数据抽取与主题开发基础流程
- 格式:docx
- 大小:22.29 KB
- 文档页数:12

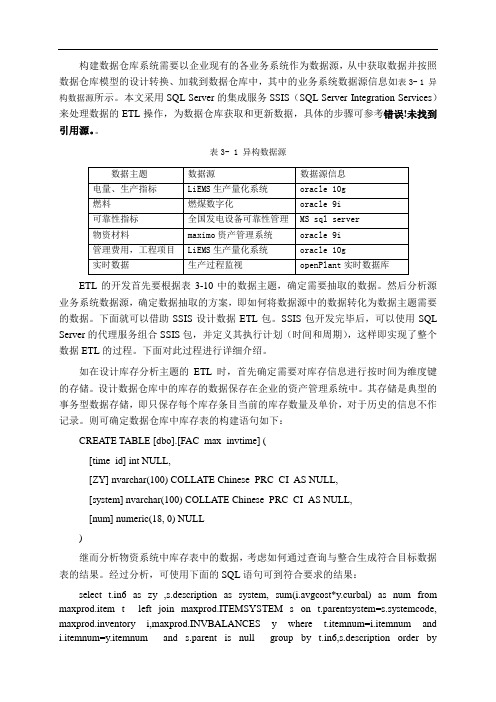
构建数据仓库系统需要以企业现有的各业务系统作为数据源,从中获取数据并按照数据仓库模型的设计转换、加载到数据仓库中,其中的业务系统数据源信息如表3- 1 异构数据源所示。
本文采用SQL Server的集成服务SSIS(SQL Server Integration Services)来处理数据的ETL操作,为数据仓库获取和更新数据,具体的步骤可参考错误!未找到引用源。
表3- 1 异构数据源数据主题数据源数据源信息电量、生产指标LiEMS生产量化系统oracle 10g燃料燃煤数字化oracle 9i可靠性指标全国发电设备可靠性管理MS sql server物资材料maximo资产管理系统oracle 9i管理费用,工程项目LiEMS生产量化系统oracle 10g实时数据生产过程监视openPlant实时数据库ETL的开发首先要根据表3-10中的数据主题,确定需要抽取的数据。
然后分析源业务系统数据源,确定数据抽取的方案,即如何将数据源中的数据转化为数据主题需要的数据。
下面就可以借助SSIS设计数据ETL包。
SSIS包开发完毕后,可以使用SQL Server的代理服务组合SSIS包,并定义其执行计划(时间和周期),这样即实现了整个数据ETL的过程。
下面对此过程进行详细介绍。
如在设计库存分析主题的ETL时,首先确定需要对库存信息进行按时间为维度键的存储。
设计数据仓库中的库存的数据保存在企业的资产管理系统中。
其存储是典型的事务型数据存储,即只保存每个库存条目当前的库存数量及单价,对于历史的信息不作记录。
则可确定数据仓库中库存表的构建语句如下:CREATE TABLE [dbo].[FAC_max_invtime] ([time_id] int NULL,[ZY] nvarchar(100) COLLATE Chinese_PRC_CI_AS NULL,[system] nvarchar(100) COLLATE Chinese_PRC_CI_AS NULL,[num] numeric(18, 0) NULL)继而分析物资系统中库存表中的数据,考虑如何通过查询与整合生成符合目标数据表的结果。

数据开发是指在数据工程中,从原始数据源中提取、转换、加载(ETL)数据,以满足数据分析、报告、机器学习等需求的过程。
以下是数据开发的一般过程介绍:1. **需求分析**:- 理解业务需求:首先,数据开发团队需要与业务部门合作,明确他们的需求和目标。
这有助于确定要提取和处理的数据。
2. **数据提取(Extract)**:- 数据源识别:确定数据来源,这可以包括数据库、API、日志文件、云服务等。
- 数据抽取:使用工具或脚本从数据源中提取数据,并将其转换为可用的格式。
通常,数据提取涉及到筛选、选择列、数据转换等操作。
3. **数据转换(Transform)**:- 数据清洗:处理不一致、不完整或错误的数据,例如处理缺失值、去除重复数据、处理异常值等。
- 数据转换:将数据转换为适合分析的结构,例如将日期格式标准化、进行聚合、创建派生字段等。
- 数据合并:将多个数据源的数据合并为一个一致的数据集。
4. **数据加载(Load)**:- 将转换后的数据加载到目标存储区域,如数据仓库、数据湖、数据库等。
- 数据仓库通常用于存储历史数据,而数据湖通常用于存储原始数据以及数据湖中的原始拷贝。
5. **调度和自动化**:- 使用调度工具(如Apache Airflow、Cron Job等)来自动执行数据开发任务,确保数据的定期提取、转换和加载。
- 设置监控和报警机制,以便及时发现和处理数据开发过程中的错误和异常。
6. **质量控制和测试**:- 实施数据质量控制措施,确保数据的准确性和一致性。
- 进行单元测试、集成测试和端到端测试,以验证数据开发过程的正确性。
7. **文档和元数据管理**:- 创建文档以记录数据开发过程,包括数据流程、字段定义、数据字典等。
- 管理元数据,以便跟踪数据的来源、变化和使用情况。
8. **维护和优化**:- 定期维护数据开发工作流程,确保它们仍然满足业务需求。
- 优化数据开发过程,提高效率和性能。

大数据数据抽取流程Data extraction is a critical process in big data analysis. 大数据分析中的数据抽取是一个非常关键的步骤。
It involves retrieving data from various sources such as databases, data warehouses, and other storage systems. 它涉及从各种来源,如数据库、数据仓库和其他存储系统中检索数据。
Data extraction is essential for businesses and organizations to gain insights and make informed decisions based on the data. 数据抽取对于企业和组织来说非常重要,可以帮助他们获得洞察并基于数据做出明智的决策。
There are several steps involved in the data extraction process, including identifying data sources, designing extraction methods, and transforming the data for analysis. 数据抽取过程涉及几个步骤,包括识别数据来源、设计抽取方法以及转换数据以进行分析。
In this article, we will explore the data extraction process in big data analysis and its significance.The first step in the data extraction process is to identify the data sources. 数据抽取过程中的第一步是识别数据来源。

数据抽取样例流程Data extraction is a process of collecting and retrieving specific data from various sources to be used for specific purposes. 数据抽取是从各种来源收集和检索特定数据的过程,以用于特定目的。
It involves extracting, transforming, and loading data from heterogeneous data sources such as databases, spreadsheets, and text files. 它涉及从异构数据源(如数据库、电子表格和文本文件)中提取、转换和加载数据。
Data extraction is crucial in various industries and business functions, as it enables organizations to make informed decisions based on accurate and timely data. 数据抽取在各行各业和业务功能中至关重要,因为它使组织能够根据准确和及时的数据做出明智的决策。
The first step in the data extraction process is to identify the specific data that needs to be retrieved. 数据抽取过程的第一步是确定需要检索的特定数据。
This involves understanding the business requirements and objectives for extracting the data, as well as identifying the sources where the data is located. 这涉及了解抽取数据的业务需求和目标,以及确定数据所在的来源。

etl开发流程ETL开发流程。
ETL(Extract, Transform, Load)是指从数据源中抽取数据,然后对数据进行转换,最终加载到目标数据库中的一种数据处理过程。
在现代数据分析和商业智能领域,ETL流程扮演着至关重要的角色。
本文将介绍ETL开发的流程,帮助读者更好地理解和应用ETL技术。
1. 需求分析。
ETL开发的第一步是需求分析。
在这个阶段,我们需要与业务部门和数据分析师沟通,了解他们的需求和期望。
通过与业务人员深入交流,我们可以明确数据的来源、格式、质量要求,以及最终数据处理后的展现形式。
需求分析阶段的重要性不言而喻,它直接影响后续的数据抽取、转换和加载工作。
2. 数据抽取。
一旦需求分析完成,接下来就是数据抽取阶段。
在这个阶段,我们需要从各种数据源中抽取数据,这可能涉及到关系型数据库、非关系型数据库、日志文件、API接口等。
数据抽取的方式多种多样,可以通过SQL查询、调用API接口、文件传输等方式来实现。
在数据抽取过程中,我们需要考虑数据的完整性、一致性和性能等方面的问题。
3. 数据转换。
数据抽取后,接下来是数据转换阶段。
在这个阶段,我们需要对抽取的数据进行清洗、处理、合并等操作,以满足最终的数据分析和报表展现需求。
数据转换可能涉及到数据清洗、数据格式转换、数据合并、计算衍生指标等工作。
数据转换的质量直接影响到最终数据的可用性和准确性。
4. 数据加载。
最后一个阶段是数据加载。
在这个阶段,我们需要将经过抽取和转换的数据加载到目标数据库中,以供后续的数据分析和报表展现。
数据加载可能涉及到全量加载、增量加载、定时加载等不同方式。
在数据加载过程中,我们需要注意数据的完整性、一致性和性能等方面的问题。
5. 测试和维护。
除了上述的ETL开发流程,测试和维护也是非常重要的环节。
在ETL开发完成后,我们需要进行各种测试,包括单元测试、集成测试、性能测试等,以确保ETL流程的稳定性和可靠性。
同时,我们还需要建立监控和报警机制,及时发现和解决ETL流程中的问题,保证数据的及时性和准确性。
收稿日期:2008-06-10基金项目:国家十一五科技支撑计划重大疑难疾病中医防治研究项目(2006BA I 04A21)作者简介:谢雁鸣(1959-),女,吉林长春人,研究员,博士生导师,学士,研究方向:中医临床疗效评价方法学。
通讯作者:廖星,E -m a i :l ok fro m 2008@h ot m ai.l co m 。
折的发生,女贞子有雌激素样作用,能抑制骨吸收。
临床结果证实,以补通结合为治法特点的静顺袋泡茶对治疗围绝经期综合征进而预防绝经后骨质疏松症的形成和发展,具有明显的协同作用,我们有必要深入研究其作用机理,以便开发出具有防治结合特点的功能性保健食品。
3 疗效探讨抗衰机理静顺袋泡茶临床应用具有显著疗效,为了探讨其抗衰机理,我们进行了临床性激素测定和动物实验预防绝经后骨质疏松症的研究。
临床研究表明,围绝经期综合征患者经静顺袋泡茶治疗3个月后,反映卵巢功能衰退的雌激素水平有不同程度的上升,治疗组雌激素(E 2)上升的幅度优于对照组(P <0.05),促卵泡激素(FS H )水平治疗后下降,与疗前比较有统计学意义(P <0.05)。
对绝经后骨质疏松模型的动物实验研究提示,静顺袋泡茶干预后能延缓和改善骨质疏松大鼠骨代谢指标(C a ,AKP 、Ca /C r 、P /Cr)的改变(P <0.05~0.01),提示其具有一定的抗骨质疏松作用,机制可能与其抑制骨吸收,减少骨丢失,促进骨形成有关。
在骨质疏松的发病过程中白细胞介素6(I L -6)分泌增多,且又通过刺激破骨细胞活动,促进骨吸收,加速骨疏松的发展,静顺袋泡茶能降低大鼠血清I L -6含量提示其抑制骨吸收作用与减少I L -6分泌有关。
临床研究表明,静顺袋泡茶尚能温和提升雌性激素水平进而对围绝经期综合征早期所出现的烘热出汗与晚期所表现的骨质疏松均具有良好的防治作用。
国内同类技术多以单味药制成袋泡茶,以保健形式提高雌激素水平,作用单一。
数据开发流程数据开发是指针对数据的采集、清洗、建模和分析等过程中所需的各种开发任务的总称。
在实际工作中,数据开发往往由专门的数据团队来负责,他们会根据业务需求和数据流程的特点来组织和执行开发工作。
本文将介绍一种常见的数据开发流程,包括需求分析、数据采集、数据清洗、数据建模和数据分析等步骤。
1. 需求分析需求分析是整个数据开发流程的第一步,其目的是明确业务需求,并将其转化为数据需求。
在需求分析阶段,数据开发团队通常与业务团队紧密合作,进行沟通和讨论,以确保对业务需求的准确理解。
需求分析的主要任务包括:•和业务团队进行沟通,了解业务需求和目标;•分析数据来源和数据质量,评估可行性;•明确数据需求和指标定义,对数据进行抽象和统一定义;•确定数据开发的优先级和时间计划。
2. 数据采集数据采集是从各个数据源获取数据的过程,包括内部系统、外部接口、第三方数据源等。
数据采集一般分为以下几个步骤:1.确定数据源:根据需求分析结果,确定需要的数据源。
2.获取数据源访问权限:获取访问数据源的权限或者账号密码。
3.编写数据采集脚本:根据数据源的访问方式(如数据库、API接口、文件等),编写相应的数据采集脚本。
4.执行数据采集脚本:按计划执行数据采集脚本,将数据导入到指定的数据存储中(如关系型数据库、NoSQL数据库、数据仓库等)。
在数据采集过程中,需要考虑以下问题:•数据源的稳定性和可靠性;•数据获取的频率和时效性;•数据的安全性和保密性。
3. 数据清洗数据清洗是指对采集到的原始数据进行预处理和清洗,以保证数据的准确性和一致性。
数据清洗一般包括以下几个阶段:1.数据预处理:对原始数据进行格式转换、字段提取、数据合并等操作,以便后续的处理和分析。
2.数据清理:对数据进行去重、缺失值处理、异常值处理等操作,修复数据错误。
3.数据整合:将不同数据源的数据进行整合和合并,生成一致的数据集。
4.数据标准化:对数据进行标准化处理,如单位转换、编码转换等,以满足数据分析的需求。
数据仓库设计与建模的流程与方法数据仓库是一个用于集中存储、管理和分析企业中各类数据的系统。
它旨在帮助企业更好地理解和利用自己的数据资源,支持决策和战略制定。
数据仓库的设计与建模是数据仓库开发的关键步骤之一。
本文将介绍数据仓库设计与建模的流程与方法。
数据仓库设计与建模流程数据仓库设计与建模是一个迭代的过程,包括以下主要步骤:1.需求收集和分析在数据仓库设计与建模之前,首先需要与业务用户和决策者进行充分的沟通和需求收集。
了解用户的需求和业务流程对于数据仓库的设计和建模至关重要。
通过与用户的交流,收集到的需求可以被细化和明确以指导后续的工作。
2.数据源选择和数据抽取确定需要从哪些数据源抽取数据,并选择合适的数据抽取工具或技术。
根据需求收集和分析的结果,进行数据抽取和转换,将源系统的数据导入到数据仓库中。
这个步骤是数据仓库设计与建模中的重要部分,关系到数据质量和数据一致性。
3.物理数据模型设计在物理数据模型设计阶段,将逻辑数据模型转化为物理数据模型。
物理数据模型设计包括确定表、字段、索引、分区等物理数据库对象的详细定义。
需要考虑到性能和存储方面的因素,并根据数据仓库的查询需求进行优化设计。
4.维度建模维度建模是数据仓库设计与建模的核心技术之一。
它通过标识和定义业务过程中的关键业务概念,如事实表、维度表和维度属性,来描述业务应用中的事实和维度关系。
维度建模的目标是提供用户友好的数据表示,支持灵活且高效的数据查询和分析。
5.粒度定义和聚合设计决定数据仓库的数据粒度是数据仓库设计与建模的一个重要决策。
粗粒度数据更适合用于高层次的分析和决策,而细粒度数据则支持更详细的数据分析。
聚合设计是为了提高数据仓库的性能和查询响应时间而进行的,它通过预计算和存储汇总数据来减少复杂查询的计算量。
6.元数据管理元数据是指描述数据的数据,是数据仓库设计与建模过程中不可忽视的一部分。
元数据管理包括收集、维护和管理数据仓库中的元数据信息,为数据仓库开发、运维和使用提供支持。
数据抽取、主题报表基础开发流程示例1数据抽取根据SG186一体化平台数据标准,相关数据抽取流程如下:为了使用户能更全面的了解数据体系的原理及应用流程。
下面我们以生产数据为例,详细演示数据的抽取的过程。
抽取模块:(中间到基础,基础到主题,基础到支撑)下面以基础表到主题表的数据抽取为例,予以详细说明。
另外,基础到支撑表的抽取与基础到主题抽取建模类似。
1.1明细表(源表)例:SC_DEV_EXAM_REP(生产设备检修基础表)表。
表结构如下:目标表T_SC_EQUIP_REPAIR(设备检修主题表)表.其表结构如下:附:T_SC_EQUIP_REPAIR(设备检修主题表)主题表数据标准。
定义宏为了移植方便,要定义宏。
应用于整个数据抽取流程。
其中定义了生产、营销的中间库、基础库、主题库的连接方式(ORACLE 9i、ORACLE 10g等数据库的连接方式)、数据库实例、用户名、密码以及数据抽取的时间戳。
(定义宏)设计Map及Process源连接选择基础表相对应的源连接、数据库别名、用户ID、密码。
最后将数据源按维度字段(在目标表(主题表)中需要分类查看的字段,其在源表(基础表中对应的字段)进行排序,以下是样例查询语句: SELECT * FROM SC_DEV_EXAM_REP WHERE TAB_YEAR = $(SOURCE_TIME_YEAR)AND TAB_MONTH = $(SOURCE_TIME_MONTH)ORDER BY TAB_YEAR,TAB_MONTH,REPAIR_TYPE,VOL_LEVEL注:这里的对源数据进行分组的依据是目标表里面的维度字段。
目标连接选择和源表相关的主题表。
选择输出模式、更新选项有四种输出模式,可以根据实际的情况选择。
定义全局变量(属性)将目标表中的维度和指标设为全局变量。
由于在源数据转化为目标数据的过程中,需要对源数据指标进行Sum或Count或百分比的计算。
其计算的结果就暂时赋给全局变量,然后又全局变量再赋给个目标值字段。
实现了源数据指标经全局变量赋给目标字段的过程。
为了便于开发、维护,全局变量的别名是依据目标字段产生的。
初始化全局变量在BeforeTransfaction事件中将需要进行计算(Sum、Count、百分比)的全局变量赋初始值0 (初始化的值一般在这里用Execute方法指定)。
将全局变量依次赋给目标字段把无值的全局变量赋给目标字段,由于全局变量是依据目标字段产生的,因此这里的赋值就便于理解以及后期的维护。
为全局变量赋值在源AfterEveryRecord事件中设置其它各维度字段的值,执行指标字段Sum或Count以及百分比计算,也就是为全局变量赋值的过程。
可参考《农电管理主题数据》经过步骤、、、的操作,整个值传递的过程结束。
此处做清洗的操作,如源表中一些数据不合规范,或不完整,需在此处做过滤,归并,重置值等操作(具体的清洗方法需根据实际源数据的质量水平来确定)。
处理OnDataChange1事件选择数据变化监视器选择需要监视的维度字段,多个字段则用表达式来处理用&关联,为全局变量赋值提供赋值依据。
ClearMapPut Record事件。
执行向目标表里面插入数据的动作。
还原全局变量,赋初始值0.为下次赋值做准备。
处理OnError事件OnError事件resume,如果抽取工程发生错误,该时间将执行数据回滚动作。
调试运行运行映射。
直接运行或调度运行。
结果是:成功读取48条,修改4条。
源表:共48条记录目标表:共4条记录注:步骤至:完成源与目标的连接、对应。
步骤至:完成源指标经全局变量赋给目标指标的过程。
步骤:监测抽取过程是否顺利进行。
步骤 : 运行、调试。
此步骤只基于源、目标一对一的情况。
建立多个映射后可将其集中到单个或多个流程中批量执行。
2主题开发以上述主题表T_SC_EQUIP_REPAIR(设备检修主题表)为例,介绍一下主题开发的具体步骤。
其表结构如下:附:T_SC_EQUIP_REPAIR(设备检修主题表)主题的设计标准。
介绍元数据库Microstrategy 元数据是存储在关系型数据库中的一个预定义的结构。
Microstrategy定义了这个元数据的结构。
元数据和数据仓库的RDBMS不必相同。
当应用程序连接到这个元数据库时,所有的框架对象、报表对象、配置对象和项目设置信息都存储在这里。
我们在这里使用Oracle数据库来存储MSTR元数据。
准备空的RDB,并定义ODBC以ORACLE 9i为例,在ORACLE中创建一个数据库实例SG186ND。
创建2个用户:basic_data/basic_data(数据仓库用户)、mstr_user/mstr_user(元数据用户)定义一个系统ODBC,命名为SG186ND_L。
配置元数据库使用Configuration Wizard(开始/程序/Microstrategy/Configuration Wizard)第一项:下一步,选择创建元数据表,下一步选择ODBC数据源名称:SG186ND_L,输入用户名和密码。
(如果使用Access作为元数据库,则选择在Access数据库配置资料库,在下面的文本框中输入Access文件的路径即可,系统会创建Access 文件并配置ODBC。
)点击下一步。
如果有警告信息,点击关闭,再点下一步。
选择元数据脚本位置,一般情况下系统会根据元数据库类型选择出默认的脚本程序,如本例中系统会找到…..\。
点击下一步。
点击完成。
点击确定。
配置元数据库完毕!!连接项目源项目源对象处于Microstrategy对象的最高级。
一个项目源代表一个元数据库连接。
这个连接可以由两种方式实现:(1)直接或两层模式:通过知道DSN、LOGIN、口令连接到元数据库。
(2)服务器或三层模式:通过指向一个定义好的Intelligence Server连接到元数据库。
这里首先使用直接方式连接,稍后再把建设好的应用配置成三层模式,以便远程用户可以访问(通过desktop或直接在网页上访问)。
启动Microstrategy Desktop。
选择菜单工具/项目源管理器,点击添加,输入项目源名称(如Training),选择连接模式为直接,选择ODBC:SG186ND_L,点击确定(两次)。
可以看到我们刚刚创建的项目源 Training创建项目在应用中定义的MSTR对象(框架对象和用户对象等)隶属于项目。
项目在项目源下,一个项目源下可以有多个项目。
在Microstrategy Desktop中双击进入刚才定义的项目源Training (最初配置一个项目源时,MSTR会创建一个内嵌的用户,用户名是Administrator,口令为空,当进入一个项目源时,需要输入这个项目源的user/PWD。
从安全的角度考虑,进入一个新项目源后,应该修改MSTR内嵌用户Administrator的口令),选择菜单框架/创建新项目。
Desktop弹出项目创建助理:项目创建助理有4个按钮,用于创建项目和快速初始化一个项目。
在这里,首先用创建项目按钮来创建项目,其余按钮的功能在后面介绍。
点击创建项目按钮输入项目名称和描述,点击确定,在弹出的登录窗口输入用户名(Administrator)和密码(空)。
项目创建完毕后,点击确定。
在项目源下出现新建的项目。
定义数据库实例数据库实例代表与数据仓库的连接。
用于在某个项目中使用的数据仓库。
在项目源下的管理 / 数据库实例管理器中点击菜单文件/新建/数据库实例输入一个数据库实例名称,选择数据库连接类型,[输入描述]在数据库连接中点击新建,输入数据库连接名称,选择一个指向所要的数据库的本地系统ODBC 数据源;在数据库登录名中点击新建输入数据库登录以及合法的登录ID和密码,点击确定选择正确的数据库登录名,点击确定选择正确的数据库连接名称,点击确定。
这样就定义了一个数据库实例,来代表物理的数据仓库。
选择数据仓库表刚才创建了一个项目(TestProject),我们要在项目中创建报表等BI应用,这些报表需要从数据仓库中的某些TABLES中选取数据。
一个项目需要哪些数据仓库表,就在仓库目录中定义。
每个项目可以配制不同的仓库目录。
将焦点放置所要控制的项目上(TestProject),选择菜单框架/仓库目录,由于现在是第一次进入仓库目录对话框,系统会弹出选择数据库实例界面:选择刚刚创建的SG186ND数据库实例,点击确定。
系统弹出仓库目录对话框。
左侧是数据仓库中可用的TABLE,右侧是选中的数据仓库表。
作为最简单项目,我们先选取6个张表:事实表T_SC_EQUIP_REPAIR,维表C_VOL_LEVEL、C_REPAIP_TYPE、CODE_MONTH、CODE_YEAR、CODE_QUARTER。
定义事实在MicroStrategy产品环境中事实是关联数据仓库中的数值和MicroStrategy报表环境的框架对象。
他们对应到数据仓库中的物理字段,并用以创建对事实数据进行运算的度量对象。
在该项目中,先定义三个事实(Fact):PLAN_NUM(计划数),FINI_PLAN_NUM(完成数),REPAIR_RATE (完成率)。
将焦点移至TestProject项目下的框架对象/事实中,选择菜单文件/新建/事实,系统载入事实编辑器,并进入到创建事实表达式界面。
先创建PLAN_NUM事实,PLAN_NUM事实存在于事实表T_SC_EQUIP_REPAIR中,在源表下拉列表中选择T_SC_EQUIP_REPAIR,把PLAN_NUM字段从可用的列拖到事实表达式中,在映射方法中选择手动,点击确定:选中T_SC_EQUIP_REPAIR表前的复选框,点击保存并新建。
确认保存的路径是框架对象/事实,输入对象名称计划数,点击保存。
再创建FINI_PLAN_NUM事实。
FINI_PLAN_NUM事实也存在于事实表T_SC_EQUIP_REPAIR中确认保存的路径是框架对象/事实,输入对象名称完成数,点击保存。
再创建REPAIR_RATE事实确认保存的路径是框架对象/事实,输入对象名称完成率,点击保存。
定义实体在Microstrategy环境中,实体——以及组成实体的元素——是业务内容的概念。
你在报表中按照实体来汇总和查看数据。
每个实体可能具有多个形式;每个形式可能从多个物理表中表示;实体间会有父子关系。
一个实体的实体形式是考察实体的一个角度。
每个实体至少有一个实体形式,通常有两个:ID描述(DESC)一些实体可能会有其它描述型形式。
比如,客户实体有客户名称形式,还有地址、Email等其它描述型形式。
实体形式之间必须具有一对一关系。
形式有两种用途:1.显示:在报表上或数据浏览时显示2.条件:分析或做查询时用于限制条件。