第五章 聚类分析(修改)
- 格式:ppt
- 大小:942.50 KB
- 文档页数:65

1聚类分析内涵1.1聚类分析定义聚类分析(Cluste.Analysis)是一组将研究对象分为相对同质的群组(clusters)的统计分析技术.也叫分类分析(classificatio.analysis)或数值分类(numerica.taxonomy), 它是研究(样品或指标)分类问题的一种多元统计方法, 所谓类, 通俗地说, 就是指相似元素的集合。
聚类分析有关变量类型:定类变量,定量(离散和连续)变量聚类分析的原则是同一类中的个体有较大的相似性, 不同类中的个体差异很大。
1.2聚类分析分类聚类分析的功能是建立一种分类方法, 它将一批样品或变量, 按照它们在性质上的亲疏、相似程度进行分类.聚类分析的内容十分丰富, 按其聚类的方法可分为以下几种:(1)系统聚类法: 开始每个对象自成一类, 然后每次将最相似的两类合并, 合并后重新计算新类与其他类的距离或相近性测度. 这一过程一直继续直到所有对象归为一类为止. 并类的过程可用一张谱系聚类图描述.(2)调优法(动态聚类法): 首先对n个对象初步分类, 然后根据分类的损失函数尽可能小的原则对其进行调整, 直到分类合理为止.(3)最优分割法(有序样品聚类法): 开始将所有样品看成一类, 然后根据某种最优准则将它们分割为二类、三类, 一直分割到所需的K类为止. 这种方法适用于有序样品的分类问题, 也称为有序样品的聚类法.(4)模糊聚类法: 利用模糊集理论来处理分类问题, 它对经济领域中具有模糊特征的两态数据或多态数据具有明显的分类效果.(5)图论聚类法: 利用图论中最小支撑树的概念来处理分类问题, 创造了独具风格的方法.(6)聚类预报法:利用聚类方法处理预报问题, 在多元统计分析中, 可用来作预报的方法很多, 如回归分析和判别分析. 但对一些异常数据, 如气象中的灾害性天气的预报, 使用回归分析或判别分析处理的效果都不好, 而聚类预报弥补了这一不足, 这是一个值得重视的方法。

第五讲聚类分析聚类分析是一种无监督学习方法,旨在将样本数据划分为具有相似特征的若干个簇。
它通过测量样本之间的相似性和距离来确定簇的划分,并试图让同一簇内的样本点相似度较高,而不同簇之间的样本点相似度较低。
聚类分析在数据挖掘、模式识别、生物信息学等领域有着广泛的应用,它可以帮助我们发现隐藏在数据中的模式和规律。
在实际应用中,聚类分析主要包含以下几个步骤:1.选择合适的距离度量方法:距离度量方法是聚类分析的关键,它决定了如何计算样本之间的相似性或距离。
常用的距离度量方法包括欧氏距离、曼哈顿距离、切比雪夫距离等。
2.选择合适的聚类算法:聚类算法的选择要根据具体的问题和数据特点来确定。
常见的聚类算法有K-means算法、层次聚类算法、DBSCAN算法等。
3.初始化聚类中心:对于K-means算法等需要指定聚类中心的方法,需要初始化聚类中心。
初始化可以随机选择样本作为聚类中心,也可以根据领域知识或算法特点选择合适的样本。
4.计算样本之间的相似度或距离:根据选择的距离度量方法,计算样本之间的相似度或距离。
相似度越高或距离越小的样本越有可能属于同一个簇。
5.按照相似度或距离将样本划分为不同的簇:根据计算得到的相似度或距离,将样本划分为不同的簇。
常用的划分方法有硬聚类和软聚类两种。
硬聚类将样本严格地分到不同的簇中,而软聚类允许样本同时属于不同的簇,并给出属于每个簇的概率。
6.更新聚类中心:在K-means等迭代聚类算法中,需要不断迭代更新聚类中心,以找到最优划分。
更新聚类中心的方法有多种,常用的方法是将每个簇内的样本的均值作为新的聚类中心。
7.评估聚类结果:通过评估聚类结果的好坏,可以判断聚类算法的性能。
常用的评估指标有轮廓系数、Dunn指数、DB指数等。
聚类分析的目标是让同一簇内的样本点尽量相似,而不同簇之间的样本点尽量不相似。
因此,聚类分析常常可以帮助我们发现数据中的分组结构,挖掘出数据的内在规律。
聚类分析在市场细分、社交网络分析、基因表达数据分析等领域都有广泛的应用。




第五章聚类分析
班级:姓名:学号:
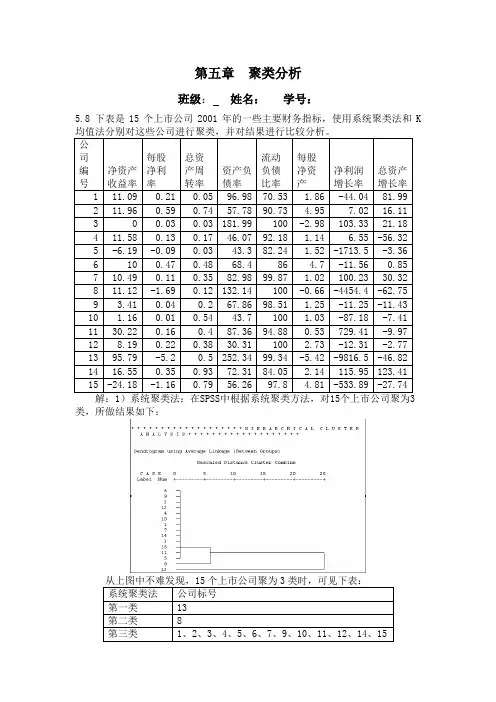
5.8 下表是15个上市公司2001年的一些主要财务指标,使用系统聚类法和K
类,所做结果如下:
2)K均值法:在SPSS4类,所做结果如下:
公司分为3类时,分类相同。
5.9 下表是某年我国16个地区农民支出情况的抽样调差数据,每个地区调查了反应每个人平局生活消费支出情况的六个经济指标,试通过统计分析软件用不同
择了以下四个方法,进行系统聚类分析,将16个地区分为4类: 1)组间连接法:
3)最近距离法:
4)最远距离法:
类,但是结果不同。
5.10 根据上题数据通过SPSS 统计分析软件进行快速聚类运算,并与系统聚类分析结果进行比较。
解:K 均值法:在SPSS 中根据K 均值法法,对16个城市为4类,所做结果如下:
出水平较接近,天津、辽宁、吉林等城市农民支出水平较接近。
5.11 表是2003年我国省会城市和计价单列市的主要经济指标:人均GDPX1(元)、人均工业产值X2(元)、客运总量X3(万人)、货运总量X4(万吨)、地方财政预算内收入X5(亿元)、固定资产投资总额X6(亿元)、在岗职工占总人口的比例X7(%)、在岗职工人均收入X8(元)、城乡居民年底储蓄余额X9(亿元)。
试通统计分析软件进行系统聚类分析,并比较何种方法与人们观察到得实际情况较接
37个城市分为3类:
1)组间连接法:
由上可以看出,将37个城市根据农民支出聚为3类时,可见下表
由上可以看出,应用组间连接法将37个城市根据农民支出聚为3类时,可见
由上可以看出,应用组内连接法将16个城市根据农民支出聚为3类时,可见
解:。



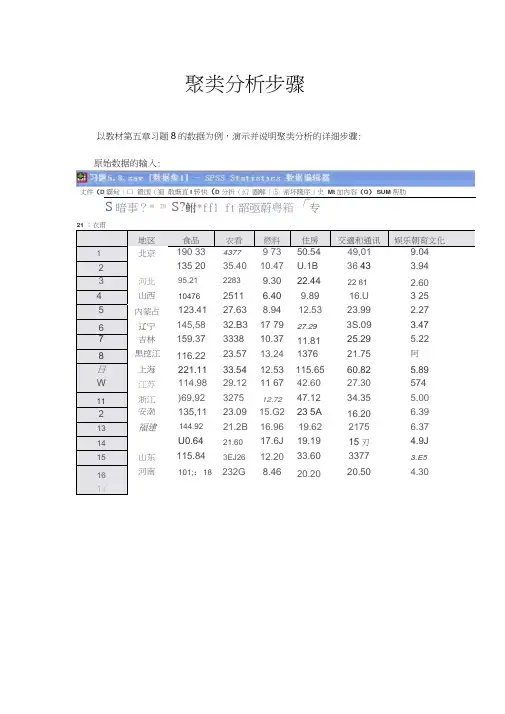
聚类分析步骤以教材第五章习题8的数据为例,演示并说明聚类分析的详细步骤:原始数据的输入:丈件(D 霸甸〔口锻国(蜀散惭直I 转快(D 分折(幻圈解〔⑤ 密坏賤序〔史Mt加内容(Q)SUM 帮肋S暗事?* ™ S?鮒*ffl ft韶亟蔚粤箱「专.选项操作:1. 打开SPSS的“分析”-“分类”-“系统聚类”,打开“系统聚类”对话框。
把“食品”、“衣着”等6变量输入待分析变量框;把“地区”输入“标注个案”;“分群”选中“个案”;“输出”选中“统计量”和“图”。
(如下图)相关说明:(1) 系统聚类法是最常用的方法,其他的方法较少使用。
(2) “标注个案”里输入“地区”,在输出结果的距离方阵和聚类树状图里会显示出“北京”、“天津”等,否则SPSS自动用“ 1”、“2”等代替。
(3) “分群”选中“个案”,也就是对北京等16个样本进行分类,而不是对食品等6个变量分类。
(4) 必须选中“输出”中的“统计量”和“图”。
在该例中会输出16个地区的欧氏距离方阵和聚类树状图。
密Ife鸟駝£臭* I必炮区H-qI 1E曲前 -------------输出v熨计養y岡2. 设置分析的统计量打开最右上角的“统计量”对话框,选中“合并进程表”和“相似性矩阵” “聚类成员”选中“无”。
然后点击“继续”。
打开第二个“绘制”对话框,必须选中“树状图”,其他的默认即可打开第三个对话框“方法”:聚类方法选中“最邻近元素”;“度量标准” 选中“区间”的“欧氏距离”;“转换值”选中“标准化”的“ Z 得分”,并且是“按照变量”。
+区町(LD : E uclidean 肚屈7" T计徹D ; 卡方度豪▼二鼻細^?TEuclicteeri■|i |g |打开第四个对话框“保存”,“聚类成员”选默认的“无”即可 三•分析结果的解读:按照SPSS 俞出结果的先后顺序逐个介绍:1. 欧氏距离矩阵:是16个地区两两之间欧氏距离大小的方阵, 该方阵是应用各 种聚类方法进行聚类的基础。