参数估计方法
- 格式:docx
- 大小:113.67 KB
- 文档页数:6


参数估计的方法及应用参数估计是统计学中的一个重要方法,用于根据已知数据估计总体的未知参数。
它是统计推断的基础,广泛应用于各个领域,包括医学、金融、市场调研等。
下面将介绍几种常见的参数估计方法及其应用。
1. 点估计点估计是参数估计中最简单的一种方法,通过计算样本数据的统计量来估计总体参数的值。
最常用的点估计方法是样本均值和样本方差,分别用来估计总体均值和总体方差。
例如,在市场调研中,可以通过抽样调查估计某一产品的平均满意度,从而评估市场反应。
2. 区间估计区间估计是参数估计中更常用的一种方法,它不仅给出了参数的一个点估计,还给出了一个区间估计,用于表达估计值的不确定性。
典型的区间估计方法有置信区间和预测区间。
2.1 置信区间置信区间是用于估计总体参数的一个区间范围,表示参数值落在该区间内的概率。
置信区间一般由样本统计量和抽样分布的分位数确定,常见的置信区间有均值的置信区间和比例的置信区间。
比如,一个医生想要估计一种药物对某种疾病的治疗效果,可以从患者中随机抽取一部分人群服用该药物,然后计算患者的治愈率。
利用样本中的治愈率和抽样分布的分位数,可以构建出一个置信区间,用于估计总体的治愈率。
2.2 预测区间预测区间是用于预测个体观测值的一个区间范围,表示个体观测值落在该区间内的概率。
和置信区间不同的是,预测区间不仅考虑参数的估计误差,还考虑了个体观测值的不确定性。
例如,在金融领域,投资者可以利用历史收益率估计某只股票的未来收益率,并通过构建预测区间来评估投资风险。
3. 极大似然估计极大似然估计是一种常用的参数估计方法,它基于样本数据的概率分布,通过寻找使得样本观测值出现的概率最大的参数值来估计总体参数。
例如,在医学研究中,研究人员可以根据已知的疾病发病率和病人的临床症状,利用极大似然估计方法来估计某一疾病的传染率。
4. 贝叶斯估计贝叶斯估计是一种基于贝叶斯统计原理的参数估计方法,它将参数看作是随机变量,并基于先验概率和样本数据来计算后验概率分布。


参数估计方法与实例例题和知识点总结一、参数估计的概念参数估计是指根据从总体中抽取的样本估计总体分布中包含的未知参数。
参数通常是描述总体分布的特征值,比如均值、方差、比例等。
二、参数估计的方法(一)点估计点估计就是用样本统计量来估计总体参数,给出一个具体的数值。
常见的点估计方法有矩估计法和最大似然估计法。
1、矩估计法矩估计法的基本思想是用样本矩来估计总体矩。
比如,用样本均值估计总体均值,用样本方差估计总体方差。
2、最大似然估计法最大似然估计法是求使得样本出现的概率最大的参数值。
它基于这样的想法:如果在一次抽样中得到了某个样本,那么这个样本出现概率最大的参数值就是总体参数的估计值。
(二)区间估计区间估计则是给出一个区间,认为总体参数以一定的概率落在这个区间内。
区间估计通常包含置信水平和置信区间两个概念。
置信水平表示区间包含总体参数的可靠程度,常见的置信水平有90%、95%和 99%。
置信区间则是根据样本数据计算得到的一个区间范围。
三、实例例题假设我们要研究某地区成年人的身高情况。
随机抽取了 100 名成年人,他们的身高数据如下(单位:厘米):165, 170, 172, 168, 175, 180, 160, 178, 176, 169,(一)点估计1、用样本均值估计总体均值:计算这 100 个数据的均值,得到样本均值为 172 厘米。
因此,我们估计该地区成年人的平均身高约为 172 厘米。
2、用样本方差估计总体方差:计算样本方差,得到约为 25 平方厘米。
(二)区间估计假设我们要以 95%的置信水平估计总体均值的置信区间。
首先,根据样本数据计算样本标准差,然后查找标准正态分布表或使用相应的统计软件,得到置信系数。
最终计算出置信区间为(168,176)厘米。
这意味着我们有 95%的把握认为该地区成年人的平均身高在 168 厘米到 176 厘米之间。
四、知识点总结(一)点估计的评价标准1、无偏性:估计量的期望值等于被估计的参数。
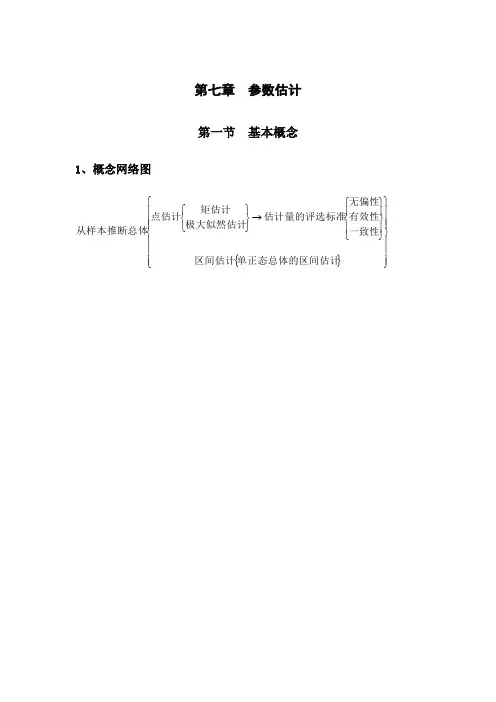
第七章 参数估计第一节 基本概念1、概念网络图{}⎪⎪⎪⎭⎪⎪⎪⎬⎫⎪⎪⎪⎩⎪⎪⎪⎨⎧⎪⎭⎪⎬⎫⎪⎩⎪⎨⎧→⎭⎬⎫⎩⎨⎧单正态总体的区间估计区间估计一致性有效性无偏性估计量的评选标准极大似然估计矩估计点估计从样本推断总体2、重要公式和结论例7.1:设总体),(~b a U X ,求对a, b 的矩估计量。
例7.2:设n x x x ,,,,21 是总体的一个样本,试证(1);2110351321x x x ++=∧μ (2);12541313212x x x ++=∧μ(3).12143313213x x x -+=∧μ都是总体均值u 的无偏估计,并比较有效性。
例7.3:设n x x x ,,,,21 是取自总体),(~2σμN X 的样本,试证∑=--=ni i x x n S 122)(11 是2σ的相合估计量。
第二节 重点考核点矩估计和极大似然估计;估计量的优劣;区间估计第三节 常见题型1、矩估计和极大似然估计例7.4:设0),,0(~>θθU X ,求θ的最大似然估计量及矩估计量。
例7.5:设总体X 的密度函数为⎪⎩⎪⎨⎧≥=--.,0,1)(/)(其他μθθμx e x f x其中θ>0, θ,μ为未知参数,n X X X ,,,21 为取自X 的样本。
试求θ,μ的极大似然估计量。
2、估计量的优劣例7.6:设n 个随机变量n x x x ,,,21 独立同分布,,)(11,1,)(122121∑∑==--===n i i n i i x x n S x n x x D σ 则(A )S 是σ的无偏估计量;(B )S 是σ的最大似然估计量; (C )S 是σ的相合估计量;(D )x S 与2相互独立。
例7.7:设总体X 的密度函数为⎪⎩⎪⎨⎧<<-=,,0,0),(6)(3其他θθθx x xx fn X X X ,,,21 是取自X 的简单随机样本。
(1) 求θ的矩估计量∧θ;(2) 求∧θ的方差D (∧θ);(3) 讨论∧θ的无偏性和一致性(相合性)。

参数估计方法及其应用参数估计是统计学中的一个重要概念,它指的是通过对样本数据的分析和统计推断,来对总体的一些未知参数进行估计。
常见的参数估计方法包括最大似然估计、贝叶斯估计和矩估计等。
最大似然估计是一种常用的参数估计方法。
它的核心思想是在给定数据的条件下,选择能使观测样本出现概率最大的参数值作为估计值。
具体过程是建立似然函数,通过最大化似然函数来得到参数的估计值。
最大似然估计方法简单直观,适用于大样本情况下的参数估计,广泛应用于一般统计推断、回归分析、生存分析等领域。
贝叶斯估计是另一种常用的参数估计方法,它是基于贝叶斯定理而提出的。
贝叶斯估计通过结合主观先验信息和样本数据,得到后验概率分布,从而对未知参数进行估计。
与最大似然估计相比,贝叶斯估计方法更加灵活,能够处理小样本、少数据情况下的参数估计。
贝叶斯估计在贝叶斯统计推断、医学诊断、决策分析等领域有广泛应用。
矩估计是一种基于矩的参数估计方法。
矩估计的基本思想是通过样本矩与理论矩的对应关系,建立矩方程组并求解参数。
具体过程是根据样本矩的计算公式,将理论矩与样本矩相等,得到参数的估计值。
矩估计方法简单易行,适用于大样本和小样本情况,广泛应用于生物学、社会科学等领域。
不同的参数估计方法适用于不同的情况和问题。
最大似然估计适用于大样本情况下,可以得到渐近无偏且有效的估计量;贝叶斯估计适用于小样本情况和需要主观先验信息的估计问题;矩估计适用于样本矩存在可计算公式的情况下的参数估计。
此外,还有其他一些参数估计方法,如偏最小二乘估计、缩小估计等。
除了以上常见的参数估计方法,实际应用中也可以根据具体情况发展新的估计方法。
例如,针对数据存在缺失的情况,可以采用最大似然估计的EM算法;对于非参数估计问题,可以使用核密度估计、经验贝叶斯方法等。
不同的参数估计方法有不同的优势和适用范围,选择合适的方法对于得到准确的参数估计结果是非常重要的。
总之,参数估计是统计学中的重要概念,通过对样本数据的分析和统计推断,来对总体的一些未知参数进行估计。

总体参数估计的方法与比较统计学中的总体参数估计是为了根据样本数据来推断总体的一些特征或指标,以帮助我们了解和分析问题。
常见的参数包括总体均值、总体方差、总体比例等。
总体参数估计的方法有很多,每种方法有其优势和适用范围。
本文将介绍几种常见的总体参数估计方法,并进行比较。
一、点估计方法点估计是通过样本数据来估计总体参数的一种方法。
最常用的点估计方法是最大似然估计和矩估计。
1. 最大似然估计:最大似然估计是通过寻找使观测到的样本数据出现的概率达到最大的参数值来估计总体参数。
它利用样本数据的信息,选择出使样本数据出现的可能性最大的总体参数估计值。
最大似然估计方法的优点在于拟合性好,当样本容量大且满足一定条件时,估计结果通常具有较好的性质。
2. 矩估计:矩估计是通过对样本矩的观察来估计总体参数。
矩估计方法基于样本的矩与总体的矩之间的关系进行参数估计。
它不需要对总体分布做出具体的假设,适用范围较广。
矩估计方法的优点在于简单易懂,计算方便。
二、区间估计方法点估计只给出了一个具体的数值,而区间估计则给出一个范围,用来估计总体参数的可能取值区间。
常见的区间估计方法有置信区间估计和预测区间估计。
1. 置信区间估计:置信区间估计是在给定置信水平的情况下,通过样本数据得到总体参数的估计区间。
例如,我们可以通过样本数据得到一个总体均值的置信区间,表明有置信水平的概率下,总体均值落在估计的区间内。
置信区间估计方法的优点在于提供了对总体参数的估计不确定性的量化。
2. 预测区间估计:预测区间估计是在给定置信水平的情况下,通过样本数据得到未来观测的总体参数的估计区间。
与置信区间估计不同的是,预测区间估计对未来观测提供了一个对总体参数的估计范围。
预测区间估计方法的优点在于可以用于预测和决策。
三、方法比较与选择在实际应用中,我们需要根据具体问题选择适合的总体参数估计方法。
下面列举一些比较常见的情况,并给出对应的适用方法。
1. 总体分布已知的情况下,样本容量大:此时最大似然估计方法是一个很好的选择。

参数估计的三种方法参数估计是统计学中的一项重要任务,其目的是通过已知的样本数据来推断未知的总体参数。
常用的参数估计方法包括点估计、区间估计和最大似然估计。
点估计是一种常见的参数估计方法,其目标是通过样本数据估计出总体参数的一个“最佳”的值。
其中最简单的点估计方法是样本均值估计。
假设我们有一个总体,其均值为μ,我们从总体中随机抽取一个样本,并计算出样本的平均值x。
根据大数定律,当样本容量足够大时,样本均值会无偏地估计总体均值,即E(x) = μ。
因此,我们可以用样本的平均值作为总体均值的点估计。
另一个常用的点估计方法是极大似然估计。
极大似然估计的思想是寻找参数值,使得给定观测数据出现的概率最大。
具体来说,我们定义一个参数θ的似然函数L(θ|x),其中θ是参数,x是观测数据。
极大似然估计即求解使得似然函数取得最大值的θ值。
举个例子,假设我们有一个二项分布的总体,其中参数p表示成功的概率,我们从总体中抽取一个样本,得到x个成功的观测值。
那么,样本观测出现的概率可以表示为二项分布的概率质量函数,即L(p|x) = C(nx, x) * p^x * (1-p)^(n-x),其中C(nx, x)是组合数。
我们通过求解使得似然函数取得最大值的p值,来估计总体成功的概率。
与点估计相比,区间估计提供了一个更加全面的参数估计结果。
区间估计指的是通过样本数据推断总体参数的一个区间范围。
常用的区间估计方法包括置信区间和预测区间。
置信区间是指通过已知样本数据得到的一个参数估计区间,使得这个估计区间能以一个预先定义的置信水平包含总体参数的真值。
置信水平通常由置信系数(1-α)来表示,其中α为显著性水平。
置信区间的计算方法根据不同的总体分布和参数类型而异。
举个例子,当总体为正态分布且总体方差已知时,可以利用正态分布的性质计算得到一个置信区间。
预测区间是指通过对总体参数的一个估计,再结合对新样本观测的不确定性,得到一个对新样本值的一个区间估计。

经典参数估计方法:普通最小二乘(OLS)、最大似然(ML)和矩估计(MM)普通最小二乘估计(Ordinary least squares,OLS)1801年,意大利天文学家朱赛普.皮亚齐发现了第一颗小行星谷神星。
经过40天的跟踪观测后,由于谷神星运行至太阳背后,使得皮亚齐失去了谷神星的位置。
随后全世界的科学家利用皮亚齐的观测数据开始寻找谷神星,但是根据大多数人计算的结果来寻找谷神星都没有结果。
时年24岁的高斯也计算了谷神星的轨道。
奥地利天文学家海因里希.奥尔伯斯根据高斯计算出来的轨道重新发现了谷神星。
高斯使用的最小二乘法的方法发表于1809年他的著作《天体运动论》中。
法国科学家勒让德于1806年独立发现“最小二乘法”,但因不为世人所知而默默无闻。
勒让德曾与高斯为谁最早创立最小二乘法原理发生争执。
1829年,高斯提供了最小二乘法的优化效果强于其他方法的证明,因此被称为高斯-莫卡夫定理。
最大似然估计(Maximum likelihood,ML)最大似然法,也称最大或然法、极大似然法,最早由高斯提出,后由英国遗传及统计学家费歇于1912年重新提出,并证明了该方法的一些性质,名称“最大似然估计”也是费歇给出的。
该方法是不同于最小二乘法的另一种参数估计方法,是从最大似然原理出发发展起来的其他估计方法的基础。
虽然其应用没有最小二乘法普遍,但在计量经济学理论上占据很重要的地位,因为最大似然原理比最小二乘原理更本质地揭示了通过样本估计总体的内在机理。
计量经济学的发展,更多地是以最大似然原理为基础的,对于一些特殊的计量经济学模型,最大似然法才是成功的估计方法。
对于最小二乘法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该使得模型能最好地拟合样本数据;而对于最大似然法,当从模型总体随机抽取n组样本观测值后,最合理的参数估计量应该是使得从模型中抽取该n组样本观测值的概率最大。
从总体中经过n次随机抽取得到的样本容量为n的样本观测值,在任一次随机抽取中,样本观测值都以一定的概率出现。

参数估计与假设检验的基本方法参数估计和假设检验是统计学中常用的方法,用于从样本数据中获取关于总体的信息,并进行推断和判断。
本文将介绍参数估计和假设检验的基本概念、方法以及相关的应用。
一、参数估计的基本概念和方法参数估计是通过样本数据对总体参数进行估计的方法,其目标是利用样本数据推断总体分布的性质。
下面我们将介绍两种常用的参数估计方法。
1. 点估计点估计是根据样本数据估计总体参数的具体数值,通常使用样本均值、样本方差等统计量作为总体参数的估计值。
点估计的优点是计算简单、易于理解,但是由于样本容量有限,点估计的估计误差往往较大。
2. 区间估计区间估计是对总体参数的估计给出一个区间,这个区间包含了真实参数值的可能范围。
常用的区间估计方法有置信区间和预测区间。
其中,置信区间是用于估计总体参数的取值范围,预测区间则是用于对新观测值进行预测的范围估计。
区间估计相比点估计更为准确,它给出了总体参数可能取值的范围,提供了对参数估计的不确定性的认识。
二、假设检验的基本概念和方法假设检验是用于判断总体参数的某个假设是否成立的方法。
在假设检验中,我们首先提出原假设(H0)和备择假设(H1),再通过计算样本数据得到的统计量与假设的理论值进行比较,从而判断原假设是否成立。
1. 原假设与备择假设原假设是我们在开始假设检验时先提出的假设,一般来说,原假设是我们希望能够支持的假设,例如总体均值等于某个值。
备择假设则是原假设的对立,表示我们希望能够反驳的假设,例如总体均值不等于某个值。
2. 显著性水平和拒绝域显著性水平是在假设检验中事先设定的一个值,表示在原假设成立的情况下,出现假阳性(错误拒绝原假设)的概率。
一般常用的显著性水平有0.05和0.01。
拒绝域则是由显著性水平确定的,当样本的统计量落入拒绝域时,我们拒绝原假设。
通过计算样本数据得到的统计量与假设的理论值进行比较,可以得到一个p值,p值表示在原假设成立的情况下,观察到的统计量或更极端情况出现的概率。

统计学中的参数估计方法统计学是一门研究收集、分析和解释数据的学科。
在统计学中,参数估计是其中一个重要的概念,它允许我们通过样本数据来推断总体的特征。
本文将介绍统计学中常用的参数估计方法,包括点估计和区间估计。
一、点估计点估计是一种通过样本数据来估计总体参数的方法。
在点估计中,我们选择一个统计量作为总体参数的估计值。
常见的点估计方法有最大似然估计和矩估计。
最大似然估计是一种基于样本数据的估计方法,它通过选择使得观察到的数据出现的概率最大的参数值来估计总体参数。
最大似然估计的核心思想是找到一个参数估计值,使得观察到的数据在该参数下出现的概率最大化。
最大似然估计方法在统计学中被广泛应用,它具有良好的渐进性质和统计学性质。
矩估计是另一种常用的点估计方法,它基于样本矩的性质来估计总体参数。
矩估计的核心思想是将样本矩与总体矩相等,通过求解方程组来得到参数的估计值。
矩估计方法相对简单,易于计算,但在样本较小或总体分布复杂的情况下,可能会出现估计不准确的问题。
二、区间估计区间估计是一种通过样本数据来估计总体参数的方法,它提供了参数估计的置信区间。
在区间估计中,我们通过计算样本数据的统计量和抽样分布的性质,得到一个包含真实参数的区间。
置信区间是区间估计的核心概念,它是一个包含真实参数的区间。
置信区间的计算依赖于样本数据的统计量和抽样分布的性质。
常见的置信区间计算方法有正态分布的置信区间和bootstrap置信区间。
正态分布的置信区间是一种常用的区间估计方法,它基于样本数据的统计量服从正态分布这一假设。
通过计算样本数据的均值和标准差,结合正态分布的性质,我们可以得到一个包含真实参数的置信区间。
Bootstrap置信区间是一种非参数的区间估计方法,它不依赖于总体分布的假设。
Bootstrap方法通过从原始样本中有放回地抽取样本,生成大量的重采样数据集,并计算每个重采样数据集的统计量。
通过分析这些统计量的分布,我们可以得到一个包含真实参数的置信区间。
参数估计的方法有
以下几种方法:
1. 最大似然估计(Maximum Likelihood Estimation, MLE):利用数据样本的信息,寻找参数的取值,使得样本出现的概率最大。
2. 最小二乘估计(Least Squares Estimation, LSE):在一组在某些方面“不完美"的观测值与模型估计值之间,寻找一个最佳拟合直线(或其他曲线),使得它们之间的残差平方和最小。
3. 贝叶斯估计(Bayesian Estimation):在先验分布和数据的基础之上,利用贝叶斯公式推导出后验分布,从而得到参数的估计值。
4. 矩估计(Moment Estimation):以样本矩估计总体矩的方法来估计参数。
5. 似然比检验估计(Likelihood Ratio Estimation):将最大似然值与模型的交集和样本容差进行比较,从而确定参数的估计值。
6. 非参数估计方法(Nonparametric Estimation):不需要对总体分布进行任何假设,在方法上不依赖于总体的形式。
参数估计方法
参数估计(Parameter Estimation)是统计学中重要的一个研究目标,也是机器学习
领域中重要的一个问题。
参数估计的目的是从给定的数据中求取一组模型参数,使得模型
最能拟合数据。
常用的参数估计方法有最小二乘法(Least Squares)、极大似然法(Maximum Likelihood)等。
最小二乘法是一种估计统计模型参数的经典方法,其基本思想是求解使得拟合散点的
模型函数的残差的平方和最小的参数向量。
它的优点是简单易行,但不能解决线性模型参
数求解问题而有多解的情况。
极大似然法是在概率论和统计学中广泛使用的参数估计技术,它的基本思想是找到使
出现观测数据最有可能的模型参数,即概率估计参数使得所有观测数据的联合概率(likelihood)最大。
优点是可以给出参数的分布关系,而每个参数的准确值也可以得到。
缺点是计算难度稍大。
此外,对参数估计的选择也会受到具体的应用背景的影响。
例如,在机器学习中,如
果所需要估计的参数太多,可以考虑使用正则化技术,通过引入一定的约束条件来达到减
少估计参数数量的目的。
因此,在实际应用中如何正确选择参数估计方法,以求得最符合实际情况的模型参数,是相当重要的研究课题。
参数估计的若干方法及应用
参数估计是指在一组观测数据或实验结果中,出最有效的参数值,以
满足实验结果或经验数据的最佳拟合,是机器学习和统计学中重要的技术,也是数据挖掘的核心过程。
参数估计通常分为经验参数估计法和概率参数
估计法,它们的估计结果和拟合效果是不同的。
一、经验参数估计法
经验参数估计法是一种基于经验数据的唯一参数估计方法,它只需要
对历史数据进行几次迭代就可以得出拟合参数的估计值,它的优点是可以
迅速收敛,有利于提高算法的效率。
常用的经验参数估计法包括最小二乘法、最小平方误差法、平滑最小二乘法、弦截法等。
(1)最小二乘法是一种经典的经验参数估计方法,它最大程度地减
少了数据拟合时的残差,也就是预测值和实际值之间的差异。
它将残差的
平方和作为优化的目标函数,最小二乘法的优化问题可以用矩阵的形式进
行求解。
(2)最小平方误差法是求解参数矩阵的有效方法,它是基于极大似
然估计的,通过极大似然法求解参数,来得到一个使得观测数据出现的概
率最大的参数矩阵,这样就可以得出一组最优参数。
(3)平滑最小二乘法是一种非线性的经验参数估计法,它的目的是
使参数矩阵有一个均匀的变化。
参数估计的方法矩法一、矩的概念矩(moment )分为原点矩和中心矩两种。
对于样本n y y y ,,, 21,各观测值的k 次方的平均值,称为样本的k 阶原点矩,记为k y ,有∑==n i k i k y n y 11,例如,算术平均数就是一阶原点矩;用观测值减去平均数得到的离均差的k 次方的平均数称为样本的k 阶中心矩,记为k y y )(-或k μˆ,有∑-=-=ni k i k y y n y y 1)(1)(,例如,样本方差∑-=n i i y y n 12)(1就是二阶中心矩。
对于总体N y y y ,,, 21,各观测值的k 次方的平均值,称为总体的k 阶原点矩,记为)(k y E ,有∑==N i k i k y N y E 11)(;用观测值减去平均数得到的离均差的k 次方的平均数称为总体的k 阶中心矩,记为])[(k y E μ-或k μ,有∑-=-=N i k i k y N y E 1)(1])[(μμ。
二、矩法及矩估计量所谓矩法就是利用样本各阶原点矩来估计总体相应各阶原点矩的方法,即 ∑==n i ki k y n y 11→)(k y E(8·6)并且也可以用样本各阶原点矩的函数来估计总体各阶原点矩同一函数,即若))(,),(),((k y E y E y E f Q 2=则),,,(k y y y f Q 2ˆ= 由此得到的估计量称为矩估计量。
[例8.1] 现获得正态分布),(2σμN 的随机样本n y y y ,,, 21,要求正态分布),(2σμN 参数μ和2σ的矩估计量。
首先,求正态分布总体的1阶原点矩和2阶中心矩:⎰=⎥⎦⎤⎢⎣⎡--⋅=⎰=∞+∞-∞+∞-μσμσπdy y y dy y yf y E 22exp 2)(21)()( (此处⎥⎦⎤⎢⎣⎡--22exp σμ2)(y 表示自然对数底数e 的⎥⎦⎤⎢⎣⎡--22σμ2)(y 的指数式,即][2)(22σμ--y e )22222exp σσμσπμμμ⎰=⎥⎦⎤⎢⎣⎡--⋅-=⎰-=-∞+∞-∞+∞-dy y y dy y f y y E 2)(21)()()()][(2 然后求样本的1阶原点矩和2阶中心矩,为∑-==∑====n i i n i i y y n s y n y 12221ˆˆ)(1,1μμ 最后,利用矩法,获得总体平均数和方差的矩估计 ∑-==∑====n i i ni i y y n s y n y 12221ˆˆ)(1,1σμ故总体平均数和方差的矩估计值分别为样本平均数和样本方差,方差的分母为n 。
参数估计的方法矩法一、矩的概念矩(moment )分为原点矩和中心矩两种。
对于样本n y y y ,,, 21,各观测值的k 次方的平均值,称为样本的k 阶原点矩,记为k y ,有∑==ni kiky ny 11,例如,算术平均数就是一阶原点矩;用观测值减去平均数得到的离均差的k 次方的平均数称为样本的k 阶中心矩,记为ky y )(-或k μˆ,有∑-=-=ni ki ky y ny y 1)(1)(,例如,样本方差∑-=ni i y y n12)(1就是二阶中心矩。
对于总体N y y y ,,, 21,各观测值的k 次方的平均值,称为总体的k 阶原点矩,记为)(k y E ,有∑==Ni kik y Ny E 11)(;用观测值减去平均数得到的离均差的k 次方的平均数称为总体的k 阶中心矩,记为])[(ky E μ-或kμ,有∑-=-=Ni ki ky Ny E 1)(1])[(μμ。
二、矩法及矩估计量所谓矩法就是利用样本各阶原点矩来估计总体相应各阶原点矩的方法,即 ∑==ni kiky ny11→)(k y E(8·6)并且也可以用样本各阶原点矩的函数来估计总体各阶原点矩同一函数,即若))(,),(),((ky E y E y E f Q 2= 则),,,(k y y y f Q 2ˆ=由此得到的估计量称为矩估计量。
[例8.1] 现获得正态分布),(2σμN 的随机样本n y y y ,,, 21,要求正态分布),(2σμN 参数μ和2σ的矩估计量。
首先,求正态分布总体的1阶原点矩和2阶中心矩:⎰=⎥⎦⎤⎢⎣⎡--⋅=⎰=∞+∞-∞+∞-μσμσπdy y y dy y yf y E 22exp 2)(21)()((此处⎥⎦⎤⎢⎣⎡--22exp σμ2)(y 表示自然对数底数e的⎥⎦⎤⎢⎣⎡--22σμ2)(y 的指数式,即][2)(22σμ--y e )22222e x p σσμσπμμμ⎰=⎥⎦⎤⎢⎣⎡--⋅-=⎰-=-∞+∞-∞+∞-dy y y dy y f y y E 2)(21)()()()][(2然后求样本的1阶原点矩和2阶中心矩,为∑-==∑====ni i ni i y y ns y ny 12221ˆˆ)(1,1μμ最后,利用矩法,获得总体平均数和方差的矩估计∑-==∑====ni i ni i y y nsy ny 12221ˆˆ)(1,1σμ故总体平均数和方差的矩估计值分别为样本平均数和样本方差,方差的分母为n 。
单峰分布曲线还有二个特征数,即偏度(skewness )与峰度(kurtosis ),可分别用三阶中心矩3μ和四阶中心矩4μ来度量。
但3μ和4μ是有单位的,为转化成相对数以便不同分布之间的比较,可分别用偏度系数和峰度系数作测度。
偏度系数(coefficient of skewness )是指3阶中心矩与标准差的3次方之比;峰度系数(coefficient of kurtosis )是指4阶中心矩与标准差的4次方之比。
当偏度为正值时,分布向大于平均数方向偏斜;偏度为负值时则向小于平均数方向偏斜;当偏度的绝对值大于2时,分布的偏斜程度严重。
当峰度大于3时,分布比较陡峭,峰态明显,即总体变数的分布比较集中。
由样本计算的偏度系数cs =231i 21i 3)(1)(1⎥⎦⎤⎢⎣⎡∑-∑-===ni ni y y n y y n33ˆˆσμ(8·7)峰度系数ck =241i 21i 4)(1)(1⎥⎦⎤⎢⎣⎡∑-∑-===ni ni y y n y y n44ˆˆσμ(8·8)最小二乘法从总体中抽出的样本观察值与总体平均数是有差异的,这种差异属于抽样误差。
因而,在总体平均数估计时要尽可能地降低这种误差,使总体平均数估计值尽可能好。
参数估计的最小二乘法就是基于这种考虑提出的。
其基本思想是使误差平方和最小,达到在误差之间建立一种平衡,以防止某一极端误差对决定参数的估计值起支配地位。
这有助于揭示更接近真实的状况。
具体方法是为使误差平方和Q 为最小,可通过求Q 对待估参数的偏导数,并令其等于0,以求得参数估计量。
[例8.4] 用最小二乘法求总体平均数μ的估计量。
若从平均数为μ的总体中抽得样本为y 1、y 2、y 3、…、y n ,则观察值可剖分为总体平均数μ与误差e i 之和,ii e y +=μ总体平均数μ的最小二乘估计量就是使y i 与μ间的误差平方和为最小,即∑-=∑==ni i i y eQ 12ˆ2)(μ为最小。
为获得其最小值,求Q 对μ的导数,并令导数等于0,可得:0)(2=∑--=∂∂=ni i y Q 1ˆμμ即总体平均数的估计量为:∑==ni iy n1ˆ1μ因此,算术平均数为总体平均数的最小二乘估计。
这与矩法估计是一致的。
此处顺便介绍估计离均差平方和2)(y y Q i -∑='的数学期望: ])([])([)(22μμ+--∑=-∑='y y E y y E Q E i inn n y y E y y y y E i i i /])(-)([])())((2-)([222222σσμμμμμμ-=-∑-∑=-∑+--∑-∑==(n -1)2σ 因而,2σ估计为:2ˆσ=1)(1)(-∑-=-'n y y n Q i 2)( 与矩法所得不同,而与常规以自由度为除数法一致。
[例8.5] 求例6.13的两向分组方差分析资料缺1个小区(表8.1)的最小二乘估计量和估计值。
从第6章可知,这种资料模式的线性模型为:ij j i ij y εβτμ+++=。
该模型的约束条件为:∑==a i i 10τ,∑==rj j 10β和误差项服从正态分布。
按照最小二乘法的估计原理,使∑∑∑---=∑===a i j i ij rj ij y Q 1212ˆ)(βτμε为最小时可以求出效应和缺失小区y e 的估计量,即⎪⎪⎪⎪⎪⎩⎪⎪⎪⎪⎪⎨⎧∑∑=---=∂∂∑=----=∂∂∑=----=∂∂∑∑=----=∂∂======a i rj j i ij ea i j i ij j r j j i ij ia i r j j i ij y y Qy Qy Q y Q1111110)2(01))(2(01))(2(01))(2(βτμβτμββτμτβτμμ从而,最小二乘估计量分别为:∑∑-∑+∑=++=∑∑-∑=-=∑∑-∑=-=∑∑==============a i rj ija i ij r j ij j i e ai rj ijai ij jj a i rj ij rj ij i i a i rj ijy ar y a y r y y ary ay y y ar y r y y y ary 111111111111ˆˆˆˆˆˆˆ11111111βτμβτμ缺区估计是根据线性模型,以及最小二乘法的原理得到的。
不过,试验中尽可能不要缺区,因为缺区估计尽管可以估计缺区的值,但是误差的自由度将减少,本试验的误差自由度将减少1。
一般地,若m 个自变数x 1、x 2、x 3、…、x m 与依变数y 存在统计模型关系 εθθθ+=),,,;,,,(k m x x x f y 2121 (8·9) 其中,k θθθ,,, 21为待估参数。
通过n 次观测(n >k )得到n 组含有),1,2,(,,,,n i y x x x i mi i i =21的数据以估计kθθθ,,, 21。
其最小二乘估计值为使22121112][ˆ),,,;,,,(k mi i i i ni ni x x x f y Q θθθε -∑∑==== (8·10)为最小的k θθθˆˆˆ21,,, 。
这种估计方法称为参数估计的最小二乘法(least squares ),或最小平方法。
第9章将应用最小二乘法估计线性回归中有关参数的估计量,此处不再赘述。
极大似然法极大似然法(maximum likelihood method )是参数估计的重要方法。
首先,通过举例来说明其思路。
例如,有1个射手射击3次,命中0次。
试问该射手的命中概率最有可能为3个命中概率:1/5、8/15和4/5中的哪一个?回答该问题可以从两方面来看,一方面,该射手的命中率为0,与此最接近的命中概率为1/5,即1/5最有可能;另一方面,分别假定该射手的命中率为1/5、8/15和4/5,根据二项分布原理分别计算出该射手射击3次命中0次的概率分别为:337527)54(1)54(,3375343)158(1)158(,33751728)51(1)51(300330033003=-=-=-C C C因此,选择使事件发生概率最大的可能命中概率为1/5,从而认为该射手的命中概率最有可能为1/5。
这种参数估计方法称为极大似然法。
极大似然法,包括二个步骤:首先建立包括有该参数估计量的似然函数(likelihood function ),然后根据实验数据求出似然函数达极值时的参数估计量或估计值。
上面根据二项分布计算概率,因而包含有待估概率的二项分布便是似然函数,它是关于待估参数的函数。
由于试验结果是由总体参数决定的,那么参数估计值就应该使参数真值与试验结果尽可能一致,似然函数正是沟通参数与试验结果一致性的函数。
一、似然函数对于离散型随机变量,似然函数是多个独立事件的概率函数的乘积,该乘积是概率函数值,它是关于总体参数的函数。
例如,一只大口袋里有红、白、黑3种球,采用复置抽样50次,得到红、白、黑3种球的个数分别为12,24,14,那么根据多项式的理论,可以建立似然函数为:143242121)()()(12!24!14!50!p p p其中p 1,p 2,p 3分别为口袋中红、白、黑3种球的概率(p 3=1-p 1-p 2),它们是需要估计的。
对于连续型随机变量,似然函数是每个独立随机观测值的概率密度函数的乘积,则似然函数为:);();();();,,,()(θθθθθn n y f y f y f y y y L L 2121== (8·11)若y 1服从正态分布),(2σμN ,则),(σμθ=,上式可变为:])()[(212)(2)(221222221222μμσσμσμσπσπσπσμ-++------==n n y y ny y ee e L)1(11),((8·12)二、极大似然估计所谓极大似然估计就是指使似然函数为最大以获得总体参数估计的方法。
其中,所获得的估计总体参数的表达式称为极大似然估计量,由该估计量获得的总体参数的估计值称为总体参数的极大似然估计值。
为了计算上的方便,一般将似然函数取对数,称为对数似然函数,因为取对数后似然函数由乘积变为加式,其表达式为:∑===ni i n y f y y y L L 121,ln ln ln )();,,,()(θθθ(8·13)通过对数似然函数和似然函数的极大化以估计总体参数的结果是一致的,一般说来,前者在计算上要容易处理些。