Lingo软件在最优化问题中的应用
- 格式:ppt
- 大小:207.50 KB
- 文档页数:17
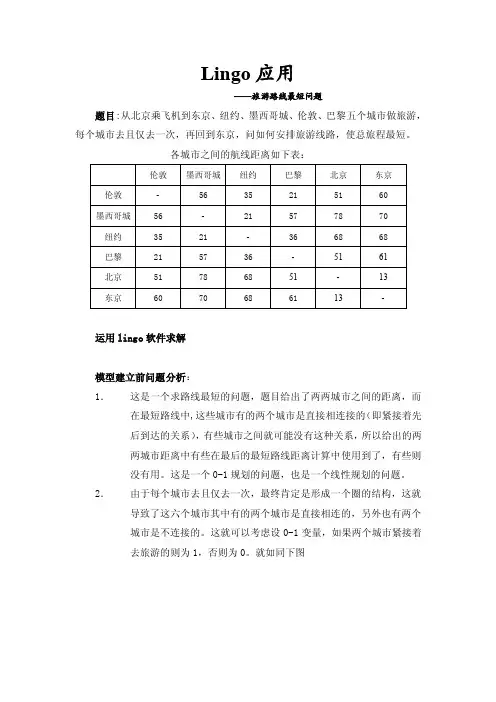
Lingo应用——旅游路线最短问题题目:从北京乘飞机到东京、纽约、墨西哥城、伦敦、巴黎五个城市做旅游,每个城市去且仅去一次,再回到东京,问如何安排旅游线路,使总旅程最短。
各城市之间的航线距离如下表:运用lingo软件求解模型建立前问题分析:1.这是一个求路线最短的问题,题目给出了两两城市之间的距离,而在最短路线中,这些城市有的两个城市是直接相连接的(即紧接着先后到达的关系),有些城市之间就可能没有这种关系,所以给出的两两城市距离中有些在最后的最短路线距离计算中使用到了,有些则没有用。
这是一个0-1规划的问题,也是一个线性规划的问题。
2.由于每个城市去且仅去一次,最终肯定是形成一个圈的结构,这就导致了这六个城市其中有的两个城市是直接相连的,另外也有两个城市是不连接的。
这就可以考虑设0-1变量,如果两个城市紧接着去旅游的则为1,否则为0。
就如同下图实线代表两个城市相连为1,虚线代表没有相连为03. 因为每个城市只去一次,所以其中任何一个城市的必有且仅有一条进入路线和一条出去的路线。
求解:为了方便解题,给上面六个城市进行编号,如下表(因为北京是起点, 将其标为1)假设:设变量x ij 。
如果x ij =1,则表示城市i 与城市j 直接相连(即先后紧接到达关系),否则若x ij =0,则表示城市i 与城市j 不相连。
特别说明:x ij 和x ji 是同一变量,都表示表示城市i 与城市j 是否有相连的关系。
这里取其中x ij (I<j)的变量。
模型建立:由于这是一个最短路线的问题,且变量已经设好。
目标函数:min z=51*x12+78*x13+68*x14+51*x15+13*x16+56*x23+35*x24+21*x25+60*x26+21*x34+57*x35+70*x36+36*x45+68*x46+61*x56约束条件:1. 上面目标函数中的变量是表示两个城市是否直接相连接的关系,且最短路线是可以形成圈的,如下图实线代表两个城市相连为1,虚线代表没有相连为0如上图城市a和城市b有直接相连接的关系,所以之间变量为1,而城市a 与城市e则没有直接相连接的关系,之间变量为0。

LINGO是一种用于线性规划、整数规划、非线性规划、混合整数规划等数学建模和优化问题的软件工具。
它可以用于解决各种实际问题,包括生产计划、物流、资源分配、网络设计等。
以下是一个简单的LINGO案例,以帮助您了解如何使用LINGO进行优化建模和求解问题:**问题描述:**假设有一家制造公司,他们生产两种产品:A和B。
公司有两个工厂,每个工厂都有不同的生产能力和成本。
公司希望确定每个工厂应该生产多少产品A和B,以最大化利润,同时满足生产能力和市场需求的限制。
**问题数据:**- 工厂1的生产能力:最多生产500个A和300个B- 工厂2的生产能力:最多生产400个A和600个B- 产品A的利润:每个A产品的利润为30美元- 产品B的利润:每个B产品的利润为40美元- 生产一个A产品的成本:工厂1为10美元,工厂2为15美元- 生产一个B产品的成本:工厂1为12美元,工厂2为10美元- 市场需求:产品A的市场需求为600个,产品B的市场需求为800个**LINGO建模和求解:**在LINGO中,可以使用数学表达式来建立优化模型。
以下是一个LINGO模型的示例:```SETS:FACTORIES = 1..2;ENDSETSDATA:CAPACITY(FACTORIES) = 500 300400 600;PROFIT = 30 40;COST(FACTORIES) = 10 1512 10;DEMAND = 600 800;ENDDATAVARIABLES:X(FACTORIES) = 0;ENDVARIABLESMAX = @SUM(FACTORIES, PROFIT(FACTORIES) * X(FACTORIES))SUBJECT TOCAPACITY_CONSTRAINT(F)$(FACTORIES): @SUM(FACTORIES, COST(F, FACTORIES) * X(FACTORIES)) <= CAPACITY(F);DEMAND_CONSTRAINT(I)$(FACTORIES): @SUM(FACTORIES,X(FACTORIES)) >= DEMAND(I);POSITIVE_X(F)$(FACTORIES): X(F) >= 0;ENDSUBMODEL:MAX;SOLVE;```上述LINGO模型首先定义了SETS、DATA、VARIABLES和MAX,然后使用SUBJECT TO部分定义了约束条件,最后使用MODEL和SOLVE命令求解优化问题。


学号系统工程与运筹学课程设计设计说明书层次分析法应用系统最优化问题起止日期:2013年11月25 日至2013 年11月29日学生姓名班级成绩指导教师经济与管理学院2013年11月29日成绩评定表目录Ⅰ研究报告 (1)课程设计题目1:改革新形式下的大学生形象评价 (1)1.问题的提出 (1)2.分层递阶结构模型 (2)3.判断矩阵及相关计算结果 (2)4.单排序及总排序计算过程及结果 (6)5.结果分析 (6)5.1结果 (6)5.2分析 (6)课程设计题目2:人员合理分配问题 (7)1.问题的提出 (7)2.问题分析 (7)3.基本假设与符号说明 (7)4.模型的建立及求解结果 (8)5.模型评价 (9)课程设计题目3:生产调运问题 (10)1.问题的提出 (10)2.问题分析 (11)3.基本假设与符号说明 (11)4.模型的建立及求解结果 (12)5.模型评价 (18)II工作报告 (19)III 参考文献 (20)附件一:人员合理分配问题lingo程序及结果 (21)附件二:生产调运问题lingo程序及结果 (22)Ⅰ研究报告课程设计题目1:改革新形式下的大学生形象评价摘要:大学生如何塑造个人形象?首先我们要了解形象这个概念以及它的重要性,得体的塑造和维护形象,会给初次见面的人以良好第一印象。
塑造大学生形象还要关注社会,放眼世界,注重群体性,同时作为大学生形象塑造最重要主体的大学生,在平时学习、生活中就应该有意识地培养、塑造自身形象,为自己在人际交往过程中、特别是未来就业求职道路上增加重要的竞争砝码。
有的人说青春就是最好的包装,天生丽质、潇洒帅气就是大学生的理想形象。
但是,我们觉得所谓的形象,并不能简单地理解为人的外表特征,更应是人的精神和内在素质通过外表的一种自然流露和表现;大学生必须在学习和实践中不断扩展自己的知识面,掌握一定的技能,如果只重外表,不重内涵构造出来的形象,则只能是肤浅和苍白无力的。



利用LINGO建立最优化模型洪文1,朱云鹃1,金震1,王其文21(安徽大学商学院 合肥 230039)2(北京大学光华管理学院 北京 100871)摘 要:本文借助于最优化软件LINGO建立了最小树、最短路、最大流、最小费用流和货郎担问题的LINGO模型,并对模型中的难点给出了注释。
利用本文提供的模型,可以很容易地求出上述5个最优化问题的最优解。
关键词:最小树、最短路、最大流、最小费用流、货郎担问题、LINGO中图分类号:0211.6 文献标识码:A 文章编号:0 引言求解最小树、最短路、最大流、最小费用流和货郎担问题的方法虽然很多,但是利用最优化求解软件LINGO建立相应的模型来求解上述5个问题是一种新的尝试。
本文建立的模型有两个突出的特点。
第一个特点是模型的数据与公式完全分离,这样使得问题的求解变得特别方便(对于不同的问题只要更换数据即可)。
第二个特点是这五个模型都是利用最优化求解软件LINGO编写而成,可进行快速求解。
1 LINGO简介LINGO是一个简单而实用的最优化软件。
利用线性和非线性最优化的方法,LINGO可以用公式简明地表示复杂的规划问题,并可以快速地求出问题的最优解。
LINGO是由美国芝加哥LINDO系统公司研制。
该公司根据用户信息、线性和非线性规划的理论和方法及计算机发展的需要不断推出新的版本。
目前LINGO已成为世界上最为流行的最优化软件之一。
LINGO在我国已经有了相当多的用户。
它的主要特点是:1)LINGO含有一系列的接口函数。
这些接口函数可用在文本文件、电子表格和数据库中,可与外部的输入/输出源进行连接。
2)LINGO可以直接嵌入到Excel中,也可以将Excel嵌入到LINGO模型中。
这样就可以将数据与模型分离,使得模型的维护和调试变得非常容易。
3)LINGO使用Windows的窗口展开优化分析功能,使用对话框展示各种功能。
清晰、直观、易学易用。
4)LINGO具有强大的计算功能。

2014~2015学年第二学期短学期《数学软件及应用(Lingo)》实验报告班级数学131班姓名张金库学号成绩实验名称奶制品的生产与销售计划的制定完成日期:2015年9月3日一、实验名称:奶制品的生产与销售计划的制定二、实验目的及任务1.了解并掌握LINGO 的使用方法、功能与应用;2.学会利用LINGO 去解决实际中的优化问题。
三、实验内容问题 一奶制品加工厂用牛奶生产1A ,2A 两种奶制品,1桶牛奶可以在甲类设备上用12h 加工成3kg 1A ,或者在乙类设备上用8h 加工成4kg 2A 。
根据市场的需求,生产1A ,2A 全部能售出,且每千克1A 获利24元,每千克2A 获利16元。
现在现在加工场每天能的到50桶牛奶的供应,每天正式工人总的劳动时间为480h ,并且甲类设备每天至多能加工100kg 1A ,乙类设备的加工能力没有限制。
为增加工厂的利益,开发奶制品的深加工技术:用2h 和3元加工费,可将1kg 1A 加工成高级奶制品1B ,也可将1kg 2A 加工成高级奶制品2B ,每千克1B 能获利44元,每千克2B 能获利32元。
试为该工厂制订一个生产销售计划,使每天的净利润最大,并讨论以下问题:(1)若投资30元可以增加供应1桶牛奶,投资3元可以增加1h 的劳动时间,应否做这些投资若每天投资150,可以赚回多少(2)每千克高级奶制品1B ,2B 的获利经常有10%的波动,对制订的生产销售计划有无影响若每千克1B 获利下降10%,计划应该变化吗(3)若公司已经签订了每天销售10kg 1A 的合同并且必须满足,该合同对公司的利润有什么影响问题分析 要求制定生产销售计划,决策变量可以先取作每天用多少桶牛奶生产1A ,2A ,再添上用多少千克1A 加工1B ,用多少千克2A 加工2B ,但是问题要分析1B ,2B 的获利对生产销售计划的影响,所以决策变量取作1A ,2A ,1B ,2B 每天的销售量更为方便。

LINGO的使用简介LINGO软件是美国的LINGO系统公司开发的一套专门用于求解最优化问题的软件包.LINGO除了能够用于求解线性规划和二次规划外,还可以用于非线性规划求解、以及一些线性和非线性方程(组)的求解等.LINGO软件的最大特色在于它允许优化模型中的决策变量为整数,即可以求解整数规划,而且执行速度快.LINGO是用来求解线性和非线性优化问题的简易工具.LINGO内置了一种建立最优化模型的语言,可以简便地表达大规模问题,利用LINGO高效的求解器可快速求解并分析结果.在这里仅简单介绍LINGO的使用方法.LINGO(Linear INteractive and General Optimizer )的基本含义是交互式的线性和通过优化求解器.它是美国芝加哥大学的 Linus Schrage 教授于1980年开发了一套用于求解最优化问题的工具包,后来经过完善成何扩充,并成立了LINDO系统公司.这套软件主要产品有:LINDO,LINGO,LINDO API和What’sBest.它们在求解最优化问题上,与同类软件相比有着绝对的优势.软件有演示版和正式版.正式版包括:求解包(solver suite)、高级版(super)、超级版(hyper)、工业版(industrial)、扩展版(extended).不同版本的LINGO对求解问题的规模有限制,如附表3-1所示.附表3-1 不同版本LINGO对求解规模的限制版本类型总变量数整数变量数非线性变量数约束数演示版 300 30 30 150求解包 500 50 50 250高级版 2000 200 200 1000超级版 8000 800 800 4000工业版 32000 3200 32000 16000扩展版无限无限无限无限3.1 LINGO程序框架LINGO可以求解线性规划、二次规划、非线性规划、整数规划、图论及网络最优化问题和最大最小求解问题,以及排队论模型中最优化等问题.一个LINGO程序一般会包括以下几个部分:(1) 集合段:集部分是LINGO模型的一个可选部分.在LINGO模型中使用集之前,必须在集部分事先定义.集部分以关键字“sets:”开始,以“endsets”结束.一个模型可以没有集部分,或有一个简单的集部分,或有多个集部分.一个集部分可以放置于模型的任何地方,但是一个集及其属性在模型约束中被引用之前必须先定义.(2) 数据段:在处理模型的数据时,需要为集部分定义的某些元素在LINGO求解模型之前为其指定值.数据部分以关键字“data:”开始,以关键字“enddata”结束.(3) 目标和约束段:这部分用来定义目标函数和约束条件等.该部分没有开始和结束的标记.主要是要用到LINGO的内部函数,尤其是与集合有关的求和与循环函数等.(4)初始段:这个部分要以关键字“INIT:”开始,以关键字“ENDINIT”结束,它的作用是对集合的属性定义一个初值.在一般的迭代算法中,如果可以给一个接近最优解的初始值,会大大减少程序运行的时间.(5) 数据预处理段:这一部分是以关键字“CALC:”开始,以关键字“ENDCALC”结束.它的作用是把原始数据处理成程序模型需要的数据,它的处理是在数据段输入完以后、开始正式求解模型之前进行的,程序语句是按顺序执行的.3.2 LINGO中集合的概念在对实际问题建模的时候,总会遇到一群或多群相联系的对象,比如工厂、消费者群体、交通工具和雇工等等.LINGO允许把这些相联系的对象聚合成集(sets).一旦把对象聚合成集,就可以利用集来最大限度地发挥LINGO建模语言的优势.现在将深入介绍如何创建集,并用数据初始化集的属性.3.2.1集的构成集是LINGO建模语言的基础,是程序设计最强有力的基本构件.借助于集能够用一个单一的、简明的复合公式表示一系列相似的约束,从而可以快速方便地表达规模较大的模型.集是一群相联系的对象,这些对象也称为集的元素.一个集可能是一系列产品、卡车或雇员.每个集的元素可能有一个或多个与之有关联的特征,把这些特征称为属性.属性值可以预先给定,也可以是未知的,有待于LINGO求解的.LINGO有两种类型的集:原始集(primitive set)和派生集(derived set).一个原始集是由一些最基本的对象组成的.一个派生集是用一个或多个其它集来定义的,也就是说,它的元素来自于其它已存在的集.3.2.2模型的集部分集部分在程序中又称为集合段,它是LINGO模型的一个可选部分.在LINGO模型中使用集之前,必须在集部分事先定义.集部分以关键字“sets:”开始,以“endsets”结束.一个模型可以没有集部分,或有一个简单的集部分,或有多个集部分.一个集部分可以放置于模型的任何地方,但是一个集及其属性在模型约束中被引用之前必须先定义.(1)原始集的定义为了定义一个原始集,必须详细说明集的名字,而集的元素和相应的属性是可选的.定义一个原始集,用下面的语法:setname[/member_list/][:attribute_list];注意:用“[]”表示该部分内容是可选的(下同).Setname是用来标记集的名字,最好具有较强的可读性.集名字必须严格符合标准命名规则:以拉丁字母或下划线为首字符,其后由拉丁字母、下划线、阿拉伯数字组成的总长度不超过32个字符的字符串,且不区分大小写.注意:该命名规则同样适用于集元素名和属性名等的命名.Member_list是集元素的列表.如果集元素放在集定义中,那么对它们可采取显式和隐式罗列两种方式.如果集元素不放在集定义中,那么可以在随后的数据部分定义.①当显式罗列元素时,必须为每个元素输入一个不同的名字,中间用空格或逗号隔开,允许混合使用.例3.1 定义一个名为friends的原始集,它具有元素John,Jill,Rose和Mike,其属性有sex和age:sets:friends/John Jill, Rose Mike/: sex, age;endsets②当隐式罗列元素时,不必罗列出每个集元素.可采用如下语法:setname/member1..member N/[: attribute_list];这里的member1是集的第一个元素名,member N是集的最后一个元素名.LINGO将自动产生中间的所有元素名.LINGO也接受一些特定的首元素名和末元素名,用于创建一些特殊的集.③集元素不放在集定义中,而在随后的数据部分来定义.例3.2!集部分;sets:friends:sex,age;endsets!数据部分;data:friends,sex,age=John,1,16 Jill,0,14 Rose,0,17 Mike,1,13;enddata注意:开头用感叹号(!),末尾用分号(;)表示注释,可跨多行.在集部分只定义了一个集friends,并未指定元素.在数据部分罗列了集元素John,Jill,Rose和Mike,并对属性sex和age分别给出了值.集元素无论用何种字符标记,它的索引都是从1开始连续计数.在attribute_ list可以指定一个或多个集元素的属性,属性之间必须用逗号隔开.LINGO内置的建模语言是一种描述性语言,用它可以描述现实世界中的一些问题,然后再借助于LINGO 求解器求解.因此,集属性的值一旦在模型中被确定,就不可能再更改.只有在初始部分中给出的集属性值在以后的求解中可更改.这与前面并不矛盾,初始部分是LINGO求解器的需要,并不是描述问题所必须的.(2) 定义派生集为了定义一个派生集,必须详细说明集的名字和父集的名字,而集元素和属性是可选的.可用下面的语法定义一个派生集:setname(parent_set_list)[/member_list/][:attribute_list];setname是集的名字.parent_set_list是已定义的集的列表,多个时要用逗号隔开.如果没有指定成员列表,那么LINGO会自动创建父集元素的所有组合作为派生集的元素.派生集的父集既可以是原始集,也可以是其它的派生集.例3.3sets:product/A,B/;machine/M,N/;week/1..2/;allowed(product,machine,week):x;endsetsLINGO生成了三个父集的所有组合共八组作为allowed集的元素,列表如下:编号元素1 (A,M,1)2 (A,M,2)3 (A,N,1)4 (A,N,2)5 (B,M,1)6 (B,M,2)7 (B,N,1)8 (B,N,2)元素列表被忽略时,派生集成员由父集成员所有的组合构成,这样的派生集成为稠密集.如果限制派生集的成员,使它成为父集成员所有组合构成的集合的一个子集,这样的派生集成为稀疏集.同原始集一样,派生集元素的说明也可以放在数据部分.一个派生集的元素列表有两种方式生成:①显式罗列;②设置元素选择的过滤器.当采用方式①时,必须显式罗列出所有要包含在派生集中的元素,并且罗列的每个元素要属于稠密集.使用前面的例子,显式罗列派生集的元素,如:allowed(product,machine,week)/A M 1,A N 2,B N 1/;如果需要生成一个大的、稀疏的集,那么显式罗列就十分麻烦.但是许多稀疏集的元素都满足一些条件,可以把这些逻辑条件看作过滤器,在LINGO生成派生集的元素时把使逻辑条件为假的元素从稠密集中过滤掉.例3.4sets:!学生集:性别属性sex,1表示男性,0表示女性;年龄属性age;students/John,Jill,Rose,Mike/:sex,age;!男学生和女学生的联系集:友好程度属性friend![0,1]之间的数;linkmf(students,students)|sex(&1)#eq#1#and#sex(&2)#eq#0: friend;!男学生和女学生的友好程度大于0.5的集;linkmf2(linkmf) | friend(&1,&2) #ge# 0.5 : x;endsetsdata:sex,age =1 16,0 14,0 17,0 13;friend =0.3,0.5,0.6;enddata用竖线(|)来标记一个元素过滤器的开始.#eq#是逻辑运算符,用来判断是否“相等”. &1可看作派生集的第1个原始父集的索引,它取遍该原始父集的所有元素;&2可看作派生集的第2 个原始父集的索引,它取遍该原始父集的所有元素;&3,&4,…,依此类推.注意如果派生集B的父集是另外的派生集A,那么上面所说的原始父集是集A向前回溯到最终的原始集,其顺序保持不变,并且派生集A的过滤器对派生集B仍然有效.因此,派生集的索引个数是最终原始父集的个数,索引的取值是从原始父集到当前派生集所作限制的总和.3.3 LINGO数据部分和初始部分在处理模型的数据时,需要为集指定一些元素并且在LINGO求解模型之前为集的某些属性指定数值.为此,LINGO为用户提供了两个可选部分:输入集元素数值的数据部分(Data Section)和为决策变量设置初始值的初始部分(Init Section).3.3.1数据部分(1) 数据部分入门数据部分以关键字“data:”开始,“enddata”结束.在这里,可以指定集元素和集的属性.其语法如下:object_list = value_list;对象列(object_list)包含要指定值的属性名、要设置集元素的集名,用逗号或空格隔开.一个对象列中只能有一个集名,而属性名可以有任意多个.如果对象列中有多个属性名,那么它们的类型必须一致.数值列(value_list)包含要分配给对象列中对象的值,用逗号或空格隔开.注意属性值的个数必须等于集元素的个数.例3.5sets:SET0/A,B,C/: X,Y;endsetsdata:X=1,2,3;Y=4,5,6;enddata在集SET0中定义了两个属性X和Y.X的三个值是1,2,3,Y的三个值是4,5,6.也可采用如下例子中的复合数据说明(data statement)实现同样的功能.例3.6sets:SET0/A,B,C/: X,Y;endsetsdata:X,Y=1 4 2,5 3 6;enddata如果对象列中有n个对象,LINGO在为对象指定值时,首先在n个对象的第1个索引处依次分配数值列中的前n个对象,然后在n个对象的第2个索引处依次分配数值列中紧接着的n个对象,…,依此类推.(2) 参数输入在数据部分也可以指定一些标量变量(scalar variables).当一个标量变量在数据部分确定时,称之为参数.例如,假设模型中用利率9%作为一个参数,就可以输入一个利率作为参数.例3.7data:interest_rate = .09;enddata实际中也可以同时指定多个参数.如:data:interest_rate,inflation_rate = .09, .025;enddata(3) 实时数据处理在某些情况下,模型中的某些数据并不是定值.譬如模型中有一个参数在2%至6%范围内,对不同的值求解模型,观察模型的结果对参数依赖的程度,那么把这种情况称为实时数据处理.处理方法是在该语句的数值后面输入一个问号(?).data:interest_rate,inflation_rate = .09 ?;enddata在每一次求解模型时,LINGO都会提示为参数inflation_rate输入一个值.在WINDOWS操作系统下,将会看到一个如下面的对话框:直接输入一个值再点击OK按钮,LINGO就会把输入的值指定赋给inflation_rate,然后继续求解模型.除了参数之外,也可以实时输入集的属性值,但不允许实时输入集元素名.(4) 指定属性为一个值可以在数据定义的右边输入一个值来把所有的元素的该属性指定为一个值.如下面的例子.例3.9sets:days /MO,TU,WE,TH,FR,SA,SU/:needs;endsetsdata:needs = 40;enddataLINGO将用40指定days集的所有元素的needs属性.对于多个属性的情形如下:sets:days /MO,TU,WE,TH,FR,SA,SU/:needs,cost;endsetsdata:needs cost = 40 90;enddata(5) 数据部分的未知数值表示法有时候只需为一个集的部分元素的某个属性指定数值,而让其余元素的该属性是未知的,以便让LINGO 去求出它们的最优值.在数据定义中输入两个相连的逗号表示该位置对应元素的属性值未知,两个逗号间可以有空格.例3.10sets:years/1..6/: capacity;endsetsdata:capacity = ,24,40,,,;属性capacity的第2个和第3个值分别为24和40,其余的未知.3.3.2初始部分初始部分是LINGO提供的另一个可选内容.在初始部分中,与数据部分中的数据定义相同,可以输入初始定义(initialization statement).在对实际问题的建模时,初始部分并不起到描述模型的作用,初始部分输入的值仅被LINGO求解器当作初始值来使用,并且仅仅对非线性模型有用.这与数据部分指定变量的值不同,LINGO求解器可以自由改变初始部分初始化变量的数值.一个初始部分以关键字“init:”开始,以关键字“endinit”结束.初始部分的初始定义规则和数据部分的数据定义规则相同.也就是说,可以在定义的左边同时初始化多个集属性,即可以把集属性初始化为一个数值,也可以用问号定义为实时数据,还可以用逗号指定为未知数值.例3.11init:X,Y = 1,0;endinitY=@log(X);X^2+Y^2<=1;3.4 LINGO函数3.4.1运算符及其优先级LINGO 中的运算符可以分为三类:算数运算符、逻辑运算符和关系运算符.(1) 算数运算符算数运算符分为5种: (加法), (减法), (乘法), (除法), (求幂).(2) 逻辑运算符逻辑运算符分为两类:#AND#(与),#OR#(或),#NOT#(非):这3个运算符是参与逻辑值之间的运算,其结果还是逻辑值.运算符#EQ#(等于),#NE#(不等于),#GT#(大于),#GE#(大于等于),#LT#(小于),#LE#(小于等于)是用于“数与数之间”的比较,其结果是实逻辑值.(3) 关系运算符LINGO中有3种关系运算符:<(小于等于),>(大于等于),=(等于).注意LINGO中优化模型的约束一般没有严格大于、严格小于,要和逻辑运算符区分开.运算符的优先等级如附表3-2所示.附表3-2 运算符的优先级3.4.2 LINGO数学函数(1) 基本数学函数LINGO中有相当丰富的数学函数,这些函数的用法简单.下面列表对各个函数的用法做简单的介绍,具体情况如附表3-3所示.(2) 集合循环函数集合循环是指对集合上的元素(下标)进行循环操作的函数,它的一般用法如下:@function(setname[(set_index_list)[|condition]]:expression_list);其中function是集合函数名,是FOR,MAX,MIN,PROD,SUM五种之一.setname是集合名;set_index_list 是集合索引列表(可以省略);condition是实用逻辑表达式描述的过滤条件(通常含有索引,可以省略);expression_list是一个表达式(对@FOR可以是一组表达式).下面对具体的集合函数作如下解释:@FOR(集合元素的循环函数):对集合setname的每个元素独立生成表达式,表达式由expression_list 描述.@MAX(集合属性的最大值):返回集合setname上的表达式的最大值.@MIN(集合属性的最小值) :返回集合setname上的表达式的最小值.@PROD(集合元素的乘积函数):返回集合setname上的表达式的积.@SUM(集合元素的求和函数) :返回集合setname上的表达式的和.(3) 集合操作函数集合操作函数是对集合进行操作的函数,主要有4种,下面分别介绍它们的一般用法.1)@INDEX([set_name,]primitive_set_element)这个函数给出元素primitive_set_element在集合set_name中的索引值(即按定义集合时元素出现顺序的位置编号).如果省略编号set_name,LINGO按模型中定义的集合顺序找到第一个含有元素primitive_set_element的集合,并返回索引值.通过下面例子解释函数的使用方法.例如,假设定义一个女孩的姓名集合和一个男孩的姓名集合:SETS:GIRLS/DEBBLE,SUE,ALICE/;BOYS/BOB,JOE,SUE,FRED/;ENDSETS注意到女孩集和男孩集中都有一个为SUE的元素,如果要调用此函数@INDEX(SUE),则得到返回索引值是2.因为集合GIRLS在集合BOYS之前,则索引函数只对集合GIRLS检索.如果想查找男孩集中的SUE,则应该使用@INDEX(BOYS,SUE),则此时得到的索引值是3.2)@IN(set_name,primitive_index_1[,primitive_index_2 …])这个函数用于判断一个集合中是否含有某个索引值.它的返回值是1(逻辑值“真”),或是0(逻辑值“假”).例3.12全集为I,B是I的一个子集,C是B的补集.sets:I/x1..x4/;B(I)/x2/;C(I)|#not#@in(B,&1):;endsets3)@wrap(index,limit)该函数返回j=index-k*limit,其中k是一个整数,取适当值保证j落在区间[1,limit]内.该函数相当于index模limit再加1.该函数在循环、多阶段计划编制中特别有用.4)@size(set_name)该函数返回集set_name的元素个数.在LINGO模型中,如果没有明确给出集的大小,则使用该函数能够使模型中的数据变化和集的大小改变更加方便.(4) 变量定界函数变量界定函数能够实现对变量取值范围的附加限制,共4种:1)@bin(x)表示限制就是x为0或1;2)@bnd(L,x,U)表示限制变量x满足;3)@free(x)表示取消对变量x的默认下界为0的限制,即x可以取任意实数;4)@gin(x)表示限制变量x为整数.在默认情况下,LINGO规定变量是非负的,即下界值为0,上界为+∞.@free取消了默认的下界为0的限制,使变量也可以取负值.@bnd用于设定一个变量的上下界,它也可以取消默认下界为0的约束.(5) 概率论中相关函数1)@pbn(p,n,x)二项分布的分布函数,当n和(或)x不是整数时,用线性插值法进行计算.2)@pcx(n,x)自由度为n的χ2分布的分布函数在x点的取值.3)@peb(load,x)当到达负荷(平均服务强度)为load,服务系统有x个服务台,且系统容量无限时的Erlang繁忙概率,多用于解决排队问题.4)@pel(load,x)当到达负荷(平均服务强度)为load,服务系统有x个服务台,系统容量为有限时的Erlang繁忙概率,多用于解决排队问题.5)@pfd(n,d,x)自由度为n和d的F分布的分布函数在x点的取值.6)@pfs(load,x,c)当负荷上限为load,顾客数为c,平行服务台数量为x时,顾客源有限的Poisson服务系统的等待或有返回顾客数的期望值.load是顾客数乘以平均服务时间,再除以平均返回时间.当c和(或)x不是整数时,采用线性插值进行计算.7)@phg(pop,g,n,x)超几何(Hypergeometric)分布的分布函数.pop表示产品总数,g是正品数.从所有产品中任意取出n(n≤pop)件.pop,g,n和x都可以是非整数,这时采用线性插值进行计算.8)@ppl(a,x)Poisson分布的线性损失函数,即返回max(0,z-x)的期望值,其中随机变量z服从均值为a的Poisson 分布.9)@pps(a,x)均值为a的Poisson分布的分布函数在x点的取值.当x不是整数时,采用线性插值进行计算.10)@psl(x)单位正态线性损失函数,即返回max(0,z-x)的期望值,其中随机变量z服从标准正态分布.11)@psn(x)标准正态分布的分布函数在x点的取值.12)@ptd(n,x)自由度为n的t分布的分布函数在x点的取值.13)@qrand(seed)产生(0,1)区间的拟随机数.@qrand只允许在模型的数据部分使用,它将用拟随机数填满集属性.通常定义一个m×n的二维表,m表示运行实验的次数,n表示每次实验所需的随机数的个数.在行内,随机数是独立分布的;在行间,随机数是非均匀的.这些随机数是用“分层取样”的方法产生的.(6) 金融函数目前LINGO提供了两个金融函数.1)@fpa(I,n)返回如下情形的净现值:单位时段利率为I,连续n个时段支付,每个时段支付单位费用.若每个时段支付x单位的费用,则净现值可用x乘以@fpa(I,n)得到.@fpa的计算公式为.净现值就是在一定时期内为了获得一定收益,在该时期初所支付的实际费用.2)@fpl(I,n)返回如下情形的净现值:单位时段利率为I,第n个时段支付单位费用.@fpl(I,n)的计算公式为.这两个函数间的关系:.(7)输入和输出函数输入和输出函数可以把模型与外部数据(如文本文件、数据库和电子表格等)连接起来.1)@file函数该函数用于从外部数据文件中输入数据,它可以放在模型中任何地方.该函数的语法格式为@file(’’).这里是文件名,可以采用相对路径和绝对路径两种表示方式.记录结束标记(~)之间的数据文件部分称为记录.如果数据文件中没有记录结束标记,那么整个文件被看作单个记录.除了记录结束标记外,从模型外部调用的文本和数据同在模型里是一样的.下面介绍一下在数据文件中的记录结束标记连同模型中@file函数调用是如何工作的.当在模型中第一次调用@file函数时,LINGO打开数据文件,然后读取第一个记录;第二次调用@file 函数时,LINGO读取第二个记录等等.文件的最后一条记录可以没有记录结束标记,当遇到文件结束标记时,LINGO会读取最后一条记录,然后关闭文件.如果最后一条记录也有记录结束标记,那么直到LINGO 求解完成模型后关闭该文件.注意,如果有多个文件同时保持打开状态,可能就会导致一些问题,LINGO允许同时打开文件的上限数是16.在LINGO中不允许嵌套调用@file函数.2)@text函数该函数被用在数据部分,用来把求解结果输出至文本文件中.它可以输出集元素和集属性值.其语法为@text([’’])这里是文件名,可以采用相对路径和绝对路径两种表示方式.如果忽略,那么数据就被输出到标准输出设备(大多数情形都是屏幕).@text函数仅能出现在模型数据部分的一条语句的左边,右边是集名(用来输出该集的所有元素名)或集属性名(用来输出该集属性的值).用接口函数产生输出的数据定义称为输出操作.输出操作仅当求解器求解完模型后才执行,执行次序取决于其在模型中出现的先后.3)@ole函数@OLE是从EXCEL中引入或输出数据的接口函数,它是基于传输的OLE技术.OLE传输直接在内存中传输数据,并不借助于中间文件.当使用@OLE时,LINGO先装载EXCEL,再通知EXCEL装载指定的电子数据表,最后从电子数据表中获得Ranges.为了使用@OLE函数,必须有EXCEL5及其以上版本.@OLE函数可在数据部分和初始部分引入数据.@OLE可以同时读集元素和集属性,集元素最好使用文本格式,集属性最好使用数值格式.原始集每个集元素需要一个单元(cell),而对于n元的派生集每个集元素需要n个单元,这里第一行的n个单元对应派生集的第一个集元素,第二行的n个单元对应派生集的第二个集元素,依此类推.4)@ranged(variable_or_row_name)为了保持最优基不变,变量的费用系数或约束行的右端项允许减少的量.5)@rangeu(variable_or_row_name)为了保持最优基不变,变量的费用系数或约束行的右端项允许增加的量.6)@status()返回LINGO求解模型后的结束状态:0 --- Global Optimum(全局最优);1 --- Infeasible(不可行);2 --- Unbounded(无界);3 --- Undetermined(不确定);4 --- Feasible(可行);5 --- Infeasible or Unbounded(通常需要关闭“预处理”选项后重新求解模型,以确定模型究竟是不可行还是无界)6 --- Local Optimum(局部最优);7 --- Locally Infeasible(局部不可行,尽管可行解可能存在,但是LINGO并没有找到一个);8 --- Cutoff(目标函数的截断值被达到);9 --- Numeric Error(求解器因在某约束中遇到无定义的算术运算而停止).通常,如果返回值不是0,4或6时,那么解将不可信,几乎不能用.该函数仅被用在模型的数据部分来输出数据.7)@dual(variable_or_row_name)返回变量的判别数(检验数)或约束行的对偶(影子)价格(dual prices).(8) 辅助函数1)@if(logical_condition,true_result,false_result)@if函数将评价一个逻辑表达式logical_condition是否为真,如果为真,返回true_ result,否则返回false_result.2)@warn(’text’,logical_condition)如果逻辑条件logical_condition为真,则产生一个内容为’text’的信息框.3)@user(user_determined_arguments)该函数允许用户自己编写函数,可以用c语言等编写,返回值为用户函数计算的结果.3.5 LINGO程序出错信息在LINGO模型求解时,系统会对程序进行编译、求解或是执行于程序相关的命令,这都有可能出现一些语法或运行的错误.当出现时,系统会弹出一个出错报告框,显示错误代码,并且大致指出错误的所在位置.这些错误信息报告对于用户发现及改正程序中的错误有很大帮助.如附表3-4就出错提示信息,进行说明(没有说明的错误编号目前还没有使用).。

Lindo 和 Lingo 是美国 Lindo 系统公司开发的一套专门用于求解最优化问题的软件包。
Lindo 用于求解线性规划和二次规划问题,Lingo 除了具有 Lindo 的全部功能外,还可以用于求解非线性规划问题,也可以用于一些线性和非线性方程(组)的求解,等等。
Lindo 和Lingo 软件的最大特色在于可以允许优化模型中的决策变量是整数(即整数规划),而且执行速度很快。
Lingo 实际上还是最优化问题的一种建模语言,包括许多常用的函数可供使用者建立优化模型时调用,并提供与其他数据文件(如文本文件、Excel电子表格文件、数据库文件等)的接口,易于方便地输入、求解和分析大规模最优化问题。
由于这些特点,Lindo系统公司的线性、非线性和整数规划求解程序已经被全世界数千万的公司用来做最大化利润和最小化成本的分析。
应用的范围包含生产线规划、运输、财务金融、投资分配、资本预算、混合排程、库存管理、资源配置等等...Lindo/Lingo 软件作为著名的专业优化软件,其功能比较强、计算效果比较好,与那些包含部分优化功能的非专业软件相比,通常具有明显的优势。
此外, Lindo/Lingo 软件使用起来非常简便,很容易学会,在优化软件(尤其是运行于个人电脑上的优化软件)市场占有很大份额,在国外运筹学类的教科书中也被广泛用做教学软件。
LingoLingo 是使建立和求解线性、非线性和整数最佳化模型更快更简单更有效率的综合工具。
Lingo 提供强大的语言和快速的求解引擎来阐述和求解最佳化模型。
简单的模型表示Lingo 可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改。
方便的数据输入和输出选择Lingo 建立的模型可以直接从数据库或工作表获取资料。
同样地,Lingo 可以将求解结果直接输出到数据库或工作表。
强大的求解引擎Lingo 内建的求解引擎有线性、非线性(convex and nonconvex)、二次、二次限制和整数最佳化。
Lingo、lindo简介一、软件概述 (1)二、快速入门 (4)三、Mathematica函数大全--运算符及特殊符号 (11)参见网址: /一、软件概述(一)简介LINGO软件是由美国LINDO系统公司研发的主要产品。
LINGO是Linear Interactive and General Optimizer的缩写,即交互式的线性和通用优化求解器。
LINGO可以用于求解非线性规划,也可以用于一些线性和非线性方程组的求解等,功能十分强大,是求解优化模型的最佳选择。
其特色在于内置建模语言,提供十几个内部函数,可以允许决策变量是整数(即整数规划,包括 0-1 整数规划),方便灵活,而且执行速度非常快。
能方便与EXCEL,数据库等其他软件交换数据。
LINGO实际上还是最优化问题的一种建模语言,包括许多常用的函数可供使用者建立优化模型时调用,并提供与其他数据文件(如文本文件、Excel 电子表格文件、数据库文件等)的接口,易于方便地输入、求解和分析大规模最优化问题。
(二)LINGO的主要特点:Lingo 是使建立和求解线性、非线性和整数最佳化模型更快更简单更有效率的综合工具。
Lingo 提供强大的语言和快速的求解引擎来阐述和求解最佳化模型。
1 简单的模型表示LINGO 可以将线性、非线性和整数问题迅速得予以公式表示,并且容易阅读、了解和修改。
LINGO的建模语言允许您使用汇总和下标变量以一种易懂的直观的方式来表达模型,非常类似您在使用纸和笔。
模型更加容易构建,更容易理解,因此也更容易维护。
2 方便的数据输入和输出选择LINGO 建立的模型可以直接从数据库或工作表获取资料。
同样地,LINGO 可以将求解结果直接输出到数据库或工作表。
使得您能够在您选择的应用程序中生成报告。
3 强大的求解器LINGO拥有一整套快速的,内建的求解器用来求解线性的,非线性的(球面&非球面的),二次的,二次约束的,和整数优化问题。
lingo数学模型
"lingo"是一种用于数学建模和优化的软件工具。
它提供了一个
直观的界面,用于建立和求解复杂的数学模型,包括线性规划、整
数规划、非线性规划、多目标规划等。
lingo的使用可以帮助分析
师和决策者在面临复杂的决策问题时进行优化决策。
在数学建模方面,lingo可以用来建立数学模型,包括定义决
策变量、约束条件和目标函数。
用户可以通过lingo的界面直观地
输入模型的各个部分,而无需深入了解数学建模的具体语法和规则。
这使得非专业的用户也能够快速地建立数学模型。
在优化方面,lingo提供了强大的求解算法,可以对各种类型
的数学模型进行求解,以找到最优的决策方案。
lingo支持对模型
进行灵敏度分析,帮助用户了解参数变化对最优解的影响,从而更
好地进行决策。
除了数学建模和优化外,lingo还具有数据可视化功能,可以
直观地展示模型的结果和决策方案。
这有助于用户向决策者传达模
型分析的结果,从而更好地支持决策过程。
总的来说,lingo作为数学建模和优化工具,为用户提供了一
个方便、强大的平台,帮助他们解决复杂的决策问题。
通过lingo,用户可以更好地理解问题、制定决策,并得到最优的解决方案。
编写LINGO 程序并求解/*最优化实验*/第一题:某班准备从5名游泳队员中选择4人组成接力队,参与学校的4*100m 混合接力比赛。
5名队员4种泳姿的百米成绩如表所示,应如何选拔队员组成接力队?解:记甲、乙、丙、丁、戊分别为队员1,2,3,4,5i =;记蝶泳、仰泳、蛙泳、自由泳分别为泳姿1,2,3,4j =,记队员i 的第j 种泳姿的百米最好成绩为()ij c s 。
决策变量:引入0-1变量ij x ,若选择队员i 参加泳姿j 的比赛,1ij x =,否则记为0ij x =。
目标函数:当队员i 入选泳姿j 时,ij ij x c 表示队员的成绩,否则0ij ij x c =。
于是接力队的成绩可以表示为5411ij ij i j f x c ===邋,这就是该问题的目标函数。
约束条件:根据组成接力队的要求,ij x 应该满足下面两个条件:每人最多只能入选4种泳姿中的一种,即对于1,2,3,4,5i =,应有411ij j x =£å;每种泳姿必须有一个人参加,即对于1,2,3,4j =,应有511ij i x ==å。
综上所述,这个问题的优化模型可写作5411min ij ij i j f x c ===邋..s t 411,1,2,3,4,5ij j x i=?å甲乙 丙 丁 戊蝶泳1’06”8 57”2 1’18” 1’10” 1’07”4仰泳1’15”6 1’06” 1’07”8 1’14”2 1’11” 蛙泳 1’27” 1’06”4 1’24”6 1’09”6 1’23”8 自由泳 58”653”59”457”21’02”4511,1,2,3,4 ijix j ===å{}0,1ijx=模型代码如下:SETS:i/1..5/;j/1..4/;SS(i,j):x;ENDSETSMIN=66.8*x11+75.6*x12+87*x13+58.6*x14+57.2*x21+66*x22+ 66.4*x23+53*x24+78*x31+67.8*x32+84.6*x33+59.4*x34+70*x 41+74.2*x42+69.6*x43+57.2*x44+67.4*x51+71*x52+83.8*x53 +62.4*x54;x11+x12+x13+x14<=1;x21+x22+x23+x24<=1;x31+x32+x33+x34<=1;x41+x42+x43+x44<=1;x51+x52+x53+x54<=1;x11+x21+x31+x41+x51=1;x12+x22+x32+x42+x52=1;x13+x23+x33+x43+x53=1;x14+x24+x34+x44+x54=1;求解这个模型,结果如下。
LINDO和LINGO是美国LINDO系统公司开发的一套专门用于求解最优化问题的软件包。
LINDO 用于求解线性规划和二次规划,LINGO除了具有LINDO的全部功能外,还可以用于求解非线性规划,也可以用于一些线性和非线性方程组的求解以及代数方程求根等。
LINDO和LINGO软件的最大特色在于可以允许优化模型中的决策变量是整数(即整数规划),而且执行速度很快。
LINGO实际上还是最优化问题的一种建模语言,包括许多常用的函数可供使用者建立优化模型时调用,并提供与其它数据文件(如文本文件、EXCEL电子表格文件、数据库文件等)的接口,易于方便地输入、求解和分析大规模最优化问题。
由于这些特点,LINDO和LINGO软件在教学、科研和工业、商业、服务等领域得到广泛应用。
1)目标函数及各约束条件之间一定要有“Subject to (ST) ”分开。
2)变量名不能超过8个字符。
3)变量与其系数间可以有空格,单不能有任何运算符号(如乘号“*”等)。
4)要输入<=或>=约束,相应以<或>代替即可。
5)一般LINDO中不能接受括号“()“和逗号“,“,例:400(X1+X2) 需写成400X1+400X2;10,000需写成10000。
6)表达式应当已经过简化。
不能出现 2 X1+3 X2-4 X1,而应写成-2X1+3 X2。
用LINDO求解施工中的线性规划(LP)问题1 引言线性规划是现代化管理的常用工具与方法,在施工过程中,很多实际问题,如配(下)料,运输(土石方调配),施工机具车辆调度,施工场地的合理设点,成品、半成品、原材料的合适库存量规划问题等等,都需要运用线性规划方法求得最优方案。
线性规划一般需要先确定要求的未知变量和目标函数,然后找出所有的约束条件,表示为线性方程或不等式,建立问题的数学模型,对于变量数目和约束条件较少的情况可用手工计算,较多的情况则需运用计算机来求解。
2 LINDO介绍LINDO是Linear INteractive and Discrete Optimizer字首的缩写形式,是由Linus Schrage 于1986年开发的优化计算软件包。