Loop+Subdivision-递归分割方法的科技文献,从表面三角网格开始进行细分,得到光滑曲面的经典算法
- 格式:pdf
- 大小:14.55 MB
- 文档页数:74



计算机科学200lVM 28N u7乔莱斯基分解递归算法的研究Stud y of Re c ur si ve A lg or it h m for C bol esk y FactortzattonTb A陈建平J。
:y w。
i。
ki(南通工学院江苏ggNza6007)(丹麦研究与教育计算中心)Ab s tr a ct R ec u rs t on new ef fe c uv e m et h od for co mpu li ng d en se linear a lg e br a h a ll o w s for dfictentutilization of m emo ry Me rar chie s of today’s M g h perf orman ce comp uter s The algorithm forCh ol es ky fact oriza tlon is s tu di ed this p a p e r A d e t a de d d er i v a ti o n of t h e Cho le sk y algo z't th mT he alg on tb m lben m lpl em ent ed in F O R T R A N90thai s u p p o r t s lan gu a ge lea g【v e nT b e efficiency of t he alg a r it h m fur t he r im p r ov e d bv m e t h o d of eleme ntT he r e su l t i ng a l g or i t h ms15“一25蟛faster th a n t h e c u rr e n t ly u s ed b lo c k 。
rderx n gal g or i th mKeywo rds Nu mer ical comput ati on,Rec urs lon.M at b lo ck i ng,Me mo ry hierar chy,FOR’rR AN90构简单.易于实现。

三角网格顶点重要度的自适应Loop细分算法王艳艳;惠丽峰;罗晓锋;张荣国【摘要】A new adaptive subdivision scheme based on vertex’s importance is presented. The vertex’s average plane is replaced by the plane that is formed by three endpoints of three longer edges connectedto the vertex in the triangle mesh, and then the distance between the vertex and its average plane is regarded as the criterion for the vertex’s importance so that it can be decided whether the vertex needs to be subdivided. Since the original triangular faces are of high density and shape similarity, the error derived from the vertex-to-plane distance as subdivision measure can be limited to a volume element. Compared with the algorithm of amending the vertex’s normal vector repeatedly, this method decreases the amount of computation greatly. Experimentally, the approach proposed can both accelerate the processing speed effectively and reduce the amount of faces greatly.%提出了一种新的自适应细分算法,在顶点的1-邻域内,用与顶点相连较长三条边的端点构成的平面去替代其平均平面,将顶点到其平均平面的距离作为判断顶点重要度的标准,对三角网格进行自适应细分。

基于二面角逆插值Loop细分的渐进传输方法史卓;孔谦;玉珂;蓝如师;罗笑南【摘要】随着虚拟现实、增强现实等领域快速发展,渐进传输获得了良好的用户体验.为了三角网格在移动终端的快速传输和显示,提出了一种基于二面角逆插值Loop细分(DRILS)的渐进传输算法.主要通过对原始三角网格进行基于二面角插值Loop细分(DILS)和插值Loop细分(ILS)进行预处理,在局部特征精确保持的同时获得具备细分连通性的精网格.在渐进传输的过程中通过对该精网格迭代操作3个步骤,即奇偶顶点划分、预测偏移量、更新三角网格.由于采用DILS与ILS结合获取精网格,在渐进传输的过程中保持了精确的局部特征,同时也加快了渐进传输的速度.实验对比表明,该算法精确、高效,适应于移动终端设备的显示传输及存储.【期刊名称】《图学学报》【年(卷),期】2019(040)001【总页数】7页(P92-98)【关键词】渐进传输;逆细分;插值Loop细分;二面角【作者】史卓;孔谦;玉珂;蓝如师;罗笑南【作者单位】桂林电子科技大学艺术与设计学院,广西桂林541004;桂林电子科技大学艺术与设计学院,广西桂林541004;桂林电子科技大学艺术与设计学院,广西桂林541004;桂林电子科技大学艺术与设计学院,广西桂林541004;桂林电子科技大学艺术与设计学院,广西桂林541004【正文语种】中文【中图分类】TP391渐进传输在视频动画、游戏、三维建模等领域具有广泛地应用价值。
渐进网格在渐进传输中是具体内容表现形式,HOPPE[1]首次提出的采用基于顶点分裂生成渐进网格,为三维网格在多分辨率渐进传输过程中受限于存储空间及传输带宽的影响提供了解决方案。
通常情况下,科研人员采用基于QEM (quadric error metrics)[2]算法在边折叠、点分裂等改进方法进行三角网格简化和生成多层次的三角网格模型。
随着三角网格细分方法的深入研究,逆细分[3]的提出使得细分在渐进网格生成得到了发展。

CosmosWorks网格划分、求解器、提示与技巧一、网格划分策略网格划分,更精确地说应该称为离散化,就是将一数学模型转化为有限元模型以准备求解。
作为一种有限元方法,网格划分完成两项任务。
第一,它用一离散的模型替代连续模型。
因此,网格划分将问题简化为一系列有限多个未知域,而这些未知域符合由近似数值技术的求解结果。
第二,它用一组单元各自定义的简单多项式函数来描述我们渴望得到的解(e.g 位移或温度)。
对于使用者来说,网格划分是求解问题必不可少的一步。
许多FEA 初学者急切盼望格划分为全自动过程而几乎不需要自己输入什么。
随着经验的增加,就会意识到这样一个现实:网格划分常常是要求非常苛刻的任务。
商用FEA 软件的发展历史见证了网格划分对FEA 用户透明的诸多尝试,然它并不是一条成功的途径。
而当网格划分过程既简单又自动执行时,它也仍旧不是一个“非手工干涉”而仅靠后台运行的任务。
作为FEA 用户,我们想要有一种可以和网格划分过程交互的方法。
COSMOSWorks 通过将用户从那些纯粹网格细节意义上的问题中解脱出来,找到了良好的平衡点;并使我们在需要时可以控制网格划分。
几何体准备理想情况下,我们用SolidWorks 的几何体,联入COSMOSWorks环境。
在这里,我们定义分析和材料的类型,施加载荷与约束,然后为几何体划分网格并得到求解。
这种方法在简单模型下能起作用。
对于更为复杂的几何体,则要求在网格划分前作些准备。
在FEA 的几何体准备过程中,我们从特定制造,CAD 几何体出发,为分析而特地构造几何体。
我们称这个几何体为FEA 几何体。
基于两者的不同要求,我们对CAD 几何体和FEA 几何体作一区别:CAD 几何体FEA 几何体必须包含机械制造所需的所有信息必须可划分网格必须允许创建能正确模拟所关心资料的网格必须允许创建能在合理时间内可求解的网格通常,CAD 几何体不能满足FEA 几何体的要求。
CAD 几何体作为有限元模型准备过程的起始点,但很少不作任何修改就用于FEA 中。
Microcomputer Applica tions Vol. 27, No. 1, 2011文章编号:1007-757X(2011)01-0050-04技术交流微型电脑应用2011 年第 27 卷第 1 期一种基于三角网格结构的医学虚拟切割算法刘青,姚莉秀摘 要: 针对由三角面片构成的医学表面网格数据, 提出了一种简单可靠的网格切割算法。
在移动切割工具的过程中采用 OBB 包围盒树进行碰撞检测。
为了简化切割过程中 OBB 树的更新仅在首次发生碰撞时对由 OBB 计算得到的碰撞面计算碰撞点, 在后续过程中通过切割工具的移动方向和网格的 AIF 数据结构计算碰撞面和碰撞点。
网格切割算法采用顶点移动的方法, 该法可以避免畸形三角面片的产生。
实验结果表明,提出的算法能够很好的仿真医学导航系统中的切割过程。
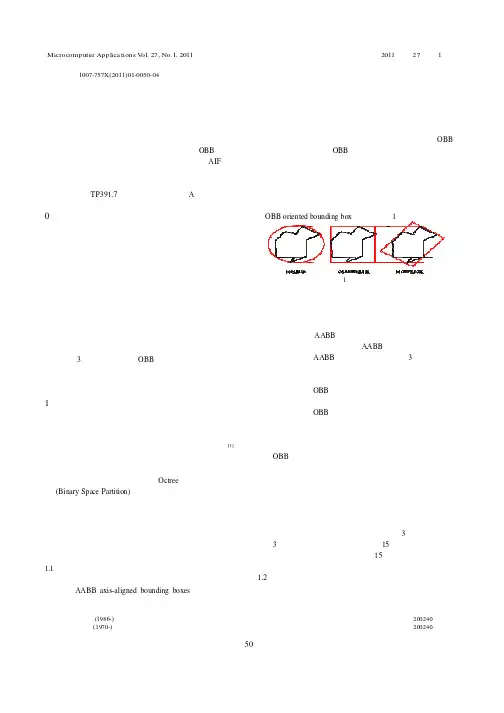
关键词:碰撞检测;虚拟切割;顶点移动;网格分离 中图分类号:TP391.7 文献标志码:A0引言(OBB oriented bounding box)等,如图 1 所示。
随着计算机图形学的发展, 其在虚拟医学导航技术中的 应用成为仿真系统研发中的热点。
由于外科手术大多需要切 割操作, 三维模型的虚拟切割交互算法也得到了人们的广泛 关注。
被切割物体的建模方法主要有面模型和体模型。
面模型图1 包围盒示意图仅包含器官的表面形状信息, 计算数据量小, 但不能表示器 官内部结构。
体模型能够表达物体内部特征, 数据量特别大, 很难在实时性要求比较高的场合应用。
本文中切割系统对计 算精度要求不高, 对实时性要求较高, 所以采用面模型建模。
在表面网格模型中, 虚拟切割算法的仿真主要包括物体 与切割工具的碰撞检测, 物体网格的切割算法和切割后网格 间的分离 3 部分。
文中采用 OBB 包围盒方法进行碰撞检测 计算, 切割部分采用基于顶点移动的算法实现, 并对切割后 的封闭区间采用广度遍历算法进行网格分离。


一种Loop细分小波的边界处理方法赵罡;季宝朋;白杰【摘要】细分小波近年来发展迅速,在计算机图形显示、渐进网格传输和网格多分辨率编辑等领域获得了广泛的应用.Bertram提出的Loop细分小波是基于提升格式的双正交细分小波的典型范例,它所针对的对象均为网格的内部顶点.目前尚未发现相关文献提及细分小波对于边界的处理.该文在Loop细分小波算法的基础上,给出了一种Loop细分小波边界处理的方法,经验证效果令人满意.【期刊名称】《图学学报》【年(卷),期】2010(031)006【总页数】5页(P34-38)【关键词】计算机应用;Loop细分曲面;细分小波;曲面边界处理【作者】赵罡;季宝朋;白杰【作者单位】北京航空航天大学机械工程及自动化学院,北京,100191;北京航空航天大学机械工程及自动化学院,北京,100191;北京航空航天大学机械工程及自动化学院,北京,100191【正文语种】中文【中图分类】TP391Loop细分模式是一种基于三角网格模型的细分方法[1]。
随后,Hoppe等人对Loop细分方法进一步拓展,拓展的Loop算法具有任意性、整体连续性、算法稳定性和可伸缩性等,因此受到越来越多的关注。
近年来,小波技术在曲面造型中的应用也越来越广泛,对小波的多分辨率和“数学显微镜”等特性的应用,能够实现物体的快速造型和灵活修改[2-4]。
随着对Loop 细分曲面的研究进一步加深,Bertram于2000年给出了基于提升格式构造双正交Loop细分小波的算法[5],这在很大程度上提升了Loop细分曲面的形状可调节性。
但是,到目前为止,笔者所看到的关于Loop细分小波的文献都只提到了对于网格内部顶点的小波分解和小波重构方法[5-6],尚未见到针对非闭合曲面边界的小波分解和重构方法,而在工程应用中,非闭合曲面大量存在。
针对有边界的非闭合网格,也有文章做了简单的处理,没有考虑内部点对边界的影响[7]。
但对于类似面具(如图 1)这种非闭合网格,若仍然对其进行简单的边界处理而不考虑内部点对边界的影响,会造成小波分解结果的不合理性,所以对于边界如何进行有效的Loop细分小波处理显得尤为重要。

第38卷第6期 计算机应用与软件Vol 38No.62021年6月 ComputerApplicationsandSoftwareJun.2021适用于电磁场有限元计算的网格剖分算法章春锋 汪 伟 吴天纬 安斯光(中国计量大学机电工程学院 浙江杭州310016)收稿日期:2019-10-18。
浙江省自然科学基金项目(LY19E070003);国家自然科学基金项目(61701467)。
章春锋,硕士生,主研领域:电磁场有限元剖分与数值计算。
汪伟,教授。
吴天纬,硕士生。
安斯光,副教授。
摘 要 网格剖分是有限元法的关键,其剖分得到的网格质量决定了有限元法计算结果的准确性。
提出基于Persson Strang算法生成非结构化三角形网格的新算法。
通过分析Laplacian平滑函数作用原理,提出新的平滑函数来减少迭代次数;提出一种在优化设计过程中无重构变形方法,通过定义边界网格框架利用坐标映射技术可以快速推导出网格;通过设置质量评估来解决不可终止性的可能和过度迭代,加入边界节点筛选功能,并对剖分得到的三角元进行有限元逆序编号处理。
将该算法与Persson Strang算法进行剖分效果对比,验证该算法应用于电磁场领域的有效性。
关键词 网格剖分 平滑函数 坐标映射 有限元 电磁场中图分类号 TP3 文献标志码 A DOI:10.3969/j.issn.1000 386x.2021.06.035MESHGENERATIONALGORITHMFORFINITEELEMENTCALCULATIONOFELECTROMAGNETICFIELDZhangChunfeng WangWei WuTianwei AnSiguang(CollegeofMechanicalandElectricalEngineering,ChinaJiliangUniversity,Hangzhou310016,Zhejiang,China)Abstract Meshgenerationisthekeyofthefiniteelementmethod.Thequalityofthemeshgeneratedbythemeshgenerationdeterminestheaccuracyoftheresultsofthefiniteelementmethod.AnewunstructuredtrianglemeshgenerationalgorithmbasedonPersson Strangalgorithmisproposed.ByanalyzingtheprincipleofLaplaciansmoothingfunction,anewsmoothingfunctionwasproposedtoreducethenumberofiterations;anonreconstructiondeformationmethodwasproposedintheprocessofoptimizationdesign,whichcanquicklydeducethegridbydefiningtheboundarygridframeworkandusingthecoordinatemappingtechnology;thepossibilityofnonterminationandoveriterationcanbesolvedbysettingthequalityevaluation,andnodefilteringfunctionwasaddedtotheboundary,andthetrigonometricelementsobtainedbysubdivisionwerenumberedinreverseorderbyfiniteelementmethod.ComparedwiththePersson Strangalgorithm,thisalgorithmisprovedtobemoreeffectiveinelectromagneticfield.Keywords Meshgeneration Smoothingfunction Coordinatemapping Finiteelement Electromagneticfield0 引 言优异的适应场域边界几何形状以及媒介物理性质变异的能力,使有限元法成为各类电磁场、电磁波工程问题定量分析和优化设计的主导数值计算方法之一[1]。

1根据不同标准的细分方法分类1.1第一类。
根据组成原始网格的图元不同,可以将细分方法分为三角形网格细分方法、四边形网格细分方法;Loop 细分方法、蝶形细分方法都是基于三角形的,而Catmull-Clark 细分方法是基于四边形的。
1.2第二类。
根据网格拓扑分裂的方式,可以将细分方法分为基本细分方法和对偶细分方法。
基本细分方法是采用面分裂,如Loop 细分方法、Butterfly 细分方法、Kobbelt 细分方法、Catmull-Clark 细分方法等;对偶细分方法是采用顶点分裂,如Mid-edge 细分方法和Doo-Sabin 细分方法等。
1.3第三类。
根据细分后得到的极限曲面的连续性,可以分为C 1,C 2。
1.4第四类。
根据极限曲线曲面是否过初始控制顶点,可以将细分方法分为逼近细分法、差值细分法。
2剖析Charles Loop 细分算法及在系统中的应用不同的标准产生了不同的细分方法,而各种细分算法都有各自的优缺点,只有根据实际的应用去选择适合的算法,Loop 细分算法实现简单,主要对该算法进行彻底是剖析来研究曲面造型技术。
2.1Charles Loop 细分算法产生的过程Loop 细分算法是一种基于三角形控制网格的经典细分算法,并于1987年由美国犹他大学的Charles Loop 在他的硕士论文中提出过。
Loop 细分算法是箱样条二分算法的推广算法,基于三向箱样条。
对于任意三角形网格来说,Loop 细分算法的极限曲面在非奇异点处为C 2连续、奇异点处为C 1连续,也可以解释为Loop 细分算法属于逼近型面分裂模式,它的细分规则其实是比较简单,也可以说Loop 细分算法是目前应用最广泛的曲面细分算法之一。
目前我国对于Loop 细分算法以及其扩展有非常多的研究,与Loop 细分算法的相关文献也很丰富。
例如Schweitzer 和Hoppe 对Loop 细分算法进行扩展,使细分曲面的内部可以创建尖锐特征;Biermann 对Loop 细分算法进行扩展,使可以控制细分曲面的某一点;Levin 也对Loop 细分算法进行扩展,并且使细分曲面能够满足一定的边界条件。