自回归模型的参数估计案例
- 格式:doc
- 大小:454.00 KB
- 文档页数:13
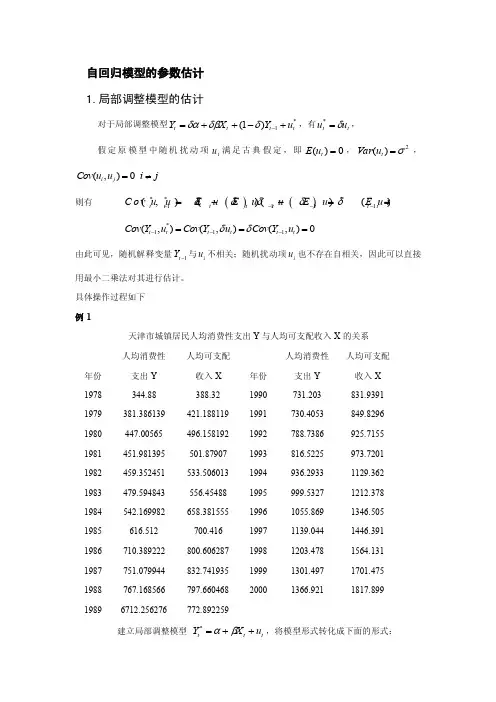
自回归模型的参数估计 1.局部调整模型的估计对于局部调整模型*1)1(t t t t u Y X Y +-++=-δδβδα,有t t u u δ=*,假定原模型中随机扰动项t u 满足古典假定,即0)(=t u E ,2)(σ=t u Var ,(,)0i j Cov u u i j =≠则有 ()()**21111(,)()()()0t t t t t tt t C o v u u E uE u uE u E u u δδδδδ----=--==*111(,)(,)(,)0t t t t t t Cov Y u Cov Y u Cov Y u δδ---===由此可见,随机解释变量1-t Y 与i u 不相关;随机扰动项i u 也不存在自相关,因此可以直接用最小二乘法对其进行估计。
具体操作过程如下 例1天津市城镇居民人均消费性支出Y 与人均可支配收入X 的关系 年份 人均消费性支出Y 人均可支配 收入X 年份 人均消费性支出Y 人均可支配收入X 1978 344.88 388.32 1990 731.203 831.9391 1979 381.386139 421.188119 1991 730.4053 849.8296 1980 447.00565 496.158192 1992 788.7386 925.7155 1981 451.981395 501.87907 1993 816.5225 973.7201 1982 459.352451 533.506013 1994 936.2933 1129.362 1983 479.594843 556.45488 1995 999.5327 1212.378 1984 542.169982 658.381555 1996 1055.869 1346.505 1985 616.512 700.416 1997 1139.044 1446.391 1986 710.389222 800.606287 1998 1203.478 1564.131 1987 751.079944 832.741935 1999 1301.497 1701.475 1988 767.168566 797.660468 2000 1366.9211817.89919896712.256276772.892259建立局部调整模型 t t t u X Y ++=βα*,将模型形式转化成下面的形式:*1*1*0*t t t t u Y X Y +++=-ββα然后直接用OLS 法估计模型参数。




一阶自回归的方差协方差矩阵
一阶自回归模型(AR(1))的方差协方差矩阵可以通过自回归模型的参数估计来计算。
假设AR(1)模型为:
X_t = c + φ*X_{t-1} + ε_t
其中,X_t表示时间t的随机变量,c是常数项,φ是自回归系数,ε_t是时间t的随机误差项。
方差协方差矩阵可以表示为:
Var(X_t) = Var(c + φ*X_{t-1} + ε_t)
= φ^2 * Var(X_{t-1}) + Var(ε_t)
因为AR(1)模型中的随机变量是序列相关的,所以需要计算时间t-1的随机变量X_{t-1}的方差。
根据AR(1)模型,可以得到X_{t-1}的方差为:
Var(X_{t-1}) = Var(c + φ*X_{t-2} + ε_{t-1})
= φ^2 * Var(X_{t-2}) + Var(ε_{t-1})
通过递归计算,可以得到方差协方差矩阵的形式为:
Var(X_t) = φ^2 * Var(X_{t-1}) + Var(ε_t)
= φ^2 * (φ^2 * Var(X_{t-2}) + Var(ε_{t-1})) + Var(ε_t)
= φ^4 * Var(X_{t-2}) + φ^2 * Var(ε_{t-1}) + Var(ε_t)
= …
可以发现,方差协方差矩阵的形式为无穷级数。
一般情况下,我们可以假设时间序列满足平稳性(即方差和自相关系数随时间不变),从而简化方差协方差矩阵的计算。


一、概述Matlab是一种强大的数学建模和仿真工具,广泛应用于工程、科学和经济领域。
ARIMA(自回归移动平均)模型是一种常用的时间序列分析方法,可以用来预测未来的数据趋势。
在本文中,我们将介绍如何使用Matlab来解arima模型,并通过例题来演示建模的步骤。
二、ARIMA模型简介ARIMA模型是由自回归(AR)和移动平均(MA)两部分组成的时间序列模型,它的主要思想是利用过去的数据来预测未来的数据。
ARIMA模型的一般形式为ARIMA(p, d, q),其中p、d和q分别代表自回归阶数、差分次数和移动平均阶数。
在Matlab中,可以使用“arima”函数来进行ARIMA模型的建模和预测。
三、ARIMA模型的建模步骤在使用Matlab解ARIMA模型时,一般包括以下几个步骤:1. 数据准备首先需要准备好要分析的时间序列数据,通常会涉及数据的收集、清洗和准备工作。
在Matlab中,可以将数据导入为时间序列对象,并进行必要的数据转换和处理。
2. 模型拟合接下来需要使用“arima”函数来拟合ARIMA模型。
在拟合模型时,需要指定ARIMA模型的阶数p、d和q,以及模型的其他参数。
Matlab会自动对模型进行参数估计,并输出模型的拟合结果和诊断信息。
3. 模型诊断拟合完成后,需要进行模型诊断来评估模型的拟合效果。
可以通过查看拟合残差序列的自相关和偏自相关图,以及进行Ljung-Box检验等方法来检验模型的残差序列是否符合白噪声假设。
4. 模型预测可以使用拟合好的ARIMA模型来进行预测。
在Matlab中,可以使用“forecast”函数来生成未来一定时间范围内的预测值,并可视化预测结果。
四、示例下面通过一个简单的示例来演示使用Matlab解ARIMA模型的建模步骤。
假设有一组销售数据,我们需要对未来的销售量进行预测。
我们将数据导入为时间序列对象:```matlabsales = [100, 120, 150, 130, 140, 160, 180, 200, 190, 210];dates = datetime(2022,1,1):calmonths(1):datetime(2022,10,1); sales_ts = timeseries(sales, dates);```使用“arima”函数拟合ARIMA模型:```matlabmodel = arima('ARLags',1,'Order',[1,1,1]);estmodel = estimate(model,sales_ts);```进行模型诊断:```matlabres = infer(estmodel,sales_ts);figuresubplot(2,1,1)plot(res)subplot(2,1,2)autocorr(res)```使用拟合好的模型进行预测:```matlab[yf,yMSE] = forecast(estmodel,5,'Y0',sales,'MSE0',res.^2);```通过以上步骤,我们成功地建立了ARIMA模型,并对未来5个月的销售量进行了预测。

自回归模型的参数估计案例案例一:建立中国长期货币流通量需求模型。
中国改革开放以来,对货币需求量(Y)的影响因素,主要有资金运用中的贷款额(X)以及反映价格变化的居民消费者价格指数(P)。
长期货币流通量模型可设定为Y—B o "iX t +為只+片(1)其中,Y t e为长期货币流通需求量。
由于长期货币流通需求量不可观测,作局部调整:Y t -YL(Y t e-Y.)(2)其中,Y为实际货币流通量。
将(1)式代入(2)得短期货币流通量需求模型:Y 二o Mt 2p (1- )Y「J表1中列出了1978年到2007年我国货币流通量、贷款额以及居民消费者价格指数的相关数据。
居民消费者价格指数年份货币流通量Y (亿元)贷款额X (亿元)P (1990 年=100)1978212.046.21850.01979267.747.12039.61980346.250.62414.31981396.351.92860.21982439.152.93180.61983529.854.03589.91984792.155.54766.11985987.860.65905.6 19861218.464.67590.819871454.569.39032.519882134.082.310551.3 19892344.097.014360.1 19902644.4100.017680.7 19913177.8103.421337.8 19924336.0110.026322.9 19935864.7126.232943.1 19947288.6156.739976.0 19957885.3183.450544.1 19968802.0198.761156.6 199710177.6204.274914.1 199811204.2202.686524.1 199913455.5199.793734.3200014652.7200.699371.1 200115688.8201.9112314.7 200217278.0200.3131293.9 200319746.0202.7158996.2 200421468.3210.6178197.8 200524031.7214.4194690.4 200627072.6217.7225347.2 200730375.2228.1261690.9对局部调整模型1X t + P2r t(1-「JYx ”运用OLS法估计结果如图1:D E餐n血nt Vanable Y fJethac Least Squares Date Tima 21 12Sample r3C|U3tedj 1979 2007Included otsen'aticns 29 after adj」wtnignt辱Vansble Coefficient Std Errcr t-Statistic ProbC-202 5275 221 964S -O 91Z430 0 3703X0D36T100012565 2842001 C 003SP 7 4557283065733 2.431956 C 022bYM)0 723634 0 132796 5 449199 0 0030^squared 0.9985B2F^ean depencent /ar 9059.631Adjjsted R-squared 0.998412S.D lepsndent ,ar 9007.257S.E of regression358.9392 Akaike irfir ci iltn uri14.73163Sum squand rssid 3220934Schwarz cnterior U 92022Loc likelihcod-209.6086 F-statisti:50E8 997L;urb i r-atscn sta:1724407ProbiF-statistic)U U'JUUJU图1回归估计结果由图1短期货币流通量需求模型的估计式:Y = -202.5+ 0.0357Xt + 7.4557R + 0.7236Y T 由参数估计结果? 0.7236,得? 0.2764o由于= -202.5= 0.0357, 、2 = 7.4557。

ARIMA模型预测案例假设我们要预测公司未来一年的销售额,已经收集到了该公司过去几年的销售额数据,我们希望通过ARIMA模型对未来的销售额进行预测。
首先,我们需要对销售额数据进行初步的可视化和分析。
通过绘制时间序列图,可以观察到销售额的趋势、季节性和随机性。
这些特征将有助于我们选择ARIMA模型的参数。
接下来,我们需要对数据进行平稳性检验。
ARIMA模型要求时间序列具有平稳性,即序列的均值和方差不随时间变化。
可以通过ADF检验或单位根检验来判断序列是否平稳。
如果序列不平稳,我们需要对其进行差分处理,直到达到平稳性。
接下来,我们需要确定ARIMA模型的参数。
ARIMA模型由AR(自回归)、I(差分)和MA(移动平均)三个部分组成。
AR部分反映了序列的自相关性,MA部分反映了序列的滞后误差,I部分反映了序列的差分情况。
我们可以使用自相关函数(ACF)和部分自相关函数(PACF)的图像来帮助确定ARIMA模型的参数。
根据ACF和PACF图像的分析,我们可以选择初始的ARIMA模型参数,并使用最大似然估计方法来进行模型参数的估计和推断。
然后,我们可以拟合ARIMA模型,并检查拟合优度。
接着,我们需要进行模型诊断,检查模型的残差是否满足白噪声假设。
可以通过Ljung-Box检验来判断残差的相关性。
如果残差不满足白噪声假设,我们需要重新调整模型的参数,并进行重新拟合。
最后,我们可以利用已经训练好的ARIMA模型对未来的销售额进行预测。
通过调整模型的参数,我们可以得到不同时间范围内的销售额预测结果。
需要注意的是,ARIMA模型的预测结果仅仅是一种可能的情况,并不代表未来的真实情况。
因此,在实际应用中,我们需要结合其他因素和信息来进行决策。
综上所述,ARIMA模型是一种经典的时间序列预测方法,在实际应用中具有广泛的应用价值。
通过对时间序列数据的分析和模型的建立,我们可以对未来的趋势进行预测,并为决策提供参考。
然而,ARIMA模型也有一些限制,如对数据的平稳性要求较高,无法考虑其他因素的影响等。


时变参数向量自回归模型1. 引言时变参数向量自回归模型(Time-Varying Parameter Vector Autoregressive Model,TVAR)是一种用于分析时间序列数据的经济计量模型。
它可以捕捉到时间序列数据中的动态性和非线性关系,因此在经济学、金融学等领域被广泛应用。
本文将介绍时变参数向量自回归模型的基本原理、建模方法以及应用案例,帮助读者全面了解该模型。
2. 基本原理2.1 自回归模型自回归模型(Vector Autoregressive Model,VAR)是一种多元时间序列分析方法。
它假设时间序列数据之间存在线性关系,并可以通过过去若干期的数据来预测未来的值。
VAR模型可以表示为:Y t=c+Φ1Y t−1+Φ2Y t−2+⋯+Φp Y t−p+εt其中,Y t是一个n维向量,表示第t期的观测值;c是一个常数向量;Φ1,Φ2,…,Φp是n×n的系数矩阵,表示自回归系数;εt是一个n维向量,表示误差项。
2.2 时变参数向量自回归模型时变参数向量自回归模型是在VAR模型的基础上引入了时变参数的扩展模型。
它认为自回归系数在时间上是可变的,可以通过某种方式来描述其动态性。
时变参数向量自回归模型可以表示为:Y t=c+Φ1(t)Y t−1+Φ2(t)Y t−2+⋯+Φp(t)Y t−p+εt其中,Φi(t)表示第i个滞后期的自回归系数在时间t上的取值。
3. 建模方法3.1 参数估计对于时变参数向量自回归模型,参数估计是一个关键步骤。
常用的方法有贝叶斯方法、频域方法和局部似然方法等。
贝叶斯方法通过引入先验分布来估计参数,可以获得参数的后验分布。
频域方法利用频域上的特征来估计参数,可以捕捉到数据的周期性。
局部似然方法则在每个时间点上估计参数,可以灵活地适应时变性。
3.2 模型选择在建立时变参数向量自回归模型时,需要选择合适的滞后阶数和模型形式。
滞后阶数决定了过去多少期的数据被考虑进模型中,一般通过信息准则(如AIC、BIC等)来选择最优阶数。
自回归模型(Autoregressive Model)是一种经典的时间序列预测模型,在许多领域中都有着广泛的应用。
它的核心思想是利用过去时间点的观测值来预测未来的观测值。
在本文中,我将介绍自回归模型的概念,并使用Python实现一个简单的自回归模型。
1.自回归模型概述自回归模型是建立在时间序列数据上的统计模型。
它假设当前时刻的观测值是过去时刻的观测值的线性组合,其中线性关系由模型的参数确定。
自回归模型可以被表示为如下形式:X_t = c + Σ(φ_i *X_(t-i)) + ε_t 其中,X_t是当前时刻的观测值,c是常数项,φ_i是参数,ε_t是误差项。
根据历史观测值和参数的不同,自回归模型可以分为不同阶数的自回归模型,如一阶自回归模型(AR(1))、二阶自回归模型(AR(2))等。
2.自回归模型的Python实现为了实现自回归模型,我们需要借助Python中的统计分析库statsmodels。
我们需要安装statsmodels库,可以使用以下命令进行安装: pip install statsmodels接下来,我们使用一个示例数据集来演示自回归模型的实现。
假设我们有一个包含100个观测值的时间序列数据,可以使用以下代码生成一个随机的时间序列数据:import numpy as np生成随机时间序列数据np.random.seed(0) data = np.random.randn(100)我们可以使用statsmodels库中的AR模型来建立自回归模型,并进行参数估计和预测。
以下是一个简单的自回归模型的实现代码示例: fromstatsmodels.tsa.ar_model import AutoReg构建AR模型model = AutoReg(data, lags=1)拟合模型model_fit = model.fit()打印模型系数print(model_fit.params)进行单步预测predictions = model_fit.predict(start=len(data), end=len(data))print(predictions)在上述代码中,我们首先使用AutoReg类构建了一个自回归模型,其中lags参数指定了模型的阶数,这里我们选择了一阶自回归模型(lags=1)。
案例二 ARMA 模型建模与预测指导一、实验目的学会通过各种手段检验序列的平稳性;学会根据自相关系数和偏自相关系数来初步判断ARMA 模型的阶数p 和q ,学会利用最小二乘法等方法对ARMA 模型进行估计,学会利用信息准则对估计的ARMA 模型进行诊断,以及掌握利用ARMA 模型进行预测。
掌握在实证研究中如何运用Eviews 软件进行ARMA 模型的识别、诊断、估计和预测和相关具体操作.二、基本概念宽平稳:序列的统计性质不随时间发生改变,只与时间间隔有关。
AR 模型:AR 模型也称为自回归模型.它的预测方式是通过过去的观测值和现在的干扰值的线性组合预测, 自回归模型的数学公式为:1122t t t p t p t y y y y φφφε---=++++式中: p 为自回归模型的阶数i φ(i=1,2, ,p )为模型的待定系数,t ε为误差, t y 为一个平稳时间序列。
MA 模型:MA 模型也称为滑动平均模型。
它的预测方式是通过过去的干扰值和现在的干扰值的线性组合预测。
滑动平均模型的数学公式为:1122t t t t q t q y εθεθεθε---=----式中: q 为模型的阶数; j θ(j=1,2, ,q )为模型的待定系数;t ε为误差; t y 为平稳时间序列。
ARMA 模型:自回归模型和滑动平均模型的组合, 便构成了用于描述平稳随机过程的自回归滑动平均模型ARMA, 数学公式为:11221122t t t p t p t t t q t q y y y y φφφεθεθεθε------=++++----三、实验内容及要求1、实验内容:(1)根据时序图判断序列的平稳性;(2)观察相关图,初步确定移动平均阶数q 和自回归阶数p ;(3)运用经典B —J 方法对某企业201个连续生产数据建立合适的ARMA (,p q )模型,并能够利用此模型进行短期预测。
2、实验要求:(1)深刻理解平稳性的要求以及ARMA 模型的建模思想;(2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARMA 模型;如何利用ARMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果.四、实验指导 1、模型识别 (1)数据录入打开Eviews软件,选择“File"菜单中的“New--Workfile”选项,在“Workfile structure type”栏选择“Unstructured /Undated”,在“Date range”栏中输入数据个数201,点击ok,见图2—1,这样就建立了一个工作文件。
自回归模型的参数估计案例自回归模型(AutoRegressive Model, AR)是一种用来描述时间序列数据的统计模型,它的基本思想是将当前时间点的观测值与前一时间点的值相关联,通过线性组合来预测未来的观测值。
在本文中,我们将介绍一个用于估计自回归模型参数的案例。
假设我们有一个每日销售额的时间序列数据,我们希望建立一个自回归模型来预测未来的销售额。
我们使用美国家零售商的销售数据作为案例数据,数据集中包含了该零售商自2000年1月1日至2024年12月31日每天的销售额。
我们将使用Python中的statsmodels库进行模型拟合和参数估计。
首先,我们需要导入相关的库和数据集。
```pythonimport pandas as pdimport statsmodels.api as sm#读取数据data = pd.read_csv('sales_data.csv')```接下来,我们可以先观察一下数据的基本情况。
```pythondata.head```日期,销售额----------,--------2000/1/2,1605.02000/1/3,2096.02000/1/4,2579.02000/1/5,2894.0我们可以看到,数据集包含两列,一列是日期,另一列是销售额。
接下来,我们将日期列设置为数据的索引,并将销售额列转换为时间序列对象。
```python#将日期列设置为索引data.set_index('Date', inplace=True)#将销售额列转换为时间序列对象ts = data['Sales']```现在,我们可以开始建立自回归模型。
AR模型的一项关键任务是确定时滞(lag),即前一时间点(或多个时间点)对当前时间点的影响。
我们可以使用自相关图(ACF,Autocorrelation Function)和偏自相关图(PACF, Partial Autocorrelation Function)来帮助我们选择合适的时滞。
[编辑]案例一:ARlMA模型在海关税收预测中的应用2008年。
海关税收预算计划8400亿元.比2007年实际完成数增加10.8%,比2007年预算数增加22.1%。
为了对2008年江门海关税收总体形势进行把握,笔者尝试利用SAS 统计分析软件的时间序列预测模块建立ARIMA模型,对2008年江门海关税收总值进行预测。
从预测结果来看,预测模型拟合度较高,预测值也切合实际情况,预测模型具有一定的应用价值。
现将预测的方法、原理以及影响税收工作的相关因素分析。
一、ARlMA模型原理ARIMA模型全称为自回归移动平均模型(Autoregressive Integrated Moving Average Model,简记ARIMA)。
是由博克思(Box)fFfl詹金斯(Jenkins)于70年代初提出的一著名时问序列预测方法,所以又称为box--jenkins模型、博克思一詹金斯法。
其中ARIMA(p,d.q)称为差分自回归移动平均模型,AR是自回归,P为自回归项;MA为移动平均,q为移动平均项数,d为时间序列成为平稳时所做的差分次数。
ARIMA模型可分为3种:(1)自回归模型(简称AR模型);(2)滑动平均模型(简称MA模型);(3)自回归滑动平均混合模型(简称ARIMA模型)。
ARIMA模型的基本思想是:将预测对象随时问推移而形成的数据序列视为—个随机序列.以时间序列的自相关分析为基础.用一定的数学模型来近似描述这个序列。
这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
ARlMA模型在经济预测过程中既考虑了经济现象在时间序列上的依存性,又考虑了随机波动的干扰性,对于经济运行短期趋势的预测准确率较高,是近年应用比较广泛的方法之一。
二、应用ARIMA模型进行预测每月税收数据.可以看作是随着时间的推移而形成的一个随机时间序列,通过对该时间序列上税款值的随机性、平稳性以及季节性等因素的分析,将这些单月税收值之间所具有的相关性或依存关系用数学模型描述出来,从而达到利用过去及现在的税收值信息来预测未来税收情况的目的。
自回归模型的参数估计案例案例一:建立中国长期货币流通量需求模型。
中国改革开放以来,对货币需求量(Y)的影响因素,主要有资金运用中的贷款额(X)以及反映价格变化的居民消费者价格指数(P)。
长期货币流通量模型可设定为120e t t t t P Y X βμββ=+++ (1)其中,e t Y 为长期货币流通需求量。
由于长期货币流通需求量不可观测,作局部调整:11()e t t t t Y Y Y Y δ---=- (2)其中,t Y 为实际货币流通量。
将(1)式代入(2)得短期货币流通量需求模型:0121(1)t t t t t Y X P Y δβδβδβδδμ-=+++-+表1中列出了1978年到2007年我国货币流通量、贷款额以及居民消费者价格指数的相关数据。
表1年份 货币流通量Y (亿元)居民消费者价格指数P (1990年=100)贷款额X (亿元)1978212.046.2 1850.0 1979 267.7 47.1 2039.6 1980 346.2 50.6 2414.3 1981 396.3 51.9 2860.2 1982 439.1 52.9 3180.6 1983 529.8 54.0 3589.9 1984 792.1 55.5 4766.1 1985 987.8 60.6 5905.6 1986 1218.4 64.6 7590.8 19871454.569.39032.51988 2134.0 82.3 10551.3 1989 2344.0 97.0 14360.1 1990 2644.4 100.0 17680.7 1991 3177.8 103.4 21337.8 1992 4336.0 110.0 26322.9 1993 5864.7 126.2 32943.1 1994 7288.6 156.7 39976.0 1995 7885.3 183.4 50544.1 1996 8802.0 198.7 61156.6 1997 10177.6 204.2 74914.1 1998 11204.2 202.6 86524.1 1999 13455.5 199.7 93734.3 2000 14652.7 200.6 99371.1 2001 15688.8 201.9 112314.7 2002 17278.0 200.3 131293.9 2003 19746.0 202.7 158996.2 2004 21468.3 210.6 178197.8 2005 24031.7 214.4 194690.4 2006 27072.6 217.7 225347.2 200730375.2228.1261690.9对局部调整模型0121(1)t t t t t Y X P Y δβδβδβδδμ-=+++-+运用OLS 法估计结果如图1:图1 回归估计结果由图1短期货币流通量需求模型的估计式:1202.50.03577.45570.7236t t t t Y X P Y -=-+++由参数估计结果ˆ10.7236δ-=,得ˆ0.2764δ=。
由于0202.5δβ=-,10.0357δβ=,27.4557δβ=。
将ˆ0.2764δ=分别带入上述三个方程,可求得0732.6β=-,10.1292β=,226.97β=。
最后得到长期货币流通需求模型的估计式为:732.60.129226.97e t t t P Y X =-++估计结果表明:① 贷款额对我国货币流通量的影响,短期为0.0357,长期为0.1292,即贷款额每增加1亿元,短期货币流通需求量将增加0.0357亿元,长期货币流通需求量将增加0.1292亿元。
② 居民消费物价指数对我国货币流通量的影响,短期为7.4557,长期为26.97,即价格指数每增加1个百分点,将导致短期货币流通需求量增加7.4557亿元,长期货币流通需求量增加26.97亿元。
注意:尽管D.W.=1.724407,但不能据此判断自回归模型不存在自相关(Why?)。
由LM 检验或者B-G 检验可用于检验随机误差项的高阶自相关性。
LM 检验的Eviews 步骤: 1、 估计方程2、在Equation 窗口中单击“View ”→“Residual Test ” →“SerialCorrelation LM Test ”,并选择滞后期为1,屏幕将显示如图2所示的信息。
图2 回归结果在图2中,LM=0.636639,小于显著性水平5%下自由度为1的卡方分布的临界值20.05(1) 3.84x =,因此,可以接受随机误差项不存在一阶自相关性的原假设。
如果直接对下式作OLS 回归120t t t t P Y X βμββ=+++可得如图3的估计结果:图3 回归估计结果在图3中,D.W=0.959975,查自由度n=30,k=3的D.W.检验表可知dl=1.28,du=1.57,容易判断该模型随机误差项存在一阶正自相关。
事实上,对于自回归模型,μt 项的自相关问题始终存在,对于此问题,至今没有完全有效的解决方法。
唯一可做的,就是尽可能地建立“正确”的模型,以使序列相关性的程度减轻。
因此,上述短期货币流通量需求模型的估计式1202.50.03577.45570.7236t t t t Y X P Y -=-+++的设定更“正确”。
案例二(格兰杰因果关系检验)根据宏观经济学可知,可支配收入与消费之间可能存在互为因果的关系。
表2中列出了1978-2006年我国居民实际可支配收入与居民实际消费总支出的相关数据,下面我们检验1978~2006年间实际可支配收入(X )与居民实际消费总支出(Y)之间的因果关系。
表2年份 实际可支配收入(X )居民实际消费总支出(Y )1978 6678.800 3806.700 1979 7551.600 4273.200 1980 7944.200 4605.500 1981 8438.000 5063.900 1982 9235.200 5482.400 1983 10074.60 5983.200 1984 11565.00 6745.700 1985 11601.70 7729.200 1986 13036.50 8210.900 1987 14627.70 8840.000 1988 15794.00 9560.500 1989 15035.50 9085.500 1990 16525.90 9450.900 199118939.6010375.801992 22056.50 11815.301993 25897.30 13004.701994 28783.40 13944.201995 31175.40 15467.901996 33853.70 17092.501997 35956.20 18080.601998 38140.90 19364.101999 40277.00 20989.302000 42964.60 22863.902001 46385.40 24370.102002 51274.00 26243.202003 57408.10 28035.002004 64623.10 30306.202005 74580.40 33214.402006 85623.10 36811.20取1阶滞后,Eviews操作及输出结果为:在Eviews建立工作文件和录入数据后,格兰杰因果检验步骤为:步骤1:步骤2步骤3:单击OK后有如图1的检验结果:图1 X与Y的格兰杰因果关系检验结果在图1中,X不是Y的格兰杰原因的F=15.1022,Y不是X 的格兰杰原因的F6.34368,查m=1,n-k=28-3=25,显著性水平为5%的F分布表可知F0.05(1,25)=4.68,上述两个F统计量均大于4.68的临界值,所以均拒绝原假设,即:既拒绝“X不是Y的格兰杰原因”的假设,也拒绝“Y不是X的格兰杰原因”的假设。
另外,由相伴概率知,在5%的显著性水平下,既拒绝“X不是Y的格兰杰原因”的假设,也拒绝“Y不是X的格兰杰原因”的假设。
因此,从1阶滞后的情况看,可支配收入X的增长与居民消费支出Y增长互为格兰杰原因。
但是应该注意的是:格兰杰因果关系检验对于滞后期长度的选择有时很敏感。
不同的滞后期可能会得到完全不同的检验结果。
一般首先以模型随机误差项不存在序列相关为标准选取滞后期,然后进行因果关系检验。
因此我们还得检验模型随机误差项是否存在序列相关性。
由案例一可知LM检验可以检验高阶序列相关性(包括一阶序列相关),但DW不能够。
LM检验的步骤为:(以Y为被解释变量的模型为例)1、估计模型(ls y c y(-1) x(-1))2、在Equation窗口中单击“View”→“Residual Test”→“Serial Correlation LM Test”,并选择滞后期为1,屏幕将显示如图2所示的信息。
图2从图2检验模型随机干扰项1阶序列相关的LM检验看,以Y为被解释变量的模型的LM=0.740584,对应的伴随概率P= 0.389474,查显著性水平5%下自由度为1的卡方分布的临界值2 0.05(1) 3.84x ,表明在5%的显著性水平下,接受原假设,即该检验模型不存在序列相关性;但是,以X为被解释变量的模型中的LM=10.01871,对应的伴随概率P= 0.00155,表明在5%的显著性水平下,该检验模型存在严重的序列相关性(见图3)。
图3下面我们讨论滞后期分别为2阶和3阶的格兰杰因果检验。
2阶滞后的X与Y的格兰杰因果关系检验结果:3阶滞后的X与Y的格兰杰因果关系检验结果:从2阶滞后期开始,检验模型都拒绝了“X不是Y的格兰杰原因”的假设,而不拒绝“Y不是X的原因”的假设。
格兰杰因果关系检验对于滞后期长度的选择有时很敏感。
不同的滞后期可能会得到完全不同的检验结果。
下面分析模型随机误差项是否存在序列相关。
2阶滞后的以Y为因变量的LM检验结果2阶滞后的以X为因变量的LM检验结果3阶滞后的以Y为因变量的LM检验结果3阶滞后的以X为因变量的LM检验结果滞后阶数为2或3时,两类检验模型都不存在序列相关性。
由赤池信息准则,发现滞后2阶检验模型拥有较小的AIC值。
因此,可判断:可支配收入X是居民消费支出Y的格兰杰原因,而不是相反,即国民收入的增加更大程度地影响着消费的增加。