单因素重复测量实验设计.
- 格式:ppt
- 大小:25.00 KB
- 文档页数:5
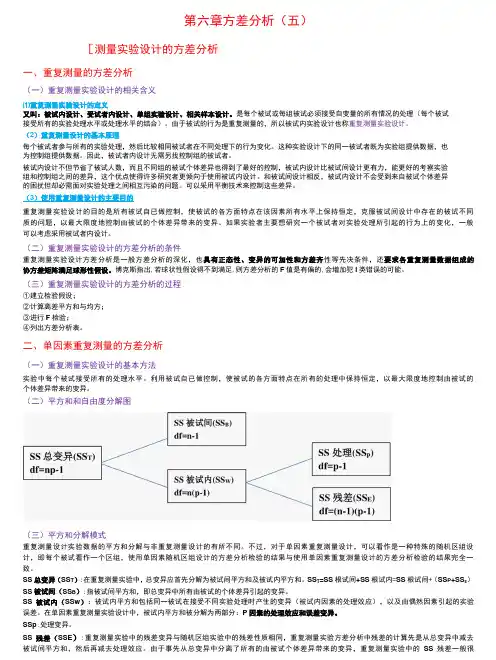
第六章方差分析(五)[测量实验设计的方差分析一、重复测量的方差分析(一)重复测量实验设计的相关含义⑴重复测量实验设计的定义又叫:被试内设计、受试者内设计、单组实验设计、相关样本设计。
是每个被试或每组被试必须接受自变量的所有情况的处理(每个被试接受所有的实验处理水平或处理水平的结合)。
由于被试的行为是重复测量的,所以被试内实验设计也称重复测量实验设计。
(2)重复测量设计的基本原理每个被试者参与所有的实验处理,然后比较相同被试者在不同处理下的行为变化。
这种实验设计下的同一被试者既为实验组提供数据,也为控制组提供数据。
因此,被试者内设计无需另找控制组的被试者。
被试内设计不但节省了被试人数,而且不同组的被试个体差异也得到了最好的控制,被试内设计比被试间设计更有力,能更好的考察实验组和控制组之间的差异,这个优点使得许多研究者更倾向于使用被试内设计。
和被试间设计相反,被试内设计不会受到来自被试个体差异的困扰但却必需面对实验处理之间相互污染的问题。
可以采用平衡技术来控制这些差异。
(3)使用重复测量设计的主要目的重复测量实验设计的目的是所有被试自已做控制,使被试的各方面特点在该因素所有水平上保持恒定,克服被试间设计中存在的被试不同质的问题,以最大限度地控制由被试的个体差异带来的变异。
如果实验者主要想研究一个被试者对实验处理所引起的行为上的变化,一般可以考虑采用被试者内设计。
(二)重复测量实验设计的方差分析的条件重复测量实验设计方差分析是一般方差分析的深化,也具有正态性、变异的可加性和方差齐性等先决条件,还要求各重复测量数据组成的协方差矩阵满足球形性假设。
博克斯指出,若球状性假设得不到满足,则方差分析的F值是有偏的,会增加犯I类错误的可能。
(三)重复测量实验设计的方差分析的过程①建立检验假设;②计算离差平方和与均方;③进行F检验;④列出方差分析表。
二、单因素重复测量的方差分析(一)重复测量实验设计的基本方法实验中每个被试接受所有的处理水平。
SPSS:单因素重复测量方差分析(史上最详细教程)一、问题与数据研究者招募了10名研究对象,研究对象进行了6个月的锻炼干预。
CRP浓度共测量了3次:干预前的CRP浓度——crp_pre;干预中(3个月)——crp_mid;干预后(6个月)——crp_post。
这三个时间点代表了受试者内因素“时间”的三个水平,因变量是CRP的浓度,单位是mg/L。
部分数据如下:二、对问题的分析使用One-way Repeated Measures Anova进行分析时,需要考虑6个假设。
对研究设计的假设:假设1:因变量唯一,且为连续变量;假设2:受试者内因素(Within-Subject Factor)有3个或以上的水平。
注:在重复测量的方差分析模型中,对同一个体相同变量的不同次观测结果被视为一组,用于区分重复测量次数的变量被称为受试者内因素,受试者内因素实际上是自变量。
对数据的假设:假设3:受试者内因素的各个水平,因变量没有极端异常值;假设4:受试者内因素的各个水平,因变量需服从近似正态分布;假设5:对于受试者内因素的各个水平组合而言,因变量的方差协方差矩阵相等,也称为球形假设。
三、思维导图(点击图片可查看大图) 四、对假设的判断在分析时,如何考虑和处理这5个假设呢?由于假设1-2都是对研究设计的假设,需要研究者根据研究设计进行判断,所以我们主要对数据的假设3-5进行检验。
(一) 检验假设3和假设4的SPSS操作1. 在主菜单点击Analyze > Descriptive Statistics > Explore...,如下图:2. 出现Explore对话框,将crp_pre、crp_mid和crp_post选入Dependent List,点击Plots;3. 出现下图Plots对话框;4. 在Boxplots下选择Dependents together,去掉Descriptive下Stem-和-leaf,选择Normality plots with tests,点击Continue;5. 回到Explore主对话框,在Display下方选择Plots,点击OK。





心理学与教育研究中的多因素实验设计——————舒华第二章 几种基本的实验设计一、 基本特点适用于:研究中有一个自变量,自变量有两个或多于两个水平。
方法:把被试随机分配给自变量的各个水平,每个水平被试只接受一个水平的处理。
二、 计算与举例(一) 检验的问题与实验设计 (二) 实验数据及其计算()()()()()22i 22j T 2j ij j ss ss X X NX X ss n nNss ss n S X ss ss X X ss X =+=-=-=∙-=-=∙=-∑∑∑∑∑∑∑∑∑∑∑∑总变异组间组内总变异组间组内总变异组间一、 基本特点适用于:研究中有一个变量,自变量有两个或多个水平(P ≥2),研究中还有一个无关变量,也有两个或多个水平(n ≥2);并且自变量的水平与无关变量的水平之间没有交互作用。
适合检验的假说:(1)处理水平的总体平均数相等或处理效应为零;(2)区组的总体平均数相等或区组效应为零。
二、计算ss ss ss (ss SS ss =+=++总变异组间组内组间区组残差)三、优点:从实验中分离出了一个无关变量的效应,从而减少了实验误差。
一、 基本特点定义:是一个含P 行、P 列、把P 个字母分配给方格的管理方案,其中每个字母在每行中只出现一次。
适用于:(1)研究中自变量与无关变量的水平平均≥2,一个无关变量的水平被分配给P行,另一个则给P列;(2)假定处理水平与无关变量水平之间没有交互作用, (3)随即分配处理水平给2P 个方格单元,每个处理水平仅在每行,每列中出现一次。
1c 2c 3c 4c无关变量C的四个水平 无关变量B的四个水平 1b 自变量A的四个水平 2b3b4bA B C SS SS SS SS SS SS SS SS =+=++++处理间总变异处理内残差单元内()一、 基本特点:(也叫被试内设计) 基本方法:实验中每个被试接受所有的处理水平目 的:利用被试自己做控制,使被试的各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。




单因素重复测量实验设计一、单因素重复测量实验设计的基本特点在单因素完全随机实验中,组内变异实际上是由两部分组成的:实验中测量误差引起的变异和未控制的无关变量带来变异,其中订是被试个体差异带来的变异。
减少误差变异的一个方法是控制个体差异引起的无关变量,达到这个目标的途径之一是使用随机区组设计,而控制个体差异的一个更有效的方法是重复测量实验设计,也叫被试内设计。
在一个非重复测量实验设计,或被试间设计中,例如我们在前面介绍的完全随机设计、随机区组设计和拉丁方设计中,一个共同的特点是实验中每个被试仅接受一个处理水平,被试的个体差异带来的变异混杂在误差变异中。
重复测量实验设计的基本方法是:实验中每个被试接受所有的处理水平。
这种实验设计的目的是利用被试自己做控制,使被试各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
使用重复测量设计的前提是研究者必须事先假设,当若干处理水平连续实施给同一被试时,被试接受前面的处理对接受后面的处理没有长期影响。
重复测量设计在有些情况下是不合适的,当处理的实施对被试有长期影响时,如学习、记忆效应,不能使用重复测设计。
例如,在一个教学研究中,要比较两种教学方法对学生学习成绩的影响。
我们不可能使用同一班学生先后接受两种教学方法,然后比较它们对学生学习成绩的影响,因为前一种教法的教学不可避免地对学生接受后一种教法的教学产生影响。
在心理与教育研究中,许多实验处理会对被试产生学习、记忆效应,因此使用重复测量设计要特别谨慎。
另外,顺序效应也是重复设计中应特别注意的问题。
被度连续接受处理时,练习、疲劳等效应是难免的,因此重复测量设计中需要考虑平衡顺序效应的问题。
与完全随机和随机区组设计非常不同的是,重复测量实验设计使用少量的被试,它们的图解比较如下:(a(b(c图2-4-1 单因素完全随机、随机区组、复重测量实验设计中分配被试的比较从三个图的比较中可以看出,在同样的有一个自变量、自变量有4个水平的实验中,完全随机设计使用16个随机选择的被试,随机区组设计使用4组、每组4个同质被试,因此也是16个被试,而重复测量设计仅用4个被试,每个被试接受所有的实验处理。
单因素重复测量结果报告一、单因素重复测量结果报告嘿,宝子们!今天咱们来唠唠单因素重复测量结果报告这事儿哈。
单因素重复测量呢,就像是你反复去看同一个东西,但是每次看可能都有不同的结果。
比如说你每天早上看自己的体重(当然这有点扎心啦,哈哈),这就是一种单因素(体重这个因素)的重复测量。
那这个结果报告呢,首先要讲清楚我们到底测量的是什么单因素。
就像刚刚说的体重,那在正经的研究里,可能是某个药物对病人某个症状的影响,这个症状就是我们的单因素啦。
我们得把这个因素描述得特别清楚,让看报告的人一下子就明白。
然后呢,测量的对象是谁呀?是一群大学生,还是特定的病人群体呢?这也得好好说。
如果是大学生,是哪个专业的,男生还是女生多,年龄大概是多少范围。
这些信息就像是给这个报告打基础的砖头,缺了可不行。
接下来就是具体的测量过程啦。
用了啥仪器,或者啥方法去测量的呢?要是用仪器,仪器的精度咋样,是不是很先进的那种,还是比较常规的。
方法呢,是问卷调查,还是实际的测试,比如说测量人的反应速度,是用那种按按钮的反应测试仪器,还是靠人工观察记录。
再说说测量的时间间隔。
是每天测一次,还是每周,甚至每个月呢?这个时间间隔可重要了。
比如说你研究植物的生长,每天测量和每周测量可能得到的结果趋势就不太一样呢。
结果部分那可就是重头戏啦。
我们得把每次测量得到的数据都列出来,可不能偷懒哦。
要是数据太多,做个表格多好呀,清晰又明了。
而且不能光列数据,还要分析这些数据的变化趋势。
是逐渐上升,还是下降,或者是波动很大呢?如果波动大,那为啥呢?是因为测量过程中有啥干扰因素,还是这个单因素本身就很不稳定呢?还有误差分析也不能少。
毕竟测量不可能是完美无缺的,总会有一些误差。
误差是怎么产生的呢?是测量仪器本身的问题,还是人为操作不当呢?比如说测量长度的时候,尺子刻度有点模糊,那这就可能造成误差啦。
最后呢,根据这个结果我们能得出啥结论呀?这个结论得跟我们最开始的研究目的挂钩。
单因素重复测量实验设计例子《单因素重复测量实验设计,就像一场有趣的冒险!》嘿,朋友们!今天我要和你们聊聊单因素重复测量实验设计这个听起来有点专业,但实际超级有意思的东西哦!你想啊,这单因素重复测量实验设计就像是我们在生活中玩的一个闯关游戏。
我们有个关键的因素,就好比那游戏里的大魔王,然后我们一遍又一遍地去挑战它,看它在不同情况下会有啥反应。
比如说,我曾经参与过一个关于口味偏好的实验。
这不就是单因素重复测量嘛!我们就研究一种新零食的味道,让参与者一次又一次地品尝,然后问他们的感觉。
嘿,这就像一场味觉的冒险!想象一下,参与者们就像勇敢的探险家,每次品尝都是一次新的挑战。
有时候他们会皱着眉头,仿佛在说:“哎呀,这次味道咋不一样啦!”有时候又会眼睛放光,好像在说:“哇塞,这次超好吃!”而我们这些搞实验的人呢,就像是背后的大导演,观察着他们的一举一动,记录下每一个有趣的反应。
而且啊,这种实验设计还有个好处,就是能让我们更深入地了解那个因素的影响。
就像挖宝藏一样,越挖越深,发现的宝贝也就越多。
可能一开始我们只看到了表面的一点点,但经过反复测量,哇哦,各种细节都浮现出来啦!当然啦,这过程中也会有一些小插曲。
比如有时候参与者会偷偷瞄我们的表情,想从我们这儿找答案,哈哈,那场面可太逗了!还有的时候,他们可能会因为吃太多次同一个东西而有点腻了,但还是得坚持完成实验,那表情真的是又好笑又让人心疼。
不过总的来说,单因素重复测量实验设计真的是一次充满乐趣和探索的旅程。
它让我们能在一个特定的领域里深入挖掘,不断发现新的东西。
就像打开了一扇神秘的门,里面有着无尽的惊喜等待着我们去探索。
所以啊,如果你还没尝试过这种实验设计,不妨去试试。
说不定你也会像我一样,爱上这场有趣的冒险,在探索的道路上发现许多意想不到的精彩呢!怎么样,准备好开启你的单因素重复测量实验之旅了吗?哈哈,让我们一起出发吧!。
单因素重复测量广义估计方程全文共四篇示例,供读者参考第一篇示例:单因素重复测量广义估计方程是一种统计方法,用于分析实验数据中单个因素下多个重复测量值的变化情况。
在实验设计中,为了消除其他因素对实验结果的影响,常常会进行重复测量,以便获取更为准确的数据。
在单因素实验中,研究者通常会对同一组对象或样本进行多次测量,比如一组实验对象在不同时间点的观测值或者在不同条件下的反应值。
这些重复测量值可能会受到多种因素的影响,比如测量误差、实验条件变化等。
为了从这些数据中提取有用的信息,需要利用统计的方法来建立估计方程。
单因素重复测量广义估计方程的建立需要考虑多个因素,其中最重要的是测量误差和实验因素的影响。
在实际数据分析中,可以利用方差分析的方法来确定实验因素对观测值的影响程度,以及测量误差的大小。
基于这些分析结果,可以建立广义估计方程,用于预测实验因素对观测值的影响。
在实际应用中,单因素重复测量广义估计方程可以用于多个领域,比如医学、生物学、工程等。
比如在药物疗效评价中,可以利用该方法来分析不同时间点下药物对疾病的影响;在工程领域可以通过实验数据的多次测量来评估不同因素对产品质量的影响。
单因素重复测量广义估计方程是一种高效的统计方法,可以帮助研究者从实验数据中获取更为准确和全面的信息。
单因素重复测量广义估计方程是一种重要的统计方法,可以帮助研究者从实验数据中提取有用的信息。
在建立该方程时,需要考虑多个因素的影响,包括实验因素和测量误差。
通过该方法的应用,可以更好地理解实验数据中的变化规律,为进一步研究提供重要参考。
希望更多的研究者能够了解并应用单因素重复测量广义估计方程,以推动相关领域的发展和进步。
【2000字】第二篇示例:单因素重复测量广义估计方程是统计学中一个重要的概念,它被广泛应用于各个领域的数据分析中。
单因素重复测量设计是实验设计中一种常见的设计方式,通过对同一组实验单位进行多次测量来分析因变量与自变量之间的关系。