Hilditch 细化算法是经典的二值图像细化算法
- 格式:doc
- 大小:63.00 KB
- 文档页数:6


Hilditch 细化算法是经典的二值图像细化算法,然而,在网上却很难找到一个详细、正确的介绍和实现。
可以找到一辆个 Hilditch 算法的C实现,但缺乏注释,代码可读性也很差。
在期刊网上找到几篇论文,提及了Hilditch 算法,结果一篇说的罗哩罗嗦根本看不懂,另一篇说的说的易懂,却是错误的!拿来主义是行不通了,于是只好结合着这几个论文和代码,从头写 Hilditch 细化算法。
假设像素p的3×3邻域结构为:Hilditch 细化算法的步骤为:对图像从左向右从上向下迭代每个像素,是为一个迭代周期。
在每个迭代周期中,对于每一个像素p,如果它同时满足6个条件,则标记它。
在当前迭代周期结束时,则把所有标记的像素的值设为背景值。
如果某次迭代周期中不存在标记点(即满足6个条件的像素),则算法结束。
假设背景值为0,前景值为1,则:6个条件为:(I):p 为1,即p不是背景;(2):x1,x3,x5,x7不全部为1(否则把p标记删除,图像空心了);(3):x1-x8 中,至少有2个为1(若只有1个为1,则是线段的端点。
若没有为1的,则为孤立点);(4):p的8连通联结数为1;联结数指在像素p的3*3邻域中,和p连接的图形分量的个数:上图中,左图的4连通联结数是2,8连通联结数是1,而右图的4联通联结数和8联通联结数都是2。
4连通联结数计算公式是:8连通联结数计算公式是:其中,至于公式怎么来的就不管了,直接用就行了。
(5)假设x3已经标记删除,那么当x3为0时,p的8联通联结数为1;(6)假设x5已经标记删除,那么当x5为0时,p的8联通联结数为1。
======在程序中,我使用的是这样的邻域编码:为了方便计算联结数,以0作为前景,1作为背景。
程序如下(完整程序见:/svn/trunk/src/mon/UnmanagedI mage/ImageU8.cs):/// <summary>/// 计算八联结的联结数,计算公式为:/// (p6 - p6*p7*p0) + sigma(pk - pk*p(k+1)*p(k+2)), k = {0,2,4)/// </summary>/// <param name="list"></param>/// <returns></returns>private unsafe Int32 DetectConnectivity(Int32* list){Int32 count = list[6] - list[6] * list[7] * list[0];count += list[0] - list[0] * list[1] * list[2];count += list[2] - list[2] * list[3] * list[4];count += list[4] - list[4] * list[5] * list[6];return count;}private unsafe void FillNeighbors(Byte* p, Int32* list, Int32 width, Byte foreground = 255){// list 存储的是补集,即前景点为0,背景点为1,以方便联结数的计算list[0] = p[1] == foreground ? 0 : 1;list[1] = p[1 - width] == foreground ? 0 : 1;list[2] = p[-width] == foreground ? 0 : 1;list[3] = p[-1 - width] == foreground ? 0 : 1;list[4] = p[-1] == foreground ? 0 : 1;list[5] = p[-1 + width] == foreground ? 0 : 1;list[6] = p[width] == foreground ? 0 : 1;list[7] = p[1 + width] == foreground ? 0 : 1;}/// <summary>/// 使用 hilditch 算法进行细化/// </summary>public unsafe void Thinning(Byte foreground = 255){Byte* start = this.Start;Int32 width = this.Width;Int32 height = this.Height;Int32* list = stackalloc Int32[8];Byte background = (Byte)(255 - foreground);Int32 length = this.Length;using (ImageU8 mask = new ImageU8(this.Width, this.Height)) {mask.Fill(0);Boolean loop = true;while (loop == true){loop = false;for (Int32 r = 1; r < height - 1; r++){for (Int32 c = 1; c < width - 1; c++){Byte* p = start + r * width + c;// 条件1:p 必须是前景点if (*p != foreground) continue;// p3 p2 p1// p4 p p0// p5 p6 p7// list 存储的是补集,即前景点为0,背景点为1,以方便联结数的计算FillNeighbors(p, list, width, foreground);// 条件2:p0,p2,p4,p6 不皆为前景点if (list[0] == 0 && list[2] == 0 && list[4] == 0 && list[6] == 0)continue;// 条件3: p0~p7至少两个是前景点Int32 count = 0;for (int i = 0; i < 8; i++){count += list[i];}if (count > 6) continue;// 条件4:联结数等于1if (DetectConnectivity(list) != 1) continue;// 条件5: 假设p2已标记删除,则令p2为背景,不改变p的联结数 if (mask[r - 1, c] == 1){list[2] = 1;if (DetectConnectivity(list) != 1)continue;list[2] = 0;}// 条件6: 假设p4已标记删除,则令p4为背景,不改变p的联结数 if (mask[r, c - 1] == 1){list[4] = 1;if (DetectConnectivity(list) != 1)continue;}mask[r, c] = 1; // 标记删除loop = true;}}for (int i = 0; i < length; i++){if (mask[i] == 1){this[i] = background;}}}}}。

浙江万里学院学报2015年3月手写数字体自动识别技术的研究现状胡玲琳,张若男,李培年,王仁芳(浙江万里学院,浙江宁波315100)摘要:脱机手写数字体自动识别一直以来是图像处理与模式识别领域中的研究热点及具有较高的实用价值。
文章对手写数字体研究现状进行概述,着重分析了预处理中的二值化、细化等方法,对特征提取中较重要的统计特征和结构特征分别进行阐述,讨论了分类识别中BP 神经网络、支持向量机等关键技术的各种主流方法。
通过分析,以期使读者对手写数字体识别的进展有较全面的了解,并对未来的研发有切实的帮助。
关键词:手写数字识别;预处理;特征提取;分类识别中图分类号:TP391文献标识码:A 文章编号:1671-2250(2015)02-0072-07收稿日期:2015-01-15基金项目:浙江省科技计划项目(项目编号:2012C21004);浙江省大学生科技创新活动计划(新苗计划)(项目编号:2014R419028)。
作者简介:胡玲琳(1989-),女,浙江建德人,浙江万里学院计算机与信息学院物流工程研究生,研究方向:物流信息技术应用。
通信作者:王仁芳(1974-),男,河南南阳人,浙江万里学院计算机与信息学院教授,研究方向:数字几何处理。
236Vo1.23No.62010年11月November 2010Journal of Zhejiang Wanli University浙江万里学院学报第28卷第2期Vo1.28No.22015年3月March 2015手写数字体识别(Handwritten digits recognition )是光学字符识别技术(Optical Character Recogni -tion ,OCR )的一个分支,其目的是让计算机自动识别出纸张上的手写数字[1]。
近几十年来,国内外学者对识别技术中的各个环节进行了广泛深入的研究,可见手写数字识别问题具有重要的学术意义和实用价值。

论文中文摘要毕业设计说明书(论文)外文摘要1 绪论图像的细化是数字图像预处理中的重要的一个核心环节。
图像细化在图像分析和图像识别中如汉子识别、笔迹鉴别。
指纹分析中有着广泛的应用。
图像的细化主要有以下几个基本要求:(1)骨架图像必须保持原图像的曲线连通性。
(2)细化结果尽量是原图像的中心线。
(3)骨架保持原来图形的拓扑结构。
(4)保留曲线的端点。
(5)细化处理速度快。
(6)交叉部分中心线不畸变。
虽然现在人们对细化有着广泛的研究,细化算法的方法有很多。
然而大多数算法如Hilditch算法和Rosenfield算法存在着细化后图形畸变,断点过多,在复杂的情况下关键信息的缺失等问题。
基于上诉考虑,传统的细化算法已经无法满足如今的数字图像处理要求。
因此,需要提出新的一种算法,来解决相关问题。
1.1 相关定义1.1.1串行与并行从处理的过程来看,主要可以分为串行和并行两类,前者对图像中当前象素的处理依据其邻域内象素的即时化结果,即对某一元素进行检测,如果该点是可删除点,则立即删除,且不同的细化阶段采用不同的处理方法;后者对当前的象素处理依据该象素及其邻域内各象素的前一轮迭代处理的结果,至始至终采用相同的细化准则。
即全部检测完汉子图像边缘上的点后再删除可删除点。
1.1.2骨架对图像细化的过程实际上是求一图像骨架的过程。
骨架是二维二值目标的重要拓扑描述,它是指图像中央的骨架部分,是描述图像几何及拓扑性质的重要特征之一。
骨架形状描述的方法是Blum最先提出来的,他使用的是中轴的概念。
如果用一个形象的比喻来说明骨架的含义,那就是设想在t=0的时刻,讲目标的边界各处同时点燃,火焰以匀速向目标内部蔓延,当火焰的前沿相交时火焰熄灭,那么火焰熄灭点的集合就构成了中轴,也就是图像的骨架。
例如一个长方形的骨架是它的长方向上的中轴线,正方形的骨架是它的中心点,圆的骨架是它的圆心,直线的骨架是它自身,孤立点的骨架也是自身。
细化的目的就是在将图像的骨架提取出来的同时保持图像细小部分的连通性,特别是在文字识别,地质识别,工业零件识别或图像理解中,先对被处理的图像进行细化有助于突出形状特点和减少冗余信息量。
地理空间信息GEOSPATIAL INFORMATION2015年4月第13卷第2期Apr.,2015V ol.13,No.2doi:10.3969/j.issn.1672-4623.2015.02.收稿日期:2014-05-06。
项目来源:国家高技术研究发展计划资助项目(2010AA12202)。
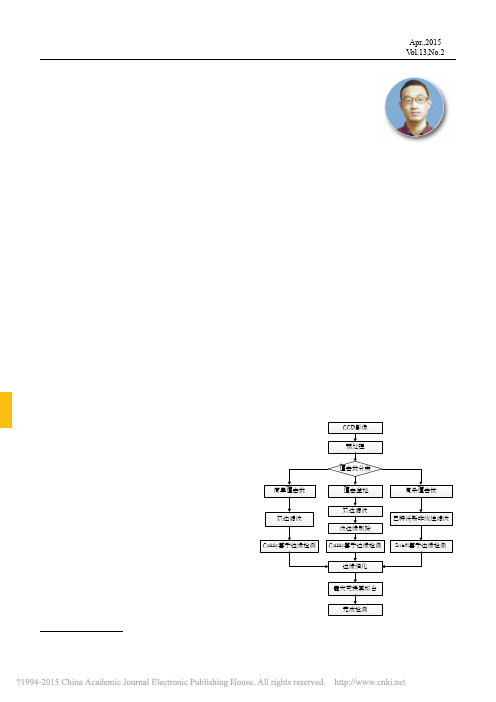
月球撞击坑分类检测研究马新凡1,苗 放2,杨文晖3,孟庆凯3(1.成都理工大学 信息科学与技术学院,四川 成都 610059;2.成都理工大学 地球探测与信息技术教育部重点实验室,四川 成都 610059;3.成都理工大学 空间信息技术研究所,四川 成都 610059)摘 要:根据嫦娥二号采集的月球CCD 影像,基于分类检测的方法,对撞击坑进行识别检测研究。
针对简单撞击坑、撞击盆地和复杂撞击坑的不同形态特征和影像特征,采用不同的滤波和检测算子进行识别。
结果表明,对直径在1.5 km 以上且光照条件较好的简单撞击坑和撞击盆地识别效果较好;对于复杂撞击坑,由于其形态结构相对复杂,造成图像边缘特征不突出, 因此识别率相对较低,有待进一步改进。
关键词:撞击坑;撞击坑分类;边缘检测;月球中图分类号:P237.3 文献标志码:B 文章编号:1672-4623(2015)02-0036-03014月球撞击坑是月球表面最显著的特征[1,2]。
对撞击坑进行正确的识别和提取,可为研究月球现状和演化历史提供直接证据。
欧阳自远曾做了月表直径>4 km 的撞击坑分布密度和月表地质年龄的关系图;冯军华等结合梯度信息,利用嫦娥一号CCD 图像, 采用最小二乘法拟合边缘椭圆的方法实现对撞击坑的检测[3]。
目前对于月球撞击坑的检测方法都各有优势,但由于月球撞击坑大小形状和深度不仅与撞击体的大小、密度、结构、撞击速度和撞击角度有密切关系,还受被撞击体的引力场和被撞击体处的岩性影响。
要完成对撞击坑的检测,就必须对撞击坑有一个清晰的认识,对每一类撞击坑特征有明确了解和掌握,这样有利于更准确地检测边缘[4,5]。

Hilditch细化算法是一种用于二值图像细化(或骨架化)的算法。
以下是一个简单的Python实现:
def hilditch(image):
# 获取图像的宽度和高度
width, height = image.shape
# 创建一个与原图大小相同的掩模,所有值初始化为1
mask = image.copy()
# 遍历原图像
for y in range(height):
for x in range(width):
# 如果当前像素是1,则进行细化操作
if image[x][y] == 1:
# 判断上下左右四个方向是否为0
if (x > 0 and image[x-1][y] == 0) or (x < width-1 and image[x+1][y] == 0):
mask[x][y] = 0
if (y > 0 and image[x][y-1] == 0) or (y < height-1 and image[x][y+1] == 0):
mask[x][y] = 0
# 返回细化后的图像
return mask
这个函数接受一个二值图像作为输入,并返回一个细化后的图像。
在函数中,我们首先创建一个与原图大小相同的掩模,并将所有值初始化为1。
然后,我们遍历原图像中的每个像素,如果当前像素是1,则检查其上下左右四个方向是否为0。
如果是,则将当前像素的值设置为0,表示该像素应该被细化掉。
最后,我们返回细化后的图像。
Hilditch细化算法是一种用于图像处理的算法,旨在对二值化图像进行细化处理,以消除图像中不必要的细节,从而得到更加清晰的边缘轮廓。
该算法在数字图像处理领域具有广泛的应用,可以帮助我们提取出图像中的有效信息,并且在计算机视觉、模式识别等领域有着重要的作用。
Hilditch细化算法的原理比较复杂,主要包括以下几个步骤:1. 定义细化算法的结构元素:Hilditch细化算法中使用了一个3x3的结构元素,该结构元素用于检测图像中的特定模式,并对其进行处理。
2. 识别图像中的特征点:在细化算法中,首先需要识别图像中的特征点,这些特征点通常指的是图像中的边缘像素点,通过对这些特征点进行分析和处理,可以实现对图像的细化处理。
3. 进行细化处理:一旦特征点被识别出来,就可以开始对图像进行细化处理。
这通常包括对结构元素进行滑动操作,利用结构元素与图像进行匹配,并根据预先设定的条件对结构元素进行处理,以使得图像的边缘轮廓更加清晰。
4. 迭代处理:细化算法通常需要进行多次迭代处理,直到图像中的所有特征点都被处理完毕,并且不再发生变化为止。
Hilditch细化算法虽然在图像处理中有着重要的作用,但是在实际应用中也存在一些问题和挑战。
算法本身的复杂性较高,需要较高的计算和存储资源;另外在处理过程中可能会出现一些误差和不确定性,这也需要我们在实际应用中做出一些改进和调整。
在Python中,我们可以利用一些开源的图像处理库来实现Hilditch 细化算法的功能,比如OpenCV、Pillow等。
这些库提供了丰富的API和功能,可以帮助我们实现图像的二值化处理、特征点的识别以及细化处理等操作。
Python本身具有简洁清晰的语法结构,也使得我们可以比较方便地编写和调试相关的算法代码。
以OpenCV为例,我们可以通过以下步骤来实现Hilditch细化算法:1. 导入OpenCV库:首先需要导入OpenCV库,并读取需要处理的图像数据。
opencv实现⼆值图像细化的算法opencv实现⼆值图像细化的算法细化算法通常和⾻骼化、⾻架化算法是相同的意思,也就是thin算法或者skeleton算法。
虽然很多图像处理的教材上不是这么写的,具体原因可以看这篇论⽂,Louisa Lam, Seong-Whan Lee, Ching Y. Suen,“Thinning Methodologies-A Comprehensive Survey ”,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 14, NO. 9, SEPTEMBER 1992 ,总结了⼏乎所有92年以前的经典细化算法。
函数:void cvThin( IplImage* src, IplImage* dst, int iterations=1)功能:将IPL_DEPTH_8U型⼆值图像进⾏细化参数:src,原始IPL_DEPTH_8U型⼆值图像dst,⽬标存储空间,必须事先分配好,且和原图像⼤⼩类型⼀致iterations,迭代次数参考⽂献:T. Y. Zhang and C. Y. Suen, “A fast parallel algorithm for thinning digital patterns,” Comm. ACM, vol. 27, no. 3, pp. 236-239, 1984.void cvThin( IplImage* src, IplImage* dst, int iterations=1){CvSize size = cvGetSize(src);cvCopy(src, dst);int n = 0,i = 0,j = 0;for(n=0; n<iterations; n++){IplImage* t_image = cvCloneImage(dst);for(i=0; i<size.height; i++){for(j=0; j<size.width; j++){if(CV_IMAGE_ELEM(t_image,byte,i,j)==1){int ap=0;int p2 = (i==0)?0:CV_IMAGE_ELEM(t_image,byte, i-1, j);int p3 = (i==0 || j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte, i-1, j+1);if (p2==0 && p3==1){ap++;}int p4 = (j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte,i,j+1);if(p3==0 && p4==1){ap++;}int p5 = (i==size.height-1 || j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j+1);if(p4==0 && p5==1){ap++;}int p6 = (i==size.height-1)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j);if(p5==0 && p6==1){ap++;}int p7 = (i==size.height-1 || j==0)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j-1);if(p6==0 && p7==1){ap++;}int p8 = (j==0)?0:CV_IMAGE_ELEM(t_image,byte,i,j-1);if(p7==0 && p8==1){ap++;}int p9 = (i==0 || j==0)?0:CV_IMAGE_ELEM(t_image,byte,i-1,j-1);if(p8==0 && p9==1){ap++;}if(p9==0 && p2==1){ap++;}if((p2+p3+p4+p5+p6+p7+p8+p9)>1 && (p2+p3+p4+p5+p6+p7+p8+p9)<7){if(ap==1){if(!(p2 && p4 && p6)){if(!(p4 && p6 && p8)){CV_IMAGE_ELEM(dst,byte,i,j)=0;}}}}}}}cvReleaseImage(&t_image);t_image = cvCloneImage(dst);for(i=0; i<size.height; i++){for(int j=0; j<size.width; j++){if(CV_IMAGE_ELEM(t_image,byte,i,j)==1){int ap=0;int p2 = (i==0)?0:CV_IMAGE_ELEM(t_image,byte, i-1, j);int p3 = (i==0 || j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte, i-1, j+1);if (p2==0 && p3==1){ap++;}int p4 = (j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte,i,j+1);if(p3==0 && p4==1){ap++;}int p5 = (i==size.height-1 || j==size.width-1)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j+1);if(p4==0 && p5==1){ap++;}int p6 = (i==size.height-1)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j);if(p5==0 && p6==1){ap++;}int p7 = (i==size.height-1 || j==0)?0:CV_IMAGE_ELEM(t_image,byte,i+1,j-1); if(p6==0 && p7==1){ap++;}int p8 = (j==0)?0:CV_IMAGE_ELEM(t_image,byte,i,j-1);if(p7==0 && p8==1){ap++;}int p9 = (i==0 || j==0)?0:CV_IMAGE_ELEM(t_image,byte,i-1,j-1);if(p8==0 && p9==1){ap++;}if(p9==0 && p2==1){ap++;}if((p2+p3+p4+p5+p6+p7+p8+p9)>1 && (p2+p3+p4+p5+p6+p7+p8+p9)<7) {if(ap==1){if(p2*p4*p8==0){if(p2*p6*p8==0){CV_IMAGE_ELEM(dst, byte,i,j)=0;}}}}}}}cvReleaseImage(&t_image);}}//使⽤举例#include "cxcore.h"#include "cv.h"#include "highgui.h"int main(int argc, char* argv[]){if(argc!=2){return 0;}IplImage *pSrc = NULL,*pDst = NULL,*pTmp = NULL;//传⼊⼀个灰度图像pSrc = cvLoadImage(argv[1],CV_LOAD_IMAGE_GRAYSCALE);if(!pSrc){return 0;}pTmp = cvCloneImage(pSrc);pDst = cvCreateImage(cvGetSize(pSrc),pSrc->depth,pSrc->nChannels);cvZero(pDst);cvThreshold(pSrc,pTmp,128,1,CV_THRESH_BINARY_INV);//做⼆值处理,将图像转换成0,1格式 //cvSaveImage("c://Threshold.bmp",pTmp,0);cvThin(pTmp,pDst,8);//细化,通过修改iterations参数进⼀步细化cvNamedWindow("src",1);cvNamedWindow("dst",1);cvShowImage("src",pSrc);//将⼆值图像转换成灰度,以便显⽰int i = 0,j = 0;CvSize size = cvGetSize(pDst);for(i=0; i<size.height; i++){for(j=0; j<size.width; j++){if(CV_IMAGE_ELEM(pDst,uchar,i,j)==1){CV_IMAGE_ELEM(pDst,uchar,i,j) = 0;}else{CV_IMAGE_ELEM(pDst,uchar,i,j) = 255;}}}//cvSaveImage("c://thin.bmp",pDst);cvShowImage("dst",pDst);cvWaitKey(0);cvReleaseImage(&pSrc);cvReleaseImage(&pDst);cvReleaseImage(&pTmp);cvDestroyWindow("src");cvDestroyWindow("dst");return 0;}。
Hilditch 细化算法是经典的二值图像细化算法,然而,在网上却很难找到一个详细、正确的介绍和实现。
可以找到一辆个 Hilditch 算法的C实现,但缺乏注释,代码可读性也很差。
在期刊网上找到几篇论文,提及了Hilditch 算法,结果一篇说的罗哩罗嗦根本看不懂,另一篇说的说的易懂,却是错误的!拿来主义是行不通了,于是只好结合着这几个论文和代码,从头写 Hilditch 细化算法。
假设像素p的3×3邻域结构为:
Hilditch 细化算法的步骤为:
对图像从左向右从上向下迭代每个像素,是为一个迭代周期。
在每个迭代周期中,对于每一个像素p,如果它同时满足6个条件,则标记它。
在当前迭代周期结束时,则把所有标记的像素的值设为背景值。
如果某次迭代周期中不存在标记点(即满足6个条件的像素),则算法结束。
假设背景值为0,前景值为1,则:
6个条件为:
(I):p 为1,即p不是背景;
(2):x1,x3,x5,x7不全部为1(否则把p标记删除,图像空心了);
(3):x1-x8 中,至少有2个为1(若只有1个为1,则是线段的端点。
若没有为1的,则为孤立点);
(4):p的8连通联结数为1;
联结数指在像素p的3*3邻域中,和p连接的图形分量的个数:
上图中,左图的4连通联结数是2,8连通联结数是1,而右图的4联通联结数和8联通联结数都是2。
4连通联结数计算公式是:
8连通联结数计算公式是:
其中,
至于公式怎么来的就不管了,直接用就行了。
(5)假设x3已经标记删除,那么当x3为0时,p的8联通联结数为1;
(6)假设x5已经标记删除,那么当x5为0时,p的8联通联结数为1。
======
在程序中,我使用的是这样的邻域编码:
为了方便计算联结数,以0作为前景,1作为背景。
程序如下(完整程序见:
/svn/trunk/src/mon/UnmanagedI mage/ImageU8.cs):
/// <summary>
/// 计算八联结的联结数,计算公式为:
/// (p6 - p6*p7*p0) + sigma(pk - pk*p(k+1)*p(k+2)), k = {0,2,4)
/// </summary>
/// <param name="list"></param>
/// <returns></returns>
private unsafe Int32 DetectConnectivity(Int32* list)
{
Int32 count = list[6] - list[6] * list[7] * list[0];
count += list[0] - list[0] * list[1] * list[2];
count += list[2] - list[2] * list[3] * list[4];
count += list[4] - list[4] * list[5] * list[6];
return count;
}
private unsafe void FillNeighbors(Byte* p, Int32* list, Int32 width, Byte foreground = 255)
{
// list 存储的是补集,即前景点为0,背景点为1,以方便联结数的计算
list[0] = p[1] == foreground ? 0 : 1;
list[1] = p[1 - width] == foreground ? 0 : 1;
list[2] = p[-width] == foreground ? 0 : 1;
list[3] = p[-1 - width] == foreground ? 0 : 1;
list[4] = p[-1] == foreground ? 0 : 1;
list[5] = p[-1 + width] == foreground ? 0 : 1;
list[6] = p[width] == foreground ? 0 : 1;
list[7] = p[1 + width] == foreground ? 0 : 1;
}
/// <summary>
/// 使用 hilditch 算法进行细化
/// </summary>
public unsafe void Thinning(Byte foreground = 255)
{
Byte* start = this.Start;
Int32 width = this.Width;
Int32 height = this.Height;
Int32* list = stackalloc Int32[8];
Byte background = (Byte)(255 - foreground);
Int32 length = this.Length;
using (ImageU8 mask = new ImageU8(this.Width, this.Height)) {
mask.Fill(0);
Boolean loop = true;
while (loop == true)
{
loop = false;
for (Int32 r = 1; r < height - 1; r++)
{
for (Int32 c = 1; c < width - 1; c++)
{
Byte* p = start + r * width + c;
// 条件1:p 必须是前景点
if (*p != foreground) continue;
// p3 p2 p1
// p4 p p0
// p5 p6 p7
// list 存储的是补集,即前景点为0,背景点为1,以方便联结数的计算
FillNeighbors(p, list, width, foreground);
// 条件2:p0,p2,p4,p6 不皆为前景点
if (list[0] == 0 && list[2] == 0 && list[4] == 0 && list[6] == 0)
continue;
// 条件3: p0~p7至少两个是前景点
Int32 count = 0;
for (int i = 0; i < 8; i++)
{
count += list[i];
}
if (count > 6) continue;
// 条件4:联结数等于1
if (DetectConnectivity(list) != 1) continue;
// 条件5: 假设p2已标记删除,则令p2为背景,不改变p的联结数 if (mask[r - 1, c] == 1)
{
list[2] = 1;
if (DetectConnectivity(list) != 1)
continue;
list[2] = 0;
}
// 条件6: 假设p4已标记删除,则令p4为背景,不改变p的联结数 if (mask[r, c - 1] == 1)
{
list[4] = 1;
if (DetectConnectivity(list) != 1)
continue;
}
mask[r, c] = 1; // 标记删除
loop = true;
}
}
for (int i = 0; i < length; i++)
{
if (mask[i] == 1)
{
this[i] = background;
}
}
}
}
}。