生物信息学的实验研究
- 格式:docx
- 大小:37.08 KB
- 文档页数:2

生物信息学技术的教程与实验指导生物信息学技术在现代生命科学研究中起着至关重要的作用。
它是一门综合性学科,结合了生物学、计算机科学和统计学的知识,用于从大规模的生物学数据中提取有意义的信息。
本文将介绍生物信息学技术的基本概念和常用工具,并提供一些实验指导以帮助读者更好地理解和应用这些技术。
一、生物信息学技术概述1.1 生物信息学的定义和应用领域生物信息学是指运用计算机科学和统计学等方法处理、分析和解释生物学数据的学科。
它广泛应用于基因组学、蛋白质组学、转录组学以及与生物相关的大数据研究中,为生物学研究提供了强大的工具和方法。
1.2 常用的生物信息学技术常用的生物信息学技术包括序列比对、基因预测、蛋白质结构预测、基因表达分析和进化分析等。
这些技术在生物学研究中被广泛应用,可以帮助研究人员理解基因组的组成、功能和进化。
二、生物信息学技术的教程2.1 序列比对技术序列比对是生物信息学中最基本的技术之一。
它用于将不同生物体中的DNA或蛋白质序列进行比对,找出它们之间的相似性和差异性。
在教程中,我们将介绍序列比对的原理、常见的比对算法以及如何使用常见的比对工具进行序列比对实验。
2.2 基因预测技术基因预测是指从DNA序列中识别和预测基因位置和结构的过程。
在教程中,我们将介绍基因预测的方法和工具,包括基于序列比对和基于统计学模型的方法,以及常用的基因预测软件的使用方法。
2.3 蛋白质结构预测技术蛋白质结构预测是指通过计算和模拟方法预测蛋白质的三维结构。
在教程中,我们将介绍常见的蛋白质结构预测方法,包括基于序列比对和基于物理化学原理的方法,以及一些常用的蛋白质结构预测软件的使用方法。
2.4 基因表达分析技术基因表达分析是指通过RNA测序技术对不同生物样本中的基因表达水平进行定量和比较分析。
在教程中,我们将介绍基因表达分析的步骤和常用的分析方法,包括差异表达基因分析、功能富集分析和调控网络分析等。
2.5 进化分析技术进化分析是指通过比对不同物种的基因组序列,分析基因组演化过程和物种之间的关系。

⽣物信息学实验报告3(三)蛋⽩质序列分析(三)蛋⽩质序列分析实验⽬的:掌握蛋⽩质序列检索的操作⽅法,熟悉蛋⽩质基本性质分析,了解蛋⽩质结构分析和预测。
实验内容:1、检索SOX-21蛋⽩质序列,利⽤ProParam⼯具进⾏蛋⽩质的氨基酸组成、分⼦质量、等电点、氨基酸组成、原⼦总数及疏⽔性(ProtScale⼯具)等理化性质的分析。
2、利⽤PredictProtein、PROF、HNN等软件预测分析蛋⽩质的⼆级结构;利⽤Scan Prosite软件对蛋⽩质进⾏结构域分析。
3、利⽤TMHMM、TMPRED、SOSUI等⼯具对蛋⽩质进⾏跨膜分析;采⽤PredictNLS进⾏核定位信号分析;利⽤PSORT进⾏蛋⽩质的亚细胞定位预测;利⽤CBS(http://www.cbs.dtu.dk/services/ProtFun/)⽹站⼯具预测蛋⽩的功能,将序列⽤Blocks、SMART、InterProScan、PFSCAN等搜索其保守序列的特征,进⾏motif 的结构分析。
4、利⽤Swiss-Model数据库软件预测该蛋⽩的三级结构,结果⽤蛋⽩质三维图象软件Jmol查看。
CPHmodels 也是利⽤神经⽹络进⾏同源模建预测蛋⽩质结构的⽅法和⽹络服务器I-TASSER预测所选蛋⽩质的空间结构。
5、分析蛋⽩质的翻译后修饰:分析信号肽及其剪切位点: SignalIP http://www.cbs.dtu.dk/services/SignalP/;分析糖链连接点:分析O-连接糖蛋⽩,NetOGlyc,http://www.cbs.dtu.dk/services/NetOGlyc/;分析N-连接糖蛋⽩,NetNGlyc,http://www.cbs.dtu.dk/services/NetNGlyc/。
6、利⽤检索的序列,进⾏同源⽐对,获得并分析⽐对结果。
实验步骤(⼀)1、在NCBI 蛋⽩质数据库中查找SOX-21蛋⽩质序列分别选择⽖蟾(Xenopus laevis)、⼩家⿏[Mus musculus]、猕猴[Macaca mulatt a]的SOX-21蛋⽩质序列,并保存其FASTA格式。

生物信息学的研究方法和主要领域生物信息学是研究生物学信息的获取、存储、分析和应用等方面的学科。
它是通过计算机和统计学等技术方法,处理和解读生物学数据,以达到理解生物学现象和生物系统功能的目的。
生物信息学涉及的技术和方法非常广泛,包括基因组学、蛋白质组学、转录组学、代谢组学、系统生物学等多个领域。
在这些领域中,生物信息学可以帮助研究者进行大规模数据分析、模拟实验、预测分子功能、构建模型、发现新的基因和蛋白质等,进而解决生物学中的问题。
计算生物学主要是利用计算机进行生物学数据的处理和分析。
在计算生物学中,常用的方法包括数据库的构建和管理、DNA和蛋白质序列分析、分子结构预测、基因组测序和注释、基因表达数据分析等。
计算生物学的目标是通过利用计算机技术和算法,对生物学数据进行处理和分析,从而获得生物学的新发现和新知识。
统计生物学则是通过应用统计学方法,对生物学数据进行分析和解释。
在统计生物学中,常用的方法包括假设检验、富集分析、聚类分析、相关分析、生存分析等。
统计生物学的目标是通过对生物学数据的统计分析,发现数据中的模式和关联,进而推断生物学过程和机制。
基因组学:基因组学研究的是生物体的整个基因组,包括基因的位置、基因之间的相互作用关系、基因的功能等。
生物信息学在基因组学中的应用包括基因组测序、基因组注释、基因组比较、基因组结构预测、进化分析等。
蛋白质组学:蛋白质组学研究的是生物体内所有蛋白质的组成、结构和功能。
生物信息学在蛋白质组学中的应用包括蛋白质序列分析、蛋白质结构预测、蛋白质互作网络分析、功能注释等。
转录组学:转录组学研究的是生物体内所有基因的转录表达情况。
生物信息学在转录组学中的应用包括基因表达数据分析、差异表达基因筛选、基因调控网络分析等。
代谢组学:代谢组学研究的是生物体内代谢产物的组成和变化。
生物信息学在代谢组学中的应用包括代谢物注释、代谢通路分析、代谢网络分析等。
系统生物学:系统生物学研究的是生物体的整体特征和复杂系统。

实验1基因组序列组装(软件CAP3的使用)一、实验目的1.了解基因组测序原理和主要策略;2.掌握CAP3序列组装软件的使用方法。
二、实验原理基因组测序常用的两种策略是克隆法(clone-based strategy)和全基因组鸟枪法(whole genome shotgun method)。
克隆法先将基因组DNA打成大的片段,连到载体上,构建DNA文库;再对每一个大片段(克隆)打碎测序。
序列组装时先组装成克隆,再组装成染色体。
克隆测序法的好处在于序列组装时可以利用已经定位的大片段克隆, 所以序列组装起来较容易, 但是需要前期建立基因组物理图谱, 耗资大, 测序周期长。
全基因组鸟枪法测序无需构建各类复杂的物理图谱和遗传图谱,采用最经济有效的实验设计方案,直接将整个基因组打成不同大小的DNA片段构建Shotgun文库,再用传统Sanger测序法或Solexa等新一代测序技术对文库进行随机测序。
最后运用生物信息学方法将测序片段拼接成全基因组序列。
该方法具有高通量、低成本优势。
序列组装时,先把把单条序列(read)组装成叠连群(contig)、再把叠连群组装成“支架”(scaffold),最后组装成染色体。
本实验将练习在Linux环境下用CAP3软件组装流感病毒基因组。
1.CAP3序列组装程序简介Huang Xiaoqiu. 和 Madan,A. 开发的一套用于序列拼接的软件,此软件适用于小的数据集或 EST 拼接,它有如下特征:1. 应用正反向信息更正拼接错误、连接contigs。
2. 在序列拼接中应用 reads 的质量信息。
3. 自动截去 reads5`端、3`端的低质量区。
4. 产生 Consed 程序可读的ace 格式拼接结果文件。
5. CAP3 能用于Staden软件包的中的GAP4 软件。
2.下载此软件可以免费下载,下载地址:http:///download.html。
填写基本信息表格,即可下载。

生物信息学的方法和应用研究生物信息学是一门交叉领域,涉及生物学、计算机科学、数学、统计学等诸多学科,其主要研究内容是利用计算机和数学的方法来分析、处理和解释生物数据信息。
生物信息学作为一个最新的学科领域,旨在帮助我们更好地理解生命系统的本质。
随着生物数据倍增速度的不断加快,生物信息学逐渐成为了现代生物学和医学研究的重要工具,其方法和应用研究也日益受到重视。
一、生物信息学的方法1.序列分析生物信息学最为常见的方法之一是序列分析。
序列分析主要针对生物分子的基本组成单元——核酸和蛋白质序列进行分析研究,目的是识别序列之间的相似性与不同点,推断其结构和功能,进而进行生物信息的比对、注释和预测。
序列分析包含多种算法,如多序列比对、DNA测序、蛋白质结构预测等等。
序列比对的主要目的是通过比较相似性和不同性来推断生物序列的起源、进化和功能。
目前常用的序列比对算法有全局比对算法、局部比对算法、Smith-Waterman算法和BLAST算法。
不同的算法之间易出现不同的结果,但是它们都有相同的优势:根据序列信息进行分析,为生物学家们提供更多了解生物体的可能性。
2.基因组学分析基因组学分析是一种应用于DNA和RNA序列的生物信息学方法。
该方法利用计算机和生物逻辑思维实现了对大量基因组或类基因组数据的简化、比较和分析。
基因组学分析主要涉及全基因组序列比对、基因外显子识别、蛋白质编码基因预测和基因功能注释等方面。
3.蛋白质组学分析蛋白质组学是对蛋白质组的分析和研究,旨在研究蛋白质分子的性质、结构和功能,以及蛋白质在生物系统中的作用和相互作用。
生物学家们早期只能分析一些单个蛋白质的性质,随着蛋白质组技术的发展,人们逐渐能够同时分析数百个或数千个蛋白质的性质。
这种技术为在疾病诊断、治疗和预防等各个方面都带来了很大的进展。
二、生物信息学的应用1.基因定位和功能研究生物信息学应用于基因定位和功能研究对于基因和疾病之间的关系研究至关重要。
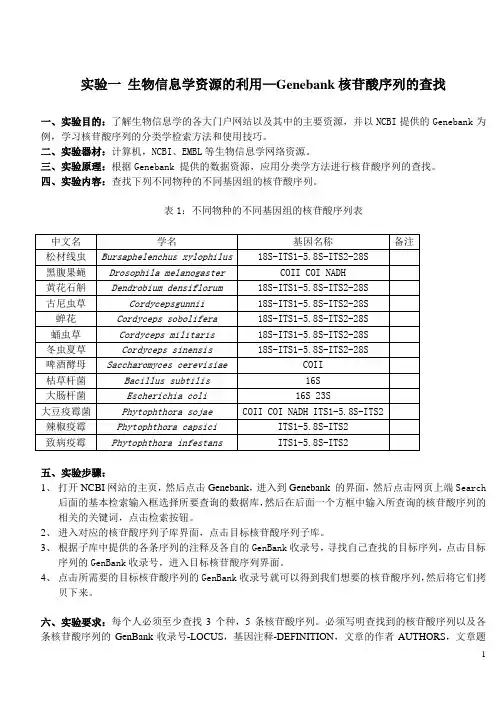
实验一生物信息学资源的利用—Genebank核苷酸序列的查找一、实验目的:了解生物信息学的各大门户网站以及其中的主要资源,并以NCBI提供的Genebank为例,学习核苷酸序列的分类学检索方法和使用技巧。
二、实验器材:计算机,NCBI、EMBL等生物信息学网络资源。
三、实验原理:根据Genebank 提供的数据资源,应用分类学方法进行核苷酸序列的查找。
四、实验内容:查找下列不同物种的不同基因组的核苷酸序列。
表1:不同物种的不同基因组的核苷酸序列表五、实验步骤:1、打开NCBI网站的主页,然后点击Genebank,进入到Genebank 的界面,然后点击网页上端Search后面的基本检索输入框选择所要查询的数据库,然后在后面一个方框中输入所查询的核苷酸序列的相关的关键词,点击检索按钮。
2、进入对应的核苷酸序列子库界面,点击目标核苷酸序列子库。
3、根据子库中提供的各条序列的注释及各自的GenBank收录号,寻找自己查找的目标序列,点击目标序列的GenBank收录号,进入目标核苷酸序列界面。
4、点击所需要的目标核苷酸序列的GenBank收录号就可以得到我们想要的核苷酸序列,然后将它们拷贝下来。
六、实验要求:每个人必须至少查找3个种,5条核苷酸序列。
必须写明查找到的核苷酸序列以及各条核苷酸序列的GenBank收录号-LOCUS,基因注释-DEFINITION,文章的作者AUTHORS,文章题目-TITLE,文章所发表的期刊-JOURNAL。
七、实验结果:查找的核苷酸序列基本情况表1LOCUS JN054403 894 bp DNA linear PLN01-NOV-2011DEFINITION Phytophthora melonis strain NN-1 18S ribosomal RNA gene, partial sequence; internal transcribed spacer 1, 5.8S ribosomal RNA gene, and internal transcribed spacer 2, complete sequence; and 28Sribosomal RNA gene, partial sequence.AUTHORS Wu,Y.G., Huang,S.L., Fu,G., Hu,C.J. and Lu,S.F.TITLE Identification of the causal agent of wax gourd blight in South ChinaJOURNAL UnpublishedORIGIN1 tgggattccc accctagaac tttccacgtg aaccgtatca acaagtagtt gggggcctgc 61 tctgtgtggc tagctgtcga tgtcaaagtc ggcgactggc tgctatgtgg cgggctctat 121 catggcgatt ggtttgggtc ctcctcgtgg ggaactggat catgagccca ccttttaaac 181 ccattcttga ttactgaata tactgtgggg acgaaagtct ctgcttttaa ctagatagca 241 actttcagca gtggatgtct aggctcgcac atcgatgaag aacgctgcga actgcgatac 301 gtaatgcgaa ttgcaggatt cagtgagtca tcgaaatttt gaacgcatat tgcacttccg 361 ggttagtcct gggagtatgc ctgtatcagt gtccgtacat caaacttggc tctcttcctt 421 ccgtgtagtc ggtggatgga gacgccagac gtgaggtgtc ttgcggcgcg gccttcgggc481 tgcctgcgag tcccttgaaa tgtactgaac tgtacttctc tttgctcgaa aagcgtgacg 541 ttgttggttg tggaggctgc ctgtatggcc agtcggcgac cagtttgtct gctgcggcgt 601 ttaatggagg agtgttcgat tcgcggtatg gttggcttcg gctgaacaat gcgcttattg 661 gatgcttttc ctgctgtggt ggtatgggct ggtgaaccgt agttgtgcga ggcttggctt 721 ttgaaccggc ggtgttgtag cgaagtagag tggcggcttc ggctgtcgag ggtcgatcca 781 tttgggaact ctgtgttgtc tctgcggctt gctgtggagg tagcatctca attggacctg 841 atatcaggca agattacccg ctgaacttaa gcatatcata aacgcggagg act2LOCUS HM596011 530 bp DNA linear PLN01-JUL-2011DEFINITION Ophiocordyceps sinensis culture-collection ARSEF:6282 clone C 18S ribosomal RNA gene, partial sequence; internal transcribed spacer 1, 5.8S ribosomal RNA gene, and internal transcribed spacer 2,complete sequence; and 28S ribosomal RNA gene, partial sequence. AUTHORS Chan,W.H.TITLE Direct SubmissionJOURNAL Submitted (28-JUN-2010) Depatment of Biology, The ChineseUniversity of Hong Kong, Shatin, Hong Kong 852, ChinaORIGIN1 tctccgttgg tgaaccagcg gagggatcat tatcgagtca ccactcccaa accccctgcg 61 aacaccacag cagttgcctc ggcgggaccg ccccggcgcc ccagggcccg gaccagggcg 121 cccgccggag gacccccaga ccctcctgtc gcagtggcat ctctcagtca agaagcaagc 181 aaatgaatca aaactttcaa caacggatct cttggttctg gcatcgatga agaacgcagc 241 gaaatgcgat aagtaatgtg aatcgcagaa ttcagtgaac catcgaatct ttgaacgcac 301 attgcgcccg ccagcactct ggcgggcatg cctgtccgag cgtcatctca accctcgagc 361 cccccgcctc gcggcggcgg ggcccggcct tgggggtcac ggccccgcgc cgccccctaa 421 acgcagtggc gaccccgccg cggctcccct gcgcagtagc tcgctgagaa cctcgcaccg 481 ggagcgcgga ggcggtcacg ccgtgaaacc accacaccct ccagttgacc3LOCUS HQ114254 711 bp DNA linear PLN31-AUG-2011DEFINITION Dendrobium densiflorum voucher PS2528MT01 18S ribosomal RNA gene, partial sequence; internal transcribed spacer 1, 5.8S ribosomal RNA gene, and internal transcribed spacer 2, complete sequence; and 28S ribosomal RNA gene, partial sequence.AUTHORS Yao,H., Gao,T. and Chen,S.-L.TITLE Direct SubmissionJOURNAL Submitted (10-AUG-2010) Institute of Medicinal Plant Development, Chinese Academy of Medical Sciences, Peking Union Medical College, No. 151 Malianwa North Road, Haidian District, Beijing 100193,ChinaORIGIN1 tttccgtagg tgaacctgcg gaaggatcat tgtcgagacc aaaataaatc gagcgatttg61 gagaaccggt caaaataagc ggtgattatt atttccgtga tgaacgccat cccagtcgtt121 acctcatccc cttagggtcg aggatgcgag taaggatgga tgaacactca agccggcgca181 gcatcgcgcc aagggaaata tcgaaacatg agcccttaaa tgggtttggt ggaatggggt241 gctgttgcac gccatatgga ttgacatgac tctcggcaat ggatatctcg gctcacgcat301 cgatgaagag cgcagcgaaa tgcgatacgt ggtgcgaatt gcagaatccc gcgaaccatc361 gagtctttga acgcaagttg cgcccgaggc caactggcca agggcacgtt tgcctgggcg421 tcaagcgtta tgtcgcttcg tgtcaactcc atcccgtcga tgtatgggct ggcgaaggct481 cggatgtgca gagtggctca tcgtgcccct cggtgcggtg agctgaagag cgggtcatca541 tctcgttggc tgcgaacgat aaggggtgga ttaaagcgag gcctatgtta ttgtgtcgtg601 tatgcccgag agaagattat acatactcag gagatcccaa atcatgcgtc gatcaaagga661 tggcgcttgg aatgcgaccc caggatgggc gaggccaccc gctgagttta a4LOCUS AJ966733 585 bp DNA linear PLN11-APR-2008DEFINITION Saccharomyces sp. CECT 11011 mitochondrial partial COII gene forcytochrome c oxidase, subunit II.AUTHORS Gonzalez,S.S., Barrio,E. and Querol,A.TITLE Molecular characterization of new natural hybrids of Saccharomyces cerevisiae and S. kudriavzevii in brewingJOURNAL Appl. Environ. Microbiol. 74 (8), 2314-2320 (2008)ORIGIN1 aatattatgt tttatttatt agttatttta ggtttagtat cttgaatgtt atatactatt61 gtaataacat attcaaaaaa ccctattgct tataaatata ttaaacatgg acaaactatt121 gaagttattt gaacaatttt cccagcagta gtattattaa ttattgcttt cccatcattt181 attttattat atttatgtga tgaagttatt tcaccagcta taactattaa agctattgga241 tatcaatgat attgaaaata tgaatattct gattttatta atgatagtgg tgaaactgtt301 gaatttgaat catatgttat tcctgatgaa ttattagaag aaggtcaatt aagattatta361 gatactgata cttctatagt tgtacctgta gatacacata ttagatttgt tgtaacagct421 gctgatgtta ttcatgattt cgctatccca agtttaggta ttaaagttga tgctactcct481 ggtagattaa atcaagtttc tgctttaatt caaagagaag gtgttttcta tgggcaatgc541 tcagagttgt gcgggctggg acatgccaac ataccaatta aaatt5LOCUS Y09069 459 bp mRNA linear INV18-APR-2005DEFINITION D.melanogaster mRNA for NADH-ubiquinone oxidoreductase acyl-carrier subunit, splice variant.AUTHORS Ragone,G., Caizzi,R., Moschetti,R., Barsanti,P., De Pinto,V. and Caggese,C.TITLE The Drosophila melanogaster gene for the NADH:ubiquinoneoxidoreductase acyl carrier protein: developmental expressionanalysis and evidence for alternatively spliced formsJOURNAL Mol. Gen. Genet. 261 (4-5), 690-697 (1999)ORIGIN1 atgtcgttca cacagatcgc gcgcagctgc agtcgactgg cggccacttt ggccccaagg61 agggtcgcct ccggcattct catccaatca caggcctcca ggatgatgca caggatcgcc121 gtgccatcga tgaccagcca gttgagccaa gagtgccgtg gtcgctggca aacgcaattg181 gtgcgcaaat actcggcgaa accgccgctc tcgctgaagc tgatcaatga gcgcgtcttg241 cttgtgctca agctctacga caagatcgat cccagcaagc tcaacgttga gtcgcacttc301 atcaacgact tgggactgga ttccttggac cacgtggagg tcatcatggc catggaggac361 gagttcggtt tcgagatccc cgactctgat gccgagaagc tgcttaaacc tgccgacatt421 attaagtacg tcgccgacaa ggaggatgtg tacgagtaa实验二序列相似性搜索软件—BLAST的使用一、实验目的:掌握序列相似性查询工具—BLAST使用方法和技巧,理解与序列相似性查询相关的几个基本概念。

生物信息学实验一简介:生物信息学实验一是生物信息学实验课程的第一部分,旨在介绍生物信息学的基本概念、工具和技术,以及生物信息学在生物学研究中的应用。
本实验将引导学生通过实际操作,学习并掌握生物信息学的基本原理和操作技巧。
实验设备和材料:- 计算机或笔记本电脑- 生物信息学软件(例如NCBI BLAST、UCSC Genome Browser等)- 相关数据库和工具(例如GenBank、KEGG等)实验目的:1. 了解生物信息学的基本概念和应用领域;2. 学习生物信息学的常用工具和技术;3. 掌握生物序列分析、基因注释和比对等基本操作;4. 学会使用生物信息学软件和数据库进行数据查询和分析;5. 培养科学研究的数据处理和解读能力。
实验步骤:1. 确定研究对象:选择一个感兴趣的生物学问题或基因序列进行研究。
2. 数据获取:使用生物信息学工具和数据库,获取与研究对象相关的生物序列数据。
3. 序列分析:使用生物信息学软件对序列数据进行分析,包括碱基组成、氨基酸序列、启动子分析等。
4. 基因注释:通过比对算法和数据库,对序列进行基因功能注释,确定基因的命名、结构和功能信息。
5. 比对分析:使用比对工具进行序列比对,比较两个或多个序列之间的相似性和差异性。
6. 数据解读:根据分析结果,结合相关文献和知识,对实验数据进行解读和分析,得出科学结论。
实验注意事项:1. 在进行实验前,先了解所要使用的工具和软件的基本操作方法和原理;2. 实验过程中注意数据安全和保密,不得将数据泄露或用于非科研目的;3. 在进行数据分析和解读时,务必准确、客观地进行,不得造假或歪曲实验结果;4. 注意数据的备份和存储,以防止数据丢失或损坏;5. 尊重他人的研究成果和知识产权,合理引用和参考相关文献。
实验结果与讨论:本实验所得的结果可以根据具体的研究对象和实验数据来展开讨论和分析。
例如,如果研究对象是某个基因序列,可以讨论其结构和功能,与其他基因的关联性,以及在哪些生物过程中有重要作用等。

生物信息学的研究方法及应用生物信息学是一门涉及计算机科学、统计学和生物学等多个领域的交叉学科,通过利用计算机分析生物分子的结构、功能及其在不同生物过程中的作用机制,为生物学领域的研究提供了新的思路和方法。
本文将讨论生物信息学的研究方法及应用,以及其对于生物医学研究领域的贡献与前景。
一、生物信息学的研究方法生物信息学的研究方法包括:1. 基因组学分析:基因组学是研究生物体基因组结构、功能和演化的学科,其研究方法主要是基于DNA序列分析和比较。
DNA 序列是生物体遗传信息的基本载体,在基因组学中,科学家们通过对DNA的序列分析,揭示DNA序列的组织方式、正负链、基因区域、基因组重复序列、基因启动子和调控元件等特征,并对其进行比较研究,以深入了解生物体基因组的演化和功能。
2. 蛋白质组学分析:蛋白质组学是研究生物体内所有蛋白质的种类、数量、结构和功能等信息的学科,其研究方法主要是基于质谱分析和蛋白质结构分析。
质谱技术是通过测量蛋白质分子的质荷比,来确定蛋白质分子的质量和序列,蛋白质结构分析是通过模拟计算、X射线晶体学和核磁共振等技术,揭示蛋白质分子的三维结构和功能。
3. 转录组学分析:转录组学是研究生物体内所有基因的转录表达水平和调控机制的学科,其研究方法主要是基于基因芯片和RNA测序技术。
基因芯片技术通过检测组织或细胞内各种基因表达情况的变化,揭示基因调控网络;RNA测序技术是直接测量RNA分子的数量和序列,鉴定转录异构体和全转录本信息。
4. 代谢组学分析:代谢组学是研究生物体代谢产物的种类、数量和代谢途径,以及代谢物与疾病的相关性的学科,其研究方法主要是基于质谱和核磁共振技术。
质谱技术通过检测分子参与产物各自的离子强度比,鉴定代谢产物;核磁共振技术是通过检测样品中的核磁共振信号,确定分子的结构信息。
二、生物信息学的应用生物信息学在生物学的多个领域都有广泛的应用,例如:1. 疾病诊断和治疗:生物信息学可以通过分析患者的基因组、蛋白质组和转录组等信息,识别某些疾病的风险因素和治疗靶点。

生物信息学实验报告班级::学号:日期:实验一核酸和蛋白质序列数据的使用实验目的了解常用的序列数据库,掌握基本的序列数据信息的查询方法。
教学基本要求了解和熟悉NCBI 核酸和蛋白质序列数据库,可以使用BLAST进行序列搜索,解读BLAST 搜索结果,可以利用PHI-BLAST 等工具进行蛋白质序列的结构域搜索,解读蛋白质序列信息,可以在蛋白质三维数据库中查询相关结构信息并进行显示。
实验容提要在序列数据库中查找某条基因序列(BRCA1),通过相关一系列数据库的搜索、比对与结果解释,回答以下问题:1. 该基因的基本功能?2. 编码的蛋白质序列是怎样的?3. 该蛋白质有没有保守的功能结构域 (NCBI CD-search)?4. 该蛋白质的功能是怎样的?5. 该蛋白质的三级结构是什么?如果没有的话,和它最相似的同源物的结构是什么样子的?给出示意图。
实验结果及结论1. 该基因的基本功能?This gene encodes a nuclear phosphoprotein that plays a role in maintaining genomic stability, and it also acts as a tumor suppressor. The encoded protein combines with other tumor suppressors, DNA damagesensors, and signal transducers to form a large multi-subunit protein complex known as the BRCA1-associated genome surveillance complex (BASC). This gene product associates with RNA polymerase II, and through the C-terminal domain, also interacts with histone deacetylase complexes. This protein thus plays a role in transcription, DNA repair of double-stranded breaks, and recombination. Mutations in this gene are responsible for approximately 40% of inherited breast cancers and more than 80% of inherited breast and ovarian cancers. Alternative splicing plays a role in modulating the subcellular localization and physiological function of this gene. Many alternatively spliced transcript variants, some of which are disease-associated mutations, have been described for this gene, but the full-length natures of only some of these variants has been described. A related pseudogene, which is also located on chromosome 17, has been identified. [provided by RefSeq, May 2009]2. 编码的蛋白质序列是怎样的?[Homo sapiens]1 mdlsalrvee vqnvinamqk ilecpiclel ikepvstkcd hifckfcmlk llnqkkgpsq61 cplcknditk rslqestrfs qlveellkii cafqldtgle yansynfakk ennspehlkd121 evsiiqsmgy rnrakrllqs epenpslqet slsvqlsnlg tvrtlrtkqr iqpqktsvyi181 elgsdssedt vnkatycsvg dqellqitpq gtrdeislds akkaacefse tdvtntehhq241 psnndlntte kraaerhpek yqgssvsnlh vepcgtntha sslqhenssl lltkdrmnve301 kaefcnkskq pglarsqhnr wagsketcnd rrtpstekkv dlnadplcer kewnkqklpc361 senprdtedv pwitlnssiq kvnewfsrsd ellgsddshd gesesnakva dvldvlnevd421 eysgssekid llasdpheal ickservhsk svesniedki fgktyrkkas lpnlshvten481 liigafvtep qiiqerpltn klkrkrrpts glhpedfikk adlavqktpe minqgtnqte541 qngqvmnitn sghenktkgd siqneknpnp ieslekesaf ktkaepisss isnmelelni601 hnskapkknr lrrksstrhi halelvvsrn lsppnctelq idscssseei kkkkynqmpv661 rhsrnlqlme gkepatgakk snkpneqtsk rhdsdtfpel kltnapgsft kcsntselke721 fvnpslpree keekletvkv snnaedpkdl mlsgervlqt ersvesssis lvpgtdygtq781 esisllevst lgkaktepnk cvsqcaafen pkglihgcsk dnrndtegfk yplghevnhs 841 retsiemees eldaqylqnt fkvskrqsfa pfsnpgnaee ecatfsahsg slkkqspkvt 901 feceqkeenq gknesnikpv qtvnitagfp vvgqkdkpvd nakcsikggs rfclssqfrg 961 netglitpnk hgllqnpyri pplfpiksfv ktkckknlle enfeehsmsp eremgnenip 1021 stvstisrnn irenvfkeas ssninevgss tnevgssine igssdeniqa elgrnrgpkl 1081 namlrlgvlq pevykqslpg snckhpeikk qeyeevvqtv ntdfspylis dnleqpmgss 1141 hasqvcsetp ddllddgeik edtsfaendi kessavfsks vqkgelsrsp spfththlaq 1201 gyrrgakkle sseenlssed eelpcfqhll fgkvnnipsq strhstvate clsknteenl 1261 lslknslndc snqvilakas qehhlseetk csaslfssqc seledltant ntqdpfligs 1321 skqmrhqses qgvglsdkel vsddeergtg leennqeeqs mdsnlgeaas gcesetsvse 1381 dcsglssqsd ilttqqrdtm qhnliklqqe maeleavleq hgsqpsnsyp siisdssale 1441 dlrnpeqsts ekavltsqks seypisqnpe glsadkfevs adsstsknke pgversspsk 1501 cpslddrwym hscsgslqnr nypsqeelik vvdveeqqle esgphdltet sylprqdleg 1561 tpylesgisl fsddpesdps edrapesarv gnipsstsal kvpqlkvaes aqspaaahtt 1621 dtagynamee svsrekpelt astervnkrm smvvsgltpe efmlvykfar khhitltnli 1681 teetthvvmk tdaefvcert lkyflgiagg kwvvsyfwvt qsikerkmln ehdfevrgdv 1741 vngrnhqgpk raresqdrki frgleiccyg pftnmptdql ewmvqlcgas vvkelssftl 1801 gtgvhpivvv qpdawtedng fhaigqmcea pvvtrewvld svalyqcqel dtylipqiph 1861 shy3. 该蛋白质有没有保守的功能结构域 (NCBI CD-search)?有保守的供能结构域。

生物信息学技术的研究及应用生物信息学是一门新兴的学科,它运用计算机、数学、物理学等多个学科知识,以及生物学、遗传学等相关领域的原理和方法,对生物学数据和信息进行收集、处理、存储、分析和展示。
随着生物学领域的快速发展和高通量技术的应用,生物信息学技术变得越来越重要。
1.生物信息学的研究1.1 基因组学基因组学是生物信息学的一个核心领域,它研究生物体的基因组结构与功能。
基因组数据的高通量产生及堆积,为基因组学领域带来了大量的问题和挑战。
目前,随着第三代测序技术的发展和应用,基因组数据已经从几个物种水平发展到了全球多个物种。
1.2 转录组学转录组学是研究一个生物物种的所有基因或部分基因在一定时间、空间或条件下的表达模式的学科。
转录组学的技术主要包括芯片和测序等方法,这些技术的应用已经扩展到研究发育过程、胁迫响应、疾病发病机制等方面。
1.3 蛋白质组学蛋白质组学是研究生物体内所有蛋白质在不同的实验条件下表达和功能的一门学科。
为了更有效地分析蛋白质组数据,研究人员发展出了一系列技术,如两种维电泳和ICAT等。
2.生物信息学技术的应用2.1 基因组学在疾病诊断和治疗中的应用基因组学技术在疾病的诊断和治疗中起着越来越重要的作用。
基因检测可以检测某个人的某些基因是否存在缺陷,从而判断是否会发生遗传性疾病。
同时,基因组学技术还可以帮助研究人员对疾病的发病机制进行更深入的研究,为疾病的诊断和治疗提供更好的方法。
2.2 生物信息学在新药研发中的应用生物信息学技术在新药研发中发挥重要作用。
通过生物信息学技术,可以对药物分子的结构、作用机理等进行分析和预测,为新药的设计和开发提供科学依据。
同时,生物信息学在药物代谢、药效等方面也可以发挥作用,加速新药研发的进度。
2.3 生物信息学在农业中的应用生物信息学技术在农业中的应用也越来越广泛。
通过基因定位和分析,可以实现作物的高效育种。
同时,生物信息学还可以用来鉴定肉类、乳制品和其他食品的真伪,确保食品的质量、安全和营养价值。

生物信息学实验一生物信息学实验一: DNA序列比对一、引言DNA序列比对是生物信息学中的基础操作之一。
DNA序列比对可以通过比较两个或多个DNA序列之间的相似性和差异性,进而揭示序列之间的进化关系、基因功能以及潜在的生物学意义。
本实验旨在介绍DNA序列比对的基本原理、常见比对工具以及实验操作步骤。
二、实验原理1. 基本原理DNA序列比对是指将两个或多个DNA序列在相同参考框架下进行对比,以确定序列之间的相似性和差异性。
基于比对结果,可以推断序列中的保守区域、突变位点、插入缺失等信息。
2. 比对方法常见的DNA序列比对方法包括全局比对和局部比对。
全局比对适用于两个序列长度相似且整体结构相似的情况,例如比对同一基因的两个亚型。
而局部比对适用于两个序列之间存在较大差异的情况,例如比对基因组中的编码区域。
3. 比对工具生物信息学领域中有许多常用的DNA序列比对工具,如BLAST (Basic Local Alignment Search Tool)、ClustalW和MUSCLE等。
每个工具都有其独特的优势和适用范围,根据具体的研究目的和样本特点选择合适的比对工具。
三、实验步骤1. 收集序列数据在进行DNA序列比对实验前,首先需要收集待比对的DNA序列数据。
可以从公共数据库(如GenBank)或实验室已有的数据中获取所需序列,并保存为FASTA格式。
2. 选择比对工具根据比对的目的和序列特点,选择合适的比对工具。
例如,对于全局比对,可以选用BLAST工具;对于局部比对,可以选择ClustalW或MUSCLE工具。
3. 导入序列数据将收集到的DNA序列导入所选择的比对工具中。
一般来说,比对工具能够接受FASTA格式的输入。
确保正确导入所有待比对的序列,并设置比对参数。
4. 进行比对运行选定的比对工具,开始进行DNA序列比对。
比对过程可能需要花费一定的时间,具体时间取决于比对工具的算法和序列的长度。
5. 分析比对结果比对完成后,可以获取比对结果。
(一)生物信息学数据库实验目的:了解生物信息学的各大门户网站,了解数据库的内容及结构,理解各数据库注释的含义。
1、分别读取人CDK4的核酸序列及蛋白质序列,保存FASTA格式序列,熟悉数据库记录的flatfile格式,看懂其中的注释。
在NCBI数据库中读取人CDK4的核酸序列,步骤入下:(1)选择核酸(Nucleotide)将CDK4输入搜索栏中,点击Search。
(2)在Top Organisms中选择人(Homo sapients)(3)在数据库出现的数据中选择合适的核酸序列,选择FASTA可以使序列以FASTA 的格式显示出来。
GenBank形式则显示该序列的详细信息。
(4)保存的FASTA格式序列如下>gi|345525417|ref|NM_000075.3| Homo sapiens cyclin-dependent kinase 4 (CDK4), mRNACACCTCCTGTCCGCCCCTCAGCGCATGGGTGGCGGTCACGTGCCCAGAACGTCCGGCGTTCGCCCCG CCCTCCCAGTTTCCGCGCGCCTCTTTGGCAGCTGGTCACATGGTGAGGGTGGGGGTGAGGGGGCCTCTCTAG CTTGCGGCCTGTGTCTATGGTCGGGCCCTCTGCGTCCAGCTGCTCCGGACCGAGCTCGGGTGTATGGG(5) 在NCBI数据库中读取人CDK4的蛋白质序列,步骤入下:选择蛋白质(Protein)将CDK4输入搜索栏中,点击Search。
选择CDK4[Homo sapiens]的FASTA格式2、2BXI练习使用Jmol浏览蛋白质的三维结构。
()先进入PDB,再查看。
无法访问此网站3、练习使用Pubmed文献数据库(1)Pubmed检索运算符逻辑与:AND;逻辑或:OR;逻辑非:NOT。
注:当当一个检索表达式中同时含有三个运算符时,运算顺序从左至右,括号可以改变运算顺序。
生物信息学的基本原理和研究方法生物信息学是一个结合了计算机技术、统计学和生物学等多个学科的交叉领域。
它通过处理生物信息来揭示生物系统内部的特征及其功能。
在这里,我们将探讨生物信息学的基本原理和研究方法。
一、生物信息学的基本原理1.1 基础生物学在进行生物信息学研究之前,需要有一定的基础生物学知识。
生物学是研究生命的领域,其研究范畴包括生物体内部和外部的结构、生物体内部的能量转化、物质代谢,以及生物体的基因组和表达状态等。
而生物信息学则是一种通过对现代生物学高通量数据的处理和分析,来加深对生物系统的理解的新型学科。
生物信息学的研究不仅涉及到大量的数据分析,还需要对基本的生物学概念有深刻的理解。
1.2 计算机技术生物信息学中最为重要的工具是计算机技术,因为这些技术能够对生物分子和生物过程进行建模和仿真。
计算机技术的发展为生物信息学的研究提供了强有力的支持和帮助。
其中,计算机科学的基本知识,如算法设计、数据结构和数据库系统的使用等,是生物信息学家必须具备的通用知识。
此外,对于那些从事基因组学和转录组学等领域研究的生物学家来说,掌握一些专门的编程语言和算法也至关重要。
1.3 统计学统计学是生物信息学中的另一个必备知识领域。
许多生物学研究所使用的实验技术都产生了大量的数据,这些数据需要通过统计学方法进行分析。
在生物信息学中,通过使用统计学方法,例如聚类分析、分类器和回归模型,可以从基因组数据、转录组数据和蛋白质组数据中得出更多有关生物体特征和生物过程的信息。
二、生物信息学的研究方法2.1 基因组学基因组学主要是针对基因组的研究。
它探索整个基因组序列,并识别其中所有的基因和非编码序列。
基因组学对于理解基因的功能和调控方式都有重大意义。
基因组学研究中最常用的分析工具是比对分析。
比对分析是将测序数据和参考序列进行比对,以此寻找变异和注释基因型的方法。
2.2 转录组学转录组学包括对一组基因在给定条件下的表达进行研究。
生物信息学实验大纲一、实验目的1.掌握基本的生物信息学知识和技能,包括生物数据库的利用、序列分析、基因组分析等。
2.学习并运用常用的生物信息学工具和软件,如BLAST、CLUSTAL、Phylogenetic等。
3.培养学生的科学思维和实验操作能力,提高数据分析和解释的能力。
4.通过实验培养学生的团队合作和沟通能力。
二、实验内容1.生物数据库的利用a.学习如何进行基因、蛋白质和基因组数据的检索和下载。
b.学习如何利用数据库进行序列比对、同源物种搜索等分析。
2.序列分析a.学习和掌握常用的序列比对软件(如CLUSTAL)和序列比对方法。
b.进行序列比对的实验操作,分析序列间的相似性和差异。
3.基因组分析a.学习并掌握基因组数据的下载和处理方法。
b.进行基因组数据分析的实验操作,如基因注释、富集分析等。
4.蛋白质结构预测a.学习并掌握蛋白质结构预测方法和软件。
b.进行蛋白质结构预测的实验操作,分析蛋白质结构的二级结构、三维结构等。
5.基因表达谱分析a.学习并掌握基因表达谱数据的获取和处理方法。
b.进行基因表达谱分析的实验操作,如差异表达基因的筛选和功能分析等。
6.进化分析a.学习进化分析的基本理论和方法。
b.进行进化分析的实验操作,如构建进化树、计算进化距离等。
三、实验要求1.实验组织形式:小组合作进行实验,每个小组由3-5名学生组成,共同完成实验设计、操作和数据分析。
2.实验前阅读实验指导书和相关科研论文,了解实验背景和基本原理。
3.每个小组在实验后撰写实验报告,并进行实验结果的展示和讨论。
4.每个学生需参与实验操作和数据分析,能够独立思考和解释实验结果。
四、实验设备和材料1.计算机及互联网连接设备。
2.生物信息学工具和软件,如BLAST、CLUSTAL、Phylogenetic等。
3.数据库访问权限或相关数据库的下载工具。
4.相关的生物序列和基因组数据。
五、实验评分指标1.独立思考和解释实验结果的能力。
生物信息学实验实验一生物信息数据库的检索一.实验目的:1.了解生物信息学的各大门户网站以及其中的主要资源。
2.了解主要数据库的内容及结构,理解各数据库注释的含义。
3.以PubMed为例,学会文献数据库的基本查询检索方法。
二.实验内容:(1)国际与国内的生物信息中心国际NCBI、EBI、ExPASy,EMBL、SIB、TIGR以及国内CBI、BioSino网站的熟悉及内容的了解。
核酸序列数据库:genbank/EMBL-bank/DDBJNCBI网址:/EBI网址:/EMBL网址:/embl蛋白质序列数据库:Swiss Prot 、ExPASy网址:/Uniprot网址:/蛋白质结构数据库:PDB网址:/pdb/(2)数据库内容、结构与注释的浏览分别读取The spike protein of SARS-Corona Virus在NCBI中的核酸序列、SWISS-PROT蛋白质序列以及PDB蛋白质结构序列,熟悉数据库记录的结构,学会看懂其中的注释。
核酸序列:SWISS-PROT蛋白质序列:PDB蛋白质结构序列:其PDB文件见附件SARS-Corona Virus.PDB文件分别读取Heamagglutinin Genes of H9N2 Subtype Influenza A Viruses(禽流感H9N2亚型HA基因)在NCBI中的核酸序列、SWISS-PROT蛋白质序列以及PDB蛋白质结构序列,熟悉数据库记录的结构,学会看懂其中的注释。
核酸序列:SWISS-PROT蛋白质序列PDB蛋白质结构序列其PDB文件见附件H9N2.PDB文件(3)文献信息的查找与管理有效地使用NCBI PubMed提供的各种主要功能,查询并下载相关课题或研究方向的论文文摘与文献全文。
查询Influenza A Viruses分子进化研究方向的文章。
三.实验要求:(1)以其中的一个信息中心网站为例,列举其中的主要资源(数据库、网上分析、生物计算、数据下载等)。
生物信息学实验教程实验一、基因、蛋白质序列分析【实验目的】1、掌握基因、蛋白质序列检索的操作方法;2、熟悉蛋白质基本性质分析及其电子表达谱3、蛋白基因的引物设计【实验内容】1、使用Entrez或SRS信息查询系统检索人脂联素(adiponectin)蛋白质序列;2、使用网站对上述蛋白质序列进行分子质量、氨基酸组成、和疏水性等基本性质分析;3、蛋白基因的引物设计【实验方法】1、人脂联素基因、蛋白质序列的检索:(1)调用Internet浏览器并在其地址栏输入Entrez网址(/Entrez);(2)在Search后的选择栏中选择nucleartide\protein;(3)在输入栏输入homo sapiens adiponectin;(4)点击go后显示序列接受号及序列名称;(5)点击序列接受号NP_004788 (adiponectin precursor; adipose most abundant genetranscript 1 [Homo sapiens])后显示序列详细信息;(6)将序列转为FASTA格式保存(参考上述步骤使用SRS信息查询系统检索人脂联素蛋白质序列);(7)进入UNIGENE数据库分析其电子表达谱2、进入网站对人脂联素蛋白质序列进行分子质量、氨基酸组成和疏水性等基本性质分析:3、利用prime prime5.0设计此基因PCR引物4、独立完成NYGGF4、LYRM1两个基因的上述操作。
【作业】1、提交使用上述软件对人脂联素、NYGGF4、LYRM1蛋白质序列进行基本性质分析及其电子表达谱蛋白质实验二、序列结构预测【实验目的】1、熟悉基于序列同源性分析的蛋白质功能预测,了解基于motif、结构位点、结构功能域数据库的蛋白质功能预测;2、了解蛋白质结构预测。
【实验内容】1、对人脂联素蛋白质序列进行基于NCBI/Blast软件的蛋白质同源性分析;2、对人脂联素蛋白质序列进行motif结构分析;3、对人脂联素蛋白质序列进行二级结构和三维结构预测。
实验报告
实验课程:生物信息学
学号:
姓名:
专业班级:
指导老师:
实验四蛋白质结构与功能预测
[实验目的]
掌握蛋白质一级、二级和三级结构分析的一些工具,了解与蛋白质功能分析相关的数据库,如:SwissProt蛋白质序列数据库、PDB结构数据库等。
[实验原理]
现有的蛋白质功能分析工具和平台都是根据已知的蛋白质结构进行诠释分析、总结结构规律建立参考数据库,并以此作为预测未知蛋白质结构和功能的依据。
[实验内容]
1、熟悉与蛋白质分析相关的数据库资源,如SwissProt蛋白质序列数据库、PDB
结构数据库、PROSITE
2、利用PredictProtein对蛋白质序列进行分析
3、利用swiss-model对蛋白质序列进行三维结构预测
[实验步骤]
1、首先我们选取几段蛋白质序列
序列的格式为FASTA格式,FASTA是一种基于文本用于表示核苷酸序列或氨基酸序列的格式。
在这种格式中碱基对或氨基酸用单个字母来编码,且允许在序列前添加序列名及注释,如下图所示。
然后我们将准备好的氨基酸序列复制到https:///
点击predictprotein等待几分钟即可得到相应的结果
下图为蛋白质的二级结构预测图
下图是关于这个蛋白质的基础组成和基本的蛋白质概述
然后我们将氨基酸序列复制到
/interactive
点击build model即可得到三维结构
三维结构为。
生物信息学的实验研究
近年来,随着基因测序和生物信息学技术的飞速发展,生物信息学已经成为生
命科学领域中不可或缺的重要分支之一。
生物信息学的主要研究内容包括:基因组学、转录组学、代谢组学、蛋白质组学等方面,其中涉及生物大数据的处理和解读等重要研究内容。
因此,越来越多的生命科学研究者开始涉足生物信息学领域,不断开展有关生物信息学的实验研究。
随着生物信息学技术的发展,生物信息学实验研究的方法和手段也越来越多样化。
其中,最常见的实验方法包括:RNA测序、蛋白质组学、基因组学等。
其中,RNA测序是一种比较常用的生物信息学实验方法,它可以通过测定细胞或组织中
的RNA分子来获取有关基因功能的信息。
RNA测序技术已经在多个研究领域中得到了广泛应用,例如:诊断疾病、寻找药物靶点、发现新的基因等。
以肿瘤研究为例,RNA测序技术可以用于研究肿瘤细胞中的基因表达变化,进而推断肿瘤相关
的信号途径和调控机制。
蛋白质组学是另一种重要的生物信息学实验研究方法,它可以通过分析细胞或
组织中的蛋白质来获取有关细胞功能和代谢途径的信息。
蛋白质组学技术通过分离、纯化、鉴定、定量、结构和功能分析、互作网络分析等手段,来研究细胞内蛋白质组成及其变化情况。
在癌症研究中,蛋白质组学技术可以用于鉴定肿瘤标志物、发现新的肿瘤治疗靶点、分析药物作用机制等。
除了RNA测序和蛋白质组学外,基因组学是另一个重要的生物信息学实验研
究方法。
基因组学主要研究基因组的序列、特征、功能和进化等问题。
基因组学技术包括:基因鉴定、功能分析、基因进化等方面,并且在生命科学研究领域中得到广泛的应用。
在深度研究人类基因组序列的过程中,人体基因组计划已经开始,其目标是:通过测序人类所有染色体的序列,解析和研究基因的功能和调控机制,这一计划为生物信息学实验研究提供了更多的研究对象和内容。
总之,生物信息学实验研究方法的不断发展,为生命科学领域的研究和应用提供了更多的可能性。
随着技术的不断更新和优化,生物信息学实验研究将进一步加强其在生命科学领域中的地位和作用,为人类的健康和幸福不断做出更大的贡献。