SPSS的常用的一些函数大全
- 格式:doc
- 大小:72.50 KB
- 文档页数:9

Spss 算术函数孙中友江苏ABS(numexpr 数值。
返回 numexpr (必须为数值的绝对值。
ARSIN(numexpr 数值。
返回 numexpr 的反正弦(以弧度为单位 ,求出的值必须为 -1 和 +1 之间的数字值。
ARTAN(numexpr 数值。
返回 numexpr 的反正切(以弧度为单位 , numexpr 必须为数字值。
COS(radians 数值。
返回 radians 的余弦(以弧度为单位 , radians 必须为数字值。
EXP(numexpr 数值。
返回 e 的 numexpr 次幂, 其中 e 是自然对数的底数, 而numexpr 是数值。
较大的 numexpr 值可能会产生超过机器性能的结果。
LN(numexpr 数值。
返回以 e 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
LNGAMMA(numexpr 数值。
返回 numexpr 的完全 Gamma 函数的对数, numexpr 必须为大于 0 的数值。
LG10(numexpr 数值。
返回以 10 为底数的 numexpr 的对数, numexpr 必须为大于 0 的数值。
MOD(numexpr,modulus 数值。
返回 numexpr 除以 modulus 所得到的余数。
两个参数都必须为数值,且 modulus 不得为 0。
RND(numexpr 数值。
返回对 numexpr 舍入后产生的整数, numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去 0 以后的数值。
SIN(radians 数值。
返回 radians 的正弦(以弧度为单位 , radians 必须为数字值。
SQRT(numexpr 数值。
返回 numexpr 的正平方根, numexpr 必须为非负数。
TRUNC(numexpr 数值。
返回 numexpr 被截断为整数(向 0 的方向的值。
统计函数后缀 .n 可在所有统计函数中使用以指定有效参数的数目。
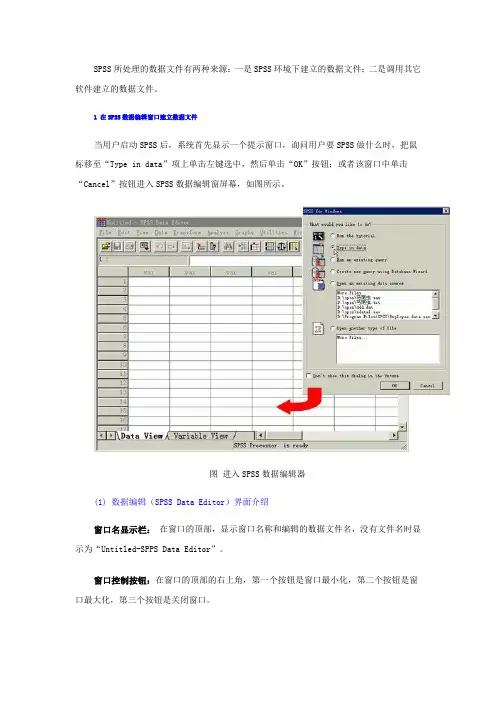
SPSS所处理的数据文件有两种来源:一是SPSS环境下建立的数据文件;二是调用其它软件建立的数据文件。
1 在SPSS数据编辑窗口建立数据文件当用户启动SPSS后,系统首先显示一个提示窗口,询问用户要SPSS做什么时,把鼠标移至“Type in data”项上单击左键选中,然后单击“OK”按钮;或者该窗口中单击“Cancel”按钮进入SPSS数据编辑窗屏幕,如图所示。
图进入SPSS数据编辑器(1) 数据编辑(SPSS Data Editor)界面介绍窗口名显示栏:在窗口的顶部,显示窗口名称和编辑的数据文件名,没有文件名时显示为“Untitled-SPPS Data Editor”。
窗口控制按钮:在窗口的顶部的右上角,第一个按钮是窗口最小化,第二个按钮是窗口最大化,第三个按钮是关闭窗口。
SPSS主菜单:在窗口显示的第二行上,有:File文档,Edit编辑,View显视,Data数据,Transform转换,Analyze分析,Graphs图形,Utilities公用项,Windows视窗。
图 SPSS窗口界面常用工具按钮:在窗口显示的第三行上,有:打开文档,保存文档,打印,对话检索,取消当前操作,重做操作,转到图形窗口,指向记录,指定变量操作,查找,在当前记录的上方插入新的空白记录,在当前变量的左边插入新的空白变量,切分文件,设置权重单元,标记单元,显示价值标签。
数据单元格信息显示栏:在编辑显示区的上方,左边显示单元格和变量名(单元格:变量名),右边显示单元里的内容。
编辑显示区:在窗口的中部,最左边列显示单元序列号,最上边一行显示变量名称,缺省为“Var”。
编辑区选择栏:在编辑显示区下方,Data View 在编辑显示区中显示编辑数据,Variable View在编辑显示区中显示编辑数据变量信息。
状态显示栏:在窗口的底部,左边显示执行的系统命令,右边显示窗口状态。
(2) 数据文件格式数据文件格式以每一行为一个记录,或称观察单位(Cases),每一列为一个变量(Variable)。

1.SPSS是软件英文名称的首字母缩写,其最初为Statistical Package for the Social Sciences的缩写,即“社会科学统计软件包”。
2.SPSS系统运行管理方式(SPSS的几种基本运行方式)有:(1)完全窗口菜单运行方式(2)程序运行管理方式(3)混合运行管理方式3.SPSS的界面提供的五个窗口:数据编辑窗口、结果管理窗口、结果编辑窗口、语法编辑窗口、脚本窗口。
第二章1.SPSS的文件类型:语法文件(*.sps)、数据文件(*.sav)、结果输出文件(*.spv)。
2.SPSS数据编辑器的每一行数据称为一个个案(Case),每一个数据代表个体的属性,即变量(Variable)。
3.SPSS变量名的命名规则:1)必须以英文字母开头,其他部分可以含有字母、数字、下划线(即“-”);2)变量名尽量避免和SPSS已有的关键字重复,例如sum、compute、anova等;3)SPSS13及以后版本支持变量名最长为64Byte,即变量名最长为64个英文字符,或者32个中文字符;4)SPSS变量名不区分大小写,即SPSS认为Name、name、nAme这三个变量名没有区别。
4.变量度量类型:定量(个数、高度、温度等)、定序(“十分重要”、“重要”、“一般”、“不重要”)、定类(名字、地址、电话等)。
5.列和宽度的区别:变量宽度:对字符型变量,该数值决定了你能输入的字符串的长度;列:设定该变量数据视图中列的宽度。
6.变量的值标签:即对数值含义的解释。
例如:值标签1 2 男女7.默认的缺失值类型:数值型类型(.)、字符串类型(空格)。
8.数据文件的合并包括:纵向合并和横向合并(合并个案和合并变量),合并变量包括一对一合并和一对多合并。
9.SPSS用“(*)”表示变量来自于当前活动数据文件中的变量,而用“(+)”表示将要和当前数据文件进行合并的数据文件中的变量。
10.在合并数据文件之前,所有需要合并的数据文件必须预先按照关键变量进行升序排列。

心理统计常用公式总结1 、组数 K (总体分布为正态)( N 为数据个数, K 取近似整数)2 、算术平均数3 、中数4 、众数5 、加权平均数,其中 W i 为权数,其中为各小组的平均数, n i 为各小组人数6 、几何平均数,其中 n 为数据个数, X i 为数据的值7 、调和平均数8 、方差与标准差,其中9 、变异系数,其中 S 为标准差, M 为平均数10 、标准分数,其中 X 为原始数据,为平均数, S 为标准差11 、全距 R =最大数-最小数12 、平均差13 、四分差,其中 L b 为该四分点所在组的精确下限, F b 为该四分点所在组以下的累加次数,和为该四分点所在组的次数, i 为组距, N 为数据个数14 、积差相关基本公式:,其中, , N 为成对数据的数目, S x 、 S y 分别为 X 和 Y 的标准差变形:差法公式:用估计平均数计算:用相关表计算:15 、斯皮尔曼等级相关,其中 D 为各对偶等级之差直接用等级序数计算:,其中 R X 、 R Y 分别为二变量各等级数有相同等级时:16 、肯德尔等级相关有相同等级:17 、点二列相关,其中是两个二分变量对偶的连续变量的平均数,p 、 q 是二分变量各自所占的比率, p+q=1 , S t 是连续变量的标准差18 、二列相关,其中 S T 与是连续变量的标准差与平均数, y 为 P 的正态曲线的高度19 、多系列相关,其中 P i 为每系列的次数比率, y 1 为每一名义变量下限的正态曲线高度, y h 为每一名义变量上线的正态曲线高度,为每一名义变量对偶的连续变量的平均数, S t 为连续变量的标准差20 、总体为正态,σ 2 已知:21 、总体为正态,σ 2 未知:22 、23 、24 、。


心理统计常用公式总结1 1 、组数、组数、组数 K K K (总体分布为正态)(总体分布为正态)( N N 为数据个数,为数据个数,为数据个数, K K K 取近似整数)取近似整数)2 2 、算术平均数、算术平均数3 3 、中数、中数4 4 、众数、众数5 5 、加权平均数、加权平均数,其中,其中 W i W i W i 为权数为权数,其中为各小组的平均数,为各小组的平均数, n i n i n i 为各小组人数为各小组人数6 6 、几何平均数、几何平均数、几何平均数,其中,其中 n n n 为数据个数,为数据个数,为数据个数, X i X i X i 为数据的值为数据的值为数据的值7 7 、调和平均数、调和平均数、调和平均数8 8 、方差与标准差、方差与标准差、方差与标准差,其中其中9 9 、变异系数、变异系数、变异系数 ,其中,其中 S S S 为标准差,为标准差,为标准差, M M M 为平均数为平均数为平均数10 10 、标准分数、标准分数、标准分数 ,其中,其中 X X X 为原始数据,为原始数据,为原始数据, 为平均数,为平均数, S S S 为标准差为标准差为标准差 11 11 、全距、全距、全距 R R R =最大数-最小数=最大数-最小数=最大数-最小数12 12 、平均差、平均差、平均差13 13 、四分差、四分差、四分差,其中,其中 L b L b L b 为该四分点所在组的精确下限,为该四分点所在组的精确下限,为该四分点所在组的精确下限, F b F b F b 为该四分点所在组以下的累加次数,为该四分点所在组以下的累加次数,为该四分点所在组以下的累加次数,和 为该四分点所在组的次数,为该四分点所在组的次数, i i i 为组距,为组距,为组距, N N N 为数据个数为数据个数为数据个数14 14 、积差相关、积差相关、积差相关基本公式:基本公式: ,其中,其中, , ,, N N 为成对数据的数目,为成对数据的数目,为成对数据的数目, S x S x S x 、、 S y S y 分别为分别为分别为 X X X 和和 Y Y 的标准差的标准差的标准差变形:变形:差法公式:差法公式:用估计平均数计算:用估计平均数计算:用相关表计算:用相关表计算:15 15 、斯皮尔曼等级相关、斯皮尔曼等级相关、斯皮尔曼等级相关,其中,其中 D D D 为各对偶等级之差为各对偶等级之差为各对偶等级之差直接用等级序数计算:直接用等级序数计算:,其中,其中 R X R X R X 、、 R Y R Y 分别为二变分别为二变量各等级数量各等级数 有相同等级时:有相同等级时:16 16 、肯德尔等级相关、肯德尔等级相关、肯德尔等级相关有相同等级:有相同等级:17 17 、点二列相关、点二列相关、点二列相关,其中,其中 是两个二分变量对偶的连续变量的平均数,平均数, p p 、、 q q 是二分变量各自所占的比率,是二分变量各自所占的比率,是二分变量各自所占的比率, p+q=1 p+q=1 p+q=1 ,, S t S t 是连续变量的标准差是连续变量的标准差是连续变量的标准差18 18 、二列相关、二列相关、二列相关,其中,其中 S T S T S T 与与是连续变量的标准差与平均数,是连续变量的标准差与平均数, y y y 为为 P P 的正态曲线的高度的正态曲线的高度的正态曲线的高度19 19 、多系列相关、多系列相关、多系列相关,其中,其中 P i P i P i 为每系列的次数比率,为每系列的次数比率,为每系列的次数比率, y 1 y 1 y 1 为每一名义变量下限的正态曲线高度,为每一名义变量下限的正态曲线高度,为每一名义变量下限的正态曲线高度, y h y h y h 为每为每一名义变量上线的正态曲线高度,一名义变量上线的正态曲线高度,为每一名义变量对偶的连续变量的平均数,为每一名义变量对偶的连续变量的平均数, S t S t S t 为连续变量的标准差为连续变量的标准差为连续变量的标准差20 20 、总体为正态,、总体为正态,、总体为正态, σ 2 2 已知:已知:已知: 21 21 、总体为正态,、总体为正态,、总体为正态, σ 2 2 未知:未知:未知:22 22 、、23 23 、、24 24 、、。

算术函数ABS(numexpr) 数值。
返回numexpr(必须为数值)的绝对值。
ARSIN(numexpr) 数值。
返回numexpr 的反正弦(以弧度为单位),求出的值必须为-1 和+1 之间的数字值。
ARTAN(numexpr) 数值。
返回numexpr 的反正切(以弧度为单位),numexpr 必须为数字值。
COS(radians) 数值。
返回radians 的余弦(以弧度为单位),radians 必须为数字值。
EXP(numexpr) 数值。
返回e 的numexpr 次幂,其中e 是自然对数的底数,而numexpr 是数值。
较大的numexpr 值可能会产生超过机器性能的结果。
LN(numexpr) 数值。
返回以e 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
LNGAMMA(numexpr) 数值。
返回numexpr 的完全Gamma 函数的对数,numexpr 必须为大于0 的数值。
LG10(numexpr) 数值。
返回以10 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
MOD(numexpr,modulus) 数值。
返回numexpr 除以modulus 所得到的余数。
两个参数都必须为数值,且modulus 不得为0。
RND(numexpr) 数值。
返回对numexpr 舍入后产生的整数,numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去0 以后的数值。
SIN(radians) 数值。
返回radians 的正弦(以弧度为单位),radians 必须为数字值。
SQRT(numexpr) 数值。
返回numexpr 的正平方根,numexpr 必须为非负数。
TRUNC(numexpr) 数值。
返回numexpr 被截断为整数(向0 的方向)的值。
统计函数后缀.n 可在所有统计函数中使用以指定有效参数的数目。
例如,仅当至少两个变量含有效值时,MEAN.2(A,B,C,D) 对变量A、B、C 和D 返回其有效值的均值。

SPSS复习提纲基本操作读取数据读取文件data list file=’’fixed/free/{varname} {format}.读取数列data list/{varname} {format}.begin data{data list}end data.读取矩阵matrix data variable {varname}/file=’’/n={n}/contents=corr.数据编辑变量名变量名不超过8个字符, 名首必须是字母变量标签variable labels {varname} ’’.不能超过40个字符值标签value labels {varname} {value} ’’. 不能超过20个字符形式format {varname} (f{w.d}).缺失值missing values {varname} ().排序sort cases by {varname} (a/b).数据合并add files/file=*/file=’’/rename {old varname}={new varname}/drop {varname}.数据转换Computecompute {target varname}={expression}.算术运算:+,-,*,/,**(幂)算术函数:sqrt, rnd(四舍五入), trunc(取整)统计函数:mean, sum, sd, max, min缺失值函数:SYSMIS,MISSING,NMISS,NVALID,VALUE(不算缺失值)时间函数: CTIME.DAYS,$JDATEIfif () {target varname}={expression}.Recoderecode {varname} (old value/else/lowest through {value}/{value} through {value}/{value} through high=new value) into {newvarname}.Missing values:user-defined 也会被重编码,因此应小心user-defined. user-defined 不包括在范围内Split fileSort cases by {varname} .split filelayered by {varname} .split fileoff.Flipflip variables = {varname}/all.Rankrank variable = {varname}.数据分析描述性统计FrequenciesFrequencies {varname}/histogram NORMAL /barchart (freq/percent)/piechart.DescriptiveDescriptive {varname}/statistics=sum mean min max (集中趋势) RANGE stddev SEMEAN VARIANC (离中趋势) skewness(偏度) SESKEW KURTOSIS(峰度) SEKURT(形状测量)/{varname} (z{newvarname}).Exploreexamine {varname}/plot BOXPLOT STEAMLEAF HISTOGRAM(不带有正态曲线) NPPLOT(证明正态)/ STATISTICS DESCRIPTIVES EXTREME/MESTIMATORS(修正均值).CrosstabsCrosstabs/tables={row varname} BY {column varname}/Statistic=chisq(默认) corr KAPPA(评定者间一致性系数)PHI CC(修正)/CELLS= .相关分析Graphscatterplot={varname} with {varname}.Personcorrelations/variables={varlist}/ MISSING=PAIRWISE/LISTWISE(数据足够时更稳定).Spearman/kendall(顺序变量)nonpar corr/variables={varlist}/print=spearman(默认)/kendall(有重复)/both. 差异性检验单样本t检验t-test testval={value}/variables={varname}.独立样本t检验t-test groups={varname}(value1 value2)/variables={varname}.相关样本t检验t-test pairs={varname} with {varname}.曼-惠特尼U检验npar tests/ m-w={varname} with { value1 value2}.维克尔松检验npar test/ wilcoxon={varname} with {varname}.方差分析前提假设:独立、等距、正态、同质数据要求:多元正态,线性(散点图)Oneway anova(单一自变量平-单一因变量)oneway{varlist} by {varname}/statistics descriptives homogeneity/contrast {valuelist}/posthoc=LSD TURKEY(敏感)BONFERRONI Scheffe(保守) snk DUNNETT.Unianova(多个自变量-单一因变量)unianova{dependent varname} BY {factor varlist}/posthoc {varlist}=lsd snk turkey/plot=profile({varname/varname*varname})/desigh={factor varlist}.manova{dependent varname} BY {factor varlist}/DESIGN={FACNAME1} within {FACNAME2}(FACNUM1) {FACNAME1} within {FACNAME2}(FACNUM2)…Multivariate(多个自变量-多个因变量)glm{dependent varlist} BY {factor varlist}/desigh={factor varlist}/PRINT = HOMOGENEITY(同质性前提)/plot=profile({varname/varname*varname})/posthoc {varlist}=lsd snk turkeymanova{dependent varlist} BY {factor varlist}/DESIGN={FACNAME1} within {FACNAME2}(FACNUM1) {FACNAME1} within {FACNAME2}(FACNUM2)…REPEATED MEASURE(包含组内自变量-多个因变量)glm{wsfactor varlist} BY {factor varlist}/WSFACTORs {wsfacname} {wsfacnum}/wsdisigh {wsfaclist}/desigh={varlist}/emmeasn = tables(varname) compare adj(lsd)/plot=profile({varname/varname*varname/varname*wsfacname})manova{wsfactor varlist} BY {facname} (facnum)/WSFACTORS {wsfacname} (wsfacnum)/WSDESIGN ={WSFACNAME1} within {WSFACNAME2}(WSFACNUM1) {WSFACNAME1} within {WSFACNAME2}(WSFACNUM2)…/DESIGN={FACNAME1} within {FACNAME2}(FACNUM1) {FACNAME1} within {FACNAME2}(FACNUM2)…/WSDESIGN={WSFACNAME}/DESIGN=MWITHIN {FACNAME} (FACNUM1) MWITHIN {FACNAME} (FACNUM2) …/DESIGN={FACNAME}/WSDESIGN=MWITHIN {WSFACNAME} (WSFACNUM1) MWITHIN {WSFACNAME} (WSFACNUM2)….回归分析前提假设:等距/等比/(顺序)线性非共线性残差正态,同质,线性数据要求:cases : variables=10:1;被试数目> 100;无Outliers();无multicollinearityIGRAPH/VIEWNAME='Scatterplot'/X1 = VAR(before) TYPE = SCALE/Y = VAR(after) TYPE = SCALE/COORDINATE = VERTICAL/FITLINE METHOD = REGRESSION LINEAR LINE = TOTAL SPIKE=OFF/X1LENGTH=3.0/YLENGTH=3.0/X2LENGTH=3.0/CHARTLOOK='NONE'/SCATTER COINCIDENT = NONE.EXE.REGRESSION/DEPENDENT {DEPENDENT VARNAME}/METHOD=STEPWISE/ENTER {FACTOR VARLIST}/STATISTICS COEFF() OUTS R ANOVA COLLIN(检验multicollinearity)/CASEWISE(检验outlier) .聚类分析CLUSTER {VARLIST}/PRINT SCHEDULE CLUSTER(CLUNUM)/PLOT DENDRGRAM VICICLE主成分分析前提假设:多元正态线性等距(顺序)相关-数据要求:cases : variables=5:1;被试数目>200;正态不是必须,如果正态分布,解决会更好;线性:如果非线性,应考虑转换变量后再作因素分析;无Outliers;在主成分分析中,multicollinearity不是问题,在主因素分析中,不能有 multicollinearity相关矩阵FACTOR/MATRIX=IN(CORR=*)/method=correlation/format=sort blank(0.40)/ROTATION VARIMAX/PLOT=EIGEN rotation.一般主成分分析FACTOR/VARIABLES {VARLIST}/PLOT EIGEN ROTATION/ROTATION VARIMAX/METHOD=CORRELATION/PRINT KMO (相关和共线性检验).数据报告描述性统计FrequenciesDescriptive•报告Descriptives峭度为正表示总体分布的峰态较标准正态更陡; 反之更缓.斜度为正表示样本值比较集中于均值的左边; 斜度为负表示样本值比较集中于均值的右边Explore•报告Descriptives去掉5%的均值5% trimmed mean四分位距interquartile range•读Respondent’s Stem-and-Leaf Plot•读Respondent’s BoxplotOutlier:从矩形框始,在1.5 倍箱距的点之外Extreme:从矩形框始,在3倍箱距的点之外1.5 倍箱距的点之外的Outlier需要给予注意,如果是多于3个点位置很近,多数情况考虑保留。

随机函数:RV.BERNOULLI(prob)。
数值。
返回具有指定概率参数prob 的Bernoulli 分布中的随机值。
RV.BETA(shape1, shape2)。
数值。
返回具有指定形状参数的Beta 分布中的随机值。
RV.BINOM(n, prob)。
数值。
返回具有指定试验次数和概率参数的二项式分布中的随机值。
RV.CAUCHY(loc, scale)。
数值。
返回具有指定位置和刻度参数的Cauchy 分布中的随机值。
RV.CHISQ(df)。
数值。
返回具有指定自由度df 的卡方分布中的随机值。
RV.EXP(scale)。
数值。
返回具有指定刻度参数的指数分布中的随机值。
RV.F(df1, df2)。
数值。
返回具有指定自由度df1 和df2 的F 分布中的随机值。
RV.GAMMA(shape, scale)。
数值。
返回具有指定形状和刻度参数的Gamma 分布中的随机值。
RV.GEOM(prob)。
数值。
以指定的概率参数从几何分布中返回一个随机值。
RV.HALFNRM(mean, stddev)。
数值。
以指定的均值和标准差从半正态分布中返回一个随机值。
RV.HYPER(total, sample, hits)。
数值。
以指定的参数从超几何分布中返回一个随机值。
RV.IGAUSS(loc, scale)。
数值。
以指定的位置和刻度参数从逆高斯分布中返回一个随机值。
PLACE(mean, scale)。
数值。
返回具有指定均值和刻度参数的Laplace 分布中的随机值。
RV.LNORMAL(a, b)。
数值。
返回具有指定参数的对数正态分布中的随机值。
RV.LOGISTIC(mean, scale)。
数值。
返回具有指定均值和刻度参数的logistic 分布中的随机值。
RV.NEGBIN(threshold, prob)。
数值。
返回具有指定阈值和概率参数的负二项式分布中的随机值。
RV.NORMAL(mean, stddev)。

有数据处理、统计分析、参数和非参数检验以及时间序列分析。
方差分析等等
主要是统计方面的,具体的可以到论坛看看大家给出的一些实例的应用你就在知道了。
spss一般用于多元统计分析中,详细可以找一本spss的教程。
matlab 功能就强大了,基本上所有的问题都可以通过matlab工具箱实现。
一般可以解决:作图、拟合、统计分析、仿真、计算积分微分等数值计算和精确计算、固定算法详见matlab 书上(推荐一本很好的书《高等应用数学问题的matlab求解》)等等
SPSS是一种统计工具,可以将已有的数据进行整理、分析。
基本功能包括数据管理、统计分析、图表分析、输出管理等
matlab更偏向数据处理,科学计算用,它可以将大量数据用某种算法进行计算、分析等,快速的得到结果数据,当然也有一点画图功能。
matlab已经写好了很多的算法及方法,使用方便。
SPSS软件是用来统计数据的,可以通过这些数据来拟合方程,Matlab是用来编程的
统计图SPSS/Excel、函数图Matlab、流程示意图Visio、几何图用几何画板
建议SPSS,对于数据分析比较实用,而且软件使用起来比较简单,另外还有Excel,07版的数据存储量极大,建模需要计算时很方便。
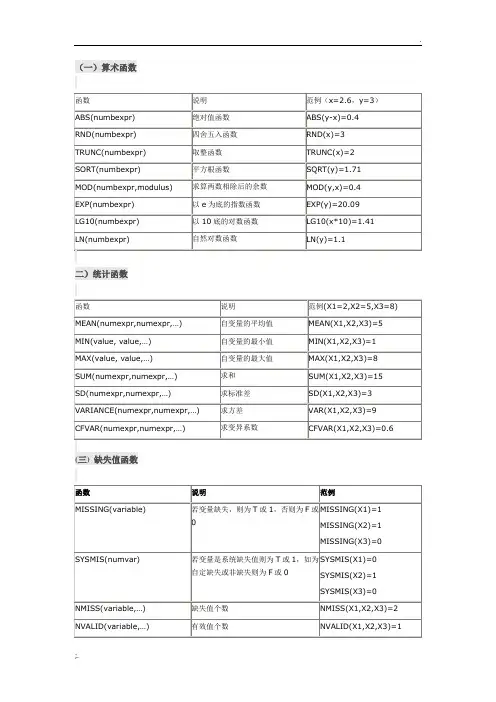
(一)算术函数
二)统计函数
注:X1为使用者界定缺失值,X2为系统缺失值,X3为非缺失值四)字符串型函数
五)时间日期函数
注:1 要正确显示以上函数值,必须先赋予其SPSS得日期型变量(DATA)格式,假设以上日期用mm/dd/yy格式显示,时间则用hh:mm:ss格式表示
2 1<=d<=31、1<=m<=12、1<=w<=52、1<=q<=4
六)其他函数
SPSS除了上述函数外,尚有日期和时间转换函数
(YOMODA\CTMIESDAYS\CTIMEHOURS\MDAYS等)、连续几率密度函数
(CDF\BINOM\CHISQ\CDF\EXP\LOGISTIC等),此外还有NORMAL(stddev)可产生平均数为0,标准差为stddev的正态分布随机数字。
UNIFORM(max)可产生平均数为0与max间呈均等分布的随机数字。
PS:还可以像EXCEL一样利用脚本编写自定义函数,目前SPSS支持python,Sax Basic(一种与VB兼容的编程语言)等语言,利用new--script可编写出自己需要的函数。
script界
面如下:。
SPSS Modeler常用函数简介SPSS Modeler软件包含多种功能丰富的函数,几乎涵盖了我们日常工作的各种需要,主要有信息函数、转换函数、比较函数、逻辑函数、数值函数、三角函数、概率函数、位元整数运算、随机函数、字符串函数、日期和时间函数、序列函数、全局函数、空值和Null 值处理函数、特殊函数等15大类,本讲义将逐一介绍并说明其注意事项。
在本讲义中涉及到的函数,具体的字段格式按照如下约定表示:此外,本讲义中的函数以函数、结果类型(整数、字符串等)和说明(如果有)各占一列的形式一一列举说明。
例如,对函数rem的说明如下。
1. 信息函数信息函数用于深入了解特定字段的值。
它们通常用于派生标志字段。
例如,可以使用@BLANK函数来创建一个标志字段,以指示选定字段的值为空值的记录。
同样,可以使用存储类型函数(如is_string)来检查某个字段的存储类型。
2. 转换函数转换函数可用来构建新字段和转换现有文件的存储类型。
例如,可通过将字符串连接在一起或分拆字符串来形成新字符串。
若要连接两个字符串,请使用运算符“><”。
例如,字段Site的值为"BRAMLEY",则"xx"><Site将返回"xxBRAMLEY"。
即使参数不是字符串,“><”的结果也始终是字符串,因此,如果字段V1为3,字段V2为5,则V1><V2将返回"35"(字符串而非数值)。
请注意,转换函数及其他要求特定类型输入(如日期或时间值)的函数取决于“流选项”对话框中指定的当前格式。
例如,要将值为Jan2003、Feb2003等的字符串字段转换为日期存储格式,请选择MONYYYY作为流的默认日期格式。
3. 比较函数比较函数用于字段值的相互比较或与指定字符串进行比较。
例如,可以使用“=”来检查字符串是否相等。
算术函数ABS(numexpr) 数值。
返回numexpr(必须为数值)的绝对值。
ARSIN(numexpr) 数值。
返回numexpr 的反正弦(以弧度为单位),求出的值必须为-1 和+1 之间的数字值。
ARTAN(numexpr) 数值。
返回numexpr 的反正切(以弧度为单位),numexpr 必须为数字值。
COS(radians) 数值。
返回radians 的余弦(以弧度为单位),radians 必须为数字值。
EXP(numexpr) 数值。
返回e 的numexpr 次幂,其中e 是自然对数的底数,而numexpr 是数值。
较大的numexpr 值可能会产生超过机器性能的结果。
LN(numexpr) 数值。
返回以e 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
LNGAMMA(numexpr) 数值。
返回numexpr 的完全Gamma 函数的对数,numexpr 必须为大于0 的数值。
LG10(numexpr) 数值。
返回以10 为底数的numexpr 的对数,numexpr 必须为大于0 的数值。
MOD(numexpr,modulus) 数值。
返回numexpr 除以modulus 所得到的余数。
两个参数都必须为数值,且modulus 不得为0。
RND(numexpr) 数值。
返回对numexpr 舍入后产生的整数,numexpr 必须为数值。
刚好以 .5 结尾的数值将舍去0 以后的数值。
SIN(radians) 数值。
返回radians 的正弦(以弧度为单位),radians 必须为数字值。
SQRT(numexpr) 数值。
返回numexpr 的正平方根,numexpr 必须为非负数。
TRUNC(numexpr) 数值。
返回numexpr 被截断为整数(向0 的方向)的值。
统计函数后缀.n 可在所有统计函数中使用以指定有效参数的数目。
例如,仅当至少两个变量含有效值时,MEAN.2(A,B,C,D) 对变量A、B、C 和D 返回其有效值的均值。
SD、V ARIANCE 和CFV AR 的缺省n 值为2,其他统计函数为1。
CFV AR(numexpr,numexpr[,...])数值。
返回其具有有效值的参数的方差系数(标准差除以均值)。
此函数需要两个或更多参数,这些参数必须为数值。
您可以指定有效参数的最小数目,以对此函数求值。
LAG(variable) 数值或字符串。
返回数据文件中前一个个案的变量值。
为第一个个案返回系统缺失值(数值变量)或空白(字符串变量)。
LAG(variable,ncases) 数值或字符串。
返回文件中前n 个个案的变量值。
为前n 个个案返回系统缺失值(数值变量)或空白(字符串变量)。
注意:在一系列的转换命令(无干预EXECUTE 命令或是其他读取数据的命令)中,延迟函数将在所有其他转换后计算,而无论命令顺序如何。
MAX(value,value[,...])数值或字符串。
返回其具有有效值的参数的最大值。
此函数需要两个或更多参数。
您可以指定有效参数的最小数目,以对此函数求值。
MEAN(numexpr,numexpr[,...])数值。
返回其具有有效值的参数的算术均值。
此函数需要两个或更多参数,这些参数必须为数值。
您可以指定有效参数的最小数目,以对此函数求值。
MIN(value,value[,...])数值或字符串。
返回其具有有效值的参数的最小值。
此函数需要两个或更多参数。
您可以指定有效参数的最小数目,以对此函数求值。
NV ALID(variable[,...])数值。
返回具有有效的非缺失值的参数的计数。
此函数需要一个或多个参数,这些参数应为工作数据文件中的变量名称。
SD(numexpr,numexpr[,...])数值。
返回其具有有效值的参数的标准差。
此函数需要两个或更多参数,这些参数必须为数值。
您可以指定有效参数的最小数目,以对此函数求值。
SUM(numexpr,numexpr[,...])数值。
返回其具有有效值的参数的和。
此函数需要两个或更多参数,这些参数必须为数值。
您可以指定有效参数的最小数目,以对此函数求值。
V ARIANCE(numexpr,numexpr[,...])数值。
返回其具有有效值的参数的方差。
此函数需要两个或更多参数,这些参数必须为数值。
您可以指定有效参数的最小数目,以对此函数求值。
字符串函数CONCA T(strexpr,strexpr[,...])字符串。
返回由其全部参数拼接而成的字符串,对其求出的值必须为字符串。
此函数需要两个或更多参数。
INDEX(haystack,needle) 数值。
返回一个整数,指示字符串needle 第一次出现在字符串haystack 中的起始位置。
如果needle 未出现在haystack 中,则返回0。
INDEX(haystack,needle,divisor) 数值。
请参阅前述函数。
可选的第三个参数divisor 是用于将needle 划分为各个单独字符串以便搜索的字符数。
它必须是一个可平均划分needle 长度的整数。
LOWER(strexpr) 字符串。
返回大写字母都更改为小写字母而其他字符不变的strexpr。
LPAD(strexpr,length) 字符串。
返回为了延伸到length 给定的长度而用空格填充左侧的字符串strexpr,length 必须为1 到255 之间的正整数。
LPAD(strexpr,length,char) 字符串。
与带两个参数的LPAD 相同,但用char 填充strexpr 的左侧。
可选的第三个参数char 是包含在一对单引号中的单个字符,或是某个产生单个字符的字符串表达式。
LTRIM(strexpr) 字符串。
返回删除了所有前导空格的字符串strexpr。
LTRIM(strexpr,char) 字符串。
与带一个参数的LTRIM 相同,但删除char 的前导实例。
可选的第二个参数char 是包含在一对单引号中的单个字符,或是某个产生单个字符的字符串表达式。
LENGTH(strexpr) 数值。
返回strexpr 的长度,strexpr 必须是一个字符串表达式。
这是定义的长度,包括尾部的空格。
要获取不带尾部空格时的长度,请使用LENGTH(RTRIM(strexpr))。
RINDEX(haystack,needle) 数值。
返回一个整数,指示字符串needle 最后一次出现在字符串haystack 中的起始位置。
如果needle 未出现在haystack 中,则返回0。
RINDEX(haystack,needle,divisor) 数值。
请参阅前述函数。
可选的第三个参数divisor 是用于将needle 划分为各个单独字符串以便搜索的字符数。
它必须是一个可平均划分needle 长度的整数。
RPAD(strexpr,length) 字符串。
返回为延伸到length 给定的长度而用空格填充右侧的字符串strexpr,length 必须为1 到255 之间的正整数。
RPAD(strexpr,length,char) 字符串。
与带有两个参数的RPAD 相同,但用char 填充strexpr 的右侧。
可选的第三个参数char 是包含在一对单引号中的单个字符,或是某个产生单个字符的表达式。
RTRIM(strexpr) 字符串。
返回删除了所有尾部空格的字符串strexpr。
此函数通常用于较大的表达式中,这是因为在将字符串分配给变量时用尾部空格填充了该字符串。
RTRIM(strexpr,char) 字符串。
与带有一个参数的RTRIM 相同,但删除char 的尾部实例。
可选的第二个参数char 是包含在一对单引号中的单个字符,或是某个产生单个字符的表达式。
SUBSTR(strexpr,pos) 字符串。
返回strexpr 中从位置pos 开始一直到结尾的子字符串。
SUBSTR(strexpr,pos,length) 字符串。
返回strexpr 中从位置pos 开始、长度为length 的子字符串。
UPCAS(strexpr) 字符串。
返回小写字母都更改为大写字母而其他字符不变的strexpr。
日期和时间函数CTIME.DAYS(timevalue) 数值。
返回timevalue 中的天数(包括有小数位的天数),timevalue 必须为时间格式的数值或表达式,如TIME.xxx 函数的结果。
CTIME.HOURS(timevalue) 数值。
返回timevalue 中的小时数(包括有小数位的小时数),timevalue 必须为时间格式(TIME.xxx 函数之一所创建的或以TIME 输入格式读取的格式)的数值或表达式。
CTIME.MINUTES(timevalue) 数值。
返回timevalue 中的分钟数(包括有小数位的分钟数),timevalue 必须为时间格式(TIME.xxx 函数之一所创建的或以TIME 输入格式所读取的格式)的数字或表达式。
CTIME.SECONDS(timevalue) 数值。
返回timevalue 中的秒数(包括有小数位的秒数),timevalue 必须为时间格式(TIME.xxx 函数之一所创建的或以TIME 输入格式所读取的格式)的数字或表达式。
DA TE.DMY(day,month,year) 日期格式的数值。
返回一个对应于所指示的day、month 和year 的日期值。
要正确显示此值,可为其指定DATE 格式。
参数都必须为整数,day 在1 和31 之间,month 在1 和13 之间,year 为一个大于1582 的四位数整数。
DA TE.MDY(month,day,year) 日期格式的数值。
返回一个对应于所指示的month、day 和year 的日期值。
要正确显示此值,可为其指定DA TE 格式。
参数则同前述函数。
DA TE.MOYR(month,year) 日期格式的数值。
返回一个对应于所指示的month 和year 的日期值。
要正确显示此值,可为其指定DA TE 格式。
参数都必须为整数,month 在 1 和13 之间,year 为一个大于1582 的四位数整数。
DA TE.QYR(quarter,year) 日期格式的数值。
返回一个对应于所指示的quarter 和year 的日期值。
要正确显示此值,可为其指定DATE 格式。
参数都必须为整数,quarter 在 1 和 4 之间,year 为一个大于1582 的四位数整数。
DA TE.WKYR(weeknum,year) 日期格式的数值。
返回一个对应于所指示的weeknum 和year 的日期值。
要正确显示此值,可为其指定DATE 格式。