汉字字模提取技术
- 格式:pdf
- 大小:158.48 KB
- 文档页数:2


汉字字模存储和提取的方法
汉字字模的存储和提取是汉字信息处理系统中的重要环节,常用的方法有以下几种:
1. 存储在程序存储器中:这是在程序不大或单片机无外部扩展数据存储区功能的情况下使用的方法。
2. 通过外扩的EEPROM存储汉字字模数据:采用哈佛结构的单片机,如8051单片机及其派生产品,程序存储器(ROM)和数据存储器(RAM)可分别寻址。
将提取的汉字字模数据存放在EPROM或EEPROM内,并设定该芯片的片选地址,只要知道某个汉字字模数据在该芯片的存储位置,通过程序计算出偏移地址,即可实现显示功能。
3. 使用外扩的EEPROM存储整个汉字库:某些高端单片机,如Motorola 的M68300系列32位单片机,寻址范围可达8M。
以上信息仅供参考,如有需要,建议查阅计算机科学和电子工程相关书籍或咨询专业人士。

基于Labview的汉字点阵字模提取目录0前言 (2)1总体设计方案 (2)2软件设计2.1输入汉字个数符合要求跳出对话框设计 (4)2.2获取首字节位置设计 (4)2.3从HZK16中提取汉字字模的设计 (4)2.4前面板LE显示汉字的设计 (4)2.5前面板十六进制汉字字模 (5)3程序调试 (5)4参考文献 (7)5课设体会 (8)基于labview的汉字点阵字模提取苑庆爽沈阳航空航天大学自动化学院摘要:介绍了汉字字符的存储结构、编码方案和显示方式;并利用LabVIEW软件灵活、简便地从计算机的汉字库中提取汉字字模并转换为供单片机直接调用的十六进制字模数据.关键词:LabVIEW; 点阵字模; 文件I/ O0.前言LabVIEW(Laboratory Virtual Inst rument s En2gineering Workbench)是美国国家仪器公司创新软件产品,也是目前应用最广、发展最快、功能最强的图形化软件开发集成环境.使用这种语言编程时 ,基本不需要编写程序代码 ,而是“绘制”程序流程图.它提供了函数库和高级分析子VI ,用户只需调出对应的操作、功能、数据处理的节点,配置相关参数 ,连接好程序框图 ,就可完成相应的程序在虚拟仪器系统中,信号的获取与采集由以计算机为核心的硬件平台来完成,在这一平台上,调用不同功能的软件可构成不同功能的虚拟仪器,软件是根据不同的信号分析与处理技术编制的。
时至今日,信号的分析与处理方法很多,在设计虚拟仪器时,需要根据仪器的功能要求和所处理信号的实际情况选择合适的分析和处理方法。
在显示技术日益发展的今天,汉字点阵文件显示技术已经成熟,但是在单片机控制的标语指示、车站机场车次航线显示、银行汇率显示等系统中,使用汉字字库芯片并不经济.因此,可以利用计算机的汉字库文件,直接调用汉字库文件,然后提取字符字模,节约了硬件开支. LabVIEW 中功能强大的文件 I/ O 函数可以方便地提取二进制文件中指定起始位置、指定字节数的数据,并且其丰富的前面板资源可以形象逼真的显示提取的字符 ,特别适合汉字点阵字模提取程序的编写。




浅谈汉字特征字母及其提取规那么所谓特征字母,是指那些最能表征汉字轮廓特点的汉字字母。
人们看到一个汉字时,一般首先注意到的是它的轮廓特征,然后才是它的局部细节。
这就是汉字的认知规律。
从图形识别的角度来看,汉字认知更加注重轮廓性和整体性,字形的细微变化并不会给汉字认知造成多大影响。
因此,特征字母一定是构成汉字轮廓的汉字字母。
研究发现:人们通常是从汉字左上角开始,沿着顺时针方向扫描汉字轮廓的〔见以下列图〕。
因此,最能表征汉字轮廓特点的特征字母,首先是构成汉字左上角的汉字字母,其次是构成汉字右上角的汉字字母,再次是构成汉字右下角的汉字字母,最后是构成汉字左下角的汉字字母。
对于左右构造的汉字来说:左上角特征字母通常就是字首首字母〔第一个字母〕;右上角特征字母通常就是字身首字母;右下角特征字母通常就是字身末字母〔最后一个字母〕;左下角特征字母通常就是字首末字母〔见以下列图〕。
因此,左右构造汉字的特征字母依次是字首首字母、字身首字母、字身末字母和字首末字母。
对于上下构造的汉字来说:左上角特征字母通常就是字首首字母;右下角特征字母通常就是字身末字母;右上角特征字母有时是字首首字母〔如“京〞字〕,有时是字首末字母〔如“简〞字〕,有时是中间字母〔如“雪〞字〕,难以确定;左下角特征字母有时是字身首字母〔如“苡〞字〕,有时是字身末字母〔如“全〞字〕,有时是中间字母〔如“罢〞字〕,同样难以确定。
对于多数上下构造的汉字来说,人们通过一次扫描还无法辨识出汉字,还要进展第二次扫描,即扫描字身左上角和右上角,扫描的角度较第一次要小些。
字身左上角特征字母通常就是字首首字母,而字身右上角特征字母的位置那么难以确定〔见以下列图〕。
因此,上下构造汉字的特征字母依次是字首首字母,字身末字母和字身首字母。
正因为上下构造汉字的辨识需要进展两次扫描,所以,人们辨识上下构造汉字所花费的时间要比辨识左右构造汉字要多些;正因为上下构造汉字的特征字母为3个,比左右构造汉字的特征字母数量少1个,所以,人们对上下构造汉字辨识的错误率比上下构造汉字要高些。


5.7点阵字模生成原理与方法[3]5.7.1 字模生成原理本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。
汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。
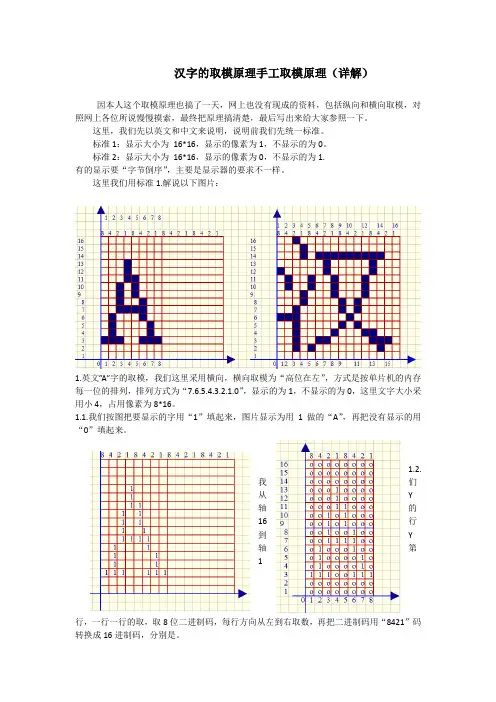
汉字的取模原理手工取模原理(详解)因本人这个取模原理也搞了一天,网上也没有现成的资料,包括纵向和横向取模,对照网上各位所说慢慢摸索,最终把原理搞清楚,最后写出来给大家参照一下。
这里,我们先以英文和中文来说明,说明前我们先统一标准。
标准1:显示大小为16*16,显示的像素为1,不显示的为0。
标准2:显示大小为16*16,显示的像素为0,不显示的为1.有的显示要“字节倒序”,主要是显示器的要求不一样。
这里我们用标准1.解说以下图片:1.英文”A”字的取模,我们这里采用横向,横向取模为“高位在左”,方式是按单片机的内存每一位的排列,排列方式为“7.6.5.4.3.2.1.0”,显示的为1,不显示的为0,这里文字大小采用小4,占用像素为8*16。
1.1.我们按图把要显示的字用“1”填起来,图片显示为用1做的“A”,再把没有显示的用“0”填起来。
1.2.我们从Y轴的16行到Y轴第1行,一行一行的取,取8位二进制码,每行方向从左到右取数,再把二进制码用“8421”码转换成16进制码,分别是。
二进制汇编十六进制C语言十六进制Y轴第16行00000000B 00H 0X00Y轴第15行00000000B 00H 0X00Y轴第14行00000000B 00H 0X00Y轴第13行00010000B 10H 0X10Y轴第12行00010000B 10H 0X10Y轴第11行00011000B 18H 0X18Y轴第10行00101000B 28H 0X28Y轴第9行00101000B 28H 0X28Y轴第8行00100100B 24H 0X24Y轴第7行00111100B 3CH 0X3CY轴第6行01000100B 44H 0X44Y轴第5行01000010B 42H 0X42Y轴第4行01000010B 42H 0X42Y轴第3行11100111B 0E7H 0XE7Y轴第2行00000000B 00H 0X00Y轴第1行00000000B 00H 0X00整理汇编为; DB 00H,00H,00H,10H,10H,18H,28H,28H,24H,3CH,44H,42H,42H,0E7H,00H,00H1.3.英文的纵向取模,纵向取模的高位在下。

Windows矢量字体字模的提取摘要:利用Windows提供的丰富的字体库,调用Win32 API函数,将矢量汉字文本转化为位图,以提取汉字字模,用于电子系统的信息显示。
关键词: Windows矢量字体Win32 API函数汉字字模位图很多场合都需要用到汉字显示,如公共汽车上用来报站的电子显示牌、商场用来显示各种商品信息的电子显示牌等。
Windows提供了丰富的字体库。
如何利用这些字体库进行汉字显示,是需要解决的一个问题。
Windows支持GDI字体和设备字体二大类字体。
GDI字体存储在硬盘文件中,而设备字体是输出设备所固有的。
GDI字体分为三种类型:点阵字体、笔划字体和TrueType字体。
点阵字体的字模可以从字库文件中直接得到,而后二种是矢量字体,无法直接得到它们的字模,所以必须将笔划字体和TrueType字体点阵化,以获得所需要的字模。
通常情况下,电子系统的信息显示使用16×16(32字节)的点阵字库,例如在Win98下的Chs16.fon即为16×16(32字节)的字库文件。
从中提取字模的方法是:汉字的内码为二个字节,设为a和b。
a的大小应该介于0xa1和0xfe之间,其区码为qu=a-0xa0,位码为wei=b-0xa0,汉字字模在字库文件中的位置为offset=((qu-1)×94+(wei-1))×32。
本文主要介绍从Windows的矢量字体中提取字模的方法。
此方法已成功地运用于单片机系统设计中,解决了汉字显示的问题。
在实际应用中,可以直接调用Win32 API函数,将需要提取字模的汉字文本转化为位图,以此实现汉字的点阵化,用来提取字模。
1 字体设置首先需要设置字体。
Win32 SDK提供了用于字体选择的通用对话框,只需调用ChooseFont函数,其返回值为一个布尔值。
具体定义为BOOL ChooseFont(LPCHOOSEFONT lpcf)。
5.7点阵字模生成原理与方法[3]5.7.1 字模生成原理本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。
汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。
字模提取的作用
随着科技的不断发展,人们对于数字化信息的需求越来越高,而字模提取技术应运而生。
字模提取是一种将纸质或手写文字数字化的技术,将文本转化为可编辑的电子文档,以便于电脑进行处理和储存。
字模提取技术的应用范围非常广泛,比如在金融、医疗、法律等领域都有着重要的应用。
在金融领域,许多银行和保险公司需要将客户的手写表单或签名转化为电子文档,以便于管理和查询。
在医疗领域,医生需要将病历和诊断报告转化为电子文档,以方便存档和共享。
在法律领域,律师需要将合同和协议转化为电子文档,以方便查看和修改。
除此之外,字模提取技术还可以用于数字化图书馆、档案馆等文化机构的文献资料,以便于保护和传承。
同时,字模提取技术还可以用于OCR(Optical Character Recognition,光学字符识别)技术的研究和开发,提高OCR的识别准确率和速度。
字模提取技术的实现过程通常分为三个步骤:扫描、识别和校对。
首先,将纸质文档或手写文本进行扫描,生成数字图像。
然后,通过OCR软件对数字图像进行识别,将文本转化为可编辑的电子文档。
最后,通过校对软件对电子文档进行校对和编辑,提高文本的准确性和可读性。
然而,字模提取技术还存在一些问题和挑战,比如在扫描过程中,光线和角度的影响可能会导致识别错误;在识别过程中,文本的字体、大小和颜色等因素也会影响识别准确率。
为了解决这些问题,需要不断优化和改进字模提取技术,提高识别准确率和速度。
字模提取技术的应用前景十分广阔,对于数字化信息的处理和管理有着重要的意义。
随着技术的不断发展和应用的不断推广,相信字模提取技术将会得到更加广泛的应用和发展。
液晶显示汉字的字模提取新方法
黄海宏;王海欣
【期刊名称】《液晶与显示》
【年(卷),期】2005(20)4
【摘要】研究了图形显示液晶模块的汉字显示方法,通过外扩的EEPROM存储整个汉字库,将其作为外部数据存储器进行寻址,以MC68332单片机为例,介绍了根据汉字的机内码计算区位码,通过汉字区位码寻址汉字库进行字模提取的液晶显示汉字取模新方法,并给出对应的C程序.该方式能大大简化系统的维护,提高程序的可读性和效率.
【总页数】4页(P346-349)
【作者】黄海宏;王海欣
【作者单位】合肥工业大学,电气学院,安微,合肥,230009;合肥工业大学,电气学院,安微,合肥,230009
【正文语种】中文
【中图分类】TN27;TN873.93
【相关文献】
1.液晶显示器汉字字模存储方法 [J], 黄长杰;包文俊
2.汉字OS字模库中汉字点阵码的提取方法 [J], 杨国松
3.液晶显示器汉字字模存储方法 [J], 黄海宏;黄长杰;王海欣
4.利用VC++实现汉字字模的提取与小汉字库的生成 [J], 王保华
5.汉字字模提取技术 [J], 张呈祥
因版权原因,仅展示原文概要,查看原文内容请购买。
汉字字模的自动提取和重建算法
李旭红
【期刊名称】《湖北民族学院学报:自然科学版》
【年(卷),期】1999(017)003
【摘要】在讨论从图像中自动提取汉字字模的同时给出了短量化存储和无级放缩字模的算法。
这些算法已编程实现,效果较为理想。
【总页数】3页(P78-80)
【作者】李旭红
【作者单位】恩施州职业技术学校
【正文语种】中文
【中图分类】TP391.41
【相关文献】
1.利用VC++实现汉字字模的提取与小汉字库的生成 [J], 王保华
2.西文DOW环境下汉字交互式界面的设计:一种汉字模糊输入方法 [J], 刘子斐
3.点阵汉字的字模与汉字变形变换技术 [J], 马尚玮;蓝涛
4.点阵汉字的字模与汉字变形变换技术 [J], 马尚玮;蓝涛
5.IBM—PC微机汉字模转变为PC—E500机能显示的汉字码 [J], 韩买侠
因版权原因,仅展示原文概要,查看原文内容请购买。