第四章条件异方差模型
- 格式:pdf
- 大小:2.31 MB
- 文档页数:46

第4章违背基本假设的情况思考与练习参考答案4.1 试举例说明产生异方差的原因。
答:例4.1:截面资料下研究居民家庭的储蓄行为Y i=β0+β1X i+εi其中:Y i表示第i个家庭的储蓄额,X i表示第i个家庭的可支配收入。
由于高收入家庭储蓄额的差异较大,低收入家庭的储蓄额则更有规律性,差异较小,所以εi的方差呈现单调递增型变化。
例4.2:以某一行业的企业为样本建立企业生产函数模型Y i=A iβ1K iβ2L iβ3eεi被解释变量:产出量Y,解释变量:资本K、劳动L、技术A,那么每个企业所处的外部环境对产出量的影响被包含在随机误差项中。
由于每个企业所处的外部环境对产出量的影响程度不同,造成了随机误差项的异方差性。
这时,随机误差项ε的方差并不随某一个解释变量观测值的变化而呈规律性变化,呈现复杂型。
4.2 异方差带来的后果有哪些?答:回归模型一旦出现异方差性,如果仍采用OLS估计模型参数,会产生下列不良后果:1、参数估计量非有效2、变量的显著性检验失去意义3、回归方程的应用效果极不理想总的来说,当模型出现异方差性时,参数OLS估计值的变异程度增大,从而造成对Y的预测误差变大,降低预测精度,预测功能失效。
4.3 简述用加权最小二乘法消除一元线性回归中异方差性的思想与方法。
答:普通最小二乘估计就是寻找参数的估计值使离差平方和达极小。
其中每个平方项的权数相同,是普通最小二乘回归参数估计方法。
在误差项等方差不相关的条件下,普通最小二乘估计是回归参数的最小方差线性无偏估计。
然而在异方差的条件下,平方和中的每一项的地位是不相同的,误差项的方差大的项,在残差平方和中的取值就偏大,作用就大,因而普通最小二乘估计的回归线就被拉向方差大的项,方差大的项的拟合程度就好,而方差小的项的拟合程度就差。
由OLS 求出的仍然是的无偏估计,但不再是最小方差线性无偏估计。
所以就是:对较大的残差平方赋予较小的权数,对较小的残差平方赋予较大的权数。

第三节 自回归条件异方差(ARCH)模型金融时间序列数据通常表现出一种所谓的集群波动现象。
模型随机误差项中同时含有自相关和异方差。
一、ARCH 模型 (Auto-regressive Conditional Heteroskedastic —自回归条件异方差模型)对于回归模型t kt k t t x b x b b y ε++++= 110 (3.3.1) 若2t ε服从AR (q )过程 t q t q t t νεαεααε++++=--221102 (3.3.2) 其中tν独立同分布,并满足0)(=t E ν , 2)(σν=tD 则称(3.3.2)式为ARCH 模型,序列t ε服从q 阶ARCH 过程,记为t ε~ARCH (q )。
(3.3.1)和(3.3.2)称为回归—ARCH 模型。
注:不同时点t ε的方差2)(t t D σε=是不同的。
对于AR (p )模型t p t p t t y y y εφφ+++=-- 11 (3.3.3) 如果tε~ARCH (q ),则(3.3.3)与(3.3.2)结合称为AR (p )-ARCH (q )模型。
ARCH (q )模型还可以表示为 *t t h =εt ν (3.3.4)21022110jt q j q t q t t h -=--∑+=+++=εααεαεααα (3.3.5)其中,tν独立同分布,且0)(=t E ν,1)(=tD ν,00>α 0≥j α)2,1(q j = 且11<∑=q j j α(保证ARCH 平稳)。
有时,(3.3.5)式等号右边还可以包括外生变量,但要注意应保证th 值是非负的。
如:p t p t q t q t t h h h ----++++++=θθεαεαα 1122110 1011<+<∑∑==p j j q i iθα对于任意时刻t ,条件期望E (tε| ,1-t ε)=0)(*=t t E h ν (3.3.6)条件方差t t t t t h E h E ==-)(*),|(2212νεσ (3.3.7) (3.3.7)式反映了序列条件方差随时间而变化。

一、 选择题。
1、在DW 检验中,当d 统计量为0时,表明( )。
A 、存在完全的正自相关B 、存在完全的负自相关C 、不存在自相关D 、不能判定 2、在检验异方差的方法中,不正确的是( )。
A 、 Goldfeld-Quandt 方法B 、ARCH 检验法C 、 White 检验法D 、 DW 检验法 3、t X 的2阶差分为 ( )。
A 、2=t t t k X X X -∇-B 、2=t t t k X X X -∇∇-∇ C 、21=t t t X X X -∇∇-∇ D 、2-12=t t t X X X -∇∇-∇4、ARMA(p,q)模型的特点是( )。
A 、自相关系数截尾,相关系数拖尾B 、自相关系数拖尾,相关系数截尾C 、自相关系数截尾,相关系数截尾D 、自相关系数拖尾,相关系数拖尾 5、以下选项中,正确地表达了序列相关的是( )。
A 、 (,)0,i j Cov i j μμ≠≠ B 、 (,)0,i j Cov i j μμ=≠ C 、 (,)0,i j Cov X X i j =≠ D 、 (,)0,i j Cov X i j μ≠≠6、在线性回归模型中,若解释变量1i X 和2i X 的观测值有如1220i i X X +=的关系,则表明模型中存在( )。
A 、 异方差B 、 多重共线性C 、 序列自相关D 、 设定误差 7、如果样本回归模型残差的一阶自相关系数ρ接近于0,那么DW 统计量的值近似等于( )A 、0B 、1C 、2D 、48、当多元回归模型中的解释变量存在完全多重共线性时,下列哪一种情况会发生( ) A 、OLS 估计量仍然满足无偏性和有效性; B 、OLS 估计量是无偏的,但非有效; C 、OLS 估计量有偏且非有效; D 、无法求出OLS 估计量。
9、在多元线性线性回归模型中,解释变量的个数越多,则可决系数R 2( )A 、越大;B 、越小;C 、不会变化;D 、无法确定 二、填空题。

时间序列计量经济学模型概述时间序列计量经济学模型是在经济学研究中广泛使用的一种方法,用于分析经济变量随时间的变化。
该模型基于时间序列数据,即经济变量在一段时间内的观测值。
时间序列计量经济学模型的核心是建立经济变量之间的关系,以解释和预测经济现象的变化。
其中最常用的模型是自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)和季节性时间序列模型。
自回归移动平均模型(ARMA)是一个包含自回归项和移动平均项的线性模型。
该模型以过去的观测值和随机项为输入,预测当前观测值。
ARMA模型基于假设,即经济变量的行为受到历史观测值的影响。
自回归条件异方差模型(ARCH)是一种考虑了随时间变化方差的模型。
该模型通过引入一个条件异方差项,模拟经济变量中的波动性。
ARCH模型的应用范围广泛,特别是在金融市场波动性分析中。
季节性时间序列模型用于分析具有明显季节性特征的经济变量,如销售额、就业人数等。
这些模型通常基于季节、趋势和随机成分的组合,以预测未来观测值。
在建立时间序列计量经济学模型时,常常需要进行模型识别、参数估计和模型诊断等步骤。
识别模型的目标是确定适当的模型结构,参数估计则是利用历史数据估计模型的参数值。
模型诊断用于检验模型的拟合程度和误差分布是否符合模型假设。
时间序列计量经济学模型在经济研究中有广泛的应用,例如预测未来经济指标、分析经济周期和波动性、评估政策效果等。
它提供了一种量化的方法,使经济学家可以更好地理解和解释经济变量的演变。
时间序列计量经济学模型是经济学研究中一种重要的统计工具,广泛应用于宏观经济、金融市场和企业经营等领域。
它可以帮助我们理解和解释经济变量随时间的变化规律,进行预测和政策分析。
本文将进一步探讨时间序列计量经济学模型的相关概念和应用。
在构建时间序列计量经济学模型之前,首先需要了解时间序列数据的特点。
时间序列数据是按照时间顺序排列的一系列观测值,通常具有趋势性、季节性、周期性和随机性等特征。


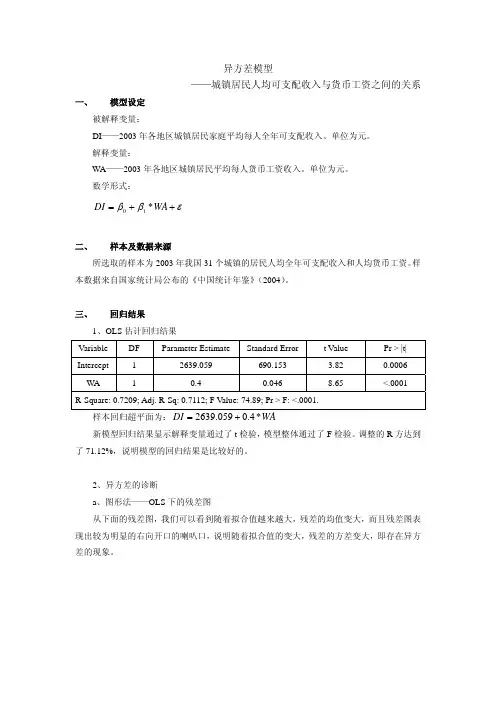
异方差模型——城镇居民人均可支配收入与货币工资之间的关系一、模型设定 被解释变量:DI ——2003年各地区城镇居民家庭平均每人全年可支配收入。
单位为元。
解释变量:WA ——2003年各地区城镇居民平均每人货币工资收入。
单位为元。
数学形式:εββ++=10WA DI *二、样本及数据来源所选取的样本为2003年我国31个城镇的居民人均全年可支配收入和人均货币工资。
样本数据来自国家统计局公布的《中国统计年鉴》(2004)。
三、回归结果1、OLS 估计回归结果 VariableDFParameter EstimateStandard Error t Value Pr > |t| Intercept 1 2639.059 690.153 3.820.0006WA 10.40.0468.65 <.0001R-Square: 0.7209; Adj. R-Sq: 0.7112; F Value: 74.89; Pr > F: <.0001.样本回归超平面为:WA DI *4.0059.2639+=新模型回归结果显示解释变量通过了t 检验,模型整体通过了F 检验。
调整的R 方达到了71.12%,说明模型的回归结果是比较好的。
2、异方差的诊断a 、图形法——OLS 下的残差图从下面的残差图,我们可以看到随着拟合值越来越大,残差的均值变大,而且残差图表现出较为明显的右向开口的喇叭口,说明随着拟合值的变大,残差的方差变大,即存在异方差的现象。
70008000900010000110001200013000-4000-200002000Fitted values R e s i d u a l slm(a$DI ~ a$WA)Residuals vs Fitted261129b 、White 检验利用White 检验的结果如下表所示Heteroscedasticity TestEquation Test Statistic DF Pr> ChiSq Variables DI White's Test12.9420.0016Cross of all varsWhite 检验的结果同样说明了异方差的存在,检验的P 值为0.0016,在1%的水平上能够通过显著性检验。

GARCH模型均值方程和方差方程一、引言在金融领域,预测和控制风险是至关重要的。
为了应对金融市场波动性的特点,学者们提出了各种模型。
其中,GARCH模型(Generalized Autoregressive Conditional Heteroskedasticity model)是一种常用的模型,用于建模和预测金融时间序列数据的波动性。
本文将深入探讨GARCH模型的均值方程和方差方程。
首先,我们将介绍GARCH模型的基本原理和概念。
然后,我们将详细讨论GARCH模型的均值方程和方差方程,并解释其含义和表示方式。
最后,我们将通过一个实例来说明如何应用GARCH模型进行波动性预测。
二、GARCH模型基本原理和概念2.1 GARCH模型的基本原理GARCH模型是一种条件异方差模型,它是对经典的自回归移动平均模型(ARMA)的扩展。
GARCH模型最初由Bollerslev(1986)提出,用于描述金融时间序列的波动性。
它的基本原理是:波动性不仅与过去的观测值相关,还与过去的波动性相关。
2.2 GARCH模型的关键概念在深入探讨GARCH模型的均值方程和方差方程之前,我们需要了解几个关键概念。
1.条件异方差:金融时间序列通常表现出波动性的不稳定性和聚集性。
条件异方差是指波动性在不同时间段内发生变化的现象。
2.自回归(AR):自回归是指序列之间的相关性。
AR模型用过去的观测值来预测当前值。
3.移动平均(MA):移动平均是指通过计算时间序列的平均数来平滑数据。
MA模型用过去的误差项来预测当前值。
4.自回归移动平均(ARMA):ARMA模型结合了AR和MA模型,用于建模时间序列数据。
三、GARCH 模型的均值方程GARCH 模型的均值方程描述了时间序列数据的平均水平。
基本形式如下:Y t =μ+∑ϕi pi=1Y t−i +εt其中,Y t 表示时间t 的观测值,μ表示均值,ϕi 表示自回归系数,p 为自回归阶数,εt 表示误差项。

经济学实证研究中的时间序列分析方法比较时间序列分析是经济学实证研究中一种常用的方法,它对经济数据的时间变化进行建模和预测。
然而,由于经济学数据的特殊性和复杂性,选择合适的时间序列分析方法至关重要。
本文将比较几种常见的时间序列分析方法,包括自回归移动平均模型(ARMA)、自回归条件异方差模型(ARCH)、广义自回归条件异方差模型(GARCH)、ARIMA模型和向量自回归模型(VAR)。
ARMA模型是最基本的时间序列分析方法之一。
它假设数据的未来观测值是过去观测值的线性组合,同时考虑了残差项的随机性。
ARMA模型适用于平稳时间序列数据,其主要优点是简单易懂、计算效率高。
然而,ARMA模型无法应对非平稳时间序列数据和异方差性的存在。
ARCH模型是针对ARMA模型的不足提出的改进方法,它考虑了数据的条件异方差性。
ARCH模型假设数据的条件方差是过去观测误差的加权和,可用于对金融市场波动性进行建模。
然而,ARCH模型无法处理高度异方差的数据,且对时间序列结构的假设限制较多。
GARCH模型是ARCH模型的扩展,考虑了条件异方差和波动性的长期记忆。
GARCH模型在金融领域得到广泛应用,能够更好地对金融市场的波动进行建模。
然而,GARCH模型对参数估计的要求较高,对数据的拟合效果较为敏感。
ARIMA模型是一种广泛应用于短期时间序列预测的方法,包括自回归、差分和移动平均三个部分。
ARIMA模型能够适应一定程度的非平稳数据,并考虑了序列的趋势和季节性变化。
然而,ARIMA模型对数据具有一定的处理要求,在应用时需要仔细选择阶数和滞后期。
VAR模型是多变量时间序列分析的方法,适用于多个相关变量之间的关系分析与预测。
VAR模型的优点在于能够捕捉不同变量之间的动态联动关系,可以考虑更多的信息。
然而,VAR模型对变量之间的相关性和滞后期的选择有一定要求,模型的估计和解释较为复杂。
综上所述,经济学实证研究中的时间序列分析方法有多种选择,每种方法都有其适用的场景和局限性。


什么是异方差性如何进行异方差性的检验与处理异方差性,它是统计学中一种常见的现象,指的是观测值的方差在不同的条件下不相等。
在数据分析和建模过程中,异方差性可能会导致模型参数估计不准确,假设检验无效以及预测效果下降等问题。
因此,了解异方差性并进行检验和处理是非常重要的。
1. 异方差性的表征异方差性通常表现为残差的方差与预测值的关系不稳定。
在回归分析中,当残差的方差与预测值的关系呈现出一定的模式时,可以初步判断存在异方差性。
常见的异方差性模式有以下几种:(1)线性模式:残差的方差与预测值呈线性关系,即残差的方差随着预测值的增大而增大或减小。
(2)指数模式:残差的方差与预测值呈指数关系,即残差的方差随着预测值的增大呈指数级别增大或减小。
(3)对数模式:残差的方差与预测值呈对数关系,即残差的方差随着预测值的增大呈对数级别增大或减小。
(4)多重峰值模式:残差的方差具有多个峰值,表示不同分组或条件之间存在不同的方差水平。
2. 异方差性的检验针对上述异方差性模式,可以进行一些统计检验来验证异方差性的存在。
常用的异方差性检验方法包括帕金森-斯皮尔曼检验(Park test)、布劳什-帕甘检验(Breusch-Pagan test)和韦斯特曼检验(White test)等。
这些检验方法都是基于残差的方差与预测值之间的关系建立的。
以布劳什-帕甘检验为例,该检验的原假设是残差的方差与预测变量之间不存在显著相关关系,即不存在异方差性。
在进行检验时,首先需要对模型进行拟合,并获得残差。
然后,根据拟合残差和预测变量的关系构建辅助回归模型,并进行显著性检验。
如果辅助回归模型的显著性检验结果小于设定的显著性水平(通常为0.05),则可以拒绝原假设,认为存在异方差性。
3. 异方差性的处理在实际数据分析中,如果检验结果表明存在异方差性,需要对数据进行处理以减小或消除其影响。
常用的异方差性处理方法包括以下几种:(1)对数或平方根变换:通过对原始数据进行对数或平方根变换,可以降低数据的异方差性。
ii i i i i i i X X X X X X e εαααααα++++++=215224213221102~第四章异方差1.异方差的概念和类型概念:对于模型 如果出现 即对于不同的样本点,随机误差项的方差不再是常数,而互不相同,则认为出现了异方差性。
异方差一般可归结为三种类型:(1)单调递增型: σi 2随X 的增大而增大(2)单调递减型: σi 2随X 的增大而减小(3)复杂型: σi 2与X 的变化呈复杂形式2.几种异方差的检验方法(描述原理即可)(1)图示检验法①用X-Y 的散点图进行判断:看是否存在明显的散点扩大、缩小或复杂型趋势(即不在一个固定的带型域中)②用X-的散点图进行判断:看是否形成一斜率为零的直线(2)帕克(Park)检验与戈里瑟(Gleiser)检验选择关于变量X 的不同的函数形式,对方程进行估计并进行显著性检验,如果存在某一种函数形式,使得方程显著成立,则说明原模型存在异方差性。
(3)G-Q 检验先将样本一分为二,对子样①和子样②分别作回归,然后利用两个子样的残差平方和之比构造统计量进行异方差检验。
由于该统计量服从F 分布,因此假如存在递增的异方差,则F 远大于1;反之就会等于1(同方差)、或小于1(递减方差)。
(4)怀特(White )检验怀特检验不需要排序,且适合任何形式的异方差。
以二元为例 先进行OLS 回归,得到 然后做辅助回归 可以证明,在同方差假设下,从该辅助回归所得到的可决系数R2与样本容量n 的乘积,渐进地服从自由度为辅助回归方程中解释变量个数的卡方分布:(R2为辅助回归的可决系数,h 为辅助回归法人解释变量的个数)如果存在异方差性,则表明确与解释变量的某种组合有显著的相关性,这时往往显示出有较高的可决系数并且某一参数的t 检验值较大。
3.异方差的后果(1)参数估计量非有效OLS 估计量仍然具有无偏性,但不具有有效性。
因为在有效性证明中利用了而且,在大样本情况下,尽管参数估计量具有一致性,但仍然不具有渐近有效性。