火车头采集器V8.6发布dedecms自定义字段完美解决方案
- 格式:docx
- 大小:15.90 KB
- 文档页数:3

火车头采集器发布设置,要更好的使用火车头采集器软件,必须需要有基本的HTML基础,能看得懂网页源码,网页结构。
同时如果用到web发布或数据库发布,则对自己文章系统及数据存储结构要非常了解。
当然对HTML和数据库不是很了解可以使用采集发布软件吗?当然不是,我们可以使用更简单的免费采集发布软件各大网站发布详细如下图各大网站自动发布:无须花费大量时间学习软件操作,一分钟即可实现自动采集→内容处理→发布到网站。
提供全自动系统化管理网站,无须人工干涉,设定任务自动执行,一个人维护成百上千网站也不是问题。
1、CMS发布:目前是市面上唯一同时支持帝国、易优、ZBLOG、织梦、WordPress、苹果CMS、人人CMS、米拓CMS、云优CMS、小旋风站群蜘蛛池、Thinkcmf、PHPCMS、Pboot、Fadmin、Destoon、海洋CMS、极致CMS、Emlog、Emlogpro、Typecho、TWCMS、WordPress社区版本、迅睿CMS、WXYCM、DZ论坛等各大CMS,并且可同时批量管理并发布的工具2、对应栏目:相应文章可发布对应栏目(支持多栏目随机发布文章)3、定时发布:可控制发布间隔/单日总发布数量4、监控数据:软件上直接监控已发布、待发布、是否伪原创、发布状态、网址、程序、发布时间、全网搜索引擎推送收录等指定网站采集:任意网站的数据都可以抓取,所见即所得的操作方式,只要点点鼠标就能轻松获得自己想要的数据,支持多任务同时采集!输入关键词采集文章:同时创建多个采集任务(一个任务可支持上传1000个关键词,软件同时还配备了关键词挖掘功能)监控采集: 能够定时的对目标网站进行采集,频率可以选择10分钟、20分钟、根据用户需求自定义设置监控采集(自动过滤重复,监控新增文章)。
标题处理设置: 根据标题或关键词自动生成标题(不管是双标题还是三标题都可以自由生成,间隔符号自定义填写,自建标题库生成,自媒体标题党生成,标题替换等等)图片处理设置:图片加标题水印/图片加关键词水印/自定义图片水印/自定义图片库替换。

dede调用自定义添加字段1.调用自定义字段用在列表页里list{dede:list pagesize='10' addfields='trueprice‘ channelid='2'}<ul class="p_pic"><li class="li1"><a href="[field:arcurl/]"><img src="[field:litpic/]" height="74" width="127" /></a></li><li class="li2">名称:<a href="[field:arcurl/]">[field:title/]</a></li><li class="li3">价格:<a href="/">[field:trueprice/]元</a></li></ul>{/dede:list}说明:addfields='trueprice'指定要获得的字段addfields='字段1,字段2'channelid='2'指定channelid 属性(内容模型的id值)图片模型的ID为22.调用自定义定段用在文章里arclist{dede:arclist addfields='jiage,title,需要查询出来的自定义字段名' channelid='自定义内容模型的ID' row='10' orderby='pubdate''}(add1,add2为自字义的字段名)<p>价格:[field:jiage /]</p><p>标题:[field:title /]</p>{/dede:arclist}3.单独调用价格:{dede:field name='jiage'/}注意:后台内容模型管理里的基本设置里有那么一项:。

今天的项目中遇到一个问题:在内容模型字段中我已经选择了“使字段可以在列表的底层模板中获得”但这一个也只是在DEDE:LIST中调用可以,同时也试过CMS的addfields 这个属性,也没起作用。
像是这样在首页中调用一些自定义字段就是调用不出来。
通过测试找到了问题的解决方法。
这里说明一下以便有遇到此问题的人参考一下:arclist标签调用附加表字段不再以频道模型指定的字段为依据,调用时需注意下面两个问题:
1、必须指定channelid (内容频道id)
这句的意思是你是在那个模型上创建的字段,比如你在【普通文章】或【商品】模型上增加了1个字段flvurl,在【内容模型管理】中,【普通文章】模型或【商品】模型的ID是【1】或【6】
2、直接在标记指定要调用的字段(可以在内容提模型管理中看这些字段名)
示例如下:
复制代码代码如下:{dede:arclist addfields='language,softtype' row='8' channelid='3'}
[field:textlink /] - [field:softtype /] - [field:language /]
{/dede:arclist}
这里假设,你的字段就是在普通文章模型里,那么它的ID值是1,这里的channelid指定值为1(既【内容模型管理】中,【普通文章】模型的ID值),而不是栏目分类的ID。
这个可千万要注意。
更多信息请查看IT技术专栏。
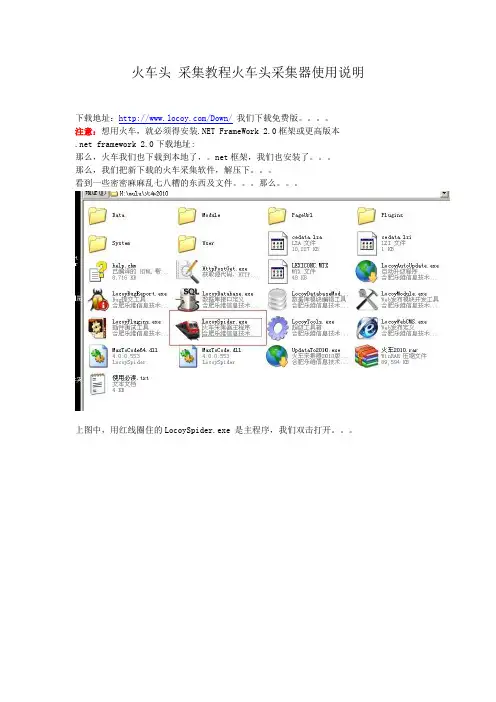
火车头采集教程火车头采集器使用说明下载地址:/Down/我们下载免费版。
注意:想用火车,就必须得安装.NET FrameWork 2.0框架或更高版本.net framework 2.0下载地址:那么,火车我们也下载到本地了,。
net框架,我们也安装了。
那么,我们把新下载的火车采集软件,解压下。
看到一些密密麻麻乱七八糟的东西及文件。
那么。
上图中,用红线圈住的LocoySpider.exe 是主程序,我们双击打开。
ps:这里说下,上图中,有好多任务是我自己用的。
新程序,并没有那么多。
我们会看到火车的界面,看起来非常复杂,是吧?呵呵,其实并没有那么复杂,对于新手,有好多东西是用不到的。
下边会一一的讲解。
我们先补习一下,火车头采集软件的工作原理。
因为我们浏览到的网页,最后都是通过html输出的,那么意味着,我们可以查看到html的源码,那么火车头为什么会采集到内容呢?我们看下网站的基本结构。
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN""/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /> -------这些蓝色的东西,对于新手,我们不需要知道!<title>网页的标题</title> ----红色的是网页的标题。
如下图(1)</head><body>内容在这个<body>和</body>之间的,是网站的内容部分。
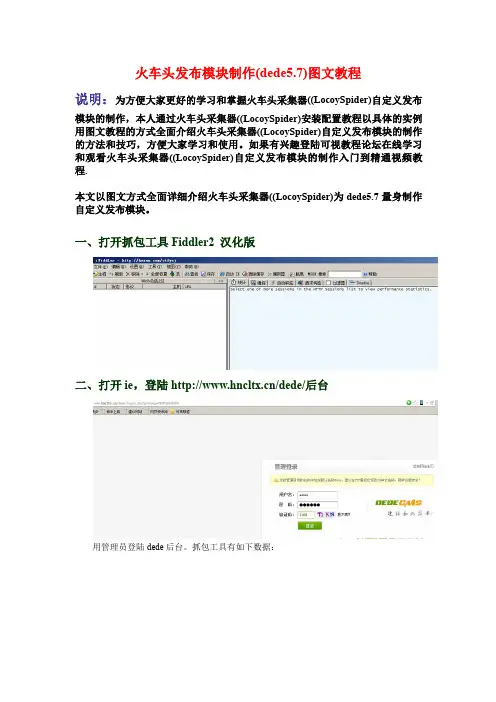
火车头发布模块制作(dede5.7)图文教程说明:为方便大家更好的学习和掌握火车头采集器((LocoySpider)自定义发布模块的制作,本人通过火车头采集器((LocoySpider)安装配置教程以具体的实例用图文教程的方式全面介绍火车头采集器((LocoySpider)自定义发布模块的制作的方法和技巧,方便大家学习和使用。
如果有兴趣登陆可视教程论坛在线学习和观看火车头采集器((LocoySpider)自定义发布模块的制作入门到精通视频教程.本文以图文方式全面详细介绍火车头采集器((LocoySpider)为dede5.7量身制作自定义发布模块。
一、打开抓包工具Fiddler2汉化版二、打开ie,登陆/dede/后台用管理员登陆dede后台。
抓包工具有如下数据:找到其中的login.php文件:如下上图右边红框内容如下:POST /dede/login.php HTTP/1.1Host:User-Agent:Mozilla/5.0(Windows NT6.1;WOW64;rv:28.0)Gecko/20100101Firefox/28.0 Accept:text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8Accept-Language:zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3Accept-Encoding:gzip,deflateReferer:/dede/login.php?gotopage=%2Fdede%2Findex.phpCookie:menuitems=1_1%2C2_1%2C3_1%2C4_1;cyan_uv=C62149898D900001D7B51A6E683024D0; lastCid=3;lastCid__ckMd5=86ae82e846e9c1b1; ENV_GOBACK_URL=%2Fdede%2Fmychannel_main.php;PHPSESSID=v806m80pcefgmsmgvlcgao5u66 Connection:keep-aliveContent-Type:application/x-www-form-urlencodedContent-Length:106gotopage=%2Fdede%2Findex.php&dopost=login&adminstyle=newdedecms&userid=admin&pwd= hncctv&validate=rug1&sm1=三、打开火车头,并新建发布:设置网站自动登陆将上面段中文字红色部分,分别粘贴到下图1,2,3对应的地方:把用户名,密码,验证码对应的值-用标签替换。

dedecms优化方案1、将当前位置的“主页"字样,改为“你自己的网站名称”.解释:学习过SEO的朋友一看就知道为什么了,增加内连接,另一个好处就是利用回首页的关键词连接告诉蜘蛛,你的网站定位。
其实这点真的很重要.我的一个NBA站,以前也写过很多实验报告,为了AD色嫌疑不发出来了,我所有的外联不超过3个词:“NBA视频”“NBA视频直播”“NBA直播”,意思就是告诉蜘蛛,我的网站定位为"NBA视频直播”。
这样的结果是,这个网站1个月没更新,其关键词依然占据GG搜索的首页.2、如果你不知道如何定位,或者担心关键词重复,不要写关键词描述标签。
这句话咋听起来怎么和第一条矛盾呢,既然第一条是为了告诉蜘蛛其网站的定位,第二条反而将专门用来定位的标签去掉呢!其实,不矛盾,有亮点解释,首页我的前提是“如果”,如果你会描写,那当然好,如果你不会呢,那去掉更好.这样也能起到强调第一条的作用.3、写一个规范的顶部导航和规范的底部版权.记得规范,代码简洁明了就好。
而且尽量做到不要改动……4、保留自带的搜索,并进行规范的设置.自带的搜索功能是很强大的,假如你网站的内容比较多,那么请将它留下,这样方便用户查找资料,这是人性化优化的一方面,但自带的模板不太漂亮,所以我们就要稍微修饰了一下.而且,这个这个搜索的模板是一个单独模板,结果页面还是有DEDE的连接,建议大家取消。
5、修改二级三级页面的标题,并给每个栏目一个单独的desciption标签。
我的建议是:二级页面“栏目名字—-网站名字”三级页面“文章标题—-网站名字"给每个栏目都有一个单独的desciption标签,很多朋友都会忽略这点.desciption长度30—50字6、使用好关键词关联功能。
这个几乎很少人用却是一个很好的功能。
我的建议是,开启这个功能,并且关键词关联这样写。
比如文章页面出现NBA 这个词,其连接地址连接到www。
XXXX。

织梦cms(dede)标签使用及问题解决方法总结longyamiao 以前使用过织梦cms(dede)进行网站建设,最近又一次做网站,在制作过程中遇到一些问题,现将标签使用解决方法总结一下。
一、dede 我的文档及收藏方面处理方法——longyamiao问题一:我的文档里有已通过、待审核、未通过三种情况。
而在点击时不是以滑动门的方式显示,而是重新加载网页。
无法达到更改已通过、待审核、未通过三处样式的目的。
问题二:当点击我的文档打开网页时,网页显示的是我所有文档,当点击已通过时,网页显示的是我的已通过审核的文档,当点击下一页查看时发现未通过的文章显示出来了。
解决:(一)点击时每次重新加载,解决方法是,一个模板复制三次,分别命名。
在模板里改变点击已通过待审核未通过的地址。
PHP 和HTM 模板分别是Default/member/myupload.phpDefault/member/templets/myupload.htm 更改PHP里打开模板的链接更改HTM模板里打开PHP的链接。
(二)在myupload.php里用$arcrank表示已通过待审核未通过分别值为1 -1 -2。
点击下一页出现故障的原因是,在分页时,分页链接查询数据库没有加入arcrank参数的限制条件。
分页样式及代码在Default/include/datalistcp.class.php中分布链接地址为$purl .= "?".$geturl; 在这里如果直接添加arcrank 变成$purl .= "?arcrank=1&".$geturl; 在已通过页面里能看到是正常的,但由于是常量,不能变化,在待审核和未通过里则显示错误,同时在我的收藏里也显示错误。
所以没有考虑像第一步那样复制成多份模板,而是想办法传递参数。
可我看代码myupload.php 没有给datalistcp.class.php传递参数。

dedecms按照自定义字段搜索教程之前看到很多人想要自定义字段搜索功能,官方又不给出,而我自己也正需要自定义字段搜索,于是就花了半天时间研究了下DEDE的搜索代码,终于研究出来了,现在分享给大家好了,废话不多说了,具体操作如下一:打开你的数据库,找到dede_full_search这个表,在里面把你自定义的字段添加进表,这里以我的网站为例,我添加了myskill,myexchange,mygoods,myexgoods,这4个字段二:打开/member/article_add_action.php,找到"//更新全站搜索索引",在下面的一段代码中插入刚才添加的4个字段,例:“'myskill'=>$myskill,'myexchange'=>$myexchange,'mygoods'=>$mygoods,'myexgoods'=>$myex goods”,这里说明一下,前面的'myskill'为你发布文章时添加的自定义字段,后面的为刚才在表dede_full_search中添加的字段(建议在表中添加字段的时候写成跟你之前字定义的字段一样)这里最好写成一样,可以省去很多麻烦三:打开/include/inc_arcsearch_view.php,搜索titlekeyword,找到如下代码Copy codeif($this->SearchType != "titlekeyword"){$kwsqlarr[] = " ying_full_search.title like '%$k%' ";}else{$kwsqlarr[] = " ying_full_search.title like '%$k%' ";$kwsqlarr[] = " ying_full_search.addinfos like '%$k%' ";$kwsqlarr[] = " ying_full_search.keywords like '%$k%' ";}分析下代码SearchType != "titlekeyword,搜索类型为titilekeyword,即前台搜索下拉框中的智能模糊搜索,$kwsqlarr[] = " ying_full_search.title like '%$k%' ";为搜索full_search表中的title字段,好了,知道了这段代码的作用,我们就知道该如何添加自己的搜索了下面把我的代码作为例子Copy codeif($this->SearchType != "skill"){$kwsqlarr[] = " ying_full_search.myskill like '%$k%' ";$kwsqlarr[] = " ying_full_search.myexchange like '%$k%' ";}else{$kwsqlarr[] = " ying_full_search.myexchange like '%$k%' ";$kwsqlarr[] = " ying_full_search.myskill like '%$k%' ";}if($this->SearchType != "goods"){$kwsqlarr[] = " ying_full_search.mygoods like '%$k%' ";$kwsqlarr[] = " ying_full_search.myexchange like '%$k%' ";}else{$kwsqlarr[] = " ying_full_search.myexchange like '%$k%' ";$kwsqlarr[] = " ying_full_search.mygoods like '%$k%' ";},因为我的myskill和myexchange2个字段是一起的,而mygoods和myexgoods是一起的,所以我用了2个if else语句四:修改搜索框代码,代码在哪我就不说了吧,大家都知道在哪,搜索框原代码为Copy code<select name="searchtype" id="searchtype"><option value="titlekeyword" selected>智能模糊搜索</option><option value="title">仅搜索标题</option></select>这里只需修改上面的代码,修改后的代码为Copy code<select name="searchtype" id="searchtype"><option value="skill" selected>搜技能</option><option value="goods">搜物品</option></select>value="",这填的是第三步中添加的SearchType后面的,即搜索类型,这个你自己定义五:还是打开/include/inc_arcsearch_view.php,找到//处理一些特殊字段,把你之前的自定义的字段添加进去,这里还是以我的为例子在先面添加Copy code$row["myskill"] = $this->GetRedKeyWord(cn_substr($row["myskill"],$infolen));$row["myexchange"] = $this->GetRedKeyWord(cn_substr($row["myexchange"],$infolen)); $row["mygoods"] = $this->GetRedKeyWord(cn_substr($row["mygoods"],$infolen));$row["myexgoods"] = $this->GetRedKeyWord(cn_substr($row["myexgoods"],$infolen));其实只要添加$row["myskill"] = $row["myskill"];(另外3个我就不写了,类似)就够了,但是我为什么要这样写呢,这样写的作用就是让你在搜索结果页调用的时候显示关键子为红色六:最后一步了,打开templets/default/search.htm,这里就是搜索页调用的模版,这里要调用只要[field:你自定义的字段/],还是以我的网站为例[field:myskill/],这样调用就OK,但是要注意一点,假如你2个字段放一起调用中间最好加个空格或者其他符号,假如[field:myskill/][field:mygoods/]这样连在一起是显示不出来的好了,写的这么详细,相信大家应该看的懂吧,虽然有点复杂,不过有总比没有好,呵呵。

Dedecms栏目自定义字段的方法鉴于这个教程没人发过,网上搜索的人也比较多。
所以就做了个。
比如我要添加:栏目图片,和栏目关键字等。
随便你吧。
好。
我们现在开始做。
第一我们要进去mysql 数据库里添加字段,自己命名好!比如我下面添加了一个栏目搜索关键字字段,当然你字段可以自己新建,找到表dede_arctype ,这个是栏目模型的数据库表,前面是你安装的表名,新手要注意,不要问我,我找不到这个表,注意。
这里老鸟跳过然后点击图片1在点击添加字段图片2添加字段图片3到这里数据库字段添加好了。
接下来我们开始做后台。
大家写找到后台栏目管理模版!要更改的 2个 D:\www\dede\templets 模版:catalog_add.htm、catalog_edit.htm下面就演示一个图片4然后添加字段表单,这个一般大家都会的我添加的代码是:<tr><td height="65">栏目搜索关键字:</td><td> <textarea name="lanmukeywrod" cols="70" rows="4"id="lanmukeywrod" class="alltxt" ><?php echo$myrow['lanmukeywrod']?></textarea></td></tr>这里大家注意了。
表单的name 和id 要和添加的 mysql表字段一样,不应的话。
还要多写个取值代码。
一样的话。
默认dedecms会自动取的,然后我们做最后一部,把数据添加进去。
大家找到: D:\www\dede\catalog_edit.php 目录可能和大家不一样也就是后台里面的 catalog_edit.php,catalog_add.php catalog_edit.php要改的地方有: 38行$upquery = "Update `dede_arctype` setissend='$issend',sortrank='$sortrank',typename='$typename',typedir='$typedir',isdefault='$isdefault',defaultname='$defaultname',issend='$issend',ishidden='$ishidden',channeltype='$channeltype',tempindex='$tempindex',templist='$templist',temparticle='$temparticle',namerule='$namerule',namerule2='$namerule2',ispart='$ispart',corank='$corank',description='$description',keywords='$keywords',moresite='$moresite',`cross`='$cross',`content`='$content',`crossid`='$crossid',`smalltypes`='$smalltypes'$uptopsqlwhere id='$id' ";sql语句里面添加我们刚才的字段进去。

织梦DedeCMS添加自定义属性
转自:/a/DEDEjiaocheng/185.html
我今天主要说如何添加自定义属性,如果增加使用织梦DedeCMS的人,肯定知道自定义属性是啥,他主要用来设置推荐文章,对标题加粗,设置跳转这些功能,并且这些自定义属性还可以组合使用,但是如果站点比较大的时候,这些自定义属性怕是就不够用了,但DedeCMS又没有添加自定义属性的功能,让我们很无奈。
我添加一天的研究,读源代码,看数据库结构,终于打开了方法,但是需要修改数据库:第一步:打开dede_archives表,修改表字段flag 这个字段是set类型的,我们可以增加值,并且必须是与之前不重复的单字母,比如我这里设置的e (我使用工具的是Navicat for MySQL,其它工具方法类似)
第二步:打开dede_arcatt表,添加记录att就是之前设置的字母,attname就是提示文字
OK,完成。
刷新后台就有增加的自定义属性了
转自:/a/DEDEjiaocheng/185.html。

织梦DedeCMS内容管理系统设置说明作者:admin 时间:2011-06-15 23:01:57 字体:[大中小] 我要投稿建网站:织梦DedeCMS内容管理系统设置说明您当前所在的位置:首页> Dede技巧> 织梦DedeCMS内容管理系统设置说明织梦DedeCMS内容管理系统设置说明站点设置,核心设置,附件设置,会员设置,互动设置,性能选项,其他选项1.1.站点设置站点根网址(cfg_basehost):网站根节点网址,例如设置,主要用于生成一些超链接中加入站点根网址,例如:百度新闻、站点RSS、系统上传附件等网页主页链接(cfg_indexurl):用于前台模板调用网站主站连接主页链接名(cfg_indexname):网站主页的连接名称,默认为“主页”网站名称(cfg_webname):全局站点的名称,通常显示在网页页面的标题栏部分,默认为“我的网站”文档HTML默认保存路径(cfg_arcdir):网站生成静态页面HTML存放路径,默认为“/html”,可以根据自己需要进行设置图片/上传文件默认路径(cfg_medias_dir):网站附件上传默认保存路径,默认为“/uploads”,可以根据自己需要进行修改编辑器(是/否)使用XHTML(cfg_fck_xhtml):控制网站内容编辑器是否启用XHTML类型的标记,默认是不起用的模板默认风格(cfg_df_style):默认模板的风格,设置后模板的路径变为“/tremplets/[设置模板风格]”,默认是default,即“/tremplets/default/”网站版权、编译JS等底部调用信息(cfg_powerby):网站底部版权及js调用信息,一般可以将流量统计代码加入到这里,前台进行调用站点默认关键字(cfg_keywords):用于显示站点默认关键字,便于SEO,通常显示在首页的<meta>中,可以根据自己需求进行修改站点描述(cfg_description):用于显示站点默认描述,便于SEO,通常显示在首页的<meta>中,可以根据自己需求进行修改网站备案号(cfg_beian):用于显示网站备案号的相关内容,可以根据自己需要进行设置1.2.核心设置DedeCms安装目录(cfg_cmspath):系统默认安装目录,默认如果安装在网站根目录即为空,如果安装在子目录需要对其进行设置,例如“cms”,一般移动网站目录需要对其进行重新设置,并重新生成内容,否则会出现页面无法显示、PHP报错等现象cookie加密码(cfg_cookie_encode):用于对用户登陆cookie加密设置,默认系统自动生成,通常使用在系统整合等方面数据备份目录(在data目录内)(cfg_backup_dir):数据库备份文件夹,通常在系统根目录的data文件夹下,默认为backupdata,即在系统“\data\backupdata”文件夹下网站发信EMAIL(cfg_adminemail):用于站点发信的E-mail地址,默认为“cfg_adminemail”,可以根据自己需要进行修改Html编辑器选项(目前仅支持fck)(cfg_adminemail):网站内容发布,字段类型为HTML 时候使用的编辑器,例如普通文章发布时候内容部分的编辑器,默认为fck,在V5.3中取消了以前的HTML编辑器,并今后不再进行开发专题的最大节点数(cfg_specnote):专题部分节点的最大数目,默认为6个节点,在添加专题内容处有相关节点的信息栏目位置的间隔符号(cfg_list_symbol):通常显示在网站当前位置部分的内容,默认为“ > ”即当前位置部分显示为“主页> 一级栏目> 二级栏目”,可以根据自己需要进行修改关键字替换(是/否)使用本功能会影响HTML生成速度(cfg_keyword_replace):系统将会替换HTML编辑器中内容部分的关键词为加亮显示,通常这个选项开启会影响系统生成HTML页面的速度,系统默认是开启的(是/否)支持多站点,开启此项后附件、栏目连接、arclist内容启用绝对网址(cfg_multi_site):系统附件生成采用地址类型,一般附件生成没有开启该选项附件将采用“/uploads/liming/test111.gif”的形式,如果开启将在附件地址前面加上网站地址,会变为“/uploads/liming/test111.gif ”设置有效解决了二级域名附件无法显示的问题,系统默认是关闭的(是/否)开启管理日志(cfg_dede_log):用于记录管理员登陆操作系统的日志,默认是关闭的FTP主机(cfg_ftp_host):部分创建将通过ftp形式进行文件创建,系统默认没有这个设置,您可以设置FTP的主机地址为,下面的FTP相关设置也是如此,如果是虚拟主机需要空间商提供FTP账号密码等FTP端口(cfg_ftp_port):同FTP主机部分FTP用户名(cfg_ftp_user):同FTP主机部分FTP密码(cfg_ftp_pwd):同FTP主机部分网站根在FTP中的目录(cfg_ftp_root):同FTP主机部分,一般虚拟主机网站根目录为wwwroot或者htdocs是否强制用FTP创建目录(cfg_ftp_mkdir):如果系统不支持PHP创建目录,启用后将采用FTP形式强行创建目录,系统默认是关闭这个选项的服务器时区设置(cfg_cli_time):用于设置系统程序执行的时区影响到全站时间相关功能,如文章添加时间、留言时间等,默认为8是否启用smtp方式发送邮件(cfg_sendmail_bysmtp):采用SMTP发送电子邮件,系统默认是关闭的,改设置将影响到找回密码、文档内容推荐等功能,如果开启需要设置以下SMTP信息,如果启用还需要保证服务器拥有邮件发送的功能,如果是主机空间可以和空间商取得联系并且确保SMTP设置正确性才能确保邮件发送smtp服务器(cfg_smtp_server):同是否启用smtp方式发送邮件部分,默认为smtp服务器端口(cfg_smtp_port):同是否启用smtp方式发送邮件部分,默认为25 SMTP服务器的用户邮箱(cfg_smtp_usermail):同是否启用smtp方式发送邮件部分SMTP服务器的用户帐号(cfg_smtp_user):同是否启用smtp方式发送邮件部分SMTP服务器的用户密码(cfg_smtp_password):同是否启用smtp方式发送邮件部分建网站:织梦DedeCMS内容管理系统设置说明(2)在线支付网关类型(cfg_online_type):设置在线支付网关类型,默认为nps删除文章文件同时删除相关附件文件(cfg_upload_switch):删除文档内容时候如果开启了这个选项将清除文档相关附件网站全局搜索时间限制(cfg_allsearch_limit):如果在使用高级搜索,查询时间大于设置时间数,系统将提示“服务器忙,请稍后搜索”,默认为1,即为1秒。
⽕车头采集器伪原创(附PHP实现代码)因为最近需要⼀批数据来做机器学习,所以⽤⽕车头采集器来抓数据,数据伪原创⽤的⼩发猫的API。
以下是PHP实现代码:<?phpset_time_limit(270);error_reporting(E_ERROR | E_WARNING | E_PARSE);define('TITLE_SEPAR', 'xxx**xxx');define('TITLE_SEPAR2', '262661');$url = '/api.php?json=0&v=1&key=';$content_tag_name = '内容';$headdd = '<figure class="wp-block-gallery columns-3 is-cropped"><ul class="blocks-gallery-grid">';$taill = '</figure>';switch($LabelArray['PageType']){case 'List'://处理列表页,只能处理htmlbreak;case 'Pages'://处理多页,只能处理htmlbreak;case 'Content'://处理默认页,只能处理htmlbreak;case 'Save'://只有保存时是可以处理标签值的// 保存原⽂try {/**********************************************************************/// 这⼀步⽤来获取伪原创⽂章/**********************************************************************/$title = $LabelArray['标题'];$content = $LabelArray[$content_tag_name];$article_src = compose_article($title, $content);$article_src_b = $article_src;//$article_src = br2newline($article_src);$article_new = get_wyc_article($article_src);$title_wyc = trim($article_new[0]);$content_wyc = trim($article_new[1]);//$article_new_x = $article_new;//$article_new = fix_newline($article_new);//$temp = explode(TITLE_SEPAR, $article_new);//$new_title = $temp[0];//$new_title = fix_title($new_title);/*$temp[1] = ltrim($temp[1], "\r\n");//$temp[1] = ltrim($temp[1], "\n");$temp[1] = ltrim($temp[1], "\r\n");//implode(PHP_EOL, $temp);$temp[1] = ltrim($temp[1], "\n");*///$new_article = get_wyc_article($LabelArray[$content_tag_name]);$content_wyc = fix_newline($content_wyc);// $new_article = newline2br($new_article);//$new_article = remove_alt($new_article);//$article_new = xfm_strong_str_replace_once('<p>', '<p>'.$new_title, $new_article);//$LabelArray[$content_tag_name] = $article_new;//$new_article;//$new_article;//$nlp = get_keywords($new_title, $new_article);//$nlp_arr = explode(TITLE_SEPAR, $nlp);//$LabelArray['关键词'] = $nlp_arr[0];//$LabelArray['内容简介'] = $nlp_arr[1];//$LabelArray['内容简介'] = curl_request($url, array('wenzhang'=>$LabelArray['内容简介']));$content_wyc = ltrim($content_wyc, '</p>');//$LabelArray[$content_tag_name] = $headdd. $content_wyc. $taill; //serialize($article_new);// $LabelArray[$content_tag_name] = $temp[1];//$LabelArray[$content_tag_name] = $article_src;$new_title = str_replace(array('[',']','%'), array('【','】','%'), $new_title);$LabelArray['标题'] = strip_tags($title_wyc);$LabelArray['标题'] = ltrim($LabelArray['标题']);$LabelArray['标题'] = trim($LabelArray['标题']);//$LabelArray['摘要'] = curl_request($url, array('wenzhang'=>$LabelArray['标题'].','.$LabelArray['摘要']));}catch (Exception $e) {$LabelArray['标题'] .= $e->getMessage();$LabelArray[$content_tag_name] .= $e->getMessage();}break;default://$LabelArray[$content_tag_name]=curl_request($url, array('wenzhang'=>$LabelArray[$content_tag_name] ));}echo serialize($LabelArray);function compose_article($title, $content) {$separator = compose_separator();return $title.$separator.$content;}function compose_separator() {return PHP_EOL.'('.TITLE_SEPAR2.')'.PHP_EOL;}function fix_separator($article) {return $article;}function get_wyc_article($str) {global $url;$separator = compose_separator();$separator = str_replace(PHP_EOL, '', $separator);$wyc = curl_request($url, array('wenzhang'=>$str));$wyc = fix_separator($wyc);$wyc = explode($separator, $wyc);if (isset($wyc[0])) $wyc[0] = trim($wyc[0]);if (isset($wyc[1])) $wyc[1] = trim($wyc[1]);return $wyc;}function get_wyc_title($str) {$title = get_wyc_article($str.PHP_EOL.PHP_EOL.PHP_EOL.$str.PHP_EOL.PHP_EOL.PHP_EOL.$str); $title = fix_newline($title);$title = explode(PHP_EOL, $title);return $title[0];}function get_keywords($title, $contents) {$url_kw = '/nlp/kws.php?appid=';$kws = curl_request($url_kw, array('title'=>$title,'len'=>100,'text'=>$contents));return $kws;}function remove_alt($contents) {$contents = preg_replace('/alt=\"(.*)\"/', '', $contents);return $contents;}function fix_title($contents) {$punctuation_symbol = array('。
织梦DedeCms采集规则教程篇一:dedecms完整采集教程(共三篇)Dedecms完整收藏教程(列表设置)-marco608原创以的html教程中的数据库为例,地址是/网页艺术/htmlbase/html/index。
html一,打开dedecms,进入【采集节点管理】,新建一个节点,模型我们就选择二、填写节点的基本信息:名称就自己定义吧。
编码更重要。
您可以右键单击页面以查看页面的编码。
来源就自己定义吧。
防盗链取决于目标站点是否有刷新限制。
如果是,请设置超时。
三,设置采集列表:我们想收集的清单如下:而我们要设置的列表是这样的:让我们解释一下如何填充这个设置。
来源网址很重要的。
列表的获取就是从这里得到的。
自己打开:/webart/htmlbase/HTML/list_33_2。
HTML查看分页规则。
这不是很难看吗?然后我们在设置列表分页时,就转换为变量值的形式:/网页艺术/htmlbase/html/list_u33_var:paging]html而变量起始值是1,结束值是3,就代表1至3的列表页了。
URL的常规配置取决于是否有更具体的文章URL字符。
例如,page1 HTML之类的。
下面的html范围就比较重要。
让我们看一下原始Dede的列表。
我们在浏览器中查看源文件。
查找以下代码:看这里,你一定知道常用的HTML代码。
这里要复制代码起始就是那个文章列表的表格的开始部分吧。
以下是物品清单表格末尾的代码:篇二:dedecms5.7详细采集教程Dedecms梦想编织系列教程,超级详细超级详尽的织梦采集教程许多网民对DEDECM的收藏教程感到头疼。
事实上,官方教程太笼统了,什么也没说。
你不能在其他网站上做任何事情。
本教程是最详细的一个。
让我们打开dedecms的后台,单击Collection-Collection node management-添加新节点这里我们以采集普通文章为例,我们选择普通文章,然后确定我们进入集合设置页面并填写节点名称,即为新节点命名。
第一步:为表添加一个字段,可以通过dedecms后台直接执行mysql 添加命令,也可以通过服务器phpmyadmin来添加,下面我们打比方要添加一个文本行的的字段,字段的名称我们取名叫hp_jiujie
那么sql命令如下:
ALTER TABLE `dede_arctype` ADD COLUMN hp_jiujie text 截图如下操作
或者通过phpmyadmin添加字段如下图所示
第二步:要更改的2个文件:\www\dede\templets 模版:
catalog_add.htm、catalog_edit.htm
这个代码就比较简单,可以参考现成的他的代码,复制一份下来做相应的字段名称修改就可以了
第三步:要更改的2个文件:catalog_edit.php,catalog_add.php catalog_edit.php要改的2处地方有
第一处:
第二处:
catalog_add.php要改的2处地方有
第一
处:
第二处:
最后:如何调用到前台-------前台调用代码如下:{dede:field.hp_jiujie/}。
1、火车头介绍2、什么是信息采集3、什么是火车头4、火车头是干啥的5、火车头规则定制6、规则编写流程7、采网址详解8、采内容详解9、注意事项什么是火车头?我们打开一个网站,看到有一篇文章很不错,于是我们就将文章的标题和内容复制了一下,将这篇文章转到我们的网站上.我们的这个过程,就可以称作一个采集,将别人网站上对自己有用的信息转到自己网站上;互联网上的内容,大多数都是通过复制-修改-黏贴的过程产生的,所以信息采集很重要,也很普遍,我们平台发到网站上的文章,多数也是这样的一个过程;为什么很多人感觉新闻更新很麻烦,因为这个工作是重复的,枯燥乏味的,浪费时间的;火车头是目前国内使用人数最多、功能最完善、网站程序支持最全面、数据库支持最丰富的软件产品;现在是大数据时代,它可以快速、批量、海量的获取到互联网上的数据,并按照我们需要的格式存储起来;说的简单一点,对我们来说有什么用?我们需要更新新闻,需要发商机,如果让你准备1000篇文章,你要用多久?5个小时?在有规则的情况下,火车头只需要5分钟!前提是有规则,所以我们要先学写规则,写规则如果数量的话,一个规则几分钟就好了,但刚开始学的时候会比较慢;名称解释与规则编写流程以火车头8.6版本为准第1步:打开—登录第2步:新建分组第3步:右击分组,新建任务,填写任务名;第4步:写采集网址规则(起始网址和多级网址获取)第5步:写采集内容规则(如标题、内容)第6步:发布内容设置勾选启用方式二(1)保存格式:一条记录保存为一个txt;(2)保存位置自定义;(3)文件模板不用动;(4)文件名格式:点右边的倒立笔型选[标签:标题];(5)文件编码可以先选utf-8,如果测试时数据正常,但保存下来的数据有乱码则选gb2312;第7步:采集设置,都选100;a.单任务采集内容线程个数:同时可以采集几个网址;b.采集内容间隔时间毫秒数:两个任务的间隔时间;c.单任务发布内容线程个数:一次保存多少条数据;d.发布内容间隔时间毫秒数:两次保存数据的时间间隔;附注:如果网站有防屏蔽采集机制(如数据很多但只能采集一部分下来,或提示多久才能打开一次页面),则适当调小a值和调大b的值;第8步:保存、勾选并开始任务(如果是同一分组的,可以在分组上批量选中)以前的方式:比如我要准备n篇文章,要先找到这个文章是在哪个网站上的(如是采集同行A还是同行B),是在其哪个栏目下的(如是产品信息还是新闻信息),在这个栏目下有n条信息,我要选哪一条,然后进去后把标题复制下来,把内容复制下来再进到另一个页面把标题内容复制下来,以此类推,然后同样的流程我要执行n遍;怎么转换:怎么把这个流程转化为软件操作呢?我要准备n篇新闻,这就表明要n个标题+对应的内容,要n个新闻链接,这n个新闻链接是从一个网站的新闻栏目上找的,而这个网站的新闻栏目有可能是很多页,比如10页,这个时候再从同行A的网站—栏目—内页;即先找到要采集的网站,打开这个网站的栏目页(确定好是采集新闻还是产品),写网址规则采集栏目下的所有新闻链接,然后写内容规则采集所有新闻链接中的标题和内容,最后保存下来;采网址详解-具体操作找到要采集网址的栏目页,如新闻栏目复制栏目的第一页链接url,起始网址右侧中点添加,在单条网址中黏贴栏目的第一页链接后点添加,如用右边的(*)代替,因为第1页已经添加了,还剩9页,这时在等差数列那一行把项数改成9,首项是2(因为第2页的链接是,然后点添加-完成;1、点对应右侧的添加,然后如下图所示是示例,右侧大图是说明;2、点击保存后点右下角的看看是否能采集到新闻网址,如果能采集到则正确,双击一个新闻网址进到下一步;如果采集到的不正确,返回修改直到成功;网址过滤可以自己观察其对应的规律;1、到采集内容规则这里后,把作者、时间、出处都选中后删掉,如右面第一张图,因为这些标签正常情况下都用不到;2、选中标题标签点修改,或直接双击该标签,进入编辑界面;3、进入后标签名的“标题”别改,改过后是要改对应的模板的;4、下面的数据提取方式:前后截取和开始结束字符串,也尽量用默认的,在不熟练的情况下不要改;5、点击下面数据处理的添加—内容替换,如右图;6、内容替换将标题后面的都替换为空,如果不替换的话采集的是页面title,这时需要打开两个新闻页面,看看这两个新闻页面的公共部分是什么,把公共部分替换掉例:如下面两个标题,“- 顶尖SEO团队”是公共部分,即把其替换为“空”;【图文】你知道螺旋加料机的加工方法吗螺旋加料机原理你了解吗【图文】气动式加料机的优点是什么你知道粉末加料机工作原理吗例:如下面的则需要把“-健康网”替换成“空”;例:如下面的则需要把“-健康网”替换成“空”;我喜欢吃西瓜-健康网苹果好吃吗?-健康网1、选中内容点编辑,或直接双击进入到内容标签编辑界面,标签名千万别改;2、写开始和结束字符串,就是找能把所有新闻都包裹起来的,在所有新在所有新闻页面中都是闻页面中都有的,且是唯一的一段字符串;即这个页面模板中的唯一代码串;举例:采集内容的时候,需要选择内容区域,因为要采集的可能是n篇,如100篇,这个时候就需要想法怎么能写一个采集到全部的,方法就是打开两个新闻链接如,查看第一篇新闻的源文件,找到新闻正文,然后向上找离新闻第一句话最近的,在这个页面中是唯一的一段代码(如果不唯一,软件能知道从第几个开始吗?),但又不是新闻中的内容,如<div id=“zoom”>,复制后在第二篇新闻页面源文件中搜一下看看有没有,如果有,则可采用;同理找到新闻最后一句话,向下找离其最近的页面中唯一的一段代码,复制后在第二篇新闻页面源文件中搜一下看看有没有,如果有,则可采用;数据处理:因为采集的是其他网站的信息,里面有可能有其他网站的资料,如公司名、联系方式、品牌等信息,也可能有其他网站的超链接等信息,这个时候就需要对信息进行过滤处理;数据处理—添加—下面对应的参数HTML标签过滤:滚动轴横向拉到最后,在所有标签前面打钩后点确定;内容替换:将这个网站的信息替换成自己的,原则是先整后拆,有公司名、电话号(拆分)、手机号(拆分)、邮箱、公司地址(拆分)、品牌名、网址(拆分);其中拆分的意思是对这个数据进行拆解替换,这个时候就需要做如下替换:因为在新闻中,,这是时候就需要对其拆解替换才能替换干净,可以多看一下他的新闻中,可能会用什么样的格式;注:数据处理还有很多技巧,需要自己在使用的过程中琢磨,更是采集的核心,如果处理不好,有可能是为他人做嫁衣,所以一定要仔细观察,考虑全面,如果处理好了,采集下来的文章甚至可以直接就发布(非自己企业站)注意事项1、右击分组:会出现如下图菜单,正常都能用到;新建任务:在此分组上新建任务;运行该分组下所有任务:顾名思义;新建任务:在该分组下再建分组;编辑/删除分组:编辑/删除当前分组;导入/导出分组规则:可以导出当前分组下的所有任务,并导入到同版本火车头上;导入任务至该分组:将导出的单个任务导入到该分组下面;黏贴任务到该分组下:要复制过任务后此项才出现,可以黏贴多个同样的任务,然后再黏贴后的任务上进行编辑即可;开始任务:和菜单栏上的开始一样;编辑任务:编辑已经写好的任务;导出任务:可以将当前规则导出,在其他同版本工具上导入,但导入数据时需重复上面的第6步-发布内容设置,必须要重新选/填一遍;复制任务到黏贴板:复制后,选择一个任务分组并右击,可以黏贴不同数量的任务到那个分组中,这样就避免同一个任务多次编写了;清空任务所有采集数据:新如果之前采集过任务想重新采集的,则需求先清空;3、其他设置:顶部菜单栏中点击工具—选项,配置全局选项和默认选项;全局选项:可以调整下同时运行任务最大个数,正常是5即可,可不调;默认选项:是否忽略大小写点是;。
dedecms织梦采集功能的使用方法(二)我是程序员Dedecms采集功能的使用方法—不含分页的普通文章(二)2.1新增采集节点:第二步设置内容字段获取规则单击“保存信息并进入下一步设置”后,便可进入“新增采集节点:第二步设置内容字段获取规则”页面,如(图22)所示,图22-设置内容字段获取规则在预览网址处,系统将会自动指定一篇将被采集文章内容页面的网址(一般为所采集列表页面的第一篇文章网址),作为示范页面。
如果文章内容页面含有分页,则需设置“内容分页导航所在的区域匹配规则”。
对于“固定采集项目”中的“内容摘要、关键字和缩略图“三个部分,系统会用正则进行自动匹配,这里仅需配置过滤内容即可。
下面主要介绍如何获取“文章标题、文章作者、文章来源、发布时间和文章内容”的采集规则,过滤规则仅简单涉及。
2.1.1 获取文章标题的采集规则首先,打开“预览网址“的页面并单击右键,选择”查看源代码“,找到文章标题”在Dreamweaver中为插入的Flash 添加透明“,如(图23)所示,图23-在源代码中的文章标题这里的文章标题处在”<h1></h1>”之间,由于在此页面中多次出现这组标签,因此这里应该填写“<div class=”arcbody”><h1>[内容]</h1>”作为文章标题的匹配规则。
如果在文章标题中含有相关链接等,可使用过滤规则加以处理,这里无需设置。
填写后,如图24所示,图24-文章标题的采集规则2.1.2 获取文章作者的采集规则如上图23所示,在“作者:”二字后面有一组标签“<font color=”red”></font>”,以此猜测,作者名将会写在这组标签之间。
同样,为了保持唯一性,这里应填写”作者:<font color=“red”>[内容]</font>“作为文章作者的采集规则。
火车头采集器V8.6发布dedecms自定义字段完美解
决方案
有很多站长网站数据需要用到火车头采集器,那么如果DEDECMS 中包含自定义字段,我们应该如何来采集呢?是不是傻眼了,不知道如何是好了?
下面,作者亲测利用火车头采集器发发布dedecms自定义字段完美解决方案,分享给大家。
1.打开dedecms编辑模块,在弹出的对话框中的post值中(也就是发布参数)增加对应字段的名称和标签值。
比如我自定义了一个模型,模型识别id是20,自定义了一个新字段,数据库字段名称为zhuliao,类型为多行文本那么应该更改:
channelid=20
同时增加:
zhuliao=
很多人做到这样就以为可以发布了,其实不然,我们需要增加dede_addonfields用来提交你新追加字段的表单信息,格式为字段名+数据类型,比如我发布的多行文本应该是:
dede_addonfields=zhuliao,multitext;
也可以发布多个字段,如:
dede_addonfields=zhuliao,multitext;fuliao,multitext;tieshi, htmltext;
切记数据模型不要写错。
还有人说应该将标点和中文decode成utf8格式的编码,才能正常使用。
所以逗号编码为%2C,分号为%3B,即:dede_addonfields=xinziduan%2Ctext%3B。
经我测试这是不正确的,也是多此一举,会导致发布不成功。
2.回到编辑页面:
新建一个标签和在post值中的字段标签名一致,如:
这样就可以用火车头来发布dede自定义字段了。