重复测量两个因素的三因素实验设计
- 格式:ppt
- 大小:225.50 KB
- 文档页数:15


SPSS重复测量的多因素方差分析多因素方差分析(ANOVA)是一种统计方法,用于比较两个或更多个因素对于一个或多个变量的影响。
在实验设计中,重复测量多因素方差分析常用于研究不同因素(比如治疗、时间、性别等)对同一测量结果的影响。
多因素方差分析假设各个因素之间相互独立,并将数据分为各个因素的组合。
例如,一个的实验可能包括两个因素:治疗和时间。
治疗可以有两个水平:A和B,时间可以有三个水平:T1、T2和T3、通过重复测量同一个变量,并结合不同的因素水平,可以得到一个完整的数据集。
进行多因素方差分析需要检验三个假设:主效应假设、交互效应假设和均等性假设。
主效应是指每个因素对于因变量的直接影响,交互效应是指多个因素之间相互作用的影响,均等性假设是指各组之间的方差是否相等。
首先,我们需要计算各组的平均值、总平均值、因素间平方和、误差平方和以及均方。
平均值是各组数据的均值,总平均值是所有数据的均值。
因素间平方和是各组均值与总平均值之差的平方和乘以每组的样本量。
误差平方和是各个样本与其对应组均值之差的平方和。
均方是因素间平方和和误差平方和除以对应的自由度。
接下来,我们需要计算F统计量,并进行假设检验来确定各个因素是否显著影响因变量。
F统计量是因素间均方和误差平方的比值。
根据假设检验的结果,如果得到的p值小于设定的显著性水平(通常为0.05),则我们拒绝原假设,即说明该因素对因变量有显著影响。
当我们观察到交互作用时,可以进行进一步的分析来确定具体哪些因素交互作用显著。
可以通过绘制交互作用图来进行可视化分析。
此外,还有很多其他的方法可以对多因素方差分析的结果进行进一步分析。
比如,事后检验(post-hoc analysis)常用于确定哪些因素水平之间存在显著差异。
Tukey's HSD、Bonferroni修正和Sidak校正是常用的事后检验方法之一总结起来,多因素方差分析是一种强大的统计方法,可以研究多个因素对一个或多个变量的影响。

心理学与教育研究中的多因素实验设计——————舒华第二章 几种基本的实验设计一、 基本特点适用于:研究中有一个自变量,自变量有两个或多于两个水平。
方法:把被试随机分配给自变量的各个水平,每个水平被试只接受一个水平的处理。
二、 计算与举例(一) 检验的问题与实验设计 (二) 实验数据及其计算()()()()()22i 22j T 2j ij j ss ss X X NX X ss n nNss ss n S X ss ss X X ss X =+=-=-=∙-=-=∙=-∑∑∑∑∑∑∑∑∑∑∑∑总变异组间组内总变异组间组内总变异组间一、 基本特点适用于:研究中有一个变量,自变量有两个或多个水平(P ≥2),研究中还有一个无关变量,也有两个或多个水平(n ≥2);并且自变量的水平与无关变量的水平之间没有交互作用。
适合检验的假说:(1)处理水平的总体平均数相等或处理效应为零;(2)区组的总体平均数相等或区组效应为零。
二、计算ss ss ss (ss SS ss =+=++总变异组间组内组间区组残差)三、优点:从实验中分离出了一个无关变量的效应,从而减少了实验误差。
一、 基本特点定义:是一个含P 行、P 列、把P 个字母分配给方格的管理方案,其中每个字母在每行中只出现一次。
适用于:(1)研究中自变量与无关变量的水平平均≥2,一个无关变量的水平被分配给P行,另一个则给P列;(2)假定处理水平与无关变量水平之间没有交互作用, (3)随即分配处理水平给2P 个方格单元,每个处理水平仅在每行,每列中出现一次。
1c 2c 3c 4c无关变量C的四个水平 无关变量B的四个水平 1b 自变量A的四个水平 2b3b4bA B C SS SS SS SS SS SS SS SS =+=++++处理间总变异处理内残差单元内()一、 基本特点:(也叫被试内设计) 基本方法:实验中每个被试接受所有的处理水平目 的:利用被试自己做控制,使被试的各方面特点在所有的处理中保持恒定,以最大限度地控制由被试的个体差异带来的变异。
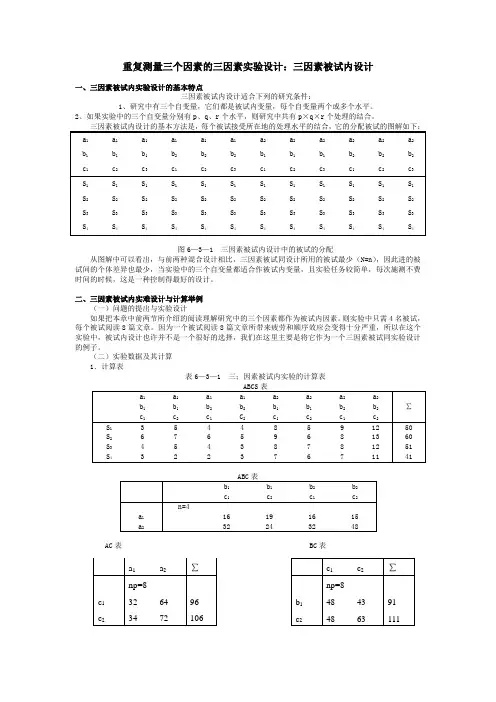
重复测量三个因素的三因素实验设计:三因素被试内设计一、三因素被试内实验设计的基本特点三因素被试内设计适合下列的研究条件:1、研究中有三个自变量,它们都是被试内变量,每个自变量两个或多个水平。
2、如果实验中的三个自变量分别有p 、q 、r 个水平,则研究中共有p ×q ×r 个处理的结合。
图6—3—1 三因素被试内设计中的被试的分配从图解中可以看出,与前两种混合设计相比,三因素被试同设计所用的被试最少(N=n ),因此进的被试间的个体差异也最少,当实验中的三个自变量都适合作被试内变量,且实验任务较简单,每次施测不费时间的时候,这是一种控制得最好的设计。
二、三因素被试内实难设计与计算举例(一)问题的提出与实验设计如果把本章中前两节所介绍的阅读理解研究中的三个因素都作为被试内因素。
则实验中只需4名被试,每个被试阅读8篇文章。
因为一个被试阅读8篇文章所带来疲劳和顺序效应会变得十分严重,所以在这个实验中,被试内设计也许并不是一个很好的选择,我们在这里主要是将它作为一个三因素被试同实验设计的例子。
(二)实验数据及其计算 1.计算表表6—3—1 三;因素被试内实验的计算表AC 表 BC 表111136202.00p q n rijkli j k l Y=====++=∑∑∑∑221111(202)[](4)(2)(2)(2)p q n r ijkl i j k l Y Y npqr ====⎛⎫⎪⎝⎭==∑∑∑∑=1275.1252221111[](3)(6)p q n rijkli j k l YABCS ======++∑∑∑∑=1544.0002221111(66)(136)[]1428.250(4)(2)(2)(4)(2)(2)q n r ijkl p i k l j Y A nqr ====⎛⎫⎪⎝⎭==+=∑∑∑∑ 2221111(91)(111)[]1287.625(4)(2)(2)(4)(2)(2)p n r ijkl p i j l k Y B npr ====⎛⎫⎪⎝⎭==+=∑∑∑∑ ACS 表 BCS 表2221111(96)(106)[]1278.250(4)(2)(2)(4)(2)(2)p q n ijkl ri j k l Y C nqr ====⎛⎫ ⎪⎝⎭==+=∑∑∑∑ 2221111(35)(56)[]1465.250(4)(2)(4)(2)n r ijkl p q i l j k Y AB nr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(32)(34)[]1432.500(4)(2)(4)(2)q n ijkl p r i l j l Y AC nq ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(48)(48)[]1303.250(4)(2)(4)(2)p n ijkl q ri j k l Y BC np ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(16)(32)[]1506.50044n ijkl p q r i j k l Y ABC n ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(50)(60)[]1297.750(2)(2)(2)(2)(2)(2)p q r ijkl nj k l i Y S pqr ====⎛⎫ ⎪⎝⎭==++=∑∑∑∑2221111(8)(13)[]1496.00022r ijkl p q nl i j k Y ABS r ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(7)(12)[]1463.00022q ijkl p n r k i j l Y ACS q ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(11)(15)[]1329.00022p ijkl q n rj i k l Y BCS p ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(16)(24)[]1456.500(2)(2)(2)(2)q r ijkl n r k l i j Y AS qr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(21)(28)[]1312.000(2)(2)(2)(2)p r ijkl q nj l i k Y BS pr ====⎛⎫⎪⎝⎭==++=∑∑∑∑2221111(24)(29)[]1301.000(2)(2)(2)(2)p q ijkl n rj k i l Y CS pq ====⎛⎫⎪⎝⎭==++=∑∑∑∑3.平方和的分解与计算(1)平方和的分解模式SS总变异=SS被试间SS被试内=SS被试间+(SSA+SS A×被试+SSB+SS B×被试+SSC+SS C×被试+SSAB+SS A×B×被试+SSAC+SS A×C×被试+SSBC+SS B×C×被试+SSABC+SS A×B×C×被试)(2)平方和的计算SS总变异=[ABCS]-[Y]=268.875SS被试间=[S]-[Y]=22.625SS被试内=SS总变异-SS被试间=246.250SSA=[A]-[Y]=153.125SS A×被试=[AS]-[Y]-SS补试间-SSA=5.625SSB=[B]-[Y]=12.500SS B×被试=[BS]-[Y]-SS被试间-SSB=1.750SSC=[C]-[Y]=3.125SS C×被试=[CS]-[Y]-SS被试间-SSC=0.125SSAB=[AB]-[Y]-SSA-SSB=24.500SS A×B×被试=[ABS]-[Y]-SS被试间-SSA-SSB-SSAB-SS A×被试-SS B×被试=0.750SSAC=[AC]-[Y]-SSA-SSC=1.125SS A×C×被试=[ACS]-[Y]-SS被试间-SSA-SSC-SSAC-SS A×被试-SS C×被试=2.125SSBC=[BC]-[Y]-SSB-SSC=12.500SS B×C×被试=[BCS]-[Y]-SS被试间-SSB-SSC-SSBC-SS B×被试-SS C×被试=1.250SSABC=[ABC]-[Y]-SSA-SSB-SSC-SSAB-SSAC-SSBC=24.500SS A×B×C×被试=SS被试内-SSA-SS A×被试-SSB-SS B×被试-SSC-SS C×被试-SSAB-SS A×B×被试-SSAC-SS A×C×被试-SSBC-SS B×C×被试-SSABC=3.250在表6-3-2中的方差分析结果表明,三个被试内因素——生字密度(A因素)F p=<、文章类型(B因素)((1,3)21.43,.05)=<、平均句长(C因素)F p((1,3)81.67,.01)=<的主效应都是显著的,AC的交互作用是不是显著的F p((1,3)75.00,.01)=<,其余交互作用((1,3)98.00,.01)=<、AB F pF p((1,3) 1.59,.05)ABC F p=<、((1,3)22.62,.05)=<都是显著的。

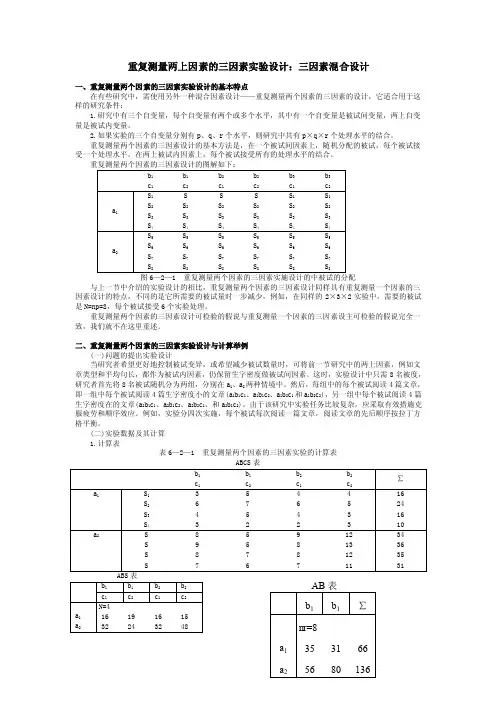
重复测量两上因素的三因素实验设计:三因素混合设计一、重复测量两个因素的三因素实验设计的基本特点在有些研究中,需使用另外一种混合因素设计——重复测量两个因素的三因素的设计,它适合用于这样的研究条件:1.研究中有三个自变量,每个自变量有两个或多个水平,其中有一个自变量是被试间变量,两上自变量是被试内变量。
2.如果实验的三个自变量分别有p 、q 、r 个水平,则研究中共有p ×q ×r 个处理水平的结合。
重复测量两个因素的三因素设计的基本方法是,在一个被试间因素上,随机分配的被试,每个被试接受一个处理水平。
在两上被试内因素上,每个被试接受所有的处理水平的结合。
与上一节中介绍的实验设计的相比,重复测量两个因素的三因素设计同样具有重复测量一个因素的三因素设计的特点,不同的是它所需要的被试量时一步减少,例如,在同样的2×3×2实验中,需要的被试是N=np=8,每个被试接受6个实验处理。
重复测量两个因素的三因素设计可检验的假说与重复测量一个因素的三因素设主可检验的假说完全一致,我们就不在这里重述。
二、重复测量两个因素的三因素实验设计与计算举例(一)问题的提出实验设计当研究者希望更好地控制被试变异,或希望减少被试数量时,可将前一节研究中的两上因素,例如文章类型和平均句长,都作为被试内因素,仍保留生字密度做被试间因素。
这时,实验设计中只需8名被度,研究者首先将8名被试随机分为两组,分别在a 1、a 2两种情境中。
然后,每组中的每个被试阅读4篇文章,即一组中每个被试阅读4篇生字密度小的文章(a 1b 1c 1、a 1b1c 2、a 1b 2c 1和a 1b 2c 2),另一组中每个被试阅读4篇生字密度在的文章(a 2b 1c 1、a 2b 1c 2、a 2b 2c 1、和a 2b 1c 2)。
由于该研究中实验任务比较复杂,应采取有效措施克服疲劳和顺序效应。
例如,实验分四次实施,每个被试每次阅读一篇文章,阅读文章的先后顺序按拉丁方格平衡。


重复测量资料组内效应、组间效应、交互效应结果解读在统计分析和实验设计中,重复测量资料经常遇到,特别是当同一组个体在多个时间点或条件下被测量时。
在这种情况下,我们可能会考虑三个主要的效应:组内效应、组间效应和交互效应。
以下是这三个效应的结果解读:组内效应(Within-Subjects Effect):组内效应描述了同一个体在不同时间点或条件下的差异。
例如,在一个研究中,我们可能对一个样本组在不同时间点(如治疗前、治疗后1周、治疗后1个月)进行相同的测量。
组内效应将揭示这些时间点之间是否存在显著差异。
如果组内效应显著,那么我们可以认为该因素(例如治疗)在组内产生了显著的影响。
组间效应(Between-Subjects Effect):组间效应描述了不同组之间的差异。
例如,在一个研究中,我们可能有两组人,一组接受了治疗,另一组没有。
组间效应将揭示这两组之间是否存在显著差异。
如果组间效应显著,那么我们可以认为该因素(例如治疗与否)在两组之间产生了显著的影响。
交互效应(Interaction Effect):交互效应描述了一个因素如何影响另一个因素的效果。
例如,考虑一个关于锻炼和饮食的研究,其中有两个组:一组遵循健康的饮食和锻炼习惯,另一组不遵循。
交互效应将揭示饮食和锻炼之间的相互作用是否产生了额外的效果。
如果交互效应显著,那么我们可以认为一个因素(例如锻炼)对另一个因素(例如饮食)的效果产生了显著的影响,并且这种影响不是简单的相加关系。
解读这些效应时,重要的是要查看统计测试的p值和置信区间,以确定观察到的效应是否统计上显著,以及这些效应的大小和方向。
此外,还需要考虑样本大小、效应大小、统计模型的假设等因素。
最终,这些结果应该结合研究背景和目的进行解释。



两因素重复测量实验设计引言:在科学研究中,为了验证研究对象的特定性质或现象,常常需要进行实验设计。
其中,重复测量实验设计是一种常见的方法,它能够减少误差因素对实验结果的影响,提高实验结果的可信度和可重复性。
本文将介绍两因素重复测量实验设计的基本原理、步骤和应用。
一、实验设计原理两因素重复测量实验设计是一种多因素实验设计方法,它通过对同一实验对象进行多次测量,以消除实验对象个体差异对实验结果的影响。
其中,两个因素分别称为主因素和副因素,主要通过重复测量和随机分组两种方式来进行实验。
二、实验设计步骤1. 确定研究目的和问题:明确实验的目的和需要验证的问题,确定主因素和副因素。
2. 设计实验方案:根据研究目的和问题,设计出合适的实验方案,包括实验对象、实验组和对照组的选择,实验条件的设置等。
3. 随机分组:根据实验方案,将实验对象随机分为不同的组别,以消除个体差异对实验结果的影响。
4. 重复测量:在实验过程中,对每个实验对象进行多次测量,以减少测量误差和提高实验结果的可靠性。
5. 数据分析与结果验证:通过对实验数据进行统计分析和假设检验,验证实验结果的可靠性和有效性。
三、实验设计应用1. 医学研究:在药物研究和治疗效果评估中,常常需要进行两因素重复测量实验设计,以确定药物的疗效和副作用。
2. 农业科学:在作物种植和农业生产中,通过两因素重复测量实验设计,可以评估不同种植条件和处理方式对作物产量和质量的影响。
3. 工程技术:在工程实践中,通过两因素重复测量实验设计,可以评估不同材料和工艺对产品性能和使用寿命的影响。
4. 教育研究:在教学实践和教育研究中,通过两因素重复测量实验设计,可以评估不同教学方法和教育资源对学生学习成绩和兴趣的影响。
结论:两因素重复测量实验设计是一种常用的实验设计方法,通过对同一实验对象进行多次测量和随机分组,可以减少个体差异对实验结果的影响,提高实验结果的可靠性和有效性。
在科学研究和应用领域中,该实验设计方法具有广泛的应用前景,对于验证和评估研究对象的特定性质和现象具有重要意义。
两因素重复测量实验的三线表一、引言两因素重复测量实验是一种常用的实验设计方法,用于研究两个或更多因素对实验结果的影响。
本文将以一份三线表为例,介绍如何使用该实验设计方法,并分析实验结果。
二、实验设计本次实验涉及两个因素:因素A和因素B,每个因素有三个水平,分别为A1、A2、A3和B1、B2、B3。
实验采用重复测量设计,每个水平下进行三次测量,共计27个观察值。
三、数据分析根据实验结果,我们可以绘制出如下的三线表:因素A因素B A1 A2 A3B1 X11 X12 X13B2 X21 X22 X23B3 X31 X32 X33其中,Xij表示在因素A的第i个水平和因素B的第j个水平下的观察值。
通过观察三线表,我们可以得到以下几个结论:1. 因素A对实验结果有显著影响:观察每一列的数据,可以发现在因素A不同水平下,观察值存在明显差异。
因此,我们可以得出结论:因素A对实验结果有显著影响。
2. 因素B对实验结果有显著影响:观察每一行的数据,可以发现在因素B不同水平下,观察值存在明显差异。
因此,我们可以得出结论:因素B对实验结果有显著影响。
3. 因素A和因素B之间存在交互作用:从整个三线表的数据来看,不同水平下的观察值存在交叉现象,即因素A和因素B之间存在交互作用。
具体来说,当因素A为A1时,因素B的影响程度可能与其他水平下不同。
四、结论与讨论通过两因素重复测量实验的三线表分析,我们得出了以下结论:1. 因素A对实验结果有显著影响;2. 因素B对实验结果有显著影响;3. 因素A和因素B之间存在交互作用。
这些结论为进一步深入研究和分析提供了重要线索。
在进行后续实验或研究时,可以重点关注因素A和因素B的影响机制,进一步探讨它们对实验结果的具体影响程度。
值得注意的是,本次实验只涉及两个因素,若研究对象更复杂,可以将两因素重复测量实验扩展为更高维度的实验设计,以获取更全面的数据和结论。
五、总结本文以一份三线表为例,介绍了两因素重复测量实验设计的基本原理和数据分析方法。
三因素实验设计对三因素重复测量实验设计进行数据处理一、三因素完全随机实验设计数据处理过程:1、打开SPSS软件,点击Data View ,进入数据输入窗口,将原始数据输入SPSS 表格区域;2、在菜单栏中选择分析→一般线性模型→单变量;3、因变量Dependent Variable方框中放入记忆成绩(JY),固定变量(Fixed Factor(s))方框中,放入自变量记忆策略、有无干扰和材料类型;4、点击选项(Options)按钮,选择Descriptive statistics,对数据进行描述性统计;选择Homogeneity tests,进行方差齐性检验;s i o n 2总计 4.2000 1.54238 20 总计实物图片7.3000 3.79889 20 图形图片 5.6500 2.39022 20总计 6.4750 3.2422540被试间变量效应检验结果:A、B、C的主效应均极显著(P<0.01);AB 交互效应显著;AC 交互效应极显著;BC 交互效应不显著;ABC 交互效应极显著。
对于二阶与三阶交互效应显著的,还需进行简单效应与简单简单效应检验。
主体间效应的检验因变量:记忆成绩源III 型平方和df 均方 F Sig.校正模型349.175a7 49.882 26.254 .000 截距1677.025 1 1677.025 882.645 .000A 65.025 1 65.025 34.224 .000B 207.025 1 207.025 108.961 .000C 27.225 1 27.225 14.329 .001 A * B 9.025 1 9.025 4.750 .037A * C 15.625 1 15.625 8.224 .007B *C 4.225 1 4.225 2.224 .146 A * B * C 21.025 1 21.025 11.066 .002 误差60.800 32 1.900总计2087.000 40校正的总计409.975 39主体间效应的检验因变量:记忆成绩源III 型平方和df 均方 F Sig.校正模型349.175a7 49.882 26.254 .000 截距1677.025 1 1677.025 882.645 .000A 65.025 1 65.025 34.224 .000B 207.025 1 207.025 108.961 .000C 27.225 1 27.225 14.329 .001 A * B 9.025 1 9.025 4.750 .037A * C 15.625 1 15.625 8.224 .007B *C 4.225 1 4.225 2.224 .146 A * B * C 21.025 1 21.025 11.066 .002 误差60.800 32 1.900总计2087.000 40校正的总计409.975 39a. R 方= .852(调整R 方= .819)简单效应检验:在主对话框中,单击Paste按钮,SPSS会把原先的全部操作转换成语句并粘贴到新打开的程序语句窗口中,在命令语句中加入EMMEANS引导的语句;结果:当被试使用联想策略进行记忆时,无干扰条件的记忆成绩极显著优于有干扰条件的记忆成绩;当被试使用复述策略进行记忆时,无干扰条件的记忆成绩也极显著优于有干扰条件的记忆成绩。