计量经济学第二章 简单线性回归
- 格式:ppt
- 大小:1.22 MB
- 文档页数:66

计量经济学复习要点参考教材:李子奈 潘文卿 计量经济学 数据类型:截面、时间序列、面板第二章 简单线性回归回归分析的基本概念,常用术语现代意义的回归是一个被解释变量对若干个解释变量依存关系的研究,回归的实质是由固定的解释变量去估计被解释变量的平均值;简单线性回归模型是只有一个解释变量的线性回归模型; 回归中的四个重要概念1. 总体回归模型Population Regression Model,PRMt t t u x y ++=10ββ--代表了总体变量间的真实关系;2. 总体回归函数Population Regression Function,PRFt t x y E 10)(ββ+=--代表了总体变量间的依存规律;3. 样本回归函数Sample Regression Function,SRFtt t e x y ++=10ˆˆββ--代表了样本显示的变量关系; 4. 样本回归模型Sample Regression Model,SRMtt x y 10ˆˆˆββ+=---代表了样本显示的变量依存规律; 总体回归模型与样本回归模型的主要区别是:①描述的对象不同;总体回归模型描述总体中变量y 与x 的相互关系,而样本回归模型描述所关的样本中变量y 与x 的相互关系;②建立模型的依据不同;总体回归模型是依据总体全部观测资料建立的,样本回归模型是依据样本观测资料建立的;③模型性质不同;总体回归模型不是随机模型,而样本回归模型是一个随机模型,它随样本的改变而改变;总体回归模型与样本回归模型的联系是:样本回归模型是总体回归模型的一个估计式,之所以建立样本回归模型,目的是用来估计总体回归模型;线性回归的含义线性:被解释变量是关于参数的线性函数可以不是解释变量的线性函数线性回归模型的基本假设简单线性回归的基本假定:对模型和变量的假定、对随机扰动项u 的假定零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定 普通最小二乘法原理、推导最小二乘法估计参数的原则是以“残差平方和最小”; Min21ˆ()niii Y Y =-∑01ˆˆ(,)ββ: 1121()()ˆ()nii i n ii XX Y Y XX ==--β=-∑∑ , 01ˆˆY Xβ=-βOLS 估计量的性质1线性:是指参数估计值0β和1β分别为观测值t y 的线性组合; 2无偏性:是指0β和1β的期望值分别是总体参数0β和1β; 3最优性最小方差性:是指最小二乘估计量0β和1β在在各种线性无偏估计中,具有最小方差; 高斯-马尔可夫定理OLS 参数估计量的概率分布OLS 随机误差项μ的方差σ2的估计 拟合优度的检验R 2 离差平方和的分解:TSS=ESS+RSS“拟合优度”是模型对样本数据的拟合程度;检验方法是构造一个可以表征拟合程度的指标——判定系数又称决定系数;121SSE SST SSR SSRR SST SST SST-===-,表示回归平方和与总离差平方和之比;反映了样本回归线对样本观测值拟合优劣程度的一种描述; 2 2[0,1]R ∈;3 回归模型中所包含的解释变量越多,2R 越大变量显着性检验,t 检验例子:回归报告函数形式对数、半对数模型系数的解释101ˆˆˆi iY X =β+β:X 变化一个单位Y 的变化 2^22()i Var x σβ=∑2^22ie n σ=-∑201ˆˆˆln ln i i Y X =β+β: X 变化1%,Y 变化1ˆβ%,表示弹性; 301ˆˆˆln i i Y X =β+β:X 变化一个单位,Y 变化百分之1001ˆβ 401ˆˆˆln i iY X =β+β:X 变化1%,Y 变化1ˆβ/100; 第三章 多元线性回归1、变量系数的解释剔除、控制其他因素的影响对斜率系数1ˆβ的解释:在控制其他解释变量X2不变的条件下,X1变化一个单位对Y 的影响;或者,在剔除了其他解释变量的影响之后,X1的变化对Y 的单独影响2、多元线性回归模型中对随机扰动项u 的假定,除了零均值假定、同方差假定、无自相关假定、随机扰动与解释变量不相关假定、正态性假定以外,还要求满足无多重共线性假定;3、多元线性回归模型参数的最小二乘估计式;参数估计式的分布性质及期望、方差和标准误差;在基本假定满足的条件下,多元线性回归模型最小二乘估计式是最佳线性无偏估计式;最小二乘法 OLS 公式: Y ' X X)' (X ˆ-1=β估计的回归模型: 的方差协方差矩阵: 残差的方差 : βˆ的估计的方差协方差矩阵是:4、修正可决系数的作用和方法;5、F 检验是对多元线性回归模型中所有解释变量联合显着性的检验,F 检验是在方差分析基础上进行的; 6、t检验7、可化为线性回归的模型 8、约束回归第四章 放宽基本假设一、异方差什么是异方差 异方差的后果ˆˆY =X β+u βˆ2ˆˆ'uu n k -s =异方差的检验White 检验 异方差的处理 加权最小二乘法 异方差稳健标准误二、序列相关什么是序列相关 序列相关的后果序列相关的检验DW 检验、LM 检验 序列相关的处理 广义最小二乘法 Newey-West 稳健标准误三、多重共线性多重共线性的概念 多重共线性的后果 多重共线性的检验 多重共线性的处理四、工具变量什么时候需要工具变量 作为工具变量的条件 两阶段最小二乘法第五章 专门问题一、虚拟变量1. 虚拟变量的定义:定性变量二值与多值;虚拟变量有时候不一定只是0和1;2. 如何引入虚拟变量:如果一个变量分成N 组,引入该变量的虚拟变量形式是只能放入N-1个虚拟变量;3. 虚拟变量系数的解释:不同组均值的差基准组或对照组与处理组4. 以下几种模型形式表达的不同含义;1tt t t u D X Y +++=210βββ:截距项不同;2tt t t t u X D X Y +++=210βββ:斜率不同;3tt t t t t u X D D X Y ++++=3210ββββ:截距项与斜率都不同;其中D 是二值虚拟变量,X 是连续的变量;第八章 时间序列平稳性的概念 白噪声 随机游走 单位根的概念单位根的检验ADF 检验,ADF 的三种形式 单整趋势平稳与差分平稳 协整的概念 协整的检验 误差修正模型Eviews 回归结果界面解释表计量经济学复习题第二章习题:1、2、3、5、6、7、9、10、11、12第三章习题:1、2、3、4、5、6、7、8、9、10、11、12、13 第四章习题:2、5、6、8、9、10 第五章习题:1、2、3、5、6 第八章习题:1、2、5、6、7、8 1、判断下列表达式是否正确 2、给定一元线性回归模型:1叙述模型的基本假定;2写出参数0β和1β的最小二乘估计公式; 3说明满足基本假定的最小二乘估计量的统计性质; 4写出随机扰动项方差的无偏估计公式; 3、对于多元线性计量经济学模型:1该模型的矩阵形式及各矩阵的含义; 2对应的样本线性回归模型的矩阵形式; 3模型的最小二乘参数估计量;4、根据美国1961年第一季度至1977年第二季度的数据,我们得到了如下的咖啡需求函数的回归方程:D D D P I P t t t t t t tT Q 321'0097.0157.00961.00089.0ln 1483.0ln 5115.0ln 1647.02789.1ˆln ----++-=其中,Q=人均咖啡消费量单位:磅;P=咖啡的价格以1967年价格为不变价格;I=人均可支配收入单位:千元,以1967年价格为不变价格;P '=茶的价格1/4磅,以1967年价格为不变价格;T=时间趋势变量1961年第一季度为1,…,1977年第二季度为66;D 1=1:第一季度;D 2=1:第二季度;D 3=1:第三季度; 请回答以下问题:① 模型中P 、I 和P '的系数的经济含义是什么 ② 咖啡的需求是否很有弹性 ③ 咖啡和茶是互补品还是替代品④ 你如何解释时间变量T 的系数 ⑤ 你如何解释模型中虚拟变量的作用 ⑥ 哪一个虚拟变量在统计上是显着的 ⑦ 咖啡的需求是否存在季节效应5、为研究体重与身高的关系,我们随机抽样调查了51名学生其中36名男生,15名女生,并得到如下两种回归模型:h W5662.506551.232ˆ+-= t=h D W7402.38238.239621.122ˆ++-= t=其中,Wweight=体重 单位:磅;hheight=身高 单位:英寸 请回答以下问题:① 你将选择哪一个模型为什么② 如果模型确实更好,而你选择了,你犯了什么错误 ③ D 的系数说明了什么6、以t Q 表示粮食产量,t A 表示播种面积,t C 表示化肥施用量,经检验,它们取对数后都是)1(I 变量且互相之间存在)1,1(CI 关系;同时经过检验并剔除不显着的变量包括滞后变量,得到如下粮食生产模型:t t t t t t C C A Q Q μααααα+++++=--1432110ln ln ln ln ln 1 ⑴ 写出长期均衡方程的理论形式; ⑵ 写出误差修正项ecm 的理论形式; ⑶ 写出误差修正模型的理论形式;⑷ 指出误差修正模型中每个待估参数的经济意义;7、简述异方差对下列各项有何影响:1OLS 估计量及其方差;2置信区间;3显着性t 检验和F 检验的使用;8、假设某研究使用250名男性和280名女性工人的工资Wage 数据估计出如下OLS 回归:标准误其中WAGE 的单位是美元/小时,Male 为男性=1,女性=0的虚拟变量;用男性和女性的平均收入之差定义工资的性别差距;1性别差距的估计值是多少2计算截距项和Male系数的t统计量,估计出的性别差距统计显着不为0吗5%显着水平的t统计量临界值为3样本中女性的平均工资是多少男性的呢4对本回归的R2你有什么评论,它告诉了你什么,没有告诉你什么评价这个回归结果5另一个研究者利用相同的数据,但建立了WAGE对Female的回归,其中Female 为女性=1,男性=0的变量;由此计算出的回归估计是什么9、基于人口调查1998年的数据得到平均小时收入对性别、教育和其他特征的回归结果,见下表;其中:AHE=平均小时收入;College=二元变量大学取1,高中取0;Female女性取1,男性取0;Age=年龄年;Northeast居于东北取1,否则为0;Midwest居于中西取1,否则为0;South居于南部取1,否则为0;West居于西部取1,否则取0;表1:基于2004年CPS数据得到的平均小时收入对年龄、性别、教育、地区的回归结果概括统计量和联合检验SERR2注:括号中是标准误;(1)计算每个回归的调整R2;(2)利用表1中列1的回归结果回答:大学毕业的工人平均比高中毕业的工人挣得多吗多多少这个差距在5%显着性水平下统计显着吗男性平均比女性挣的多吗多多少这个差距在5%显着性水平下统计显着吗(3)年龄是收入的重要决定因素吗请解释;使用适当的统计检验来回答;(4)Sally是29岁女性大学毕业生,Betsy是34岁女性大学毕业生,预测她们的收入;(5)用列3的回归结果回答:地区间平均收入存在显着差距吗利用适当的假设检验解释你的答案;(6)为什么在回归中省略了回归变量West如果加上会怎样;解释3个地区回归变量的系数的经济含义;7Juantia是南部28岁女性大学毕业生,Jennifer是中西部28岁女性大学毕业生,计算她们收入的期望差距。

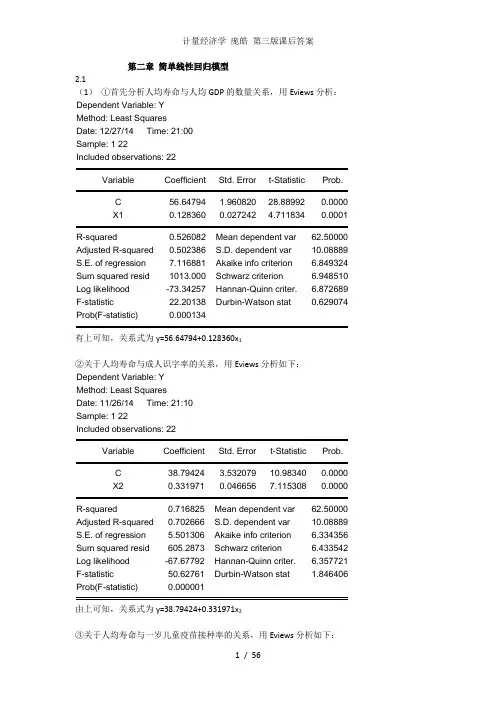
第二章简单线性回归模型2.1(1)①首先分析人均寿命与人均GDP的数量关系,用Eviews分析:Dependent Variable: YMethod: Least SquaresDate: 12/27/14 Time: 21:00Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 56.64794 1.960820 28.88992 0.0000X1 0.128360 0.027242 4.711834 0.0001R-squared 0.526082 Mean dependent var 62.50000 Adjusted R-squared 0.502386 S.D. dependent var 10.08889 S.E. of regression 7.116881 Akaike info criterion 6.849324 Sum squared resid 1013.000 Schwarz criterion 6.948510 Log likelihood -73.34257 Hannan-Quinn criter. 6.872689 F-statistic 22.20138 Durbin-Watson stat 0.629074 Prob(F-statistic) 0.000134有上可知,关系式为y=56.64794+0.128360x1②关于人均寿命与成人识字率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:10Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 38.79424 3.532079 10.98340 0.0000X2 0.331971 0.046656 7.115308 0.0000R-squared 0.716825 Mean dependent var 62.50000 Adjusted R-squared 0.702666 S.D. dependent var 10.08889 S.E. of regression 5.501306 Akaike info criterion 6.334356 Sum squared resid 605.2873 Schwarz criterion 6.433542 Log likelihood -67.67792 Hannan-Quinn criter. 6.357721 F-statistic 50.62761 Durbin-Watson stat 1.846406 Prob(F-statistic) 0.000001由上可知,关系式为y=38.79424+0.331971x2③关于人均寿命与一岁儿童疫苗接种率的关系,用Eviews分析如下:Dependent Variable: YMethod: Least SquaresDate: 11/26/14 Time: 21:14Sample: 1 22Included observations: 22Variable Coefficient Std. Error t-Statistic Prob.C 31.79956 6.536434 4.864971 0.0001X3 0.387276 0.080260 4.825285 0.0001R-squared 0.537929 Mean dependent var 62.50000Adjusted R-squared 0.514825 S.D. dependent var 10.08889S.E. of regression 7.027364 Akaike info criterion 6.824009Sum squared resid 987.6770 Schwarz criterion 6.923194Log likelihood -73.06409 Hannan-Quinn criter. 6.847374F-statistic 23.28338 Durbin-Watson stat 0.952555Prob(F-statistic) 0.000103由上可知,关系式为y=31.79956+0.387276x3(2)①关于人均寿命与人均GDP模型,由上可知,可决系数为0.526082,说明所建模型整体上对样本数据拟合较好。








第二章 简单线性回归模型一、单项选择题(每题2分): 1、回归分析中定义的( )。
A 、解释变量和被解释变量都是随机变量B 、解释变量为非随机变量,被解释变量为随机变量C 、解释变量和被解释变量都为非随机变量D 、解释变量为随机变量,被解释变量为非随机变量2、最小二乘准则是指使( )达到最小值的原则确定样本回归方程。
A 、1ˆ()nt tt Y Y=-∑B 、1ˆn t tt Y Y =-∑ C 、ˆmax t tY Y - D 、21ˆ()n t t t Y Y =-∑3、下图中“{”所指的距离是( )。
A 、随机误差项B 、残差C 、i Y 的离差D 、ˆiY的离差 4、参数估计量ˆβ是iY 的线性函数称为参数估计量具有( )的性质。
A 、线性 B 、无偏性 C 、有效性 D 、一致性5、参数β的估计量βˆ具备最佳性是指( )。
A 、0)ˆ(=βVarB 、)ˆ(βVar 为最小C 、0ˆ=-ββD 、)ˆ(ββ-为最小 6、反映由模型中解释变量所解释的那部分离差大小的是( )。
A 、总体平方和 B 、回归平方和 C 、残差平方和 D 、样本平方和7、总体平方和TSS 、残差平方和RSS 与回归平方和ESS 三者的关系是( )。
A 、RSS=TSS+ESS B 、TSS=RSS+ESS C 、ESS=RSS-TSS D 、ESS=TSS+RSS 8、下面哪一个必定是错误的( )。
A 、 i i X Y 2.030ˆ+= ,8.0=XY rB 、 i i X Y 5.175ˆ+-= ,91.0=XY rC 、 i i X Y 1.25ˆ-=,78.0=XY rD 、 i i X Y 5.312ˆ--=,96.0-=XY r9、产量(X ,台)与单位产品成本(Y ,元/台)之间的回归方程为ˆ356 1.5YX =-,这说明( )。
A 、产量每增加一台,单位产品成本增加356元B 、产量每增加一台,单位产品成本减少1.5元C 、产量每增加一台,单位产品成本平均增加356元D 、产量每增加一台,单位产品成本平均减少1.5元10、回归模型i i i X Y μββ++=10,i = 1,…,n 中,总体方差未知,检验010=β:H 时,所用的检验统计量1ˆ11ˆβββS -服从( )。