【VIP专享】实验4—Hadoop集群搭建
- 格式:pdf
- 大小:798.43 KB
- 文档页数:8

【图⽂详解】Hadoop集群搭建(CentOs6.3)本⽂主要详细地描述了hadoop集群的搭建以及⼀些配置⽂件的说明,⽤于⾃⼰复习以及供新⼈学习,若有错误之处还请指出。
前期准备先给出我的集群架构:装好四台虚拟机(我的四台虚拟机是CentOs6.3系统)四台虚拟机都装好jdk四台虚拟机都配好免密登录四台虚拟机都配置好ip地址和主机名映射关系(以下是我的地址映射关系)vim /etc/hosts192.168.25.13 mini1192.168.25.14 mini2192.168.25.15 mini3192.168.25.16 mini4以上步骤有不会的可查看我的其他⼏篇博客:1、将hadoop安装包上传到mini1上,解压后改名,并创建⽬录hadoopdata与hadoop⽬录平⾏tar -zxvf hadoop-2.6.5.tar.gz -C /root/apps/cd /root/apps/mv hadoop-2.6.5 hadoopmkdir hadoopdata2、进⼊hadoop配置⽂件⽬录下,可看到以下配置⽂件cd hadoop/etc/hadoop/3、修改hadoop-env.sh配置⽂件vim hadoop-env.sh#写上⾃⼰的JAVA_HOME4、修改core-site.xml配置⽂件vim core-site.xml<configuration><property><name>fs.defaultFS</name><value>hdfs://mini1:9000</value></property><property><name>hadoop.tmp.dir</name><value>/root/apps/hadoopdata</value></property></configuration>配置说明:fs.defaultFS:hadoop使⽤什么⽂件系统hdfs://mini1:9000:指定hadoop系统使⽤hdfs⽂件系统,并指明namenode为mini1,客户端访问端⼝为9000hadoop.tmp.dir:hadoop⽂件存储⽬录有2个参数可配置,但⼀般来说我们不做修改。

实训项目名称:搭建Hadoop集群项目目标:通过实际操作,学生将能够搭建一个基本的Hadoop集群,理解分布式计算的概念和Hadoop生态系统的基本组件。
项目步骤:1. 准备工作介绍Hadoop和分布式计算的基本概念。
确保学生已经安装了虚拟机或者物理机器,并了解基本的Linux命令。
下载Hadoop二进制文件和相关依赖。
2. 单节点Hadoop安装在一台机器上安装Hadoop,并配置单节点伪分布式模式。
创建Hadoop用户,设置环境变量,编辑Hadoop配置文件。
启动Hadoop服务,检查运行状态。
3. Hadoop集群搭建选择另外两台或更多机器作为集群节点,确保网络互通。
在每个节点上安装Hadoop,并配置集群节点。
编辑Hadoop配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml等。
配置SSH无密码登录,以便节点之间能够相互通信。
4. Hadoop集群启动启动Hadoop集群的各个组件,包括NameNode、DataNode、ResourceManager、NodeManager 等。
检查集群状态,确保所有节点都正常运行。
5. Hadoop分布式文件系统(HDFS)操作使用Hadoop命令行工具上传、下载、删除文件。
查看HDFS文件系统状态和报告。
理解HDFS的数据分布和容错机制。
6. Hadoop MapReduce任务运行编写一个简单的MapReduce程序,用于分析示例数据集。
提交MapReduce作业,观察作业的执行过程和结果。
了解MapReduce的工作原理和任务分配。
7. 数据备份和故障恢复模拟某一节点的故障,观察Hadoop集群如何自动进行数据备份和故障恢复。
8. 性能调优(可选)介绍Hadoop性能调优的基本概念,如调整副本数、调整块大小等。
尝试调整一些性能参数,观察性能改善情况。
9. 报告撰写撰写实训报告,包括项目的目标、步骤、问题解决方法、实验结果和总结。
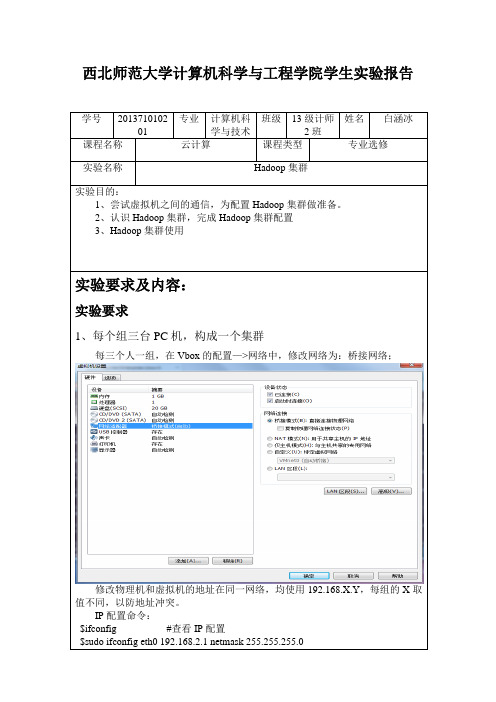
西北师范大学计算机科学与工程学院学生实验报告学号201371010201 专业计算机科学与技术班级13级计师2班姓名白涵冰课程名称云计算课程类型专业选修实验名称Hadoop集群实验目的:1、尝试虚拟机之间的通信,为配置Hadoop集群做准备。
2、认识Hadoop集群,完成Hadoop集群配置3、Hadoop集群使用实验要求及内容:实验要求1、每个组三台PC机,构成一个集群每三个人一组,在Vbox的配置—>网络中,修改网络为:桥接网络;修改物理机和虚拟机的地址在同一网络,均使用192.168.X.Y,每组的X取值不同,以防地址冲突。
IP配置命令:$ifconfig #查看IP配置$sudo ifconfig eth0 192.168.2.1 netmask 255.255.255.0测试组内所有的物理机、虚拟机相互之间是否可ping通。
2、Hadoop集群安装(1)在所有的机器上建立相同的用户(2)修改hosts文件,使得三个节点可使用机器名相互访问(3)SSH配置①在所有机器上建立.ssh目录:$ mkdir .ssh,在ubuntunamenode上生成密钥对:$ ssh-keygen -t rsa$cd ~/.ssh$cp id_rsa.pub authorized_keys②下图为解决不能连接端口号22的方法③拷贝公钥到namenode节点:$scp authorized_keys test1:/home/grid/.ssh$scp authorized_keys test2:/home/grid/.ssh④进入各节点的.ssh目录,改变authorized_keys文件权限$chmod 644 authorized_keys(4)在所有机器上配置Hadoop①在ubuntunamenode上配置编辑core-site.xml、hdfs-site.xml和mapred-site.xmlcore-site.xmlhdfs-site.xmlmapred-site.xml编辑conf/masters,修改为master的主机名,每个主机名一行,即test1;编辑conf/slaves,加入所有slaves的主机名,即test2和test3;②把Hadoop安装文件复制到其他机器上$ scp –r hadoop-0.20.2 ubuntudata1:/home/grid$ scp –r hadoop-0.20.2 test2:/home/grid③编辑所有机器的conf/hadoop-env.sh文件(5)Hadoop运行①格式化分布式文件系统$bin/hadoop namenode -format②启动Hadoop守护进程$ bin/start-all.sh$/usr/java/jdk1.6.0_24/bin/jps(可使用Java的jps命令查看已运行的进程:Namenode, JobTracker)(6)熟练使用HDFS命令上传一个大文件到Hadoop集群,在HDFS中查看文件在各节点的存放情况;编写程序读写Hadoop集群上的文件;在Hadoop集群上运行Mapreduce示例程序查看运行结果实验总结:通过这次实验了解了hadoop集群的基本设置,尝试三台虚拟机之间的通信,为配置Hadoop集群做准备。

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。

组建hadoop集群实验报告一、实验目的本次实验的目的是通过组建Hadoop 集群,熟悉和掌握Hadoop 的部署过程和相关技术,加深对分布式计算的理解并掌握其应用。
二、实验环境- 操作系统:Ubuntu 20.04- Hadoop 版本:3.3.0- Java 版本:OpenJDK 11.0.11三、实验步骤1. 下载和安装Hadoop在官方网站下载Hadoop 的二进制文件,并解压到本地的文件夹中。
然后进行一些配置,如设置环境变量等,以确保Hadoop 可以正常运行。
2. 配置Hadoop 集群a) 修改核心配置文件在Hadoop 的配置目录中找到`core-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>fs.defaultFS</name><value>hdfs:localhost:9000</value></property></configuration>b) 修改HDFS 配置文件在配置目录中找到`hdfs-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>dfs.replication</name><value>1</value></property></configuration>c) 修改YARN 配置文件在配置目录中找到`yarn-site.xml` 文件,在其中添加以下配置:xml<configuration><property><name>yarn.resourcemanager.hostname</name><value>localhost</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</nam e><value>org.apache.hadoop.mapred.ShuffleHandler</value></property></configuration>3. 启动Hadoop 集群在终端中执行以下命令来启动Hadoop 集群:bashstart-all.sh这将启动Hadoop 中的所有守护进程,包括NameNode、DataNode、ResourceManager 和NodeManager。

hadoop集群搭建实验心得
Hadoop是一个分布式存储和计算框架,它能够处理大数据集和高并发访问请求。
在实际应用中,我们经常需要搭建Hadoop集群来进行数据处理和分析。
在本次实验中,我成功地搭建了一个Hadoop 集群,并深入了解了其工作原理和配置方法。
首先,我了解了Hadoop集群的基本架构,并熟悉了其各个组件的作用。
在搭建集群过程中,我按照官方文档逐步操作,包括安装并配置Java、Hadoop和SSH等软件环境,以及设置节点间的通信和数据传输。
在实验过程中,我不断调试和优化配置,确保集群的稳定和性能。
通过实验,我了解了Hadoop集群的优缺点和应用场景,以及如何利用Hadoop进行数据处理和分析。
我还学习了Hadoop生态系统中的其他工具和框架,例如Hive、Pig和Spark等,这些工具能够更好地支持数据分析和机器学习等应用。
总的来说,通过本次实验,我深入了解了Hadoop集群的搭建和配置方法,并了解了其应用和发展前景。
我相信这些经验和知识将对我未来的工作和学习有所帮助。
- 1 -。
hadoop集群安装配置的主要操作步骤-概述说明以及解释1.引言1.1 概述Hadoop是一个开源的分布式计算框架,主要用于处理和存储大规模数据集。
它提供了高度可靠性、容错性和可扩展性的特性,因此被广泛应用于大数据处理领域。
本文旨在介绍Hadoop集群安装配置的主要操作步骤。
在开始具体的操作步骤之前,我们先对Hadoop集群的概念进行简要说明。
Hadoop集群由一组互联的计算机节点组成,其中包含了主节点和多个从节点。
主节点负责调度任务并管理整个集群的资源分配,而从节点则负责实际的数据存储和计算任务执行。
这种分布式的架构使得Hadoop可以高效地处理大规模数据,并实现数据的并行计算。
为了搭建一个Hadoop集群,我们需要进行一系列的安装和配置操作。
主要的操作步骤包括以下几个方面:1. 硬件准备:在开始之前,需要确保所有的计算机节点都满足Hadoop的硬件要求,并配置好网络连接。
2. 软件安装:首先,我们需要下载Hadoop的安装包,并解压到指定的目录。
然后,我们需要安装Java开发环境,因为Hadoop是基于Java 开发的。
3. 配置主节点:在主节点上,我们需要编辑Hadoop的配置文件,包括核心配置文件、HDFS配置文件和YARN配置文件等。
这些配置文件会影响到集群的整体运行方式和资源分配策略。
4. 配置从节点:与配置主节点类似,我们也需要在每个从节点上进行相应的配置。
从节点的配置主要包括核心配置和数据节点配置。
5. 启动集群:在所有节点的配置完成后,我们可以通过启动Hadoop 集群来进行测试和验证。
启动过程中,我们需要确保各个节点之间的通信正常,并且集群的各个组件都能够正常启动和工作。
通过完成以上这些操作步骤,我们就可以成功搭建一个Hadoop集群,并开始进行大数据的处理和分析工作了。
当然,在实际应用中,还会存在更多的细节和需要注意的地方,我们需要根据具体的场景和需求进行相应的调整和扩展。
Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
流程:配置阶段:配置一系列文件在所有slave节点上拷贝master和JobTracker 的公钥在JobTracker节点上拷贝master的公钥运行阶段:启动hadoop跑wordcount集群搭建准备:至少两台已完成单节点搭建的机器(此例为两台,IP分别是192.168.1.10与192.168.1.11,其中10为master)配置阶段:1、配置一系列文件(所有节点上)1、配置etc下的hosts文件sudo gedit /etc/hosts(注:打开后将里面的内容全部删除,不删除的话启动时会出现所有slave启动正常,但是master上的DataNode为0,导致系统不能正常运转的情况,全部删除以后添加所有节点的IP和标识符,格式如下192.168.1.10 master192.168.1.11 slave标识符可以随便写,主要是起到一个映射作用)2、进入hadoop目录下,配置conf下的masters文件cd /usr/local/hadoopsudo gedit conf/masters(打开后将里面内容清空,然后添加“master”或者master 的IP“192.168.1.10”,此处即是hosts中配置的映射,填master或者直接填IP都是一样的)3、配置conf下的slaves文件sudo gedit conf/slaves(打开后将里面内容清空,然后添加“slave”或者slave 的IP“192.168.1.11”,原因同上)4、配置conf下的core-site.xml文件sudo gedit conf/core-site.xml(因为已完成单节点配置,因此只需要修改就行了。
打开后将第一个<property>标签中的localhost改为“master”或者master的IP,如下Xml代码1.<property>2. <name></name>3. <value>hdfs://master:9000</value>4.</property>第二个<property> 标签,即包含<name>dfs.replication</name>一行的那个,其中的“<value>”表示文件上传到dfs上时的备份个数,此数值不能大于slave即datanode的个数)5、配置conf下的hdfs-site.xml文件(此配置在slave 节点上可有可无)sudo gedit conf/hdfs-site.xml(打开后在空的<configuration> </configuration>中添加如下配置Xml代码1.<property>2. <name>dfs.replication</name>3. <value>1</value>4.</property>5.6.<property>7. <name>.dir</name>8. <value>/home/hadoop/hdfs/name</value>9.</property>10.11.<property>12. <name>dfs.data.dir</name>13. <value>/home/hadoop/hdfs/data</value>14.</property>6、配置conf下的mapred-site.xml文件sudo gedit conf/mapred-site.xml(打开后将<value>标签里的localhost改为JobTracker的IP,因为本例中JobTracker也是master本身,所以将localhost改为“master”或master的IP)2、在所有slave节点上拷贝master和JobTracker的公钥1、拷贝公钥scp hadoop@master:/home/hadoop/.ssh/id_rsa.pub/home/hadoop/.ssh/master_rsa.pubscp hadoop@master:/home/hadoop/.ssh/id_rsa.pub/home/haddop/.ssh/jobtracker_rsa.pub(注:因为本例中master和JobTracker是同一台机器,所以相当于在master上拷了两次公钥)2、将拷贝的公钥添加到信任列表cat /home/hadoop/.ssh/master_rsa.pub >>/home/hadoop/.ssh/authorized_keyscat /home/hadoop/.ssh/jobtracker_rsa.pub >>/home/hadoop/.ssh/authorized_keys3、在JobTracker上拷贝master的公钥1、拷贝公钥scp hadoop@master:/home/hadoop/.ssh/id_rsa.pub/home/hadoop/.ssh/master_rsa.pub(注:本例中master和JobTracker是同一台机器,所以相当于自己拷自己的公钥.....囧......)2、添加到信任列表cat /home/hadoop/.ssh/master_rsa.pub >>/home/hadoop/.ssh/authorized_keys运行阶段:1、启动hadoop1、在所有节点上删除/home/hadoop/下的tmp文件夹(包括master节点)sudo rm -r /home/hadoop/tmp(注:tmp文件夹内部存放有NameNode的ID信息,如果ID不一样的话是无法正常连接的,此处的删除操作是为了保证ID的一致性)2、在master上格式化NameNodehadoop namenode -format3、启动hadoopbin/start-all.sh4、查看各节点是否正常启动jps(此语句执行后,slave节点中必须有DataNode,master 节点中必须有NameNode,否则启动失败)5、查看整个系统状态hadoop dfsadmin -report(此语句执行后能显示当前连接的slave数,即DataNode 数)2、跑wordcount1、准备测试文件sudo echo "mu ha ha ni da ye da ye da da" >/tmp/test.txt2、将测试文件上传到dfs文件系统hadoop dfs -put /tmp/test.txt multiTest(注:如multiTest目录不存在的话会自动创建)3、执行wordcounthadoop jar hadoop-mapred-examples0.21.0.jar wordcout multiTest result(注:如result目录不存在的话会自动创建)4、查看结果hadoop dfs -cat result/part-r-00000至此集群环境搭建完毕~!补充说明:网上文档中说的关于“关闭防火墙”和“关闭安全模式”,我们在实践中并未涉及到,如遇到连接不到datanode的问题,请检查您的hosts文件中是否最上面多出两行,如果是的话请删除,然后重新按照“运行阶段”的步骤来。
(1)每三个人一组,在Vbox的配置—>网络中,修改网络为:桥接网络。
(2)修改物理机和虚拟机的地址在同一网络,均使用192.168.X.Y,每组的X取值不同,以防地址冲突。
IP配置命令:
(3)测试组内所有的物理机、虚拟机相互之间是否可ping通。
文件,使得三个节点可使用机器名相互访问
2)下图为解决不能连接端口号22的方法
3)拷贝公钥到namenode节点:
$scp authorized_keys test1:/home/grid/.ssh
$scp authorized_keys test2:/home/grid/.ssh
4)进入各节点的.ssh目录,改变authorized_keys文件权限$chmod 644 authorized_keys
(4)在所有机器上配置Hadoop
1)在ubuntunamenode上配置
编辑core-site.xml、hdfs-site.xml和mapred-site.xml core-site.xml
hdfs-site.xml
mapred-site.xml
编辑conf/masters,修改为master的主机名,每个主机名一行,即test1;编辑conf/slaves,加入所有slaves的主机名,即test2和test3;
2)把Hadoop安装文件复制到其他机器上
$ scp –r hadoop-0.20.2 ubuntudata1:/home/grid
$ scp –r hadoop-0.20.2 test2:/home/grid
3)编辑所有机器的conf/hadoop-env.sh文件
(5)Hadoop运行
1)格式化分布式文件系统
$bin/hadoop namenode -format
2)启动Hadoop守护进程
$ bin/start-all.sh
$/usr/java/jdk1.6.0_24/bin/jps
(可使用Java的jps命令查看已运行的进程:Namenode, JobTracker)
(6)熟练使用HDFS命令
1)上传一个大文件到Hadoop集群,在HDFS中查看文件在各节点的存放情况; 2)编写程序读写Hadoop集群上的文件;
3)在Hadoop集群上运行Mapreduce示例程序
4)查看运行结果。