专题2:线性判别分析、诊断的敏感度、特异度及ROC曲线的绘制
- 格式:doc
- 大小:312.00 KB
- 文档页数:7

绘制ROC曲线什么是ROC曲线ROC曲线是什么意思,书⾯表述为:“ROC 曲线(接收者操作特征曲线)是⼀种显⽰分类模型在所有分类阈值下的效果的图表。
”好吧,这很不直观。
其实就是⼀个⼆维曲线,横轴是FPR,纵轴是TPR:⾄于TPR,FPR怎么计算:⾸先要明确,我们是在讨论分类问题中,讨论怎样绘制ROC曲线的,⼤前提是分类问题。
别想太多,就当是⼆分类问题好了,⼀类是Positive,⼀类是Negative分类模型的预测结果,被阈值化之后,判定为TP,FP,TN,FN四种情况:if Y_pred ≥ thresh and Y_gt is Positive, then TP++if Y_pred ≥ thresh and Y_gt is Negative, then FP++if Y_pred < thresh and Y_gt is Positive, then FN++if Y_pred < thresh and Y_gt is Negative, then TN++然后TPR, FPR的定义为TPR = TP / (TP + FN) (也就是Recall)FPR = FP / (FP + TN)举个栗⼦假设你现在做机器学习笔试题,题⽬给了分类任务中的测试集标签和分类模型的预测结果,也就是给了Y_pred和Y_gt,让你⼿绘AUC曲线。
Can you draw it?答案⼀定是Yes, I can(看⼀下就会了)。
gt: [0, 1, 0, 1]. pred: [0.1, 0.35, 0.4, 0.8] 那么在阈值分别取{0.1, 0.35, 0.4, 0.8}的时候,分别判断出每个pred是TP/FP/TN/FP中的哪个,进⽽得出当前阈值下的TPR和FPR,也就是(FPR, TPR)这⼀ROC曲线图上的点;对于所有阈值都计算相应的(FPR, TPR),则得到完整的ROC曲线上的⼏个关键点,再连线(稍微脑补⼀下?)就得到完整ROC曲线。

一、导言在机器学习领域,ROC曲线(Receiver Operating Characteristic curve)是一种常用的评估分类模型性能的方法。
ROC曲线能够显示出不同分类器在不同阈值下的表现,可以帮助我们选择最优的分类器。
在Python中,我们可以使用一些库来绘制ROC曲线,这篇文章将介绍如何使用Python代码绘制ROC曲线。
二、准备工作在使用Python代码绘制ROC曲线之前,我们需要安装一些必要的库。
我们需要安装scikit-learn库,它是一个用于机器学习的库,包含了许多常用的机器学习算法和工具。
我们需要安装matplotlib库,它是一个用于绘图的库,可以方便地绘制ROC曲线。
在安装好以上两个库之后,我们就可以开始使用Python代码绘制ROC曲线了。
三、数据准备在绘制ROC曲线之前,我们需要准备一些分类模型的预测结果。
假设我们已经训练好了一个分类器,并且得到了它在测试集上的预测结果。
这些预测结果通常是一个概率值,表示样本属于正例的概率。
我们可以使用这些预测结果来绘制ROC曲线。
四、绘制ROC曲线接下来,我们将介绍如何使用Python代码绘制ROC曲线。
我们首先需要导入必要的库和模块:```pythonimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.metrics import roc_curve, auc```我们可以使用roc_curve函数计算出ROC曲线的横坐标和纵坐标,并计算出曲线下面积(AUC):```pythonfpr, tpr, thresholds = roc_curve(y_true, y_score)roc_auc = auc(fpr, tpr)```在上面的代码中,y_true表示真实的标签,y_score表示模型的预测结果。
我们可以使用matplotlib库绘制出ROC曲线:```pythonplt.figure()plt.plot(fpr, tpr, color='darkorange', lw=2, label='ROC curve(area = 0.2f)' roc_auc)plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')plt.xlim([0.0, 1.0])plt.ylim([0.0, 1.05])plt.xlabel('False Positive Rate')plt.ylabel('True Positive Rate')plt.title('Receiver Operating Characteristic')plt.legend(loc="lower right")plt.show()```五、总结在本文中,我们介绍了如何使用Python代码绘制ROC曲线。

医学roc曲线的绘制与解释
医学ROC曲线是用于评估诊断试验敏感性和特异性的一种常用方法。
绘制ROC曲线需要收集一组已知阳性和阴性的样本数据,通过改变分类器的阈值来计算出不同敏感性和特异性条件下的真阳性率和假阳性率,并将这些数据绘制在ROC曲线上。
ROC曲线的形状和位置可以反映出诊断试验的准确性和可靠性。
一般来说,ROC曲线越接近左上角,试验的准确性越高;而曲线越靠近对角线,试验的准确性越低。
在解释ROC曲线时,可以根据需要选择不同的阈值来平衡敏感性和特异性,同时可以根据ROC曲线下面积(AUC)的大小来比较不同试验的准确性。
总之,绘制和解释ROC曲线对于评估和比较不同诊断试验的性能至关重要。
- 1 -。

ROC曲线(受试者工作特征曲线)分析详解一、ROC曲线的概念受试者工作特征曲线(receiver operator characteristic curve, ROC曲线),最初用于评价雷达性能,又称为接收者操作特性曲线。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。
ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。
因此,ROC曲线评价方法适用的范围更为广泛。
二、ROC曲线的主要作用1.ROC曲线能很容易地查出任意界限值时的对疾病的识别能力。
2.选择最佳的诊断界限值。
ROC曲线越靠近左上角,试验的准确性就越高。
最靠近左上角的ROC曲线的点是错误最少的最好阈值,其假阳性和假阴性的总数最少。
3.两种或两种以上不同诊断试验对疾病识别能力的比较。
在对同一种疾病的两种或两种以上诊断方法进行比较时,可将各试验的ROC 曲线绘制到同一坐标中,以直观地鉴别优劣,靠近左上角的ROC曲线所代表的受试者工作最准确。
亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的AUC最大,则哪一种试验的诊断价值最佳。
三、ROC曲线分析的主要步骤1.ROC曲线绘制。
依据专业知识,对疾病组和参照组测定结果进行分析,确定测定值的上下限、组距以及截断点(cut-off point),按选择的组距间隔列出累积频数分布表,分别计算出所有截断点的敏感性、特异性和假阳性率(1-特异性)。
以敏感性为纵坐标代表真阳性率,(1-特异性)为横坐标代表假阳性率,作图绘成ROC曲线。
2.ROC曲线评价统计量计算。
ROC曲线下的面积值在1.0和0.5之间。

ROC曲线受试者工作特征曲线(Receiver Operating Characteristic curve,简称ROC曲线),又称为感受性曲线(Sensitivity curve)。
得此名的原因在于曲线上各点反映着相同的感受性,它们都是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。
接受者操作特性曲线就是以虚报概率为横轴,击中概率为纵轴所组成的坐标图,和被试在特定刺激条件下由于采用不同的判断标准得出的不同结果画出的曲线。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
传统的诊断试验评价方法有一个共同的特点,必须将试验结果分为两类,再进行统计分析。
ROC曲线的评价方法与传统的评价方法不同,无须此限制,而是根据实际情况,允许有中间状态,可以把试验结果划分为多个有序分类,如正常、大致正常、可疑、大致异常和异常五个等级再进行统计分析。
因此,ROC曲线评价方法适用的范围更为广泛。
主要作用1.ROC曲线能很容易地查出任意界限值时的对疾病的识别能力。
2.选择最佳的诊断界限值。
ROC曲线越靠近左上角,试验的准确性就越高。
最靠近左上角的ROC曲线的点是错误最少的最好阈值,其假阳性和假阴性的总数最少。
3.两种或两种以上不同诊断试验对疾病识别能力的比较。
在对同一种疾病的两种或两种以上诊断方法进行比较时,可将各试验的ROC曲线绘制到同一坐标中,以直观地鉴别优劣,靠近左上角的ROC曲线所代表的受试者工作最准确。
亦可通过分别计算各个试验的ROC曲线下的面积(AUC)进行比较,哪一种试验的AUC最大,则哪一种试验的诊断价值最佳。
ROC曲线分析的主要步骤ROC曲线绘制。
依据专业知识,对疾病组和参照组测定结果进行分析,确定测定值的上下限、组距以及截断点(cut-off point),按选择的组距间隔列出累积频数分布表,分别计算出所有截断点的敏感性、特异性和假阳性率(1-特异性)。

如何快速绘制ROC曲线?ROC曲线是一个非常实用的工具。
对于医学研究来说,更是不可缺少。
举个例子。
“ 针对某种疾病,现有A、B两种公认的诊断方法,你的团队研究出新诊断方法C。
自然而然,肯定需要比较A、B、C三种方法,判断到底哪一种对该疾病的诊断更准确?”此时,ROC曲线就派上用场了。
ROC曲线全称receiver operating characteristic curve,又称作感受性曲线(sensitivity curve)。
简单来说,就是曲线上不同的点是对同一信号刺激的反应,只不过是在几种不同的判定标准下所得的结果而已。
按照上面的例子讲。
要达到比较A、B、C三种方法诊断的目的,首先你需要在临床上收病例,对照组和患病组(注意,两组人数可以不一致哦,但不可差太多)。
然后分别用A、B、C三种方法对每一位入组人员进行诊断,在设定准确的截断值后,可以分别得到A、B、C 三种诊断方法对于单个人的敏感度和假阳性率数据。
随后采用这些数据绘制ROC曲线图(横坐标为假阳性率,纵坐标为敏感度)。
通过比较ROC曲线特征和曲线下面积,就可以比较A、B、C三种诊断方法了。
ROC曲线的使用方法大致就是如此,大家可以根据具体情况类推。
ROC曲线的详细解读将放在后面几期中进行。
老规矩,先说怎么绘制单个的ROC曲线图。
(1)打开GraphPad Prism,选择column,然后按如下选择。
(2)以软件自带数据进行示例。
选择data后,再选择Analyze,弹框中选择ROC Curve。
点击OK。
(3)弹框中如下选择,一般默认即可。
置信区间95%,百分比呈现,P值在小数后点4或5位均可。
(4)P值<0.001,说明两组之间有显著差异。
曲线下面积AUC为0.9467。
(5)点击左侧的Graph,选择ROC curve: ROC of data A。
可以看到曲线已经出来了,但是不太美观,下面对其进行美化。
(6)打双击图中的曲线,在弹窗中如下选择。

诊断试验的R OC 曲线一、ROC 曲线的概念在诊断试验中,对诊断指标每一个可能的诊断界值,都能得到一个四格表:诊断试验金标准诊断病人非病人合计+ ab 1m - cd0m合计1n 0nn计算出这些四格表的灵敏度和特异e S 度p S ,以假阳性率p S 1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上作图,所得到的线图称为RO C 曲线(Recei v er Opera t or Chara c teri s tic)。
例如:为了研究肌酸激酶(CK )诊断心肌梗塞的作用,对金标准诊断为心肌梗塞的230例病人和130名正常人分别测定了每个人的C K 值,有如下频数表:CK 值 病人组 正常人组 合计 1~ 2 88 90 40~ 13 26 39 80~ 118 15 133 280~ 97 1 98 合计230130将这4种诊断方法的结果列成下表:诊断界值e Sp Sp S -11 1 0 1 40 0.9913 0.6769 0.3231 80 0.9348 0.8769 0.1231 2800.41270.99230.0077对上表的数据,以假阳性率p S -1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上描点,将点连成曲线,就得到了R O C 曲线:二、ROC 曲线的用途 1.评价指标的诊断能力; 2.确定最佳诊断界值;3.比较两个诊断指标的诊断能力。
三、ROC 曲线评价指标的诊断能力 ROC 曲线下的面积计算(1)参数法如果诊断试验的指标在病人和非病人总体中均服从正态分布,可用参数法估计ROC 曲线下的面积。
设诊断指标x 在非病人总体中服从)(200σμN ,在病人总体中服从)(211σμN 。
如果01μμ>,101)(σμμ-=a ,1σσ=b 如果01μμ<,110)(σμμ-=a ,1σσ=bROC 曲线下的面积为:)1(2b a A +Φ=)(u Φ是标准正态分布曲线下(-∞,u )范围中的面积,可通过《医学统计学》中的附表1查到。

roc曲线绘制方法ROC曲线(Receiver Operating Characteristic Curve)是一种用于评估二分类模型性能的工具。
以下是在Python中使用scikit-learn库绘制ROC 曲线的方法:首先,需要安装scikit-learn库,可以通过pip命令进行安装:```shellpip install scikit-learn```然后,可以使用以下代码绘制ROC曲线:```pythonimport numpy as npimport as pltfrom sklearn import datasetsfrom _selection import train_test_splitfrom _model import LogisticRegressionfrom import roc_curve, auc加载数据集iris = _iris()X =y =将数据集划分为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=, random_state=42)创建逻辑回归模型并进行训练model = LogisticRegression()(X_train, y_train)获取预测概率值和预测标签y_pred_prob = _proba(X_test)[:, 1]y_pred = (X_test)计算ROC曲线所需的值fpr, tpr, thresholds = roc_curve(y_test, y_pred_prob)roc_auc = auc(fpr, tpr)绘制ROC曲线()(fpr, tpr, color='darkorange', lw=2, label='ROC curve (area = %)' % roc_auc)([0, 1], [0, 1], color='navy', lw=2, linestyle='--')([, ])([, ])('False Positive Rate')('True Positive Rate')('Receiver Operating Characteristic Example')(loc="lower right")()```在上述代码中,我们使用了逻辑回归模型进行训练,并使用`predict_proba`方法获取预测概率值。

科研绘图:如何用GraphPadPrism绘制ROC曲线1什么是ROC曲线①基本概念受试者工作特征曲线(receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。
ROC曲线首先是由二战中的电子工程师和雷达工程师发明的,用来侦测战场上的敌军载具(飞机、船舰),也就是信号检测理论,后面广泛应用于医学、无线电、生物学、犯罪心理学领域中,而且最近在机器学习(machine learning)和数据挖掘(data mining)领域也得到了很好的发展。
ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线,反映了敏感性与特异性之间关系。
②理解ROC曲线针对一个二分类问题,我们将实例分成正类/阳性(positive)和负类/阴性(negative)两种。
在实际分类中,会出现四种情况。
如果一个实例是阳性并且也被预测为阳性,即为真阳性(true positive,TP),如果实例为阴性被预测为阳性,称之为假阴性(false negative,FN);相应的,如果实例是阴性被预测为阴性,称之为真阴性(true negative,TN),如果实例为阴性被预测为阳性,称之为假阳性(false positive,FP)。
ROC曲线以假阳性率(False positive rate,FPR)即“1-特异度(1-Specificity)”为横坐标,真阳性率(True positive rate,TPR)即“灵敏度(Sensitivity)”为纵坐标,其中:在ROC曲线中,FPR越大,预测阳性中实际阴性越多,TPR越大,预测阳性类别中实际阳性越多。
理想状态下,TPR应该接近1,FPR应该接近0,因此ROC曲线越靠拢(0,1)点,越偏离45度对角线越好,特异度、灵敏度越大效果越好。
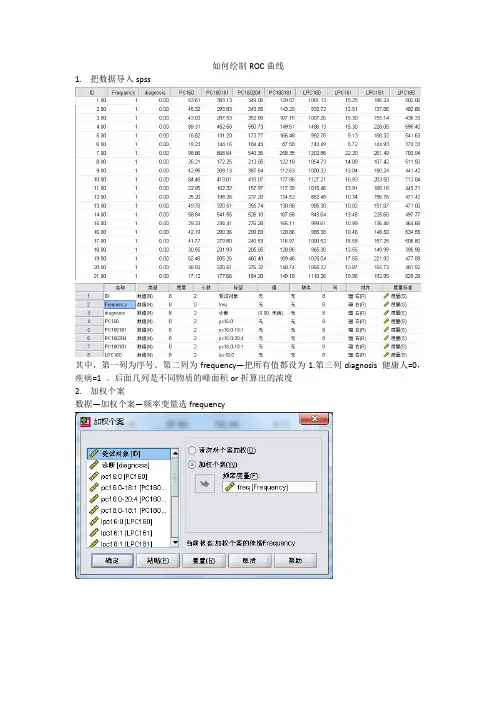
如何绘制ROC曲线
1.把数据导入spss
其中,第一列为序号。
第二列为frequency—把所有值都设为1.第三列diagnosis 健康人=0,疾病=1 。
后面几列是不同物质的峰面积or折算出的浓度
2.加权个案
数据—加权个案—频率变量选frequency
3.分析—回归—二元logistic
因变量选diagnosis,协变量是我们分析的物质(如本例PC160204),选择变量是frequency,点规则=1
点保存,勾选概率,勾选包含协方差矩阵
此时在数据列表中会新出现一列PRE_1
4.ROC 曲线的绘制
分析—ROC曲线图
检验变量为刚刚新生成的列PRE_1(记住,这个代表了之前选定的PC160204)其余保持默认。
即可输出ROC曲线(即PC160204这个物质的ROC曲线)。

一篇搞定ROC曲线图上图是Sci Figure 中的ROC 曲线(receiver operating characteristic curve,简称 ROC 曲线),以真阳性率(灵敏度)为纵坐标,假阳性率(1-特异度)为横坐标绘制的曲线。
横纵坐标可由软件(SPSS、Origin、Graphpad Prism)计算得出,Results 中可得到ROC 曲线下面积等,以比较反映诊断试验的诊断价值。
ROC 曲线如何评价诊断准确性?ROC 曲线下的面积值在 0.5 和 1.0 之间。
在 AUC>0.5 的情况下,AUC 越接近于1,说明诊断效果越好。
AUC 在 0.5~0.7 时有较低准确性,AUC 在 0.7~0.9 时有一定准确性,AUC 在 0.9 以上时有较高准确性。
AUC = 0.5 时,说明诊断方法完全不起作用,无诊断价值。
AUC<0.5>0.5>ROC 曲线优点ROC 曲线分为单指标 ROC 曲线以及多指标 ROC 曲线,SPSS 和Origin 均可以绘制 ROC 曲线,因为 Graphpad Prism 使用非常便捷,在此将使用 Graphpad Prism5.0(Win7, 64 位系统)手把手教你来绘制 ROC 曲线。
单指标 ROC 曲线Step 1 打开Graphpad Prism5.0 软件,选择Column,选择Scatter plot,CreateStep 2 输入数据点击Analyze,选择Column,ROC curve,OK进入ROC 曲线参数设置,分别对应的选定Control values 和Patient values,对于Report results as 有两种表示方法。
Fraction 将坐标表示为0-1,Percentage 将坐标表示为百分数0-100。
New graph 可以选择添加 Line of identity,显示对角线。
专题2:线性判别分析、诊断的敏感度、特异度及ROC曲线的绘制一、判别分析判别分析是利用已知类别的样本建立判别模型,对未知类别的样本判别的一种统计方法。
进行判别分析必须已知观测对象的分类和若干表明观测对象特征的变量值。
判别分析从中筛选出能提供较多信息的变量并建立判别函数,使得利用推导出的判别函数对观测量判别其所属类别时的错判率最小。
判别函数一般形式是:Y = a1X1+a2X2+a3X3...+a n X n其中: Y 为判别分数(判别值);X1,X2,X3:⋯X n 为反映研究对象特征的变量,a1、a2、a3⋯a n 为各变量的系数,也称判别系数。
SPSS 对于分为m类的研究对象,建立m-1个线性判别函数。
对于每个个体进行判别时,把测试的各变量值代入判别函数,得出判别分数,从而确定该个体属于哪一类。
或者计算属于各类的概率,从而判断该个体属于哪—类。
例如:脂肪肝与健康人的判别分析SPSS中的操作:分析——分类——判别,在判别分析对话框中将是否患有脂肪肝选入“分类变量”点击定义范围最小值输入0,最大值输入1。
之后将所有质量数变量选入“自变量”,选择“使用步进方法进入”(根据自变量对判别贡献的大小进行逐步选择)点击“分类”按钮,在输出选择“不考虑该个案的分类”进行互交式检验。
点击“保存”按钮,选择“判别得分”,方可画出ROC曲线。
其他选项默认即可。
输出结果如下:输入的/删除的变量a,b,c,d步骤输入的Wilks 的Lambda统计量精确 F统计量df1 df2 Sig.1 v55 .935 1 1 896.000 62.707 1 896.000 .0002 v59 .898 2 1 896.000 51.005 2 895.000 .0003 v42 .862 3 1 896.000 47.685 3 894.000 .0004 v33 .844 4 1 896.000 41.144 4 893.000 .0005 v89 .827 5 1 896.000 37.440 5 892.000 .0006 v117 .819 6 1 896.000 32.818 6 891.000 .0007 v86 .811 7 1 896.000 29.707 7 890.000 .0008 v112 .806 8 1 896.000 26.819 8 889.000 .0009 v23 .802 9 1 896.000 24.419 9 888.000 .000 在每个步骤中,输入了最小化整体Wilk 的Lambda 的变量。
绘制roc曲线的步骤
绘制ROC曲线的步骤如下:
1.收集分类器输出:首先,需要使用你的分类器对测试数据进行预测,并获得每个样本的预测概率值或分类得分。
这些分数通常表示为样本属于某个类别的可能性。
2.计算TPR和FPR:随着阈值的变化,计算每个阈值下的真阳性率(TPR)和伪阳性率(FPR)。
TPR表示被正确分类为正例的正例样本比例,计算公式为:TPR=TP/(TP+FN),其中TP为真阳性数量,FN为假阴性数量。
FPR表示被错误分类为正例的负例样本比例,计算公式为:FPR=FP/(FP+TN),其中FP为伪阳性数量,TN为真阴性数量。
3.绘制ROC曲线:将每个阈值对应的FPR和TPR值作为坐标点,在坐标系中绘制出这些点。
可以使用Matplotlib等绘图库来完成这个步骤。
4.计算曲线下的面积(AUC):AUC代表ROC曲线下的面积,是评估分类器性能的指标之一。
可以使用Python中的sklearn库等工具来计算AUC。
5.分析结果:根据ROC曲线和AUC值来评估分类器的性能,选择合适的阈值或模型。
需要注意的是,绘制ROC曲线时,不同的阈值会对应不同的FPR和TPR值,因此需要进行多次计算和绘制。
同时,ROC曲线和AUC值只能用于二分类问题,不适用于多分类问题。
诊断试验的ROC 曲线一、ROC 曲线的概念在诊断试验中,对诊断指标每一个可能的诊断界值,都能得到一个四格表:诊断试验金标准诊断病人非病人合计+ ab 1m- cd0m合计1n 0nn计算出这些四格表的灵敏度e S 和特异度p S ,以假阳性率p S 1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上作图,所得到的线图称为ROC 曲线(Receiver Operator Characteristic)。
例如:为了研究肌酸激酶(CK )诊断心肌梗塞的作用,对金标准诊断为心肌梗塞的230例病人和130名正常人分别测定了每个人的CK 值,有如下频数表:CK 值 病人组 正常人组合计 1~ 2 88 90 40~ 13 26 39 80~ 118 15 133 280~ 97 1 98 合计230130将这4种诊断方法的结果列成下表:诊断界值e Sp Sp S -11 1 0 1 40 0.9913 0.6769 0.3231 80 0.9348 0.8769 0.1231 2800.41270.99230.0077对上表的数据,以假阳性率p S -1为横轴,以真阳性率e S 为纵轴,在算术坐标纸上描点,将点连成曲线,就得到了ROC 曲线:二、ROC 曲线的用途 1.评价指标的诊断能力; 2.确定最佳诊断界值;3.比较两个诊断指标的诊断能力。
三、ROC 曲线评价指标的诊断能力 ROC 曲线下的面积计算(1)参数法如果诊断试验的指标在病人和非病人总体中均服从正态分布,可用参数法估计ROC 曲线下的面积。
设诊断指标x 在非病人总体中服从)(200σμN ,在病人总体中服从)(211σμN 。
如果01μμ>,101)(σμμ-=a ,10σσ=b 如果01μμ<,110)(σμμ-=a ,1σσ=bROC 曲线下的面积为:)1(2b a A +Φ=)(u Φ是标准正态分布曲线下(-∞,u )范围中的面积,可通过《医学统计学》中的附表1查到。
roc曲线的绘制方法宝子,今天咱来唠唠ROC曲线的绘制方法哈。
ROC曲线全名叫受试者工作特征曲线(Receiver Operating Characteristic Curve),这名字听起来是不是有点高大上?其实画起来也没那么难啦。
咱得先有一些数据哦。
通常呢,是要有模型预测出来的结果,比如说每个样本属于正类的概率值,还有这些样本实际的类别(是正类还是负类)。
那开始画的时候呀,我们要先确定横纵坐标。
横坐标是假阳性率(False Positive Rate,FPR),这个咋算呢?就是把负类样本中被错误预测为正类的样本数除以负类样本总数。
纵坐标呢,是真阳性率(True Positive Rate,TPR),它就是正类样本中被正确预测为正类的样本数除以正类样本总数。
然后呢,我们要按照一定的规则来计算不同阈值下的FPR和TPR的值。
这个阈值就是我们用来判定样本是正类还是负类的那个界限。
比如说,我们把预测概率大于0.5的判定为正类,那0.5就是一个阈值。
我们要不断地改变这个阈值,从最小到最大,然后计算出每一个阈值对应的FPR和TPR。
接下来就可以在坐标平面上开始描点啦。
把每个阈值对应的(FPR,TPR)坐标点都画出来。
等把所有的点都画好之后呢,再把这些点按照顺序连接起来,一条弯弯的ROC曲线就出来啦。
宝子你可能会问,这曲线有啥用呢?嘿它可有用啦。
可以用来评估分类模型的好坏哦。
如果曲线越靠近左上角,就说明模型的性能越好。
要是曲线是一条从左下角到右上角的对角线,那就说明这个模型是瞎猜的,没有啥区分能力。
还有哦,如果我们想定量地比较不同模型的好坏,可以计算ROC曲线下的面积(Area Under the Curve,AUC)。
AUC的值越大,模型就越厉害。
宝子,你看,ROC曲线绘制也不是啥特别难搞的事儿吧。
只要把数据准备好,按照步骤来,很容易就能画出这个有趣的曲线啦。
。
ROC曲线的绘制假设现在有⼀个⼆分类问题,先引⼊两个概念:真正例率(TPR):正例中预测为正例的⽐例假正例率(FPR):反例中预测为正例的⽐例再假设样本数为6,现在有⼀个分类器1,它对样本的分类结果如下表(按预测值从⼤到⼩排序)ROC曲线的横轴为假正例率,纵轴为真正例率,范围都是[0,1],现在我们开始画图——根据从⼤到⼩遍历预测值,把当前的预测值当做阈值,计算FPR和TPR。
step1:选择阈值最⼤,即为1,正例中和反例中都没有预测值⼤于等于1的,所以FPR=TPR=0。
step2:根据上表,选择阈值为0.9,正例中有1个样本的预测值⼤于等于1,反例中有0个,所以,TPR=1/3,FPR=0。
step3:根据上表,选择阈值为0.8,正例中有2个样本的预测值⼤于等于1,反例中有0个,所以,TPR=2/3,FPR=0。
step4:根据上表,选择阈值为0.7,正例中有3个样本的预测值⼤于等于1,反例中有0个,所以,TPR=1,FPR=0。
step5:根据上表,选择阈值为0.3,正例中有3个样本的预测值⼤于等于1,反例中有1个,所以,TPR=1,FPR=1/3。
step6:根据上表,选择阈值为0.2,正例中有3个样本的预测值⼤于等于1,反例中有2个,所以,TPR=1,FPR=2/3。
step7:根据上表,选择阈值为0.1,正例中有3个样本的预测值⼤于等于1,反例中有3个,所以,TPR=1,FPR=1。
综上,我们得到下表:描点连线,画出的图是下⾯这样什⼉的可以看出这个分类器还是很理想的。
假设现在⼜有⼀个分类器2,对同样⼀组样本,分类结果如下根据上⾯描述的⽅法,画出ROC曲线如下发现这个曲线的左上⾓⽐之前往右下⾓凹了⼀点。
emmmm,现在⼜来了⼀个分类器3,对同样⼀组样本,分类结果如下不多说,直接画图——哎?这个曲线⽐之前更“凹”了。
实际上,不⽤画出曲线,只是根据这3个分类器的分类结果,我们也能⼤概能分析出它们的性能:分类器1>分类器2>分类器3。
roc曲线绘制 r语言ROC(Receiver Operating Characteristic)曲线是一种广泛应用于评估分类模型性能的方法。
该曲线以分类模型的真阳性率(TPR)为纵坐标,假阳性率(FPR)为横坐标绘制而成。
在绘制ROC曲线之前,我们需要理解TPR和FPR的概念。
TPR代表分类模型正确预测为阳性样本的比例,即预测为阳性且实际为阳性的样本数量占所有实际阳性样本数量的比例。
FPR则代表分类模型错误预测为阳性样本的比例,即预测为阳性但实际为阴性的样本数量占所有实际阴性样本数量的比例。
绘制ROC曲线的步骤如下:1.首先,我们需要一个已训练好的分类模型用于预测概率值或者类别信息。
这里以二分类问题为例,我们假设已经有了一个模型,可以预测样本属于阳性类别的概率。
2.接下来,我们需要定义不同的阈值(threshold)来将概率转化为类别预测结果。
比如,当概率大于等于0.5时,我们将样本预测为阳性类别,否则预测为阴性类别。
3.在设定不同阈值的情况下,我们可以计算模型的TPR和FPR。
具体计算方法如下:-设定一个阈值-根据设定的阈值将模型的预测概率转化为类别标签-计算TPR和FPR4.在不同阈值情况下,我们得到一组TPR和FPR的值。
我们可以按照FPR的升序对这些值进行排序。
5.在排序后的TPR和FPR值上插入两个额外的点,即(0,0)和(1,1),分别代表FPR和TPR的最小和最大值。
6.最后,我们按照排序后的TPR和FPR值的顺序,依次连接这些点以绘制ROC曲线。
在R语言中,可以利用pROC包绘制ROC曲线。
以下是一个示例代码:```R#安装pROC包(如果未安装)# install.packages("pROC")#导入pROC包library(pROC)#假设已经有了分类模型的预测概率值和实际的类别标签predicted_prob <- c(0.2, 0.5, 0.8, 0.3, 0.7) #分类模型的预测概率值actual_label <- c(0, 1, 1, 0, 1) #实际的类别标签#计算ROC曲线的数据roc_data <- roc(actual_label, predicted_prob)#绘制ROC曲线plot(roc_data, main = "ROC曲线", xlab = "False Positive Rate", ylab = "True Positive Rate")#添加对角线lines(x = c(0, 1), y = c(0, 1), col = "gray")#添加参考线abline(h = seq(0, 1, 0.1), v = seq(0, 1, 0.1), col = "lightgray", lty = 2)#添加曲线标签text(0.5, 0.5, paste0("AUC = ", round(auc(roc_data), 2))) #添加图例legend("bottomright", legend = c("ROC曲线"), col = "black", lty = 1, bty = "n")```以上代码首先安装并导入pROC包,然后给出了一个示例数据集的预测概率值和实际类别标签。
专题2:线性判别分析、诊断的敏感度、特异度及ROC曲线的绘制
一、判别分析
判别分析是利用已知类别的样本建立判别模型,对未知类别的样本判别的一种统计方法。
进行判别分析必须已知观测对象的分类和若干表明观测对象特征的变量值。
判别分析从中筛选出能提供较多信息的变量并建立判别函数,使得利用推导出的判别函数对观测量判别其所属类别时的错判率最小。
判别函数一般形式是:Y = a1X1+a2X2+a3X3...+a n X n
其中: Y 为判别分数(判别值);X1,X2,X3:⋯X n 为反映研究对象特征的变量,a1、a2、
a3⋯a n 为各变量的系数,也称判别系数。
SPSS 对于分为m类的研究对象,建立m-1个线性判别函数。
对于每个个体进行判别时,把测试的各变量值代入判别函数,得出判别分数,从而确定该个体属于哪一类。
或者计算属于各类的概率,从而判断该个体属于哪—类。
例如:脂肪肝与健康人的判别分析
SPSS中的操作:分析——分类——判别,在判别分析对话框中将是否患有脂肪肝选入“分类变量”点击定义范围最小值输入0,最大值输入1。
之后将所有质量数变量选入“自变量”,选择“使用步进方法进入”(根据自变量对判别贡献的大小进行逐步选择)点击“分类”按钮,在输出选择“不考虑该个案的分类”进行互交式检验。
点击“保存”按钮,选择“判别得分”,方可画出ROC曲线。
其他选项默认即可。
输出结果如下:
输入的/删除的变量a,b,c,d
步骤
输入的Wilks 的Lambda
统计量
精确 F
统计量df1 df2 Sig.
1 v55 .935 1 1 896.000 62.707 1 896.000 .000
2 v59 .898 2 1 896.000 51.005 2 895.000 .000
3 v42 .862 3 1 896.000 47.685 3 894.000 .000
4 v33 .844 4 1 896.000 41.144 4 893.000 .000
5 v89 .827 5 1 896.000 37.440 5 892.000 .000
6 v11
7 .819 6 1 896.000 32.81
8 6 891.000 .000
7 v86 .811 7 1 896.000 29.707 7 890.000 .000
8 v112 .806 8 1 896.000 26.819 8 889.000 .000
9 v23 .802 9 1 896.000 24.419 9 888.000 .000 在每个步骤中,输入了最小化整体Wilk 的Lambda 的变量。
a. 步骤的最大数目是200。
b. 要输入的最小偏F 是3.84。
c. 要删除的最大偏F 是2.71。
d. F 级、容差或VIN 不足以进行进一步计算。
标准化的典型判别式函数系数
函数
1
v23 .159
v33 -.359
v42 .439
v55 .601
v59 -.474
v86 .227
v89 .314
v112 -.185
v117 .230
分类结果b,c
是否患有脂肪肝预测组成员
0 1
合计
初始计数0 306 119 425
1 170 303 473
% 0 72.0 28.0 100.0
1 35.9 64.1 100.0 交叉验证a计数0 304 121 425
1 174 299 473
% 0 71.5 28.5 100.0
1 36.8 63.
2 100.0
a. 仅对分析中的案例进行交叉验证。
在交叉验证中,每个案例都是按照从该案例以外的所有其他案例派生的函数来分类的。
b. 已对初始分组案例中的 67.8% 个进行了正确分类。
c. 已对交叉验证分组案例中的 67.1% 个进行了正确分类。
二、敏感度与特异度
敏感度和特异度是用来说明诊断性试验准确性的两个常用指标。
诊断性试验的敏感度越高,漏诊率越低。
特异性高的诊断性试验的阳性结果对诊断更有意义。
特异度越高,误诊的比例越低。
敏感度(sensitivity)又称真阳性率,即实际有病而按该筛检实验的标准被正确判断为有病的百分比。
它反映筛检实验发现病人的能力。
特异度(specificity)又称真阴性率,即实际无病按该诊断标准被正确地判断为无病的百分比。
它反映筛检实验确定非病人的能力。
阳性预测值(Positive Predictive Value,PPV)指筛检实验阳性者不患目标疾病的可能性。
阴性预测值(Negative Predictive Value,NPV)指筛检实验阴性者患目标疾病的可能性。
预测
1 0 合计
实际 1 True Positive(TP) False Negative(FN) Actual Positive(TP+FN)
0 Fasle Positive(FP) True Negative(TN) Actual Negative(FP+TN) 合计Predicted Positive(TP+FP) Predicted Negative (FN+TN) TP+FP+FN+TN
呼气测试结果
脂肪肝健康合计
B超结果脂肪肝331 142 473 Sensitivity=TP/(TP+FN)
=70%
健康100 325 425 Specificity=TN/(FP+TN)
=76%
合计431 467 898
PPV=TP/(TP+FP)
=77%
NPV=TN/(FN+TN)
=70%
以上结果来自于线性判别分析
三、ROC曲线
ROC曲线指受试者工作特征曲线(receiver operating characteristic curve), 是反映敏感性和特异性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性,再以敏感性为纵坐标、(1-特异性)为横坐标绘制成曲线,曲线下面积越大,诊断准确性越高。
在ROC 曲线上,最靠近坐标图左上方的点为敏感性和特异性均较高的临界值。
Youden指数则为灵敏度与特异度两者之和减一。
AUC(Area under the curv)曲线下方的面积,AUC的值就是处于ROC curve下方的那部分面积的大小。
ROC曲线的做法
SPSS中:分析——ROC曲线图——将判别得分选入检验变量,后将“是否患有脂肪肝”作为状态变量,将状态值选为1.其他默认即可。
输出结果如下
曲线下的面积
检验结果变量:用于分析 1 的来自函数 1 的判别得分
面积
.762
检验结果变量:用于分析 1 的来自函数 1 的判别得分在正的和负的实际状态组之间至少有一个结。
统计量可能会出现偏差。