文本分析之制作网络关系图
- 格式:docx
- 大小:387.81 KB
- 文档页数:7

知识图谱与语义网络的建模与分析随着互联网的不断发展和人工智能的快速崛起,知识图谱和语义网络成为了研究和应用领域的热门话题。
它们对于机器理解和推理、信息检索和知识管理等方面具有重要意义。
本文将就知识图谱与语义网络的建模与分析进行探讨。
一、知识图谱的建模知识图谱是一种用于描述和组织知识的结构化数据模型。
它通过实体、属性和关系来表示知识,以图的形式展现。
知识图谱的建模过程包括三个主要步骤:实体识别、关系抽取和属性填充。
在实体识别阶段,需要从原始文本中识别出实体,例如人物、地点、物品等。
这可以通过命名实体识别和实体链接等技术来实现。
随后,在关系抽取步骤中,需要从文本中抽取出实体之间的关系。
这可以在预定义的关系集合中进行匹配或者使用远程监督等自动标注方法。
最后,对于每个实体和关系,还需要填充属性信息,以更加详尽地描述它们的特征。
二、语义网络的建模语义网络是一种基于语义关系的知识表示方法,它通过节点和边来表示实体和关系之间的语义联系。
与知识图谱类似,语义网络也可以用于组织和描述知识,但是它更加注重语义关系的建模。
语义网络的建模主要涉及两个方面:节点的语义表示和边的语义关系。
节点可以表示实体、概念或者属性等。
对于不同的应用场景,可以使用不同的节点类型和特征表示方法。
而边则表示实体之间的语义关系,例如属于、关联、相似等。
常见的语义关系有上下位关系、关联关系、相似关系等。
三、知识图谱与语义网络的分析知识图谱和语义网络的建模为后续的分析任务提供了基础。
在知识图谱的分析中,常见的任务包括图结构分析、图聚类和图挖掘等。
图结构分析可以揭示知识图谱中的拓扑结构特征,例如节点的度中心性、介数中心性和聚集系数等。
图聚类则可以将相似的节点聚集到同一个社区中,从而发现潜在的知识群体。
而图挖掘则可以探索知识图谱中隐藏的模式和规律。
对于语义网络的分析来说,常见的任务包括关系推理、语义相似度计算和语义链接等。
关系推理可以通过推理算法和规则引擎发现隐含的语义关系,从而丰富语义网络的表示能力。

基于图神经网络的社交媒体文本情感分析作者:王治学来源:《电脑知识与技术》2023年第25期摘要:随着社交媒体的广泛应用,人们在平台上产生了大量的文本内容,包含丰富的情感信息。
传统的情感分析方法往往忽视了文本之间的关系和上下文信息,导致结果不够准确。
为了解决这一问题,图神经网络被引入社交媒体文本情感分析中。
图神经网络可以有效地捕捉文本之间的复杂关系,并结合上下文信息进行情感分类。
因此,文章基于图神经网络的社交媒体文本情感展开分析,以便更好地挖掘社交媒体文本中的情感信息,为用户提供更精准的情感分析服务。
关键词:图神经网络;社交媒体;文本情感;分析中图分类号:TP3 文献标识码:A文章编号:1009-3044(2023)25-0027-03开放科学(资源服务)标识码(OSID):0 引言社交媒体已经成为人们日常生活中不可或缺的一部分,通过社交媒体平台,人们可以分享自己的想法、情感和体验,这种大规模的信息交流使得社交媒体成为研究用户情感和意见的宝贵数据源。
情感分析作为自然语言处理的重要任务之一,旨在识别和理解文本中所蕴含的情感倾向,从而为用户提供更个性化的服务和决策支持。
然而,社交媒体文本的情感分析面临着诸多挑战。
为了解决问题,图神经网络被引入社交媒体文本情感分析中。
图神经网络是一种适用于处理图结构数据的强大工具,它通过学习节点之间的连接和交互关系来推断节点的属性和标签。
在社交媒体文本情感分析中,可以将文本看作节点,将用户之间的关系看作图中的边,通过图神经网络模型来学习文本之间的关系和上下文信息,从而更准确地进行情感分类。
1 图神经网络的基本原理和变体1.1 基本原理图神经网络是一种基于图结构数据进行学习和推断的机器学习模型。
与传统的神经网络主要关注于处理向量和矩阵数据不同,图神经网络通过建模节点之间的连接关系来捕捉数据中的结构信息。
图神经网络的基本原理可以分为两个关键步骤:节点表示学习和图卷积操作。
节点表示学习是图神经网络的核心任務之一,旨在将每个节点表示为具有丰富语义信息的向量。


大数据分析政府工作报告随着信息技术的飞速发展,大数据技术也越来越被广泛应用。
政府工作报告可以看作是政府工作的总结和展望,对于政策制订和决策执行等方面都具有重要的指导作用。
因此,利用大数据对政府工作报告进行分析,既能对政府工作的实施情况有更加全面客观的了解,又能为政府在未来的政策制定和执行中提供有力的支持和参考。
一、政府工作报告的概述政府工作报告是国务院总理在全国人民代表大会上所作的政府工作的总结和报告。
它具有权威性和全面性,是全年中国政府工作的重要总结和回顾。
政府工作报告主要包括经济和社会发展情况分析、国内外形势评估、政府工作总体部署以及各行各业的政策和工作计划等内容。
政府工作报告的小标题、关键字、表格数据等都蕴含着大量可供挖掘的信息。
二、大数据对政府工作报告的分析1. 文本分析政府工作报告涉及范围广泛,包含了许多关键词。
可以利用文本分析技术对政策重点领域、政策目标和重点内容等进行分析。
文本分析可分为词频分析、基于正负情感分析以及主题模型分析等。
词频分析可以统计政府工作报告中某些特定词汇的出现频率。
基于正负情感分析可以度量政府工作报告的态度和情感,并以此作为政策制订和执行的参考。
主题模型分析可将政府工作报告根据主题内容进行聚类分析,以便了解某些特定政策领域的发展状况。
2. 可视化分析政府工作报告的表格和图片等数据资料多,可用可视化方式进行分析。
数据可视化是一种能够将数据以图形或其他形式展示出来的技术,可帮助用户理解数据的分布和趋势变化。
例如,可以通过绘制地图、折线图和柱状图等形式展示各省市的经济和社会发展情况,以便了解不同地区的发展情况,以及制定针对性的政策措施。
3. 网络关系图分析政府工作涉及多个部门和多个领域之间的协作关系。
可分析政府工作报告中各部委的职能和任务,以及不同部门和领域之间的合作情况。
可通过分析政府工作报告中涉及到的部委、政策及其它关键词之间的关系等形成网络关系图,以了解各部门的职能分工,以及不同部门之间的协作与配合情况。

基于网络分析的文本分类研究近年来,随着互联网技术的迅猛发展,以文本为代表的海量数据呈现出爆炸式增长的趋势。
因此,如何高效、准确地进行文本分类成为了一个热门研究课题。
而基于网络分析的文本分类研究则是其中的一个重要分支,它借助于网络科学的理论和方法,对文本数据进行了有效地处理和分析,能够更好地解决文本分类中遇到的难点和问题。
网络分析在文本分类中的应用网络分析是一种研究复杂系统的有效工具,可以将人们经常面对的各种现象和问题抽象成为一个图或网络模型,通过探索网络结构和特征,揭示出系统内部的规律和关系,从而实现对系统行为的深入理解和控制。
相比于传统的机器学习算法,在文本分类中应用网络分析技术有以下优势:首先,网络分析能够将文本抽象成为节点,文本间的关系抽象成为边,从而形成网络结构。
通过分析网络的拓扑结构和各个节点之间的关系,可以深入挖掘文本数据的内在规律和特征,发现象句法、语法、主题等不同层次的特征,从而更好地帮助用户理解和分析文本。
其次,网络分析能够处理大规模复杂的文本数据,可以将文本分为多个层次,如单词层、文本层、语料库层等,通过对不同层次的分析和整合,可以更全面、准确地表达文本数据。
此外,网络分析还能够检测和识别文本中存在的社区结构和重要度的差异,较好地解决了传统机器学习算法中存在的维度灾难、过拟合等问题。
最后,由于网络分析具有较强的可视化能力,并且能够将文本数据转化为数学模型,因此极大地提高了文本分类的可解释性和推广性。
同时,它还能够让文本分类结果更加透明,降低了分类错误的概率。
因此,基于网络分析的文本分类已经成为了当前文本领域的一个研究热点,得到了越来越广泛的关注和应用。
基于网络分析的文本分类方法目前,基于网络分析的文本分类方法主要可以分为以下几类:1.基于图同构和特征重构的文本分类方法。
该方法将文本表示成一张图,通过探索节点的度、聚类系数、介数中心度等网络结构信息和节点的词频、词义、语义等文本特征,重新构建文本特征表示模型,进而实现文本分类。

2020年4月下半月刊基于网络文本分析的主题公园形象感知研究——以郑州方特欢乐世界为例刘苏华本文以郑州方特欢乐世界为研究对象,通过网络采集游客评论,利用内容分析法和共现网络分析法对郑州方特欢乐世界的旅游感知形象进行分析,得出了游客对其整体感知是积极的、正面的,这种感知主要来自项目给游客带来的体验很刺激和愉快的结论,同时也针对其给游客带来的“遗憾”进行主要原因分析后提出了相应建议。
引言自1971年Hunt博士提出旅游形象概念以来,关于旅游形象的研究开始进入人们的视野,而伴随计算机技术与网络技术的成长与推广,越来越多的研究人员致力于将互联网数据用作旅游形象研究,网络文本采集、过滤与分析成为一种重要的研究手段。
戴光全、梁春鼎通过网络文本分析法,对西安世博会开幕前后网友态度进行研究,发现开幕后网友更多呈现的是“客人”的心态;苗红、马金涛等利用内容分析法,研究宁夏休闲农业开发与需求特征之后发现其有很大的发展空间;滕茜、杨勇等采取网络文本分析法对上海地区旅游形象分析后发现影响游客对旅游景区偏好的主要因素是景区的价值与旅游成本;梁保尔、攀植强基于游客的数字足迹,对上海历史街区研究后认为官方宣传的重点在于对环境的保护;钟栎娜采用复杂网络文本分析法从实证的角度证明了旅游者对旅游地的感知首先是环境整体;宋炳华、马耀峰等以平遥古城为例,利用网络文本分析,发现“人”主要影响了游客对其的消极感知;郑华伟在对红色旅游的网络文本进行分析后得出红色旅游对红色旅游者幸福感的内化构建以价值观内化为主要心理过程的结论;赵咪咪、张建国以丽水白云森林公园为例,通过网络文本分析法发现此公园的旅游形象感知主要为自然景观类;万蕙、唐雪琼在对傣族泼水节游客狂欢体验进行网络文本分析后发现游客在傣族泼水节身份被消解;孙小龙、林璧属利用网络文本分析法,以西江苗寨的旅游符号为研究对象,发现商铺数量、人流量、门票及非真实性是影响游客商业化识别的主要次类符号;宋振春、赵彩虹等对中国出境游进行网络文本分析发现中国人对出境旅游的社会认知受到传统文化影响,具有明显的集体主义特色;张瑞、张建国基于网络文本分析法,对上海辰山植物园旅游形象感知研究得出游客体验要素的分值总体较高,整体为积极感知的结论;彭丹、黄燕婷以丽江古城为研究对象,利用网络文本分析法,发现游客对其情感评价以积极情感为主,负面情感相对较少;刘逸、陈欣诺等采用内容分析法对游客的自然和人文旅游资源的情感画像差异进行研究,发现游客对自然资源的情感表达结构较为集中;宋楠楠、崔会平等以游客在宁波奉化滕头村的旅游体验为研究对象,进行文本分析后发现游客体验的满意与不满意之处,并提出了改进建议。

日常舆情检测方案随着社交媒体的崛起和普及,舆情监测对于企业和政府机构的重要性越来越显著。
在日常运营中,需要及时监测和分析公众对企业或政府机构的态度、声音和评价。
本文介绍一种基于网络抓取和文本分析的日常舆情检测方案。
1. 数据抓取数据抓取是舆情检测的基础工作。
我们可以使用一些流行的爬虫框架,如Scrapy、Beautiful Soup等。
通过指定关键词、时间范围和媒体类型等限制条件,从网络上抓取预定量的文本数据。
数据来源主要包括以下几类:•微博、微信公众号等社交媒体平台•新闻网站、论坛等官方或非官方媒体平台•公司或政府官网、客服中心等官方平台2. 数据预处理抓取到的数据还需要进行预处理,包括以下几个步骤:2.1 数据去重由于网络上的信息流量很大,同一条信息在不同媒体平台上可能会有多个转载和传播。
因此需要对抓取到的数据进行去重处理,保证每条数据只会出现一次。
2.2 数据清洗由于数据来源的多样性,抓取到的数据可能会包含一些无关信息,如广告、链接、图片等。
因此需要对数据进行清洗,只保留关键信息,如标题、正文、发布时间等。
2.3 数据归一化不同媒体平台上的文本格式差异很大,需要将不同格式的文本转换为统一的格式。
例如,将微博、微信公众号、新闻网站等不同平台上的文本都转化为纯文本格式。
2.4 数据存储预处理后的数据需要存储到数据库中,以便后续的数据分析和处理。
可以使用开源的数据库,如MySQL、MongoDB等。
3. 数据分析数据分析是数据实际意义的体现。
通过对海量数据的分析和挖掘,可以发现隐藏在数据背后的规律、趋势和信息。
下面介绍两种常用的数据分析技术。
3.1 文本情感分析文本情感分析是一种基于自然语言处理技术的文本分析方法,旨在识别文本中的情感和情绪。
可以将情感分为正面、负面、中性三种,对每个文本进行打分和分类。
常见的文本情感分析技术包括:•情感词典方法•机器学习方法•深度学习方法3.2 主题模型分析主题模型分析是一种对大量文本进行自动分析和摘要的方法,旨在发现文本中隐藏的主题和话题。


基于网页结构与链接关系的中文文本分类方法郭晓;蒋宗礼【摘要】提出一种通过综合考虑网页的HTML结构信息以及网页间的链接关系,修改网页文本在向量空间模型表示中的权值,对网页进行分类的方法.考虑到页面里处在不同HTML标记下的内容具有不同的语义含义,某些特殊标记下的内容具有较重要的意义,对网页的分类起较大的作用,因此对不同标记下的内容赋以不同的权值,可以提高分类效果.考虑到页面正文中链接指向的页面内容与原网页相关度较高,通过综合考虑这些页面的内容,可以有效加强类别关键词的权值,减少噪声,提高分类效果.经过实验证明这一方法提高了分类结果的F1值.【期刊名称】《现代电子技术》【年(卷),期】2010(033)022【总页数】4页(P54-56,63)【关键词】中文文本分类;HTML结构;链接关系;向量空间模型【作者】郭晓;蒋宗礼【作者单位】北京工业大学,计算机学院,北京,100124;北京工业大学,计算机学院,北京,100124【正文语种】中文【中图分类】TN911-34;TP391随着计算机技术、通信技术等信息技术的高速发展,以及互联网基础设施建设与网络信息工具的大量推广应用,网络上的信息正在以几何级数进行着增长。
如何使用户能够方便地从网络上海量的信息资源中获得其期望的部分,成为了当前信息领域重要的研究课题。
网络搜索引擎,是用来进行网络文本索引的一种重要手段,是针对网络中大量网页文本信息进行信息挖掘的有效手段。
在网络搜索引擎的构建中,网页文本分类问题是一个关键性的核心问题。
高质量高效率的网页文本自动分类,对构建高效、实用的搜索引擎起着重要的作用。
同时在解决主题搜索、个性化信息检索、搜索引擎的目录导航等相关问题时,网页文本分类技术也是十分重要的。
因此研究如何提升网页文本分类性能,对研究新一代搜索引擎有着重要意义。
1 网页文本分类技术简析网页文本分类是指按照预先定义的主题类别,根据海量网页文档的内容,确定相应网页的类别。

基于网络文本分析的游客沙漠露营体验感知研究——以敦煌市沙漠露营地为例欧阳正宇尚彤(西北师范大学旅游学院,甘肃兰州730070)[摘要]本研究选取敦煌市六家沙漠露营地的在线点评数据作为研究样本,采用内容分析法,对网络点评文本进行分析,利用ROST CM6软件提取高频词及生成语义网络图进行内容分析,并利用NVivo 12Plus 软件进行开放式编码、关联式编码和选择式编码提炼核心主题,寻找沙漠露营旅游者的露营体验感知。
研究发现,网络点评文本中感知到的四个核心体验为娱乐体验、住宿体验、服务体验以及区位环境。
通过分析游客沙漠露营体验感知,以期为沙漠露营地的有效供给、建设发展以及精准营销提供参考依据。
[关键词]沙漠露营;ROST CM6;NVivo 12Plus ;内容分析法;住宿体验[中图分类号]F592.7[文献标识码]A[文章编号]1005-3115(2023)04-0098-10[作者简介]欧阳正宇(1968-),女,汉族,湖南汝城人,博士,副教授。
研究方向:旅游文化与资源开发、民族旅游、遗产旅游。
尚彤(1998-),女,汉族,山西运城人,在读硕士。
研究方向:旅游文化。
一、前言随着个性化需求的增长与接近大自然的需要,露营旅游成为人们体验另类生活、接触大自然的最主要方式之一,其中沙漠露营旅游是一种新兴的露营旅游方式。
露营按照距离长短可分为短距离周边露营和长距离露营,按装备可分为帐篷露营、房车露营等。
沙漠露营是指在沙漠环境下进行的露营,相比于惯常环境以及舒适环境下的露营来说,沙漠环境更加新奇也更加陌生,游客对沙漠环境缺乏经验,沙漠环境具有温差大、方向不易辨别、行进不方便、虫子多、有发生沙尘暴的可能性等常人难以解决的情况,比其他一般性露营更加需要专业人士的指导。
在欧美国家,露营产业从第一代的自驾车载帐篷到第二代的拖挂房车旅游产品,再到第三代的露营社区的形成,露营已经成为一种度假常态。
我国露营旅游跳过第一阶段和第二阶段,直接进入第三阶段。
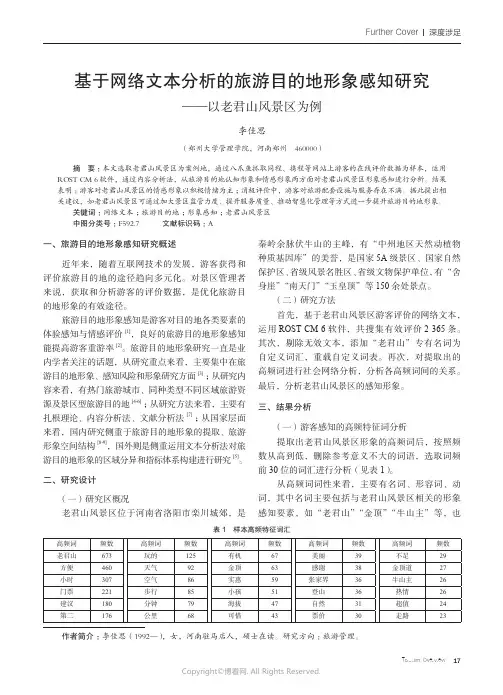
Tourism Overview17Further Cover深度涉足基于网络文本分析的旅游目的地形象感知研究——以老君山风景区为例李佳思(郑州大学管理学院,河南郑州 460000)摘 要:本文选取老君山风景区为案例地,通过八爪鱼抓取同程、携程等网站上游客的在线评价数据为样本,运用ROST CM 6软件,通过内容分析法,从旅游目的地认知形象和情感形象两方面对老君山风景区形象感知进行分析。
结果表明:游客对老君山风景区的情感形象以积极情绪为主;消极评价中,游客对旅游配套设施与服务存在不满。
据此提出相关建议,如老君山风景区可通过加大景区监管力度、提升服务质量、推动智慧化管理等方式进一步提升旅游目的地形象。
关键词:网络文本;旅游目的地;形象感知;老君山风景区中图分类号:F592.7 文献标识码:A一、旅游目的地形象感知研究概述近年来,随着互联网技术的发展,游客获得和评价旅游目的地的途径趋向多元化。
对景区管理者来说,获取和分析游客的评价数据,是优化旅游目的地形象的有效途径。
旅游目的地形象感知是游客对目的地各类要素的体验感知与情感评价[1],良好的旅游目的地形象感知能提高游客重游率[2]。
旅游目的地形象研究一直是业内学者关注的话题,从研究重点来看,主要集中在旅游目的地形象、感知风险和形象研究方面[3];从研究内容来看,有热门旅游城市、同种类型不同区域旅游资源及景区型旅游目的地[4-6];从研究方法来看,主要有扎根理论、内容分析法、文献分析法[7];从国家层面来看,国内研究侧重于旅游目的地形象的提取、旅游形象空间结构[8-9],国外则是侧重运用文本分析法对旅游目的地形象的区域分异和指标体系构建进行研究[5]。
二、研究设计(一)研究区概况老君山风景区位于河南省洛阳市栾川城郊,是秦岭余脉伏牛山的主峰,有“中州地区天然动植物种质基因库”的美誉,是国家5A 级景区、国家自然保护区、省级风景名胜区、省级文物保护单位,有“舍身崖”“南天门”“玉皇顶”等150余处景点。
总结关系图1. 简介关系图是一种用于显示实体之间相互关系的可视化工具。
它通过节点和边来表示实体和它们之间的连接。
关系图可以用于展示各种不同类型的关系,例如人际关系、组织结构、知识图谱等。
在本文档中,我们将会总结关系图的基本概念、使用场景以及常见的工具和库。
2. 关系图的基本概念关系图中的基本元素包括节点和边。
节点表示实体,可以是人、组织、地点等,而边则表示节点之间的关系。
2.1 节点节点是关系图中的基本单位,用于表示实体。
每个节点通常具有一个唯一的标识符和一些属性。
节点可以有不同的样式和颜色,以在图表中进行区分。
2.2 边边是两个节点之间的连接线,用于表示节点之间的关系。
边可以是有向的或无向的,有向边表示关系是单向的,而无向边表示关系是双向的。
边也可以具有属性,例如权重、标签等。
3. 关系图的使用场景关系图在许多不同的领域和场景中都有广泛的应用。
下面列举了一些典型的使用场景。
3.1 人际关系图人际关系图用于描述人与人之间的关系网。
它可以用于社交网络分析、人脉管理、团队协作等。
通过分析人际关系图,我们可以了解人们之间的联系、影响力和信息流动。
3.2 组织结构图组织结构图用于显示一个组织内部的层级关系和职位关系。
它可以展示公司的部门结构、员工的上下级关系以及团队之间的协作关系。
组织结构图可以帮助管理者更好地了解组织的工作流程和决策过程。
3.3 知识图谱知识图谱是一种用于表示知识之间的关联关系的图形结构。
它可以用于知识管理、学习导图、文本分析等领域。
通过构建知识图谱,我们可以发现知识之间的关联性,帮助我们更好地理解和应用知识。
4. 常见的关系图工具和库关系图可以使用各种不同的工具和库进行绘制和分析。
下面列举了一些常见的关系图工具和库。
4.1 Microsoft VisioMicrosoft Visio是一款流程图和关系图绘制工具,它提供了丰富的图形库和绘图功能。
Visio可以用于制作各种类型的关系图,如组织结构图、流程图、数据流程图等。
基于网络文本分析的成都旅游目的地形象感知研究作者:唐嘉罗梦婷夏雪李钦清李奕潞来源:《中国集体经济》2021年第10期摘要:近年来,随着我国旅游业不断发展,人们对旅游业的关注度越来越高,旅游目的地形象的有关问题也成为业界研究的热点。
文章以成都主城区为旅游目的地案例,运用ROSTCM6软件对成都旅游体验感知的高频特征词进行分析,了解旅游者对成都旅游目的地的偏好,找出成都旅游目的地在发展过程中的不足并提出针对性建议,促进成都旅游向好发展。
关键词:网络文本;旅游目的地;成都;形象感知一、前言在旅游研究领域中,随着旅游个性化体验时代的到来和旅游多元化价值取向的确立,旅游目的地形象感知对于各地旅游业发展的重要性日益凸显。
随着物联网和移动互联网的发展,分享旅游攻略、发表游记的平台与论坛不断涌现。
对于目的地形象的感知,潜在消费者可通过网络渠道获取,这些感知在一定程上被当作旅游地的真实反映,这极大影响着潜在消费者的认知和决策。
因此,本文以成都主城区为旅游目的地案例,选取相关网络游记作为文本资料,运用ROST CM6软件对相关游记进行分析,探讨成都作为旅游目的地的形象。
二、研究设计(一)研究方法基于在成都主城区旅游游客评论的网络文本,运用ROST CM6软件对成都作为旅游目的地的网络游记文本的高频词和频数进行归纳提取,从而了解游客在成都主城区旅游的体验感知情况;其次,通过对网络游记文本中提取出的高频词汇进行社会网络分析,分析各高频词之间的关系;最后,从旅游者的情感和认知等方面来分析成都旅游目的地的感知形象。
(二)样本选择本研究以飞猪、携程、马蜂窝等旅游网站中的成都相关游记为样本数据,选取自2018年1月至2019年12月在成都市区游玩的网络游记样本,共73篇。
三、结果分析(一)游客感知的高频特征词分析通过ROST CM6软件提取关于成都旅游形象的高频特征词,按照出现的频数由高到低选取词频前50位的词汇进行分析,如表1所示。
社交媒体分析的技巧与方法社交媒体已经成为了人们日常生活中不可或缺的一部分。
无论是个人用户还是商业机构,都开始意识到社交媒体的重要性,并将其作为传播信息、互动交流的重要平台。
然而,社交媒体上的信息量庞大,要想从中获得有价值的信息和见解,并运用于实际的决策中,需要一定的技巧和方法。
本文将探讨社交媒体分析的技巧与方法。
一、文本分析文本分析是社交媒体分析的基础。
在社交媒体中,用户产生的内容包括文字、图片、视频等多种形式。
而文字是其中最为重要的一部分,因为其包含了用户的观点、情感等信息。
在进行文本分析时,可以运用文本挖掘技术,包括关键词提取、情感分析等,从海量的文本中提取有用的信息。
关键词提取是一种常用的文本挖掘方法。
通过统计词频和TF-IDF等算法,可以找出在社交媒体中频繁出现的关键词,进而了解用户的关注点和热点话题。
例如,通过分析某个品牌在社交媒体上被提及的关键词,可以了解到用户对该品牌的印象和评价。
情感分析是另一种常用的文本挖掘方法。
通过自然语言处理技术,可以判断出文本中表达的情感倾向,包括积极、消极、中性等。
这对于商业机构来说尤为重要,因为可以了解用户对产品或服务的态度,从而及时调整营销策略或改进产品。
二、网络关系分析社交媒体的本质就是人与人之间的互动关系,因此网络关系分析是社交媒体分析的关键。
通过分析社交媒体上用户之间的关注关系、互动行为,可以了解用户的兴趣爱好、社交圈子等信息,从而实现精准营销和用户画像。
社交网络图是一种常用的网络关系分析方法。
通过构建社交网络图,将用户表示为节点,互相关系表示为边,可以直观地展示出用户之间的连接和关系。
通过分析社交网络图的拓扑结构,可以找出核心用户、意见领袖、关键连接等,为精准营销提供依据。
三、趋势分析社交媒体上的信息更新速度快,趋势分析能帮助我们及时了解热点话题和用户兴趣的变化。
通过监测社交媒体上的关键词、话题等,可以发现正在流行的事件或话题,并及时采取相应的行动。
16种常用数据分析方法数据分析是指通过收集、整理、处理和分析数据,以帮助人们做出决策和提供洞见的过程。
在数据分析中,有许多常用的方法可以应用于不同类型的数据和问题。
以下是16种常用的数据分析方法:1.描述性统计分析:通过计算数据的中心趋势、离散程度和分布特征,来描述数据的基本统计特征。
2.相关分析:用于确定变量之间的相关性,并通过计算相关系数来描述这种相互关系。
3.回归分析:用于建立一个预测模型,通过探查自变量和因变量之间的关系,来预测未来的数值。
4.时间序列分析:通过对随机变量按照时间顺序进行观测和测量,来探究时间的影响和趋势的变化。
5.聚类分析:通过对数据进行分组,使得每个组内的对象彼此相似,而不同组之间的对象则差异较大。
6.因子分析:用于确定潜在的因素或维度,以解释观察到的多个变量之间的相互关系。
7.决策树分析:通过树状图模型方法,以帮助决策者理解和解决决策问题。
8.关联规则分析:用于发现数据中的关联规则,即有哪些项集经常同时出现。
9.假设检验:用于根据样本数据对总体参数进行测试,以判断推论结果是否统计上显著。
10.因果推断:通过观察因果关系的各个方面,以推断原因与结果之间的关系。
11.可视化分析:通过图表、图像和动画等可视化工具展示数据,以加强对数据的理解和发现。
12.数据挖掘:利用计算机科学和统计学的技术,从大量的数据中发现隐藏的模式和知识。
13.协同过滤:根据用户的历史行为、兴趣和偏好,推荐适合的产品或信息。
14.文本分析:通过分析文本数据中的关键字、主题和情感等内容,来提取有用的信息。
15.预测建模:通过历史数据中的模式和趋势,来预测未来的趋势和结果。
16.网络分析:通过对网络关系图进行分析,以揭示网络中的重要节点和关键路径。
以上是常用的16种数据分析方法,每种方法都有其独特的应用和适用范围。
根据数据的类型和问题的需求,选择适当的数据分析方法可以帮助人们更好地理解数据,并作出更准确的决策。
2024年高考二轮复习高频考点强化训练卷24 实用类文本阅读之图表分析类1.B 2.D3.①意义:开启了后人对雪花晶体的研究;②启示:善于从生活中发现科学问题,养成良好的科学观察习惯,运用科学思维探讨现象背后的本质【解析】1.本题考查学生筛选并辨析信息的能力。
材料三相关表述是“在-2℃左右时呈板状,在-5℃左右时呈柱状,在-15℃左右时又呈板状,在低于-25℃时呈柱状或板状”“当湿度高时,快速生成的柱状晶体会变成轻软的针状晶体,而六角形板状晶体会变成星状的枝蔓晶体。
随着温度的下降,雪晶的形状会在板状和柱状之间来回变化好几次,而且变化很大:在几度温差范围内,雪晶会从又细又长的针状晶体(-5℃)变为薄而平的板状晶体(-15℃)”。
雪晶的形状“在-15℃左右时……呈板状”;过饱和度湿度高时,“六角形板状晶体会变成星状的枝蔓晶体”,而AD项六角形板状晶体在上,星状的枝蔓晶体在下,正好相反,可排除AD;雪晶的形状“在-2℃左右时呈板状”;过饱和度湿度高时“快速生成的柱状晶体会变成轻软的针状晶体”,而C项是由实心板状晶体变成的针状晶体,可排除C。
故选B。
2.本题考查学生对多个信息进行比较、辨析的能力。
A.“雪花具有对称的六角形结构”错,原文是“雪花是六瓣的这一事实”;“是世界上最早的表述”错,原文是“最先在文献上发表的”;B.“因此”强加因果。
原文是“开普勒出于对几何、对称的兴趣,写了一本小书专门来研究雪花为何是六瓣的,尽管他当时所掌握的知识是不足以解释其成因的,但是,他这个方向是很有意思的”,可见他的研究没有向前推进,也没有得出可信的结论不是因为他的研究“只是出于对几何和对称的兴趣”,而是因为“他当时所掌握的知识是不足以解释其成因”;C.“开普勒认为雪花呈六角形与水汽无关”与文本不符。
原文“开普勒认为雪花呈六角形的原因不能通过‘材质’寻找”。
“他没有再对此机制作出解释”错,原文是“进而,他猜想这个机制可能是冰‘球’的有序堆积过程”,可见开普勒对机制作出了猜想。
基于网络文本分析的旅游目的地形象感知研究作者:陈敏艳夏鑫来源:《商情》2020年第04期【摘要】当今世界互联网高速发展,网络游记影响着目的地形象的塑造,本文以日本为研究对象,基于马蜂窝的1980篇游记为研究内容,通过网络文本分析游客对日本的形象感知,结果发现:(1)游客对日本的感知是以“日本”为核心,以基础设施为重点的圈层式扩散结构特征;(2)游客对日本的情绪以正向情感为主,但其中也存在不少负面情感,主要包括配套设施、旅游吸引物和主客互动三方面。
并据此对目的地营销组织提出相关建议。
【关键词】日本旅游形象马蜂窝游记1.引言随着网络技术的更新换代,我国已逐渐进入全民互联网时代,互联网走入更多家庭,并更为国民所接受。
互联网与传统旅游业的深度融合发展已成为不可阻挡的时代潮流,越来越多的网民更加依赖网络信息,通过互联网了解世界。
网络平台成为旅游者出游前获取旅游目的地形象最容易、最快捷的途径,游客往往会倾向于查阅相关游记、评论来感知旅游地。
互联网的到来在改善和丰富旅游者的旅游体验之时,也产生了旅游者记录的大量不同类型的旅游数据,这也为研究者提供了网络研究素材,减少了传统问卷和访谈因问卷数量、调查者的动机以及调查问卷设计等因素产生的数据质量问题。
时代的变迁和科技技术的高速发展,使得来越多研究者认可通过网络文本研究旅游形象的价值。
日本是中国一衣带水的邻邦国家,据日本旅游局统计数据显示,2018年中国去日本游客数超800万,让人不禁好奇,日本因何能将旅游业做的如此发达?因此本文根据游客对日本游记的高频特征词及情感整理分析,从而深入分析游客对日本的整体感知,以期为未来其他国家的旅游营销策略提供现实指向。
2.研究设计2.1样本选取与处理在互联网迅速发展的今天,在线旅游企业发挥中越来越重要的作用,不仅为后端旅游商提供了精准的流量,也可以帮助更多前端的用户做出消费决策。
因此本文选择国内影响力较大的马蜂窝网站作为本研究的样本来源。
文本分析之制作网络关系图Python
今天给大家带来我一个脚本,用来分析社会网络关系。
这个图我没有用到gephi或者其他的工具,是我用python纯脚本运行出来的。
简单的实现了封装,大家有兴趣可以下载下脚本,运行下。
原理知识
我就简单说下原理吧,先刻画一个简单的图A
1. import networkx as nx
2. import matplotlib.pyplot as plt
3. #有向图
4. DG = nx.DiGraph()
5. #添加一个节点
6. DG.add_node('A')
7. #作图,设置节点名显示,节点大小,节点颜色
8. nx.draw(DG,with_labels=True,node_size=900,node_color = 'green')
9. plt.show()
双节点,有方向A–>B
1. #有向图
2. DG = nx.DiGraph()
3. #添加一个节点
4. DG.add_node('A')
5. DG.add_node('B')
6. #添加边,有方向,A-->B
7. DG.add_edge('A','B')
8. #作图,设置节点名显示,节点大小,节点颜色
9. nx.draw(DG,with_labels=True,node_size=900,node_color = 'green')
10. plt.show()
添加更多节点
1. import networkx as nx
2. import matplotlib.pyplot as plt
3.
4. colors = ['red', 'green', 'blue', 'yellow']
5. #有向图
6. DG = nx.DiGraph()
7. #一次性添加多节点,输入的格式为列表
8. DG.add_nodes_from(['A', 'B', 'C', 'D'])
9. #添加边,数据格式为列表
10. DG.add_edges_from([('A', 'B'), ('A', 'C'), ('A', 'D'), ('D','A')])
11. #作图,设置节点名显示,节点大小,节点颜色
12. nx.draw(DG,with_labels=True, node_size=900, node_color = colors)
13. plt.show()
好了,同样的道理,咱们建立角色词典,插入节点列表,然后遍历插入有向边关系,就能做出这图:
《Python基于共现提取《釜山行》人物关系》
这篇文章写的很好(希望不要黑我,我也是觉得真心好)。
我基本上借鉴了这篇文章思路写今天这个脚本,实现了自动生成关系网络图。
准备工作
1. 一、安装matplotlib、networkx
2.
3. 二、解决matplotlib无法写中文问题
4.
5. 1、找到pythonX\lib\site-packages\matplotlib\mpl-data\fonts\ttf文件夹
6.
7. 2、matplotlib默认调用的为DejaVuSans.ttf字体文件,网上下载个
8.
9. 微软雅黑.ttf
10.
11. 3、将微软雅黑文件名改为DejaVuSans.ttf粘贴到ttf文件夹下即可。
脚本文件简介
你下载后脚本文件夹名为:人民的名义
其中的relationship.py就是大邓写的库(直接能调用的哦)
实现功能:
1、读入小数数据和角色词典后,对数据分词后生成角色关系数据(有向关系数据)
2、无需gephi绘图即可制作绚丽角色关系网络图。
注意:
1、运行脚本前,文件夹中只保留角色名单.txt 人民的名义.txt 和relationship.py
2、要想图片好看点,一定要联网啊。
里面我写了个爬虫,爬取一个配色网站的配色值。
如果你们想单机也可以画出好看的图,可以修改下代码,将代码爬虫部分改成读取本地颜色数据使用示例
1、建好小说数据中的角色字典,格式如下
2、在文件夹中放入小说txt文件(人民的名义.txt)
3、在脚本文件夹中新建一个test.py文件
1. #导入relationship库中的Relationship类
2. from relationship import Relationship
3.
4. #自定义节点词典(小说中人物角色)
5. dictpath = r'/Users/suosuo/Desktop/人民的名义/角色名单.txt'
6. #小说路径,只能是编码方式为utf-8的txt文件
7. datapath = r'/Users/suosuo/Desktop/人民的名义/人民的名义.txt'
8. #程序运行生成的角色关系图保存地址
9. pic = r'/Users/suosuo/Desktop/人民的名义/人物关系图.png'
10. Re = Relationship(dictpath, datapath)
11. relation = Re.relationship()
12. graph = work_digraph(relation, pic)
4、运行
文件夹中生成了人物关系图.png、node_edge.txt和node_freq.txt文件。
node_edge.txt 有向图关系数据,可以后续导入gephi软件自定义制图
node_freq.txt 节点出现频率
注意:每次运行前请把人物关系图.png、node_edge.txt和node_freq.txt文件删除掉,再运行。
【编辑推荐】
1.Apriori算法介绍(Python实现)
2.python学习之路——python切片模拟LRU算法
3.Python分布式抓取和分析京东商城评价
4.如何用PyTorch实现递归神经网络?
5.像Excel一样使用python进行数据分析-(2)。