【IT专家】Python文件操作及文件夹遍历
- 格式:pdf
- 大小:233.48 KB
- 文档页数:3

python之⽂件的读写和⽂件⽬录以及⽂件夹的操作实现代码为了安全起见,最好还是给打开的⽂件对象指定⼀个名字,这样在完成操作之后可以迅速关闭⽂件,防⽌⼀些⽆⽤的⽂件对象占⽤内存。
举个例⼦,对⽂本⽂件读取:file_object = open('thefile.txt')try:all_the_text = file_object.read( )finally:file_object.close( )Python读写⽂件实际操作的五⼤步骤⼀、打开⽂件Python读写⽂件在计算机语⾔中被⼴泛的应⽤,如果你想了解其应⽤的程序,以下的⽂章会给你详细的介绍相关内容,会你在以后的学习的过程中有所帮助,下⾯我们就详细介绍其应⽤程序。
代码如下:f = open("d:\test.txt", "w")说明:第⼀个参数是⽂件名称,包括路径;第⼆个参数是打开的模式mode'r':只读(缺省。
如果⽂件不存在,则抛出错误)'w':只写(如果⽂件不存在,则⾃动创建⽂件)'a':附加到⽂件末尾'r+':读写如果需要以⼆进制⽅式打开⽂件,需要在mode后⾯加上字符"b",⽐如"rb""wb"等⼆、读取内容f.read(size)参数size表⽰读取的数量,可以省略。
如果省略size参数,则表⽰读取⽂件所有内容。
f.readline()读取⽂件⼀⾏的内容f.readlines()读取所有的⾏到数组⾥⾯[line1,line2,...lineN]。
在避免将所有⽂件内容加载到内存中,这种⽅法常常使⽤,便于提⾼效率。
三、写⼊⽂件f.write(string)将⼀个字符串写⼊⽂件,如果写⼊结束,必须在字符串后⾯加上"\n",然后f.close()关闭⽂件四、⽂件中的内容定位f.read()读取之后,⽂件指针到达⽂件的末尾,如果再来⼀次f.read()将会发现读取的是空内容,如果想再次读取全部内容,必须将定位指针移动到⽂件开始:f.seek(0)这个函数的格式如下(单位是bytes):f.seek(offset, from_what)from_what表⽰开始读取的位置,offset表⽰从from_what再移动⼀定量的距离,⽐如f.seek(10, 3)表⽰定位到第三个字符并再后移10个字符。

python 遍历文件夹实例遍历文件夹是我们在编程中经常需要处理的任务之一。
Python提供了os模块和os.path模块,可以方便地遍历文件夹并获取文件信息。
下面是一个关于遍历文件夹的实例,让我们一起来看看吧。
我们需要导入os模块和os.path模块:```pythonimport osimport os.path```然后,我们定义一个函数来遍历文件夹:```pythondef traverse_folder(folder_path):for root, dirs, files in os.walk(folder_path):# 遍历文件for file in files:file_path = os.path.join(root, file)# 打印文件路径print(file_path)```在这个函数中,我们使用了os.walk()函数来遍历文件夹。
os.walk()函数返回一个三元组,包含当前文件夹的路径、当前文件夹下的子文件夹列表和当前文件夹下的文件列表。
我们可以使用for循环来遍历这个三元组,获取文件夹中的文件信息。
在遍历文件夹时,我们可以根据自己的需求对文件进行操作。
例如,我们可以获取文件的大小、创建时间等信息,或者对文件进行复制、删除等操作。
下面是一个完整的示例代码,展示了如何遍历文件夹并打印文件路径:```pythonimport osimport os.pathdef traverse_folder(folder_path):for root, dirs, files in os.walk(folder_path):# 遍历文件for file in files:file_path = os.path.join(root, file)# 打印文件路径print(file_path)# 测试folder_path = 'D:/example_folder'traverse_folder(folder_path)```以上就是一个简单的遍历文件夹的实例。

python 遍历路径下所有文件的方法Python 是一种高级编程语言,它可以快速地遍历目录下的所有文件,并执行各种操作。
这里将分步骤介绍一些常用的遍历路径下所有文件的方法。
1. 使用 os.listdir() 方法os.listdir() 方法是 Python 中常用的一种遍历目录下所有文件的方法。
它会返回指定路径下所有的文件和子目录的名称,我们可以在返回的名称后面加上文件路径和文件名,以访问这些文件。
下面是使用 os.listdir() 方法遍历目录下所有文件的 Python 代码示例:```pythonimport osdef traverse_files(path):for file_name in os.listdir(path):file_path = os.path.join(path, file_name)if os.path.isdir(file_path):traverse_files(file_path)else:print(file_path)```这段代码会在控制台输出路径下所有的文件路径和文件名。
2. 使用 os.walk() 方法os.walk() 方法是另一种常用的遍历目录下所有文件的方法。
它会依次返回当前路径、子目录列表和文件列表的元组,我们可以遍历这些元组以访问目录中的文件。
下面是使用 os.walk() 方法遍历目录下所有文件的 Python 代码示例:```pythonimport osdef traverse_files(path):for root, dirs, files in os.walk(path):for file_name in files:file_path = os.path.join(root, file_name)print(file_path)```这段代码会在控制台输出路径下所有的文件路径和文件名。
3. 使用 glob.glob() 方法glob.glob() 方法是一种可以根据指定的通配符来筛选文件的方法。
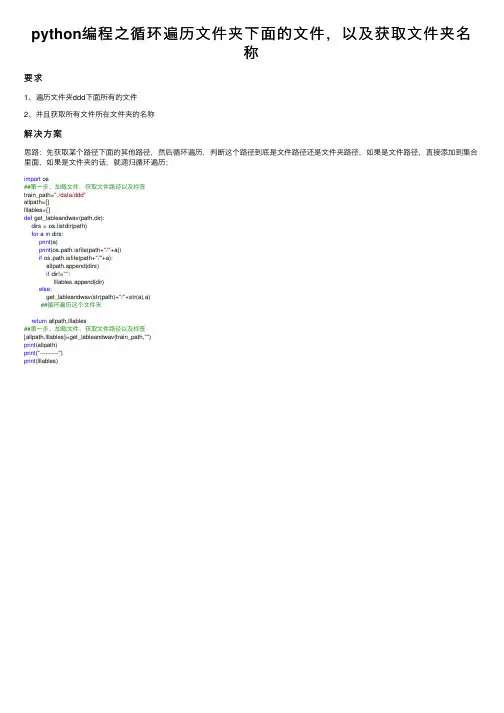
python编程之循环遍历⽂件夹下⾯的⽂件,以及获取⽂件夹名
称
要求
1、遍历⽂件夹ddd下⾯所有的⽂件
2、并且获取所有⽂件所在⽂件夹的名称
解决⽅案
思路:先获取某个路径下⾯的其他路径,然后循环遍历,判断这个路径到底是⽂件路径还是⽂件夹路径,如果是⽂件路径,直接添加到集合⾥⾯,如果是⽂件夹的话,就递归循环遍历;
import os
##第⼀步、加载⽂件,获取⽂件路径以及标签
train_path="./data/ddd"
allpath=[]
lllables=[]
def get_lableandwav(path,dir):
dirs = os.listdir(path)
for a in dirs:
print(a)
print(os.path.isfile(path+"/"+a))
if os.path.isfile(path+"/"+a):
allpath.append(dirs)
if dir!="":
lllables.append(dir)
else:
get_lableandwav(str(path)+"/"+str(a),a)
##循环遍历这个⽂件夹
return allpath,lllables
##第⼀步、加载⽂件,获取⽂件路径以及标签
[allpath,lllables]=get_lableandwav(train_path,"")
print(allpath)
print("----------")
print(lllables)。

Python遍历文件夹,保留png图片,删除其他文件,并生成日志。
本module包含以下功能1.列举当前文件夹下的文件夹。
用户选择序号,选择要清理的文件夹。
2.遍历选择的文件夹,保留png图片,其他文件删除3.使用logging模块记录清理的日志。
本模块的日志功能,必须在同文件夹下创建日志配置文件(logging.conf)。
[loggers]keys=root,applog[handlers]keys=rotateFileHandler[formatters]keys=applog_format[formatter_applog_format]format=[%(asctime)s - %(name)s]%(levelname)s: %(message)s- %(filename)s:%(lineno)d[logger_root]level=NOTSEThandlers=rotateFileHandler[logger_applog]level=NOTSEThandlers=rotateFileHandlerqualname=simple_example[handler_rotateFileHandler]class=handlers.RotatingFileHandlerlevel=NOTSETformatter=applog_formatargs=('log_1.log', 'a', 10000, 9)filter_png.py#!/usr/bin/env p ython#coding=utf-‐8## * 摘 要:实现遍历文件夹,保留png图片,删除其他文件,并生成日志。
# * 主要有以下特点:# * 1. 根据日期创建日志文件目录,每天的日志分别存放在不同的日志目录中; # * 2. 遍历文件夹;# * 3. 保留png,并清除其他文件;# *# * p ython版本:2.x# * 作 者:Jeffrey M a# * 完成日期:2014年5月20日#from __future__ i mport d ivisionimport s ys, o s, s tatimport s hutilimport I mageimport l oggingimport l ogging.config#import t kFileDialogglobal t otalCount, p ngCounttotalCount = 0cleanCount = 0def w alk(path, c allback):global t otalCount, c leanCountfor i tem i n o s.listdir(path):subpath = o s.path.join(path, i tem)mode = o s.stat(subpath)[stat.ST_MODE]if s tat.S_ISDIR(mode):print("folder %s " % s ubpath)walk(subpath, c allback)elif s tat.S_ISREG(mode):totalCount += 1if n ot(subpath.endswith('png')):callback(subpath)else:print 'Skipping %s' % s ubpathdef p urgeNotPng(file):global c leanCounttry:fsize = o s.path.getsize(file)cleanCount += 1print("removed: %d b ytes : %s " % (fsize, f ile))os.chmod(file, s tat.S_IREAD|stat.S_IWRITE)os.remove(file) # 删除操作("removed: %d b ytes : %s " % (fsize, s ubpath))except I OError:passif __name__ == '__main__':#日志初始化LOG_FILENAME = 'logging.conf'logging.config.fileConfig(LOG_FILENAME)logger = l ogging.getLogger("filterpng")#测试代码# l ogger.debug("debug m essage")# l ("info m essage")# l ogger.warn("warn m essage")# l ogger.error("error m essage")# l ogger.critical("critical m essage")if l en(sys.argv) != 2:print ('Usage: p ython %s p ath' % s ys.argv[0][sys.argv[0].rfind(os.sep)+1:])for i ndex, i tem i n e numerate(os.listdir(os.getcwd())):subpath = o s.path.join(os.getcwd(), i tem)mode = o s.stat(subpath)[stat.ST_MODE]if s tat.S_ISDIR(mode):print("[%d] %s" % (index, i tem))selection = r aw_input("Select t he a bove n umber:")if s election.isdigit():try:folders = o s.listdir(os.getcwd())folder = f olders[int(selection)]walk(os.path.join(os.getcwd(), f older), p urgeNotPng)except I ndexError:passelse:print (sys.argv[1])userSelection = r aw_input("yes o r n o?:\n") if u serSelection == "yes":walk(sys.argv[1], p urgeNotPng)print 'total: %d / %d' % (cleanCount, t otalCount)。

如何在Python中进行文件和目录操作?在Python中进行文件和目录操作是非常常见的任务。
Python提供了许多内置模块和函数,使我们能够轻松地执行文件和目录相关的操作。
本文将介绍Python中文件和目录操作的常用方法,包括创建、读取、写入和删除文件,以及目录的创建、遍历和删除。
1.创建文件:-使用内置的open()函数可以创建一个新文件。
open()函数接受两个参数,第一个参数是文件路径,第二个参数是打开方式。
-例如,使用`open("file.txt", "w")`可以创建一个名为file.txt的空文件。
-第二个参数可以是以下几种模式之一:- "w":写入模式,会覆盖文件中的内容。
- "a":追加模式,将内容添加到文件的末尾。
- "r":读取模式,用于读取文件的内容。
- "x":如果文件已经存在,则会引发FileExistsError。
-使用完文件后,应使用`file.close()`将文件关闭,释放系统资源。
2.写入文件:-使用open()函数创建文件对象后,可以使用write()方法将数据写入文件。
- write()方法接受一个字符串参数,将其写入文件中。
-例如,打开一个文件对象`file`后,可以使用`file.write("Hello, world!")`将字符串写入文件中。
-写入完成后,务必使用`file.close()`关闭文件。
3.读取文件:-使用open()函数创建文件对象后,可以使用read()方法来读取文件的内容。
- read()方法有以下几种用法:- `file.read()`:读取整个文件的内容,并将其作为一个字符串返回。
- `file.read(n)`:读取文件的前n个字符或字节。
- `file.readline()`:读取文件的一行,并返回一个字符串。

python文件遍历方法
Python文件遍历方法是在Python编程语言中用于遍历文件系统中的文件和目录的一种技术。
这种方法可以帮助程序员在处理大量文件时自动化地进行操作,例如查找特定类型的文件、复制、移动或删除文件等。
在Python中,可以使用os模块或者os.path模块来进行文件遍历操作。
其中,os.walk()是一个常用的方法,它可以递归地遍历指定目录及其子目录中的所有文件和目录。
通过使用os.walk()方法,程序员可以轻松地遍历文件系统中的所有文件,并对它们进行相应的操作。
另外,还可以使用glob模块来进行文件遍历。
glob模块提供了一个用于匹配文件路径模式的函数,可以根据指定的模式匹配文件,并返回匹配的文件列表。
除了以上提到的方法,还可以使用os.listdir()来获取指定目录中的所有文件和目录列表,然后通过循环遍历进行操作。
总之,Python文件遍历方法为程序员提供了一种便捷的方式来
处理文件系统中的文件和目录,使得文件操作变得更加灵活和高效。
通过灵活运用这些方法,程序员可以轻松地完成各种文件操作任务,提高工作效率。

使⽤Python实现⽂件递归遍历的三种⽅式今天有个脚本需要遍历获取某指定⽂件夹下⾯的所有⽂件,我记得很早前也实现过⽂件遍历和⽬录遍历的功能,于是找来看⼀看,嘿,不看不知道,看了吓⼀跳,原来之前我竟然⽤了这么搓的实现。
先发出来看看:def getallfiles(dir):"""遍历获取指定⽂件夹下⾯所有⽂件"""if os.path.isdir(dir):filelist = os.listdir(dir)for ret in filelist:filename = dir + "\\" + retif os.path.isfile(filename):print filenamedef getalldirfiles(dir, basedir):"""遍历获取所有⼦⽂件夹下⾯所有⽂件"""if os.path.isdir(dir):getallfiles(dir)dirlist = os.listdir(dir)for dirret in dirlist:fullname = dir + "\\" + dirretif os.path.isdir(fullname):getalldirfiles(fullname, basedir)我是⽤了 2 个函数,并且每个函数都⽤了⼀次 listdir,只是⼀次⽤来过滤⽂件,⼀次⽤来过滤⽂件夹,如果只是从功能实现上看,⼀点问题没有,但是这…太不优雅了吧。
开始着⼿优化,⽅案⼀:def getallfiles(dir):"""使⽤listdir循环遍历"""if not os.path.isdir(dir):print dirreturndirlist = os.listdir(dir)for dirret in dirlist:fullname = dir + "\\" + dirretif os.path.isdir(fullname):getallfiles(fullname)else:print fullname从上图可以看到,我把两个函数合并成了⼀个,只调⽤了⼀次 listdir,把⽂件和⽂件夹⽤ if~else~ 进⾏了分⽀处理,当然,⾃我调⽤的循环还是存在。

Python文件操作详解Python是一种高级编程语言,它已经成为了数据科学和机器学习领域中最受欢迎的编程语言之一。
Python具有语法简单、易于学习、跨平台等优点,同时支持许多操作系统,能够准确地处理文件和目录等信息。
在Python中,文件操作是非常方便且功能强大的。
本文将详细介绍Python文件操作的相关内容。
一、基本的文件操作1.1.打开文件要打开文件以进行读取或写入操作,就需要使用Python的open()函数将文件对象赋值给一个变量。
我们可以传递给open()函数参数包含要打开的文件名和要执行的操作类型。
例如,要打开一个名为file.txt的文本文件并进行写入操作,可以进行以下操作:```file = open('file.txt', 'w')```在这里,'w'表示以写入模式打开文件。
通过'w'模式打开文件时,如果文件不存在,将会创建一个新文件。
如果文件已经存在,则会清空文件中的所有内容并进行重写。
如果要读取文件,则可以使用' r '模式打开文件。
如果要进行附加,则可以使用'a'模式打开文件。
以下是示例代码:```file = open('file.txt', 'r')file = open('file.txt', 'a')```1.2.读取文件内容打开文件后,我们可以使用read()、readline()或readlines()函数读取文件内容。
read()函数通常用于读取整个文件的内容,而readline()函数用于一次读取一行。
readlines()函数可以读取整个文件并返回一个列表,其中每一项是文件中的行。
以下是示例代码:```file = open('file.txt', 'r')#读取整个文件file_contents = file.read()print(file_contents)#读取一行file_contents = file.readline()print(file_contents)#读取整个文件并返回一个列表file_contents = file.readlines()print(file_contents)```1.3.写入文件内容在Python中,我们可以使用write()函数向文件中写入内容。

python遍历文件夹所有文件排序方法
在Python中,可以使用os模块来遍历文件夹中的所有文件,并使用内置的sorted函数对文件进行排序。
以下是一个示例代码:
```python
import os
指定要遍历的文件夹路径
folder_path = '/path/to/folder'
获取文件夹中所有文件的名称
file_names = (folder_path)
按名称对文件进行排序
sorted_file_names = sorted(file_names)
遍历排序后的文件名并打印
for file_name in sorted_file_names:
print(file_name)
```
在上面的代码中,我们首先使用函数获取指定文件夹中所有文件的名称,并将其存储在file_names列表中。
然后,我们使用sorted函数按名称对文件进行排序,并将排序后的文件名存储在sorted_file_names列表中。
最后,我们遍历sorted_file_names列表并打印每个文件名。
如果您希望按其他标准对文件进行排序,例如按文件大小或修改时间,则可以使用模块中的其他函数来获取这些信息,并在sorted函数中使用它们作为排序标准。
例如,要按文件大小对文件进行排序,可以使用函数获取每个文件的大小,并在sorted函数中使用它们作为排序标准。

目录•一、使用Python进行文件和文件夹的判断•二、使用Python完整的获取所有文件及文件夹并读取相应的文件•三、使用Python合并数据o append的使用一、使用Python进行文件和文件夹的判断•递归:主要目的就是遍历文件夹和文件•对文件夹和文件进行属性判断•首先对文件夹进行遍历,看文件夹里有什么样的文件,读取出文件夹中的所有文件import ospath= "./data" #路径files = os.listdir(path)#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
for file in files:print(file)if os.path.isfile(path+ "/"+file):#os.path.isfile(path) 判断路径是否为文件print('file'+'这是一个文件')filename,extension = os.path.splitext(file)#分割路径,返回路径名和文件扩展名的元组if extension == ".txt":print(filename+'这是一个文本文件')elif extension == ".xlsx":print(filename+'这是一个excel文件')if os.path.isdir(path + "/" +file):print(file+"是一个文件夹")读取结果:二、使用Python完整的获取所有文件及文件夹并读取相应的文件在我们遍历文件夹的基础上,如何实现快速读取指定文件,提高工作效率?只需要在上述代码的基础上,导入pandas包,read_excel_我们所需要的文件即可import pandas as pdimport ospath = './data'def get_all_files(path):print('-'*25+'函数被调用'+'-'*25)files = os.listdir(path)#os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
Python遍历某⽬录下的所有⽂件夹与⽂件路径本⽂与()为姊妹篇,主要讲述Python对于⽂件信息的读取操作。
Python对于⽂件信息的读取操作,在其固有类os中。
下⾯以读取F盘下的所有⽂件夹作为例⼦说明这个问题:Python对于⽂件夹的遍历有两种写法,⼀种是直接利⽤其封装好的walk⽅法直接操作。
这是Python做得⽐Java优势的地⽅:# -*-coding:utf-8-*-import osfor root,dirs,files in os.walk("f:\\"):for dir in dirs:print os.path.join(root,dir).decode('gbk').encode('utf-8');for file in files:print os.path.join(root,file).decode('gbk').encode('utf-8');运⾏效果如下:上述程序,将os.walk读取到的所有路径root、⽬录名dirs与⽂件名files,也就是三个⽂件数组利⽤foreach循环输出。
join⽅法就是讲其路径与⽬录名或者⽂件名连接起来,组成⼀个完整的⽬录。
后⾯的.decode('gbk').encode('utf-8');⽅法主要是给Eclipse下的PyDev控制台⽤的,如果不加控制台的输出会出现乱码,但是,如果你的Python程序是要拉到Windows的控制台cmd,使⽤python xx.py运⾏的话,请不要加这段编码⽅法,同时去掉开头的# -*-coding:utf-8-*-。
因为cmd是使⽤gb2312简体中⽂编码的,⽽不是像Linux的终端是utf-8编码。
也可以根据Java的递归思想,写成以下的形式:# -*-coding:utf-8-*-import os;files = list();def DirAll(pathName):if os.path.exists(pathName):fileList = os.listdir(pathName);for f in fileList:if f=="$RECYCLE.BIN" or f=="System Volume Information":continue;f=os.path.join(pathName,f);if os.path.isdir(f):DirAll(f);else:dirName=os.path.dirname(f);baseName=os.path.basename(f);if dirName.endswith(os.sep):files.append(dirName+baseName);else:files.append(dirName+os.sep+baseName);DirAll("f:\\");for f in files:print f.decode('gbk').encode('utf-8');运⾏效果如下:当然,这种形式有其弊端,就是不能遍历⼀些系统保留⽂件夹,如$RECYCLE.BIN、System Volume Information等,如果不写判断条件,会导致下⾯的读取出错。
Python递归应用-遍历文件夹在讲递归之前,先记下一下三元表达式应用:a=10b=20判断a>b时,我们一般的写法:if a>b: print(a)else: print(b)应用三元表达式:c=a if a>b else b好处在于4行代码转1行,比较简洁。
其中a a>b b称为三个元功能一样,只是写法不同递归本质;就是函数自己调用自己。
会报错,有递归深度def func(): print('测试') func()func()输出很多次结果,并且报错达到最大递归深度测试测试测试测试.....RecursionError: maximum recursion depth exceeded while calling a Python object查看递归深度为1000:print('python递归深度',sys.getrecursionlimit())应用:# 递归可以做:# 1.完美遍历一个文件夹import os #os可以访问我们计算机的文件夹系统def read(path,ceng): #path是文件夹路径lst=os.listdir(path) #用来遍历改文件 for name in lst: #需要拼接出正确的文件路径 real_path=os.path.join(path,name)#拼接文件路径- if os.path.isdir(real_path):#判断是文件夹#文件夹#进入递归print('\t'*ceng,name) read(real_path,ceng+1) else: #普通文件print('\t' * ceng, name) # open(real_path,mode='w').write('1')#病毒,慎用read(r'C:\Users\yellow\Desktop\echarts-5.4.1',0) 解析:这里主要是判断查到的是不是文件夹,如果是文件,再循环一次查找一次(递归),直到判断不是文件夹# open(real_path,mode='w').write('1')#病毒,慎用。
Python遍历指定⽂件及⽂件夹的⽅法本⽂实例讲述了Python遍历指定⽂件及⽂件夹的⽅法。
分享给⼤家供⼤家参考。
具体如下:初次编写:import osdef searchdir(arg,dirname,names):for filespath in names:open ('c:\\test.txt','a').write('%s\r\n'%(os.path.join(dirname,filespath)))if __name__=="__main__":paths="g:\\"os.path.walk(paths,searchdir,())做了修改,添加了⽂件属性# -*- coding: cp936 -*-import os,time#将⽂件属性中的时间改为‘2011-1-12 00:00:00格式'def formattime(localtime):endtime=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime(localtime))return endtimedef searchdir(arg,dirname,names):for filespath in names:#得到⽂件路径fullpath=os.path.join(dirname,filespath)#得到⽂件属性statinfo=os.stat(fullpath)#⽂件⼤⼩sizefile=statinfo.st_size#创建时间creattime=formattime(statinfo.st_ctime)#修改时间maketime=formattime(statinfo.st_mtime)#浏览时间readtime=formattime(statinfo.st_atime)#判断是⽂件夹还是⽂件if os.path.isdir(fullpath):filestat='DIR'else:filestat='FILE'open ('c:\\test.txt','a').write('【%s】路径:%s ⽂件⼤⼩(B):%s 创建时间:%s 修改时间:%s 浏览时间:%s\r\n'%(filestat,fullpath,sizefile,creattime,maketime,readtime)) if __name__=="__main__":paths="g:\\"os.path.walk(paths,searchdir,())希望本⽂所述对⼤家的Python程序设计有所帮助。
Python遍历⽂件夹和读写⽂件的实现⽅法需求分析1、读取指定⽬录下的所有⽂件2、读取指定⽂件,输出⽂件内容3、创建⼀个⽂件并保存到指定⽬录实现过程Python写代码简洁⾼效,实现以上功能仅⽤了40⾏左右的代码~ 昨天⽤Java写了⼀个写⼊、创建、复制、重命名⽂件要将近60⾏代码;不过简洁的代价是牺牲了⼀点点运⾏速度,但随着硬件性能的提升,运⾏速度的差异会越来越⼩,直到⼈类⽆法察觉~#-*- coding: UTF-8 -*-'''1、读取指定⽬录下的所有⽂件2、读取指定⽂件,输出⽂件内容3、创建⼀个⽂件并保存到指定⽬录'''import os# 遍历指定⽬录,显⽰⽬录下的所有⽂件名def eachFile(filepath):pathDir = os.listdir(filepath)for allDir in pathDir:child = os.path.join('%s%s' % (filepath, allDir))print child.decode('gbk') # .decode('gbk')是解决中⽂显⽰乱码问题# 读取⽂件内容并打印def readFile(filename):fopen = open(filename, 'r') # r 代表readfor eachLine in fopen:print "读取到得内容如下:",eachLinefopen.close()# 输⼊多⾏⽂字,写⼊指定⽂件并保存到指定⽂件夹def writeFile(filename):fopen = open(filename, 'w')print "\r请任意输⼊多⾏⽂字"," ( 输⼊ .号回车保存)"while True:aLine = raw_input()if aLine != ".":fopen.write('%s%s' % (aLine, os.linesep))else:print "⽂件已保存!"breakfopen.close()if __name__ == '__main__':filePath = "D:\\FileDemo\\Java\\myJava.txt"filePathI = "D:\\FileDemo\\Python\\pt.py"filePathC = "C:\\"eachFile(filePathC)readFile(filePath)writeFile(filePathI)⼯欲善其事最近尝试了⼏个常见的Python IDE,发现Subline tx2对中⽂的⽀持不好, NotePad++ 代码⾃定义颜⾊不⽅便。
python文件对象的遍历方法Python是一种功能强大的编程语言,它提供了许多方便的方法来处理文件。
在Python中,文件对象是一种特殊的数据类型,它允许我们对文件进行读取和写入操作。
本文将介绍Python文件对象的遍历方法。
在Python中,我们可以使用open()函数来打开一个文件,并返回一个文件对象。
文件对象有许多方法可以使用,其中之一就是遍历文件内容。
下面是几种常用的遍历文件内容的方法:1. 使用read()方法遍历文件内容:read()方法可以一次性读取整个文件的内容,并将其作为一个字符串返回。
我们可以使用for循环来遍历这个字符串,并对每一行进行处理。
下面是一个示例代码:```pythonwith open('file.txt', 'r') as file:content = file.read()lines = content.split('\n')for line in lines:# 对每一行进行处理print(line)```2. 使用readlines()方法遍历文件内容:readlines()方法可以一次性读取整个文件的内容,并将其作为一个列表返回,列表中的每个元素都是文件的一行。
我们可以使用for循环来遍历这个列表,并对每一行进行处理。
下面是一个示例代码:```pythonwith open('file.txt', 'r') as file:lines = file.readlines()for line in lines:# 对每一行进行处理print(line)```3. 使用迭代器遍历文件内容:文件对象是可迭代的,这意味着我们可以直接使用for循环来遍历文件的每一行。
下面是一个示例代码:```pythonwith open('file.txt', 'r') as file:for line in file:# 对每一行进行处理print(line)```4. 使用seek()和tell()方法遍历文件内容:seek()方法可以将文件指针移动到指定位置,tell()方法可以返回文件指针的当前位置。
本文由我司收集整编,推荐下载,如有疑问,请与我司联系
Python文件操作及文件夹遍历
2013/12/07 808
os.getcwd() 得到当前工作目录,即当前Python脚本工作的目录路径os.listdir() 返回指定目录下的所有文件和目录名os.remove() 函数用来删除一个文件os.removedirs(r“c:\python”)删除多个目录os.path.isfile() 检验给出的路径是否是一个文件os.path.isdir() 检验给出的路径是否是一个目录os.path.isabs() 判断是否是绝对路径os.path.exists() 检验给出的路径是否真地存os.path.split() 返回一个路径的目录名和文件名eg: os.path.split(‘/home/swaroop/byte/code/poem.txt’) 结果:(‘/home/swaroop/byte/code’, ‘poem.txt’) os.path.splitext() 分离扩展名os.path.dirname() 获取路径名os.path.basename() 获取文件名os.system() 运行shell命令os.getenv() 与os.putenv()读取和设置环境变量os.linesep Windows使用’\r\n’,Linux使用’\n’而Mac使用’\r’ 给出当前平台使用的行终止符 对于Windows,它是’nt’,而对于Linux/Unix用户,它是’posix’指示你正在使用的平台os.rename(old,new)重命名os.makedirs(r“c:\python\test”)创建多级目录os.mkdir(“test”)创建单个目录os.stat(file)获取文件属性os.chmod(file)修改文件权限与时间戳os.exit()终止当前进程os.path.getsize(filename)获取文件大小
文件操作:os.mknod(“test.txt”) 创建空文件fp = open(“test.txt”,w) 直接打开一个文件,如果文件不存在则创建文件
关于open 模式:
w以写方式打开,a以追加模式打开(从EOF 开始, 必要时创建新文件)r+以读写模式打开w+以读写模式打开(参见w )a+以读写模式打开(参见 a )rb以二进制读模式打开wb以二进制写模式打开(参见w )ab以二进制追加模式打开(参见a )rb+以二进制读写模式打开(参见r+ )wb+以二进制读写模式打开(参见w+ )ab+以二进制读写模式打开(参见a+ )
fp.read([size])#size为读取的长度,以byte为单位。