生物信息学实验大纲
- 格式:docx
- 大小:15.26 KB
- 文档页数:4

生物信息学分析上机实验教学大纲一、制定本大纲的依据依据《生物信息学分析教学大纲》制定本上机实验大纲。
生物信息学是当今生命科学和自然科学的核心领域和最具活力的前沿领域之一,是一门新兴的交叉学科,是现代生物学研究的重要工具。
它所研究的材料是生物学的数据,而它进行研究所采用的方法,则是从各种计算技术衍生出来的。
随着Internet的广泛应用和基因组研究的深入进行,生物信息学也得到了飞速的发展。
只有通过系统的理论学习和实际的上机操作,才能使学生了解当今生物信息学网络资源,学会常用生物信息数据库查询、数据库搜索方法、生物大分子序列分析和分子进化分析软件等的使用方法,初步解决科研和实际工作中生物信息的存储、检索、分析和利用的问题。
二、本实验课程的具体安排实验项目的设置及学时分配三、本实验课在该课程体系中的地位与作用根据《生物信息学分析教学大纲》开设的上机实验,能够使学生掌握生物信息学的基础知识与概念,了解生物信息学网络资源,实践具体的操作方法。
培养学生具有生物信息学方面的理论基础和基本技能,并且能够运用所掌握的生物信息学理论、方法和技术,初步解决科研和实际工作中生物信息的存储、检索、分析和利用的问题。
四、学生应达到的实验能力与标准:通过上机实验的开设,学生应了解生物信息学的主要内容, 理解生物信息技术的原理和应用领域,掌握并能使用生物信息学的基本工具,提高分析和解决实际问题的能力,为今后开展相关研究打下基础。
通过上机实验具体的操作过程,学生应达到以下要求:1、熟悉并掌握各生物数据库的查询检索方法。
2、了解生物大分子结构生物信息学的内容与分析方法。
3、熟悉网上数据分析预测工具的使用。
4、培养学生进行生物绘图、生物计算、数据处理、分析结果的基本能力。
5、培养学生独立从事科研实验的技能和素养、与组员分工合作能力及对在上机实验过程中遇到问题的解决能力。
五、上机实验的基本理论与实验技术知识:实验一常用分子生物学数据库的使用基本要求:了解生物信息学的各大门户网站以及其中的主要资源,掌握主要数据库的内容及结构,理解各数据库注释的含义。

《生物信息学》教学大纲学时。
授课时间:第6学期,讲授36学时,上机实验18学时。
第1章生物信息学概论1.1 生物信息学的概念和发展历史生物信息学的概念和发展历史1.1.1 生物信息学的定义生物信息学的定义1.1.2 生物信息学兴起的生物学和计算机技术背景生物信息学兴起的生物学和计算机技术背景1.1.3 国内外生物信息学发展历史国内外生物信息学发展历史1.2 生物信息学的生物学基础生物信息学的生物学基础1.2.1 分子生物学基础分子生物学基础1.2.2 基因组学基础基因组学基础1.3 生物信息学的计算机和网络基础生物信息学的计算机和网络基础1.3.1 计算机硬件平台(PC、MACINTOSH、Workstation、Supercomputer) 1.3.2 计算机操作系统(WINDOWS、MAS OS、UNIX/LINUX)1.3.3 数据库技术数据库技术1.3.4 计算机算法计算机算法1.3.5 计算机编程语言(C++, VB, PERL, HTML, XML) 1.3.6 网络技术(WWW、FTP、BBS、EMAIL、)1.4 生物信息学的数学基础生物信息学的数学基础1.4.4 离散数学离散数学1.4.2 概率论与数理统计概率论与数理统计1.4.3 人工神经网络人工神经网络1.4.4 数据挖掘数据挖掘1.5 生物信息学的产业化生物信息学的产业化1.5.1 生物信息学的产业化生物信息学的产业化1.5.2 国内外生物信息学公司和著名产品简介国内外生物信息学公司和著名产品简介1.6 生物信息学研究内容和发展前景展望生物信息学研究内容和发展前景展望1.6.1生物信息学的主要研究内容生物信息学的主要研究内容1.6.2 后基因组时代生物信息学的研究方向后基因组时代生物信息学的研究方向1.6.3 生物信息学的发展前景生物信息学的发展前景第2章分子生物学数据库2.1 生物学数据库概述生物学数据库概述2.1.1 数据库的分类数据库的分类2.1.2 数据格式数据格式2.1.3数据库的冗余与偏误数据库的冗余与偏误2.2 核苷酸序列与基因组数据库核苷酸序列与基因组数据库2.2.1 GenBank数据库与ENTREZ网络服务(2.1.1 1 GenBank序列数据库简介, 2.1.1.2 一级和二级数据库, 2.1.1.3 数据库格式2.1.1.4 数据库, 2.1.1.5 剖析GenBank Flatfile))2.2.2 EMBL核苷酸序列库与EBI网络服务网络服务2.2.3 DDBJ数据库数据库2.2.4密码子使用与核苷酸信号数据库密码子使用与核苷酸信号数据库2.2.5基因组序列数据库GSDB 2.2.6人类基因组数据库GDB 2.2.7模式生物基因组数据库MGD、ECDC、NRSub 2.2.8基因组的图形交互显示和检索、浏览工具资源基因组的图形交互显示和检索、浏览工具资源2.3 蛋白质序列与模式、同源性数据库蛋白质序列与模式、同源性数据库2.3.1蛋白质序列数据库PIR-International 2.3.2蛋白质序列数据库SWIIS-PROT 2.3.3 蛋白质家族分类数据库蛋白质家族分类数据库2.3.4蛋白质基序与结构域数据库(蛋白质基序与结构域数据库( Prosite、Blocks、PRINTS和SBASE数据库)数据库) 2.4 结构数据库结构数据库2.4.1结构数据库简介结构数据库简介2.4.2 PDB:Brookhaven国家实验室蛋白质数据库国家实验室蛋白质数据库2.4.3 MMDB:NCBI的分子建模数据库的分子建模数据库2.4.4 结构文件格式结构文件格式2.4.5 结构信息显示结构信息显示2.4.6 数据库结构浏览器数据库结构浏览器2.5 基因和分子的互作和代谢途径信息数据库基因和分子的互作和代谢途径信息数据库2.5.1基因和基因组百科全书数据库KEGG 2.5.2 E.coliK-12基因组和代谢途径数据库基因组和代谢途径数据库2.5.3 E.coli基因及其产物的数据库GenProtEC 2.5.4果蝇的遗传和分子数据的数据库FlyBase 2.6 RNA核苷酸序列数据库核苷酸序列数据库2.6.1 18S RNA 2.6.2 28S RNA 2.6.3 5S RNA 2.6.4 Mt rna 2.7 线粒体DNA数据库数据库2.7.1 MITOMAP 2.7.2 MmtDB 2.8 免疫球蛋白、T细胞受体、MHC的整合数据库lMGT 2.9 突变数据库突变数据库2.10 放射杂交作图数据库Rhdb 2.11 限制酶数据库REBASE与分子探针数据库MPOB 2.12 其它遗传学与分子生物学资源其它遗传学与分子生物学资源2.13 数据库中存在的问题及使用注意事项数据库中存在的问题及使用注意事项第3章序列比对与数据库检索3.1 序列比对概述序列比对概述3.1.1序列比对的概念和进化理论基础序列比对的概念和进化理论基础3.1.2序列比对的分类(双序列比对和多序列比对) 3.2 双序列比对双序列比对3.2.1 Needleman-Wunsch 算法算法3.2.2 Smith-Waterman 算法算法3.2.3 Karlin-Altchul 统计方法统计方法3.2.4 替换矩阵替换矩阵 (3.2.4.1 替换矩阵的一般原理;3.2.4.2 P AM 氨基酸替换矩阵;3.2.4.3 BLOSUM 氨基酸替换矩阵;3.2.4.4 DNA 替换矩阵) 3.2.5相似性得分、取代罚分与空位(Gap)罚分)罚分3.3 比对的统计学显著性比对的统计学显著性3.3.1 Monte Carlo仿真法仿真法3.3.2 BLAST得分显著性的Karlin-Altschul公式公式3.3.3局部配准的统计显著性局部配准的统计显著性3.3.4短序列配准的显著性评价短序列配准的显著性评价3.3.5核酸序列比较的显著性评价核酸序列比较的显著性评价3.4 多序列比对多序列比对3.4.1多序列比对的算法多序列比对的算法3.4.2 DNA多序列比对及其常用软件多序列比对及其常用软件3.4.3 蛋白质多序列比对及其常用软件蛋白质多序列比对及其常用软件3.5数据库搜索数据库搜索3.5.1 BLAST:核酸数据库搜索:核酸数据库搜索3.5.2 BLAST:蛋白质数据库搜索:蛋白质数据库搜索3.5.3 F AST A:另一种搜索策略:另一种搜索策略3.5.4 有空位对准的BLAST程度与位置特异的迭代BLAST程序程序3.6基因组长序列比对基因组长序列比对第3章DNA序列的统计学与信息学分析3.1单一序列的组成、关联性与信息学分析单一序列的组成、关联性与信息学分析3.1.1 碱基组成碱基组成3.1.2 碱基相邻频率碱基相邻频率3.1.3同向与反向重复序列分析同向与反向重复序列分析3.1.4 DNA 序列的几何学分析——Z 曲线曲线3.1.5核苷酸序列的长程相关与非线性方法核苷酸序列的长程相关与非线性方法3.1.6长程互作对DNA的结构和可变性的作用的结构和可变性的作用3.1.7重复对熵的影响重复对熵的影响3.1.8编码片段的相互信息编码片段的相互信息3.1.9 DNA序列的模式结构序列的模式结构3.1.10 语言学复杂性测度语言学复杂性测度3.1.11 非编码区(“Junk”DNA)基因组序列)基因组序列3.2 密码子指纹与密码子使用偏好性分析密码子指纹与密码子使用偏好性分析3.2.1单、双核苷酸的相对丰度和基因组指纹分析单、双核苷酸的相对丰度和基因组指纹分析3.2.2密码子频率和密码子指纹密码子频率和密码子指纹3.2.3基因间和基因类间的异质性基因间和基因类间的异质性3.3编码DNA片段的长度与GC含量含量3.4重叠基因的信息论问题重叠基因的信息论问题3.7 功能相关基因在两个基因组间或内部的聚类关系功能相关基因在两个基因组间或内部的聚类关系3.7.1基因组比较与基于功能组成的物种间的比较基因组比较与基于功能组成的物种间的比较3.7.2两个细菌基因组间或内部的聚类关系两个细菌基因组间或内部的聚类关系3.8 真核生物的基因表达调控(表达促进网络)真核生物的基因表达调控(表达促进网络)3.8.1相对同义密码子使用值与密码子适应指数相对同义密码子使用值与密码子适应指数3.8.2信息聚类方法与自身一致信息聚类信息聚类方法与自身一致信息聚类3.8.3碱基组成及相关性与基因表达的关系碱基组成及相关性与基因表达的关系第4章核酸序列的信号和功能识别4.1 固定序列模式检索固定序列模式检索4.2 短寡聚核苷酸序列的随机出现机率短寡聚核苷酸序列的随机出现机率4.3 编码区DNA寡聚体出现频率寡聚体出现频率4.5 蛋白质基因识别蛋白质基因识别4.5.1开放阅读框架分析开放阅读框架分析4.5.2编码区识别4.5.2.1碱基组成偏歧法4.5.2.2密码子使用法4.5.2.3密码子偏歧法密码子偏歧法4.5.3基因识别4.5.3.1GenLang基因识别4.5.3.2GRAIL基因识别基因识别4.5.4基因识别的一些相关程序4.5.4.1发现和屏蔽重复4.5.4.2序列相似性与标纹数据库搜其它功能信号识别 索4.5.4.3整合的基因识别4.5.4.4序列片段的编码区分析4.5.4.5其它功能信号识别4.4 核酸序列的特殊信号检索核酸序列的特殊信号检索4.4.1基准序列频率表和权值矩阵法基准序列频率表和权值矩阵法4.4.2启动子分析启动子分析4.4.3内含子/外显子剪接位点识别外显子剪接位点识别4.4.4 翻译起始位点和翻译终止位点识别翻译起始位点和翻译终止位点识别4.6 编码序列翻译编码序列翻译4.7限制性酶作图限制性酶作图4.7.1限制性酶位点寻找限制性酶位点寻找4.7.2 绘制限制酶作图绘制限制酶作图4.8 PCR引物和寡核苷酸探针设计引物和寡核苷酸探针设计4.8.1.2 通用PCR引物的类型和一般要求; ; 4.8.1.2 4.8.1.1 PCR4.8.1 引物设计(4.8.1.1 通用 PCR引物设计方法; 4.8.1.5 4.8.1.4 从蛋白质序列设计简并引物; ; 4.8.1.5 4.8.1.3 特异性PCR引物设计方法; ; 4.8.1.4 OLIGO6和PRIMER PREMIER 软件使用)软件使用)4.8.2 用于检测相关基因的简并探针设计用于检测相关基因的简并探针设计第5章RNA序列分析与结构预测5.1 RNA标纹识别和局部结构配对标纹识别和局部结构配对5.1.1信号搜索:概率方法信号搜索:概率方法5.1.2信号搜集:模式匹配方法信号搜集:模式匹配方法5.1.3 tRNA的二级结构预测的二级结构预测5.1.4 RNA序列的局部结构配准序列的局部结构配准第6章蛋白质序列分析与结构预测方法6.1 多肽理化性质计算与预测多肽理化性质计算与预测6.1.1 多肽分子量、等电点、电荷分布和酶切特征预测多肽分子量、等电点、电荷分布和酶切特征预测6.1.2 多肽亲水性/疏水性分析与制图疏水性分析与制图6.1.3 多肽抗原位点分析多肽抗原位点分析6.1.4 多肽多肽6.2 蛋白质家族与蛋白质分类蛋白质家族与蛋白质分类6.2.1蛋白质家族与超家族蛋白质家族与超家族Blocks分类方法6.2.2.2加权特征标纹分类方法6.2.2.4 6.2.2 蛋白质分类的方法(6.2.2.1 6.2.2.1 BlocksProfile 方法)方法)6.3蛋白质序列模式和结构域模式分析蛋白质序列模式和结构域模式分析6.3.1基准序列(序列模式):标纹、标志、指纹和地点:标纹、标志、指纹和地点 6.3.2序列结构域与模式匹配方法6.3.2.1频率表方法6.3.2.2权值矩阵法:Profile 分析分析6.4蛋白质结构预测与分子设计蛋白质结构预测与分子设计6.4.1蛋白质结构预测蛋白质结构预测6.4.2蛋白质二级结构和和折叠类预测蛋白质二级结构和和折叠类预测6.4.3三级结构预测三级结构预测6.4.3合理药物分子设计合理药物分子设计第7章 核酸和蛋白质序列的进化分析7.1 分子系统发育概述分子系统发育概述7.2 系统发育模型的组成系统发育模型的组成7.2 系统发育数据分析的一般步骤系统发育数据分析的一般步骤7.3 建立数据模型(比对)建立数据模型(比对)7.4 决定取代模型决定取代模型7.5 建树方法建树方法7.5.1 距离矩阵法(UPGMA,NJ) 7.5.2 最简约法最简约法7.5.3 极似然法极似然法7.6 进化树搜索进化树搜索7.7 确定树根确定树根7.8 评估进化树和数据评估进化树和数据7.9 系统发育软件(MEGA2, PAUP*, MACCLADE, PHYLIP) 第8章 基因组测序与分析8.1 DNA 测序与序列片段的拼接测序与序列片段的拼接8.1.1 DNA 测序的一般方法测序的一般方法8.1.2 DNA 测序策略(8.1.2.1 从遗传图谱、物理图谱到基因组序列图谱;8.1.2.2 鸟枪测序法(shotgun shotgun sequencing sequencing );8.1.2.3 引物步查法(primer primer walking walking );8.1.2.4 限制性酶切-亚克隆法(restriction endonuclease digestion and subcloning )8.1.3 序列片段的拼接方法序列片段的拼接方法8.2 编码蛋白质基因区域的预测编码蛋白质基因区域的预测8.2.1 从序列中寻找基因从序列中寻找基因 (8.2.1.1 基因及基因区域预测;8.2.1.2 发现基因的一般过程;8.2.1.3 解读序列) 8.2.2基于编码区特性的最长ORF 法等法等8.2.3 数据库相似性搜索法数据库相似性搜索法8.2.4 神经网络法神经网络法8.2.5 隐马尔可夫模型法(HMM )8.3 基因组的比较基因组的比较8.3.1比较基因组学比较基因组学8.3.2 基因组多样性基因组多样性8.3.3 基因组比较的方法基因组比较的方法8.4 人类基因组制图与测序人类基因组制图与测序8.4.1人类基因组制图人类基因组制图 (8.2.1.1遗传图, 8.2.1.2物理图, 8.2.1.3序列图, 8.2.1.4转录图(表达图)与cDNA 文库构建) 8.4.2 基因组遗传图的构建方法基因组遗传图的构建方法 (8.2.2.1检测连锁与估计重组率, , 8.2.2.28.2.2.2估计相对图距和推测多位点测序, 2.2.1图距与交叉干涉, 2.2.2推测多位点测序) 8.5 基因组物理图谱与测序基因组物理图谱与测序 (8.5.3.1克隆与克隆库, 8.5.3.2随机克隆重叠构图) 8.6锚定法作图锚定法作图8.7检测重叠的Bayes 方法8.5.1重叠构型8.5.2重叠检测重叠检测8.8由随机克隆的指纹法组装物理图由随机克隆的指纹法组装物理图8.9用Y AC 克隆构造人类基因组图谱的策略设计克隆构造人类基因组图谱的策略设计8.10采用高冗余度的亚克隆库采用高冗余度的亚克隆库 8.11 Conting 图或克隆定序图或克隆定序8.12 直接作图法直接作图法8.11有序鸟枪测序作图的仿真分析有序鸟枪测序作图的仿真分析8.14定位克隆的流水线鸟枪策略定位克隆的流水线鸟枪策略8.15放射杂交作图和FISH 作图作图第9章 功能基因组信息学9.1功能基因组信息学概述功能基因组信息学概述9.2 基因表达数据分析基因表达数据分析9.3 第10章 生物多样性信息学和神经生物信息学10.1 生物多样性信息学生物多样性信息学10.2 神经生物信息学神经生物信息学生物信息学实验教学大纲实验1. 常用分子生物学数据库的使用和数据格式、数据库查询与下载常用分子生物学数据库的使用和数据格式、数据库查询与下载实验2. DNA 序列的统计学、信息学和功能分析序列的统计学、信息学和功能分析实验3 蛋白质序列分析和结构预测蛋白质序列分析和结构预测实验4. 核酸和蛋白质序列的进化分析(CLUSTALX 、MEGA2软件的使用) 实验5. 使用Oligo 和PrimerPremier 软件设计PCR 引物引物实验6. 常用重要生物信息学软件使用方法(DNAStar 、OMIGA 、V ectorNT suite )。

目录实验一文献检索和浏览各大生物分子数据库 (1)实验二 DNA Blast(利用DNA数据库上提供的Blast功能) (7)实验三 DNA Blast(使用DNAssist软件) (11)主要参考文献 (13)实验一文献检索和浏览各大生物分子数据库一、实验目的1、学习文献检索方法2、了解生物信息学常用数据库的结构二、实验内容文献检索是每个科研工作者必须具备的能力,这里主要以我校的资源为例,说明网络文献检索的一些基本方法。
国际上已经建立起许多分子公共数据库,包括基因组图谱数据库、核酸序列数据库、蛋白质序列数据库及生物大分子结构数据库等。
这些数据库由专门的机构建立和维护,他们负责收集、组织、管理和发布生物分子数据,并提供数据检索和分析工具,向生物学研究人员提供大量有用的信息,为他们的研究服务。
本实验通过登陆GenBank、EMBL、DDBJ三个国际上权威的核酸序列数据库、GDB基因组数据库、人类基因组数据库Ensembl、表达序列标记数据库dbEST、序列标记位点数据库dbSTS,以及PIR、SWISS-PROT、TrEMBL蛋白质序列数据库、蛋白质数据仓库UniProt、生物大分子数据库PDB等,了解各数据库的结构,。
三、实验仪器、设备及材料计算机(联网)四、实验原理建立生物分子数据库的动因是由于生物分子数据的高速增长,而另一方面也是为了满足分子生物学及相关领域研究人员迅速获得最新实验数据的要求。
生物分子信息分析已经成为分子生物学研究必备的一种方法。
数据库及其相关的分析软件是生物信息学研究和应用的重要基础,也是分子生物学研究必备的工具。
核酸序列是了解生物体结构、功能、发育和进化的出发点。
国际上权威的核酸序列数据库有三个,分别是美国生物技术信息中心(NCBI)的GenBank (/web/Genbank/index/html)、欧洲分子生物学实验室的EMBL-Bank (简称EMBL,/embl/index/html)及日本遗传研究所的DDBJ (http://www.ddbj.nig.ac.jp/)。

《生物信息学》课程教学大纲课程编号:0235212课程名称:生物信息学总学时数:28学时实验学时:0学时先修课及后续课:先修课有《普通生物学》、《生物化学》、《微生物学》、《细胞生物学》、《遗传学》、《基因工程》、《分子生物学》。
一、说明部分1、课程性质生物信息学是生物工程专业的选修课程,适宜于已有生物化学和分子生物学基础的学生。
生物信息学是一门交叉学科,是现代生物学研究的重要工具,因此本课程在人才培养过程中具有很重要的地位。
本课程系统地概括了该学科的核心内容,包括主要生物信息学数据库及数据库查询、序列相似性搜索、多序列比对和进化树分析、序列的一般分析、生物信息学在人类基因组研究计划中的应用及蛋白质组信息学等主要内容。
2、教学目标及意义使学生学习、掌握生物信息学的先进理论知识和技术,掌握信息时代彼此相互学习、相互交流医学知识必不可少的现代工具和技术手段。
3、教学内容及教学要求(1)要求学生掌握生物信息学的基本理论知识和基本概念,熟悉生物信息学的相关技术方法,特别是分子生物学中常用的关键技术及常用软件。
(2)考虑到生物信息学实践性很强的特点,结合生物医学实际,设计了一些实验供学生练习操作,以巩固所学的知识和技术。
要求学生熟悉生物信息学的常用网络技术方法,掌握网络技术基本要领。
4、教学重点、难点重点:生物信息学的概念、主要生物信息学数据库及数据库查询、序列相似性搜索、序列的一般分析。
难点:主要生物信息学数据库及数据库查询、序列相似性搜索、序列的一般分析。
通过系统的学习,使学生能够掌握生物信息学的基础知识与概念、运用生物信息学成果解决生命科学相关问题的基本方法与途径,培养分析问题与解决问题的能力;了解生物信息学网络资源,开拓视野;培养对生物工程专业课程研究的兴趣。
5、教学方法与手段在教学方法上采取课堂讲授为主,辅以多媒体课件、网上数据库使用等,以加强学生对理论知识的消化和理解,在教学过程应注意积极启发学生的思维,培养学生发现问题和解决问题的能力。
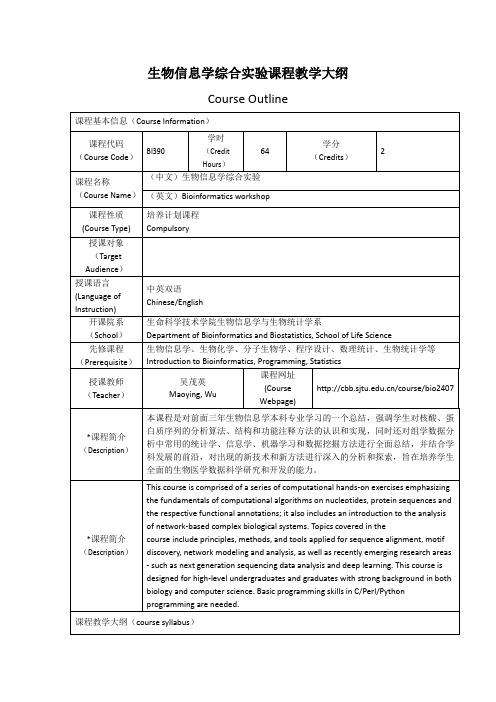

红河学院《生物信息学》课程教学大纲一、课程基本情况与说明(一)课程代码:(二)课程英文名称:bioinformatics(三)课程中文名称:生物信息学(四)授课对象:生物科学和生物技术专业本科生(五)开课单位:生命科学与技术学院(六)教材:1、生物技术专业:《生物信息学应用技术》,王禄山、高培基编,化学工业出版社,2008年2、生物科学专业:《生物信息学基础》,孙啸、陆祖宏、谢建明编,清华大学出版社,2005年(七)参考书目[1]《生物信息学》,DavidW.Mount著,钟扬等译,高等教育出版社,2003年[2]《基因组数据分析手册》,胡松年、薛庆中编,浙江大学出版社,2003年[3]《生物信息学中的计算机技术(Developing Bioinformatics Computer Skills)》,CynthiaGibas,Per Jambeck著,孙超等译,中国电力出版社,2002年[4]《生物信息学:基因和蛋白质分析的实用指南》,Andreas D. Baxevanis,Francis OuelletteB F著,李衍达、孙之荣等译,清华大学出版社,2000年[5]《生物信息学算法导论(An Introduction to Bioinformatics Algorithms )》,琼斯,帕夫纳著,王翼飞等译,化学工业出版社,2007年(八)课程性质(五号宋体加粗)生物信息学是生命科学领域一门新兴的边缘学科,综合了生物学、计算机学、信息学、统计学等方面的知识。
该学科在学生掌握生物化学、遗传学、分子生物学以及计算机应用、高等数学等相关知识的基础上开设,属于生物类专业的专业课程(必修或选修)。
通过学习,学生能够加深对分子生物学和基因工程等课程的理解,并为进一步学习基因组学(genomics)和蛋白质组学(protemics) 奠定基础。
(九)教学目的1、给学生介绍生物信息学的主要内容以及未来可能的发展方向,为学生构建相关知识体系,开阔学生的视野,为将来进一步学习、科研打下基础。
生物信息学教学大纲生物信息学教学大纲引言:生物信息学是一门综合性学科,结合了生物学、计算机科学和统计学的知识,旨在利用计算机技术和统计方法来解析和理解生物学数据。
随着生物学研究的不断发展和高通量技术的广泛应用,生物信息学在生命科学领域中的作用日益重要。
为了培养具备生物信息学分析能力的专业人才,制定一份全面而合理的生物信息学教学大纲显得尤为关键。
一、课程目标生物信息学教学的主要目标是培养学生掌握基本的生物信息学理论和技术,具备生物信息学数据分析和解释的能力。
通过该课程的学习,学生将能够:1. 理解生物信息学的基本概念、原理和方法;2. 掌握常用的生物信息学工具和软件的使用;3. 学会生物序列分析、基因表达分析和蛋白质结构预测等生物信息学分析方法;4. 培养独立思考和解决生物信息学问题的能力;5. 培养团队合作和科学沟通的能力。
二、课程内容1. 生物信息学基础知识a. 生物信息学的定义和发展历程b. 生物学基础知识回顾c. 计算机科学基础知识回顾d. 统计学基础知识回顾2. 生物信息学数据库和工具a. 基因组数据库和工具b. 转录组数据库和工具c. 蛋白质数据库和工具d. 其他生物信息学数据库和工具3. 生物序列分析a. 基本序列分析方法b. 基因预测和注释c. DNA、RNA和蛋白质序列比对d. 序列比对算法和软件4. 基因表达分析a. 基因表达数据处理和分析流程b. 差异表达分析方法c. 基因共表达网络分析d. 基因表达数据可视化5. 蛋白质结构预测与分析a. 蛋白质结构预测方法b. 蛋白质结构数据库和工具c. 蛋白质结构分析方法d. 蛋白质结构可视化6. 生物信息学实践案例a. 基于生物信息学的研究案例b. 生物信息学在药物研发中的应用c. 生物信息学在农业和环境科学中的应用d. 生物信息学在人类健康和疾病研究中的应用三、教学方法为了提高学生的学习效果和培养实际操作能力,生物信息学教学应采用多种教学方法:1. 理论讲授:通过课堂讲解,向学生介绍生物信息学的基本概念、理论和方法。
生物信息学实验一简介:生物信息学实验一是生物信息学实验课程的第一部分,旨在介绍生物信息学的基本概念、工具和技术,以及生物信息学在生物学研究中的应用。
本实验将引导学生通过实际操作,学习并掌握生物信息学的基本原理和操作技巧。
实验设备和材料:- 计算机或笔记本电脑- 生物信息学软件(例如NCBI BLAST、UCSC Genome Browser等)- 相关数据库和工具(例如GenBank、KEGG等)实验目的:1. 了解生物信息学的基本概念和应用领域;2. 学习生物信息学的常用工具和技术;3. 掌握生物序列分析、基因注释和比对等基本操作;4. 学会使用生物信息学软件和数据库进行数据查询和分析;5. 培养科学研究的数据处理和解读能力。
实验步骤:1. 确定研究对象:选择一个感兴趣的生物学问题或基因序列进行研究。
2. 数据获取:使用生物信息学工具和数据库,获取与研究对象相关的生物序列数据。
3. 序列分析:使用生物信息学软件对序列数据进行分析,包括碱基组成、氨基酸序列、启动子分析等。
4. 基因注释:通过比对算法和数据库,对序列进行基因功能注释,确定基因的命名、结构和功能信息。
5. 比对分析:使用比对工具进行序列比对,比较两个或多个序列之间的相似性和差异性。
6. 数据解读:根据分析结果,结合相关文献和知识,对实验数据进行解读和分析,得出科学结论。
实验注意事项:1. 在进行实验前,先了解所要使用的工具和软件的基本操作方法和原理;2. 实验过程中注意数据安全和保密,不得将数据泄露或用于非科研目的;3. 在进行数据分析和解读时,务必准确、客观地进行,不得造假或歪曲实验结果;4. 注意数据的备份和存储,以防止数据丢失或损坏;5. 尊重他人的研究成果和知识产权,合理引用和参考相关文献。
实验结果与讨论:本实验所得的结果可以根据具体的研究对象和实验数据来展开讨论和分析。
例如,如果研究对象是某个基因序列,可以讨论其结构和功能,与其他基因的关联性,以及在哪些生物过程中有重要作用等。
生物信息学实验大纲一、实验目的1.掌握基本的生物信息学知识和技能,包括生物数据库的利用、序列分析、基因组分析等。
2.学习并运用常用的生物信息学工具和软件,如BLAST、CLUSTAL、Phylogenetic等。
3.培养学生的科学思维和实验操作能力,提高数据分析和解释的能力。
4.通过实验培养学生的团队合作和沟通能力。
二、实验内容1.生物数据库的利用a.学习如何进行基因、蛋白质和基因组数据的检索和下载。
b.学习如何利用数据库进行序列比对、同源物种搜索等分析。
2.序列分析a.学习和掌握常用的序列比对软件(如CLUSTAL)和序列比对方法。
b.进行序列比对的实验操作,分析序列间的相似性和差异。
3.基因组分析a.学习并掌握基因组数据的下载和处理方法。
b.进行基因组数据分析的实验操作,如基因注释、富集分析等。
4.蛋白质结构预测a.学习并掌握蛋白质结构预测方法和软件。
b.进行蛋白质结构预测的实验操作,分析蛋白质结构的二级结构、三维结构等。
5.基因表达谱分析a.学习并掌握基因表达谱数据的获取和处理方法。
b.进行基因表达谱分析的实验操作,如差异表达基因的筛选和功能分析等。
6.进化分析a.学习进化分析的基本理论和方法。
b.进行进化分析的实验操作,如构建进化树、计算进化距离等。
三、实验要求1.实验组织形式:小组合作进行实验,每个小组由3-5名学生组成,共同完成实验设计、操作和数据分析。
2.实验前阅读实验指导书和相关科研论文,了解实验背景和基本原理。
3.每个小组在实验后撰写实验报告,并进行实验结果的展示和讨论。
4.每个学生需参与实验操作和数据分析,能够独立思考和解释实验结果。
四、实验设备和材料1.计算机及互联网连接设备。
2.生物信息学工具和软件,如BLAST、CLUSTAL、Phylogenetic等。
3.数据库访问权限或相关数据库的下载工具。
4.相关的生物序列和基因组数据。
五、实验评分指标1.独立思考和解释实验结果的能力。
生物信息学教学大纲一、课程概述生物信息学是一门融合生物学、计算机科学、数学和统计学等多学科知识的新兴交叉学科。
它旨在运用计算方法和工具对生物数据进行获取、存储、管理、分析和解释,以揭示生命现象背后的规律和机制。
本课程将为学生提供生物信息学的基本理论、方法和技术,培养学生运用生物信息学手段解决生物学问题的能力。
二、课程目标1、使学生了解生物信息学的基本概念、发展历程和应用领域。
2、让学生掌握生物信息学中常用的数据类型、数据库和数据格式。
3、培养学生运用生物信息学工具和算法进行数据分析的能力。
4、引导学生运用所学知识解决实际生物学问题,培养创新思维和实践能力。
三、课程内容(一)生物信息学基础1、生物信息学的定义、发展历程和研究内容。
2、生物学基础知识,包括基因组、转录组、蛋白质组等。
3、计算机基础知识,如操作系统、编程语言等。
1、常用的生物数据库介绍,如 NCBI、UniProt、PDB 等。
2、数据库的检索和使用方法。
(三)序列分析1、核酸和蛋白质序列的获取和处理。
2、序列比对算法,如全局比对、局部比对。
3、相似性搜索和同源性分析。
(四)基因组分析1、基因组结构和功能分析。
2、基因预测和注释。
3、比较基因组学。
(五)转录组分析1、 RNAseq 数据分析流程。
2、差异表达基因分析。
(六)蛋白质组分析1、蛋白质结构预测。
2、蛋白质相互作用分析。
1、生物网络的构建和分析。
2、代谢通路分析。
(八)生物信息学应用1、在疾病诊断和治疗中的应用。
2、在农业和环境科学中的应用。
四、教学方法1、课堂讲授:讲解生物信息学的基本概念、原理和方法。
2、实验教学:通过实际操作,让学生掌握生物信息学工具的使用。
3、案例分析:通过实际案例,培养学生解决问题的能力。
4、小组讨论:促进学生之间的交流与合作,培养团队精神。
五、课程考核1、平时成绩(30%):包括考勤、作业、实验报告等。
2、期末考试(70%):采用闭卷考试,考查学生对生物信息学知识的掌握程度。
生物信息学实验大纲 1. 引言。
介绍生物信息学的定义和作用。
解释生物信息学在生命科学研究中的重要性。
概述实验大纲的目标和结构。
2. 基础知识。
DNA、RNA和蛋白质的结构和功能。
基因组学和转录组学的基本概念。
基本的计算机科学和统计学原理。
3. 数据库和工具。
常用的生物信息学数据库和工具的介绍。
如何使用数据库和工具来获取和处理生物学数据。
数据库搜索和数据挖掘的基本技巧。
4. 实验设计与数据采集。
设计合适的实验来回答特定的生物学问题。
选择适当的实验方法和技术来采集数据。
数据质量控制和实验重复性的考虑。
5. 数据分析与解释。
基因表达数据分析的基本流程和方法。
基因组序列分析的基本流程和方法。
蛋白质结构和功能预测的基本方法。
6. 数据可视化与报告。
使用图表和图形展示生物学数据。
如何撰写生物信息学实验报告和解释结果。
如何有效地传达实验结果和发现。
7. 实验案例分析。
分析和讨论一些生物信息学实验的案例。
探索不同研究领域中的生物信息学应用。
理解生物信息学在解决生物学问题中的潜力和局限性。
8. 实验项目。
学生根据所学知识设计和完成一个小型的生物信息学实验项目。
学生需要自行收集数据、分析数据并撰写实验报告。
导师或教师对学生的实验项目进行评估和指导。
这只是一个大致的生物信息学实验大纲,具体的内容和学习重点可能会因教育机构、课程设置和教师要求而有所不同。
希望这个概述能给你提供一些关于生物信息学实验的基本了解。