数据挖掘关于Kmeans算法的研究(含数据集)
- 格式:doc
- 大小:177.00 KB
- 文档页数:22
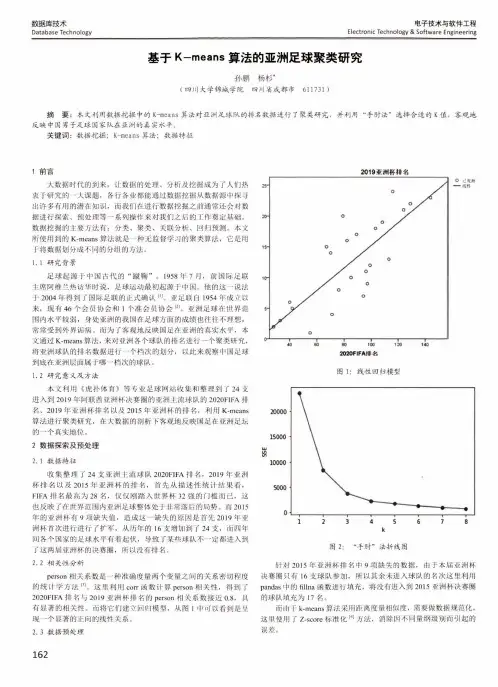
电子技术与软件工程Electronic Technology & Software Engineering数据库技术Database Technology 基于K-means 算法的亚洲足球聚类研究孙鹏杨杉*(四川大学锦城学院 四川省成都市 611731 )摘 要:本文利用数据挖掘中的K-means 算法对亚洲足球队的排名数据进行了聚类研究,并利用“手肘法”选择合适的K 值,客观地 反映中国男子足球国家队在亚洲的真实水平。
关键词:数据挖掘;K-means 算法;数据特征1前言大数据时代的到来,让数据的处理、分析及挖掘成为了人们热 衷于研究的一大课题,各行各业都能通过数据挖掘从数据源中探寻 出许多有用的潜在知识,而我们在进行数据挖掘之前通常还会对数 据进行探索、预处理等一系列操作来对我们之后的工作奠定基础。
数据挖掘的主要方法有:分类、聚类、关联分析、回归预测。
本文 所使用到的K-means 算法就是一种无监督学习的聚类算法,它是用 于将数据划分成不同的分组的方法。
1. 1研究背景足球起源于中国古代的“蹴鞠”。
1958年7月,前国际足联 主席阿维兰热访华时说,足球运动最初起源于中国。
他的这一说法 于2004年得到了国际足联的正式确认⑴。
亚足联自1954年成立以 来,现有46个会员协会和1个准会员协会⑵。
亚洲足球在世界范 围内水平较弱,身处亚洲的我国在足球方面的成绩也往往不理想, 常常受到外界诟病。
而为了客观地反映国足在亚洲的真实水平,本 文通过K-means 算法,来对亚洲各个球队的排名进行一个聚类研究, 将亚洲球队的排名数据进行一个档次的划分,以此来观察中国足球 到底在亚洲层面属于哪一档次的球队。
1. 2研究意义及方法本文利用《虎扑体育》等专业足球网站收集和整理到了 24支 进入到2019年阿联酋亚洲杯决赛圈的亚洲主流球队的2020FIFA 排 名、2019年亚洲杯排名以及2015年亚洲杯的排名,利用K-means 算法进行聚类研究,在大数据的剖析下客观地反映国足在亚洲足坛 的一个真实地位。


kmeans的聚类算法K-means是一种常见的聚类算法,它可以将数据集划分为K个簇,每个簇包含相似的数据点。
在本文中,我们将详细介绍K-means算法的原理、步骤和应用。
一、K-means算法原理K-means算法基于以下两个假设:1. 每个簇的中心是该簇内所有点的平均值。
2. 每个点都属于距离其最近的中心所在的簇。
基于这两个假设,K-means算法通过迭代寻找最佳中心来实现聚类。
具体来说,该算法包括以下步骤:二、K-means算法步骤1. 随机选择k个数据点作为初始质心。
2. 将每个数据点分配到距离其最近的质心所在的簇。
3. 计算每个簇内所有数据点的平均值,并将其作为新质心。
4. 重复步骤2和3直到质心不再变化或达到预定迭代次数。
三、K-means算法应用1. 数据挖掘:将大量数据分成几组可以帮助我们发现其中隐含的规律2. 图像分割:将图像分成几个部分,每个部分可以看做是一个簇,从而实现图像的分割。
3. 生物学:通过对生物数据进行聚类可以帮助我们理解生物之间的相似性和差异性。
四、K-means算法优缺点1. 优点:(1)简单易懂,易于实现。
(2)计算效率高,适用于大规模数据集。
(3)结果可解释性强。
2. 缺点:(1)需要预先设定簇数K。
(2)对初始质心的选择敏感,可能会陷入局部最优解。
(3)无法处理非球形簇和噪声数据。
五、K-means算法改进1. K-means++:改进了初始质心的选择方法,能够更好地避免陷入局部最优解。
2. Mini-batch K-means:通过随机抽样来加快计算速度,在保证精度的同时降低了计算复杂度。
K-means算法是一种常见的聚类算法,它通过迭代寻找最佳中心来实现聚类。
该算法应用广泛,但也存在一些缺点。
针对这些缺点,我们可以采用改进方法来提高其效果。

实验设计过程及分析:1、通过通信企业数据(USER_INFO_M.csv),使用K-means算法实现运营商客户价值分析,并制定相应的营销策略。
(预处理,构建5个特征后确定K 值,构建模型并评价)代码:setwd("D:\\Mi\\数据挖掘\\")datafile<-read.csv("USER_INFO_M.csv")zscoredFile<- na.omit(datafile)set.seed(123) # 设置随机种子result <- kmeans(zscoredFile[,c(9,10,14,19,20)], 4) # 建立模型,找聚类中心为4round(result$centers, 3) # 查看聚类中心table(result$cluster) # 统计不同类别样本的数目# 画出分析雷达图par(cex=0.8)library(fmsb)max <- apply(result$centers, 2, max)min <- apply(result$centers, 2, min)df <- data.frame(rbind(max, min, result$centers))radarchart(df = df, seg =5, plty = c(1:4), vlcex = 1, plwd = 2)# 给雷达图加图例L <- 1for(i in 1:4){legend(1.3, L, legend = paste("VIP_LVL", i), lty = i, lwd = 3, col = i, bty = "n")L <- L - 0.2}运行结果:2、根据企业在2016.01-2016.03客户的短信、流量、通话、消费的使用情况及客户基本信息的数据,构建决策树模型,实现对流失客户的预测,F1值。

第1篇一、实验背景聚类分析是数据挖掘中的一种重要技术,它将数据集划分成若干个类或簇,使得同一簇内的数据点具有较高的相似度,而不同簇之间的数据点则具有较低相似度。
本实验旨在通过实际操作,了解并掌握聚类分析的基本原理,并对比分析不同聚类算法的性能。
二、实验环境1. 操作系统:Windows 102. 软件环境:Python3.8、NumPy 1.19、Matplotlib 3.3.4、Scikit-learn0.24.03. 数据集:Iris数据集三、实验内容本实验主要对比分析以下聚类算法:1. K-means算法2. 聚类层次算法(Agglomerative Clustering)3. DBSCAN算法四、实验步骤1. K-means算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的KMeans类进行聚类,设置聚类数为3。
(3)计算聚类中心,并计算每个样本到聚类中心的距离。
(4)绘制聚类结果图。
2. 聚类层次算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的AgglomerativeClustering类进行聚类,设置链接方法为'ward'。
(3)计算聚类结果,并绘制树状图。
3. DBSCAN算法(1)导入Iris数据集,提取特征数据。
(2)使用Scikit-learn库中的DBSCAN类进行聚类,设置邻域半径为0.5,最小样本数为5。
(3)计算聚类结果,并绘制聚类结果图。
五、实验结果与分析1. K-means算法实验结果显示,K-means算法将Iris数据集划分为3个簇,每个簇包含3个样本。
从聚类结果图可以看出,K-means算法能够较好地将Iris数据集划分为3个簇,但存在一些噪声点。
2. 聚类层次算法聚类层次算法将Iris数据集划分为3个簇,与K-means算法的结果相同。
从树状图可以看出,聚类层次算法在聚类过程中形成了多个分支,说明该算法能够较好地处理不同簇之间的相似度。

基于数据抽样的自动k-means聚类算法罗军锋;洪丹丹【摘要】为了解决传统k-means算法需要输入k值和在超大规模数据集进行聚类的问题,这里在前人研究基础上,首先在计算距离时引入信息熵,在超大规模数据集采用数据抽样,抽取最优样本数个样本进行聚类,在抽样数据聚类的基础上进行有效性指标的验证,并且获得算法所需要的k值,然后利用引入信息熵的距离公式再在超大数据集上进行聚类。
实验表明,该算法解决了传统k-means算法输入k值的缺陷,通过数据抽样在不影响数据聚类质量的前题下自动获取超大数据集聚类的k值。
%In order to solve the problems of the traditional k-means algorithm in which k values needs to be input and the the ultra-large-scale data set needs to be clustered,on the basis of previous studies,the information entropy is brought in when distance is calculated,and data sampling method is adopted,that is,the optimal samples are extracted from the ultra-large-scale data set to conduct sample clustering. Based on the sample data clustering,the validity indexes are verified and k value re-quired by the algorithm is obtained. The distance formula for information entropy is brought in to carry out clustering on the ultra-large data set. Experiments show that the algorithm can overcome the defects of traditional k-means algorithm for k value input, and can automatically obtain k values of ultra-large data clustering under the premise of not affecting the quality of the early da-ta clustering.【期刊名称】《现代电子技术》【年(卷),期】2014(000)008【总页数】3页(P19-21)【关键词】k-means算法;信息熵;最优样本抽取;有效性指标【作者】罗军锋;洪丹丹【作者单位】西安交通大学信息中心,陕西西安 710049;西安交通大学信息中心,陕西西安 710049【正文语种】中文【中图分类】TN911-34;TP311聚类是数据挖掘中重要的三个领域(关联规则,聚类和分类)之一。


基于K-means的电力系统典型日负荷特性计算方法研究一、引言电力系统的负荷特性计算对于电力系统的运行与规划非常重要。
负荷特性可以反映出用户用电的规律与变化,对于电力系统的日常调度和未来规划具有重要的参考价值。
而K-means聚类算法是一种常用的数据挖掘方法,可以对数据进行分群,从而分析出不同类别的特性。
本文将通过研究基于K-means的电力系统典型日负荷特性计算方法,以期为电力系统调度和规划提供更为准确的负荷特性分析。
二、K-means聚类算法K-means聚类算法是一种基于距离的聚类方法,其基本思想是将数据集分成K个簇,并使每个数据点都被分配到最近的簇中,使得簇内数据的相似度最大化,簇间数据的相似度最小化。
K-means算法的过程可以分为以下几步:1. 随机初始化K个中心点2. 根据每个点到中心点的距离,将所有点分配到最近的中心点所在的簇3. 重新计算每个簇的中心点4. 重复第2步和第3步,直到中心点不再发生变化或达到迭代次数最终得到K个簇,以及每个簇的中心点,从而对数据集进行了分群。
三、基于K-means的电力系统典型日负荷特性计算方法1. 数据准备为了进行典型日负荷特性的计算,首先需要准备一段时间内的负荷数据。
通常可以选择一年内的数据作为分析对象。
这样的原始数据量过大,不适合直接进行K-means聚类,因此需要进行预处理,将原始负荷数据进行聚合,得到更为精简的数据集。
常见的聚合方式包括按天、按周、按月进行聚合,从而将原始数据进行压缩,方便后续的聚类分析。
2. K值的选择K-means聚类算法需要事先确定簇的个数K,而对于电力系统的典型日负荷特性计算,K值的选择往往是一个挑战。
一般来说,K的选择需要根据具体的数据集与分析目的来确定,可以通过经验或者利用一些模型进行K值的选择。
在实际应用中,可以尝试不同的K值,通过评价指标(如轮廓系数、Calinski-Harabasz指数等)来确定最优的K值。

K-Means聚类算法的研究周爱武;于亚飞【摘要】The algorithm of K-means is one kind of classical clustering algorithm, including both many points and also shortages.For example must choose the initial clustering number.The choose of initial clustering centre has randomness.The algorithm receives locally optimal solution easily, the effect of isolated point is serious.Mainly improved the choice of initial clustering centre and the problem of isolated point.First of all ,the algorithm calculated distance between all data and eliminated the effect of isolated point.Then proposed one new method for choosing the initial clustering centre and compared the algorithm having improved and the original algorithm using the experiment.The experiments indicate that the effect of isolated point for algorithm having improved reduces obviously, the results of clustering approach the actual distribution of the data.%K-Means算法是一种经典的聚类算法,有很多优点,也存在许多不足.比如初始聚类数K要事先指定,初始聚类中心选择存在随机性,算法容易生成局部最优解,受孤立点的影响很大等.文中主要针对K-Means算法初始聚类中心的选择以及孤立点问题加以改进,首先计算所有数据对象之间的距离,根据距离和的思想排除孤立点的影响,然后提出了一种新的初始聚类中心选择方法,并通过实验比较了改进算法与原算法的优劣.实验表明,改进算法受孤立点的影响明显降低,而且聚类结果更接近实际数据分布.【期刊名称】《计算机技术与发展》【年(卷),期】2011(021)002【总页数】4页(P62-65)【关键词】K-Means算法;初始聚类中心;孤立点【作者】周爱武;于亚飞【作者单位】安徽大学,计算机科学与技术学院,安徽,合肥,230039;安徽大学,计算机科学与技术学院,安徽,合肥,230039【正文语种】中文【中图分类】TP301.6聚类分析是数据挖掘领域中重要的研究课题,用于发现大规模数据集中未知的对象类。

面向大型数据集的局部敏感哈希K−means 算法魏峰1,2, 马龙1,2(1. 煤炭科学技术研究院有限公司,北京 100013;2. 煤炭资源高效开采与洁净利用国家重点实验室,北京 100013)摘要:大型数据集高效处理策略是煤矿安全监测智能化、采掘智能化等煤矿智能化建设的关键支撑。
针对K−means 算法面对大型数据集时聚类高效性及准确性不足的问题,提出了一种基于局部敏感哈希(LSH )的高效K−means 聚类算法。
基于LSH 对抽样过程进行优化,提出了数据组构建算法LSH−G ,将大型数据集合理划分为子数据组,并对数据集中的噪声点进行有效删除;基于LSH−G 算法优化密度偏差抽样(DBS )算法中的子数据组划分过程,提出了数据组抽样算法LSH−GD ,使样本集能更真实地反映原始数据集的分布规律;在此基础上,通过K−means 算法对生成的样本集进行聚类,实现较低时间复杂度情况下从大型数据集中高效挖掘有效数据。
实验结果表明:由10个AND 操作与8个OR 操作组成的级联组合为最优级联组合,得到的类中心误差平方和(SSEC )最小;在人工数据集上,与基于多层随机抽样(M−SRS )的K−means 算法、基于DBS 的K−means 算法及基于网格密度偏差抽样(G−DBS )的K−means 算法相比,基于LSH−GD 的K−means 算法在聚类准确性方面的平均提升幅度分别为56.63%、54.59%及25.34%,在聚类高效性方面的平均提升幅度分别为27.26%、16.81%及7.07%;在UCI 标准数据集上,基于LSH−GD 的K−means 聚类算法获得的SSEC 与CPU 消耗时间(CPU−C )均为最优。
关键词:智慧矿山;大型数据集;K−means 聚类;局部敏感哈希;噪声点筛选;密度偏差抽样中图分类号:TD67 文献标志码:ALocality-sensitive hashing K-means algorithm for large-scale datasetsWEI Feng 1,2, MA Long 1,2(1. CCTEG China Coal Research Institute, Beijing 100013, China ;2. National Key Lab of Coal Resources High Efficient Mining and Clean Utilization, Beijing 100013, China)Abstract : Efficient processing strategy for large datasets is a key support for coal mine intelligent constructions, such as the intelligent construction of coal mine safety monitoring and mining. To address the problem of insufficient clustering efficiency and accuracy of the K-means algorithm for large datasets, a highly efficient K-means clustering algorithm based on locality-sensitive hashing (LSH) is proposed. Based on LSH, the sampling process is optimized, and a data grouping algorithm LSH-G is proposed. The large dataset is divided into subgroups and the noisy points in the dataset are removed effectively. Based on LSH-G, the subgroup division process in the density biased sampling (DBS) algorithm is optimized. And a data group sampling algorithm, LSH-GD, is proposed. The sample set can more accurately reflect the distribution law of the original dataset. On this basis, the K-means algorithm is used to cluster the generated sample set, achieving efficient mining of effective data from large datasets with low time complexity. The experimental results show that the收稿日期:2022-08-05;修回日期:2023-03-10;责任编辑:胡娴。

k-means聚类法标准化数值概述及解释说明1. 引言1.1 概述在数据分析和机器学习领域中,聚类算法是一种常用的无监督学习方法,它可以将具有相似特征的数据点划分为不同的组或簇。
其中,k-means聚类法是一种经典且广泛使用的聚类算法。
它通过迭代计算数据点与各个簇中心之间的距离,并将数据点划分到距离最近的簇中心。
k-means聚类法在数据挖掘、图像处理、模式识别等领域有着广泛的应用。
1.2 文章结构本文主要围绕着k-means聚类法以及标准化数值展开讨论。
首先介绍了k-means聚类法的原理和应用场景,详细解释了其算法步骤和常用的聚类质量评估指标。
接下来对标准化数值进行概述,并阐述了常见的标准化方法以及标准化所具有的优缺点。
随后,文章从影响因素分析角度探讨了k-means聚类算法与标准化数值之间的关系,并深入剖析了标准化在k-means中的作用及优势。
最后,通过实例解释和说明,对文中所述的理论和观点进行了验证与分析。
1.3 目的本文旨在向读者介绍k-means聚类法及其在数据分析中的应用,并深入探讨标准化数值在k-means聚类算法中扮演的重要角色。
通过本文的阐述,希望读者能够理解k-means聚类法的基本原理、运行步骤以及质量评估指标,并认识到标准化数值对于提高聚类算法性能以及结果准确性的重要性。
最终,通过结论与展望部分,给出对未来研究方向和应用领域的展望和建议,为相关领域研究者提供参考和启示。
2. k-means聚类法:2.1 原理及应用场景:k-means聚类算法是一种常用的无监督学习方法,主要用于将数据集划分为k 个不同的簇(cluster)。
该算法基于距离度量来确定样本之间的相似性,其中每个样本被划分到距离最近的簇。
它的主要应用场景包括图像分割、文本分类、市场细分等。
2.2 算法步骤:k-means聚类算法具有以下几个步骤:1. 初始化: 选择k个随机点作为初始质心。
2. 分配: 对于每个数据点,计算其与各个质心之间的距离,并将其分配到最近的质心所属的簇中。
k-means 算法***************************************************************************一.算法简介k -means 算法,也被称为k -平均或k -均值,是一种得到最广泛使用的聚类算法。
它是将各个聚类子集内的所有数据样本的均值作为该聚类的代表点,算法的主要思想是通过迭代过程把数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个聚类内紧凑,类间独立。
这一算法不适合处理离散型属性,但是对于连续型具有较好的聚类效果。
二.划分聚类方法对数据集进行聚类时包括如下三个要点:(1)选定某种距离作为数据样本间的相似性度量k-means 聚类算法不适合处理离散型属性,对连续型属性比较适合。
因此在计算数据样本之间的距离时,可以根据实际需要选择欧式距离、曼哈顿距离或者明考斯距离中的一种来作为算法的相似性度量,其中最常用的是欧式距离。
下面我给大家具体介绍一下欧式距离。
假设给定的数据集 ,X 中的样本用d 个描述属性A 1,A 2…A d 来表示,并且d 个描述属性都是连续型属性。
数据样本x i =(x i1,x i2,…x id ), x j =(x j1,x j2,…x jd )其中,x i1,x i2,…x id 和x j1,x j2,…x jd 分别是样本x i 和x j 对应d 个描述属性A 1,A 2,…A d 的具体取值。
样本xi 和xj 之间的相似度通常用它们之间的距离d(x i ,x j )来表示,距离越小,样本x i 和x j 越相似,差异度越小;距离越大,样本x i 和x j 越不相似,差异度越大。
欧式距离公式如下:(2)选择评价聚类性能的准则函数{}|1,2,...,m X x m total ==(),i j d x x =k-means 聚类算法使用误差平方和准则函数来评价聚类性能。
给定数据集X ,其中只包含描述属性,不包含类别属性。
K—means聚类算法综述摘要:空间数据挖掘是当今计算机及GIS研究的热点之一。
空间聚类是空间数据挖掘的一个重要功能.K—means聚类算法是空间聚类的重要算法。
本综述在介绍了空间聚类规则的基础上,叙述了经典的K-means算法,并总结了一些针对K-means算法的改进。
关键词:空间数据挖掘,空间聚类,K—means,K值1、引言现代社会是一个信息社会,空间信息已经与人们的生活已经密不可分。
日益丰富的空间和非空间数据收集存储于空间数据库中,随着空间数据的不断膨胀,海量的空间数据的大小、复杂性都在快速增长,远远超出了人们的解译能力,从这些空间数据中发现邻域知识迫切需求产生一个多学科、多邻域综合交叉的新兴研究邻域,空间数据挖掘技术应运而生.空间聚类分析方法是空间数据挖掘理论中一个重要的领域,是从海量数据中发现知识的一个重要手段。
K—means算法是空间聚类算法中应用广泛的算法,在聚类分析中起着重要作用。
2、空间聚类空间聚类是空间数据挖掘的一个重要组成部分.作为数据挖掘的一个功能,空间聚类可以作为一个单独的工具用于获取数据的分布情况,观察每个聚类的特征,关注一个特定的聚类集合以深入分析。
空间聚类也可以作为其它算法的预处理步骤,比如分类和特征描述,这些算法将在已发现的聚类上运行。
空间聚类规则是把特征相近的空间实体数据划分到不同的组中,组间的差别尽可能大,组内的差别尽可能小。
空间聚类规则与分类规则不同,它不顾及已知的类标记,在聚类前并不知道将要划分成几类和什么样的类别,也不知道根据哪些空间区分规则来定义类。
(1)因而,在聚类中没有训练或测试数据的概念,这就是将聚类称为是无指导学习(unsupervised learning)的原因。
(2)在多维空间属性中,框定聚类问题是很方便的。
给定m个变量描述的n个数据对象,每个对象可以表示为m维空间中的一个点,这时聚类可以简化为从一组非均匀分布点中确定高密度的点群.在多维空间中搜索潜在的群组则需要首先选择合理的相似性标准.(2)已经提出的空间聚类的方法很多,目前,主要分为以下4种主要的聚类分析方法(3):①基于划分的方法包括K—平均法、K—中心点法和EM聚类法。
基于Hive的分布式K_means算法设计与研究作者:冯晓云陆建峰来源:《计算机光盘软件与应用》2013年第21期摘要:针对大数据的处理效率问题,论文主要应用Hadoop技术,探讨了分布式技术应用于大数据挖掘的编程模式。
论文以k_means算法作为研究对象,采用Hadoop的一个数据仓库工具——HIVE来实现该算法的并行化,并在结构化的UCI数据集上进行了实验,实验结果表明该方法具有优良的加速比和运行效率,适用于结构化海量数据的分析。
关键词:大数据;Hadoop;分布式;k-means中图分类号:TP393.02―大数据‖时代已经降临,在商业、经济及其他领域中,决策将日益基于数据和分析而作出,而并非基于经验和直觉[1]。
随着互联网和信息行业的发展,在日常运营中生成、累积的用户网络行为数据的规模是非常庞大的,以至于不能用G或T来衡量。
我们希望从这些结构化或半结构化的数据中学习到有趣的知识,但这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。
因此,并行化数据挖掘成为了当下的一个热门研究课题,其主要编程模式包括:数据并行模式,消息传递模式,共享内存模式以及后两种模式同时使用的混合模式[2][3]。
1 国内研究现状当前中国的云计算的发展正进入成长期,国内很多研究者正进入分布式的数据挖掘领域,利用国外的成熟平台,例如Hadoop来实现大数据的聚类等算法。
但是数据的多样性,文本多格式,造成对数据的操作有很大的难度,而如今大多数论文都利用了标准化的mapreduce方法来进行代码的编写,具有一定的通用性,但是Hadoop下还有许多的工具,能够简化m/r过程,同样对一定结构的数据具有很好的并行效果,但是这方面的研究比较少,因此本文引入了HIVE的运用,简化了数据的操作过程,利用类似标准的SQL语句对数据集进行运算,在一定程度上提高了并行化计算的效率。
2 Hadoop并行化基础数据挖掘(Data Mining)是对海量数据进行分析和总结,得到有用信息的知识发现的过程[4]。
浙江大学算法研究实验报告数据挖掘题目:K-means目录一、实验内容 (5)二、实验目的 (7)三、实验方法 (7)3.1软、硬件环境说明 (7)3.2实验数据说明 (7)图3-1 (7)3.3实验参数说明/软件正确性测试 (7)四、算法描述 (9)图4-1 (10)五、算法实现 (11)5.1主要数据结构描述 (11)图5-1 (11)5.2核心代码与关键技术说明 (11)5.3算法流程图 (14)六、实验结果 (15)6.1实验结果说明 (15)6.2实验结果比较 (21)七、总结 (23)一、 实验内容实现K-means 算法,其中该算法介绍如下:k-means 算法是根据聚类中的均值进行聚类划分的聚类算法。
输入:聚类个数k ,以及包含n 个数据对象的数据。
输出:满足方差最小标准的k 个聚类。
处理流程:Step 1. 从n 个数据对象任意选择k 个对象作为初始聚类中心; Step 2. 根据每个聚类对象的均值(中心对象),计算每个对象与这些中心对象的距离,并根据最小距离重新对相应对象进行划分; Step 3. 重新计算每个(有变化)聚类的均值(中心对象) Step 4. 循环Step 2到Step 3直到每个聚类不再发生变化为止;k-means 算法的工作过程说明如下:首先从n 个数据对象任意选择k 个对象作为初始聚类中心,而对于所剩下的其它对象,则根据它们与这些聚类中心的相似度(距离),分别将它们分配给与其最相似的(聚类中心所代表的)聚类。
然后,再计算每个所获新聚类的聚类中心(该聚类中所有对象的均值),不断重复这一过程直到标准测度函数开始收敛为止。
一般都采用均方差作为标准测度函数,具体定义如下:21∑∑=∈-=ki iiE C p m p (1)其中E 为数据库中所有对象的均方差之和,p 为代表对象的空间中的一个点,m i 为聚类C i 的均值(p 和m i 均是多维的)。
公式(1)所示的聚类标准,旨在使所获得的k 个聚类具有以下特点:各聚类本身尽可能的紧凑,而各聚类之间尽可能的分开。
重点要求:用于聚类的测试级不能仅为单独的一类属性,至少有两种属性值参与聚类。
二、实验目的通过实现K-means算法,加深对课本上聚类算法的理解,并对数据集做出较高的要求,以期锻炼我们的搜索查找能力。
最后自己实现K-means算法,可以加强我们的编程能力。
三、实验方法3.1软、硬件环境说明采用win7旗舰版(盗版)系统,用vs2010实现3.2实验数据说明实验数据,源于google的广告关键词推荐页面,在该页面输入关键词,会出现与该关键词相关的一些信息,包括月均搜索量,关键词价值等等,取出来在经过自己处理,就得到了我们需要的实验数据,包括关键词、月均搜索量、竞争力、估价以及关键词排名,包含两种属性。
部分数据如下:关键词月均搜索量竞争力建议出价排名模拟股票700.1427.89194股票交流300.1119.17160股票交易系统300.1711.46101股票交易5900.3131.86203gupiao10000.0615.94137股市投资200.29 2.8216股票趋势200.11 6.9555财经网19000.2213.38123股票书500.0689.06246图3-13.3实验参数说明/软件正确性测试我采用了各种数据对程序进行测试,出现一些数组越界bug,修改后再次测试,无问题,测试通过。
四、算法描述KMeans算法的基本思想是初始随机给定K个簇中心,按照最邻近原则把待分类样本点分到各个簇。
然后按平均法重新计算各个簇的质心,从而确定新的簇心。
一直迭代,直到簇心的移动距离小于某个给定的值。
K-Means聚类算法主要分为三个步骤:(1)第一步是为待聚类的点寻找聚类中心(2)第二步是计算每个点到聚类中心的距离,将每个点聚类到离该点最近的聚类中去(3)第三步是计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心反复执行(2)、(3),直到聚类中心不再进行大范围移动或者聚类次数达到要求为止下图展示了对n个样本点进行K-means聚类的效果,这里k取2:(a)未聚类的初始点集(b)随机选取两个点作为聚类中心(c)计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(d)计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心(e)重复(c),计算每个点到聚类中心的距离,并聚类到离该点最近的聚类中去(f)重复(d),计算每个聚类中所有点的坐标平均值,并将这个平均值作为新的聚类中心图4-1五、算法实现5.1主要数据结构描述这里我建造了一个data的结构体,如下:typedef vector<double> Tuple;//存储每条数据记录struct data{string s;//存储关键词Tuple tup;//存储属性信息};图5-15.2核心代码与关键技术说明5.2.1计算距离函数此函数用于计算两个元祖之间的距离,对于每个元祖的属性值,对于数值型的属性值(X1,X2,X3,X i,X n),我们用Y i代替X i来进行归一化处理,其中Y i计算公式如下:Y i=(X i - X min )/(X max -X min )对于序数型属性值(M 1,M 2,M 3,M i ,M n ), 我们用Q i 代替M i 进行归一化处理,其中Q i 计算公式如下:Q i=(Z(Q i )-1)/(Z (Total )-1) 其中Z (Q i )表示Q i 属于的组数,Z (Total )表示总共的组数,他们的计算规则如下:Z(Total )= kZ (Q i )= Q i/(dataNum/k )+1 (其中dataNum 为总数据量,K 为总分组数。
)归一化处理之后,在计算两个元祖之间的欧式几何距离,具体实现代码如下:double getDistXY(const data &t1, const data &t2){double sum = 0,temp1=0,temp2=0,temp3=0,temp4=0;int zuBase,zu1,zu2; //确定分组依据zuBase=dataNum/k;zu1=t1.tup[4]/zuBase+1;//确定分组zu2=t2.tup[4]/zuBase+1;temp3=(zu1-1)/6;if(temp3>1)temp3=1;temp4=(zu2-1)/6;if(temp4>1)temp4=1;//修正序数度量temp1=(t1.tup[1]-10)/367990;temp2=(t2.tup[1]-10)/367990;sum+=(temp1-temp2)*(temp1-temp2)+(temp3-temp4)*(temp3-temp4); for(int i=2; i<dimNum-1; ++i){sum += (t1.tup[i]-t2.tup[i]) * (t1.tup[i]-t2.tup[i]);}return sqrt(sum);}5.2.2重新分簇对于每个簇,算出当前每个元祖与各个质心间的距离,重新判定该元组属于哪一个簇,代码如下:int clusterOfTuple(data means[],const data& tuple){double dist=getDistXY(means[0],tuple);double tmp;int label=0;//标示属于哪一个簇for(int i=1;i<k;i++){tmp=getDistXY(means[i],tuple);if(tmp<dist) {dist=tmp;label=i;}}return label;}5.3算法流程图六、实验结果6.1实验结果说明进过归一化操作聚类效果比较明显,可以看到大家对股票的哪一方面比较关心,并且给广告投资商一些参考,帮助其决定把广告投到哪一个关键词上,进而得到的关注量最大同时花费最少。
同时,考虑到结果的聚类性,用户搜索某个关键词时,可以推荐给他同一个簇内其他的关键词。
具体实验结果如下:第1个簇:关键词编号搜索量竞争价值估价排名股票学习网 8 20 0.11 27.19 193 股票初学 15 20 0.16 22.41 171 指数股票 16 20 0.07 26.66 191 怎样看股票 18 20 0.14 18.93 155 股票入门教程 30 20 0.11 17.5 149 购买股票 31 20 0.2 23.75 180 股票交流 35 30 0.11 19.17 160 中国股市论坛 44 30 0.16 23.98 182 上海股票指数 50 30 0.04 29.41 196 股票开户流程 54 30 0.1 25.71 187 股票怎么看 56 30 0.1 19.84 164 股票投资入门 62 40 0.23 21.38 170 美国股票软件 67 40 0.28 20.74 168 虚拟股票 72 40 0.13 30.66 199 股票市盈率 81 50 0.07 24.42 184 股市走势 86 50 0.1 17.05 145 查股票 90 50 0.21 17.02 143 股票公式 102 70 0.07 20.73 167 如何购买股票 104 70 0.17 19.73 163 航空股票 105 70 0.12 19 157 股票买卖 109 70 0.24 22.86 173 中国远洋股票 111 70 0.05 30.55 198 模拟股票 114 70 0.14 27.89 194 股票走势 117 70 0.11 21.33 169 股票基础知识 119 70 0.11 24.16 183 股票公司 125 90 0.36 17.04 144 股票交易费用 129 90 0.13 24.47 185 中国铁建股票 131 90 0.09 19.05 158股票分析软件 132 90 0.24 22.7 172 新手股票 141 110 0.18 23.92 181 谷歌股票 142 110 0.04 20.07 165 股票网 161 140 0.2 17.47 148 中国中铁股票 164 140 0.06 27.17 192 怎么买股票 165 140 0.19 17.86 152 股票技术分析 168 140 0.07 19.37 162 中国联通股票 172 170 0.05 25.72 188 搜狐股票 173 170 0.06 19.08 159 新浪财经股票首页 174 170 0.03 23.3 176 香港股票查询 183 210 0.48 23.4 177 股票交易时间 189 210 0.06 30.44 197 股票交易所 190 210 0.17 30.78 201 股票行 194 210 0.49 17.17 146 如何看股票 196 210 0.11 18.66 154 基金股票 197 210 0.21 18.98 156 股指 198 210 0.04 30.73 200 百度股票 202 260 0.05 32.88 204 股票行情查询 205 260 0.04 22.86 174 股票投资 212 320 0.32 25.64 186 股票網 214 320 0.38 20.35 166 股票知识 215 320 0.12 17.18 147 股票新手 228 390 0.23 23.69 179 股票交易 233 590 0.31 31.86 203 股票软件 234 590 0.2 29.04 195 新加坡股票 235 590 0.35 18.01 153 股票入门 242 880 0.15 26.05 189 中国股票 248 1300 0.11 30.84 202 炒股 250 1900 0.15 26.28 190 gushi 252 2400 0.01 19.18 161 香港股票 254 2400 0.46 23.26 175 新浪股票 256 2900 0.05 17.71 151 港股 260 6600 0.21 23.52 178 股市 266 368000 0.01 17.51 150 第2个簇:关键词编号搜索量竞争价值估价排名股票模拟软件 24 20 0.13 75.05 237 股票自动交易软件 26 20 0.13 77.44 239 新浪股票博客 36 30 0.06 80.16 240 股票怎么买 73 40 0.21 92.89 248 股票技巧 80 50 0.23 85.53 244 新股票 89 50 0.11 68.96 235 股票书 92 50 0.06 89.06 246 联通股票 93 50 0.03 104.99 252股票基本知识 107 70 0.09 68.56 234 股票大盘 127 90 0.1 103.13 251 股票研究 133 90 0.11 80.77 241 中国重工股票 138 90 0.1 90.51 247 中国股票行情 148 110 0.07 76.05 238 股票网上开户 159 140 0.1 103.04 250 股票交易手续费 166 140 0.12 85.11 243 石油股票 191 210 0.18 93.22 249 台湾股票 200 210 0.23 71.25 236 澳洲股票 218 390 0.21 85.95 245 新浪股市 223 390 0.04 84.8 242 第3个簇:关键词编号搜索量竞争价值估价排名江苏阳光股票 29 20 0.1 154.15 262 今日股市行情大盘 49 30 0.12 117.53 253 怎么玩股票 52 30 0.1 133.11 257 银行股票 68 40 0.11 123.23 254 股票计算器 74 40 0.1 144.89 259 股票频道 101 70 0.04 130.46 255 a股大盘 126 90 0.06 174.74 264 证券股 137 90 0.03 150.32 260 中国石化股票 158 140 0.01 142.11 258 st股票 169 140 0.05 168.23 263 民生银行股票 193 210 0.06 130.61 256 招商银行股票 210 320 0.03 152.85 261 第4个簇:关键词编号搜索量竞争价值估价排名美国股票交易软件 2 10 0.32 4.65 34 股票价格查询 4 10 0.09 1.83 11 投资美国股票 5 10 0.38 0.1 1 股票书籍下载 6 10 0.12 5.8 44 股票趋势 11 20 0.11 6.95 55 股市投资 12 20 0.29 2.82 16 股票怎么开户 13 20 0.16 0.68 4 股票下载 17 20 0.2 3.4 20 世界股市行情 19 20 0.13 0.18 3 加拿大股票交易 21 20 0.17 4.29 32 怎么买美国股票 22 20 0.28 2.63 15 购买美国股票 23 20 0.18 3.42 21 股票购买 27 20 0.14 2.42 13 股票入门知识 38 30 0.12 4.35 33 股市资讯网 53 30 0.08 1.05 8 中国股指期货 58 40 0.05 5.37 42 如何买美国股票 61 40 0.26 3.51 23深圳股票交易所 65 40 0.13 7.27 56 股市场 69 40 0.21 1.39 10 股票操盘手 76 40 0.05 0.85 6 北美股票 78 50 0.22 4.75 36 股市财经 85 50 0.1 0.1 2 今日股市行情大盘走势91 50 0.13 0.97 7 股票信息 98 50 0.23 3.21 19 美国股票市场 100 70 0.29 5.36 41 怎样买股票 108 70 0.24 6.11 48 今天股票行情 110 70 0.22 6.44 51 股票基础 122 70 0.07 3.96 25 a股新股 124 90 0.05 4.07 28 股票怎么玩 130 90 0.16 2.56 14 股市指数 136 90 0.09 5.68 43 美国股票开户 144 110 0.23 6.66 53 香港股票行情 147 110 0.5 6.62 52 投资股票 149 110 0.29 4.98 37 新加坡股票交易所 150 110 0.14 1.22 9 全球股票 151 110 0.13 2.97 18 巴菲特股票 157 110 0.07 3.48 22 a股行情 170 140 0.09 6.21 50 人民网新闻 171 170 0.2 3.97 26 股票价格 176 170 0.13 7.32 57 股票资讯 186 210 0.16 4.09 29 如何玩股票 203 260 0.14 4.7 35 股票查询 204 260 0.15 6.95 54 qq股票 206 260 0.08 5.86 45 什么是股票 207 260 0.1 3.68 24 加拿大股票 217 390 0.08 4.04 27 股票市场 220 390 0.22 4.23 31 股票型基金 226 390 0.24 4.18 30 a股基金 227 390 0.39 5.3 40 马来西亚股票 232 590 0.15 2.9 17 雅虎股票 237 720 0.15 5.88 46 股票消息 238 720 0.21 2.11 12 今日股票行情 243 880 0.2 6.19 49 美国股票 244 880 0.31 5.3 39 新浪网新闻 253 2400 0.06 0.72 5 財經網 261 8100 0.21 5.19 38 第5个簇:关键词编号搜索量竞争价值估价排名中国股市大盘 33 30 0.04 50.39 227 香港股票软件 39 30 0.54 40.68 219财经资讯 41 30 0.07 45.02 223 怎么炒股票 42 30 0.11 49.45 225 股票短线 43 30 0.05 33.05 205 新浪股市行情 51 30 0.04 33.96 206 股市中国 57 30 0.06 53.1 228 股票图 79 50 0.1 39.41 216 股票预测 84 50 0.04 39.11 214 同花顺股票 88 50 0.06 39.06 213 股市新闻 116 70 0.15 53.13 229 股票交易软件 128 90 0.21 38.16 211 股票学习 145 110 0.08 61.42 233 股票入门基础知识 153 110 0.14 39.81 218 中国股票市场 162 140 0.14 49.94 226 和讯股票 179 170 0.05 58.63 231 股票指数 181 210 0.06 34.19 209 tcl股票 184 210 0.04 59.64 232 股票吧 185 210 0.04 36.77 210 股价 192 210 0.05 46.88 224 网易股票 211 320 0.1 42.09 221 炒股票 216 390 0.25 41.99 220 新浪财经股票 221 390 0.12 33.99 207 中国股市行情 229 480 0.13 39.39 215 中石化股票 231 590 0.09 43.83 222 股票开户 236 590 0.17 55.28 230 苹果股票 240 720 0.06 39.59 217 证券 247 1300 0.04 38.53 212 第6个簇:关键词编号搜索量竞争价值估价排名模拟股票游戏 1 10 0.07 11.78 105 同花顺股票软件 3 10 0.1 16.73 140 买什么股票好 7 10 0.13 14.45 127 股票证券 9 20 0.13 12.9 118 新浪网股票 10 20 0.09 9.45 84 新浪财经新闻 14 20 0.05 12.35 110 上证股票 20 20 0.09 11.52 102 学股票 25 20 0.14 12.85 116 怎样炒股票 28 20 0.23 7.72 58 中国股票网 32 20 0.15 12.59 112 股票交易系统 34 30 0.17 11.46 101 今日股票行情查询 37 30 0.16 9.87 89 股票自动交易 45 30 0.08 14.92 131 买美国股票 46 30 0.5 9.26 80 如何买卖股票 47 30 0.22 8.48 69美国股票交易 48 30 0.33 8.99 78 如何购买美国股票 55 30 0.3 8.62 72 格力股票 59 40 0.08 9.82 88 股票教程 60 40 0.09 12.03 107 指数期货 63 40 0.08 12.11 108 股票代码查询 66 40 0.1 10.45 92 如何选股票 70 40 0.07 7.96 62 股票走势图 71 40 0.11 9.48 85 股票新浪 75 40 0.06 8.55 71 腾讯财经股票 77 40 0.12 14.85 129 稀土股票 82 50 0.14 13.05 119 股票行情软件 83 50 0.12 12.77 114 股票模拟 94 50 0.13 9.78 86 股票新闻 95 50 0.16 8.9 75 股票入门书籍 96 50 0.04 13.81 124 财经股票 97 50 0.66 15.39 134 股票期货 99 50 0.1 8.36 68 股票网站 103 70 0.13 13.17 120 股票工具 106 70 0.25 10.63 94 股票游戏 112 70 0.08 14.45 128 如何炒股票 113 70 0.23 8.04 65 香港股票开户 115 70 0.7 10.98 96 如何投资股票 118 70 0.34 9.36 82 财经新闻网 120 70 0.47 7.77 60 紫金矿业股票 121 70 0.1 13.27 121 美国股票行情 123 90 0.31 9.14 79 创业板股票 134 90 0.06 14.12 126 鸿海股票 135 90 0.07 7.74 59 新上市股票 139 110 0.18 8.83 74 建设银行股票 140 110 0.05 15.77 136 中國股票市場 143 110 0.27 16.81 141 股票走勢 146 110 0.23 8.53 70 股票估值 152 110 0.11 14.07 125 中国证券 154 110 0.03 11.29 99 香港股票交易所 155 110 0.52 12.22 109 股票是什么 156 110 0.1 9.32 81 买股票 160 140 0.22 15.34 133 财经频道 163 140 0.02 15.96 138 股票手续费 167 140 0.12 16.67 139 如何买股票 175 170 0.18 15.22 132 股市大盘 177 170 0.07 12.88 117 股票佣金 178 170 0.37 15.56 135 股票报价 180 170 0.45 8.04 66 看股票 182 210 0.09 11.25 98深圳股票 187 210 0.29 12.65 113 股票價 188 210 0.55 11.58 103 股票推荐 195 210 0.16 13.33 122 股票代码 199 210 0.07 8.02 63 日本股票 201 260 0.17 12.36 111 今日股票 208 260 0.18 8.96 77 股票資訊 209 260 0.26 11.77 104 中國股市行情 213 320 0.07 7.88 61 股票基金 219 390 0.26 16.97 142 股票配资 224 390 0.19 8.94 76 股票论坛 225 390 0.09 12.79 115 上海股票 230 480 0.08 11.88 106 全球股市指數 239 720 0.01 9.39 83 股市報價 241 720 0.2 8.02 64 gupiao 245 1000 0.06 15.94 137 腾讯股票 246 1000 0.05 10.86 95 财经新闻 249 1300 0.19 10.48 93 财经网 251 1900 0.22 13.38 123 今日股市行情 255 2400 0.06 8.12 67 股價 257 3600 0.08 11.08 97 股票分析 258 4400 0.06 11.38 100 财经 259 5400 0.15 10.31 91 股票行情 262 8100 0.15 10.22 90 基金 263 22200 0.41 9.81 87 美股 264 27100 0.06 8.62 73 股票 265 74000 0.27 14.87 130 第7个簇:关键词编号搜索量竞争价值估价排名股票交易平台 87 50 0.43 253.84 265 股票期权 222 390 0.05 380.25 2666.2实验结果比较拿来比较的算法用时:5600ms我的算法用时:4399ms从性能上看,我的算法好一点。