数学地质第六章 判别分析:线性-逐步解析
- 格式:ppt
- 大小:4.03 MB
- 文档页数:105



线性判别分析(LDA)说明:本⽂为个⼈随笔记录,⽬的在于简单了解LDA的原理,为后⾯详细分析打下基础。
⼀、LDA的原理LDA的全称是Linear Discriminant Analysis(线性判别分析),是⼀种supervised learning。
LDA的原理:将带上标签的数据(点),通过投影的⽅法,投影到维度更低的空间中,使得投影后的点,会形成按类别区分,⼀簇⼀簇的情况,相同类别的点,将会在投影后的空间中更接近。
因为LDA是⼀种线性分类器。
对于K-分类的⼀个分类问题,会有K个线性函数:当满⾜条件:对于所有的j,都有Yk > Yj,的时候,我们就说x属于类别k。
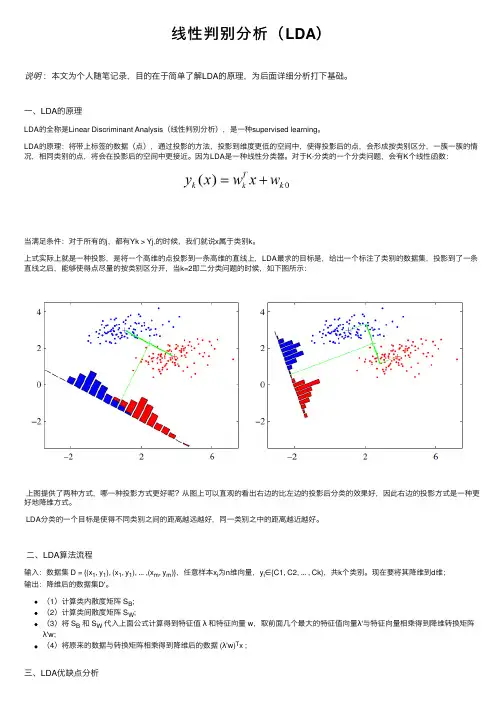
上式实际上就是⼀种投影,是将⼀个⾼维的点投影到⼀条⾼维的直线上,LDA最求的⽬标是,给出⼀个标注了类别的数据集,投影到了⼀条直线之后,能够使得点尽量的按类别区分开,当k=2即⼆分类问题的时候,如下图所⽰:上图提供了两种⽅式,哪⼀种投影⽅式更好呢?从图上可以直观的看出右边的⽐左边的投影后分类的效果好,因此右边的投影⽅式是⼀种更好地降维⽅式。
LDA分类的⼀个⽬标是使得不同类别之间的距离越远越好,同⼀类别之中的距离越近越好。
⼆、LDA算法流程输⼊:数据集 D = {(x1, y1), (x1, y1), ... ,(x m, y m)},任意样本x i为n维向量,y i∈{C1, C2, ... , Ck},共k个类别。
现在要将其降维到d维;输出:降维后的数据集D'。
(1)计算类内散度矩阵 S B;(2)计算类间散度矩阵 S W;(3)将 S B和 S W代⼊上⾯公式计算得到特征值λ和特征向量 w,取前⾯⼏个最⼤的特征值向量λ'与特征向量相乘得到降维转换矩阵λ'w;(4)将原来的数据与转换矩阵相乘得到降维后的数据 (λ'w)T x ;三、LDA优缺点分析LDA算法既可以⽤来降维,⼜可以⽤来分类,但是⽬前来说,主要还是⽤于降维。

判别分析导言判别分析是统计学中一种常用的数据分析方法,用于区分不同群体或类别之间的差异。
它通过寻找最佳的分类边界,帮助我们预测或判定未知样本的分类。
判别分析常用于模式识别、数据挖掘、生物学、医学等领域。
本文将介绍判别分析的基本概念、应用领域和算法。
一、判别分析的基本概念判别分析旨在通过构造合适的判别函数,将不同群体或类别的样本区分开来。
判别函数的建立是判别分析的核心任务,而判别函数的类型通常根据问题的特点来选择。
常见的判别函数有线性判别函数、二次判别函数、贝叶斯判别函数等。
判别分析的目标是使得样本在不同类别的判别函数值有较大差异。
二、判别分析的应用领域1. 模式识别判别分析在模式识别中的应用非常广泛。
通过判别分析,我们可以建立能够识别不同模式的模型。
例如,在人脸识别任务中,我们可以使用判别分析来建立一个分类器,能够将不同人脸的图像正确分类。
2. 数据挖掘在数据挖掘领域,判别分析可以帮助我们发现变量之间的关系,并进行预测。
通过对已有数据进行判别分析,我们可以预测未知样本的分类。
例如,在市场营销中,通过对消费者进行判别分析,我们可以预测消费者的购买行为,从而制定更精准的营销策略。
3. 生物学和医学判别分析在生物学和医学领域中也有广泛的应用。
例如,在癌症诊断中,通过对患者的临床数据进行判别分析,我们可以建立一个分类器,能够判断该患者是否患有癌症。
三、判别分析的算法判别分析的算法根据问题的特点和要求选择。
下面介绍两种常见的判别分析算法:1. 线性判别分析(LDA)线性判别分析是一种常见且简单的判别分析算法。
它的核心思想是通过将高维数据映射到低维空间中,使得不同类别的样本在投影空间中有较大的差异。
在LDA算法中,我们需要计算类内散度矩阵和类间散度矩阵,并求解其特征值和特征向量,从而确定投影向量。
2. 二次判别分析(QDA)二次判别分析是一种更为复杂的判别分析算法。
它假设不同类别的样本的协方差矩阵不相等,即每个类别内部的变化程度不同。
第11,12,13课判别分析(Discriminant Analysis)讲五个问题:一、什么是判别分析;二、费歇准则下的二组判别分析;三、贝叶斯多组判别分析;四、多组逐步判别分析;五、问题讨论和实例。
一、什么是判别分析概念:判别分析是一种判别样品所属类型的统计方法。
思想:根据已知类型的样品,按其特征,构造一个判别函数,定出划分类型的界线,并对新样品所属类型进行判别(也可对已知类型的样品进行判别检验)。
类型:若判别类型是两个时,称两组判别分析。
如油层、水层;有矿、无矿等。
若判别的类型是两个以上时称多组判别分析。
如油层、气层、水层;泥岩、砂岩、灰岩等。
原则:两组判别分析是在fisher意义下求解,多组判别是在Bayes意义下求解。
原理:见如下几何图形所示:当P=2时:211221jjj y c x c x cx ==+=∑当在P 维时:11221pp p jj j y c x c x c x cx ==+++=∑y—综合指标,是i x 的线性函数,也有非线性的。
式中:j c —判别系数。
应用:◆ 判别和检验样品的所属类型;◆评价,如岩体评价,区别海相或陆相砂岩,区别含油层或含水层。
鉴别矿物、岩石类型和古生物的种属;◆地层和岩相的划分;◆解释砂体的构造背景,区别沉积条件和环境,火山构造类型等。
二、两组判别分析—Fisher 准则前提条件:A 、B 两类总体,A 组取了1n 个样品,B 组取了2n 个样品,每个样品测定了P 个指标,原始数据见教材。
1、求线性判别函数y11221pp p jj j y c x c x c x cx ==+++=∑式中:j c —待定系数 j x —指标问题的关键是如何求得j c ,使得A 、B 两组分的很清楚,即要得到y 值,使得A 、B 区分开。
原则:Fisher :类间差别要大,类内差别要小。
综合指标 A 类 (1n 个样品) 综合指标 B 类 (2n 个样品)1112121222(),(),,()(),(),,()P P x A x A x A x A x A x A 12()()y A y A 1112121222(),(),,()(),(),,()P P x B x B x B x B x B x B 12()()y B y BA 类样品用 1111()()n i i y A y A n ==∑——代表=1()()pjj j y A cx A ==∑A 类样品用 2121()()n i i y B y B n ==∑——代表=1()()pjj j y B cx B ==∑A 类内差别为:[]121()()n i i y A y A =-∑B 类内差别为:[]221()()n i i y B y B =-∑类内差别为:[][]122211()()()()n n iii i F y A y A y B y B ===-+-∑∑类间差别为:[]2()()Q y A y B =-Fisher 准则:使Q I F=达到极大,求出j c 。

线性判别分析LDA点x 0到决策⾯g (x )=w T x +w 0的距离:r =g (x )‖⼴义线性判别函数因任何⾮线性函数都可以通过级数展开转化为多项式函数(逼近),所以任何⾮线性判别函数都可以转化为⼴义线性判别函数。
Fisher LDA(线性判别分析)Fisher准则的基本原理找到⼀个最合适的投影轴,使两类样本在该轴上投影之间的距离尽可能远,⽽每⼀类样本的投影尽可能紧凑,从⽽使两类分类效果为最佳。
分类:将 d 维分类问题转化为⼀维分类问题后,只需要确定⼀个阈值点,将投影点与阈值点⽐较,就可以做出决策。
未知样本x的投影点 y= w ^{* T} x .1. 计算各类样本均值向量:m_i={1\over N_i}\sum_{X\in w_i}X,\quad i=1,22. 计算样本类内离散度矩阵S_i 和总类内离散度矩阵S_w .(w ithin scatter matrix)S_i=\sum_{X\in w_i}(X-m_i)(X-m_i)^T,\quad i=1,2 \\ S_w=S_1+S_23. 计算样本类间离散度矩阵S_b=(m_1-m_2)(m_1-m_2)^T .(b etween scatter matrix)4. 求向量w^*.定义Fisher准则函数:J_F(w)={w^TS_bw\over w^TS_ww}J_F 取最⼤值时w^*=S_w^{-1}(m_1-m_2)Fisher准则函数推导:投影之后点y= w ^{T} x ,y对应的离散度矩阵为\tilde S_w,\tilde S_b ,则⽤以评价投影⽅向w的函数为J_F(w)={\tilde S_b\over \tilde S_w}={w^TS_b\ w\over w^TS_w\ w}5. 将训练集内所有样本进⾏投影:y=(w^*)^TX6. 计算在投影空间上的分割阈值,较常⽤的⼀种⽅式为:y_0={N_1\widetilde {m_1}+N_2\widetilde{m_2}\over N_1+N_2}7. 对于给定的测试X,计算它在w^*上的投影点y=(w^*)^TX 。




数据分析知识:数据分析中的线性判别分析数据分析中,线性判别分析是一种常见的分类方法。
它的主要目的是通过在不同类别间寻找最大化变量方差的线性组合来提取有意义的特征,并对数据进行分类。
线性判别分析在实际应用中非常有用,例如在医学诊断、金融风险评估和生物计量学等领域。
一、简要介绍线性判别分析线性判别分析是一种有监督的数据挖掘技术,在分类问题中常用。
整个过程包括两个主要的部分:特征提取和分类器。
特征提取的任务是从原始数据中提取有意义的特征,用以区分不同类别的样本。
而分类器则是将已知类别的样本分成预先定义的类别。
在实际应用中,线性判别分析通常用于二分类问题。
其基本思想是,在不同类别(即两个不同样本)之间寻找一个最优的超平面,使得在该平面上不同类别的样本能够被清晰地分开。
也就是说,在分类平面上,同类样本尽可能地被压缩到一起,而不同类别的样本尽可能地被分开。
二、分类器在线性判别分析中的应用在进行线性判别分析时,一般都会用到一个分类器。
分类器可以对已知类别的样本进行分类,并对新的未知样本进行预测。
常用的分类器有:最近邻分类器、支持向量机、朴素贝叶斯分类器和决策树等。
其中,最近邻分类器是一种较为简单的分类器,其原理是对未知样本进行分类时,找到离该样本最近的一个或几个已知样本,并将该样本划归到该已知样本所属的类别。
而支持向量机则是一种复杂且有效的分类器。
它采用最大间隔的思想,在将不同类别分开的同时,尽可能地避免分类器过拟合的情况。
朴素贝叶斯分类器则是一种基于贝叶斯定理的分类器,它假设不同变量之间相互独立,并通过给定类别的样本来估算样本中各个特征的概率分布。
最后,决策树则是一种可视化的分类器,它通过一系列的条件分支,将样本划分为不同的类别。
三、特征提取在线性判别分析中的应用特征提取是在原始数据基础上提取可识别和易于分类的特征过程。
在线性判别分析中,常用到的特征提取方法有:主成分分析、线性判别分析和奇异值分解等。
其中,主成分分析(Principal Component Analysis, PCA)是一种常见的数据降维方法。
第六章判别分析第六章判别分析近年来,判别分析在植物分类、天⽓预报、经济决策与管理、社会调查、农业科研、科研数据整理分析中都得到了⼴泛的应⽤。
判别分析是⼀种很有实⽤价值⽽且应⽤极其⼴泛的⼀种统计⽅法。
本章介绍两种常⽤的判别⽅法:距离判别及Fisher 判别。
§1 距离判别距离判别是先给出⼀个样品到某个总体的距离的定义,然后根据样品到各个总体的距离的远近,来判断该样品应归属于哪⼀个总体。
本节先介绍多元分析中⼴泛应⽤的马⽒距离的概念,然后,再介绍距离判别的⽅法。
⼀、马⽒距离 1.概念距离是⼀个最直观的概念,多元分析中许多⽅法都可⽤距离的观点来推导,其中最著名的⼀个距离是印度统计学家Mahalanobis 于1936年引进的,所以习惯上称之为马⽒距离。
下⾯我们很快会看到,马⽒距离是我们熟知的欧⽒距离的⼀种推⼴。
定义:设P 维总体G 的均值向量为u ,协差阵为V>0(有V -1>0存在)X,Y 是总体G 的两个样品,则:(1)X 与Y 两点的马⽒距离d(X,Y)为:211)]()[(),(Y X V Y X Y X d -'-=-(2) X 与总体G 的马⽒距离为:211)]()[(),(u X V u X G X d -'-=-2.性质很容易证明,马⽒距离符合作为距离的三条基本公理:设X ,Y ,Z 是总体G 的三个样品,则有: (1)⾮负性:Y X Y X d Y Xd =?=≥0),(,0),( (2)对称性:),(),(X Y d Y X d =(3)满⾜三⾓不等式:),(),(),(Z Y d Y X d Z X d +≤证:(2)),()]()[()]()[(),(211211X Y d X Y V X Y Y X V Y X Y X d =-'-=-'-=-- 其它性质不证。
由马⽒距离的定义知,当V=E 时,X 与Y 的马⽒距离就变成为欧⽒距离:221121)()()]()[(),(p p y x y x Y X Y X Y X d -++-=-'-=所以,马⽒距离是欧⽒距离的推⼴,欧⽒距离是马⽒距离的特例。
线性判别分析(LinearDiscriminantAnalysis,LDA)⼀、线性判别器的问题分析线性判别分析(Linear Discriminant Analysis, LDA)是⼀种经典的线性学习⽅法,在⼆分类问题上亦称为 "Fisher" 判别分析。
与感知机不同,线性判别分析的原理是降维,即:给定⼀组训练样本,设法将样本投影到某⼀条直线上,使相同分类的点尽可能地接近⽽不同分类的点尽可能地远,因此可以利⽤样本点在该投影直线上的投影位置来确定样本类型。
⼆、线性判别器的模型还是假定在p维空间有m组训练样本对,构成训练集T=(x1,y1),(x2,y2),...,(x n,y n),其中x i∈R1×p,y i∈{−1,+1},以⼆维空间为例,在线性可分的情况下,所有样本在空间可以描述为:我们的⽬的就是找到⼀个超平⾯Φ:b+w1x1+w2x2+..+w n x n=0,使得所有的样本点满⾜ “类内尽可能接近,类外尽可能遥远"。
那么我们⽤类内的投影⽅差来衡量类内的接近程度,⽤类间的投影均值来表⽰类间的距离。
这⾥,我们另w代表投影⽅向,如下图所⽰,在这⾥,x,w均为p×1 的列向量,那么根据投影定理,x在w上的投影p既有⽅向⼜有距离,那么:p与w同⽅向,表⽰为:w||w||;p的长度为:||x||cosθ=||x||x⋅w||w||||x||=x⋅w||w||由于w的长度不影响投影结果,因此我们为了简化计算,设置 ||w||=1,只保留待求w的⽅向:||p||=x⋅w=w T x 2.1 类间投影均值我们假设⽤u0,u1分别表⽰第1,2类的均值,那么:u0=1mm∑i=1x i,u1=1nn∑i=1x i所以,第⼀,⼆类均值在w⽅向上的投影长度分别表⽰为:w T u0,w T u1 2.2 类内投影⽅差根据⽅差的计算公式,第⼀类的类内投影⽅差可以表⽰为:z0=1nn∑i=1(w T x i−w T u0)2=1nn∑i=1(w T x i−w T u0)(w T x i−w T u0)T即:z0=1nn∑i=1w T(x i−u0)(x i−u0)T w=w T[1nn∑i=1(x i−u0)(x i−u0)T]w如下图所⽰:当x i,u0都是⼀维时,式⼦1n∑ni=1(x i−u0)(x i−u0)T就表⽰所有输⼊x i的⽅差;当x i,u0都是⼆维时,式⼦1n∑ni=1(x i−u0)(x i−u0)T就表⽰:1nn∑i=1x11−u01x12−u02x11−u01x12−u02=1nn∑i=1(x11−u01)2(x11−u01)(x12−u02)(x12−u02)(x11−u01)(x12−u02)2其中:u01表⽰第⼀类集合中在第⼀个维度上的均值,u01表⽰第⼀类集合中在第⼆个维度上的均值,x11表⽰第⼀类集合中第⼀个维度的坐标值,x12表⽰第⼀类集合中第⼆个维度的坐标值[][][]综上:当x i,u0都是p维时,式⼦1n∑ni=1(x i−u0)(x i−u0)T表⽰p个维度之间的协⽅差矩阵,我们⽤符号M0表⽰。