spss回归分析大全
- 格式:ppt
- 大小:7.97 MB
- 文档页数:2

SPSS—回归—多元线性回归结果分析(二),最近一直很忙,公司的潮起潮落,就好比人生的跌岩起伏,眼看着一步步走向衰弱,却无能为力,也许要学习“步步惊心”里面“四阿哥”的座右铭:“行到水穷处”,”坐看云起时“。
接着上一期的“多元线性回归解析”里面的内容,上一次,没有写结果分析,这次补上,结果分析如下所示:结果分析1:由于开始选择的是“逐步”法,逐步法是“向前”和“向后”的结合体,从结果可以看出,最先进入“线性回归模型”的是“price in thousands"建立了模型1,紧随其后的是“Wheelbase"建立了模型2,所以,模型中有此方法有个概率值,当小于等于0.05时,进入“线性回归模型”(最先进入模型的,相关性最强,关系最为密切)当大于等0.1时,从“线性模型中”剔除结果分析:1:从“模型汇总”中可以看出,有两个模型,(模型1和模型2)从R2 拟合优度来看,模型2的拟合优度明显比模型1要好一些(0.422>0.300)2:从“Anova"表中,可以看出“模型2”中的“回归平方和”为115.311,“残差平方和”为153.072,由于总平方和=回归平方和+残差平方和,由于残差平方和(即指随即误差,不可解释的误差)由于“回归平方和”跟“残差平方和”几乎接近,所有,此线性回归模型只解释了总平方和的一半,3:根据后面的“F统计量”的概率值为0.00,由于0.00<0.01,随着“自变量”的引入,其显著性概率值均远小于0.01,所以可以显著地拒绝总体回归系数为0的原假设,通过ANOVA方差分析表可以看出“销售量”与“价格”和“轴距”之间存在着线性关系,至于线性关系的强弱,需要进一步进行分析。
结果分析:1:从“已排除的变量”表中,可以看出:“模型2”中各变量的T检的概率值都大于“0.05”所以,不能够引入“线性回归模型”必须剔除。
从“系数a” 表中可以看出:1:多元线性回归方程应该为:销售量=-1.822-0.055*价格+0.061*轴距但是,由于常数项的sig为(0.116>0.1) 所以常数项不具备显著性,所以,我们再看后面的“标准系数”,在标准系数一列中,可以看到“常数项”没有数值,已经被剔除所以:标准化的回归方程为:销售量=-0.59*价格+0.356*轴距2:再看最后一列“共线性统计量”,其中“价格”和“轴距”两个容差和“vif都一样,而且VIF 都为1.012,且都小于5,所以两个自变量之间没有出现共线性,容忍度和膨胀因子是互为倒数关系,容忍度越小,膨胀因子越大,发生共线性的可能性也越大从“共线性诊断”表中可以看出:1:共线性诊断采用的是“特征值”的方式,特征值主要用来刻画自变量的方差,诊断自变量间是否存在较强多重共线性的另一种方法是利用主成分分析法,基本思想是:如果自变量间确实存在较强的相关关系,那么它们之间必然存在信息重叠,于是就可以从这些自变量中提取出既能反应自变量信息(方差),而且有相互独立的因素(成分)来,该方法主要从自变量间的相关系数矩阵出发,计算相关系数矩阵的特征值,得到相应的若干成分。
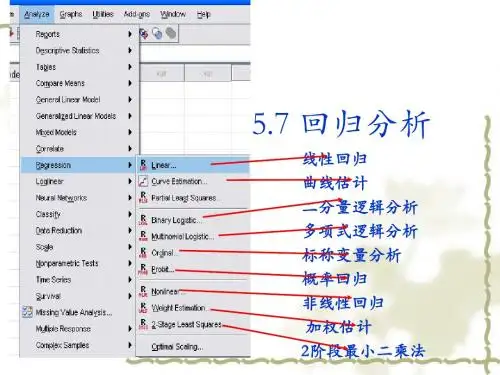



多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
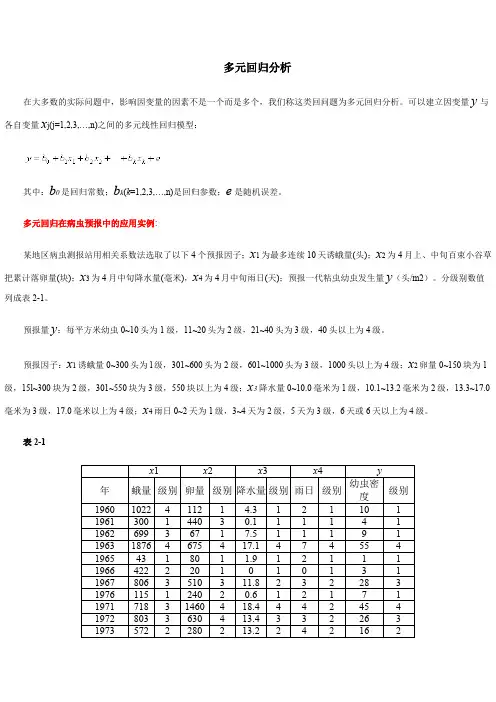
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960102241121 4.3121101 1961300144030.111141 196269936717.511191 196318764675417.1474554 1965431801 1.912111 19664222201010131 19678063510311.8232283 1976115124020.612171 197171831460418.4442454 19728033630413.4332263 19735722280213.224216219742641330342.243219219751981165271.84532331976461214017.515328319777693640444.7432444197825516510101112数据保存在“DATA6-5.SAV”文件中。

回归分析例题SPSS求解过程(一)1、一元线性回归SPSS求解过程:判别:xy202.0173.2ˆˆˆ1+=+=ββ,且x与y的线性相关系数为R=0.951,回归方程的F检验值为75.559,对应F值的显著性概率是0.000<0.05,表示线性回归方程具有显著性,当对应F值的显著性概率>0.05,表示回归方程不具有显著性。
每个系数的t检验值分别是3.017与8.692,对应的检验显著性概率分别为:0.017(<0.05)和0.000(<0.05),即否定0H,也就是线性假设是显著的。
二、一元非线性回归SPSS求解过程:1、Y与X的二次及三次多项式拟合:所以,二次式为:2029.07408.00927.6xxY-+=三次式为:320046.01534.07068.1118.4xxxY+-+=2、把Y与X的关系用双曲线拟合:作双曲线变换:xVyU1,1==判别:V U 131.0082.0-=,x V y U 1,1==,V 与U 的相关系数为R=0.968,回归方程系数的F 检验值为196.227,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是440514与14.008,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。
3、把Y 与X 的关系用倒指数函数拟合:x bae Y =,则x b a Y 1ln ln +=令U1=LN (Y ),V1=V=1/x,有 U1=c+bV1.判别:V U 111.1458.21-=,x V y U /1,ln 1==,V 与1U 的相关系数为R=0.979,回归方程的F 检验值为303.190,对应F 值的显著性概率是0.000(<0.05),表示线性回归方程具有显著性 ,每个系数的t 检验值分别是195.221与-17.412,对应的检验显著性概率分别为:0.000(<0.05)和0.000(<0.05),即否定0H ,也就是线性假设是显著的。


27. 回归分析回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。
主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。
其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。
它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:(1)获取自变量和因变量的观测值;(2)绘制散点图,并对异常数据做修正;(3)写出带未知参数的回归方程;(4)确定回归方程中参数值;(5)假设检验,判断回归方程的拟合优度;(6)进行解释、控制、或预测。
(一)一元线性回归一、基本原理一元线性回归模型:Y=0+1X+ε其中 X 是自变量,Y 是因变量, 0, 1是待求的未知参数, 0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:① ε的均值为0; ② ε的方差为 2;③ 协方差COV(εi , εj )=0,当i≠j 时。
即对所有的i≠j, εi 与εj 互不相关。
二、用最小二乘法原理,得到最佳拟合效果的01ˆˆ,ββ值: 1121()()ˆ()niii nii x x yy x x β==--=-∑∑, 01ˆˆy x ββ=- 三、假设检验1. 拟合优度检验计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。
通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
2. 回归方程参数的检验回归方程反应了因变量Y 随自变量X 变化而变化的规律,若 1=0,则Y 不随X 变化,此时回归方程无意义。
所以,要做如下假设检验:H 0: 1=0, H 1: 1≠0; (1) F 检验若 1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是 2的无偏估计,因而采用F 统计量:来检验原假设β1=0是否为真。
