最新SPSS-回归分析
- 格式:ppt
- 大小:684.50 KB
- 文档页数:22

SPSS—回归—多元线性回归结果分析(二),最近一直很忙,公司的潮起潮落,就好比人生的跌岩起伏,眼看着一步步走向衰弱,却无能为力,也许要学习“步步惊心”里面“四阿哥”的座右铭:“行到水穷处”,”坐看云起时“。
接着上一期的“多元线性回归解析”里面的内容,上一次,没有写结果分析,这次补上,结果分析如下所示:结果分析1:由于开始选择的是“逐步”法,逐步法是“向前”和“向后”的结合体,从结果可以看出,最先进入“线性回归模型”的是“price in thousands"建立了模型1,紧随其后的是“Wheelbase"建立了模型2,所以,模型中有此方法有个概率值,当小于等于0.05时,进入“线性回归模型”(最先进入模型的,相关性最强,关系最为密切)当大于等0.1时,从“线性模型中”剔除结果分析:1:从“模型汇总”中可以看出,有两个模型,(模型1和模型2)从R2 拟合优度来看,模型2的拟合优度明显比模型1要好一些(0.422>0.300)2:从“Anova"表中,可以看出“模型2”中的“回归平方和”为115.311,“残差平方和”为153.072,由于总平方和=回归平方和+残差平方和,由于残差平方和(即指随即误差,不可解释的误差)由于“回归平方和”跟“残差平方和”几乎接近,所有,此线性回归模型只解释了总平方和的一半,3:根据后面的“F统计量”的概率值为0.00,由于0.00<0.01,随着“自变量”的引入,其显著性概率值均远小于0.01,所以可以显著地拒绝总体回归系数为0的原假设,通过ANOVA方差分析表可以看出“销售量”与“价格”和“轴距”之间存在着线性关系,至于线性关系的强弱,需要进一步进行分析。
结果分析:1:从“已排除的变量”表中,可以看出:“模型2”中各变量的T检的概率值都大于“0.05”所以,不能够引入“线性回归模型”必须剔除。
从“系数a” 表中可以看出:1:多元线性回归方程应该为:销售量=-1.822-0.055*价格+0.061*轴距但是,由于常数项的sig为(0.116>0.1) 所以常数项不具备显著性,所以,我们再看后面的“标准系数”,在标准系数一列中,可以看到“常数项”没有数值,已经被剔除所以:标准化的回归方程为:销售量=-0.59*价格+0.356*轴距2:再看最后一列“共线性统计量”,其中“价格”和“轴距”两个容差和“vif都一样,而且VIF 都为1.012,且都小于5,所以两个自变量之间没有出现共线性,容忍度和膨胀因子是互为倒数关系,容忍度越小,膨胀因子越大,发生共线性的可能性也越大从“共线性诊断”表中可以看出:1:共线性诊断采用的是“特征值”的方式,特征值主要用来刻画自变量的方差,诊断自变量间是否存在较强多重共线性的另一种方法是利用主成分分析法,基本思想是:如果自变量间确实存在较强的相关关系,那么它们之间必然存在信息重叠,于是就可以从这些自变量中提取出既能反应自变量信息(方差),而且有相互独立的因素(成分)来,该方法主要从自变量间的相关系数矩阵出发,计算相关系数矩阵的特征值,得到相应的若干成分。

简单易懂的SPSS回归分析基础教程章节一:SPSS回归分析基础概述SPSS(Statistical Package for the Social Sciences,社会科学统计软件包)回归分析是一种常用的统计方法,用于研究自变量对因变量的影响程度以及变量之间的关系。
本章将介绍SPSS回归分析的基本概念和目的,以及相关的统计指标。
SPSS回归分析的目的是建立一个数学模型,描述自变量与因变量之间的关系。
通过这个模型,我们可以预测因变量的变化,以及各个自变量对因变量的贡献程度。
回归分析包括简单回归分析和多元回归分析,本教程主要讲解简单回归分析。
在SPSS回归分析中,我们需要了解一些统计指标。
其中,相关系数(correlation coefficient)用于衡量自变量与因变量之间的线性关系强度。
回归系数(regression coefficient)描述自变量对因变量的影响程度,可用于建立回归方程。
残差(residual)表示实际观测值与回归模型预测值之间的差异。
下面我们将详细介绍SPSS回归分析的步骤。
章节二:数据准备和导入在进行SPSS回归分析之前,我们需要准备好数据集,并将数据导入SPSS软件。
首先,我们需要确定因变量和自变量的测量水平。
因变量可以是连续型数据,如身高、体重等,也可以是分类数据,如满意度水平等。
自变量可以是任何与因变量相关的变量,包括连续型、分类型或二元变量。
其次,我们需要收集足够的样本量,以获取准确和可靠的结果。
在选择样本时,应该遵循随机抽样的原则,以保证样本的代表性。
最后,我们将数据导入SPSS软件。
通过依次点击“File”、“Open”、“Data”,选择数据文件,并设置变量类型、名称和标签等信息。
完成数据导入后,我们就可以开始进行回归分析了。
章节三:简单回归分析步骤简单回归分析是一种研究一个自变量与一个因变量之间关系的方法。
下面将介绍简单回归分析的步骤。
第一步,我们需要确定自变量和因变量。

SPSS回归分析SPSS(统计包统计软件,Statistical Package for the Social Sciences)是一种强大的统计分析软件,广泛应用于各个领域的数据分析。
在SPSS中,回归分析是最常用的方法之一,用于研究和预测变量之间的关系。
接下来,我将详细介绍SPSS回归分析的步骤和意义。
一、回归分析的定义和意义回归分析是一种对于因变量和自变量之间关系的统计方法,通过建立一个回归方程,可以对未来的数据进行预测和预估。
在实际应用中,回归分析广泛应用于经济学、社会科学、医学、市场营销等领域,帮助研究人员发现变量之间的关联、预测和解释未来的趋势。
二、SPSS回归分析的步骤1. 导入数据:首先,需要将需要进行回归分析的数据导入SPSS软件中。
数据可以以Excel、CSV等格式准备好,然后使用SPSS的数据导入功能将数据导入软件。
2. 变量选择:选择需要作为自变量和因变量的变量。
自变量是被用来预测或解释因变量的变量,而因变量是我们希望研究或预测的变量。
可以通过点击"Variable View"选项卡来定义变量的属性。
3. 回归分析:选择菜单栏中的"Analyze" -> "Regression" -> "Linear"。
然后将因变量和自变量添加到正确的框中。
4.回归模型选择:选择回归方法和模型。
SPSS提供了多种回归方法,通常使用最小二乘法进行回归分析。
然后,选择要放入回归模型的自变量。
可以进行逐步回归或者全模型回归。
6.残差分析:通过检查残差(因变量和回归方程预测值之间的差异)来评估回归模型的拟合程度。
可以使用SPSS的统计模块来生成残差,并进行残差分析。
7.结果解释:最后,对回归结果进行解释,并提出对于研究问题的结论。
要注意的是,回归分析只能描述变量之间的关系,不能说明因果关系。
因此,在解释回归结果时要慎重。

SPSS多元线性回归分析实例操作步骤在数据分析领域,多元线性回归分析是一种强大且常用的工具,它能够帮助我们理解多个自变量与一个因变量之间的线性关系。
接下来,我将为您详细介绍使用 SPSS 进行多元线性回归分析的具体操作步骤。
首先,准备好您的数据。
数据应该以特定的格式整理,通常包括自变量和因变量的列。
确保数据的准确性和完整性,因为这将直接影响分析结果的可靠性。
打开 SPSS 软件,在菜单栏中选择“文件”,然后点击“打开”,找到您存放数据的文件并导入。
在导入数据后,点击“分析”菜单,选择“回归”,再点击“线性”。
这将打开多元线性回归的对话框。
在“线性回归”对话框中,将您的因变量拖放到“因变量”框中,将自变量拖放到“自变量”框中。
接下来,点击“统计”按钮。
在“统计”对话框中,您可以选择一些常用的统计量。
例如,勾选“估计”可以得到回归系数的估计值;勾选“置信区间”可以得到回归系数的置信区间;勾选“模型拟合度”可以评估模型的拟合效果等。
根据您的具体需求选择合适的统计量,然后点击“继续”。
再点击“图”按钮。
在这里,您可以选择生成一些有助于直观理解回归结果的图形。
比如,勾选“正态概率图”可以检查残差的正态性;勾选“残差图”可以观察残差的分布情况等。
选择完毕后点击“继续”。
然后点击“保存”按钮。
您可以选择保存预测值、残差等变量,以便后续进一步分析。
完成上述设置后,点击“确定”按钮,SPSS 将开始进行多元线性回归分析,并输出结果。
结果通常包括多个部分。
首先是模型摘要,它提供了一些关于模型拟合度的指标,如 R 方、调整 R 方等。
R 方表示自变量能够解释因变量变异的比例,越接近 1 说明模型拟合效果越好。
其次是方差分析表,用于检验整个回归模型是否显著。
如果对应的p 值小于给定的显著性水平(通常为 005),则说明模型是显著的。
最重要的是系数表,它给出了每个自变量的回归系数、标准误差、t 值和 p 值。
回归系数表示自变量对因变量的影响程度,p 值用于判断该系数是否显著不为 0。


如何使用统计软件SPSS进行回归分析如何使用统计软件SPSS进行回归分析引言:回归分析是一种广泛应用于统计学和数据分析领域的方法,用于研究变量之间的关系和预测未来的趋势。
SPSS作为一款功能强大的统计软件,在进行回归分析方面提供了很多便捷的工具和功能。
本文将介绍如何使用SPSS进行回归分析,包括数据准备、模型建立和结果解释等方面的内容。
一、数据准备在进行回归分析前,首先需要准备好需要分析的数据。
将数据保存为SPSS支持的格式(.sav),然后打开SPSS软件。
1. 导入数据:在SPSS软件中选择“文件”-“导入”-“数据”命令,找到数据文件并选择打开。
此时数据文件将被导入到SPSS的数据编辑器中。
2. 数据清洗:在进行回归分析之前,需要对数据进行清洗,包括处理缺失值、异常值和离群值等。
可以使用SPSS中的“转换”-“计算变量”功能来对数据进行处理。
3. 变量选择:根据回归分析的目的,选择合适的自变量和因变量。
可以使用SPSS的“变量视图”或“数据视图”来查看和选择变量。
二、模型建立在进行回归分析时,需要建立合适的模型来描述变量之间的关系。
1. 确定回归模型类型:根据研究目的和数据类型,选择适合的回归模型,如线性回归、多项式回归、对数回归等。
2. 自变量的选择:根据自变量与因变量的相关性和理论基础,选择合适的自变量。
可以使用SPSS的“逐步回归”功能来进行自动选择变量。
3. 建立回归模型:在SPSS软件中选择“回归”-“线性”命令,然后将因变量和自变量添加到相应的框中。
点击“确定”即可建立回归模型。
三、结果解释在进行回归分析后,需要对结果进行解释和验证。
1. 检验模型拟合度:可以使用SPSS的“模型拟合度”命令来检验模型的拟合度,包括R方值、调整R方值和显著性水平等指标。
2. 检验回归系数:回归系数表示自变量对因变量的影响程度。
通过检验回归系数的显著性,可以判断自变量是否对因变量有统计上显著的影响。

相关分析和回归分析SPSS实现SPSS(统计包统计分析软件)是一种广泛使用的数据分析工具,在相关分析和回归分析方面具有强大的功能。
本文将介绍如何使用SPSS进行相关分析和回归分析。
相关分析(Correlation Analysis)用于探索两个或多个变量之间的关系。
在SPSS中,可以通过如下步骤进行相关分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“相关”子菜单。
3.在“相关”对话框中,选择将要分析的变量,然后单击“箭头”将其添加到“变量”框中。
4.选择相关系数的计算方法(如皮尔逊相关系数、斯皮尔曼等级相关系数)。
5.单击“确定”按钮,SPSS将计算相关系数并将结果显示在输出窗口中。
回归分析(Regression Analysis)用于建立一个预测模型,来预测因变量在自变量影响下的变化。
在SPSS中,可以通过如下步骤进行回归分析:1.打开SPSS软件并导入数据集。
2.选择“分析”菜单,然后选择“回归”子菜单。
3.在“回归”对话框中,选择要分析的因变量和自变量,然后单击“箭头”将其添加到“因变量”和“自变量”框中。
4.选择回归模型的方法(如线性回归、多项式回归等)。
5.单击“统计”按钮,选择要计算的统计量(如参数估计、拟合优度等)。
6.单击“确定”按钮,SPSS将计算回归模型并将结果显示在输出窗口中。
在分析结果中,相关分析会显示相关系数的数值和统计显著性水平,以评估变量之间的关系强度和统计显著性。
回归分析会显示回归系数的数值和显著性水平,以评估自变量对因变量的影响。
值得注意的是,相关分析和回归分析在使用前需要考虑数据的要求和前提条件。
例如,相关分析要求变量间的关系是线性的,回归分析要求自变量与因变量之间存在一定的关联关系。
总结起来,SPSS提供了强大的功能和工具,便于进行相关分析和回归分析。
通过上述步骤,用户可以轻松地完成数据分析和结果呈现。
然而,分析结果的解释和应用需要结合具体的研究背景和目的进行综合考虑。

SPSS-回归分析回归分析(⼀元线性回归分析、多元线性回归分析、⾮线性回归分析、曲线估计、时间序列的曲线估计、含虚拟⾃变量的回归分析以及逻辑回归分析)回归分析中,⼀般⾸先绘制⾃变量和因变量间的散点图,然后通过数据在散点图中的分布特点选择所要进⾏回归分析的类型,是使⽤线性回归分析还是某种⾮线性的回归分析。
回归分析与相关分析对⽐:在回归分析中,变量y称为因变量,处于被解释的特殊地位;;⽽在相关分析中,变量y与变量x处于平等的地位。
在回归分析中,因变量y是随机变量,⾃变量x可以是随机变量,也可以是⾮随机的确定变量;⽽在相关分析中,变量x和变量y都是随机变量。
相关分析是测定变量之间的关系密切程度,所使⽤的⼯具是相关系数;⽽回归分析则是侧重于考察变量之间的数量变化规律。
统计检验概念:为了确定从样本(sample)统计结果推论⾄总体时所犯错的概率。
F值和t值就是这些统计检定值,与它们相对应的概率分布,就是F分布和t分布。
统计显著性(sig)就是出现⽬前样本这结果的机率。
标准差表⽰数据的离散程度,标准误表⽰抽样误差的⼤⼩。
统计检验的分类:拟合优度检验:检验样本数据聚集在样本回归直线周围的密集程度,从⽽判断回归⽅程对样本数据的代表程度。
回归⽅程的拟合优度检验⼀般⽤判定系数R2实现。
回归⽅程的显著性检验(F检验):是对因变量与所有⾃变量之间的线性关系是否显著的⼀种假设检验。
回归⽅程的显著性检验⼀般采⽤F 检验。
回归系数的显著性检验(t检验): 根据样本估计的结果对总体回归系数的有关假设进⾏检验。
1.⼀元线性回归分析定义:在排除其他影响因素或假定其他影响因素确定的条件下,分析某⼀个因素(⾃变量)是如何影响另⼀事物(因变量)的过程。
SPSS操作2.多元线性回归分析定义:研究在线性相关条件下,两个或两个以上⾃变量对⼀个因变量的数量变化关系。
表现这⼀数量关系的数学公式,称为多元线性回归模型。
SPSS操作3.⾮线性回归分析定义:研究在⾮线性相关条件下,⾃变量对因变量的数量变化关系⾮线性回归问题⼤多数可以化为线性回归问题来求解,也就是通过对⾮线性回归模型进⾏适当的变量变换,使其化为线性模型来求解。

SPSS的线性回归分析分析SPSS是一款广泛用于统计分析的软件,其中包括了许多功能强大的工具。
其中之一就是线性回归分析,它是一种常用的统计方法,用于研究一个或多个自变量对一个因变量的影响程度和方向。
线性回归分析是一种用于解释因变量与自变量之间关系的统计技术。
它主要基于最小二乘法来评估自变量与因变量之间的关系,并估计出最合适的回归系数。
在SPSS中,线性回归分析可以通过几个简单的步骤来完成。
首先,需要加载数据集。
可以选择已有的数据集,也可以导入新的数据。
在SPSS的数据视图中,可以看到所有变量的列表。
接下来,选择“回归”选项。
在“分析”菜单下,选择“回归”子菜单中的“线性”。
在弹出的对话框中,将因变量拖放到“因变量”框中。
然后,将自变量拖放到“独立变量”框中。
可以选择一个或多个自变量。
在“统计”选项中,可以选择输出哪些统计结果。
常见的选项包括回归系数、R方、调整R方、标准误差等。
在“图形”选项中,可以选择是否绘制残差图、分布图等。
点击“确定”后,SPSS将生成线性回归分析的结果。
线性回归结果包括多个重要指标,其中最重要的是回归系数和R方。
回归系数用于衡量自变量对因变量的影响程度和方向,其值表示每个自变量单位变化对因变量的估计影响量。
R方则反映了自变量对因变量变异的解释程度,其值介于0和1之间,越接近1表示自变量对因变量的解释程度越高。
除了回归系数和R方外,还有其他一些统计指标可以用于判断模型质量。
例如,标准误差可以用来衡量回归方程的精确度。
调整R方可以解决R方对自变量数量的偏向问题。
此外,SPSS还提供了多种工具来检验回归方程的显著性。
例如,可以通过F检验来判断整个回归方程是否显著。
此外,还可以使用t检验来判断每个自变量的回归系数是否显著。
在进行线性回归分析时,还需要注意一些统计前提条件。
例如,线性回归要求因变量与自变量之间的关系是线性的。
此外,还需要注意是否存在多重共线性,即自变量之间存在高度相关性。
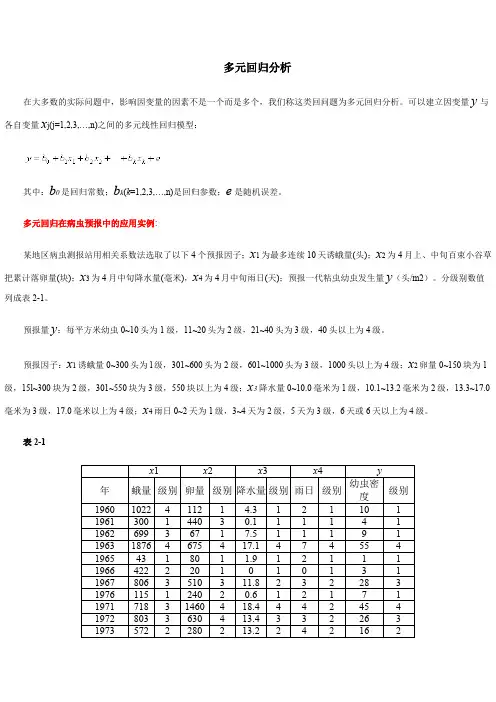
多元回归分析在大多数的实际问题中,影响因变量的因素不是一个而是多个,我们称这类回问题为多元回归分析。
可以建立因变量y与各自变量x j(j=1,2,3,…,n)之间的多元线性回归模型:其中:b0是回归常数;b k(k=1,2,3,…,n)是回归参数;e是随机误差。
多元回归在病虫预报中的应用实例:某地区病虫测报站用相关系数法选取了以下4个预报因子;x1为最多连续10天诱蛾量(头);x2为4月上、中旬百束小谷草把累计落卵量(块);x3为4月中旬降水量(毫米),x4为4月中旬雨日(天);预报一代粘虫幼虫发生量y(头/m2)。
分级别数值列成表2-1。
预报量y:每平方米幼虫0~10头为1级,11~20头为2级,21~40头为3级,40头以上为4级。
预报因子:x1诱蛾量0~300头为l级,301~600头为2级,601~1000头为3级,1000头以上为4级;x2卵量0~150块为1级,15l~300块为2级,301~550块为3级,550块以上为4级;x3降水量0~10.0毫米为1级,10.1~13.2毫米为2级,13.3~17.0毫米为3级,17.0毫米以上为4级;x4雨日0~2天为1级,3~4天为2级,5天为3级,6天或6天以上为4级。
表2-1x1 x2 x3 x4 y年蛾量级别卵量级别降水量级别雨日级别幼虫密度级别1960102241121 4.3121101 1961300144030.111141 196269936717.511191 196318764675417.1474554 1965431801 1.912111 19664222201010131 19678063510311.8232283 1976115124020.612171 197171831460418.4442454 19728033630413.4332263 19735722280213.224216219742641330342.243219219751981165271.84532331976461214017.515328319777693640444.7432444197825516510101112数据保存在“DATA6-5.SAV”文件中。

用SPSS做回归分析回归分析是一种统计方法,用于研究两个或多个变量之间的关系,并预测一个或多个因变量如何随着一个或多个自变量的变化而变化。
SPSS(统计软件包的统计产品与服务)是一种流行的统计分析软件,广泛应用于研究、教育和业务领域。
要进行回归分析,首先需要确定研究中的因变量和自变量。
因变量是被研究者感兴趣的目标变量,而自变量是可能影响因变量的变量。
例如,在研究投资回报率时,投资回报率可能是因变量,而投资额、行业类型和利率可能是自变量。
在SPSS中进行回归分析的步骤如下:1.打开SPSS软件,并导入数据:首先打开SPSS软件,然后点击“打开文件”按钮导入数据文件。
确保数据文件包含因变量和自变量的值。
2.选择回归分析方法:在SPSS中,有多种类型的回归分析可供选择。
最常见的是简单线性回归和多元回归。
简单线性回归适用于只有一个自变量的情况,而多元回归适用于有多个自变量的情况。
3.设置因变量和自变量:SPSS中的回归分析工具要求用户指定因变量和自变量。
选择适当的变量,并将其移动到正确的框中。
4.运行回归分析:点击“运行”按钮开始进行回归分析。
SPSS将计算适当的统计结果,包括回归方程、相关系数、误差项等。
这些结果可以帮助解释自变量如何影响因变量。
5.解释结果:在完成回归分析后,需要解释得到的统计结果。
回归方程表示因变量与自变量之间的关系。
相关系数表示自变量和因变量之间的相关性。
误差项表示回归方程无法解释的变异。
6.进行模型诊断:完成回归分析后,还应进行模型诊断。
模型诊断包括检查模型的假设、残差的正态性、残差的方差齐性等。
SPSS提供了多种图形和统计工具,可用于评估回归模型的质量。
回归分析是一种强大的统计分析方法,可用于解释变量之间的关系,并预测因变量的值。
SPSS作为一种广泛使用的统计软件,可用于执行回归分析,并提供了丰富的功能和工具,可帮助研究者更好地理解和解释数据。
通过了解回归分析的步骤和SPSS的基本操作,可以更好地利用这种方法来分析数据。
《数据统计分析软件SPSS的应用(五)——相关分析与回归分析》篇一数据统计分析软件SPSS的应用(五)——相关分析与回归分析一、引言在当今的大数据时代,数据统计分析成为了科学研究、市场调研、社会统计等众多领域的重要工具。
SPSS(Statistical Package for the Social Sciences)作为一款功能强大的数据统计分析软件,被广泛应用于各类数据分析中。
本文将重点介绍SPSS 中相关分析与回归分析的应用,以帮助读者更好地理解和掌握这两种分析方法。
二、相关分析1. 相关分析的概念与目的相关分析是研究两个或多个变量之间关系密切程度的一种统计方法。
其目的是通过计算相关系数,了解变量之间的线性关系强度和方向,为后续的回归分析提供依据。
2. SPSS中的相关分析操作步骤(1)导入数据:将数据导入SPSS软件中,建立数据文件。
(2)选择分析方法:在SPSS菜单中选择“分析”->“相关”->“双变量”,进行相关分析。
(3)设置变量:在弹出的对话框中,设置需要进行相关分析的变量。
(4)计算相关系数:点击“确定”后,SPSS将自动计算两个变量之间的相关系数,并显示在结果窗口中。
3. 相关分析的注意事项(1)选择合适的相关系数:根据研究目的和数据特点,选择合适的相关系数,如Pearson相关系数、Spearman相关系数等。
(2)控制混淆变量:在进行相关分析时,要控制可能影响结果的混淆变量,以提高分析的准确性。
三、回归分析1. 回归分析的概念与目的回归分析是研究一个或多个自变量与因变量之间关系的一种预测建模方法。
其目的是通过建立自变量和因变量之间的数学模型,预测因变量的值或探究自变量对因变量的影响程度。
2. SPSS中的回归分析操作步骤(1)导入数据:同相关分析一样,将数据导入SPSS软件中。
(2)选择分析方法:在SPSS菜单中选择“分析”->“回归”->“线性”,进行回归分析。
SPSS回归分析SPSS(Statistical Package for the Social Sciences)是一种用来进行统计分析的软件,其中包括回归分析。
回归分析是一种用来找出因变量与自变量之间关系的统计方法。
在回归分析中,我们可以通过控制自变量,预测因变量的值。
SPSS中的回归分析提供了多种模型,其中最常用的是线性回归分析。
线性回归分析模型假设因变量与自变量之间存在线性关系。
在执行回归分析前,需要明确因变量和自变量的选择。
通常,因变量是我们要预测或解释的变量,而自变量是用来解释或预测因变量的变量。
首先,我们需要导入数据到SPSS。
在导入数据前,要确保数据的结构合适,缺失值得到正确处理。
然后,在SPSS中打开回归分析对话框,选择线性回归模型。
接下来,我们需要指定因变量和自变量。
在指定因变量和自变量后,SPSS会自动计算回归模型的系数和统计指标。
其中,回归系数表示自变量的影响程度,统计指标(如R方)可以衡量模型的拟合程度。
在执行回归分析后,我们可以进一步分析回归模型的显著性。
一种常用的方法是检查回归系数的显著性。
SPSS会为每个回归系数提供一个t检验和相应的p值。
p值小于其中一显著性水平(通常是0.05)可以认为回归系数是显著的,即自变量对因变量的影响是有意义的。
此外,我们还可以通过分析残差来检查模型的适当性。
残差是观测值与回归模型预测值之间的差异。
如果残差分布服从正态分布,并且没有明显的模式(如异方差性、非线性),则我们可以认为模型是适当的。
最后,我们可以使用SPSS的图表功能来可视化回归模型。
比如,我们可以绘制散点图来展示自变量和因变量之间的关系,或者绘制残差图来检查模型的适当性。
总之,SPSS提供了强大的回归分析功能,可以帮助我们探索变量之间的关系并预测因变量的值。
通过进行回归分析,我们可以得到有关自变量对因变量的影响的信息,并评估模型的拟合程度和适用性。
27. 回归分析回归分析是研究一个或多个变量(因变量)与另一些变量(自变量)之间关系的统计方法。
主要思想是用最小二乘法原理拟合因变量与自变量间的最佳回归模型(得到确定的表达式关系)。
其作用是对因变量做解释、控制、或预测。
回归与拟合的区别:拟合侧重于调整曲线的参数,使得与数据相符;而回归重在研究两个变量或多个变量之间的关系。
它可以用拟合的手法来研究两个变量的关系,以及出现的误差。
回归分析的步骤:(1)获取自变量和因变量的观测值;(2)绘制散点图,并对异常数据做修正;(3)写出带未知参数的回归方程;(4)确定回归方程中参数值;(5)假设检验,判断回归方程的拟合优度;(6)进行解释、控制、或预测。
(一)一元线性回归一、基本原理一元线性回归模型:Y=0+1X+ε其中 X 是自变量,Y 是因变量, 0, 1是待求的未知参数, 0也称为截距;ε是随机误差项,也称为残差,通常要求ε满足:① ε的均值为0; ② ε的方差为 2;③ 协方差COV(εi , εj )=0,当i≠j 时。
即对所有的i≠j, εi 与εj 互不相关。
二、用最小二乘法原理,得到最佳拟合效果的01ˆˆ,ββ值: 1121()()ˆ()niii nii x x yy x x β==--=-∑∑, 01ˆˆy x ββ=- 三、假设检验1. 拟合优度检验计算R 2,反映了自变量所能解释的方差占总方差的百分比,值越大说明模型拟合效果越好。
通常可以认为当R 2大于0.9时,所得到的回归直线拟合得较好,而当R 2小于0.5时,所得到的回归直线很难说明变量之间的依赖关系。
2. 回归方程参数的检验回归方程反应了因变量Y 随自变量X 变化而变化的规律,若 1=0,则Y 不随X 变化,此时回归方程无意义。
所以,要做如下假设检验:H 0: 1=0, H 1: 1≠0; (1) F 检验若 1=0为真,则回归平方和RSS 与残差平方和ESS/(N-2)都是 2的无偏估计,因而采用F 统计量:来检验原假设β1=0是否为真。