最优二叉树
- 格式:doc
- 大小:49.50 KB
- 文档页数:6


动态规划-最优⼆叉搜索树摘要: 本章介绍了⼆叉查找树的概念及操作。
主要内容包括⼆叉查找树的性质,如何在⼆叉查找树中查找最⼤值、最⼩值和给定的值,如何找出某⼀个元素的前驱和后继,如何在⼆叉查找树中进⾏插⼊和删除操作。
在⼆叉查找树上执⾏这些基本操作的时间与树的⾼度成正⽐,⼀棵随机构造的⼆叉查找树的期望⾼度为O(lgn),从⽽基本动态集合的操作平均时间为θ(lgn)。
1、⼆叉查找树 ⼆叉查找树是按照⼆叉树结构来组织的,因此可以⽤⼆叉链表结构表⽰。
⼆叉查找树中的关键字的存储⽅式满⾜的特征是:设x为⼆叉查找树中的⼀个结点。
如果y是x的左⼦树中的⼀个结点,则key[y]≤key[x]。
如果y是x的右⼦树中的⼀个结点,则key[x]≤key[y]。
根据⼆叉查找树的特征可知,采⽤中根遍历⼀棵⼆叉查找树,可以得到树中关键字有⼩到⼤的序列。
介绍了⼆叉树概念及其遍历。
⼀棵⼆叉树查找及其中根遍历结果如下图所⽰:书中给出了⼀个定理:如果x是⼀棵包含n个结点的⼦树的根,则其中根遍历运⾏时间为θ(n)。
问题:⼆叉查找树性质与最⼩堆之间有什么区别?能否利⽤最⼩堆的性质在O(n)时间内,按序输出含有n个结点的树中的所有关键字?2、查询⼆叉查找树 ⼆叉查找树中最常见的操作是查找树中的某个关键字,除了基本的查询,还⽀持最⼤值、最⼩值、前驱和后继查询操作,书中就每种查询进⾏了详细的讲解。
(1)查找SEARCH 在⼆叉查找树中查找⼀个给定的关键字k的过程与⼆分查找很类似,根据⼆叉查找树在的关键字存放的特征,很容易得出查找过程:⾸先是关键字k与树根的关键字进⾏⽐较,如果k⼤⽐根的关键字⼤,则在根的右⼦树中查找,否则在根的左⼦树中查找,重复此过程,直到找到与遇到空结点为⽌。
例如下图所⽰的查找关键字13的过程:(查找过程每次在左右⼦树中做出选择,减少⼀半的⼯作量)书中给出了查找过程的递归和⾮递归形式的伪代码:1 TREE_SEARCH(x,k)2 if x=NULL or k=key[x]3 then return x4 if(k<key[x])5 then return TREE_SEARCH(left[x],k)6 else7 then return TREE_SEARCH(right[x],k)1 ITERATIVE_TREE_SEARCH(x,k)2 while x!=NULL and k!=key[x]3 do if k<key[x]4 then x=left[x]5 else6 then x=right[x]7 return x(2)查找最⼤关键字和最⼩关键字 根据⼆叉查找树的特征,很容易查找出最⼤和最⼩关键字。

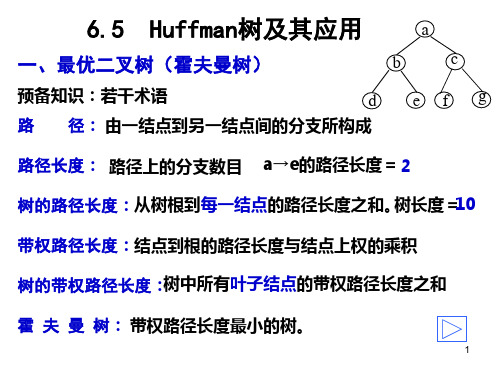
最优⼆叉树(哈夫曼树)的构建及编码参考:数据结构教程(第五版)李春葆主编⼀,概述1,概念 结点的带权路径长度: 从根节点到该结点之间的路径长度与该结点上权的乘积。
树的带权路径长度: 树中所有叶结点的带权路径长度之和。
2,哈夫曼树(Huffman Tree) 给定 n 个权值作为 n 个叶⼦结点,构造⼀棵⼆叉树,若该树的带权路径长度达到最⼩,则称这样的⼆叉树为最优⼆叉树,也称为哈夫曼树。
哈夫曼树是带权路径长度最短的树,权值较⼤的结点离根较近。
⼆,哈夫曼树的构建1,思考 要实现哈夫曼树⾸先有个问题摆在眼前,那就是哈夫曼树⽤什么数据结构表⽰? ⾸先,我们想到的肯定数组了,因为数组是最简单和⽅便的。
⽤数组表⽰⼆叉树有两种⽅法: 第⼀种适⽤于所有的树。
即利⽤树的每个结点最多只有⼀个⽗节点这种特性,⽤ p[ i ] 表⽰ i 结点的根节点,进⽽表⽰树的⽅法。
但这种⽅法是有缺陷的,权重的值需要另设⼀个数组表⽰;每次找⼦节点都要遍历⼀遍数组,⼗分浪费时间。
第⼆种只适⽤于⼆叉树。
即利⽤⼆叉树每个结点最多只有两个⼦节点的特点。
从下标 0 开始表⽰根节点,编号为 i 结点即为 2 * i + 1 和 2 * i + 2,⽗节点为 ( i - 1) / 2,没有⽤到的空间⽤ -1 表⽰。
但这种⽅法也有问题,即哈夫曼树是从叶结点⾃下往上构建的,⼀开始树叶的位置会因为⽆法确定⾃⾝的深度⽽⽆法确定,从⽽⽆法构造。
既然如此,只能⽤⽐较⿇烦的结构体数组表⽰⼆叉树了。
typedef struct HTNode // 哈夫曼树结点{double w; // 权重int p, lc, rc;}htn;2,算法思想 感觉⽐较偏向于贪⼼,权重最⼩的叶⼦节点要离根节点越远,⼜因为我们是从叶⼦结点开始构造最优树的,所以肯定是从最远的结点开始构造,即权重最⼩的结点开始构造。
所以先选择权重最⼩的两个结点,构造⼀棵⼩⼆叉树。
然后那两个最⼩权值的结点因为已经构造完了,不会在⽤了,就不去考虑它了,将新⽣成的根节点作为新的叶⼦节加⼊剩下的叶⼦节点,⼜因为该根节点要能代表整个以它为根节点的⼆叉树的权重,所以其权值要为其所有⼦节点的权重之和。


最优⼆叉搜索树背景:语⾔翻译,从英语到法语,对于给定的单词在单词表⾥找到该词⽅法:创建⼀棵⼆叉搜索树,以英语单词作为关键字构建树⽬标:尽快地找到英语单词,使总的搜索时间尽量少思路:频繁使⽤的单词,如the应尽可能的靠近根;⽽不经常出现的单词可以离根远⼀点前提假设:所有元素互异⼀些定义:⼆叉搜索树⼆叉搜索树T是⼀棵⼆元树,它或者为空,或者其每个结点含有⼀个可以⽐较⼤⼩的数据元素,且有:T的左⼦树的所有元素⽐根结点中的元素⼩;T的右⼦树的所有元素⽐根结点中的元素⼤;T的左⼦树和右⼦树也是⼆叉搜索树。
最优⼆叉搜索树给定含有n个关键字的已排序的序列K=<k1,k2,…,k n>(不失⼀般性,设k1<k2<…<k n),对每个关键字k i,都有⼀个概率p i表⽰其被搜索的频率。
根据k i和p i构建⼀个⼆叉搜索树T,每个k i对应树中的⼀个结点。
搜索对象x,在T中可能找到、也可能找不到:若x等于某个k i,则⼀定可以在T中找到结点k i,称为成功搜索。
成功搜索的情况⼀共有n种,分别是x恰好等于某个k i。
若x<k1或x>k n或k i<x<k i+1(1≤i<n), 则在T中搜索x将失败,称为失败搜索。
为此引⼊外部结点d0,d1,...,d n,⽤来表⽰不在K中的值,称为伪关键字。
伪关键字在T中对应外部结点,共有n+1个。
—扩展⼆叉树:内结点表⽰关键字k i,外结点(叶⼦结点)表⽰d i这⾥每个d i代表⼀个区间。
d0表⽰所有⼩于k1的值,d n表⽰所有⼤于k n的值,对于i=1,…,n−1,d i表⽰所有在k i和k i+1之间的值。
每个d i也有⼀个概率表⽰搜索对象x恰好落q i⼊区间d i的频率。
⼆叉搜索树的期望搜索代价⼀次搜索的代价等于从根结点开始访问结点的数量(包括外部结点)。
从根结点开始访问结点的数量等于结点在T中的深度+1。
记depth T(i)为结点i在T中的深度。
文件压缩总结(哈夫曼压缩)在学习哈弗曼压缩之前,还是首先来了解什么是哈夫曼树,哈夫曼编码。
1.哈夫曼树是一种最优二叉树,它的带权路径长度达到最小。
树的带权路径长度为所有叶子结点带权路径长度之和。
而结点的带权路径长度是结点的路径长度乘以结点的权值。
2.哈夫曼编码是依据字符出现概率来构造异字头的平均长度最短的码字。
从哈弗曼树的根结点开始,按照左子树代码为“0”,右子树代码为“1”的规则,直到树的叶子结点,每个叶子结点的哈弗曼编码就是从根结点开始,将途中经过的枝结点和叶子结点的代码按顺序串起来。
哈夫曼压缩是字节符号用一个特定长度的01序列替代,在文件中出现频率高的符号,使用短的01序列,而出现频率少的字节符号,则用较长的01序列表示。
这里的文件压缩,我还只能做简单的文件A-->压缩为文件B--->解压为文件C,看文件A和文件C是不是相同。
那么就要分两个大步骤,小步骤:不过,根据哈弗曼树的特点,我们首先还是要定义结点类型结点类型代码1.public class TreeNode {2. public TreeNode parent; //双亲结点3. public TreeNode left; //左孩子结点4. public TreeNode right; //右孩子结点5.6. public byte con;// 结点的数据7. public int rate;8. public String bian="";9. public int count=0;10. public TreeNode(byte con, int rate) {11. super();12. this.con= con;13. this.rate = rate;14. }15. }然后分两大步骤一. 首先压缩文件1. 将源文件A中数据按字节读取,然后用MAP统计每个字节出现的次数(Key--不同的字节,value--次数)。