案例分析 一元线性回归模型
- 格式:docx
- 大小:30.68 KB
- 文档页数:6

第三章 一元线性回归模型一、预备知识(一)相关概念对于一个双变量总体,若由基础理论,变量和变量之间存在因果),(i i x y x y 关系,或的变异可用来解释的变异。
为检验两变量间因果关系是否存在、x y 度量自变量对因变量影响的强弱与显著性以及利用解释变量去预测因变量x y x ,引入一元回归分析这一工具。
y 将给定条件下的均值i x i yi i i x x y E 10)|(ββ+=(3.1)定义为总体回归函数(PopulationRegressionFunction,PRF )。
定义为误差项(errorterm ),记为,即,这样)|(i i i x y E y -i μ)|(i i i i x y E y -=μ,或i i i i x y E y μ+=)|(i i i x y μββ++=10(3.2)(3.2)式称为总体回归模型或者随机总体回归函数。
其中,称为解释变量x (explanatory variable )或自变量(independent variable );称为被解释y 变量(explained variable )或因变量(dependent variable );误差项解释μ了因变量的变动中不能完全被自变量所解释的部分。
误差项的构成包括以下四个部分:(1)未纳入模型变量的影响(2)数据的测量误差(3)基础理论方程具有与回归方程不同的函数形式,比如自变量与因变量之间可能是非线性关系(4)纯随机和不可预料的事件。
在总体回归模型(3.2)中参数是未知的,是不可观察的,统计计10,ββi μ量分析的目标之一就是估计模型的未知参数。
给定一组随机样本,对(3.1)式进行估计,若的估计量分别记n i y x i i ,,2,1),,( =10,),|(ββi i x y E 为,则定义3.3式为样本回归函数^1^0^,,ββi y ()i i x y ^1^0^ββ+=n i ,,2,1 =(3.3)注意,样本回归函数随着样本的不同而不同,也就是说是随机变量,^1^0,ββ它们的随机性是由于的随机性(同一个可能对应不同的)与的变异共i y i x i y x 同引起的。

一元线性回归模型案例分析一元线性回归是最基本的回归分析方法,它的主要目的是寻找一个函数能够描述因变量对于自变量的依赖关系。
在一元线性回归中,我们假定存在满足线性关系的自变量与因变量之间的函数关系,即因变量y与单个自变量x之间存在着线性关系,可表达为:y=β0+ β1x (1)其中,β0和β1分别为常量,也称为回归系数,它们是要由样本数据来拟合出来的。
因此,一元线性回归的主要任务就是求出最优回归系数和平方和最小平方根函数,从而评价模型的合理性。
下面我们来介绍如何使用一元线性回归模型进行案例分析。
数据收集:首先,研究者需要收集自变量和因变量之间关系的相关数据。
这些数据应该有足够多的样本观测值,以使统计分析结果具有足够的统计力量,表示研究者所研究的关系的强度。
此外,这些数据的收集方法也需要正确严格,以避免因相关数据缺乏准确性而影响到结果的准确性。
模型构建:其次,研究者需要利用所收集的数据来构建一元线性回归模型。
即建立公式(1),求出最优回归系数β0和β1,即最小二乘法拟合出模型方程式。
模型验证:接下来,研究者需要对所构建的一元线性回归模型进行验证,以确定模型精度及其包含的统计意义。
可以使用F检验和t检验,以检验回归系数β0和β1是否具有统计显著性。
另外,研究者还可以利用R2等有效的拟合检验统计指标来衡量模型精度,从而对模型的拟合水平进行评价,从而使研究者能够准确无误地判断其研究的相关系数的统计显著性及包含的统计意义。
另外,研究者还可以利用偏回归方差分析(PRF),这是一种多元线性回归分析技术,用于计算每一个自变量对相应因变量的贡献率,使研究者能够对拟合模型中每一个自变量的影响程度进行详细的分析。
模型应用:最后,研究者可以利用一元线性回归模型进行应用,以实现实际问题的求解以及数据挖掘等功能。
例如我们可以使用这一模型来预测某一物品价格及销量、研究公司收益及投资、检测影响某一地区经济发展的因素等。
综上所述,一元线性回归是一种利用单变量因变量之间存在着线性关系来拟合出回归系数的回归分析方法,它可以应用于许多不同的问题,是一种非常实用的有效的统计分析方法。

实验报告金融系金融学专业级班实验人:实验地点:实验日期:实验题目:进行相应的分析,揭示某地区住宅建筑面积与建造单位成本间的关系实验目的:掌握最小二乘法的基本方法,熟练运用Eviews软件的一元线性回归的操作,并能够对结果进行相应的分析。
实验内容:实验采用了建筑地编号为1号至12号的数据,通过模型设计、估计参数、检验统计量、回归预测四个步骤对数据进行相关分析。
实验步骤:一、模型设定1.建立工作文件。
双击eviews,点击File/New/Workfile,在出现的对话框中选择数据频率,因为该例题中为截面数据,所以选择unstructured/undated,在observations中设定变量个数,这里输入12。
图12.输入数据。
在eviews 命令框中输入data X Y,回车出现group窗口数据编辑框,在对应的X,Y下输入数据,这里我们可以直接将excel中被蓝笔选中的部分用cirl+c复制,在窗口数据编辑框中1所对应的框中用cirl+v粘贴数据。
图23.作X与Y的相关图形。
为了初步分析建筑面积(X)与建造单位成本(Y)的关系,可以作以X为横坐标、以Y为纵坐标的散点图。
方法是同时选中工作文件中的对象X和Y,双击得X和Y的数据表,点View/Graph/scatter,在File lines中选择Regressions line/ok(其中Regressions line为趋势线)。
得到如图3所示的散点图。
图3 散点图从散点图可以看出建造单位成本随着建筑面积的增加而降低,近似于线性关系,为分析建造单位成本随建筑面积变动的数量规律性,可以考虑建立如下的简单线性回归模型:二、估计参数假定所建模型及其中的随机扰动项满足各项古典假定,可以用OLS法估计其参数。
Eviews软件估计参数的方法如下:在eviews命令框中键入LS Y C X,按回车,即出现回归结果。
Eviews的回归结果如图4所示。
图4 回归结果可用规范的形式将参数估计和检验结果写为:(19.2645)(4.8098)t=(95.7969)(-13.3443)0.9468 F=178.0715 n=12若要显示回归结果的图形,在equation框中,点击resids,即出现剩余项、实际值、拟合值的图形,如图5所示。

第二章 一元线性回归模型典型例题分析例1、令kids 表示一名妇女生育孩子的数目,educ 表示该妇女接受过教育的年数。
生育率对教育年数的简单回归模型为μββ++=educ kids 10(1)随机扰动项μ包含什么样的因素?它们可能与教育水平相关吗?(2)上述简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
例2.已知回归模型μβα++=N E ,式中E 为某类公司一名新员工的起始薪金(元),N 为所受教育水平(年)。
随机扰动项μ的分布未知,其他所有假设都满足。
如果被解释变量新员工起始薪金的计量单位由元改为100元,估计的截距项与斜率项有无变化?如果解释变量所受教育水平的度量单位由年改为月,估计的截距项与斜率项有无变化?例3.对于人均存款与人均收入之间的关系式t t t Y S μβα++=使用美国36年的年度数据得如下估计模型,括号内为标准差:)011.0()105.151(067.0105.384ˆtt Y S +==0.538 023.199ˆ=σ (1)β的经济解释是什么?(2)α和β的符号是什么?为什么?实际的符号与你的直觉一致吗?如果有冲突的话,你可以给出可能的原因吗?(3)对于拟合优度你有什么看法吗? (4)检验统计值?例4.下列方程哪些是正确的?哪些是错误的?为什么?⑴ y xt n t t=+=αβ12,,, ⑵ yx t n t tt=++=αβμ12,,, ⑶ y x t n t t t=++= ,,,αβμ12⑷ ,,,y x t n t t t =++=αβμ12 ⑸ y x t n t t =+= ,,,αβ12 ⑹ ,,,y x t n t t=+=αβ12 ⑺ y x t n t t t =++= ,,,αβμ12 ⑻ ,,,y x t n t t t=++=αβμ12 其中带“^”者表示“估计值”。
例5.对于过原点回归模型i i i u X Y +=1β ,试证明∑=∧221)(iu X Var σβ例6、对没有截距项的一元回归模型i i i X Y μβ+=1称之为过原点回归(regression through the origin )。


线性回归20094788 陈磊 计算2SouthWest JiaoT ong U niversity-------------------------------------------------------------------线性回归分为一元线性回归和多元线性回归。
一元线性回归的模型为Y=β0+β1X+ε,这里X是自变量,Y是因变量,ε是随机误差项。
通常假设随机误差的均值为0,方差为σ2(σ2>0),σ2与X的值无关。
若进一步假设随机误差服从正态分布,就叫做正态线性模型。
一般情况,设有k个自变量和一个因变量,因变量的值可以分解为两部分:一部分是由于自变量的影响,即表示为自变量的函数,其中函数形式已知,但含有一些未知参数;另一部分是由于其他未被考虑的因素和随机性的影响,即随机误差。
当函数形式为未知参数的线性函数时,称为线性回归分析模型。
如果存在多个因变量,则回归模型为:Y=β0+β1X1+β2X2+⋯+βi X i+ε。
由于直线模型中含有随机误差项,所以回归模型反映的直线是不确定的。
回归分析的主要目的是要从这些不确定的直线中找出一条最能拟合原始数据信息的直线,并将其作为回归模型来描述因变量和自变量之间的关系,这条直线被称为回归方程。
通常在回归分析中,对ε有以下最为常用的经典假设。
1、ε的期望值为0.2、ε对于所有的X而言具有同方差性。
3、ε是服从正态分布且相互独立的随机变量。
对线性回归的讲解,本文以例题为依托展开。
在下面的例题中既有一元回归分析,又有二元回归分析。
例题(《数据据分析方法》_习题2.4_page79)某公司管理人员为了解某化妆品在一个城市的月销量Y(单位:箱)与该城市中适合使用该化妆品的人数X1(单位:千人)以及他们人均月收入X2(单位:元)之间的关系,在某个月中对15个城市作了调查,得到上述各量的观测值如表2.12所示。
假设Y与X1,X2之间满足线性回归关系y i=β0+β1x i1+β2x i2+εi,i=1,2,…,15其中εi独立同分布于N(0,σ2).(1)求线性回归系数β0,β1,β2的最小二乘估计和误差方差σ2的估计,写出回归方程并对回归系数作解释;(2)求出方差分析表,解释对线性回归关系显著性检验结果。

一元线性回归模型案例一元线性回归模型是统计学中最基本、应用最广泛的一种回归分析方法,可以用来探究自变量与因变量之间的线性关系。
一元线性回归模型的数学公式为:y = β0 + β1x,其中y表示因变量,x表示自变量,β0和β1分别为截距和斜率。
下面以一个实际案例来说明一元线性回归模型的应用。
假设我们有一组数据,其中x表示一个房屋的面积,y表示该房屋的售价,我们想利用一元线性回归模型来预测房屋的售价。
首先,我们需要收集一组已知数据,包括房屋的面积和售价。
假设我们收集了10个不同房屋的面积和售价数据,如下所示:房屋面积(x)(平方米)售价(y)(万元)80 12090 130100 140110 150120 160130 170140 180150 190160 200170 210我们可以根据这组数据绘制散点图,横坐标表示房屋面积x,纵坐标表示售价y,如下所示:(插入散点图)接下来,我们可以利用最小二乘法来拟合一条直线,使其能够最好地拟合这些散点。
最小二乘法是一种最小化误差平方和的方法,可以得到最优的拟合直线。
根据一元线性回归模型的公式,可以通过计算拟合直线的斜率β1和截距β0来实现最小二乘法。
其中,斜率β1可以通过下式计算得到:β1 = n∑(xiyi) - (∑xi)(∑yi)n∑(xi^2) - (∑xi)^2截距β0可以通过下式计算得到:β0 = (1/n)∑yi - β1(1/n)∑xi通过带入已知数据,我们可以计算得到斜率β1和截距β0的具体值。
在本例中,计算结果如下:β1 ≈ 1.0667β0 ≈ 108.6667最后,利用得到的斜率β1和截距β0,我们可以得到一元线性回归模型的具体公式为:y ≈ 108.6667 + 1.0667x我们可以利用这个回归模型进行预测。
例如,如果有一个房屋的面积为130平方米,那么根据回归模型,可以预测该房屋的售价为170 + 108.6667 ≈ 278.6667万元。

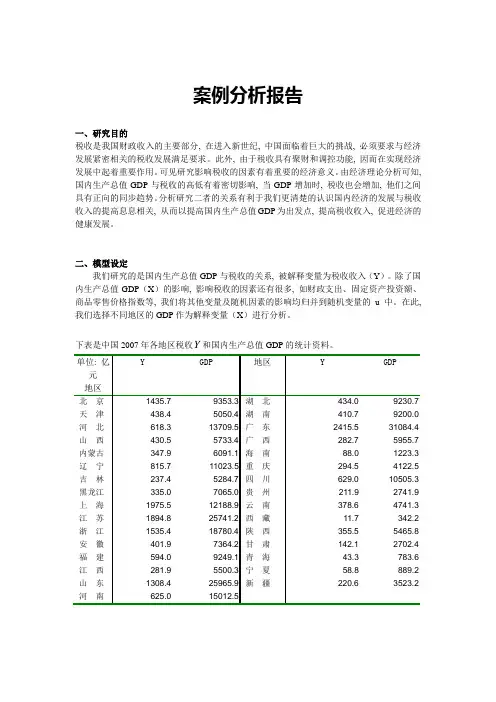
案例分析报告一、研究目的税收是我国财政收入的主要部分, 在进入新世纪, 中国面临着巨大的挑战, 必须要求与经济发展紧密相关的税收发展满足要求。
此外, 由于税收具有聚财和调控功能, 因而在实现经济发展中起着重要作用。
可见研究影响税收的因素有着重要的经济意义。
由经济理论分析可知, 国内生产总值GDP与税收的高低有着密切影响, 当GDP增加时, 税收也会增加, 他们之间具有正向的同步趋势。
分析研究二者的关系有利于我们更清楚的认识国内经济的发展与税收收入的提高息息相关, 从而以提高国内生产总值GDP为出发点, 提高税收收入, 促进经济的健康发展。
二、模型设定我们研究的是国内生产总值GDP与税收的关系, 被解释变量为税收收入(Y)。
除了国内生产总值GDP(X)的影响, 影响税收的因素还有很多, 如财政支出、固定资产投资额、商品零售价格指数等, 我们将其他变量及随机因素的影响均归并到随机变量的u中。
在此, 我们选择不同地区的GDP作为解释变量(X)进行分析。
下表是中国2007年各地区税收Y和国内生产总值GDP的统计资料。
根据X 与Y 之间的散点图(图1)可以看出他们的变化趋势是线性的, 由此建立各地区税收Y 与国内生产总值X 之间的一元线性回归模型i i i u X Y ++=10ββ三、回归结果以及检验假定模型中随机误差项 满足古典假定, 运用OLS 法估计模型参数, 结果如下:由此可知, 税收Y随GDP变化的一元线性回归方程为:Yˆ= -10.63+0.071X i(86.07) (0.007)t=(0.12)(9.59) R2=0.7603 F=91.99 D.W.=1.57 RSS=2760310四、斜率的经济意义是:2007年, 中国内地各省区GDP每增加1亿元时, 税收平均增加0.071亿元。
五、t检验和拟合优度检验因此, 从参数的t检验值看, 斜率项显然不为零, 但不拒绝截距项为零的假设。
另外, 拟合优度R2=0.7603 表明, 税收的76%的变化也以由GDP的变化来解释, 因此拟合情况较好。

8.2 一元线性回归模型及其应用(精讲)考点一 样本中心解小题【例1】(2021·江西赣州市)某产品在某零售摊位上的零售价x (元)与每天的销售量y (个)统计如下表:据上表可得回归直线方程为 6.4151y x =-+,则上表中的m 的值为( ) A .38B .39C .40D .41【答案】D 【解析】由题意1617181917.54x +++==,50343111544m my ++++==,所以115 6.417.51514m+=-⨯+,解得41m =.故选:D . 【一隅三反】1.(2021·江西景德镇市·景德镇一中)随机变量x 与y 的数据如表中所列,其中缺少了一个数值,已知y关于x 的线性回归方程为ˆ0.93yx =+,则缺少的数值为( )A .6B .6.6C .7.5D .8【答案】A【解析】设缺少的数值为m ,由于回归方程为ˆ0.93yx =+过样本中心点(),x y , 且2345645x ++++==,代入0.943 6.6y =⨯+=,所以5679 6.65my ++++==,解得6m =.故选:A.2.(2021·河南信阳市)根据如下样本数据:得到的回归方程为y bx a =+,则( ) A .0a >,0b > B .0a >,ˆ0b < C .0a <,0b > D .0a <,ˆ0b< 【答案】B【解析】由图表中的数据可得,变量y 随着x 的增大而减小,则ˆ0b<, 2345645x ++++==,4 2.50.5230.25y +---==,又回归方程y bx a =+经过点(4,0.2),可得0a >,故选:B .3.(2021·安徽六安市·六安一中)蟋蟀鸣叫可以说是大自然优美、和谐的音乐,殊不知蟋蟀鸣叫的频率x(每分钟鸣叫的次数)与气温y (单位:C )存在着较强的线性相关关系.某地观测人员根据下表的观测数据,建立了y 关于x 的线性回归方程0.25y x k =+.则当蟋蟀每分钟鸣叫62次时,该地当时的气温预报值为( ) A .33C B .34CC .35CD .35.5C【答案】D【解析】由表格中的数据可得2030405060405x ++++==,2527.52932.536305y ++++==,由于回归直线过样本中心点(),x y ,可得300.2540k =⨯+,解得20k =.所以,回归直线方程为0.2520y x =+.在回归直线方程中,令62x =,可得0.25622035.5y =⨯+=.故选:D.考点二一元线性方程【例2】(2021·兴义市第二高级中学)在2010年春节期间,某市物价部门,对本市五个商场销售的某商品一天的销售量及其价格进行调查,五个商场的售价x 元和销售量y 件之间的一组数据如下表所示: 通过分析,发现销售量y 对商品的价格x 具有线性相关关系,求 (1)销售量y 对商品的价格x 的回归直线方程; (2)若使销售量为12,则价格应定为多少.附:在回归直线ˆˆy bxa =+中1221ˆni ii nii x y nxyb xnx ==-=-∑∑,ˆˆay bx =- 【答案】(1) 3.240y x =-+ (2) 8.75 【解析】(1)由题意知10x =,8y =,∴999580635551083.28190.25100110.25121ˆ5100b++++-⨯⨯==-++++-⨯,8(3.2)1040a =--⨯=,∴线性回归方程是 3.240y x =-+;(2)令 3.24012y x =-+=,可得8.75x =,∴预测销售量为12件时的售价是8.75元.【一隅三反】1.(2020·河南开封市)配速是马拉松运动中常使用的一个概念,是速度的一种,是指每公里所需要的时间,相比配速,把心率控制在一个合理水平是安全理性跑马拉松的一个重要策略.图1是一个马拉松跑者的心率y (单位:次/分钟)和配速x (单位:分钟/公里)的散点图,图2是一次马拉松比赛(全程约42公里)前3000名跑者成绩(单位:分钟)的频率分布直方图.(1)由散点图看出,可用线性回归模型拟合y 与x 的关系,求y 与x 的线性回归方程;(2)该跑者如果参加本次比赛,将心率控制在160左右跑完全程,估计他跑完全程花费的时间,并估计他能获得的名次.参考公式:线性回归方程ˆˆˆybx a =+中,12()()ˆ()nii i nixx y y b xx =--=-∑∑,ˆˆay bx =- 参考数据:135y =.【答案】(1)25285x y ∧=-+;(2)210分钟,192名. 【解析】(1)由散点图中数据和参考数据得 4.55677.565x ++++==,1001091301651711355y ++++==,()()()51522222211.536(1)300(5)1(26) 1.5(35)25( 1.5)(1)01 1.5ˆiii i i x x y y bx x ==---⨯+-⨯+⨯-+⨯-+⨯-===--+-+++-∑∑,135(25)62ˆ85ˆay bx =-=--⨯=, 所以y 与x 的线性回归方程为25285x y ∧=-+. (2)将160y =代入回归方程得5x =,所以该跑者跑完马拉松全程所花的时间为425210⨯=分钟. 从马拉松比赛的频率分布直方图可知成绩好于210分钟的累积频率为()0.0008500.00242102000.064⨯+⨯-=,有6.4%的跑者成绩超过该跑者,则该跑者在本次比赛获得的名次大约是0.0643000192⨯=名.2.(2020·云南红河哈尼族彝族自治州)随着电商事业的快速发展,网络购物交易额也快速提升,特别是每年的“双十一”,天猫的交易额数目惊人.2020年天猫公司的工作人员为了迎接天猫“双十一”年度购物狂欢节,加班加点做了大量准备活动,截止2020年11月11日24时,2020年的天猫“双十一”交易额定格在3700多亿元,天猫总公司所有员工对于新的战绩皆大欢喜,同时又对2021年充满了憧憬,因此公司工作人员反思从2014年至2020年每年“双十一”总交易额(取近似值),进行分析统计如下表:(1)通过分析,发现可用线性回归模型拟合总交易额y 与年份代码t 的关系,请用相关系数加以说明; (2)利用最小二乘法建立y 关于t 的回归方程(系数精确到0.1),预测2021年天猫“双十一”的总交易额. 参考数据:71()()138.5ii i tt y y =--=∑26.7= 2.646≈;参考公式:相关系数()()niit t y y r --=∑;回归方程y bt a ∧∧∧=+中,斜率和截距的最小二乘估计公式分别为:()()()711722211niii ii i niii i tty y t y nx yb tttnx∧====---==--∑∑∑∑,=a y bt ∧∧-.【答案】(1)答案见解析;(2)回归方程为ˆ 4.9 1.2yt =-,预测2021年天猫“双十一”的总交易额约为38百亿.【解析】(1)4t =,721()28ii tt =-=∑,17()()138.5i ii t t yy =--=∑26.7=所以()()138.50.982 2.64626.7niit t y y r --=≈≈⨯⨯∑因为总交易额y 与年份代码t 的相关系数近似为0.98, 说明总交易额y 与年份代码t 的线性相关性很强,从而可用线性回归模型拟合总交易额y 与年份代码t 的关系. (2)因为18.4y =,721()28ii tt =-=∑,所以()()71271()138.5ˆ 4.928i ii i i t t yy bt t ==--==≈-∑∑, ˆˆay b =-,18.4 4.94 1.2b ≈-⨯=- 所以y 关于t 的回归方程为ˆ 4.9 1.2yt =- 又将2021年对应的8t =代入回归方程得:ˆ 4.98 1.238y=⨯-=. 所以预测2021年天猫“双十一”的总交易额约为38百亿.3.(2021·湖北省武昌实验中学高二期末)根据统计,某蔬菜基地西红柿亩产量的增加量y (百千克)与某种液体肥料每亩使用量x(千克)之间的对应数据的散点图,如图所示.(1)依据数据的散点图可以看出,可用线性回归模型拟合y与x的关系,请计算相关系数r并加以说明(若0.75r>,则线性相关程度很高,可用线性回归模型拟合);(2)求y关于x的回归方程,并预测当液体肥料每亩使用量为12千克时,西红柿亩产量的增加量约为多少?附:相关系数公式()()n ni i i ix x y y x y nx y r---==∑∑0.55≈0.95≈.回归方程y bx a=+中斜率和截距的最小二乘估计公式分别为()()()1122211n ni i i ii in ni ii ix x y y x y nx ybx x x nx====---==--∑∑∑∑,a y xb=-.【答案】(1)0.95;答案见解析;(2)0.3 2.5y x=+;610千克.【解析】(1)由已知数据可得2456855x++++==,3444545y++++==,所以()()()()()5131100010316i iix x y y=--=-⨯-+-⨯+⨯+⨯+⨯=∑,====所以相关系数()()50.95iix x y y r --===≈∑.因为0.75r >,所以可用线性回归模型拟合y 与x 的关系.(2)()()()5152160.320iii ii x x y y b x x ==--===-∑∑,450.3 2.5a =-⨯=, 所以回归方程为0.3 2.5y x =+. 当12x =时,0.312 2.5 6.1y =⨯+=,即当液体肥料每亩使用量为12千克时,西红柿亩产量的增加量约为610千克.考点三 非一元线性方程【例3】(2020·全国高二课时练习)在一次抽样调查中测得5个样本点,得到下表及散点图.(1)根据散点图判断y a bx =+与1y c k x -=+⋅哪一个适宜作为y 关于x 的回归方程;(给出判断即可,不必说明理由)(2)根据(1)的判断结果试建立y 与x 的回归方程;(计算结果保留整数) (3)在(2)的条件下,设=+z y x 且[)4,x ∈+∞,试求z 的最小值.参考公式:回归方程ˆˆˆybx a =+中,()()()1122211ˆn niii ii i nniii i x x y y x y nx yb x x xnx====---==--∑∑∑∑,a y bx =-.【答案】(1)1y c k x -=+⋅;(2)41y x=+;(3)6. 【解析】(1)由题中散点图可以判断,1y c k x -=+⋅适宜作为y 关于x 的回归方程; (2)令1t x -=,则y c kt =+,原数据变为由表可知y 与t 近似具有线性相关关系,计算得4210.50.251.555t ++++==,16125217.25y ++++==,222222416212150.520.2515 1.557.238.4544210.50.255 1.559.3k ⨯+⨯+⨯+⨯+⨯-⨯⨯==≈++++-⨯,所以,7.24 1.551c y kt =-=-⨯=,则41y t =+. 所以y 关于x 的回归方程是41y x=+. (3)由(2)得41z y x x x=+=++,[)4,x ∈+∞, 任取1x 、24x ≥,且12x x >,即124x x >≥,可得()()()21121212121212124444411x x z z x x x x x x x x x x x x -⎛⎫⎛⎫⎛⎫-=++-++=-+-=-+ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭()()1212124x x x x x x --=,因为124x x >≥,则120x x ->,1216>x x ,所以,12z z >,所以,函数41z x x =++在区间[)4,+∞上单调递增,则min 44164z =++=. 【一隅三反】1.(2020·江苏省如皋中学高二月考)某种新产品投放市场一段时间后,经过调研获得了时间x (天数)与销售单价y (元)的一组数据,且做了一定的数据处理(如表),并作出了散点图(如图).表中10111,10i i i i w w w x ===∑.(1)根据散点图判断y a bx =+,与dy c x=+哪一个更适合作价格y 关于时间x 的回归方程类型?(不必说明理由)(2)根据判断结果和表中数据,建立y 关于x 的回归方程. (3)若该产品的日销售量()g x (件)与时间x 的函数关系为()()100120g x x N x-=+∈,求该产品投放市场第几天的销售额最高?最高为多少元?附:对于一组数据()()()()112233,,,,,,...,,n n u v u v u v u v ,其回归直线vuαβ=+的斜率和截距的最小二乘法估计分别为121()(),()nii i nii vv u u v u u u βαβ==--==--∑∑.【答案】(1)dy c x =+更适合作价格y 关于时间x 的回归方程;(2)120(1)y x=+;(3)第10天,最高销售额为2420元;【解析】(1)根据散点图知dy c x=+更适合作价格y 关于时间x 的回归方程类型; (2)令1w x=,则y c dw =+, 而1011021()()18.4200.92()iii ii w w yy d w w ==--===-∑∑, 37.8200.8920c y dw =-=-⨯=,即有120(1)y x=+;(3)由题意结合(2)知:日销售额为1100()()20(1)(120)f x y g x x x=⋅=+-, ∴2110015()20(1)(120)400(6)f x x x x x=+-=+-, 若1t x =,令221121()655()1020h t t t t =+-=--+, ∴110t =时,max 1121()()1020h t h ==,即10x =天,max 121()(10)400242020f x f ==⨯=元, 所以该产品投放市场第10天的销售额最高,最高销售额为2420元.2.(2021·江苏苏州市)我国为全面建设社会主义现代化国家,制定了从2021年到2025年的“十四五”规划.某企业为响应国家号召,汇聚科研力量,加强科技创新,准备增加研发资金.现该企业为了了解年研发资金投入额x (单位:亿元)对年盈利额y (单位:亿元)的影响,研究了“十二五”和“十三五”规划发展期间近10年年研发资金投入额i x 和年盈利额i y 的数据.通过对比分析,建立了两个函数模型:①2y x αβ=+,②x t y e λ+=,其中α,β,λ,t 均为常数,e 为自然对数的底数.令2i i u x >,()ln 1,2,,10i i v y i ==⋅⋅⋅,经计算得如下数据:(1)请从相关系数的角度,分析哪一个模型拟合程度更好?(2)(ⅰ)根据(1)的选择及表中数据,建立y 关于x 的回归方程;(系数精确到0.01)(ⅱ)若希望2021年盈利额y 为250亿元,请预测2021年的研发资金投入额x 为多少亿元?(结果精确到0.01)附:①相关系数()()niix x y y r --=∑,回归直线ˆˆˆya bx =+中:121()()ˆ()niii nii x x yy b x x ==--=-∑∑,ˆˆay bx =- ②参考数据:ln 20.693≈,ln5 1.609≈. 【答案】(1)模型x ty eλ+=的拟合程度更好;(2)(ⅰ)0.180.56ˆx ye +=;(ⅱ)27.56.【解析】(1)设{}i u 和{}i y 的相关系数为1r ,{}i x 和{}i v 的相关系数为2r ,由题意,()()101130.8715iiu u y y r --===≈∑,()()102120.9213iix x v v r --===≈∑,则12r r <,因此从相关系数的角度,模型x ty e λ+=的拟合程度更好.(2)(ⅰ)先建立v 关于x 的线性回归方程, 由x ty eλ+=,得ln y t x λ=+,即v t x λ=+,()()()101102112ˆ65iii ii x x v v x x λ==--==-∑∑, 12ˆˆ 5.36260.5665tv x λ=-=-⨯=, 所以v 关于x 的线性回归方程为ˆ0.180.56vx =+, 所以ˆln 0.180.56yx =+,则0.180.56ˆx y e +=.(ⅱ)2021年盈利额250y =(亿元), 所以0.180.56250x e +=,则0.180.56ln 250x +=, 因为ln 2503ln5ln 23 1.6090.693 5.52=+≈⨯+=, 所以 5.520.5627.560.18x -≈≈.所以2021年的研发资金投入量约为27.56亿元.。
⼀元线性回归模型案例第⼆章⼀元线性回归模型案例⼀、中国居民⼈均消费模型从总体上考察中国居民收⼊与消费⽀出的关系。
表2.1给出了1990年不变价格测算的中国⼈均国内⽣产总值(GDPP)与以居民消费价格指数(1990年为100)所见的⼈均居民消费⽀出(CONSP)两组数据。
1) 建⽴模型,并分析结果。
输出结果为:对应的模型表达式为:201.1070.3862CONSP GDPP =+(13.51) (53.47) 20.9927,2859.23,0.55R F DW ===从回归估计的结果可以看出,拟合度较好,截距项和斜率项系数均通过了t 检验。
中国⼈均消费增加10000元,GDP 增加3862元。
⼆、线性回归模型估计表2.2给出⿊龙江省伊春林区1999年16个林业局的年⽊材采伐量和相应伐⽊剩余物数据。
利⽤该数据(1)画散点图;(2)进⾏OLS 回归;(3)预测。
表2.2 年剩余物y 和年⽊材采伐量x 数据(1)画散点图先输⼊横轴变量名,再输⼊纵轴变量名得散点图(2)OLS估计弹出⽅程设定对话框得到输出结果如图:由输出结果可以看出,对应的回归表达式为:0.76290.4043t t yx =-+ (-0.625) (12.11)20.9129,146.7166, 1.48R F DW === (3)x=20条件下模型的样本外预测⽅法⾸先修改⼯作⽂件范围将⼯作⽂件范围从1—16改为1—17确定后将⼯作⽂件的范围改为包括17个观测值,然后修改样本范围将样本范围从1—16改为1—17打开x的数据⽂件,利⽤Edit+/-给x的第17个观测值赋值为20将Forecast sample选择区把预测范围从1—17改为17—17,即只预测x=20时的y的值。
由上图可以知道,当x=20时,y的预测值是7.32,yf的分布标准差是2.145。
三、表2.3列出了中国1978—2000年的参政收⼊Y和国内⽣产总值GDP的统计资料。
一元线性回归模型:案例分析下面用一个实例对本章内容作一简单回顾。
我们将收集中国财政收入和国内生产总值在1978~2006年间的历史数据,然后建立两者的一元线性回归模型,并用最小二乘法对其中的参数进行估计,最后对模型进行一些必要的检验。
一、中国财政收入和国内生产总值的历史数据由经济学等相关学科的理论我们知道,国内生产总值是财政收入的来源,因此财政收入在很大程度上由国内生产总值来决定。
为了考察中国财政收入和国内生产总值之间的关系,我们收集了中国财政收入和国内生产总值在1978~2005年间的历史数据,如表 2.4.1所示。
表2.4.1中国财政收入和国内生产总值数据表单位:亿元年份财政收入(Y) 国内生产总值(X) 年份财政收入(Y) 国内生产总值(X)1978 1132 3624 1992 3483 266521979 1146 4038 1993 4349 345611980 1160 4518 1994 5218 466701981 1176 4860 1995 6242 607941982 1212 5302 1996 7408 711771983 1367 5957 1997 8651 789731984 1643 7207 1998 9876 844021985 2005 8989 1999 11444 896771986 2122 10201 2000 13395 992151987 2199 11955 2001 16386 1096551988 2357 14922 2002 18904 1203331989 2665 16918 2003 21715 1358231990 2937 18598 2004 26396 1598781991 3149 21663 2005 31628 183868我们以X为横轴,Y为纵轴将这些数据的描绘在二维坐标图上,得到如下的散点图(图2.4.1 )。
一元线性回归模型案例一元线性回归是统计学中常用的一种回归分析方法,用于研究一个自变量和一个因变量之间的线性关系。
在本文中,我们将通过一个实际案例来介绍一元线性回归模型的应用和分析过程。
案例背景:假设我们是某家电商平台的数据分析师,我们希望通过用户的年龄来预测其在平台上的消费金额。
我们收集了100位用户的年龄和其在平台上的消费金额的数据,现在我们希望利用一元线性回归模型来分析这些数据,以便更好地了解用户消费行为。
数据分析:首先,我们需要对收集到的数据进行初步的分析。
我们可以使用散点图来观察年龄和消费金额之间的关系。
通过观察散点图,我们可以初步判断年龄和消费金额之间是否存在线性关系,以及线性关系的方向和强度。
模型建立:在确认了年龄和消费金额之间存在线性关系后,我们可以建立一元线性回归模型。
模型的基本形式为,Y = β0 + β1X + ε,其中Y表示因变量(消费金额),X表示自变量(年龄),β0和β1分别表示截距和斜率,ε表示误差项。
我们需要通过最小二乘法来估计β0和β1的值,从而建立回归方程。
模型评价:建立回归模型后,我们需要对模型进行评价。
我们可以通过计算回归方程的拟合优度R^2来评价模型的拟合程度,R^2的取值范围为0到1,值越接近1表示模型拟合得越好。
此外,我们还可以利用残差分析来检验模型的假设是否成立,以及检验模型的稳健性和可靠性。
预测分析:最后,我们可以利用建立的回归模型进行预测分析。
通过输入不同年龄的值,我们可以利用回归方程来预测用户在平台上的消费金额。
预测分析可以帮助电商平台更好地了解不同年龄段用户的消费特点,从而制定针对性的营销策略和服务方案。
结论:通过以上一元线性回归模型的应用分析,我们可以得出结论,用户的年龄和在平台上的消费金额之间存在一定的线性关系,通过建立回归模型,我们可以对用户的消费金额进行预测和分析。
这对于电商平台来说具有重要的参考价值,可以帮助平台更好地了解用户消费行为,从而提升用户体验和增加销售额。
一元线性回归模型案例分析一、研究的目的要求居民消费在社会经济的持续发展中有着重要的作用。
居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
改革开放以来随着中国经济的快速发展,人民生活水平不断提高,居民的消费水平也不断增长。
但是在看到这个整体趋势的同时,还应看到全国各地区经济发展速度不同,居民消费水平也有明显差异。
例如,2002年全国城市居民家庭平均每人每年消费支出为6029.88元, 最低的黑龙江省仅为人均4462.08元,最高的上海市达人均10464元,上海是黑龙江的2.35倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,居民的收入水平、就业状况、零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定我们研究的对象是各地区居民消费的差异。
居民消费可分为城市居民消费和农村居民消费,由于各地区的城市与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城市居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y 选定为“城市居民每人每年的平均消费支出”。
因为研究的目的是各地区城市居民消费的差异,并不是城市居民消费在不同时间的变动,所以应选择同一时期各地区城市居民的消费支出来建立模型。
因此建立的是2002年截面数据模型。
影响各地区城市居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
案例分析报告
(2014——2015学年第一学期)
课程名称:预测与决策
专业班级:电子商务1202
学号: 2204120202
学生姓名:陈维维
2014 年 11月
案例分析(一元线性回归模型)
我国城镇居民家庭人均消费支出预测
一、研究目的与要求
居民消费在社会经济的持续发展中有着重要的作用,居民合理的消费模式和居民适度的消费规模有利于经济持续健康的增长,而且这也是人民生活水平的具体体现。
从理论角度讲,消费需求的具体内容主要体现在消费结构上,要增加居民消费,就要从研究居民消费结构入手,只有了解居民消费结构变化的趋势和规律,掌握消费需求的热点和发展方向,才能为消费者提供良好的政策环境,引导消费者合理扩大消费,才能促进产业结构调整与消费结构优化升级相协调,才能推动国民经济平稳、健康发展。
例如,2008年全国城镇居民家庭平均每人每年消费支出为11242.85元,?最低的青海省仅为人均8192.56元,最高的上海市达人均19397.89元,上海是黑龙江的2.37倍。
为了研究全国居民消费水平及其变动的原因,需要作具体的分析。
影响各地区居民消费支出有明显差异的因素可能很多,例如,零售物价指数、利率、居民财产、购物环境等等都可能对居民消费有影响。
为了分析什么是影响各地区居民消费支出有明显差异的最主要因素,并分析影响因素与消费水平的数量关系,可以建立相应的计量经济模型去研究。
二、模型设定?
我研究的对象是各地区居民消费的差异。
居民消费可分为城镇居民消费和农村居民消费,由于各地区的城镇与农村人口比例及经济结构有较大差异,最具有直接对比可比性的是城市居民消费。
而且,由于各地区人口和经济总量不同,只能用“城镇居民每人每年的平均消费支出”来比较,而这正是可从统计年鉴中获得数据的变量。
所以模型的被解释变量Y选定为“城镇居民每人每年的平均消费支出”。
因为研究的目的是各地区城镇居民消费的差异,并不是城镇居民消费在不同时间的变动,所以应选择同一时期各地区城镇居民的消费支出来建立模型。
因此建立的是2008年截面数据模型。
影响各地区城镇居民人均消费支出有明显差异的因素有多种,但从理论和经验分析,最主要的影响因素应是居民收入,其他因素虽然对居民消费也有影响,但有的不易取得数据,如“居民财产”和“购物环境”;有的与居民收入可能高度相关,如“就业状况”、“居民财产”;还有的因素在运用截面数据时在地区间的差异并不大,如“零售物价指数”、“利率”。
因此这些其他因素可以不列入模型,即便它们对居民消费有某些影响也可归入随即扰动项中。
为了与“城镇居民人均消费支出”相对应,选择在统计年鉴中可以获得的“城市居民每人每年可支配收入”作为解释变量X。
以下是2008年各地区城镇居民人均年消费支出和可支配收入表
数据来源:
作城镇居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)的散点图,如图
从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立的计量经济模型为如下线性模型: Yi=a+bXi+εi??i=1,2,···n
一元线性回归预测法,是指两个具有线性关系的变量,配合线性回归模型,根据自
变量的变动来预测因变量平均发展趋势的方法。
三、OLS 估计
采用OLS 法估计其模型的回归系数
最小平方法的中心思想,是通过数学模型,配合一条较为理想的趋势线。
这条趋势线必须满足以下两点要求:
(1)原数列的观察值与模型的估计值的离差平方和为最小; (2)原数列的观察值与模型的估计值的离差总和为零。
1、首先进入Excel 程序,建立工作薄,接下来进行一元线性回归的输入形式。
2、计算2x 、2y 及xy ,分别在“D2、E2、F2”单元格通过相对引用输入计算公式并向下复制。
3、计算∑x 、∑y 、∑2x 、∑2y 及∑xy 。
4、一元线性回归系数的计算:
所以b=0.6647
a=725.3459
5、按bX a Y
+=ˆ计算估计值: 四、相关系数
相关系数是一元线性回归中用来衡量两个变量之间相关程度的重要指标。
主要有两种定义方法:根据总变差定义以及根据积差法定义,由于根据积差法定义的相关系数不需要先求回归模型的剩余变差,可以直接从样本数据中计算得到,所以在本案例中比较适合使用。
其定义为
相关系数2
2
2
2
y y n x x n y
x xy n r )
()
(∑∑∑∑∑∑∑---=
;
五、模型检验
1、经济意义检验
所估计的参数0.6194,说明城镇居民人均年可支配收入每相差1元,可导致居民消费支出相差0.6194元,这与经济学中边际消费倾向的意义相符。
2、显着性检验
本案例中可决系数为0.945802(可决系数R 2
的大小表明了在y 的总变差中自由量x 变动所引起的百分比,它是评价两个变量之间线性相关关系强弱的一个重要指标。
),说明所建模型整体上对样本数据拟合较好,即解释变量“城镇居民人均年可支配收入”对被解释变量“城镇居民人均年消费支出”的绝大部分差异作出了解释。
对回归系数的t 检验:当显着性水平取α=0.05,自由度为n-2=31-2=29
查相关系数临界值表,得R 0.05(29)=0.355。
因为R=0.97252>R 0.05(29)=0.355。
故在α=0.05显着性水平之上,检验通过,说明两个变量之间相关关系显着,也就是表明,城镇人均年可支配收入对人均年消费支出有显着影响。
六、回归预测
1、计算估计标准误差。
查表确定)(2/2n t -α。
在Excel 中输入=POWER((E34-K8*C34-K6*F34)/(G33-2),0.5) 即可得到
s
y
=645.7119
由图表中可以看出来,黑龙江省、贵州省、甘肃省、青海省、新疆省等地可支配收入以及消费支出都排名靠后。
还有其他部分省虽然可支配收入高于其他省,但是消费支出却少于其他,例如,山西省,江西省,河南省等(我选择的可支配收入的临界值是12000,消费水平的临界值是9000)。
其中大部分都是西部地区。
在西部大开发的推动下,如果西部地区的城市居民人均年可支配收入第一步争取达到2000美元(按现有汇率即人命币12245元),第二步再争取达到2500美元(即人民币15306.25元),利用所估计的模型可预测这时城市居民可能达到的人均年消费支出水平。
可以注意到,这里的预测是利用所示数据模型对被解释变量在不同空间状况的空间预测。
接下来进行预测:首先
所谓预测区间就是指在一定的显着性水平上,依据数理统计方法计算出的包含预测目标未来真实值的某一区间范围。
根据公式可以求得:
当显着性水平取α=0.05,自由度n-m=31-2=29时,查t 分布表得:
t0.025(29)=2.05
第一步达到12245元的时候,预测区间为:
输入公式=H35-K29*K33,=H35+K29*K33,得:
预测区间为(7510.3966,10219.9319)
第二步达到15306.25元的时候,预测区间为:
输入公式=H36-K29*K33,=H36+K29*K33,得:
预测区间为(9545.3512,12254.8865)
七、总结
消费需求主要来源于居民的可支配收入,而居民的可支配收入又来自于居民的人均收入即狭义上的居民的固定工资,它是形成当期购买力最主要的来源,同样也是影响消费需求的最直接最重要的因素。
此次案例分析我以2008年全国各地可支配收入和消费支出数据资料为基础,假设人均年可支配收入为自变量X(单位:元),人均年消费支出为因变量y(单位:元),并做出可支配收入和消费支出的相关关系图。
从这两个变量的相关关系图可观测到两者之间的大体趋势,发现它们基本上呈现出一种直线的统计关系,所以我进一步进行回归分析,并进行线性相关系数R的显着性检验。
若|R|=1表示完全线性相关;0<|R|<1表示存在不同程度线性相关;|R|<0.3为低度线性相关,0.3<|R|<0.7为中度线性相关,|R|>0.7为高度线性相关。
|R|越接近于I,说明两个变量的相关程度越密切。
通过公式,利用Excel数字处理功能,进行数据处理和简单的线性相关分析,我得出2008年全国城镇居民可支配收入和消费需求的回归方程式:y=0.6647x+725.3459。
相关系数为:R=0.9725 ,R2=0.9458,说明2008年全国城镇居民可支配收入和消费支出之间存在着显着的相关关系。
居民可支配收入每增加1000元,消费支出将增加大约72.5元。
可以这么说,居民可支配收入与消费需求状况紧密相关,可支配收入会对消费需求产生重要影响,即可支配收入的扩大或缩小会导致消费需求的相应的变化。
最后通过线性相关性的检验,证实前面得出的结论:居民的可支配收入对消费需求的影响十分显着。
居民可支配收入的稳定提高,使居民的消费需求有了最坚实的基础,进而提高居民的消费需求和消费支出,拥有一个稳定舒心的生活,高水平的居民可支配收入,是影响消费需求的决定性的因素。