粮食产量预测
- 格式:docx
- 大小:41.38 KB
- 文档页数:9

一、总体概述四川省作为中国的农业大省之一,农业经济发展一直占据重要位置。
2024年,四川省农业经济呈现出以下几个特点:1.粮食产量稳定增长。
四川省主要种植稻谷、小麦和玉米等粮食作物。
2024年,该省粮食总产量达到2000万吨,同比增长3%,预计2024年粮食产量将保持稳定增长。
2.农产品结构不断优化。
四川省具备丰富的农产品资源,包括果蔬、畜牧和水产品等。
近年来,该省积极推进农业结构调整,加大对特色农产品的培育和推广力度。
预计2024年,四川省农产品结构将进一步优化。
3.农业现代化水平提高。
四川省农业现代化水平逐步提高,农业科技创新成果不断涌现。
该省积极推进农业机械化、信息化和智能化技术在农业生产中的应用,提高农业生产效率和品质。
预计2024年,四川省农业现代化水平将进一步提高。
二、存在的问题尽管四川省农业经济发展取得了一定的成绩,但仍存在一些问题:1.农产品质量安全问题。
由于缺乏统一的农产品质量安全监管标准和监管体系不健全,以及农民素质和技术水平相对较低,农产品质量安全问题在四川省仍然比较突出。
2.农业产业链不完善。
四川省农业产业链相对分散,缺乏统一的组织和协调,造成生产、流通和销售环节不畅通,农产品附加值较低。
3.农业资源利用不合理。
四川省农业资源庞大,但利用率不高。
农业用地过度分散和过度利用,水资源浪费现象较为严重,影响了农业的可持续发展。
三、发展对策1.加强农产品质量安全监管。
建立健全统一的农产品质量安全监管标准和监管体系,加强农产品质量检测和监督,提高农民素质和技术水平,确保农产品质量安全。
2.推进农业供给侧结构性。
加大对特色农产品的培育和推广力度,优化农业产业链,组织和协调生产、流通和销售环节,提高农产品附加值。
3.加强农业资源合理利用。
优化农业土地利用结构,提高农田水利设施的建设和管理水平,制定合理的农业水资源利用规划,减少农田水资源浪费。
四、发展预测基于以上分析和对四川省农业经济发展的预测,预计2024年四川省农业经济将继续保持稳定增长,具体表现为:1.粮食产量将保持稳定增长。

我国粮食产量影响因素分析与预测摘要:本文采用计量经济分析方法,以1980—2010年中国粮食产量及其重要影响因素的时间序列数据为样本,仿照C-D生产函数,建立了以粮食产量为因变量,以农用化肥施用量、有效灌溉面积、财政支农支出、农村用电量、农村机械总动力、粮食作物播种面积、农业灾害成灾面、农业劳动力八种可量化的影响因素为自变量的多对数回归模型,利用模型对各个因素进行了比较分析。
同时,对模型进行检验与修整,并在此基础上提出了一些关于增加粮食产量的可供参考的意见。
关键字:计量经济分析粮食产量多对数回归模型一、前言粮食是关系国计民生的重要战略物资。
粮食综合生产能力与粮食安全问题一直是世界性的重大问题,备受世界各国政府及专家学者的关注与研究。
近年来,中国粮价上涨过快,通货膨胀压力明显加大,不仅给低收入群体的生活带来很多困难,也使得国民经济的发展受到了制约。
粮食近年来连续减产、国家储备库存和农民手中的存粮减少,加上消费者需求的过量扩大,粮食将从结构性短缺转为战略性短缺。
粮食生产关系到我国的社会经济发展,因此认真研究和加深了解中国粮食生产的规律和特点,找出影响粮食总产量的主要因素,并采取针对性的粮食增产措施,对于稳定和发展粮食生产就有重要意义,对增加农民收入,乃至拉动整个国民经济的增长具有重要作用。
二、文献综述我国学者很早就对粮食生产问题展开了研究,并取得了一系列突出成果。
赵俊晔、王川采用逐步回归和灰色关联分析的方法对1991-2004年影响我国粮食产量变化的主要因素进行了分析,发现有效灌溉面积与粮食产量一直保持高的关联度,成灾面积与粮食产量的关联仅次于有效灌溉面积,在此基础上对提高我国粮食生产科技支撑能力、稳定发展粮食生产提出了建议。
梁子谦、李小军选取了15个指标,通过建立因子分析模型,对中国粮食单产和播种面积的影响因子进行了市政分析,研究结果表明,对粮食单产影响最大的因子是科技进步,其次是物质投入因子、环境与气候因子和中策因子。


基于 ARIMA模型预测黑龙江省粮食产量摘要:运用模型对1990-2021年黑龙江省粮食产量数据进行预测。
将预测值与实际值对比,结果表明,模型,拟合效果较好,并预测出2022年黑龙江省粮食产量为7998.669万吨。
关键词:模型;粮食产量;预测1引言黑龙江省2021年粮食产量为1573.54亿斤,连续11年在全国领跑,为保障国家粮食安全做出了巨大贡献。
黑龙江省粮食生产在全国占有重要的战略地位,对粮食产量进行预测研究,对我国的农业发展具有重大的意义。
2黑龙江省粮食产量增长分析通过查询《黑龙江省统计年鉴》收集黑龙江省1990年到2021年的粮食产量数据,发现黑龙江省粮食产量总体是呈上升的趋势的,在1990年至2003年增长缓慢,并且存在较大波动,2004年至2015年急速上升,2015年到2021年又呈现平稳增长趋势。
同时数据波动具有明显的周期性,因此选择模型进行预测分析。
3黑龙江省粮食产量的预测3.1 平稳性检验利用软件绘制时序图,发现序列存在一定的周期趋势,并没有显著的线性趋势。
对原始序列,一阶差分序列以及二阶差分序列进行单位根检验,在临界值在1%,5%,10%的情况下,二阶差分后数据的P值为0,小于0.05,可见序列是平稳的,则可选择二阶差分序列进行时间序列分析。
3.2 模型定阶与检验对二阶差分序列绘制自相关与偏自相关函数图。
通过观察二阶差分序列具有明显的拖尾特征,大部分序列位于置信上限和置信下限之内。
对模型的定阶,采用BIC准则,当BIC函数值达到最小时模型最优。
经过计算最终选择模型,模型结果如表1所示。
表1 AIRMA(1,2,0)检验表项符号值Q统计量Q6(P值)0.925(0.336)Q12(P值) 2.939(0.817)Q18(P值)10.887(0.539)Q24(P值)13.668(0.750)Q39(P值)18.947(0.755)信息准则AIC433.879BIC438.083拟合优度0.978由表1可以看出,Q统计量的p值均大于0.1,表明模型通过了白噪声检验。

2021(2)陕西气象49魏子力•黑龙江省气候生产力时空分布及粮食产量预测$%陕西气象#021(2):49-55.文章编号:1006-4354(2021)02-0049-07黑龙江省气候生产力时空分布及粮食产量预测魏子力12(1.信阳师范学院,河南信阳464000;2.河南省水土环境污染协同防治重5实验室,河南信阳464000)摘要:为充分利用气候资源推动农业可持续发展,研究复杂地形条件下气候生产力的分布变化(利用黑龙江省25个站点1961—2017年逐年气温和降水量资料,基于Thornthwaite Memorial模型研究了气候变化对气候生产力的影响;采用线性回归法、克里金空间插值和相关统计方法研究气候生产力时空分布特征;利用灰色系统方法预估了未来10a黑龙江省粮食产量变化特征(结果表明:(1)近57a来黑龙江省年平均气温、年平均降水量和气候生产力均呈上升趋势,变化倾向率分别为0.28土0.11L/10a、7.06土10.97mm/10a和117.05+52.67kg/(hm2•10a)。
(2)黑龙江省气候生产力存在显著空间差异,空间变化总体上呈由东南向西北和由东北向西南递减的特征,形成通河县、漠河市两个低值中心和以富锦市为中心的高值中心。
影响黑龙江气候生产力最重要的因素是降水,其次是光热条件的综合影响((3)预估未来10a粮食产量将继续呈增长趋势,2030年粮食理论产量可达11162.04X104@关键词:气候生产力;粮食产量;黑龙江省中图分类号:S162.3:F326.11文献标识码:A联合国政府间气候变化专门委员会发布的第四次和第五次气候变化评估报告指出:1880—2012年期间,全球平均地表温度升高了0.85L,1850—1900年时期和2003—2012年两个时期平均温度总升温幅度为0.78L,预计2030—2052年间可能达到1.5,这将使全球粮食产量面临重大挑战。
因此加强对气候变化监测和预报对保障全球粮食安全具有重要作用。

1995─2019年甘肃省粮食产量的趋势预测研究粮食生产波动与消费并对未来情况的作出预测,是粮食问题宏观决策和控制的主要条件。
短期研究一般应用多元统计的回归分析方法,从价格、比较效益、投入、经营方式等方面对波动给出了事后解释,却没有令人满意的事前预测。
的确,农业生产的独特性增加了对它预测的难度,因为事先并不知道当年农业实际投入与未来实际气候条件。
所以,避开上述这一切因素,仅仅研究这些因素交互作用下的客体粮食自身的变化,以求得某种规律。
本文正是基于这种思想,根据1949──1994年甘肃省粮食产量历史资料,运用自回归动平均模型简称模型,对我省未来粮食生产量情况所做的一次有益的尝试性研究。
一、三因素的选择一个经济时间序列{x}=1,2,…,,通常认为由三种因素组成,即长期趋势、周期因素季节因素、随机因素。
对于一个时间序列,宜于选用自相关分析图来判别序列的平稳性与周期,并且通过自相关和偏相关分析图确定模型的自回归阶与动平阶。
⒈自相关系数-=1∑-+-=─────────=1∑-2其中为{}=1,2,…,的平均值,为滞后期的自相关系数。
1平稳性识别如果=1,…,随着增大而迅速靠近零,或散乱地分布在零点周围,则认为序列平稳;否则非平稳。
对于非平稳序列,通过差分,消除其趋势。
2周期识别对于一平稳序列,观察其自相关分析图,如果每隔时间,自相关系数显著偏高,可以认为该序列具有周期;否则,无周期无季节性。
⒉偏自相关系数在已知自相关系数的条件下,解如下一系列方程组│11……-1││ρ1││1││11……-2││ρ2│=│2││││││││-1……1││ρ│││得到偏自相关系数ρ11,ρ22,…,ρ。
然后根据自相关系数和偏自相关系数的截尾与拖尾确定自回归阶与动平均阶。

组合预测方法及其在粮食产量预测中的应用
组合预测方法是指将多种预测方法结合起来,综合利用各种预测方法的优点和不足,从而提高预测精度和可靠性的方法。
组合预测方法可以包括统计学方法、机器学习方法、时间序列分析方法等,其具体应用方法可以根据实际预测对象和需求进行选择和调整。
在粮食产量预测中,组合预测方法可以结合多种因素和模型,包括但不限于:
基于经验模型和统计模型的预测方法,如趋势分析法、灰色预测法、ARIMA模型等。
基于机器学习的预测方法,如神经网络模型、支持向量机模型、随机森林模型等。
基于专家经验和先验知识的预测方法,如层次分析法、模糊综合评价法等。
在应用组合预测方法时,需要综合考虑各种预测方法的优缺点,选择适合当前预测对象和需求的预测方法进行组合。
在粮食产量预测中,可以根据历史数据、气象数据、土壤数据、种植面积数据等因素进行分析和建模,从而进行预测和评估。
同时,在实际应用过程中,需要不断优化和更新预测模型,以确保预测的准确性和可靠性。
总之,组合预测方法在粮食产量预测中具有广泛的应用前景,可以提高预测精度和可靠性,为农业生产和粮食安全提供重要支持和保障。

如何使用测绘技术进行粮食产量监测与预测近年来,随着粮食安全问题的日益突出,粮食产量的监测与预测变得尤为重要。
测绘技术作为现代科技的重要组成部分,为粮食产量监测与预测提供了强大的支持。
本文将探讨如何使用测绘技术进行粮食产量监测与预测。
首先,测绘技术在粮食产量监测中的应用不可忽视。
通过空间遥感技术,可以对农田进行全面、快速的监测。
利用卫星遥感数据,可以获取高精度的农田覆盖面积、农作物类型等信息。
这些数据可以直接用于粮食产量的监测与预测,为决策者提供科学依据。
同时,利用无人机进行航测,可以获取更加详细、精准的农田信息,为粮食产量的预测提供更可靠的数据支持。
其次,测绘技术在粮食产量预测中的应用也非常广泛。
通过高精度的地理信息系统(GIS)技术,可以对农田土壤质量、水源分布等因素进行定量排查。
利用测量仪器,可以对农田进行实地调查和采样,进一步分析土壤中的养分含量、酸碱度等指标。
这些数据与历史产量数据进行对比分析后,可以建立粮食产量与土壤质量、水源分布等因素之间的关联模型。
基于这些模型,可以对未来粮食产量进行预测,为农业生产提供决策支持。
此外,测绘技术也可以用于灾害监测与预警。
自然灾害如干旱、水灾等对粮食产量有着直接的影响。
利用测绘技术获取的高分辨率卫星影像和无人机航测数据,可以实时监测农田的生长状况,并通过遥感数据与农田观测数据的对比分析,提前预警灾害发生的可能性。
基于这些预警信息,农户和政府可以采取相应的措施,保障粮食生产的稳定性。
此外,测绘技术在粮食产量监测与预测中的应用还可以延伸到农业供应链管理。
通过建立农田地理信息数据库和粮食产业链的地理信息系统,可以实现对粮食生产全过程的监控与优化。
利用数据挖掘和人工智能等技术,可以对农田的种植情况、农作物生长状况等进行实时监测和分析,为农业生产提供精细化管理。
同时,通过粮食产量预测模型和市场预测模型的结合,可以实现对粮食供应与需求的平衡,避免产销失衡的情况发生。

小麦产量预测模型研究近年来,农业成为了越来越多人所关注的领域,其中小麦作为主要粮食作物之一,因其广泛的种植、重要的经济价值和社会意义备受瞩目。
通过对小麦产量的预测,可以帮助农民做好商业决策,在农业生产中取得更高的效益。
因此,小麦产量预测模型的研究显得尤为重要。
一、研究背景小麦的生长过程受多种因素的影响,如气温、降雨量、土壤养分、农业技术等。
而传统的预测方法主要是依据观测值和历史数据进行分析,存在预测精度低、不稳定等缺点。
现代的技术手段和计算机技术的快速发展,为小麦产量预测模型的研究提供了广阔的空间和机会。
因此,研究小麦产量预测模型,提高预测精度,对于全球粮食生产和粮食供给安全具有重要意义。
二、常用小麦产量预测模型1. 时间序列模型时间序列模型是一种根据历史数据和未来趋势预测当前或未来情况的模型,通常适用于常规、季节性和周期性事件的预测。
经典的时间序列模型有ARIMA模型、SARIMA模型等。
这些模型可以使用以往的数据建立出时间序列模型,并通过预测下一时间点上小麦产量来实现预测。
2. 神经网络模型神经网络模型是一种仿生学模型,它通过模仿生物神经元之间相互作用的方式,实现对模型的训练和预测。
神经网络模型主要分为前向网络和反向网络两种,其中前向网络属于传统的神经网络模型,反向网络则广泛应用于小麦产量预测。
它可以建立各种复杂的非线性映射关系,并能够对输入数据自适应处理和预测。
3. 统计回归模型统计回归模型是一种建立因变量与自变量之间关系模型的方法。
在小麦产量预测中,可以利用线性回归、逻辑回归、岭回归等模型建立起小麦产量预测的模型,通过系数分析和残差检验来评估模型的精度和适用性。
三、模型选择与建立在选择合适的小麦产量预测模型时,需要根据不同的数据特点和模型优缺点进行选择。
例如,当数据具有季节性和周期性时,时间序列模型是更为合适的选择;当数据具有非线性关系时,神经网络模型是更好的选择。
而统计回归模型的选择,则要考虑自变量和因变量之间的线性关系。

摘要本文第一章给出了黑龙江省粮食生产状况,粮食产量预测的背景和意义。
第二章给出了多元线性回归的理论主体:包括多元线性回归模型的标准形式,多元线性回归模型的参数估计,模型的检验和预测原理。
第三章应用多元线性回归模型对黑龙江省粮食产量进行预测,分析并确定影响粮食产量的主要因素,建立多元线性回归方程,收集并整理相关数据,应用Eviews6.0软件对多元线性线性回归方程进行参数估计,分别对模型进行拟合程度检验、t检验、f检验,并对自变量进行多重共线性检验,使用逐步回归方法剔除部分自变量,降低自变量间的多重共线性,确定最优回归方程,并应用模型进行粮食产量的预测。
第四章对预测结果及各主要影响因素进行分析解读,最后对黑龙江粮食生产安全提出建议。
关键词:多元回归;多重共线性;逐步回归;粮食产量;预测AbstractThe first chapter of this paper gives the situation of grain production in Heilongjiang Province,and the background and significance of the foodstuff yield prediction.The second chapter gives the multiple linear regression theory, including the standard form of multiple linear regression model,estimation of multiple linear regression model,the method of model test and prediction theory. The third chapter use the multivariate linear regression model to predict the grain yield in Heilongjiang Province. Research and analysis of the main factor that affects grain production,and the establishment of multiple linear regression equation,subsequently collected related data,the application of Eviews software on multiple linear regression equations to estimate the parameters,using the degree of fitting test, t test, F test to detect model,the independent variables were multiple colinearity test,the use of stepwise regression method to eliminate some variables,reduce one of Multicollinearity,determination of the optimal regression equation,then apply the model to the forecast of grain yield.The fourth chapter puts forward suggestions on grain production in Heilongjiang Province.Keywords:multiple regression, multicollinearity, stepwise regression, grain yield, forecast目录序言 (2)第一章课题背景 (3)§1.1 黑龙江省粮食生产状况 (3)§1.2 多元回归分析与预测的引入 (3)第二章多元线性回归的理论主体 (4)§2.1标准多元线性回归模型 (4)§2.2模型的估计 (4)§2.3模型的检验方法和预测原理 (5)第三章应用多元线性回归模型预测黑龙江省粮食产量 (9)§3.1 分析确定影响粮食产量的主要因素 (9)§3.2 回归方程的建立 (10)§3.3 回归模型的估计 (10)§3.4 回归模型的检验 (13)§3.5 自变量的多重共线性及最优方程的确定 (14)§3.6 模型的实际预测 (18)第四章对黑龙江省粮食生产的建议 (20)结束语 (21)谢词 (22)参考文献 (23)序言粮食生产和安全问题是现阶段全球最为关注的问题之一。
新疆粮食产量动态变化及预测分析作者:李振波 | 来源:资源网摘要:本文分析了新疆粮食产量的现状,在此基础上对1949-2006年新疆粮食总产量动态变化情况进行了分析,另外,通过GM(1,1)模型对新疆粮食供需状况进行了预测,通过预测发现新疆未来粮食供需状况在今后相当长一段时期内,应该是可以达到供需平衡的,可以满足自治区“区内平衡、略有结余”的粮食安全目标,并提出了相关对策建议。
关键词:粮食总产量;动态变化;预测;新疆粮食生产在新疆经济中占有重要地位,建国以来,新疆粮食生产取得了突破性发展,特别是党的十一届三中全会后,粮食连续20年丰收,随着西部大开发战略的实施,新疆农业结构战略性调整遇到了历史性机遇。
致使粮食生产成为该地区综合治理、农业持续发展,乃至整个地区国民经济能否按计划快速增长的一个核心问题。
因此,深入研究新疆地区粮食生产的动态变化并对其进行预测分析,对当前和今后农业生产和社会可持续发展具有重要意义。
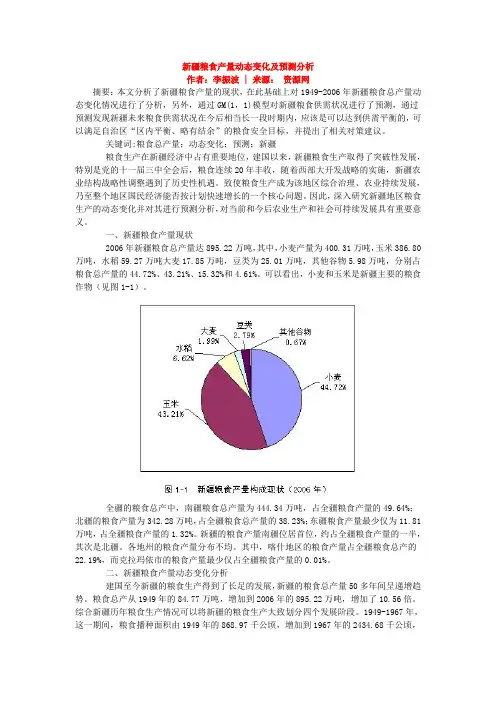
一、新疆粮食产量现状2006年新疆粮食总产量达895.22万吨,其中,小麦产量为400.31万吨,玉米386.80万吨,水稻59.27万吨大麦17.85万吨,豆类为25.01万吨,其他谷物5.98万吨,分别占粮食总产量的44.72%、43.21%、15.32%和4.61%。
可以看出,小麦和玉米是新疆主要的粮食作物(见图1-1)。
全疆的粮食总产中,南疆粮食总产量为444.34万吨,占全疆粮食产量的49.64%;北疆的粮食产量为342.28万吨,占全疆粮食总产量的38.23%;东疆粮食产量最少仅为11.81万吨,占全疆粮食产量的1.32%。
新疆的粮食产量南疆位居首位,约占全疆粮食产量的一半,其次是北疆。
各地州的粮食产量分布不均。
其中,喀什地区的粮食产量占全疆粮食总产的22.19%,而克拉玛依市的粮食产量最少仅占全疆粮食产量的0.01%。
二、新疆粮食产量动态变化分析建国至今新疆的粮食生产得到了长足的发展,新疆的粮食总产量50多年间呈递增趋势。
基于深度学习的小麦产量预测模型研究一、引言随着全球人口的不断增长和耕地面积的有限性,提高农作物产量成为了农业领域的重要课题。
小麦作为全球重要的粮食作物之一,其产量的预测对于保障粮食安全具有重要意义。
传统的小麦产量预测方法主要依赖于统计模型和经验判断,但这些方法往往存在一定的局限性,如对环境变化的适应性不强,难以处理复杂的非线性关系等。
近年来,随着深度学习技术的快速发展,基于深度学习的小麦产量预测模型逐渐成为研究的热点。
深度学习模型能够自动提取特征并建立复杂的非线性关系,从而提高预测的准确性。
本文将探讨基于深度学习的小麦产量预测模型的研究进展,分析其优势和挑战,并提出未来研究方向。
二、深度学习技术概述深度学习是机器学习的一个分支,它通过构建多层的神经网络来学习数据的高层特征。
与传统的机器学习方法相比,深度学习能够处理更复杂的数据结构,如图像、声音和文本等。
深度学习的核心优势在于其强大的特征学习能力,能够自动从大量数据中学习到有用的信息,而无需人工设计特征。
在农业领域,深度学习技术已经被广泛应用于作物病虫害识别、土壤质量评估、作物生长监测等方面。
在小麦产量预测方面,深度学习技术同样展现出巨大的潜力。
三、小麦产量预测模型的研究进展3.1 数据预处理在构建小麦产量预测模型之前,首先需要对收集到的数据进行预处理。
数据预处理的目的是消除噪声,填补缺失值,标准化数据,以及进行特征选择等。
这些步骤对于提高模型的预测性能至关重要。
例如,可以通过归一化处理来消除不同特征之间的量纲影响,通过主成分分析(PCA)等方法进行特征降维,以减少模型的复杂度和过拟合的风险。
3.2 特征工程特征工程是构建预测模型的关键步骤之一。
在小麦产量预测中,需要从大量的环境因素、土壤条件、作物生长状况等数据中提取出对产量有显著影响的特征。
这些特征可能包括温度、湿度、光照强度、土壤类型、施肥量、病虫害情况等。
通过特征工程,可以将这些原始数据转化为对模型有用的信息,从而提高预测的准确性。
农业信息技术中的粮食产量预测模型构建与优化近年来,随着农业信息技术的不断发展,粮食产量预测模型在农业生产管理中的作用越来越重要。
粮食是人类生活中不可或缺的重要食物之一,预测粮食产量对于农业生产、市场供需调控以及粮食安全具有重要意义。
因此,构建并优化粮食产量预测模型对于提高农业生产管理的效率和粮食供应的稳定性至关重要。
构建粮食产量预测模型需要综合考虑多种因素,包括农作物生长环境、气象条件、土壤质量、种植面积等。
为了准确预测粮食产量,可采用以下方法:首先,建立历史数据模型。
通过收集和整理历年的粮食产量数据,结合相关的农业环境因素和气象数据,建立统计模型。
常用的统计方法包括回归分析和时间序列分析。
回归分析可以通过建立影响粮食产量的参数和因素之间的关系模型,从而预测未来粮食产量。
时间序列分析可根据历史数据的规律性变化,预测未来的产量走势。
这些统计模型可以通过计算机软件进行建模和优化。
其次,采用机器学习算法进行预测。
机器学习算法可以更好地处理大数据量和复杂数据集。
例如,可以使用支持向量机(SVM)算法,通过建立决策边界和分类函数,预测粮食产量。
另外,人工神经网络(ANN)算法也可以用于粮食产量预测。
ANN通过模拟人脑神经元间的连接和传递方式,具备非线性建模能力,可以更好地拟合数据关系。
然后,结合遥感技术进行粮食产量预测。
遥感技术可以获取地表表征、植被指数、土壤湿度等数据,这些数据与粮食产量密切相关。
通过使用遥感数据,可以构建基于空间分布的粮食产量预测模型,进一步提高预测准确性。
最后,优化粮食产量预测模型。
模型的优化可以通过参数调整和模型选择来实现。
参数调整可以通过使用交叉验证方法,最小化模型的误差,提高预测精度。
模型选择可以比较不同模型的预测效果,并选择最优模型。
此外,合理选择预测模型的输入参数和特征,也是提高预测准确性的重要因素。
在实际应用中,粮食产量预测模型的建立和优化仍面临一些挑战和限制。
首先,数据获取困难。
中国粮食播种面积、粮食产量、粮食单产、各省市产量分析及粮食生产情况预测一、2019年中国粮食播种面积、粮食产量、粮食单产各省市产量情况分析粮食是指烹饪食品中,作为主食的各种植物种子总称,也可概括称为“谷物”。
粮食有基本是属于禾本科植物,所含营养物质主要为醣类,主要是淀粉,其次是蛋白质。
2018年全年粮食种植面积11704万公顷,比上年减少95万公顷。
其中,小麦种植面积2427万公顷,减少24万公顷;稻谷种植面积3019万公顷,减少56万公顷;玉米种植面积4213万公顷,减少27万公顷。
棉花种植面积335万公顷,增加16万公顷。
油料种植面积1289万公顷,减少33万公顷。
糖料种植面积163万公顷,增加9万公顷。
2019年,各地积极贯彻落实中央一号文件精神,坚持农业农村优先发展,毫不放松抓好粮食生产,推动“藏粮于地、藏粮于技”落实落地,深入推进农业供给侧结构性改革,在保障粮食生产能力不降低的同时,稳步推进耕地轮作休耕试点工作,调减低质低效作物种植,扩大大豆、杂粮等优质高效作物种植规模,因地制宜发展经济作物,全国粮、经、饲种植结构进一步优化。
《2019-2025年中国粮食行业市场现状分析及投资前景预测报告》数据显示:2019年全国粮食播种面积116064千公顷(174095万亩),比2018年减少975千公顷(1462万亩),下降0.8%。
2019年,各地大力发展紧缺、绿色优质农产品生产,粮食生产品质提升,结构优化。
2018年粮食产量65789万吨,比上年减少371万吨,减产0.6%。
其中,夏粮产量13878万吨,减产2.1%;早稻产量2859万吨,减产4.3%;秋粮产量49052万吨,增产0.1%。
全年谷物产量61019万吨,比上年减产0.8%。
其中,稻谷产量21213万吨,减产0.3%;小麦产量13143万吨,减产2.2%;玉米产量25733万吨,减产0.7%。
2019年粮食产量再创新高,全国粮食总产量66384万吨(13277亿斤),比2018年增加594万吨(119亿斤),增长0.9%。
农作物生长模型改进及其粮食产量预测应用农作物是人类重要的食物来源之一,对其生长模型的改进以及粮食产量的准确预测对于农业发展和人口粮食安全具有重大意义。
本文将探讨农作物生长模型的改进和其在粮食产量预测中的应用。
农作物生长模型是利用数学和物理原理,结合大量实验数据和气象信息,建立起的一种农作物生长的数学模拟方法。
通过模拟和预测,可为农业生产提供科学依据和决策支持。
然而,传统的农作物生长模型在一些方面存在着一定的局限性,需要不断进行改进和优化。
首先,传统的农作物生长模型在对环境胁迫的响应方面需要进一步改进。
环境胁迫包括了温度、水分、光照、营养等因素的限制。
传统模型往往没有考虑到这些胁迫对于农作物生长的影响,导致模型的预测结果与实际情况存在较大差异。
因此,改进模型需要引入环境胁迫指数,进一步细化模型对环境因素的响应,提高模型的预测准确性。
其次,农作物生长模型对不同品种的适应性有待提高。
不同品种的农作物在生长过程中表现出不同的特性和生理响应,传统的模型对于不同品种的生长规律缺乏足够的理解和描述。
改进模型需要考虑到不同品种的特点,建立不同品种的生长模型,提高对不同品种的生长预测准确性。
第三,农作物生长模型在预测农作物生长周期和有效开花期的能力上有待改进。
农作物的生长周期和农作物开花期对于粮食产量的预测和农业管理具有重要意义。
然而,传统模型往往无法准确预测农作物的生长周期以及其有效开花期,从而影响了对农作物粮食产量的预测和农业管理的决策制定。
改进模型需要通过引入更多的生长期划分和环境调节因子,提高对农作物生长过程中重要阶段的预测能力。
改进的农作物生长模型在粮食产量预测中有着广泛的应用。
通过对农作物的生长模拟和预测,可以有效地预测粮食产量。
这对于粮食供应、粮食安全和农业管理具有重大意义。
通过模型预测,政府和农业部门可以及时调整农业政策、科学配置农业资源,提高农作物的产量和质量。
同时,对于粮食供应不足地区,农作物生长模型的精确预测也可以提前采取相应的措施,避免粮食短缺和饥荒的发生。
基于深度信念网络的粮食产量预测徐路路;张德贤【摘要】为了研究地区粮食产量的预测问题,提出了一种基于深度信念网络的粮食产量预测模型,利用改进K-means算法构建数据集预处理模型,通过多层受限玻尔兹曼机构建深度信念网络的预测模型,并利用对比散度算法训练预测模型.以河南省西华县1996-2016年小麦产量、种植面积与降雨量数据作为应用研究实例,将1996-2013年的小麦产量、种植面积与降雨量数据作为建模样本、2014-2016年的相关数据作为测试样本,进行预测模型的研究.结果表明,基于深度信念网络的粮食产量预测模型的平均预测精度超过97%,说明深度信念网络适用于地区粮食产量的预测,为粮食产量预测提供了一种新方法.【期刊名称】《河南工程学院学报(自然科学版)》【年(卷),期】2019(031)001【总页数】4页(P77-80)【关键词】受限玻尔兹曼机;深度信念网络;小麦;产量预测【作者】徐路路;张德贤【作者单位】河南工业大学信息科学与工程学院,河南郑州450001;河南工业大学信息科学与工程学院,河南郑州450001【正文语种】中文【中图分类】TP181粮食产量不仅关系民生,而且对国家的稳定也具有重要的战略意义。
粮食产量的准确预测可为政府推出相关措施提供依据,从而确保国家发展的长期稳定。
小麦作为我国农作物中的主要品种,是各粮食大省种植面积最多的作物,故对小麦产量的预测至关重要。
近年来,粮食产量预测研究一直是热门课题,有学者提出时间序列、回归分析和支持向量机等方法[1-2],但此类方法均是将粮食产量关系假定为线性关系进行的,而就实际情况而言,粮食产量受降雨量、种植面积等众多因素的影响而经常呈现出非线性、波动性大等特点[3-4]。
因此,传统的基于线性、平稳时间序列的预测方法很难精准预测出粮食的产量。
2006年,Hinton等[5]提出深度信念网络的概念后迅速得到了广大学者的高度关注,其在预测回归方面的应用也得到了充分的肯定[6-7]。
粮食产量的预测与决策支持粮食是人类的基本生活物资,而粮食产量的预测与决策支持对于国家粮食安全、农业发展和市场调控都具有重要意义。
然而,粮食产量的预测涉及到多个因素的综合考量和评估,同时还需要以科学的方式为决策者提供准确的支持。
本文将就粮食产量预测的方法和决策支持的关键措施进行探讨。
预测方法一、模型预测模型预测是粮食产量预测中常用的方法之一。
该方法基于历史数据和统计分析,建立了反映粮食产量与影响因素之间关系的模型。
通过对模型进行参数估计和误差修正,可以预测未来的粮食产量。
常用的模型有趋势模型、灰色模型和ARIMA模型等。
趋势模型是基于时间序列分析的方法,能够揭示粮食产量的长期趋势和周期性变化。
灰色模型则利用少量的数据,通过建立灰色微分方程来预测粮食产量。
ARIMA模型结合了时间序列的自回归和滑动平均分析,对粮食产量进行预测。
二、遥感技术遥感技术是粮食产量预测中一种新兴的方法。
它利用卫星遥感技术获取农作物的生长状态和农田的空间分布,从而推测粮食产量。
通过遥感图像的解译和数据分析,可以获取农田的植被指数、叶面积指数等参数,并结合气象数据和土壤质量等因素,建立相应的预测模型进行预测。
遥感技术具有操作灵活、数据更新快、覆盖范围广等优势,可以实现对大范围、长周期的粮食产量进行实时监测和预测。
同时,遥感技术还可以帮助监测病虫害、灾害等因素对粮食产量的影响,为决策者提供决策支持。
决策支持措施一、信息平台建设为了支持粮食产量的预测与决策,需要建设一个信息平台来集成、管理和分析各类数据。
这个信息平台应该包括气象数据、农业统计数据、遥感数据、粮食市场数据等多种数据源,利用数据挖掘和机器学习的方法,提取其中的关联规律,为决策者提供科学的参考和建议。
二、制定科学政策粮食产量的预测与决策支持是为了指导政府制定相关政策。
政府应该依据预测结果和市场需求,制定科学、合理的粮食生产政策和市场调控政策,促进粮食生产和农业发展。
同时,政府还应该加大对农业科技的投入,推广先进的农业技术和管理方法,提高农业生产的效率和质量,保障粮食产量的稳定增长。
粮食产量预测国内外文献综述“为政之要,首在足食”。
粮食安全始终是关系我国国民经济发展、社会和谐稳定和国家安全自立的全局性重大战略问题。
这是由于粮食不仅是关系到国计民生和国家安全的重要战略物资,也是人民群众最基本的生活资料。
从当前粮食的供给来看,我国基本解决温饱问题,正在全面建设小康社会,粮食单产稳步提高,粮食生产获得十年连续增长。
从粮食需求来看,我国正在大力推进新型工业化、信息化、城镇化和农业现代化道路(简称“四化”),人口规模和居民膳食结构的变化,以及全球气候变化和资源环境约束导致给粮食安全带来了新的矛盾与挑战。
据国家统计局发布的公告,2013年我国粮食产量达到60193. 5万吨,连续7年稳定在5亿吨以上水平。
但是,随着我国人口的继续增长、城乡居民膳食结构的不断升级及工业化、城镇化的快速推进,粮食消费需求增长的速度快于粮食供给增长的速度,供需缺口不断扩大。
2012年我国粮食净进口规模达到7718万吨,粮食年度自给率己降至88.4%,其中大豆自给率仅18.1%。
新形势下,我国粮食安全面临粮食需求不断增长和水、土地及劳动力资源消耗不断加快的双重挑战,确保我国中长期粮食安全及主要农产品有效供给难度加大。
粮食生产受到多重因素的制约,未来产量如何变动,是否能够保障国家粮食安全是一个十分现实而且紧迫的问题。
因此,如何有效的分析和预测我国粮食生产能力,对加强粮食宏观调控、促进政策调整和保障粮食安全具有十分重大的意义。
目前国内外学者围绕着粮食安全、粮食生产、粮食消费与贫困等问题展开了深入而广泛的研究。
我国学者对粮食产量的预测模型总体上来说大致可以分为三大类: 时间序列模型、回归模型和人工神经网络模型。
指数平滑模型、灰色预测模型及基于马尔可夫链的预测模型等都属于时间序列模型。
回归模型中使用比较多的就是线性回归模型和双对数模型。
人工神经网络模型是近几年才开始使用的基于生物学原理的预测系统。
这些方法的优缺点分析如下:(一)指数平滑模型指数平滑模型的原理和计算方法比较简单,对历史数据的数量没有太大的要求。
迟灵芝( 2004)曾运用单指数平滑方法首先对我国1991-1999年的粮食产量进行拟合,计算出平均相对误差为0104%,效果还是比较理想的。
但是模型中对平滑系数的确定直接关系到模型的精度问题,所以不同的平滑系数就可能造成结果的差异。
目前为止没有一个固定的方法来确定平滑系数。
在一般的研究中大多是根据经验来选择平滑系数,这就导致了预测结果的失真性。
林绍森等( 2007)对三种预测模型的分析的结果证明了指数平滑法的预测误差最大。
此外,由于模型本身在计算方法上的局限性,该方法只适用于近、短期预测。
灰色预测模型也是比较常用的粮食产量预测模型。
迟灵芝( 2002)对灰色预测方法和回归模型进行比较分析,得出灰色预测的平均相对误差最小的结论。
林绍森等( 2007)对单指数平滑、自回归移动平均和灰色预测三种模型进行了比较,他指出灰色预测模型比自回归预测模型和单指数平滑预测模型更适合长期的预测。
线性(或非线性)回归模型的一个优点是可对变量之间进行因果分析,描述其内在的联系。
很多学者利用这一方法建立了粮食产量模型,找到了影响粮食产量的主要因素。
如李子奈( 2000)的线性回归函数、石森昌等( 2003)的双对数生产函数、李云松等( 2002)、肖海峰等( 2004)、程杰等( 2007)的柯布-道格拉斯生产函数等等。
虽然他们选取的变量都不尽相同,但是都证明了回归模型对粮食产量的拟合效果很好。
但是回归方法受到解释变量的约束,一般也只用在近、短期预测中。
(二)神经网络模型神经网络模型是一种建立在生物学神经元基础上的一个不需要建立解释变量与被解释变量之间具体关系的数学模型。
它可以通过隐含层的学习和训练实现输入元素与输出元素之间的非线性映射。
该模型的模拟效果可以在王启平( 2002)、禹建丽等(2004)的文章中看到。
但是目前我国尚无比较完善和成熟的理论指导网络模型,在神经网络的程序设计中对隐含层单元数及目标参数的设置都只能凭经验或者是经过反复的训练和测试才能确定。
总之,每个模型都有其优点和不足之处。
对于数据比较少的短期预测问题, 应用简单的指数进行平滑。
对于结构复杂、影响因素众多的中长期问题一般用灰色预测模型。
回归模型一般用来做因素分析,而且预测期较短。
此外,我国学者对粮食产量方面的研究绝大多数还是基于单一的模型。
单一模型预测的缺点就是对预测对象的分析具有一定的局限性。
即通过对被预测对象所处的环境,结合自身模型的特点做出某些假设。
所以在各因素的选取及模型的设计等方面都是不完善的。
而组合预测模型就能利用更多的信息,使单一模型之间优势互补,提高了模型的精度。
(三)组合预测模型所谓组合预测,是指采用两种或两种以上的方法对同一对象进行预测,并对各单个预测结果进行加权综合。
根据组合定理,即使一个预测结果不理想的方法,如果它含有系统的独立信息,当与另一个较好的预测方法进行组合后,同样可以增加系统的预测性能。
因此,组合预测能够更大化地利用有用信息,比单一预测方法更为科学、有效,并能提高模型的模拟精度。
自1969年Bates与Granger首先提出组合预测以来,对组合预测理论及应用的研究先后在国内外逐渐开展起来。
但是近几年我国学者才将这一方法应用到粮食预测领域。
理论和实践研究都表明,在诸种单项预测模型各异且数据来源不同的情况下,组合预测模型可能获得一个比任何一个独立预测值更好的预测值,组合预测模型能减少预测的系统误差,显著改进预测效果。
肖彰仁( 1999)、张海云等( 2002)、吴春霞等( 2002)、丁晨芳( 2007)在预测粮食产量时都运用了组合模拟分析方法,只不过在组合中所嵌入的模型不同,但是却得出同样的结论,即组合预测模型的预测精度比单一模型要高。
组合预测法的基本思路是,运用两种或两种以上的预测方法对同一预测项目进行预测,再根据各个方法的权重将所得结果综合成一个预测结果。
假设对同一问题有N 种预测方法,通过计算分析,确定方法j 的权重为Wj ( j= 1, 2, 3, ,, N) , 则组合预测理论模型为:Y = W 1Y t1+ W 2Y t2 + + W N Y tN ,且∑W j = 1其中,Y tj 表示在t 时间第j 种方法的预测值;Y t 表示在t 时间组合预测的预测值。
在组合预测中,合理的权重会大大提高预测精度。
因此,如何选择权重就成为决定该模型拟合效果的关键。
根据以往的研究,权重选择方法有算术平均法、标准差法、方差倒数法、均方倒数法、离异系数法、AHP 法、德尔菲法、最优加权法等。
其中, 使用比较广泛、误差较小且操作方便的就是方差倒数法。
其原理为:对误差平方和小的模型赋予较高的权重,误差平方和大的赋予较小的权重。
其应用公式如下:W j =D j −1∑D j −1N J=1⁄ 其中, ∑D j −1N J=1=1(j=1,2,…N ) 上式中,D j 为第j 个模型的误差平方和,即D j =∑(Yt−Y tj )2N j=1 (四)灰色预测模型GM (1,1)(五)HP 滤波分析方法HP 滤波分析方法是分析时间序列中的长期趋势和波动成分的方法。
它是在Hodrick 和Prescott 于1980年分析战后美国经济周期的论文中首次使用的。
这种方法可以测算出经济发展的周期趋势(产出缺口,即实际产出与潜在产出之差, 它是指现有条件下实际产出离最大的潜在产出的差距)和无周期趋势的内在趋势(即潜在产出,它是指社会经济活动在没有劳动力失业、在现有资源和技术水平下, 最大的产出水平)。
农产品产量的预测是十分重要的,这是因为他可以改进作物管理和调控市场,更进一步而言,如果产量可以精准的预测出来,那么农业投入如化肥、水和农药等田间操作可以根据作物的实际需求进行有效提供。
农产品产量的难以预测性和产量的变化性特点给政策调整带来困难,它也容易导致精准农业的决策支持系统难以凑效。
在农作物产量的预测方面,最初的预测方法主要采用相关和多元线性回归方法(multiple linear regression,MLR),这一方法需要考虑影响农作物产量的重要因素(Kravchenko and Bullock,2000;Park et al.,2005;Huang et al.,2010)。
但是采用上述方法对农作物产量的预测效果不是很明显,其原因是由于该模型没有考虑多项式和内生项的存在。
在线性模型分析中,描述粮食产量和影响变量之间的线性关系方面是受到限制的,而且当这些关系不是线性关系时预测结果就可能会造成误导。
另外一种预测农作物如粮食产量的方法是综合运用多变量技术进行多步回归(Jiang and Thelen,2004;Fortin et al.,2010),比如主成分分析方法(principal component analysis,PCA)和因子分析方法(factor analysis,FA)。
上述方法试图最小化内生变量导致的问题,使复杂关系之间的解释变得容易,并力图减少数据维度或者从大量数据中筛选出一套合适的变量。
之后,对农作物的预测方法逐渐采用人工智能方法和计算机技术进行分析。
人工神经网络(Artificial neural networks,ANNs),作为一个非线性的统计技术,也被用于分析和调查农作物的产量当中。
其中,ANN分析已经用于精准农业的空间分析和农作物田间管理(Kitchen et al.,2003)。
这一方法,比较适于分析由于投入和产出相关的变量调整导致的问题,可以认为是一种非线性的分析工具,人工神经网络可以和其他人工智能技术或者统计分析方法相结合,可以避免人工智能需要大量训练数据的缺点。
Papageorgiou et.al(2013)利用模糊认知图方法(Fuzzy Cognitive Maps,FCMs)预测了希腊的苹果产量,FCMs是一个分析因果认知关系并方便建模和模拟动态系统的理想工具,其利用一个概念模型可以分析和描述人类对既定体系的认知。
并不局限于准确的价值标准和评价方法。
这一模型的优点包括,简单、适应性强和能够接近抽象的结构,因其有助于解决复杂的问题能适用于不同的情景而获得广泛应用。
该方法还具有动态的特点和学习能力,可用于农作物的产量预测和农作物管理。
小麦作为欧洲国家十分重要的农作物,2002-2012年间平均年产小麦1.26亿吨,在维持欧洲国家的粮食安全方面发挥了十分重要的作用。
Kowalik et.al (2014)利用1999-2009年间标准站点不同植被的标准化指数统计数据和1km空间范围内的冬季活动雷达预测了欧洲国家小麦的产量,其所使用的站点植被产品利用官方小麦产量数据对模型做了微调,基于最小二乘回归方法(Partial Least Squares Regression,PLSR)做了分析。