地质统计学与随机建模原理5-多点地质统计学
- 格式:ppt
- 大小:1005.50 KB
- 文档页数:16


多点地质统计学原理、方法及应用概述及解释说明1. 引言1.1 概述本文旨在探讨多点地质统计学的原理、方法及应用,为读者提供一个全面了解该领域的概述。
多点地质统计学是一门研究如何有效地利用多变量数值以及空间数据进行地质分析和预测的学科。
它通过综合多种数据,包括物理测量数据、遥感图像数据和野外调查数据等,来实现对不同地质现象和过程的建模与研究。
1.2 文章结构本文按照以下结构组织内容:首先介绍多点地质统计学的基本原理,包括其定义与概念、基本假设以及原理解释。
随后,针对多点地质统计学的方法进行详细阐述,探讨数据收集与预处理、变量选择和缺失值处理以及统计模型拟合与优化算法应用等关键步骤。
接下来,我们将通过具体案例研究来展示多点地质统计学在矿产资源评估与勘探、地下水资源管理与保护以及石油勘探与开发中的应用实践。
最后,在结论部分对全文进行概括总结,并展望未来多点地质统计学研究的发展方向。
1.3 目的本文旨在全面介绍多点地质统计学的原理、方法及应用,以帮助读者对该领域有一个清晰的认识。
通过阐述基本原理和方法,读者可以了解多点地质统计学在地质分析和预测中的重要性。
此外,通过具体案例的引入,读者将能够更好地理解多点地质统计学在实际问题中的应用价值和潜力。
最后,通过对未来研究方向的展望,读者可以获得一些启示,并为自己在该领域开展研究提供参考。
2. 多点地质统计学原理2.1 定义与概念多点地质统计学是一种广泛应用于地质科学领域的统计学方法。
它通过对多个地点上的地质数据进行收集、分析和解释,旨在揭示地下资源的分布规律和空间变异性。
多点地质统计学基于一系列假设和方法,能够提供可靠的预测结果和决策依据。
2.2 基本假设在多点地质统计学中,存在几个基本假设:- 空间自相关假设:相邻位置上的地质现象存在关联性,即一个位置的观测值可能受到相邻位置观测值的影响。
- 空间平稳假设:在整个研究区域内,不同位置上的地质变量具有类似的变异性。

储层多点地质统计学随机建模方法摘要:多点地质统计学使用训练图像代替变差函数,将更多的地质资料整合到储层建模过程中,使得最终模型更加符合地质认识。
随着研究的不断深入,越来越多的地质工作人员开始熟悉这一方法,凭借自身的独特优势,多点地质统计学将在储层建模领域占得重要的一席。
关键词:多点地质统计学训练图像储层建模一、多点地质统计学与训练图像基于变差函数的传统地质统计学随机模拟是目前储层非均质性模拟的常用方法。
然而,变差函数只能建立空间两点之间的相关性,难于描述具有复杂空间结构和几何形态的地质体的连续性和变异性。
针对这一问题,多点地质统计学方法应运而生。
该方法着重表达空间中多点之间的相关性,能够有效克服传统地质统计学在描述空间形态较复杂的地质体方面的不足。
多点地质统计学的基本工具是训练图像,其地位相当于传统地质统计学中的变差函数。
对于沉积相建模而言,训练图像相当于定量的相模式,实质上就是一个包含有相接触关系的数字化先验地质模型,其中包含的相接触关系是建模者认为一定存在于实际储层中的。
二、地质概念模型转换成图像训练地质工作人员擅于根据自己的先验认识、专业知识或现有的类比数据库来建立储层的概念模型。
当地质工作人员认为某些特定的概念模型可以反映实际储层的沉积微相接触关系时,这些概念模型就可以转换或直接作为训练图像来使用。
利用训练图像整合先验地质认识,并在储层建模过程中引导井间相的预测,是多点地质统计学模拟的一个突破性贡献。
可以将训练图像看作是一个显示空间中相分布模式的定量且直观的先验模型。
地质解释成果图、遥感数据或手绘草图都可以作为训练图像或建立训练图像的要素来使用。
理想状态下,应当建立一个训练图像库,这样一来建模人员就可以直接选取和使用那些包含目标储层典型沉积模式的训练图像,而不需要每次都重新制作训练图像。
三、多点模拟原理进行多点模拟,需要使用地质统计学中的序贯模拟。
但是,多点模拟与传统的基于变差函数的两点模拟是不同的。

第一章绪论一、历史背景与产生地质统计学是二十世纪六七十年代发展起来的一门新兴的数学地质学科的分支。
它开始主要是为解决矿床从普查勘探、矿山设计到矿山开采整个过程中各种储量计算和误差估计问题而发展起来的。
它是由法国著名学者G. 马特隆教授于1962年创立的。
其核心即所谓的“克立格”。
它是一种无偏的最小误差的储量计算方法。
该方法按照样品与待估块段的相对空间位置和相关程度来计算块段品位及储量,并使估计误差为最小。
这是南非采矿工程师D. G. Krige 根据南非金矿的具体情况与1952年提出的,故命名为克立格法。
后来法国学者G. 马特隆(Matheron)对克立格提出的方法进行研究,认为克立格提出的方法是在考虑了空间分布特征的基础上,合理地改进了统计学,是一种传统方法与统计学方法结合起来的新方法。
同时为了解决具二重型(结构型与随机性)的地质变量的条件下使用统计方法的问题。
马特隆教授提出了区域化变量的概念(Regionalized Variable),从而创立了地质统计学。
根据地质统计学理论,地质特征可以用区域化变量的空间分布特征来表征。
而研究区域化变量的空间分布特征分布的主要数学工具是变差函数(Variogram)。
到七十年代中后期,马特隆的学生JOURENL等在研究其它地质变量的基础上,认为某些地质变量并不是一成不变的,而是有一定波动的,这样使用克立格法就不能很好再现地质变量的分布特征。
因此他们采样模拟的方法,将克立格估计的离散方差的波动性模拟出来,从而产生了随机模拟法。
因此,从二十世纪八十年代以来,地质统计学分为两派:一派以法国的马特隆教授等人为主,仍致力于克立格估计的研究;一派以美国JOURENL等人为主,主要致力于随机模拟方法的研究。
地质统计学的产生是在经典统计学的基础上发展起来的。
在此前,为了反映地质变量的空间变化性,一些地质学家曾经使用一些经典的概率统计方法来研究地质变量。
但由于地质变量并不是纯粹的随机变量,因此,直接用简单的统计方法解决复杂的地质问题,有一定的局限性。

多点地质统计学随机建模方法原理详细教程多点地质统计学(Multiple-Point Geostatistics,简称MPGS)是一种用于地质建模的统计学方法,旨在综合考虑多个地质属性之间的空间关系,可以用于模拟地质体结构和属性的空间分布。
下面是一个详细的MPGS建模方法的教程。
1.数据收集和准备首先,需要收集和准备地质数据。
这些数据可以包括钻孔数据、采矿数据、地球物理数据等。
数据应该包括多个不同属性的测量结果。
2.数据预处理对收集的数据进行预处理是为了消除异常值、填充缺失值和准备数据用于建模。
这些步骤可以包括数据清洗、插值等。
3.定义模型网格创建一个用于建模的三维网格,通常由正交的网格单元组成。
网格的尺寸和边界应根据实际问题的要求进行选择。
4.模式提取在做MPGS建模之前,需要从数据中提取出具有空间一致性和相关性的模式。
这可以通过模式提取算法实现,如基于模拟退火算法的直方图匹配。
5.模式匹配在模型建模过程中,需要通过模式匹配找到与已知数据最相似的地质模式。
这可以通过计算模式之间的相似性指标,如多点统计函数(MPS)实现。
6.模式合成一旦找到与已知数据相似的地质模式,可以根据模式之间的空间关系来生成新的地质模式。
这可以通过使用概率或变异性模型来实现。
7.模型重建利用已生成的地质模式,可以在模型网格单元上对地质属性进行插值,以重建地质体的结构和属性分布。
这可以使用插值方法,如克里金插值、逼近法等。
8.模型评估和修正完成模型重建后,需要评估模型的性能并根据需求对模型进行修正。
可以利用模型与实际数据之间的比较以及其他准则来评估模型的准确性和合理性。
9.模型应用完成最终的地质建模后,可以将模型应用于相关的地质问题,如矿产资源评估、地质风险评估等。
以上是MPGS建模方法的详细教程。
这种方法在地质建模中广泛应用,可以提供更准确和全面的地质属性分布信息,对于地质资源开发和管理具有重要意义。

多点地质统计学Multiple-point geostatistic是相对于传统的两点地质统计学而言的,主要应用于储层表征与建模中.传统的地质统计学在储层建模中主要应用于两大方面:其一,应用各种克里金方法建立确定性的模型,这类方法主要有简单克里金、普通克里金、泛克里金、协同克里金、贝叶斯克里金、指示克里金等;其二,应用各种随机建模的方法建立可选的、等可能的地质模型,这类方法主要有高斯模拟(如序贯高斯模拟)、截断高斯模拟、指示模拟(如序贯指示模拟)等。
上述方法的共同特点是空间赋值单元为象元(即网格),故在储层建模领域将其归属为基于象元的方法。
这些方法均以变差函数为工具,亦可将其归属为基于变差函数的方法。
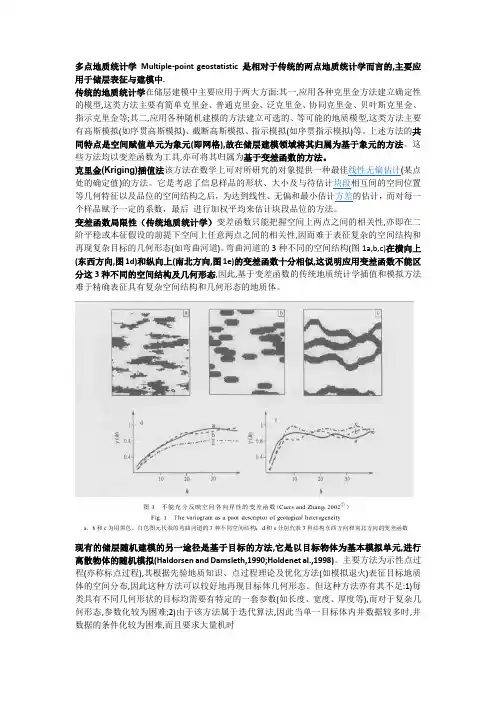
变差函数局限性(传统地质统计学)变差函数只能把握空间上两点之间的相关性,亦即在二阶平稳或本征假设的前提下空间上任意两点之间的相关性,因而难于表征复杂的空间结构和再现复杂目标的几何形态(如弯曲河道)。
弯曲河道的3种不同的空间结构(图1a,b,c)在横向上(东西方向,图1d)和纵向上(南北方向,图1e)的变差函数十分相似,这说明应用变差函数不能区分这3种不同的空间结构及几何形态,因此,基于变差函数的传统地质统计学插值和模拟方法难于精确表征具有复杂空间结构和几何形态的地质体。
现有的储层随机建模的另一途径是基于目标的方法,它是以目标物体为基本模拟单元,进行离散物体的随机模拟(Haldorsen and Damsleth,1990;Holdenet al.,1998)。
主要方法为示性点过程(亦称标点过程),其根据先验地质知识、点过程理论及优化方法(如模拟退火)表征目标地质体的空间分布,因此这种方法可以较好地再现目标体几何形态。
但这种方法亦有其不足:1)每类具有不同几何形状的目标均需要有特定的一套参数(如长度、宽度、厚度等),而对于复杂几何形态,参数化较为困难;2)由于该方法属于迭代算法,因此当单一目标体内井数据较多时,井数据的条件化较为困难,而且要求大量机时2多点地质统计学的基本概念多点统计学着重表达多点之间的相关性。

收稿日期:2008-01-11基金项目:中国石油天然气勘探开发公司项目(HW ZX0502)作者简介:张伟(1980-),男(汉族),山东五莲人,博士研究生,从事油藏描述及储层建模研究。
文章编号:1673-5005(2008)04-0024-05多点地质统计学在秘鲁D 油田地质建模中的应用张 伟,林承焰,董春梅(中国石油大学地球资源与信息学院,山东东营257061)摘要:应用多点地质统计学和相控建模相结合的方法,以秘鲁D 油田V 层为例进行了地质条件约束下的地质建模研究。
首先根据地质概念模型建立训练图像,然后应用多点地质统计学Snes i m 算法模拟沉积微相,最后在沉积微相控制下进行储层参数模拟。
研究结果表明:多点地质统计学方法不仅忠实于井点数据,而且可以在使用的训练图像中加入地质概念,从而对随机模型进行地质约束;V 层沉积微相随机模拟较好地再现了沉积微相的空间结构,其孔隙度模拟实现与相应沉积微相模型吻合较好,且沉积微相对储层参数的空间分布具有较大影响;多点地质统计学方法和相控建模的建模原则有助于从地质的角度对模型进行约束,促进概念模型向定量模型的转化,从而建立合理的反映地下实际情况的三维模型。
关键词:多点地质统计学;相控建模;地质建模;秘鲁;D 油田中图分类号:TE 319 文献标识码:AApp licati on of multi ple -poi nt geostatistics i n geologi calmodeli ng of D O ilfiel d i n PeruZ HANG W e,i L I N Cheng -yan ,DONG Chun -m ei(Facult y of G eo -Resource and Infor m ation in Chi na Universit y of P etro leu m,D ongy ing 257061,Shandong P rov i nce ,Ch i na)Abstrac t :T aking t he V l ayer of D O ilfi e l d i n Pe ru as an example ,geolog ical mode li ng restricted by geolog i cal conditi ons was researched usi ng the me t hod comb i ned mu lti ple -po i nt geo statistics and facies contro lled m odeli ng .F irst ,tra i ning i m age was bu ilt accord i ng to the geo l og i ca l conceptm ode,l and the Snesi m algorith m o fmu lti ple -po i nt geostatisticsw as applied to si m u l a te sed i m entary m i crofac i es .F i nall y ,a rese rvo i r para m eters si m ulation w as perfor m ed under the contro l of sedi m entary m i crofacies .T he results s how that ,on the basis o f t he rea lwe ll data and tra i n i ng i m agesw it h geo l og ica l conception ,m ulti p l e -po i nt geostatis -ti cs succeeded i n restr i cti ng stochasti c m odel g eo l og ica lly ,w hich presents a better spati a l structure of sedi m entary m icro facies i n the stochastic m odeli ng of sedi m entary m i crofac i es of V l ayer .T he comb i na ti on of mu lti ple -po i nt geostati stics and fac ies con -troll ed m odeli ng i s he l pf u l to restrict t he m ode l from the geological po i nt o f vie w,promo te the transfor m from conceptm odel t o the quantitative model and build a reasonable 3D m ode l re flecti ng the true subsurface situati on .K ey word s :mu lti ple -po int geo sta ti sti cs ;facies controlled m odeli ng;geo l og ica lm ode li ng ;P eru ;D O ilfi e l d自从多点地质统计学(m ultiple -pu i n t geostatis -tics)应用于随机建模以来,国外学者作了大量的研究工作,取得了丰富的研究成果[1-6]。

多点地质统计学python -回复"多点地质统计学python"是一种基于Python编程语言的地质统计学方法,它通过使用多点统计技术来分析地质数据和建立地质模型。
多点地质统计学python可以用于地质建模、矿产资源评估、油气勘探等地质领域。
本文将逐步介绍多点地质统计学python的基本原理、数据处理步骤以及应用案例。
第一步:理解多点地质统计学的基本原理多点地质统计学是一种从多个样本点中提取信息进行推断的统计学方法,它考虑了地质数据在空间上的相关性和变异性。
这种方法的基本原理是通过对多个样本点进行统计分析,揭示地质变量的分布和空间结构。
多点地质统计学方法在地质学领域得到广泛应用,可以实现对地质数据的建模和预测。
第二步:了解多点统计技术在python中的实现Python是一种功能强大且易于使用的编程语言,具有丰富的数据处理和分析库,例如NumPy、Pandas和Matplotlib等。
这些库提供了处理大型地质数据集和执行统计分析的工具。
在python中,可以使用这些库来实现多点地质统计学方法,例如多点统计算法、样本点选择和空间变异性分析等。
第三步:处理地质数据集在使用多点地质统计学python之前,首先需要准备一个地质数据集。
这个数据集包含了地质变量的观测值,例如地层厚度、属性值或矿石品位等。
地质数据集通常以表格形式存储,可以使用Pandas库将数据导入到python环境中进行处理。
第四步:分析地质数据集在有了地质数据集之后,可以使用多点地质统计学python来分析数据。
首先,可以使用NumPy库计算地质数据的统计指标,例如均值、方差和协方差等。
这些统计指标可以用来揭示地质变量的中心趋势和空间关系。
接下来,可以使用多点统计算法来分析地质数据的变异性和空间结构。
其中,常见的多点地质统计学方法包括变差函数、半变异函数和变异权重等。
这些方法可以用来评估地质数据的变异性,并揭示地质变量之间的空间关联性。

多点地质统计学在点坝内部构型三维建模中的应用刘可可;侯加根;刘钰铭;史燕青;柳琳;唐力;高兴军;周新茂【摘要】首次将多点地质统计学应用于点坝内部三维建模。
基于60 m超小井距资料,统计点坝内部夹层发育特征,利用统计结果人机交互绘制训练图像,定量表征了夹层的厚度、倾角、频率、密度、水平间距等信息。
选取典型点坝,将单井解释夹层沿着夹层面垂直投影至点坝顶面,结合点坝沉积样式,获取建模过程中旋转数据体,以此来表征夹层走向信息。
利用多点地质统计学Snesim算法进行点坝内部侧积夹层三维建模,与序贯指示模拟方法在同一点坝和旋转数据体基础上建立的点坝内部三维构型模型进行对比分析。
研究结果表明,序贯指示模拟方法建立的点坝内部三维构型模型,虽然能够在一定程度上表征点坝内部夹层特征,但在表征夹层的连续性方面效果不佳,并且由于缺少训练图像的约束,只能定性展示夹层发育情况,无法达到定量刻画的程度。
而利用多点地质统计学方法建立的模型,点坝内部夹层受控于训练图像及旋转数据体的双重约束,能够定量再现夹层的发育规模和产状,精确表征点坝内部夹层的几何形态与空间结构。
结合水淹信息表明,此多点方法建立的点坝内部三维构型模型对于剩余油分布研究有指导意义。
%For the first time,an application of Multiple-point geostatistics in 3D internal architecture modeling of point bar is proposed in this paper.Data from dense well patterns ( well spacing of 60 m) offer us the statistical distribution charac-teristics of interbeds within the point bar.Training images are produced by interactive processing of the statistical results for quantitative characterization of the interbeds,such as theirthickness,dip,frequency,density and horizontal spacing.A typical point bar is first choosed for vertically projecting the interbeds interpreted fromsingle well data to its top surface along the surfaces of interbeds,and then a 3D spinning cube is calculated in combination with the depositional patterns of the point bar for strike characterization of the interbeds.The Snesim algorithm is used for 3D architectural modeling of lat-eral accretion,and the results are compared with those from sequential indicator simulation ( SIS) .It is concluded that SIS may represent the characteristics of interbeds,but it is inadequate to characterize their continuity.Besides,a lack of constraints from training images forbids satisfactory quantitative characterization.In contrast,the model based on Snesim is under the dual control of training images and 3D spinning cube,thus it can quantitatively characterize the distribution,ge-ometry and spatial structure of the interbeds.The data of watered-out reservoirs reveal that the architecture model built with multiple-point geostatistics method can guide the mapping of remaining oil.【期刊名称】《石油与天然气地质》【年(卷),期】2016(037)004【总页数】7页(P577-583)【关键词】训练图像;旋转数据体;密井网;多点地质统计学;点坝;剩余油分布【作者】刘可可;侯加根;刘钰铭;史燕青;柳琳;唐力;高兴军;周新茂【作者单位】中国石油大学北京地球科学学院,北京102249; 中国石油长城钻探工程有限公司测井公司,辽宁盘锦124011;中国石油大学北京地球科学学院,北京102249;中国石油大学北京地球科学学院,北京102249;中国石油大学北京地球科学学院,北京102249;中国石油大学北京地球科学学院,北京102249; 中国石油长城钻探工程有限公司地质研究院,辽宁盘锦124010;中国石油大学北京地球科学学院,北京102249; 中国石油华北油田公司勘探开发研究院,河北任丘062552;中国石油勘探开发研究院,北京100083;中国石油勘探开发研究院,北京100083【正文语种】中文【中图分类】TE122.2侧积层是曲流河储层中点坝内部砂体主要的渗流屏障,因此建立精确的点坝内部构型三维模型,对曲流河储层内部剩余油预测及挖潜具有重要实用价值[1-4]。

地质统计学方法一、引言地质统计学是地质学中的一个重要分支,它运用统计学的理论和方法来分析和解释地质现象和地质数据。
地质统计学的发展与地质学研究的需要密切相关,它可以帮助地质学家更好地理解地质现象、预测地质事件以及优化地质资源的开发利用。
本文将介绍地质统计学方法的基本原理和常用技术,以及其在地质学中的应用。
二、地质统计学方法的基本原理地质统计学方法的基本原理是基于概率统计的理论,它认为地质现象和地质数据的分布具有一定的规律性。
地质统计学方法通过对地质数据进行采样、观测和分析,可以得到地质现象的统计特征和概率模型,进而进行地质事件的预测和模拟。
三、地质统计学方法的常用技术1. 变量分析变量分析是地质统计学中最基本的技术之一,它主要用于研究地质现象和地质数据的变量特征。
常用的变量分析方法包括:频数分析、概率分布函数拟合、变异系数计算等。
这些方法可以帮助地质学家了解地质现象的变量分布规律,从而为后续的地质建模和预测提供依据。
2. 空间分析空间分析是地质统计学中另一个重要的技术,它主要用于研究地质现象和地质数据的空间特征。
常用的空间分析方法包括:半方差函数分析、克里金插值、空间统计模型建立等。
这些方法可以帮助地质学家揭示地质现象的空间分布规律,从而为地质资源的勘探和开发提供指导。
3. 地质模拟地质模拟是地质统计学中的一项重要技术,它主要用于通过随机模拟方法生成符合实际地质条件的模拟数据。
常用的地质模拟方法包括:高斯模拟、马尔可夫链模拟、蒙特卡洛模拟等。
这些方法可以帮助地质学家预测地质事件的概率和可能性,提高地质资源的开发效率。
四、地质统计学方法在地质学中的应用1. 地质资源评价地质统计学方法可以帮助地质学家评价地质资源的分布和储量,从而为资源的合理开发提供依据。
通过对地质数据的变量分析和空间分析,可以揭示地质资源的分布规律和富集规律,进而进行资源量的估算和评价。
2. 地质灾害预测地质统计学方法可以帮助地质学家预测地质灾害的发生概率和可能性,提前做好防灾准备工作。
基于随机游走过程的多点地质统计学建模方法石书缘;尹艳树;和景阳;冯文杰【期刊名称】《地质科技情报》【年(卷),期】2011(30)5【摘要】在分析国内外建模方法现状及其特点的基础上,提出了一种用于河流相储层模拟的新方法,即基于随机游走过程的多点地质统计学方法(RMPS)。
首先提出了7个方向迁移概率计算及4个方向河道源头搜索的随机游走过程的改进,实现了高曲率回旋河道和网状河等模拟以及各种类型河流相的主流线预测。
其次在预测河道主流线的基础上,利用它对多点地质统计学的数据事件选择性进行约束,从而提高了数据事件选择的合理性,可以获得更加准确的河道地质模型。
通过对GoogleEarth 取得的现代河流卫星图片模拟结果表明,RMPS比多点地质统计学方法更好地再现了河道的形态。
敏感性分析结果表明,该方法具有一定的稳定性。
【总页数】6页(P127-131)【关键词】随机游走;多点地质统计学;GoogleEarth;河流相;主流线;迁移概率【作者】石书缘;尹艳树;和景阳;冯文杰【作者单位】中国石油勘探开发研究院;长江大学地球科学学院【正文语种】中文【中图分类】P628.2【相关文献】1.综合随机游走过程与多点统计的河流相建模新方法 [J], 尹艳树;张昌民;石书缘;冯文杰;和景阳2.多点地质统计学随机建模方法及应用实例分析 [J], 刘颖;金亚杰3.深水浊积复合水道砂体内部建筑结构随机模拟——基于多点地质统计学与软概率属性协同约束方法 [J], 张宇焜;高博禹;卜范青4.多点地质统计学在沉积微相随机建模中的应用 [J], 马志武5.储层多点地质统计学随机建模方法 [J], 陈涛因版权原因,仅展示原文概要,查看原文内容请购买。
多点地质统计学建模的发展趋势石书缘;尹艳树;冯文杰【摘要】从算法研究、训练图像处理和实际应用三个方面详细解剖了国内外多点地质统计学的发展历程,在此基础上,分析了多点地质统计学主流的几种算法的核心原理、适用范围及优缺点,以此来对储层建模的发展趋势作出展望.目前,多点地质统计学虽是随机建模的一种前沿研究热点,但由于其尚未成熟,仍需对建模算法进行研究.为此,在前人研究的基础上,重点分析了多点地质统计学的发展趋势:合理处理训练图像;合理利用软信息;选择合适的相似性方法;选择合适的标准化方法;合理利用平稳性;算法间的耦合;选择合适的过滤器;拓展缝洞型碳酸盐岩模拟.最后,提出多点地质统计学在储层建模方面,应从增加储层的模拟区域、提高模拟精度、扩大储层相的模拟范围和提高计算机模拟效率等方面进行改进.%Starting with algorithm designing, training image,and practical application,the authors analyzed multiple-point statistics research trends both in China and abroad. On such a basis, the core principles of the main four MPS algorithms, their applicable ranges and advantages as well as disadvantages were analyzed,so as to forecast the trend of reservoir modeling. Multiple-point geostatistics is an international forefront research tool in stochastic modeling; nevertheless, as the algorithm is not yet mature, it should be further improved. On the basis of previous researches, the existing problems of the multiple-point geostatistics that need to be modified and the direction of the processing of training images are proposed, such as suitable processing of training image, choice of similarity methods, choice of standardized data,smoothing,couplingamong algorithms,and expansion of the simulation extent for fractured-vuggy carbonate reservoir. In order to improve the usage of multiple-point geostatistics for reservoir stochastic modeling,we should spare no efforts to increase the simulation area,improve simulation accuracy,expand the scope of simulation of reservoir types,save simulation time and improve simulation efficiency.【期刊名称】《物探与化探》【年(卷),期】2012(036)004【总页数】6页(P655-660)【关键词】储层建模;多点地质统计学;模拟精度;缝洞型碳酸盐岩模拟;发展趋势【作者】石书缘;尹艳树;冯文杰【作者单位】中国石油勘探开发研究院,北京 100083;长江大学地球科学学院,湖北荆州 434023;中国石油大学地球科学学院,北京 102249【正文语种】中文【中图分类】TE319目前,中国东部大部分油田进入高含水开发阶段,在新区勘探难度加大的情况下,对老油田进行挖潜寻找剩余油及拓展深层碳酸盐岩勘探开发已成为当前油气勘探开发的几个主要发展方向。