字模提取详细解读
- 格式:pdf
- 大小:196.85 KB
- 文档页数:15

img2lcd 字模提取原理
哎呀,你这问题可有点意思啊,要用四川话、陕西话、还有北京话混合着来回答。
那我就试试看,咱们先聊聊这img2lcd字模提取原理吧。
咱们先从四川话开始。
说起这个img2lcd,那可不简单哦,它的原理就像咱们四川的火锅一样,得一层层地揭开才能看到里面的好东西。
你要先有个图片,就像火锅里得有各种食材一样,然后img2lcd就能帮你把这个图片里的字模给提取出来,就像火锅里把食材煮熟了捞出来一样。
再来说说陕西话。
陕西的汉子们都知道,咱这地方讲究实在。
img2lcd字模提取原理也是这么回事,你得实实在在地给它一个图片,它才能实实在在地给你提取出字模来。
这原理就像咱陕西的黄土高原一样,你得脚踏实地,才能看到它的真实面貌。
最后咱们来聊聊北京话。
在北京,人们讲究的是个明白。
img2lcd字模提取原理就是让你明白,原来图片里的字模可以这么简单地提取出来。
就像北京的四合院一样,看似复杂,其实结构清晰,一目了然。
所以说啊,这个img2lcd字模提取原理,就像咱们各地的方言一样,各有各的特色,但都是为了让人更好地理解和使用。
不管你是四川人、陕西人还是北京人,都能通过这个原理,轻松地把图片里的字模提取出来。
这就是它的神奇之处,也是它的魅力所在。


汉字字模存储和提取的方法
汉字字模的存储和提取是汉字信息处理系统中的重要环节,常用的方法有以下几种:
1. 存储在程序存储器中:这是在程序不大或单片机无外部扩展数据存储区功能的情况下使用的方法。
2. 通过外扩的EEPROM存储汉字字模数据:采用哈佛结构的单片机,如8051单片机及其派生产品,程序存储器(ROM)和数据存储器(RAM)可分别寻址。
将提取的汉字字模数据存放在EPROM或EEPROM内,并设定该芯片的片选地址,只要知道某个汉字字模数据在该芯片的存储位置,通过程序计算出偏移地址,即可实现显示功能。
3. 使用外扩的EEPROM存储整个汉字库:某些高端单片机,如Motorola 的M68300系列32位单片机,寻址范围可达8M。
以上信息仅供参考,如有需要,建议查阅计算机科学和电子工程相关书籍或咨询专业人士。


1 2 3 4 5 6 7 8 1 2 3 4 5 6 7 8 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 1 1 2 2 3 3 4 4 5 5 6 6 7 7 88逐列式:0x00,0x10,0x04,0x10,0x04,0x90,0xF4,0x5F, 0x54,0x35,0x54,0x15,0x54,0x15,0x5F,0x15, 0x54,0x15,0x54,0x15,0x54,0x35,0xF4,0x5F,0x04,0x90,0x04,0x10,0x00,0x10,0x00,0x00,/*"真",1*/ 逐行式:0x80,0x00,0x80,0x00,0xFE,0x3F ,0x80,0x00, 0xF8,0x0F,0x08,0x08,0xF8,0x0F,0x08,0x08, 0xF8,0x0F,0x08,0x08,0xF8,0x0F ,0x08,0x08,0xFF,0x7F,0x10,0x04,0x08,0x08,0x04,0x10,/*"真",0*/ /* (16 X 16 , 宋体 )*/字模中每一点使用一个二进制位(Bit)表示 字模提取有两种排列方式:逐列式、逐行式 逐列式:即从左端起,每列开头第1个点最后一个点。
逐行式:即从第1列起,每行第1个点到最后一个点。
两种取码方式:阴码、阳码 阴码:亮为1,灭为0 阳码:亮为0,灭为1下面以16*16点阵取“真”字为例,有逐列式和逐行式两段程序,且都为阴码。
程序中是十六进制,在字模提取时转换为二进制,逐列式:从第1列开始,每列16位,且从低位到高位,需2个十六进制数,如第列:0x00,0x10,转二进制:0000 0000;0001 000;对应方格中相应的位。
依次类推24*24点阵取模方法。

彩屏字模提取说明1、打开软件“航太电子资料\5.常用软件\取字模软件\PCtoLCD2002.exe”,点开选项,进行如下配置:2、配置完成后即可输入需要的汉字或英文,点击生成字模生成下面的数组3、复制生成的数组到工程文件“ch_enlib.c”的结构体数组struct CnCharType code cn_char[] 下面如下所示:struct CnCharType code cn_char[] ={0x02,0x00,0xFA,0x00,0x0B,0xE0,0x8C,0x20,0x58,0x40,0x51,0x00,0x21,0x00,0 x21,0x00,0x52,0x80,0x52,0x80,0x84,0x40,0x08,0x20,"欢",//00x84,0x00,0x59,0xE0,0x11,0x20,0x11,0x20,0xD1,0x20,0x51,0x20,0x55,0x20,0 x59,0x20,0x51,0x60,0x41,0x00,0x41,0x00,0xBF,0xE0,"迎",//10x11,0x00,0x11,0x00,0x2F,0xE0,0x21,0x00,0x6F,0xE0,0xA9,0x20,0x2F,0xE0,0 x29,0x00,0x25,0x00,0x22,0x00,0x25,0x80,0x28,0x60,"使",//20x00,0x00,0x7F,0xC0,0x44,0x40,0x44,0x40,0x7F,0xC0,0x44,0x40,0x44,0x40,0 x7F,0xC0,0x44,0x40,0x44,0x40,0x44,0x40,0x81,0xC0,"用",//30x21,0x00,0x78,0x80,0x4F,0xE0,0x68,0x00,0x58,0x00,0x4B,0x80,0xFA,0x80,0x4A,0x80,0x6A,0x80,0x5A,0xA0,0x4C,0xA0,0x98,0x60,"航",//40x04,0x00,0x04,0x00,0x04,0x00,0xFF,0xE0,0x04,0x00,0x0A,0x00,0x0A,0x00,0 x12,0x00,0x11,0x00,0x29,0x00,0x44,0x80,0x80,0x60,"太",//50x08,0x00,0x08,0x00,0xFF,0x80,0x88,0x80,0x88,0x80,0xFF,0x80,0x88,0x80,0 x88,0x80,0xFF,0x80,0x88,0x20,0x08,0x20,0x07,0xE0,"电",//60x00,0x00,0x3F,0x80,0x01,0x00,0x02,0x00,0x04,0x00,0x04,0x00,0xFF,0xE0,0 x04,0x00,0x04,0x00,0x04,0x00,0x04,0x00,0x1C,0x00,"子",//70x20,0x80,0x11,0x00,0x7F,0xC0,0x44,0x40,0x7F,0xC0,0x44,0x40,0x7F,0xC0,0 x04,0x00,0xFF,0xE0,0x04,0x00,0x04,0x00,0x04,0x00,"单",//80x01,0x00,0x21,0x00,0x21,0x00,0x21,0x00,0x3F,0xE0,0x20,0x00,0x20,0x00,0 x3F,0x80,0x20,0x80,0x40,0x80,0x40,0x80,0x80,0x80,"片",//90x20,0x00,0x27,0x80,0x24,0x80,0xF4,0x80,0x24,0x80,0x74,0x80,0x6C,0x80,0 xA4,0x80,0x24,0x80,0x24,0xA0,0x28,0xA0,0x30,0x60,"机",//100x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0 x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00," ",//空字符};4、在后面即可直接使用该汉字了,本字模是12*12大小的,用户可以根据实际需要,参考demo程序,改成其他大小的字模。

(33条消息)汉字常用特征的提取方法详解汉字模板制作:汉字模板即是对字模图片进行特征提取,将特征数据存放到存储器上构成模板。
模板制作与提取待识别汉字特征需要将原始汉字图片进行归一化,可增加特征的鲁棒性。
汉字数据尺度归一化到为64*64,归一化方法很多,最常用的是基于重心的归一化,不做详细介绍。
网格特征:在实际中,为了增加特征的鲁棒性,常常采用网格技术。
即统计汉字某一区域内特征的总和,这样可以削弱局部干扰。
网格结构主要是等分网格和弹性网格。
等分网格即是把原图像按尺寸平均分割为若干小网格,弹性网格则根据笔画密度划分原始图像。
弹性网格对字符位置偏移、扭曲更加不敏感,是目前使用最多的网格结构,考虑到“一” “l”等极端过窄字符,限制弹性网格弹力范围。
汉字的网格特征:汉字常用特征有:粗外围特征、外轮廓特征、内轮廓特征、方向线素特征。
其中粗外围、外轮廓用于粗分类,外轮廓、内轮廓、方向线素用于细分类。
1)粗外围特征该特征用于描述汉字较粗糙的结构信息。
首先对原汉字进行细化处理,得到汉字的骨架图像。
常用的图像细化算法均可,推荐使用R方法其速度较快。
R算法的一个链接:/detail/jy02660221/9584580原图像与骨架图像首先对骨架图像进行内部区域填充处理。
若该点为白色(非笔画区域),则检测其上下左右四个方向是否有笔画,若都有笔画则认为该点为内部区域,将白色置为黑色,依次处理完所有白点。
然后将填充图分成4*4共16个小块,统计每一小块黑色点数(笔画)数量,构成16维粗外围特征。
特征提取示意如下。
填充图及粗外围特征2)外轮廓特征该特征用于描述汉字外部轮廓信息。
原汉字二值图像沿上下左右4个方向进行扫描。
为了提高对字符形变的鲁棒性,本文用弹性网格对扫描区域进行划分,统计该部分第一次碰到笔画的面积。
如下图(箭头表示的扫描方向) ,每个方向被分为了 4 个区域,每个区域阴影面积即是 1维特征。
那么经该处理后,得到 4*4=16 维特征。

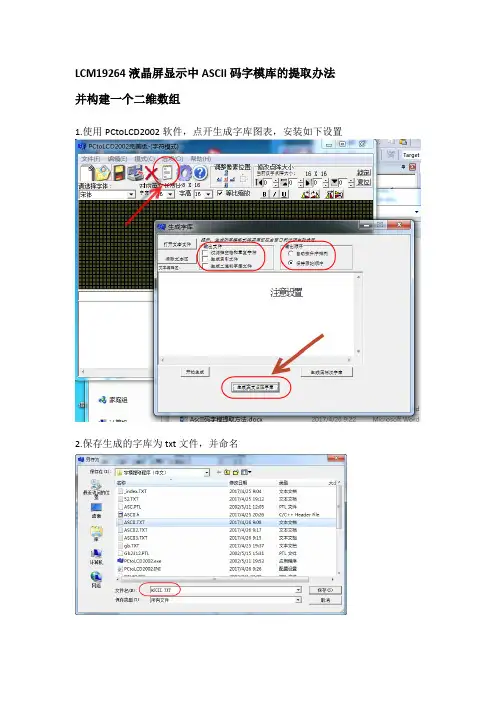
LCM19264液晶屏显示中ASCII码字模库的提取办法并构建一个二维数组
1.使用PCtoLCD2002软件,点开生成字库图表,安装如下设置
2.保存生成的字库为txt文件,并命名
3.打开刚刚生成的TXT文件,里面的每一行代表一个ASCII码的字码。
注意:31以上(包括31为不可见字符,我们不需要)
4. 在keil下新建文件Ascii.h,用了保存ASCII码字模Ascii.h文件内内容如下
以上声明了一个二维数组nAscii[][] ,并使用Code关键字将数组定义在Flash空间内,二维数组的第二位大小为16 ,此值为一个Ascii码字模的大小。
5. 将第3步文件中的可见字符复制到Ascii.h文件内的二维数组nAscii[][16] 中。
最后内容如下。

字符取模原理字符取模原理解析什么是字符取模字符取模是一种常见的编程技巧,用于判断字符串中某个字符在另一个字符集合中是否存在。
利用字符取模可以快速判断某个字符是否包含在一个字符串中,以及计算出字符在字符串中的位置。
字符取模的原理字符取模的原理基于ASCII码表,每个字符都对应一个唯一的ASCII码,范围从0到127。
通过将字符串中的字符与字符集合进行比较,可以根据字符的ASCII码判断字符是否存在于字符集合中。
字符取模的步骤1.将字符串和字符集合转换为ASCII码形式。
2.遍历字符串中的每个字符,并获取字符的ASCII码。
3.检查字符ASCII码是否包含在字符集合的ASCII码范围内。
4.如果包含,则表示字符存在于字符集合中;否则,表示字符不存在于字符集合中。
字符取模的示例以下是一个使用字符取模技巧判断字符串中是否包含某个字符的示例代码:def is_character_exists(string, character):# 获取字符集合的ASCII码character_set = set(ord(c) for c in string)# 获取字符的ASCII码char_ascii = ord(character)# 判断字符是否存在于字符集合中if char_ascii in character_set:return Trueelse:return False字符取模的优势和适用场景字符取模是一种高效的算法,可以快速判断一个字符是否存在于字符串中。
相比于遍历字符串逐个比较字符的方法,字符取模可以大大提高执行效率。
字符取模适用于以下场景: - 判断字符串中是否包含某个特定的字符。
- 在字符串中查找某个字符并获取其位置。
- 对字符串中的字符进行去重操作。
总结字符取模是一种利用字符的ASCII码进行快速判断字符是否存在于字符串中的编程技巧。
它遵循将字符串和字符集合转换为ASCII码,通过比较字符的ASCII码范围来判断字符是否存在的原理。

浅谈汉字特征字母及其提取规那么所谓特征字母,是指那些最能表征汉字轮廓特点的汉字字母。
人们看到一个汉字时,一般首先注意到的是它的轮廓特征,然后才是它的局部细节。
这就是汉字的认知规律。
从图形识别的角度来看,汉字认知更加注重轮廓性和整体性,字形的细微变化并不会给汉字认知造成多大影响。
因此,特征字母一定是构成汉字轮廓的汉字字母。
研究发现:人们通常是从汉字左上角开始,沿着顺时针方向扫描汉字轮廓的〔见以下列图〕。
因此,最能表征汉字轮廓特点的特征字母,首先是构成汉字左上角的汉字字母,其次是构成汉字右上角的汉字字母,再次是构成汉字右下角的汉字字母,最后是构成汉字左下角的汉字字母。
对于左右构造的汉字来说:左上角特征字母通常就是字首首字母〔第一个字母〕;右上角特征字母通常就是字身首字母;右下角特征字母通常就是字身末字母〔最后一个字母〕;左下角特征字母通常就是字首末字母〔见以下列图〕。
因此,左右构造汉字的特征字母依次是字首首字母、字身首字母、字身末字母和字首末字母。
对于上下构造的汉字来说:左上角特征字母通常就是字首首字母;右下角特征字母通常就是字身末字母;右上角特征字母有时是字首首字母〔如“京〞字〕,有时是字首末字母〔如“简〞字〕,有时是中间字母〔如“雪〞字〕,难以确定;左下角特征字母有时是字身首字母〔如“苡〞字〕,有时是字身末字母〔如“全〞字〕,有时是中间字母〔如“罢〞字〕,同样难以确定。
对于多数上下构造的汉字来说,人们通过一次扫描还无法辨识出汉字,还要进展第二次扫描,即扫描字身左上角和右上角,扫描的角度较第一次要小些。
字身左上角特征字母通常就是字首首字母,而字身右上角特征字母的位置那么难以确定〔见以下列图〕。
因此,上下构造汉字的特征字母依次是字首首字母,字身末字母和字身首字母。
正因为上下构造汉字的辨识需要进展两次扫描,所以,人们辨识上下构造汉字所花费的时间要比辨识左右构造汉字要多些;正因为上下构造汉字的特征字母为3个,比左右构造汉字的特征字母数量少1个,所以,人们对上下构造汉字辨识的错误率比上下构造汉字要高些。
5.7点阵字模生成原理与方法[3]5.7.1 字模生成原理本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。
汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。
汉字的取模原理手工取模原理(详解)因本人这个取模原理也搞了一天,网上也没有现成的资料,包括纵向和横向取模,对照网上各位所说慢慢摸索,最终把原理搞清楚,最后写出来给大家参照一下。
这里,我们先以英文和中文来说明,说明前我们先统一标准。
标准1:显示大小为16*16,显示的像素为1,不显示的为0。
标准2:显示大小为16*16,显示的像素为0,不显示的为1.有的显示要“字节倒序”,主要是显示器的要求不一样。
这里我们用标准1.解说以下图片:1.英文”A”字的取模,我们这里采用横向,横向取模为“高位在左”,方式是按单片机的内存每一位的排列,排列方式为“7.6.5.4.3.2.1.0”,显示的为1,不显示的为0,这里文字大小采用小4,占用像素为8*16。
1.1.我们按图把要显示的字用“1”填起来,图片显示为用1做的“A”,再把没有显示的用“0”填起来。
1.2.我们从Y轴的16行到Y轴第1行,一行一行的取,取8位二进制码,每行方向从左到右取数,再把二进制码用“8421”码转换成16进制码,分别是。
二进制汇编十六进制C语言十六进制Y轴第16行00000000B 00H 0X00Y轴第15行00000000B 00H 0X00Y轴第14行00000000B 00H 0X00Y轴第13行00010000B 10H 0X10Y轴第12行00010000B 10H 0X10Y轴第11行00011000B 18H 0X18Y轴第10行00101000B 28H 0X28Y轴第9行00101000B 28H 0X28Y轴第8行00100100B 24H 0X24Y轴第7行00111100B 3CH 0X3CY轴第6行01000100B 44H 0X44Y轴第5行01000010B 42H 0X42Y轴第4行01000010B 42H 0X42Y轴第3行11100111B 0E7H 0XE7Y轴第2行00000000B 00H 0X00Y轴第1行00000000B 00H 0X00整理汇编为; DB 00H,00H,00H,10H,10H,18H,28H,28H,24H,3CH,44H,42H,42H,0E7H,00H,00H1.3.英文的纵向取模,纵向取模的高位在下。
基于Qt4.5的Unicode字模提取工具一、关于字模提取的方式。
制作字模提取工具的原理,其实方法都大同小异。
就我所查阅的资料来看,提取字模主要有以下几种方法:1、从字模库中直接提取。
该方法受限于字模库,比如你需要16*16的字模和20*20的字模,你就必须去找到这2个字模库。
2、从ttf库中直接提取。
该方法提取出来的字模很光滑,效果很好。
同样你需要一个ttf库,它是矢量的,可以支持不同的大小。
3、在内存的位图上画出文字,然后生成字模。
该方法写出来的程序不需要额外的字库文件,依赖于操作系统中的字体。
但是一般操作系统中都带有大量的字体,足够我们使用,还可以很自由的选择自己喜欢的字体、大小等等。
所以我决定使用第3种方法来制作工具。
二、关于Qt4.5。
采用Qt4.5来制作该工具的最主要的原因是它可以编写跨平台的代码,其次是我正在学习Qt,学以致用才是王道。
另外Qt内部全采用unicode的编码,且提供了其他编码转unicode的良好支持,它同样提供了非常方便的设备上下文的绘图操作,可以方便的完成文字在内存中的绘制和提取字模的工作。
三、关于网上的同类软件。
目前在网上能搜到很多字模提取的工具和方法,大部分都介绍如何从中文的字模库中提取出字模用于嵌入式设备上LCD屏的显示。
其次大多工具都是基于VC开发,无法做到跨平台且基本上都没有开放源代码,有时候需要定制生成字库的文件格式,只有自己实现。
四、关于一些技术细节。
1、Qt的绘图操作。
Qt绘图使用的类是QPainter,使用该类在QWidget上绘图时,需要重载void QWidget::paintEvent ( QPaintEvent * event ) [virtual protected]并在此函数中进行绘图操作,在其他地方使用QPainter直接对QWidgets绘图会出现错误:QPainter::begin: Widget painting can only begin as a result of a paintEvent如果不是直接对QWidget绘图,而是在内存中建立一个位图,选入设备,然后在位图上绘图,则没有该限制。
Python文本提取是指利用Python编程语言进行文本分析和信息提取的过程。
在这个过程中,我们可以使用各种工具和库来对文本进行处理,去除噪音,提取关键信息,进行文本分类等操作。
其中,nltk (Natural Language Toolkit)是一个非常流行的用于自然语言处理的Python库,它提供了丰富的函数和工具来处理文本数据。
在本文中,我们将从以下几个方面来介绍Python文本提取和nltk库的原理以及使用方法。
一、Python文本提取的基本原理1.1 文本处理的基本流程在进行文本处理时,我们通常会先进行文本清洗,去除一些无关的标点符号、停用词和特殊字符。
然后进行分词操作,将文本分割成单词或短语。
接着可以对文本进行词性标注、命名实体识别等操作。
最后可以进行文本分析、挖掘等后续处理。
1.2 Python文本处理的常用工具和库在Python中,有许多用于文本处理的工具和库,比如nltk、jieba、SnowNLP等。
这些工具可以帮助我们进行文本处理、分析和挖掘。
二、nltk库的原理和基本用法2.1 nltk库的基本功能nltk库包含了非常丰富的自然语言处理工具和数据资源,比如分词器、词性标注器、命名实体识别器、语法分析器等。
我们可以利用这些工具来对文本进行各种处理和分析。
2.2 nltk库的基本用法在使用nltk库时,首先需要安装nltk库,然后下载相应的数据资源。
接着我们可以使用nltk库提供的函数和类来进行分词、词性标注、命名实体识别等操作。
nltk还提供了一些文本处理的示例和教程,帮助我们更好地理解和应用这些工具。
三、文本指定内容模型的实现3.1 文本指定内容模型的概念文本指定内容模型是指对文本中特定内容进行识别、提取或分类的模型。
比如我们可以利用文本指定内容模型来提取文本中的关键词、短语或实体等。
3.2 基于nltk库的文本指定内容模型实现在nltk库中,我们可以利用词性标注器、命名实体识别器等工具来实现文本指定内容模型。
5.7点阵字模生成原理与方法[3]5.7.1 字模生成原理本设计中因为使用汉字的点阵显示,需要提取汉字字模,因此我们首先来了解汉字点阵字模的提取方法。
汉字的点阵字模是从点阵字库文件中提取出来的。
例如常用的16×16点阵HZK16文件,12×12点阵HZK12文件等等,这些文件包括了GB 2312字符集中的所有汉字。
现在只要弄清汉字点阵在字库文件中的格式,就可以按照自己的意愿去显示汉字了。
下面以HZK16文件为例,分析取得汉字点阵字模的方法。
HZK16文件是按照GB 2312-80标准,也就是通常所说的国标码或区位码的标准排列的。
国标码分为 94 个区(Section),每个区 94个位(Position),所以也称为区位码。
其中01~09 区为符号、数字区,16~87 区为汉字区。
而 10~15 区、88~94 区是空白区域。
如何取得汉字的区位码呢?在计算机处理汉字和ASCII字符时,使每个ASCII字符占用1个字节,而一个汉字占用两个字节,其值称为汉字的内码。
其中第一个字节的值为区号加上32(20H),第二个字节的值为位号加上32(20H)。
为了与ASCII字符区别开,表示汉字的两个字节的最高位都是1,也就是两个字节的值都又加上了128(80H)。
这样,通过汉字的内码,就可以计算出汉字的区位码。
具体算式如下:qh=c1-32-128=c1-160 wh=c2-32-128=c2-160或qh=c1-0xa0 wh=c2-0xa0qh,wh为汉字的区号和位号,c1,c2为汉字的第一字节和第二字节。
根据区号和位号可以得到汉字字模在文件中的位置:location=(94*(qh-1)+(wh-1))*一个点阵字模的字节数。
那么一个点阵字模究竟占用多少字节数呢?我们来分析一下汉字字模的具体排列方式。
例如下图中显示的“汉”字,使用16×16点阵。
字模中每一点使用一个二进制位(Bit)表示,如果是1,则说明此处有点,若是0,则说明没有。