数据挖掘分类算法研究综述终板
- 格式:doc
- 大小:44.00 KB
- 文档页数:3


分析Technology AnalysisI G I T C W 技术136DIGITCW2021.021 决策树分类算法1.1 C 4.5分类算法的简介及分析C4.5分类算法在我国是应用相对较早的分类算法之一,并且应用非常广泛,所以为了确保其能够满足在对规模相对较大的数据集进行处理的过程中有更好的实用性能,对C4.5分类算法也进行了相应的改进。
C4.5分类算法是假如设一个训练集为T ,在对这个训练集建造相应的决策树的过程中,则可以根据In-formation Gain 值选择合理的分裂节点,并且根据分裂节点的具体属性和标准,可以将训练集分为多个子级,然后分别用不同的字母代替,每一个字母中所含有的元组的类别一致。
而分裂节点就成为了整个决策树的叶子节点,因而将会停止再进行分裂过程,对于不满足训练集中要求条件的其他子集来说,仍然需要按照以上方法继续进行分裂,直到子集所有的元组都属于一个类别,停止分裂流程。
决策树分类算法与统计方法和神经网络分类算法相比较具备以下优点:首先,通过决策树分类算法进行分类,出现的分类规则相对较容易理解,并且在决策树中由于每一个分支都对应不同的分类规则,所以在最终进行分类的过程中,能够说出一个更加便于了解的规则集。
其次,在使用决策树分类算法对数据挖掘中的数据进行相应的分类过程中,与其他分类方法相比,速率更快,效率更高。
最后,决策树分类算法还具有较高的准确度,从而确保在分类的过程中能够提高工作效率和工作质量。
决策树分类算法与其他分类算法相比,虽然具备很多优点,但是也存在一定的缺点,其缺点主要体现在以下几个方面:首先,在进行决策树的构造过程中,由于需要对数据集进行多次的排序和扫描,因此导致在实际工作过程中工作量相对较大,从而可能会使分类算法出现较低能效的问题。
其次,在使用C4.5进行数据集分类的过程中,由于只是用于驻留于内存的数据集进行使用,所以当出现规模相对较大或者不在内存的程序及数据即时无法进行运行和使用,因此,C4.5决策树分类算法具备一定的局限性。

数据挖掘中聚类算法研究综述随着数据量的不断增加,数据挖掘成为了探索数据背后规律的一种重要方法。
而聚类算法作为数据挖掘中的一种基本技术,其在数据分析、模式识别、生物信息学、社交网络分析等领域都有着广泛的应用。
本文就对数据挖掘中的聚类算法进行了研究和总结,旨在对聚类算法的原理、特点、应用等方面进行探讨。
一、聚类算法的基本原理聚类算法是指将一组对象划分为若干个组或类,使得组内对象之间的相似度尽可能大,组间对象之间的相似度尽可能小,从而达到数据分类和分析的目的。
聚类算法的基本原理包括以下三个方面:1. 相似度度量:聚类算法的基础在于相似度度量,即将每个对象之间的相似度进行计算。
相似度度量可以采用欧几里得距离、曼哈顿距离、余弦相似度等多种方法。
2. 聚类分配:聚类分配是指将每个对象划分到合适的聚类中。
聚类分配可以通过最近邻法、k-means算法等实现。
3. 聚类更新:聚类更新是指对各个聚类进行调整,使得聚类内对象之间的相似度尽可能大,聚类间对象之间的相似度尽可能小。
聚类更新可以采用层次聚类法、DBSCAN算法等。
二、聚类算法的分类根据聚类算法的不同特点和应用场景,可以将聚类算法分为以下几种类型:1. 基于距离的聚类算法:包括最近邻法、k-means算法、k-medoid 算法等。
2. 基于密度的聚类算法:包括DBSCAN算法、OPTICS算法等。
3. 基于层次的聚类算法:包括凝聚层次聚类法、分裂层次聚类法等。
4. 基于模型的聚类算法:包括高斯混合模型聚类、EM算法等。
三、聚类算法的应用聚类算法在各种领域中都有着广泛的应用,包括数据分析、模式识别、社交网络分析、生物信息学等。
下面简单介绍一下聚类算法在这些领域中的应用:1. 数据分析:聚类算法可以对数据进行分类和分组,从而提取出数据中的规律和趋势,帮助人们更好地理解和利用数据。
2. 模式识别:聚类算法可以对图像、声音、文本等数据进行分类和分组,从而实现对数据的自动识别和分类。

数据挖掘各类算法综述了解数据挖掘的各类算法的原理和应用领域以及优缺点对于在实际的工作中选择合适的方法,并加以改进有很重要的指导意义。
1.1 关联规则挖掘算法R.Agrawal等人于1993年首先提出了挖掘顾客交易数据库中项集间的关联规则问题,其核心方法是基于频集理论的递推方法。
此后人们对关联规则的挖掘问题进行了大量研究,包括对Apriori算法优化、多层次关联规则算法、多值属性关联规则算法、其他关联规则算法等,以提高算法挖掘规则的效率。
1)Apriori算法Apriori算法是最有影响的挖掘布尔关联规则频繁项集的算法。
算法Apriori利用“在给定的事务数据库D中,任意频繁项集的非空子集都必须也是频繁的”这一原理对事务数据库进行多次扫描,第一次扫描得出频繁1-项集L ,第k (k>1)次扫描前先利用第k-1次扫描的结果(即频繁k-1项集L k-1)和函数Apriori—gen产生候选k-项集C k,然后在扫描过程中确定C k女中每个元素的支持数,最后在每次扫描结束时计算出频繁k-项集L k,算法在当频繁n-项集为空时结束。
算法:Apriori,使用根据候选生成的逐层迭代找出频繁项集输入:事务数据库D;最小支持度阈值min_sup输出:D中的频繁项集L方法:(1) L1 = find_frequent_1–itemsets(D);(2)for (k = 2;L k-1 ≠Φ;k ++){(3) C k = apriori_gen(L k-1 , min_sup);(4)for each transaction t ∈ D { //scan D for counts(5) C t= subset (C k,t); //get the subset of t that are candidates(6)for each candidate c ∈ C t(7) c.count++;(8) }∕ (9) L k = { c ∈C k | c.count ≥min_sup };(10) }(11) return L = ∪k L k ;// apriori_gen 用来产生候选k 项集procedure apriori_gen(L k-1:(k-1)项频繁集, min_sup :最小值尺度 )(1) for each itemset l 1 ∈ L k-1(2) for each itemset l 2 ∈ L k-1(3) if (l 1[1]= l 2[1])∧(l 1[2]= l 2[2]) ∧…∧(l 1[k-2]= l 2[k-2]) ∧(l 1[k-1]< l 2[k-1])then {(4) c = l 1 自连接 l 2 ; //产生候选项集(5) if has_infrequent_subset (c , L k-1 ) then(6) delete c; //根据性质作剪枝操作(7) else add c to C k ;(8) }(9) return C k ;//procedure has_infrequent_subse (c , L k-1 )(1) for each (k-1)-subset s of c(2) if s ∈ Lk-1 then (3) return True;(4) return false;appriori_gen做两个动作:连接和剪枝。


数据挖掘算法综述数据挖掘算法综述随着信息技术的不断发展,数据量呈现爆炸式增长,如何从海量数据中提取有用的信息成为了一个重要的问题。
数据挖掘技术应运而生,它是一种从大量数据中自动提取模式、关系、规律等信息的技术。
数据挖掘算法是数据挖掘技术的核心,本文将对常用的数据挖掘算法进行综述。
1.分类算法分类算法是数据挖掘中最常用的一种算法,它通过对已知数据进行学习,建立分类模型,然后将未知数据分类到相应的类别中。
常用的分类算法包括决策树、朴素贝叶斯、支持向量机等。
决策树是一种基于树形结构的分类算法,它通过对数据进行分裂,构建一棵树形结构,从而实现对数据的分类。
朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它假设各个特征之间相互独立,通过计算先验概率和条件概率来进行分类。
支持向量机是一种基于间隔最大化的分类算法,它通过找到一个最优的超平面来实现分类。
2.聚类算法聚类算法是一种将数据分成不同组的算法,它通过对数据进行相似性度量,将相似的数据归为一类。
常用的聚类算法包括K均值、层次聚类、DBSCAN等。
K均值算法是一种基于距离的聚类算法,它通过将数据分成K个簇,使得簇内的数据相似度最大,簇间的数据相似度最小。
层次聚类算法是一种基于树形结构的聚类算法,它通过不断合并相似的簇,最终形成一棵树形结构。
DBSCAN算法是一种基于密度的聚类算法,它通过定义密度可达和密度相连的点来进行聚类。
3.关联规则算法关联规则算法是一种用于挖掘数据中项集之间关系的算法,它通过发现数据中的频繁项集,进而发现项集之间的关联规则。
常用的关联规则算法包括Apriori算法、FP-Growth算法等。
Apriori算法是一种基于频繁项集的关联规则算法,它通过不断扫描数据集,找到频繁项集,然后根据频繁项集生成关联规则。
FP-Growth 算法是一种基于FP树的关联规则算法,它通过构建FP树,发现频繁项集,然后根据频繁项集生成关联规则。
4.异常检测算法异常检测算法是一种用于发现数据中异常值的算法,它通过对数据进行分析,发现与其他数据不同的数据点。

数据挖掘中分类算法综述分类算法是数据挖掘中最常用的一种算法之一,它可以根据给定的数据集将其划分为不同的类别。
分类算法的应用涵盖了各个领域,如金融、医疗、电子商务等。
本文将对数据挖掘中常用的分类算法进行综述。
1. 决策树算法决策树算法是一种基于树形结构的分类算法,它可以根据给定的数据集构建一棵树,从而对未知的数据进行分类。
决策树的节点包括内部节点和叶子节点,内部节点用于分裂数据,而叶子节点则表示最终的分类结果。
决策树算法具有易于理解、可解释性强、处理缺失数据等优点,但是容易出现过拟合的问题。
2. 朴素贝叶斯算法朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,它假设所有的特征都是相互独立的。
根据给定的数据集,朴素贝叶斯算法可以计算出不同类别的先验概率和条件概率,从而对未知的数据进行分类。
朴素贝叶斯算法具有计算速度快、对于高维数据具有较好的表现等优点,但是对于特征之间存在相关性的数据集表现不佳。
3. K近邻算法K近邻算法是一种基于距离度量的分类算法,它假设样本点最近的K个邻居具有相似的特征,从而将未知的数据分类为出现最多的那个类别。
K近邻算法具有易于理解、对于非线性数据具有较好的表现等优点,但是对于维度较高的数据集表现不佳。
4. 支持向量机算法支持向量机算法是一种基于最大间隔分类的算法,它通过将数据投影到高维空间中,从而找到一个最优的超平面,将不同的类别分开。
支持向量机算法具有对于高维数据具有较好的表现、能够处理非线性数据等优点,但是对于样本量较大、参数调整困难等问题仍存在挑战。
5. 神经网络算法神经网络算法是一种模拟人类神经系统的分类算法,它由多层神经元组成,每个神经元接收输入信号并产生输出信号。
通过调整神经元之间的连接权值,神经网络可以对未知的数据进行分类。
神经网络算法具有对于非线性数据具有较好的表现、具有学习能力等优点,但是容易出现过拟合的问题。
分类算法在数据挖掘中具有重要的应用价值。
不同的分类算法具有各自的优缺点,需要根据具体的应用场景进行选择。

ISSN 100020054CN 1122223 N 清华大学学报(自然科学版)J T singhua U niv (Sci &Tech ),2002年第42卷第6期2002,V ol .42,N o .65 387272730数据挖掘中的数据分类算法综述刘红岩, 陈 剑, 陈国青(清华大学经济管理学院,北京100084)收稿日期:2001202213基金项目:清华大学“九八五”基础研究项目作者简介:刘红岩(19682),女(汉),山东,讲师。
E 2m ail :hyliu @tsinghua .edu .cn摘 要:分类算法是数据挖掘中的最重要的技术之一。
通过对当前提出的最新的具有代表性的分类算法进行分析和比较,总结每类算法的各方面特性,从而便于研究者对已有的算法进行改进,提出具有更好性能的新的分类算法,同时方便使用者在应用时对算法的选择和使用。
关键词:数据挖掘;分类;关联规则中图分类号:T P 311;T P 391文献标识码:A文章编号:100020054(2002)0620727204Rev iew of cla ssif ica tion a lgor ithm sfor da ta m i n i ngL I U Hongya n ,CHEN J ia n ,CHEN Guoq ing(School of Econo m ics and M anage men t ,Tsi nghua Un iversity ,Be ij i ng 100084,Chi na )Abstract :C lassificati on is one of the mo st i m po rtant techniques in data m ining .T h is paper summ arizes the m ain features of every algo rithm by analyzing and comparing a variety of typ ical classifiers to p rovide a basis fo r i m p roving o ld algo rithm s o r develop ing new effective ones .T he summ ary can also be used to select these data m ining techniques fo r new app licati ons .Key words :data m ining;classificati on;associati on rules 分类是数据挖掘中应用领域极其广泛的重要技术之一,至今已经提出很多算法。


《数据挖掘》数据挖掘分类算法综述专业:计算机科学与技术专业学号:S*************指导教师:***时间:2011年08月21日数据挖掘分类算法综述数据挖掘出现于20世纪80年代后期,是数据库研究中最有应用价值的新领域之一。
它最早是以从数据中发现知识(KDD,Knowledge Discovery in Database)研究起步,所谓的数据挖掘(Data Mining,简称为DM),就从大量的、不完全的、有噪声的、模糊的、随机的、实际应用的数据中提取隐含在其中的、人们不知道的但又有用的信息和知识的过程。
分类是一种重要的数据挖掘技术。
分类的目的是根据数据集的特点构造一个分类函数或分类模型(也常常称作分类器)。
该模型能把未知类别的样本映射到给定类别中的一种技术。
1. 分类的基本步骤数据分类过程主要包含两个步骤:第一步,建立一个描述已知数据集类别或概念的模型。
如图1所示,该模型是通过对数据库中各数据行内容的分析而获得的。
每一数据行都可认为是属于一个确定的数据类别,其类别值是由一个属性描述(被称为类别属性)。
分类学习方法所使用的数据集称为训练样本集合,因此分类学习又可以称为有指导学习(learning by example)。
它是在已知训练样本类别情况下,通过学习建立相应模型,而无指导学习则是在训练样本的类别与类别个数均未知的情况下进行的。
通常分类学习所获得的模型可以表示为分类规则形式、决策树形式或数学公式形式。
例如,给定一个顾客信用信息数据库,通过学习所获得的分类规则可用于识别顾客是否是具有良好的信用等级或一般的信用等级。
分类规则也可用于对今后未知所属类别的数据进行识别判断,同时也可以帮助用户更好的了解数据库中的内容。
图1 数据分类过程中的学习建模第二步,利用所获得的模型进行分类操作。
首先对模型分类准确率进行估计,例如使用保持(holdout)方法。
如果一个学习所获模型的准确率经测试被认为是可以接受的,那么就可以使用这一模型对未来数据行或对象(其类别未知)进行分类。
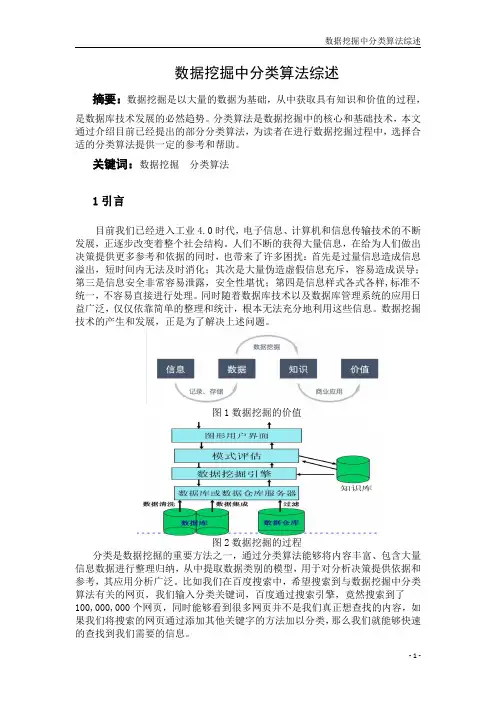
数据挖掘中分类算法综述摘要:数据挖掘是以大量的数据为基础,从中获取具有知识和价值的过程,是数据库技术发展的必然趋势。
分类算法是数据挖掘中的核心和基础技术,本文通过介绍目前已经提出的部分分类算法,为读者在进行数据挖掘过程中,选择合适的分类算法提供一定的参考和帮助。
关键词:数据挖掘分类算法1引言目前我们已经进入工业4.0时代,电子信息、计算机和信息传输技术的不断发展,正逐步改变着整个社会结构。
人们不断的获得大量信息,在给为人们做出决策提供更多参考和依据的同时,也带来了许多困扰:首先是过量信息造成信息溢出,短时间内无法及时消化;其次是大量伪造虚假信息充斥,容易造成误导;第三是信息安全非常容易泄露,安全性堪忧;第四是信息样式各式各样,标准不统一,不容易直接进行处理。
同时随着数据库技术以及数据库管理系统的应用日益广泛,仅仅依靠简单的整理和统计,根本无法充分地利用这些信息。
数据挖掘技术的产生和发展,正是为了解决上述问题。
图1数据挖掘的价值图2数据挖掘的过程分类是数据挖掘的重要方法之一,通过分类算法能够将内容丰富、包含大量信息数据进行整理归纳,从中提取数据类别的模型,用于对分析决策提供依据和参考,其应用分析广泛。
比如我们在百度搜索中,希望搜索到与数据挖掘中分类算法有关的网页,我们输入分类关键词,百度通过搜索引擎,竟然搜索到了100,000,000个网页,同时能够看到很多网页并不是我们真正想查找的内容,如果我们将搜索的网页通过添加其他关键字的方法加以分类,那么我们就能够快速的查找到我们需要的信息。
2分类的定义和过程2.1分类的定义分类就是通过收集大量的现有样本数据,构成已知数据训练集,每个样本都可能具有多个属性,将其中一个属性作为样本归类的标准,通过对已知类别的训练集的分析,用样本的其他属性建立一个关于类别属性准确划分的模型,以便用来判定新的测试数据的类别。
图3分类的定义示意图2.2分类的过程对样本数据进行分类,需要经过两个基本步骤。
数据挖掘中分类算法的研究与应用数据挖掘是指通过自动或半自动的方法从大量数据中发现潜在模式、关系和规律的过程。
而分类算法则是数据挖掘中的重要一环,它可以帮助我们将数据进行分类,找到其中的关联规律。
分类算法在各个领域都有着广泛的应用,比如医疗诊断、金融风险评估、舆情分析等。
本文将对数据挖掘中分类算法的研究与应用进行探讨,希望能够给读者带来一些启发和思考。
一、分类算法的研究1.传统分类算法传统的分类算法主要包括决策树、朴素贝叶斯、支持向量机等。
这些算法在分类任务中有着较好的效果,但也存在一些问题,比如对于非线性可分数据的处理能力有限,对于大规模数据的处理速度较慢等。
2.深度学习分类算法近年来,随着深度学习的发展,深度学习在分类任务中也取得了很好的效果。
深度学习的特点是可以学习到数据中的高级抽象特征,对非线性可分数据有很好的处理能力,而且在大规模数据下也能够取得较快的处理速度。
深度学习正在逐渐成为分类算法研究的热点。
集成学习是一种将多个分类器集成起来进行决策的方法。
通过结合多个分类器的判断,可以得到更加稳定、准确的分类结果。
目前,集成学习在分类算法研究中也得到了广泛的应用。
1.医疗诊断在医疗领域,数据挖掘的分类算法可以帮助医生对患者进行诊断和预测疾病的风险。
根据患者的个人信息和检测数据,可以利用分类算法来判断患者是否患有某种疾病,以及预测患病的可能性。
这对于医生提高诊断准确性和预防疾病都有着积极的意义。
2.金融风险评估在金融领域,数据挖掘的分类算法可以用来评估客户的信用风险、贷款违约的可能性等。
利用这些算法,金融机构可以更好地控制风险,提高贷款的准确性,降低贷款的损失。
3.舆情分析在舆情分析中,分类算法可以帮助企业对舆情信息进行分类,找到其中的关键信息和热点问题,从而更好地制定应对策略和改善产品服务。
三、分类算法的挑战与发展方向1.多样化数据的处理随着数据的多样化和复杂化,分类算法也面临着更多的挑战。
比如处理非线性可分数据、大规模数据、高维数据等,都是分类算法所面临的挑战。
68*本文系国家自然科学基金资助项目“用于数据挖掘的神经网络模型及其融合技术研究”(项目编号:60275020课题研究成果之一。
收稿日期:2006-03-25修回日期:2006-07-23本文起止页码:68-71,108钱晓东天津大学电气与自动化工程学院天津300072〔摘要〕对数据挖掘中的核心技术分类算法的内容及其研究现状进行综述。
认为分类算法大体可分为传统分类算法和基于软计算的分类法两类,主要包括相似函数、关联规则分类算法、K 近邻分类算法、决策树分类算法、贝叶斯分类算法和基于模糊逻辑、遗传算法、粗糙集和神经网络的分类算法。
通过论述以上算法优缺点和应用范围,研究者对已有算法的改进有所了解,以便在应用中选择相应的分类算法。
〔关键词〕数据挖掘分类软计算〔分类号〕TP183A Review on Classification Algorithms in Data Mining Qian XiaodongSchool of Electrical Engineering and A utomation, Tianjin University, Tianjin 300072〔Abstract〕As one of the kernel techniques in the data mining, it is necessary to summarize the research status of classification algorithm.Classification algorithms can be divided into classical algorithms and algorithms based on soft computing, primarily including similar function,classification algorithms based on association rule, K-nearest Neighbor, decision tree, Bayes network and classification algorithms based on fuzzy logic, genetic algorithm, neural network and rough sets. By presenting the advantages and disadvantages and the application range of the algorithms mentioned above, it will behelpful for people to improve and select algorithms for applications, and even to develop new ones.〔Keywords〕data mining classification soft computing数据挖掘中分类方法综述*1前言数据挖掘源于20世纪90年代中期,是一个既年轻又活跃的研究领域,涉及机器学习、模式识别、统计学、数据库、知识获取与表达、专家系统、神经网络、模糊数学、遗传算法等多个领域。
数据挖掘中的分类算法研究数据挖掘是指通过一定的数据分析工具和技术,从大量的数据中发现有意义的规律和知识,并用于决策支持、市场营销、产品设计等领域。
而数据挖掘中最重要的算法之一就是分类算法。
该算法可以将原始数据按照一定的规则进行分类,并根据这些分类结果进行数据分析。
一、分类算法概述分类算法是数据挖掘中一类比较常见的算法,它主要是按照数据的特征和属性将数据分成多个类别。
数据的分类可以是二元分类(例如一种有或没有、是或否),多类分类(例如颜色分类),或有序分类(例如一年级到八年级)等。
利用分类算法,可以对数据做出预测,判断数据属于哪一类。
数据挖掘中的分类算法可分为两种:有监督学习和无监督学习。
有监督学习算法需要训练数据集和测试数据集,通过对训练集的学习和预测,得到测试集的分类结果。
而无监督学习不需要训练集和测试集,其主要目的是通过对数据进行聚类,寻找数据的内部结构和规律。
二、有监督学习中的分类算法1. 决策树算法决策树算法是一种基于树状结构的分类算法。
该算法通过分析数据的特征和属性,生成一种树状结构,使数据能够被分类到相应的叶节点上。
决策树算法具有易于理解、易于实现、可处理不完整数据等优点。
但是其也存在过拟合的缺点。
2. 朴素贝叶斯算法朴素贝叶斯算法是一种基于概率统计的分类算法。
该算法通过学习已知数据集的概率分布,来预测新数据的分类概率。
朴素贝叶斯算法具有高效、可扩展、适用于高维数据等优点,但是其也需要假设属性之间相互独立,因此在某些情况下会出现分类误差较大的情况。
3. 支持向量机算法支持向量机算法是一种基于统计学习的分类算法。
该算法通过寻找最大化分类超平面的边距,来实现对数据的分类。
支持向量机算法具有处理高维数据、具有较强泛化能力等优点,但是其也存在训练速度慢、对核函数的选择敏感等问题。
三、无监督学习中的分类算法1. k-means算法k-means算法是一种基于聚类的无监督学习算法。
该算法通过将数据划分为k个簇,使得簇内数据的相似度较高,簇间数据的差异性较大。
数据挖掘中聚类算法研究综述引言随着大数据时代的到来,数据挖掘成为了一种重要的技术手段,用于从大量数据中发现有用的信息和隐藏的模式。
其中,聚类算法作为一种经典的数据挖掘技术,在各个领域都有广泛的应用。
本文将对数据挖掘中聚类算法进行综述,包括算法的分类、原理、应用等方面的研究。
聚类算法的分类聚类算法根据不同的原理和方法,可以分为以下几类:基于距离的聚类算法基于距离的聚类算法是将样本点间的距离作为相似度的度量依据,常见的算法包括K-means、DBSCAN、层次聚类等。
其中,K-means算法是最经典的聚类算法之一,通过最小化样本点与聚类中心的距离和来划分不同的簇。
DBSCAN算法则是一种基于密度的聚类算法,通过定义邻域半径和样本点的最小邻域数来确定核心对象和簇。
层次聚类算法则是一种自底向上或自顶向下的聚类方法,通过计算样本点之间的距离来不断合并或分割簇。
基于密度的聚类算法基于密度的聚类算法是根据样本点周围的密度来划分簇,不受距离的限制。
除了前面提到的DBSCAN算法,OPTICS算法也是一种常用的基于密度的聚类算法,它通过构建样本点的可达距离图来发现高密度和低密度区域。
基于模型的聚类算法基于模型的聚类算法假设样本数据服从某种概率分布或数学模型,并通过最大化似然估计来寻找最优模型参数。
常见的基于模型的聚类算法包括高斯混合模型(GMM)和潜在狄利克雷分配(LDA)等。
基于网格的聚类算法基于网格的聚类算法是将数据空间划分为网格,然后对每个网格进行聚类分析。
这种算法主要用于处理高维数据和大规模数据,常见的算法包括CLIQUE和STING等。
聚类算法的原理不同的聚类算法有不同的原理和数学模型。
以K-means算法为例,它的原理如下:1.随机选择K个样本点作为初始的聚类中心。
2.将所有样本点分别分配到离它们最近的聚类中心所在的簇。
3.更新每个簇的聚类中心,即将簇内所有样本点的均值作为新的聚类中心。
4.重复步骤2和步骤3,直到聚类中心不再改变或达到预定的迭代次数。
数据挖掘理论算法综述数据挖掘的理论与算法是挖掘最新发现以及形式化的知识以支持决策过程的一类技术。
它包括许多被称作“数据挖掘技术”的一般方法,这些方法主要是从大量数据中挖掘有价值的信息,并应用于实际的应用程序中。
本文综述了数据挖掘领域的主要理论算法,重点讨论它们的特性和原理,详细分析它们在实际应用中的优缺点,以及它们在数据挖掘过程中的应用。
一类常用的数据挖掘算法包括决策树算法、聚类算法、关联规则算法和神经网络算法。
决策树算法是一种以树形结构表示的决策过程,是用来分析数据集和进行决策分析的流行算法。
它用树状图形化表示决策过程,使用熵和信息增益来衡量每个节点的信息含量,从而有效地识别潜在模式,从而建立一个类别树。
聚类算法是一种数据挖掘技术,它将数据实例划分到不同的相关聚类中,这一集群可以反映数据集中隐藏的模式及结构关系,研究者可以发现这些集群中的特征以及它们之间的联系,从而理解它们的结构和模式。
聚类算法基本上分为基于密度的聚类算法和基于近似的聚类算法。
关联规则算法是一种从大型数据库中挖掘出一些关联规则的方法,即它试图从这一大型数据库中发现有意义的频繁项集,以及它们之间的关联规则,实现对数据分析和知识发现的目标。
它可以从形式化的模型中推导出有用的推论,识别存在于数据库的罕见的或有价值的模式,从而揭示价值知识。
神经网络算法是一种仿生学算法,它以人工神经网络的结构为基础,解决一些机器学习和分类问题,它可以从高维数据中学习潜在表示,以改善学习问题解决方案的准确性,有助于发现预测和识别未知信息,并发现有用的模式和决策。
本文综述了常用的数据挖掘理论与算法,它们在数据挖掘过程中均有着重要的作用,可以从大量的复杂数据中挖掘有价值的信息,从而帮助企业和研究机构获得有用的信息和模式。
数据挖掘分类算法研究综述
程建华
(九江学院信息科学学院软件教研室九江332005 )
摘要:随着数据库应用的不断深化,数据库的规模急剧膨胀,数据挖掘已成为当今研究的热点。
特别是其中的分类问题,由于其使用的广泛性,现已引起了越来越多的关注。
对数据挖掘中的核心技术分类算法的内容及其研究现状进行综述。
认为分类算法大体可分为传统分类算法和基于软计算的分类法两类。
通过论述以上算法优缺点和应用范围,研究者对已有算法的改进有所了解,以便在应用中选择相应的分类算法。
关键词:数据挖掘;分类;软计算;算法
1引言
1989年8月,在第11届国际人工智能联合会议的专题研讨会上,首次提出基于数据库的知识发现(KDD,Knowledge DiscoveryDatabase)技术[1]。
该技术涉及机器学习、模式识别、统计学、智能数据库、知识获取、专家系统、数据可视化和高性能计算等领域,技术难度较大,一时难以应付信息爆炸的实际需求。
到了1995年,在美国计算机年会(ACM)上,提出了数据挖掘[2](DM,Data Mining)的概念,由于数据挖掘是KDD过程中最为关键的步骤,在实践应用中对数据挖掘和KDD这2个术语往往不加以区分。
基于人工智能和信息系统,抽象层次上的分类是推理、学习、决策的关键,是一种基础知识。
因而数据分类技术可视为数据挖掘中的基础和核心技术。
其实,该技术在很多数据挖掘中被广泛使用,比如关联规则挖掘和时间序列挖掘等。
因此,在数据挖掘技术的研究中,分类技术的研究应当处在首要和优先的地位。
目前,数据分类技术主要分为基于传统技术和基于软计算技术两种。
2传统的数据挖掘分类方法
分类技术针对数据集构造分类器,从而对未知类别样本赋予类别标签。
在其学习过程中和无监督的聚类相比,一般而言,分类技术假定存在具备环境知识和输入输出样本集知识的老师,但环境及其特性、模型参数等却是未知的。
2.1判定树的归纳分类
判定树是一个类似流程图的树结构,其中每个内部节点表示在一个属性上的测试,每个分支代表一个测试输出,而每个树叶节点代表类或类分布。
树的最顶层节点是根节点。
由判定树可以很容易得到“IFTHEN”形式的分类规则。
方法是沿着由根节点到树叶节点的路径,路径上的每个属性-值对形成“IF”部分的一个合取项,树叶节点包含类预测,形成“THEN”部分。
一条路径创建一个规则。
判定树归纳的基本算法是贪心算法,它是自顶向下递归的各个击破方式构造判定树。
其中一种著名的判定树归纳算法是建立在推理系统和概念学习系统基础上的ID3算法。
2.2贝叶斯分类
贝叶斯分类是统计学的分类方法,基于贝叶斯公式即后验概率公式。
朴素贝叶斯分类的分类过程是首先令每个数据样本用一个N维特征向量X={X1,X2,⋯X n}表示,其中X k是属性A k的值。
所有的样本分为m类:C1,C2,⋯,C n。
对于一个类别的标记未知的数据记录而言,若P(C i/X)>P(C j/X),1≤ j≤m,j≠i,也就是说,如果条件X下,数据记录属于C i类的概率大于属于其他类的概率的话,贝叶斯分类将把这条记录归类为C i类。
建立贝叶斯信念网络可以被分为两个阶段。
第一阶段网络拓扑学习,即有向非循环图的———————————————————
作者简介:程建华(1982-),女,汉族,江西九江,研究生,主要研究方向为数据挖掘、信息安全。
学习,利用贝叶斯网络的学习算法,从实例数据建立所有属性变量和类变量构成的贝叶斯网结构。
第二个阶段网络中每个变量的局部条件概率分布的学习,采用贝叶斯网的推理算法,计算给定属性变量的值时类变量的最大后验概率。
采用这种分类思想的算法有TAN(tree augmented Bayes network)算法。
但是统计上的贝叶斯分类对非线性样本数据,含噪声、孤立点的数据,在分类准确性上仍存在问题。
3基于软计算的数据分类方法
在数据挖掘领域,软计算的用途越来越广泛:模糊逻辑用于处理不完整、不精确的数据以及近似答案等;神经网络用于高非线形决策、泛化学习、自适应、自组织和模式识别;遗传算法用于动态环境下的高效搜索、复杂目标对象的自适应和优化;粗糙集根据“核”属性获得对象的近似描述,能有效处理不精确、不一致、不完整等各种不完备信息。
当数据集表现出越来越多的无标签性、不确定性、不完整性、非均匀性和动态性特点时,传统数据挖掘算法对此往往无能为力,软计算却可为此提供一种灵活处理数据的能力,软计算内的融合和与传统数据挖掘方法的结合逐渐成为数据挖掘领域的研究趋势。
3.1粗糙集(rough set)
粗糙集理论是一种刻划不完整和不确定性数据的数学工具[3],不需要先验知识,能有效地处理各种不完备信息,从中发现隐含的知识,并和各种分类技术相结合建立起能够对不完备数据进行分类的算法。
粗糙集理论将分类能力和知识联系在一起,使用等价关系来形式化地表示分类,知识因而表示为等价关系集R对离散空间U的划分。
粗糙集理论还包含求取数据中最小不变集和最小规则集的理论,即约简算法(即分类中属性约简和规则生成),其基本原理是通过求属性的重要性并排序,在泛化关系中找出与原始数据具有同一决策或分辨能力的相关属性的最小集合,以此实现信息约简,这也是粗糙集理论在分类中的主要应用。
3.2遗传算法
遗传算法在解决多峰值、非线性、全局优化等高复杂度问题时具备独特优势,它是以基于进化论原理发展起来的高效随机搜索与优化方法。
它以适应值函数为依据,通过对群体、个体施加遗传操作来实现群体内个体结构的优化重组,在全局范围内逼近最优解。
遗传算法综合了定向搜索与随机搜索的优点,避免了大多数经典优化方法基于目标函数的梯度或高阶导数而易陷入局部最优的缺陷,可以取得较好的区域搜索与空间扩展的平衡。
在运算时随机的多样性群体和交叉运算利于扩展搜索空间;随着高适应值的获得,交叉运算利于在这些解周围探索。
遗传算法由于通过保持一个潜在解的群体进行多方向的搜索而有能力跳出局部最优解。
遗传算法的应用主要集中在分类算法[4]等方面。
其基本思路如下:
数据分类问题可看成是在搜索问题,数据库看作是搜索空间,分类算法看作是搜索策略。
因此,应用遗传算法在数据库中进行搜索,对随机产生的一组分类规则进行进化,直到数据库能被该组分类规则覆盖,从而挖掘出隐含在数据库中的分类规则。
应用遗传算法进行数据分类,首先要对实际问题进行编码;然后定义遗传算法的适应度函数,由于算法用于规则归纳,因此,适应度函数由规则覆盖的正例和反例来定义。
4结语
分类算法是数据挖掘中的核心和基础技术之一,本文对基于传统算法和软计算的常见数据分类算法进行了综述;从而便于研究者对已有算法进行改进和设计新的分类算法。
未来数据分类算法的研究则更多地集中在智能分类领域,如基于软计算的分类算法以及免疫算法、
分形编码、蚁群优化等智能算法的分类研究上。
参考文献
[1]Liu B, Hsu W. Integrating classification and association rulemining Agrawal R, Stdorz P, Piatetsky G. Proc of 4th Int.Conf. on Knowledge Discovery and Data Mining. Menlo Park:AAAI Press, 1998:80-86.
[2] Kuncheva L I. Editing for the k-nearest neighbors rule by agenetic. Pattern Recognition Letters, 1995,16:809-814.
[3] Friedman N, Geiger D, Goldszmidt M. Bayesian network classifier. Machine Learning,
1997,29(1):131-163.
[4] 曾黄麟.粗集理论及其应用.重庆:重庆大学出版社,1996.。