AscII码字模提取方法
- 格式:docx
- 大小:392.89 KB
- 文档页数:3

汉字字模存储和提取的方法
汉字字模的存储和提取是汉字信息处理系统中的重要环节,常用的方法有以下几种:
1. 存储在程序存储器中:这是在程序不大或单片机无外部扩展数据存储区功能的情况下使用的方法。
2. 通过外扩的EEPROM存储汉字字模数据:采用哈佛结构的单片机,如8051单片机及其派生产品,程序存储器(ROM)和数据存储器(RAM)可分别寻址。
将提取的汉字字模数据存放在EPROM或EEPROM内,并设定该芯片的片选地址,只要知道某个汉字字模数据在该芯片的存储位置,通过程序计算出偏移地址,即可实现显示功能。
3. 使用外扩的EEPROM存储整个汉字库:某些高端单片机,如Motorola 的M68300系列32位单片机,寻址范围可达8M。
以上信息仅供参考,如有需要,建议查阅计算机科学和电子工程相关书籍或咨询专业人士。

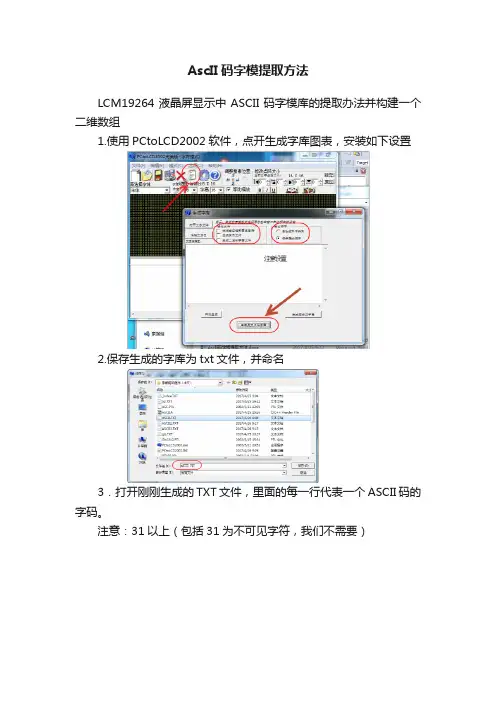
AscII码字模提取方法
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii 码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。

1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 1 1 2 2 3 3 4 4 5 5 6 6 7 7 88逐列式:0x00,0x10,0x04,0x10,0x04,0x90,0xF4,0x5F, 0x54,0x35,0x54,0x15,0x54,0x15,0x5F,0x15, 0x54,0x15,0x54,0x15,0x54,0x35,0xF4,0x5F,0x04,0x90,0x04,0x10,0x00,0x10,0x00,0x00,/*"真",1*/ 逐行式:0x80,0x00,0x80,0x00,0xFE,0x3F ,0x80,0x00, 0xF8,0x0F,0x08,0x08,0xF8,0x0F,0x08,0x08, 0xF8,0x0F,0x08,0x08,0xF8,0x0F ,0x08,0x08,0xFF,0x7F,0x10,0x04,0x08,0x08,0x04,0x10,/*"真",0*/ /* (16 X 16 , 宋体 )*/字模中每一点使用一个二进制位(Bit)表示 字模提取有两种排列方式:逐列式、逐行式 逐列式:即从左端起,每列开头第1个点最后一个点。
逐行式:即从第1列起,每行第1个点到最后一个点。
两种取码方式:阴码、阳码 阴码:亮为1,灭为0 阳码:亮为0,灭为1下面以16*16点阵取“真”字为例,有逐列式和逐行式两段程序,且都为阴码。
程序中是十六进制,在字模提取时转换为二进制,逐列式:从第1列开始,每列16位,且从低位到高位,需2个十六进制数,如第列:0x00,0x10,转二进制:0000 0000;0001 000;对应方格中相应的位。
依次类推24*24点阵取模方法。


我们知道英文字母数量比较少,我们只要用一个字节(8位)就足以表达。
但是汉字非常多。
要怎么表达呢?前人采用的一个方法就是把ASCII码的高128位作为汉字的内码,低128位仍然作为英文字母的内码,然后用两个字节来表示一个汉字。
通过这个内码,我们可以获取汉字的字模信息。
然后再根据这些字模的信息,把相应的汉字显示出来。
二、什么是汉字字库?如何寻址?点阵字库其实就是按照汉字内码的顺序,把汉字的字模信息存起来。
16×16的点阵字库有94区,每个区有94个汉字的字模。
这样总的有94×94个汉字。
我们之前说了,一个汉字由两个ASCII扩展码构成。
第一个ASCII扩展码用来存放汉字的区码,第二个ASCII扩展码用来存放汉字的位码。
具体是这样的:第一个扩展ASCII码= 128 + 汉字的区码第二个扩展ASCII码= 128 +汉字的位码这样,如果我们用char HZ[2]来表示一个汉字。
则:区码= HZ[0] - 128位码= HZ[1] - 128这样,算出区位码之后,我们就可以用它在汉字库里面寻址找字模了。
具体的方式是:该汉字的偏移地址 = (区码-1)×94×一个字占用的字节数+位码×一个字占用的字节数这样我们就很容易的写出显示汉字字模的函数:INT8U *HZK = (INT8U *)0x801c0000; /* 汉字字库的存储地址*/INT8U *ASCII = (INT8U *)0x801fba00; /* ASCII码字库的存储地址 */INT8U const cmp_w[8]={128,64,32,16,8,4,2,1};/********************************************************************************** ************************* Function : DisplayHZ()** Description: 该函数用于在F DGK/GUI上显示一个汉字。

汇编语言获得汉字内码的方法汇编语言是一种低级语言,它可以直接操作计算机的硬件。
在汇编语言中,我们可以通过一些方法来获得汉字的内码。
本文将介绍一些常用的方法,以帮助读者更好地理解汇编语言中获得汉字内码的过程。
一、ASCII码ASCII码是一种常见的字符编码方式,其中包含了大量的字符,包括英文字母、数字和一些特殊符号。
在ASCII码表中,每个字符都对应着一个唯一的数字,即该字符的内码。
汉字在ASCII码中是没有对应的内码的,因此不能直接使用ASCII码来表示汉字的内码。
二、GB2312编码GB2312编码是汉字的一种常用编码方式,其中包含了大约7000多个常用汉字。
在GB2312编码中,每个汉字由两个字节表示,其中每个字节的范围均是0xA1~0xFE。
因此,我们可以通过查表的方式,将汉字转换为对应的GB2312编码。
三、Unicode编码Unicode编码是一种全球通用的字符编码方式,它包含了几乎所有的字符,包括汉字在内。
Unicode编码使用16位或32位的二进制数来表示一个字符,其中包含了汉字的内码。
在汇编语言中,我们可以通过将Unicode编码转换为对应的二进制数,来获得汉字的内码。
四、汉字库在一些汇编语言的开发工具中,会提供一些汉字库,其中包含了大量的汉字及其对应的内码。
通过使用这些汉字库,我们可以直接获得汉字的内码,而无需进行其他的转换操作。
五、自定义表除了使用已有的编码方式和汉字库外,我们还可以自己创建一张汉字与内码的对应表。
在这个表中,我们可以将每个汉字与一个唯一的内码进行对应。
通过使用这个自定义表,我们可以直接根据汉字来获取其对应的内码。
总结:获得汉字内码的方法有很多种,常用的包括使用ASCII码、GB2312编码、Unicode编码、汉字库和自定义表。
通过这些方法,我们可以将汇编语言与汉字进行有效的结合,实现对汉字的处理和展示。
无论是在汇编语言的开发中,还是在其他相关领域中,了解汉字的内码获取方法都是非常重要的。

ascii码的运算方法嘿,朋友们!今天咱来聊聊 ASCII 码的运算方法。
这玩意儿啊,就像是计算机世界里的密码本,可神奇啦!你想想看,计算机它可不认识咱平时说的那些字啊、符号啊,它就靠这 ASCII 码来理解和处理信息呢。
那 ASCII 码的运算方法是咋回事呢?咱就打个比方吧,这 ASCII 码就好比是每个字符的独特编号。
比如说字母 A,它在 ASCII 码里就有自己特定的数值。
那如果我们要对这些字符进行运算呢,不就像是在摆弄这些编号嘛。
比如说,我们要比较两个字符谁大谁小,这时候不就是比较它们对应的 ASCII 码数值嘛。
那要是想把一个字符变成另一个字符呢,说不定就得通过改变它的 ASCII 码数值来实现呀。
哎呀,你说这计算机的世界是不是挺奇妙的?就这么一串数字,就能代表那么多的字符和信息。
那怎么来进行具体的运算呢?比如说加法,咱给一个字符的 ASCII 码加上一个数值,会得到什么呢?会不会就变成另一个字符啦?或者是做减法呢,又会有啥不一样的结果。
其实啊,这里面的门道可多了去了。
我们可以通过一些编程语句或者特定的工具来对ASCII 码进行运算操作。
就像是我们有了一把钥匙,可以打开计算机字符世界的大门。
你再想想,要是我们能熟练掌握 ASCII 码的运算方法,那我们不就能在计算机的世界里自由驰骋啦?想让它显示什么字符,就通过运算来搞定。
是不是感觉特别酷?而且啊,这可不仅仅是好玩哦,在很多实际的应用中都非常有用呢。
比如在数据处理、加密解密等方面,ASCII 码的运算都能发挥大作用呢。
所以啊,朋友们,可别小瞧了这 ASCII 码的运算方法。
它就像是隐藏在计算机世界里的魔法,等着我们去探索和发现呢!好好去研究研究它,说不定能给你带来意想不到的惊喜和收获呢!咱可不能错过这么有趣又有用的东西呀,对吧?。

字符取模原理字符取模原理解析什么是字符取模字符取模是一种常见的编程技巧,用于判断字符串中某个字符在另一个字符集合中是否存在。
利用字符取模可以快速判断某个字符是否包含在一个字符串中,以及计算出字符在字符串中的位置。
字符取模的原理字符取模的原理基于ASCII码表,每个字符都对应一个唯一的ASCII码,范围从0到127。
通过将字符串中的字符与字符集合进行比较,可以根据字符的ASCII码判断字符是否存在于字符集合中。
字符取模的步骤1.将字符串和字符集合转换为ASCII码形式。
2.遍历字符串中的每个字符,并获取字符的ASCII码。
3.检查字符ASCII码是否包含在字符集合的ASCII码范围内。
4.如果包含,则表示字符存在于字符集合中;否则,表示字符不存在于字符集合中。
字符取模的示例以下是一个使用字符取模技巧判断字符串中是否包含某个字符的示例代码:def is_character_exists(string, character):# 获取字符集合的ASCII码character_set = set(ord(c) for c in string)# 获取字符的ASCII码char_ascii = ord(character)# 判断字符是否存在于字符集合中if char_ascii in character_set:return Trueelse:return False字符取模的优势和适用场景字符取模是一种高效的算法,可以快速判断一个字符是否存在于字符串中。
相比于遍历字符串逐个比较字符的方法,字符取模可以大大提高执行效率。
字符取模适用于以下场景: - 判断字符串中是否包含某个特定的字符。
- 在字符串中查找某个字符并获取其位置。
- 对字符串中的字符进行去重操作。
总结字符取模是一种利用字符的ASCII码进行快速判断字符是否存在于字符串中的编程技巧。
它遵循将字符串和字符集合转换为ASCII码,通过比较字符的ASCII码范围来判断字符是否存在的原理。

提取一串字符串中的数字和字母是在日常生活和工作中经常会遇到的需求,尤其在数据处理、文本处理、编程等领域中,提取数字和字母是一项基本且重要的操作。
为了方便快捷地实现这一目标,我们可以借助一些快捷键和工具来提高工作效率。
在文本编辑器中,我们经常需要从一串字符串中提取数字和字母。
以下是一些常见的快捷键和技巧:1. 使用Ctrl + F快捷键进行查找和替换操作。
在大部分文本编辑器中,Ctrl + F可以打开查找和替换功能,我们可以在查找框中输入正则表达式来匹配数字和字母,然后通过替换功能将其提取出来。
我们可以使用\d来匹配数字,使用\w来匹配字母,在替换框中输入$1可以提取出匹配的内容。
2. 使用正则表达式进行提取。
正则表达式是一种强大的文本匹配工具,我们可以通过编写简单的正则表达式来实现对数字和字母的提取。
使用\d+可以匹配一个或多个数字,使用\w+可以匹配一个或多个字母。
3. 使用专业的文本处理工具进行提取。
除了文本编辑器外,还有许多专业的文本处理工具可以帮助我们快速提取数字和字母。
Sublime Text、Notepad++、Visual Studio Code等工具提供了丰富的文本处理功能,可以通过快捷键或插件来实现快速提取数字和字母。
在编程领域,提取数字和字母同样是一项常见的操作。
以下是一些常见的快捷键和技巧:1. 使用正则表达式进行匹配和提取。
在编程中,我们经常会使用正则表达式来进行文本匹配和提取操作。
许多编程语言都提供了对正则表达式的支持,我们可以通过编写简单的正则表达式来实现对数字和字母的提取。
2. 使用字符串处理函数进行提取。
许多编程语言提供了丰富的字符串处理函数,包括对字符串的查找、替换、分割等操作。
我们可以通过调用这些函数来实现对数字和字母的提取。
除了常见的快捷键和技巧外,我们还可以借助一些工具来实现快速提取数字和字母。
以下是一些常见的工具和库:1. 使用Python中的re库进行正则表达式匹配。

5.7点阵字模生成原理与方法[3]5.7.1 字模生成原理本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。
汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。
字模提取及基于Proteus的串行通信仿真李现国1*,苗长云1,袁臣虎1,张艳2(1天津工业大学,天津,300160)(2 天津城市建设学院,天津,300384)摘要:采用扫描VB图片框的方法提取字模,并利用VB、Proteus和Keil软件联合仿真了上位机和51单片机的串行通信。
实现了任意字体、16×16到64×64不同点阵格式的字模的提取,软件仿真可以全面的观察出上位机字模数据的传送以及单片机对于数据的接收及存储情况,为单片机应用开发提供了一种新的方法和手段。
关键词:字模提取;串行通信;VB;Proteus;联合仿真;中图分类号:Tp312 文献标识码:BDot-matrix Abstraction and the Proteus Simulation of SerialCommunicationXianguo-Li1, Changyun-Miao1,Chenhu-Yuan1,Yan-Zhang2(1 Tianjin Polytechnic University, Tianjin City, China, 300160)(2 Tianjin Institute of Urban Construction, Tianjin City, China, 300384)Abstract:Dot–matrices were abstracted in the way of scanning the PictureBox of the VB software, and the serial communication was simulated by the VB associated with the Proteus and Keil. The use of scanning the PictureBox of the VB can not only obtain multiple font but also provide the dot matrix of multiple matrices from 16×16 to 64×64, and the state of data transmitted to the single chip compute can be observed conveniently by the software simulation. It is more flexible and scalable than hardware simulation, and this provides a new way to the single chip computer application and exploitation.Keywords: Dot-matrix Abstraction; Serial Communication; VB; Proteus; Associated Simulation;1.引言在当前的工业生产及商业开发等许多领域,越来越多的需要用点阵来显示汉字。
8*8ASCII码点阵软字库的获取
唐龙;蒋东方
【期刊名称】《软件世界》
【年(卷),期】1996(000)005
【摘要】在制作大屏幕LED显示屏配套软件的过程中,肯定要用到字母、数字等符号,这就要求设计者想法获得ASCII码点阵字库。
对单行条屏,8*8点阵的ASCII码字库是一个恰当的选择。
笔者在软件开发中先后用两种方法获得了这种字库,方法有一定代表性。
第一种方法将显示卡初始化为CGA 640*200图形模式,此时显示屏背景色为黑色(0值),显示字符为白色(1值)。
在显示屏某位置输出一字符,然后从左到右,从上到下逐点读取8*8共64个像素点,每8个点组成一个字节,用一无符号字符型变量装配起来。
【总页数】2页(P27-28)
【作者】唐龙;蒋东方
【作者单位】不详;不详
【正文语种】中文
【中图分类】TP311.52
【相关文献】
1.基于点阵结构光获取物体点云的摄影测量方法 [J], 叶子伟;陈志
2.BMP 图像点阵数据获取方法探讨 [J], 左继怀;杨东昌
3.BMP图像点阵数据获取方法探讨 [J], 左继怀;杨东昌;
4.基于光点阵列的三维表面数据获取技术及实现 [J], 刘晖;胡平;李华
5.从矢量字库中获取近似汉字点阵 [J], 严健武
因版权原因,仅展示原文概要,查看原文内容请购买。
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。