和功率谱的作用。
频谱是对动态信号在频率域内进行分析对动态信号在频率域内进行分析对动态信号在频率域内进行分析对动态信号在频率域内进行分析,分析的结果是以频率为横坐标的各种物理量的谱线和曲线,即各种幅值以频率为变量的频谱函数F(ω)。
频谱分析中可求得幅值谱、相位谱、功率谱和各种谱密度等等。
频谱分析过程较为复杂,它是以傅里叶级数和傅里叶积分为基础的。