美国当代英语语料库(COCA)使用介绍要点
- 格式:ppt
- 大小:1.97 MB
- 文档页数:56


coca等级词汇【原创实用版】目录1.引言:介绍 COCA 等级词汇表2.COCA 等级词汇表的构成3.COCA 等级词汇表的应用领域4.COCA 等级词汇表在我国的影响5.结论:总结 COCA 等级词汇表的重要性正文1.引言COCA 等级词汇表是一个用于描述英语语言中词汇频率的列表,它由美国南加州大学语言学家马克·戴维斯(Mark Davies)创建,并根据最大的英语语料库——COCA 语料库(Corpus of Contemporary American English)而得名。
这个表对于英语学习者、教育工作者和研究者来说都具有重要的参考价值。
2.COCA 等级词汇表的构成COCA 等级词汇表将英语词汇分为五个等级,分别是:(1)核心词汇(Core vocabulary):最常用的词汇,包括大约 2,200 个单词,这些词汇在英语中出现的频率非常高,掌握这些词汇有助于进行日常交流。
(2)基本词汇(Basic vocabulary):常用词汇,包括大约 7,500 个单词,这些词汇在英语中出现频率较高,掌握这些词汇有助于进行一般性的阅读、写作和交流。
(3)通用词汇(General vocabulary):包括大约 22,000 个单词,这些词汇在英语中出现频率适中,掌握这些词汇有助于进行更深入的阅读、写作和交流。
(4)学术词汇(Academic vocabulary):包括大约 10,000 个单词,这些词汇在学术性阅读和写作中出现频率较高,掌握这些词汇有助于进行专业性的阅读、写作和交流。
(5)专业词汇(Professional vocabulary):非常专业的词汇,包括大约 50,000 个单词,这些词汇在特定领域的阅读和写作中出现,掌握这些词汇有助于进行专业领域的研究和交流。
3.COCA 等级词汇表的应用领域COCA 等级词汇表在多个领域都有广泛的应用,包括英语教学、研究、翻译等。

美国当代英语语料库简介发表于《中小学外语教学(中学篇)》2013年第10期/s/blog_6056c9a60101nav5.html湖北:周韵【摘要】美国杨百翰大学的Mark Davies教授主持创立了一系列英语语料库,语料以各种英语变体为主,包括美国英语、英国英语、加拿大英语、《时代》杂志中的书面英语和美国肥皂剧中的英语口语。
其中,美国当代英语语料库是当前针对美国英语的大型历时语料平衡的网络语料库,具有库容大、语料丰富、检索方便灵活等特点。
本文介绍了美国当代英语语料库,以语料库及其关系数据库为平台,通过不同检索实例演示了以词汇为中心的应用与操作,以期探讨美国当代英语语料库在词汇教学中的应用。
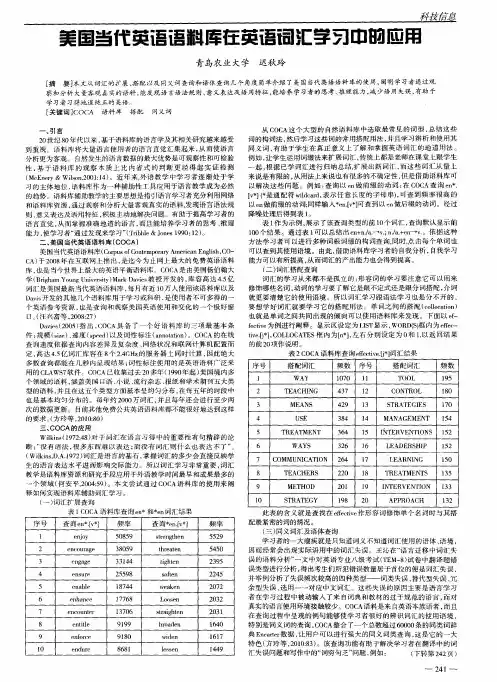
【关键词】美国当代英语语料库,词汇教学,词汇检索,关系数据库一、美国当代英语语料库美国当代英语语料库(Corpus of Contemporary American English,简称COCA)是目前最大的免费英语语料库,也是第一个大型的语料平衡的美国英语语料库,口语、小说、流行杂志、报纸和学术性文体在语料库库容中各占20%。
它不仅是一个简单的在线词典,而且从建立之初就体现了其作为检索语料库的特征,能够协助研究者追溯语言发展中的变迁(Davies,2010)。
该语料库由美国杨百翰大学的Mark Davies教授主持创立并在2008年正式上线。
目前,每月有数以万计的包括语言学家、教师、翻译工作者在内的各种类型的研究者通过互联网免费使用该语料库。
美国当代英语语料库由包含4.5亿词的文本构成,这些文本由口语、小说、流行杂志、报纸以及学术文章五种不同的文体构成。
从1999年至2012年这五个部分以每年增加2亿词的速度进行扩充,以保证语料库内容的时效性。
语料库每年更新1~2次。
因此,美国当代英语语料库被认为是用来观察美国英语当前发展变化的最合适的英语语料库。
除了在语料上拥有其他语料库无法比拟的优势外,美国当代英语语料库还将语料和检索软件结合起来,帮助语言研究者方便、快捷地分析和研究语料。

coca等级词汇【原创实用版】目录1.引言:介绍 COCA 词汇等级2.COCA 词汇等级的定义与划分3.COCA 词汇等级的应用领域4.COCA 词汇等级对于英语学习的重要性5.结论:总结 COCA 词汇等级的价值和意义正文1.引言COCA(Corpus of Contemporary American English)是美国当代英语的一个大规模语料库,它包含了众多英语词汇和短语。
在 COCA 中,词汇被分为五个等级,分别为高频词汇、中频词汇、低频词汇、罕见词汇和极罕见词汇。
这些等级对于英语学习者来说具有重要的参考价值。
2.COCA 词汇等级的定义与划分(1)高频词汇:在 COCA 语料库中出现频率最高的词汇,如“the”、“is”、“and”等。
这些词汇是英语基础中的基础,掌握这些词汇有助于提高阅读和写作效率。
(2)中频词汇:在 COCA 语料库中出现频率较高的词汇,如“education”、“technology”等。
这些词汇扩大了英语学习者的词汇量,有助于提高阅读理解的能力。
(3)低频词汇:在 COCA 语料库中出现频率适中的词汇,如“empanada”、“antics”等。
这些词汇在日常交流中不常用,但在特定场景下会出现,掌握这些词汇有助于提高英语表达的准确性。
(4)罕见词汇:在 COCA 语料库中出现频率较低的词汇,如“plethora”、“ephemeral”等。
这些词汇在日常交流中很少出现,但在文学作品或专业领域中会有所涉及,掌握这些词汇有助于提高英语阅读和写作的深度。
(5)极罕见词汇:在 COCA 语料库中出现频率极低的词汇,如“supercalifragilisticexpialidocious”等。
这些词汇在英语学习中几乎不会用到,但对于语言研究和词汇爱好者来说具有一定的价值。
3.COCA 词汇等级的应用领域COCA 词汇等级在英语教学、研究、翻译等领域都有广泛的应用。
英语学习者可以根据这些等级有针对性地进行学习和记忆,提高自己的英语水平。

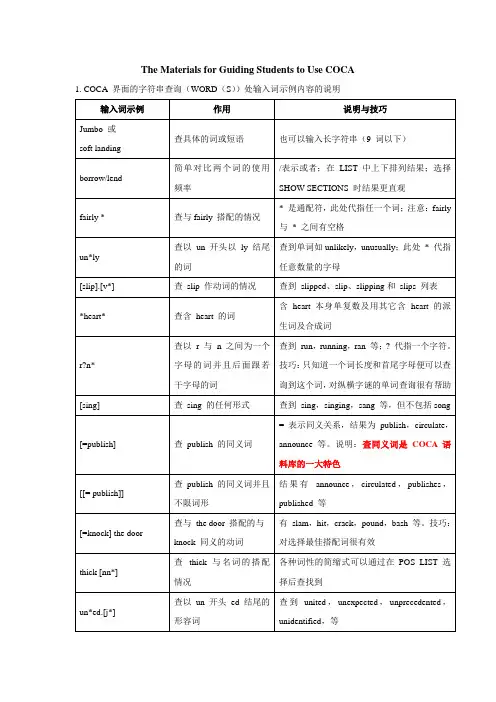
在美国当代英语语料库(COCA)如何查词.doc 在美国当代英语语料库(COCA)如何查词摘要:美国当代英语语料库(Corpus of Contemporary American English,COCA)由美国Brigham Young University 的Mark Davies教授开发,目前单词容量在4.5亿,是美国当前最新的当代英语语料库,也是当今世界上最大的英语平衡语料库。
该语料库的语料来自1990-2012年,每年更新,检索功能强大,是最佳的英语学习助手。
本文以sorry为例介绍了如何在美国当代英语语料库中查询单词及对单词sorry的检查与研究结果。
关键词:美国当代英语语料库,平衡语料库,sorryAbstract: The Corpus of Contemporary American English (COCA) is the largest freely-available corpus of English,and the only large and balanced corpus of American English.The corpus was created by Mark avies of Brigham Young University,and it is used by tens of thousands of sers every month (linguists,teachers,translators,and other searchers).COCA is also related to other large corpora that we have created.The corpus contains more than 450 million words of text and isqually divided among spoken,fiction,popular magazines,newspapers,and academic texts.It includes 20 million words each year from 1990-2012.Key words: the Corpus of Contemporary American English,parallel corpus,sorry中图分类号:H319.3文献标识码:A文章编号:1006-026X(2013)12-0000-02一、引论美国当代英语语料库(Corpus of Contemporary American English,COCA)由美国Brigham Young University 的Mark Davies教授开发,目前单词容量在4.5亿以上,是美国当前最新的当代英语语料库,也是当今世界上最大的英语平衡语料库,且与其他所建语料库相连。


coca语料库在英语写作课堂教学中的应用Coca语料库在英语写作课堂教学中的应用________________________________________________________________________随着社会经济发展,英语已经成为世界上最重要的语言。
在大多数国家,学生都必须学习英语作为一门外语,以满足他们的学习和工作需求。
英语写作教学是一项重要的教育活动,旨在培养学生的英语写作能力。
然而,由于教师们缺乏有效的教学方法,学生在写作过程中经常会遇到各种问题。
因此,有必要引入一种有效的写作教学方法,以改善学生的写作能力。
Coca语料库是一种新兴的教学方法,它主要通过分析大量的英语文本来帮助学生更好地理解英语句子结构。
Coca语料库是一个由大量英语文本组成的数据库,包括来自不同文本来源的英语句子。
它可以帮助学生理解英语句子的结构,从而更好地进行写作。
Coca语料库的主要应用是帮助学生理解句子的结构,以便于他们更好地进行写作。
例如,Coca语料库可以帮助学生理解句子的主干成分、句子的主题和句子的结构特征。
这将有助于学生更好地理解句子的内容,从而更好地进行写作。
此外,Coca语料库还可以帮助学生更好地理解英语文本中使用的词汇和句式。
通过分析文本中使用的词汇和句式,学生可以更好地理解文本的意思,从而帮助他们更好地进行写作。
此外,Coca语料库也可以帮助学生分析不同文本之间的差异。
通过对不同文本中使用的词汇和句式进行分析,学生可以更好地理解不同文本之间的差异,从而帮助他们进行写作时更好地考虑到不同文本之间的差异。
最后,Coca语料库还可以帮助学生理解不同文化背景下使用的不同表达方式。
通过分析不同文化背景下使用的不同表达方式,学生可以更好地理解不同文化背景下使用的表达方式,从而帮助他们在写作时更好地考虑到不同文化背景之间的差异。
总之,Coca语料库是一种有效的写作教学方法,可以帮助学生更好地理解句子的结构、词汇和句式、文本之间的差异以及不同文化背景下使用的表达方式,从而帮助他们更好地进行写作。


1. Who created these corpora?The corpora were created by Mark Davies, Professor of Linguistics at Brigham Young University in Provo, Utah, USA. In most cases (though see #2 below) this involved designing the corpora, collecting the texts, editing and annotating them, creating the corpus architecture, and designing and programming the web interfaces. Even though I use the terms "we" and "us" on this and other pages, most activities related to the development of most of these corpora were actually carried out by just one person.2. Who else contributed?3. Could you use additional funding or support?As noted above, we have received support from the US National Endowm ent for the Humanities and Brigham Young University for the developm ent of several corpora. However, we are always in need of ongoing support for new hardware and software, to add new features, and especially to create new corpora. Because we do not charge for the use of the corpora (which are used by 80,000+ researchers, teachers, and language learners each month) and since the creation and maintenance of these corpora is essentially a "one person enterprise", any additional support would be very welcom e. There might be graduate programs in linguistics, or ESL or linguistics publishers, who might want to make a contribution, and we would then "spotlight" them on the front page of the corpora. Also, if you have contacts at a funding source like the Mellon Foundation or the MacArthur grants, please let them know about us (and no, we're not kidding).4. What's the history of these corpora?The first large online corpus was the Corpus del Español in 2002, followed by the BYU-BNC in 2004, the Corpus do Português in 2006, TIME Corpus in 2007, the Corpus of Contemporary American English (COCA) in 2008, and the Corpus of Historical American English (COHA) in 2010. (More details...)5. What is the advantage of these corpora over other ones that are available?For some languages and time periods, these are really the only corpora available. For example, in spite of earlier corpora like the American National Corpus and the Bank of English, our Corpus of Contemporary American English is the only large, balanced corpus of contemporary American English. In spite of the Brown family of corpora and the ARCHER corpus, the Corpus of Historical American English is the only large and balanced corpus of historical American English. And the Corpus del Español and the Corpus do Português are the only large, annotated corpora of these two languages. Beyond the "textual" corpora, however, the corpus architecture and interface that we have developed allows for speed, size, annotation, and a range of queries that we believe is unmatched with other architectures, and which makes it useful for corpora such as the British National Corpus, which does have other interfaces. Also, they're free -- a nice feature.6. What software is used to index, search, and retrieve data from these corpora?We have created our own corpus architecture, using Microsoft SQL Server as the backbone of the relational database approach. Our proprietary architecture allows for size, speed, and very good scalability that we believe are not available with any other architecture. Even complex queries of the more than 425 million word COCA corpus or the 400 million word COHA corpus typically only take one or two seconds. In addition, be cause of the relational database design, we can keep adding on more annotation "modules" with little or no performance hit. Finally, the relational database design allows for a range of queries that we believe is unmatched by any other architecture for large corpora.7. How many people use the corpora?As measured by Google Analytics, as of March 2011 the corpora are used by more than 80,000 unique people each month. (In other words, if the same person uses three different corpora a total of ten times that month, it counts as just one of the 80,000 unique users). The most widely-used corpus is the Corpus of Contemporary American English -- with more than 40,000 unique users each month. And people don't just come in, look for one word, and move on -- average time at the site each visit is between 10-15 minutes.8. What do they use the corpora for?For lots of things. Linguists use the corpora to analyze variation and change in the different languages. Some are materials developers, who use the data to create teaching materials. A high number of users are language teachers and learners, who use the corpus data to model native speaker performance and intuition. Translators use the corpora to get precise data on the target languages. Some businesses purchase data from the corpora to use in natural language processing projects. And lots of people are just curious about language, and (believe it or not) just use the corpora for fun, to see what's going on with the languages currently. If you are a registered user, you can look at the profiles of other users (by country or by interest) after you log in.9. Are there any published materials that are based on these corpora?As of mid-2011, researchers have submitted entries for more than 260 books, articles and conference presentations that are based on the corpora, and this is probably only a sm all fraction of all of the publications that have actually been done. In addition, we ourselves have published three frequency dictionaries that are based on data from the corpora -- Spanish (2005), Portuguese (2007), and American English (2010).10. How can I collaborate with other users?You can search users' profiles to find researchers from your country, or to find researchers who have similar interests. In the near future, we may start a Google Group for those who want more interaction.11. What about copyright?Our corpora contain hundreds of millions of words of copyrighted material. The only way that their use is legal (under US Fair Use Law) is because of the limited "Keyword in Context" (KWIC) displays. It's kind of like the "snippet defense" used by Google. They retrieve and index billions of words of copyright material, but they only allow end users to access"snippets" (片段,少许)of this data from their servers. Click here for an extended discussion of US Fair Use Law and how it applies to our COCA texts.12. Can I get access to the full text of these corpora?Unfortunately, no, for reasons of copyright discussed above. We would love to allow end users to have access to full-text, but we simply cannot. Even when "no one else will ever use it" and even when "it's only one article or one page" of text, we can't. We have to be 100% compliant with US Fair Use Law, and that means no full text for anyone under any circumstances -- ever. Sorry about that.13. I want more data than what's available via the standard interface. What can I do?Users can purchase derived data -- such as frequency lists, collocates lists, n-grams lists (e.g. all two or three word strings of words), or even blocks of sentences from the corpus. Basically anything, as long as it does not involve full-text access (e.g. paragraphs or pages of text), which would violate copyright restrictions. Click here for much more detailed information on this data, as well as downloadable samples.14. Can my class have additional access to a corpus on a given day?Yes. Sometimes your school will be blocked after an hour or so of heavy use from a classroom full of students. (This is a security mechanism, to prevent "bots" from running thousands of queries in a short time.) To avoid this, sign up ahead of time for "group access".15. Can you create a corpus for us, based on our own materials?Well, I probably could, but I'm not overly inclined to at this point. Creating and maintaining corpora is extremely time intensive, even when you give me the data "all ready" to import into the database. The one exception, I guess, would be if you get a large grant to create and maintain the corpus. Feel free to contact me with questions.16. How do I cite the corpora in my published articles?Please use the following information when you cite the corpus in academic publications or conference papers. And please remember to add an entry to the publication database (it takes only 30-40 seconds!). Thanks.In the first reference to the corpus in your paper, please use the full name. For example, for COCA: "the Corpus of Contemporary American English" with the appropriate citation to the references section of the paper, e.g. (Davies 2008-). After that reference, feel free touse something shorter, like "COCA" (for example: "...and as seen in COCA, there are..."). Also, please do not refer to the corpus in the body of your paper as "Mark Davies' COCA corpus", "a corpus created by Mark Davies", etc. The bibliographic entry itself is enough to indicate who created the corpus.。
COCA(Corpus of Contemporary American English)是一个大型的英语语料库,它包含了大量的美国英语口语和书面语料。
COCA词频词汇是指在这个语料库中被统计出来出现频率较高的词汇。
这些词汇被认为是英语母语者日常交流和阅读中常用的词汇。
由于COCA词频词汇表包含的词汇非常多,这里提供几个示例词汇及其释义:1. justice - n. 公正,公道,正义;司法制度;法律制裁。
例如:"The word justice is usually associated with courts of law."(正义这个词常常同法院联系在一起。
)2. justify - vt. 证明……正当/有理;为辩解。
例如:"You should attempt to justify yourself."(你应该设法证明自己有理。
)3. keep - vt. & vi. 使处于,保持(某种状态);遵守;保守;保留;保管;存放;供养;饲养;经营;记(日记、帐等)。
例如:"Keep calm, especially when you are with other people."(保持镇静,尤其是身边还有其他人的时候。
)4. keep away from -远离。
例如:"In the past, following others was a way to keep away from danger."(在过去,跟随别人是一种远离危险的方法。
)5. keep on -继续进行,继续下去。
例如:"Never keep on exercising if you feel pain."(如果你感到疼痛,就不要继续锻炼。
)这些词汇只是COCA词频词汇表中的一部分。
COCA词汇表根据词汇在语料库中的出现频率进行排序,频率高的词汇代表了英语使用者的常用词汇。
coca词汇表(最新版)目录1.引言:介绍 COCA 词汇表2.COCA 词汇表的构成3.COCA 词汇表的应用领域4.COCA 词汇表的优势和局限性5.结论:总结 COCA 词汇表的重要性正文1.引言COCA(Corpus of Contemporary American English)词汇表是一个收录了大量美国英语词汇的表单,对语言学家、教育工作者以及翻译人员等有着重要的参考价值。
本文将详细介绍 COCA 词汇表的构成、应用领域、优势和局限性。
2.COCA 词汇表的构成COCA 词汇表是由美国杨百翰大学(Brigham Young University)的语言学家马克·戴维斯(Mark Davis)教授领导的团队创建的。
该词汇表收录了超过 500 万条美国英语词汇,包括单词、词组、短语以及它们的词频。
这些词汇来源于大量的当代美国英语语料库,如新闻文章、小说、电影剧本等。
3.COCA 词汇表的应用领域COCA 词汇表在多个领域有着广泛的应用,包括但不限于:(1)语言学研究:COCA 词汇表为语言学家提供了大量真实语料,有助于分析和研究美国英语的词汇特征、用法以及演变规律。
(2)教育:COCA 词汇表为英语教育工作者提供了参考,有助于制定教学大纲、设计课程以及编写教材。
(3)翻译:COCA 词汇表为翻译人员提供了美国英语词汇的准确用法,有助于提高翻译质量。
(4)词典编纂:COCA 词汇表为词典编纂者提供了大量真实语料,有助于修订和完善词典内容。
4.COCA 词汇表的优势和局限性优势:(1)真实性:COCA 词汇表的词汇来源于大量的当代美国英语语料库,反映了现实语言的真实面貌。
(2)全面性:COCA 词汇表收录了超过 500 万条美国英语词汇,具有较高的覆盖率。
局限性:(1)地域性:COCA 词汇表主要收录美国英语词汇,对于其他地区的英语用法可能不够全面。
(2)时效性:COCA 词汇表的词汇来源于当代语料库,对于历史英语词汇的收录可能不够全面。