频繁子图在监控系统数据挖掘中的应用_史伟奇
- 格式:pdf
- 大小:188.24 KB
- 文档页数:3
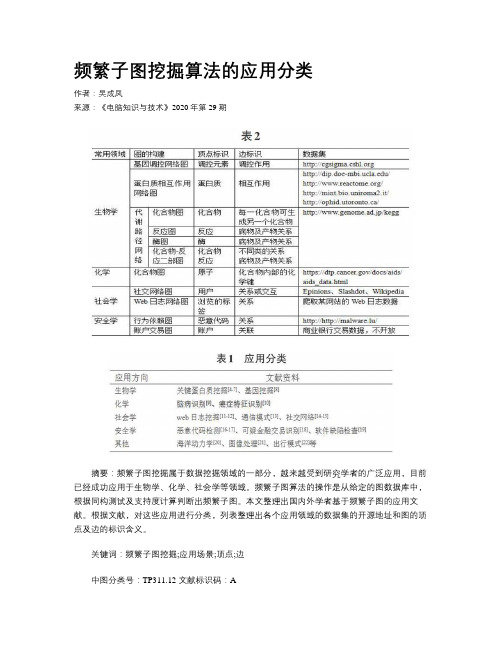
频繁子图挖掘算法的应用分类作者:吴成凤来源:《电脑知识与技术》2020年第29期摘要:频繁子图挖掘属于数据挖掘领域的一部分,越来越受到研究学者的广泛应用,目前已经成功应用于生物学、化学、社会学等领域。
频繁子图算法的操作是从给定的图数据库中,根据同构测试及支持度计算判断出频繁子图。
本文整理出国内外学者基于频繁子图的应用文献。
根据文献,对这些应用进行分类,列表整理出各个应用领域的数据集的开源地址和图的顶点及边的标识含义。
关键词:频繁子图挖掘;应用场景;顶点;边中图分类号:TP311.12 文献标识码:A文章编号:1009-3044(2020)29-0040-021 引言在数据挖掘的领域中,频繁子图挖掘算法越来越受到国内外研究学者的关注。
频繁子图将各种数据处理成顶点到顶点的逻辑关系的表示,在该模型[1]中,顶点和对应的边关系可以具有与它们相关联的标签,这些标签不是唯一的。
使用这样的图表示,频繁模式的问题变成了在整个图上寻求频繁出现子图的问题,运用频繁子图算法挖掘其潜在的价值。
频繁子图挖掘算法即在给定的图中根据设定的支持度阈值,寻找出同构子图大于等于给定支持度阈值的子图。
频繁子图算法的发展历经二十年,基于频繁子图的应用也越来越广泛。
2 运用场景在由顶点和边构成的图中,顶点有其分类的标识,边亦有其分类的标识,我们需要在给定的图数据库中寻找出顶点标识和标识对应一致的子图,计算出支持度,若一旦支持度超过给定的阈值,便输出其子图,其子图便是一个频繁子图。
Lin W[2]等人认为频繁子图挖掘问题分为两个方面:在一个大图的不同区域挖掘子图适用于社交网络分析等领域;在大规模图集中挖掘子图适用于生物信息学和计算药理学等领域。
图集上的挖掘是指在多张图的图数据库中挖掘这些图中共现的子图。
在一张大图上的挖掘则是在一张图上挖掘图内出现的子图。
基于图事务集合的频繁子图挖掘算法与基于单个大图的频繁子图挖掘算法不同,在计算候选子图支持度的时候,基于图事务集合的频繁子图挖掘算法只需要计算候选子图与图事务集合中满足子图同构的小图的个数,而基于单个大图的频繁子图挖掘算法需要在这个大图中找出候选子图所有的同构的子图,计算用同构的子图的候选子图支持度[3]。


大规模时序图中稠密子图搜索算法的研究与应用时序图是一种常用于描述时间序列数据的图形模型,广泛应用于许多领域,例如交通流量分析、社交网络分析等。
随着数据规模的不断增大,大规模时序图的分析与挖掘成为了一个重要的研究课题。
其中,稠密子图搜索算法的研究与应用在大规模时序图的分析中具有重要意义。
稠密子图是指图中节点之间存在大量的连接关系,具有较高的密度。
在时序图中,稠密子图可以表示节点之间的相似性或者关联性。
因此,对大规模时序图进行稠密子图搜索可以帮助我们发现其中具有相似特征或相关性的节点集合,进而深入分析和挖掘时序数据的内在规律。
在研究中,学者们提出了许多有效的大规模时序图稠密子图搜索算法。
其中,一种常用的方法是基于图的聚类算法。
该算法将时序图中的节点划分为不同的簇,每个簇代表一个稠密子图。
通过计算节点之间的相似性度量,将相似的节点聚类在一起,从而找到稠密子图。
另一种常用的方法是基于子图挖掘的算法。
该算法通过枚举所有可能的子图组合,并计算其密度,找到具有最高密度的子图作为稠密子图。
为了提高算法的效率,研究者们还提出了一些剪枝策略,减少子图挖掘的计算量。
除了算法研究,大规模时序图稠密子图搜索算法也得到了广泛的应用。
例如,在交通流量分析中,研究者通过搜索稠密子图,可以找到具有相似车辆行驶模式的节点集合,从而预测交通拥堵情况。
在社交网络分析中,稠密子图搜索算法可以帮助我们发现具有相似兴趣爱好的用户群体,为个性化推荐等应用提供支持。
总之,大规模时序图中稠密子图搜索算法的研究与应用具有重要意义。
这些算法可以帮助我们从海量的时序数据中挖掘出具有相似特征或相关性的节点集合,为数据分析和挖掘提供支持。
随着数据规模的不断增大,稠密子图搜索算法的研究与应用还有很大的发展空间,将对各个领域的研究和实践产生重要影响。

9.数据挖掘技术在图像识别中的应用1. 引言随着数字化时代的到来,图像数据已经成为了人们生活、工作和娱乐的日常。
同时,图像数据中蕴藏着丰富的信息,如何快速、精确地从中提取有用信息,成为了图像处理和分析领域最为重要的问题之一。
数据挖掘技术在图像识别中的应用,成为了解决这一问题的一种新途径。
2. 图像识别的基本技术图像识别基于图像处理技术和模式识别技术实现。
其中,图像处理技术主要包括图像的预处理、增强、分割等步骤,用于去除噪声、提高图像质量、分割出物体等。
模式识别技术包括特征提取、分类等步骤,用于从图像中找出与具体问题相关的特征,并根据这些特征进行分类识别。
3. 数据挖掘技术在图像识别中的应用数据挖掘技术的应用可以帮助我们从海量的图像数据中提取有用的信息,以及发现其中的规律和特征。
下面介绍数据挖掘在图像识别中的两个主要应用:特征提取和分类识别。
(1)特征提取图像识别中的特征提取是指从图像中提取出与所要识别的对象相关的特征。
常用的特征包括线性特征、非线性特征、局部特征等。
数据挖掘技术中的特征提取,基于机器学习算法,可以自动地从图像中提取出最相关的特征,对提高图像识别的精确度有重要意义。
例如,基于深度学习的卷积神经网络(CNN)可以从大量的图像中学习到更具有代表性的特征,达到更高的分类精度。
这种方法主要是通过将一个图像处理为多个卷积层,并从中提取出多个不同方向、不同形状的特征,然后将这些特征与分类标签进行比较学习,以此提高分类精度。
(2)分类识别分类识别是指将所要识别的对象分为不同的类别。
数据挖掘技术中的分类识别,主要是基于机器学习算法,如支持向量机、决策树、随机森林等进行分类。
例如,基于支持向量机的图像分类,可以将图像中的特征提取出来作为输入数据,通过训练模型,建立起分类器。
在测试时,分类器会根据图像中的特征及其所属的类别进行学习和判断。
4. 数据挖掘技术的应用案例利用数据挖掘技术,可以对不同领域的图像数据进行处理和分析,得到更加精准的结果。

空间数据挖掘技术在遥感数据处理中的应用研究一、引言随着遥感技术的逐步发展和普及,遥感数据处理成为了一个热门的研究领域,而空间数据挖掘技术作为一种新兴的数据挖掘技术,在遥感数据处理中也得到了广泛的应用。
本文旨在探讨空间数据挖掘技术在遥感数据处理中的应用以及发展趋势。
二、空间数据挖掘技术概述空间数据挖掘技术是数据挖掘技术的一种,在空间数据的处理和分析方面具有很好的应用前景。
空间数据指的是涉及地理位置信息的数据,包括遥感数据、地理信息系统数据等。
空间数据挖掘技术主要是通过对数据进行分析和挖掘来发现其中的规律和有价值的信息,从而为后续的决策提供支持和保证。
目前,空间数据挖掘技术已经被广泛应用于城市规划、环境监测、农业生产等领域。
三、遥感数据处理中的应用研究1. 遥感图像分类遥感图像分类是遥感数据处理中的一个重要环节。
在遥感图像分类中,空间数据挖掘技术可以帮助分析和识别出图片中的各种地物与覆盖类型,并提供决策支持。
对于遥感图像分类中的数据特征提取过程中,空间数据挖掘技术可以帮助从多个精度尺度的空间数据中提取出具有较好分类性能的特征,从而提高分类精度。
2. 遥感影像分析随着遥感技术的不断进步,遥感影像分析也成为了遥感数据处理的一个重要环节。
在遥感影像分析中,空间数据挖掘技术可以帮助分析和处理影像中的时空数据,包括温度、变化、植被等信息,从而促进对影像的进一步理解和利用。
3. 空间数据挖掘中的地理信息系统地理信息系统是一种将软件技术和地理信息相结合的信息系统。
在地理信息系统中,空间数据挖掘技术可以帮助分析和挖掘出其中的地理信息,如交通路线、商业区域、人群热点等信息,为城市规划、交通设计等方面提供有效的决策数据支持。
四、空间数据挖掘技术在遥感数据处理中的发展趋势随着遥感技术和空间数据挖掘技术的不断发展和进步,这两种技术也不断拓展其应用范围。
未来,我们可以预见到以下几点发展趋势:1. 多源数据融合未来,会出现更多的遥感数据源,如卫星遥感和无人机遥感等,同时,各类遥感数据种类和所提供的信息也将更加丰富。

基于混合投影的频繁模式挖掘算法
刘君强;潘云鹤
【期刊名称】《计算机研究与发展》
【年(卷),期】2003(040)010
【摘要】频繁模式挖掘是最基本的数据挖掘问题,由于内在复杂性,提高挖掘算法性能一直是个难题. HP是通过数据库混合投影来挖掘频繁模式完全集的全新算法.HP 混合投影思想是:任意数据集都不能简单地归入某个单一特性类别,挖掘过程应根据局部数据子集的特性变化动态地调整频繁模式树构造策略、事务子集表示形式、投影方法. HP提出基于树表示的虚拟投影与基于数组表示的非过滤投影,较好地解决了提高时间效率与节省内存空间的矛盾.实验表明,HP时间效率比Apriori,FP-Growth和H-Mine高出1~3个数量级,并且空间可伸缩性也大大优于这些算法.【总页数】11页(P1488-1498)
【作者】刘君强;潘云鹤
【作者单位】杭州商学院计算机科学系,杭州,310035;浙江大学人工智能研究所,杭州,310027;浙江大学人工智能研究所,杭州,310027
【正文语种】中文
【中图分类】TP311
【相关文献】
1.一种基于混合搜索的高效Top-K最频繁模式挖掘算法 [J], 敖富江;杜静;陈彬;黄柯棣
2.一种基于频繁模式有向无环图的数据流频繁模式挖掘算法 [J], 任家东;王倩;王蒙
3.不产生候选的快速投影频繁模式树挖掘算法 [J], 何炎祥;向剑文;朱骁峰;孔维强
4.基于投影二维表的最大频繁模式挖掘算法 [J], 王利军
5.基于有序FP-tree结构和投影数据库的最大频繁模式挖掘算法 [J], 王利军; 唐立因版权原因,仅展示原文概要,查看原文内容请购买。
机器学习和数据挖掘在图像处理领域的应用研究近年来,机器学习和数据挖掘技术的发展,已经引发了学术界和工业界的广泛关注。
这些新技术的出现和普及,也为图像处理领域带来了新的应用前景。
在此背景下,我们有必要深入研究机器学习和数据挖掘在图像处理领域的应用。
一、机器学习在图像处理领域的应用机器学习是一种人工智能的分支,它的目标是让计算机具有像人类一样的"学习"能力。
机器学习可以分为无监督学习、有监督学习和强化学习等几种不同的方法。
在图像处理领域中,无监督学习和有监督学习应用最为广泛。
无监督学习对于图像处理的应用主要在于图像分割、聚类和降维等方面。
图像分割就是将一张图像按照一定规则划分为多个区域,以达到对图像进行精细化分析的目的。
聚类则是将具有相似性质的像素森集合到一起,而降维技术可以将高维数据压缩成低维数据,以便更好地用于可视化。
有监督学习在图像处理领域的应用则较多,主要包括物体分类、标注和识别等方面。
其中,物体分类是将图像中的物体分类为特定的种类,标注是对图像中每个像素进行标注,识别则是对图像中的物体进行识别。
有监督学习在图像处理领域中的应用发展迅速,相应的算法也越来越成熟。
二、数据挖掘在图像处理领域的应用数据挖掘是根据大数据集中的特征和关联性来发掘隐藏的知识和规律的过程。
在图像处理领域中,数据挖掘可以用于图像检索、目标跟踪和特征提取等方面。
图像检索是指在海量图像数据中,通过相似性检索出与目标图像相似的图片。
图像检索是一项非常具有挑战性的技术,而数据挖掘则可以通过将大数据集中的特征进行关联性挖掘,从而更加精准地检索出目标图像。
目标跟踪则是在一段时间内追踪图像中的目标物体,其应用广泛于安防领域以及智能监控等领域。
数据挖掘可以通过分析大量的数据集,预测目标物体的位置和状态,从而更好地追踪目标。
特征提取是指从图像中获取一组特征向量,并用于后续的分类、识别等应用中。
数据挖掘可以通过同类别样本和不同类别样本的特征分析,确定更加有效的特征提取方法,从而提高图像处理的效率和精准度。
大数据理论考试(习题卷13)第1部分:单项选择题,共64题,每题只有一个正确答案,多选或少选均不得分。
1.[单选题]()是指给目标用户产生的错误或不准确的视觉感知,而这种感知与数据可视化者的意图或数据本身的真实情况不一致。
A)视觉假象B)视觉认知C)视觉感知D)数据可视答案:A解析:视觉假象(Visual Illusion)是数据可视化工作中不可忽略的特殊问题。
视觉假象是指给目标用户产生的错误或不准确的视觉感知,而这种感知与数据可视化者的意图或数据本身的真实情况不一致。
视2.[单选题]python不支持的数据类型有A)charB)intC)floatD)list答案:A解析:3.[单选题]在图集合中发现一组公共子结构,这样的任务称为()。
A)频繁子集挖掘B)频繁子图挖掘C)频繁数据项挖掘D)频繁模式挖答案:B解析:频繁子图挖掘是指在图集合中挖掘公共子结构。
4.[单选题]下列哪个方法不属于情感分析的评测()。
A)CO评测B)cifar10数据集评测C)F TI评测D)TAC评答案:B解析:cifar10数据集Cifar-10由60000张32*32的RGB彩色图片构成,这个数据集最大的特点在于将识别迁移到了普适物体,而且应用于多分类,不属于情感分析的测评。
5.[单选题]SQL语句中修改表结构的命令是A)modify tableB)modify structureC)alter tableD)alter structure答案:C解析:6.[单选题]考虑值集{12 24 33 2 4 55 68 26},其四分位数极差是:()A)21B)24C)55D)3答案:A解析:四分位差,也称为内距或四分间距,它是上四分位数(QU,即位于75%)与下四分位数(QL,即位于25%)的差。
计算公式为:QD =QU-QL。
将数据从小到大排序,可得到QU=33,QL=12,因此QD=QU-QL=217.[单选题]下列不属于transform操作的是()A)mapB)filterC)sampleD)count答案:D解析:Transformation常用函数为map、filter、flatMap、sample、union、join等。
频繁子图挖掘算法的比较研究在大数据时代,数据挖掘技术成为了人们研究数据的重要手段之一。
频繁子图挖掘算法是挖掘图数据中潜在关系的一种常用手段。
它可以挖掘出图数据中频繁出现的子图,如社交网络中的社区结构、生物信息学中的蛋白质相互作用网络等。
在实践中,频繁子图挖掘算法被广泛地应用于数据挖掘、机器学习等领域。
当前,随着研究的深入,频繁子图挖掘算法也在不断地发展和创新。
本文将对目前主流的几种频繁子图挖掘算法进行比较研究。
一、背景介绍频繁子图挖掘是指在给定的大规模无向或有向图中,挖掘出满足支持度和置信度要求的子图,其中支持度指的是子图在图中出现的次数,置信度指的是满足支持度的子图在图中出现的比例。
频繁子图挖掘算法可以在无需精确查询的前提下,对图中的隐含模式进行发现和分析。
目前,有很多种不同的频繁子图挖掘算法,其中最常用的是基于Apriori算法的频繁子图挖掘算法。
随着研究的深入,越来越多的算法被提出来,并逐渐成为了主流,如GSpan、FSG等算法。
本文将对这几种算法进行比较研究。
二、Apriori算法Apriori算法最早由Agrawal和Srikant在1994年提出。
该算法适用于一般的数据挖掘任务,可用于频繁项集挖掘、关联规则挖掘、分类和聚类等任务。
该算法的基本思想是通过多次扫描事务数据库来寻找频繁项集,通过候选项集的生成和筛选来减少扫描次数,从而提高算法的效率。
在频繁子图挖掘领域,Apriori算法也有相应的改进。
例如,Menardi和Torelli 等人提出了一种改进版本的Apriori算法——RapidMiner,在速度上有了显著的提升。
另外,Apriori算法还有很多种变种,例如Eclat、FP-Growth等,这里不再赘述。
三、GSpan算法GSpan算法是一种高效的频繁子图挖掘算法。
GSpan算法以图的邻接矩阵及其迭代的方式,满足Apriori性质,通过对子图的遍历,不断生成候选子图并判断其是否频繁,从而提高算法的效率。
精心整理一种有效的并行频繁子图挖掘算法陈晓云赵娟陈鹏飞邢乔金刘国华(兰州大学信息科学与工程学院兰州730000)摘要:在分析并行频繁项集挖掘算法的基础上,提出了一种有效的并Keywords:parallel;frequentitemset;frequentsubgraph1.引言:频繁子图挖掘与其他比较成熟的频繁模式挖掘相比,图结构数据所包含的信息比一般的数据类型的数据量更大,其数据结构比线性表和树更为复杂。
在图形结构中,结点之间的关系是任意的,任意两个数据元素之间都可能相关。
尽管其结构很复杂,但是由于基于图的应用越来越广泛,其已经渗入到诸如语言学、逻辑学、物理、化学、计算机科学及数学的这些分支学科中。
如通过对已有的生物分子结构与未知的生物结构的研究,来确定未知生物分子与已知生物分子之间的成的子树集分发到其他从处理节点。
第二部分将频繁子图边扩展及同构判断这部分频繁子图挖掘算法中时间复杂度最高的部分并行处理。
文章在最后通过实验验证了本算法的有效性和可行性。
2.并行频繁项集挖掘综述频繁模式挖掘的搜索空间可以被模拟成类似格的结构,其中由模式的大小来决定它处于格中的哪一层,每一层又以某种顺序进行排列。
模式格的维数决定了问题的指数级别。
例如,对于一个有着n 个不同项的事务数据库,可能的模式就会有2n。
也就是说,如果一个事务数据库有100个不同的项,搜索空间就达到2100 1030。
巨大点上共享的来避免假负现象。
建立这样的树大大减少了生成频繁项集的开销。
这些树上的频繁项都是交叉连接起来的(与FP-Tree中相同),并且总体上连接在一个全局头表上。
每块树森林(treeforest)被分配到各个处理节点上,分开后的FP-Tree在挖掘过程中被自下向上的顺序快速遍历。
树的位置降低了并行节点间由于错误的操作而覆盖其他节点更新的可能性,同时使得死锁的可能性最小化。
但是基于共享式内存的并行频繁项集不能够适用于广泛使用的集群系统,因此局限性比较大。
价值工程0引言监控系统视频数据挖掘主要是通过对运动物体的行为方式及场景事件反馈的语义信息进行挖掘,得到一些用户感兴趣的信息及特征模式,用于在某种应急情况作出相关的响应[1]。
目前在一些应用领域,如在公安监控系统视频数据挖掘治安相关的事件的语义信息、刑事案件语义信息、交通案件语义信息等,快速获取这些信息可以及时进行相关决策和处理。
刑事案件要处理大量视频数据,目的是要从视频中得到嫌疑目标的身份信息,例如嫌疑人员个人信息及相关交通工具信息等;视频语义挖掘在交通案件的应用也较为广泛,交通监控视频需要在各个交通要道处获取车辆识别信息,在运动的目标的视频中获取相关事件信息,如异常拥堵、违法停车等异常事件,另外为了能优化管理交通,还需要从视频中提取车流量、车速等信息。
为了打击毒品犯罪,监听、监视、手机轨迹监控、网络监控、视频监控等秘密侦查手段成为侦查机关经常采用的侦查方法。
由于视频监控是在犯罪嫌疑人不察觉的情况下进行,所取得材料真实度高,因而对破案、查明案情及法院判案都具有重要意义。
要从非格式化的多媒体视频数据中提取相关的语义信息是一项十分困难的事情,因为视频数据缺少必要的描述信息。
传统的文本信息挖掘技术已经不能适合视频监控系统语义挖掘,如果对视频监控系统采用语义标注的人工方法,将耗费大量人力和物力,不能实时、有效地批量处理目前视频监控系统大量的数据[2]。
目前,基于监控系统内容的视频挖掘技术已经成为研究热点[3],对监控系统视频挖掘提出一种新方法已经迫在眉睫。
把监控系统视频内容提取转化为图数据,利用图理论和图数据挖掘技术对监控系统视频挖掘,得出视频语义信息,这将是监控系统数据挖掘的技术的新的尝试,对监控视频语义分析有着极其重要意义。
1视频挖掘与频繁子图挖掘技术融合关键帧是反映在监控视频内容中的某个或若干图像,这些帧图像反应视频主要语义信息,提取可以降低对全部视频内容处理带来的复杂度[4],把识别出来的关键帧保存成一个文本中,记为K 。
对视频的音频信号做出预处理,然后进行音频信号识别,识别的结果保存在文本中,记为A 。
对视频的文本数据进行识别处理得到文字,识别结果保存在文本中,记为V 。
隐马尔可夫模型HMM 是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生,是对统计过程随机描述的概率模型,它能对视频多种特征数据样本进行融合构建多模特征,有很好的抗干扰和抗噪能力。
自20世纪80年代以来,HMM 被应用于语音识别,取得重大成功。
到了90年代,HMM 还被引入计算机文字识别和移动通信核心技术“多用户的检测”。
HMM 在生物信息科学、故障诊断等领域也开始得到应用,目前在音频识别方法中甚为有效而广泛应用。
所以,对前面保存的文本K 、A 和V 分别进行基于HMM 的分词处理,首先去掉无实际语义词,将限定词和中文词性标注等去掉,然后对剩下词中的动词和名词进行进一步处理,将结果分别记为Wk 、Wa 和Wv ,最后分别计算名词、动词两个相同词性之间的语义相似度。
采用中国知网CNKI 中的距离测量方法作为语义相似度计算方法[5],———————————————————————基金项目:湖南省教育规划课题阶段性成果(警察信息素质教育理念及实战能力培养研究XJK013CXX012);湖南省公安厅资助科研项目(No.2013);湖南警察学院院级教学改革研究项目(湘警院教(2014)9号)。
作者简介:史伟奇(1967-),男,湖南长沙人,硕士,教授,主要研究方向为信息安全、计算机取证、数据挖掘。
频繁子图在监控系统数据挖掘中的应用Application of Frequent Subgraph on Monitoring System Data Mining史伟奇SHI Wei-qi(湖南警察学院信息技术(网监)系,长沙410138)(Department of Information Technology ,Hunan Police Academy ,Changsha 410138,China )摘要:监控系统数据挖掘研究近年来受到了国内外学者的逐渐关注,监控系统数据挖掘是发现基于视频原始底层数据对应于应用层的语义信息关联及对应关系。
视频底层数据特征十分复杂,沿用传统数据挖掘思想去理解和看待监控系统数据挖掘还不够。
与一般的数据比较,图能够表达更加丰富的语义。
把监控系统视频数据转化为图模型,将频繁子图挖掘算法应用到监控系统语义挖掘中,提出一种新的监控系统语义挖掘方法,与现有的方法相比较,该方法具有有效性和可行性。
Abstract :In recent years,more and more researchers over the world show great interests in monitoring system data mining gradually.The purpose of the monitoring system data mining is to establish the mapping between the underlying video data to high-level semantic information.Because this mapping is more complex,most of the research follows the idea of traditional data mining to understand and look at the monitor data pared with other data,graph can express richer semantic meaning.Converted monitoring system video data to graph data model,which frequent subgraph mining algorithm is applied to the monitoring system data mining.A prototype based on the model had been developed,and validated the correctness of the model,which can provide enlightenment to the designers Who work at monitoring system data mining.关键词:频繁子图;数据特征;监控系统;语义挖掘Key words :frequent subgraph ;data characteristics ;monitoring system ;semantic mining 中图分类号:TP311.1文献标识码:A 文章编号:1006-4311(2015)09-0298-03·298·DOI:10.14018/13-1085/n.2015.09.140Value Engineering记为β,且β∈[0,1]。
将分词处理的结果Wk、Wa和Wv中每单个词语记为图数据模型的结点V,进一步将相似度β定义为连接词语结点之间边的权重w,这样就构造出结点V和边权重为w 的监控视频的图模数据型[6]。
由此构造的图是一个带权无向图,记为G=(V,E),其中V表示结点集合,E表示边集合,且|V|=N表示结点个数为N,其中E中的任意边e的权重w(e)是一个非负数,即0≤w(e)≤1,w(e)的定义即为结点之间的语义相似度计算。
因为监控视频中图像、文字和音频等多媒体数据通常是表达一个主题,所以这些数据特征表示的语义相同。
具体包括如下步骤:①对训练集合及测试集合中的视频镜头均提取图像、音频、文本三种模态的底层特征,每个视频张量镜头由这三种底层数据特征组成三阶张量来表示其底层数据特征;②根据第一步的三阶视频张量视频场景集合的流线空间基本特征结构,采用转换矩阵对原始高维张量的维度进行降维处理;③利用支持向量机对第二步降维处理后的视频张量镜头集合进行处理,建立多种特征数据分类器模型;④对于测试镜头,由训练集合计算会得出相应的转换矩阵,然后对其投影计算,再利用第三步分类器模型对其进行语义概念检测。
以上做的目标是对Wk、Wa和Wv的三个向量的语义相似度距离降到最小,如果有不符合最小化原则的语义,则是因为识别处理错误导致,我们将其去除。
相似度距离最小化原则的公式表示为:argmini,j∑m,n,m≠n∑i,j,i≠jf w mi,w nj≠≠(1)其中w mi ,w nj表示上述分词处理结果的第i个和第j个词语,且有m,n∈{Wk,Wa,Wv},Wk,Wa,Wv表示的三阶视频张量中其中的一个向量;另外,i和j表示某个词语序号,且有0≤i≤|m|和0≤j≤|n|,i和j最大值为监控视频张量中其中某个向量的最大维数;函数f为某两个词语的相似度距离,且有f∈[0,1]。
分词处理结果经过最小化原则后,将问题转化为基于图模型数据挖掘问题[7]。
图数据挖掘先要定义两个重要概念,支持度和频繁度。
在G=(V,E)中,找到频繁子图g=(v,e),g为子图,v为频繁子图顶点集合,e为频繁子图的边集合。
用支持度和频繁度来发现视频模式的频繁子结构是监控系统挖掘语义新的尝试方法。
假设图Q=(V Q,E Q,l Q)和B=(V B,E B,l B)为两个带权标号的图,B∈GB={G1,G2,…,G n}。
设Q是一候选子图,B是图数据集里某个数据图,则候选子图Q在GB中的包含的子图的个数为σ(Q)=∑B∈GB b B (Q),其含义为图数据集GB中含有候选子图Q的数目之和。
候选子图Q在GB中总共出现的次数即频繁数为X (Q)=∑B∈GBδB(Q),其含义是候选子图Q在图数据集GB中的出现次数总和。
这样就可以对支持数和频繁数形式化定义了,Q在GB中的支持度形式化定义:R(Q)=σ(Q)/|GB|,Q在GB中的频繁度形式化定义:U(Q)=X(Q)/|GB|,且有0≤R(Q)≤1,U(Q)≥R(Q),这里U(Q)一般都大于1。
图1是对监控系统Wk,Wa,Wv等主要属性关联示意图,比如能从这个关联图中找出事件的核心信息及信息背后隐藏的规律。
监控系统语义挖掘就是从这个图中发现符合条件频繁出现的子图结构,对找出事件活动规律及事件发展动态趋势提供了参考依据,目前一些监控系统语义挖掘并不能发现某些具有丰富语义结构模式,也没有为决策提供及时有用信息,因此未能为社会安全预警体系能及时正确预警。