模式识别理论
- 格式:ppt
- 大小:1.08 MB
- 文档页数:66

模式识别的基本理论与方法模式识别是人工智能和计算机科学领域中的一个重要分支,也是现代科学技术中广泛应用的一种技术手段。
它涉及到从大量的数据中自动识别出某种模式的过程,其应用领域非常广泛,如人脸识别、指纹识别、语音识别等领域。
一、模式识别的基本理论模式是事物或现象中简单重复的部分或整体,模式识别是通过对数据进行分类、聚类等方式分析、发现事物或现象中的规律性,并将其应用于实际生产和科学研究中。
模式识别的基本理论主要包括数据分析、统计学、人工神经网络及算法模型等。
1. 数据分析数据分析是模式识别的一个重要组成部分,它是指通过对数据进行收集、分析、处理和应用,从中发现有用的信息以及可用于决策或预测的模型。
数据分析可以采用统计学、机器学习、人工神经网络等方法,无论采用何种方法,数据分析的目的都是找到数据表达的规律和模式。
2. 统计学统计学是模式识别所使用的数学工具之一,主要通过收集和分析数据来提供决策支持和预测结果。
统计学的主要应用领域包括控制过程、质量控制、风险评估和数据挖掘等。
3. 人工神经网络人工神经网络是一种基于人类大脑神经结构的人工智能技术,它通过对输入的数据进行处理、学习,将数据转换为信号输出,以此模拟人脑的神经网络功能。
人工神经网络可以应用于图像识别、音频识别等领域。
4. 算法模型算法模型是模式识别的基本理论之一,它是指在进行数据分析和处理的时候所采用的算法模型。
常用的算法模型包括决策树、支持向量机、神经网络等。
二、模式识别的方法模式识别的方法主要包括监督学习、无监督学习和半监督学习。
1. 监督学习监督学习是指在训练模型时,数据集中已知了对应的标签或类别信息。
监督学习的主要步骤是将已知数据输入到模型中进行训练,训练好的模型之后可以将未知的数据进行分类或预测处理。
监督学习包括分类和回归两种类型。
2. 无监督学习无监督学习是指在训练模型时,数据集中没有对应的标签或类别信息。
无监督学习的主要步骤是将数据输入到模型中进行训练,训练好的模型之后可以从数据中提取出特定的模式、结构或规律。

基于模糊逻辑的模式识别理论与应用研究摘要:模式识别是计算机科学中的重要研究领域,它旨在从大量数据中寻找可重复的模式和规律,并根据这些模式和规律进行分类、识别以及预测。
虽然传统的模式识别方法在某些情况下能够取得良好的效果,但是对于那些复杂、模糊或者不确定的问题,传统的方法存在局限性。
因此,基于模糊逻辑的模式识别理论逐渐引起研究者们的关注。
本文将介绍基于模糊逻辑的模式识别理论的基本概念、原理以及应用,并对其进行总结与展望。
一、引言模式识别是一门综合性的研究领域,它涉及信号处理、模式分类、机器学习等方面的知识,并且在图像识别、人脸识别、语音识别等领域有着广泛的应用。
然而,传统的模式识别方法主要基于精确逻辑,难以处理模糊、混乱、不确定的问题。
而基于模糊逻辑的模式识别理论在处理模糊问题时表现出了良好的效果,因此逐渐成为研究者们的关注焦点。
二、基于模糊逻辑的模式识别理论的基本概念1. 模糊逻辑的基本原理模糊逻辑是一种用来处理模糊概念和模糊问题的数学理论,它基于隶属度的概念,将事物划分为不同的模糊集合,并定义了模糊集合之间的运算规则。
在模糊逻辑中,每个元素都有一个与之相关的隶属度,代表了其属于某个集合的程度。
2. 模糊集合和隶属函数模糊集合是指具有模糊性质的集合,其中的元素隶属于该集合的程度可以用隶属函数来描述。
隶属函数可以看作是一个映射,将元素映射到一个隶属度值,代表了元素属于该模糊集合的程度。
3. 模糊逻辑的推理机制模糊逻辑的推理机制主要包括模糊逻辑运算和模糊推理两个方面。
模糊逻辑运算包括模糊交、模糊并和模糊补等操作,用来对模糊集合进行运算。
模糊推理则是基于模糊规则,通过模糊推理机制来实现对未知事物的推理和预测。
三、基于模糊逻辑的模式识别应用研究基于模糊逻辑的模式识别应用研究已经涉及到多个领域,并取得了一些重要的成果。
1. 图像识别在图像识别领域,基于模糊逻辑的模式识别方法能够有效处理图像中的模糊和噪声问题。


设计如何应用模式识别和原型说的理论举例说明模式识别和原型说是两种常用的理论框架,可以应用于各个领域,比如计算机科学、心理学、社会科学等。
它们可以帮助我们识别和解释事物之间的关联性和相似性,从而提高我们的认知水平和问题解决能力。
首先,我们来介绍一下模式识别。
模式识别是一种研究对象之间的关联性和相似性的方法。
它的基本思想是通过比较事物之间的相似之处,找到它们的共同特征或规律。
模式识别可以帮助我们从海量的数据中提取出有用的信息,并将其应用于实际问题的解决中。
下面举一个计算机科学中的应用例子。
假设我们要开发一个能够自动识别图片中物体的系统,比如识别猫的系统。
我们可以使用模式识别的方法来训练此系统。
首先,我们需要收集大量的猫的图片作为数据集。
然后,我们可以使用机器学习算法,比如卷积神经网络,来训练我们的模型。
通过反复的训练和调整参数,我们可以使模型具备识别猫的能力。
最后,当我们给系统输入一张新的图片时,它就能够通过比对图片的特征和已有的模式来判断出其中是否有猫的存在。
接下来,我们来介绍一下原型说。
原型说是一种心理学理论,认为人类在形成概念时会根据已有的原型或范例进行分类和判断。
原型说认为人们对于一些概念的理解是基于一种典型的例子,而不是根据所有实例的综合。
下面举一个心理学中的应用例子。
假设我们要研究人类对于美的感知。
我们可以采用原型说的方法,首先让被试评价一系列图片的美观程度,并记录下他们的评分。
然后,我们可以分析这些评分数据,找出评分较高的几个图片,并将它们作为我们研究的“美的原型”。
接下来,我们可以设计更多的实验,观察人们对于这些原型的反应。
通过检测人们对于这些原型的注意力、情绪等方面的反应,我们可以研究出人们对于美的感知的一些普遍规律。
无论是模式识别还是原型说,它们都可以帮助我们在认知和问题解决中起到指导作用。
模式识别通过发现事物之间的关联性和相似性,帮助我们提取有用的信息;而原型说通过找出典型范例,帮助我们建立概念和判断。


人类的心理学认知心理学的关键理论心理学是研究人类心理活动和行为的科学。
在心理学领域中,认知心理学是一门重要的分支,主要关注人类的心理认知过程以及与之相关的心理学理论。
在认知心理学中,存在着一些关键理论,本文将对其中的一些理论进行探讨。
一、信息加工理论信息加工理论是认知心理学研究的基石之一。
根据该理论,人类的认知活动可以类比为计算机的信息加工过程。
人类从外界获取信息,通过感知、注意、记忆、推理和问题解决等过程对信息进行加工和处理。
这一理论为我们理解人类认知活动的本质提供了重要的视角。
二、模式识别理论模式识别理论是认知心理学中的一项关键理论,它描述了人类在认知活动中是如何通过对信息的模式和结构进行识别与理解的。
根据模式识别理论,人类通过将刺激与其在记忆中存储的模式进行匹配,从而对信息进行认知和理解。
这一理论不仅对我们认知的基本过程有着重要的解释作用,还在智能系统设计和模式识别技术方面具有实际应用。
三、认知心理学的开放系统理论认知心理学的开放系统理论是指人类认知系统与外界环境之间相互作用的理论。
根据这一理论,人类认知系统不仅仅是一个封闭的个体内部过程,它与外部环境之间的相互作用对于认知过程的发展和塑造起着重要作用。
这一理论的提出,拓展了我们对人类认知过程的理解,也为研究认知与行为的关系提供了新的视角。
四、认知失调理论认知失调理论是由心理学家弗斯基提出的,旨在解释人类在认知冲突和矛盾情境下的的心理体验和行为调整。
认知失调理论认为,当人类遇到认知冲突时,会产生一种不舒服的心理状态,进而通过调整自己的认知来减轻这种不适。
这一理论对于理解人类的人际关系、认知偏差以及心理控制等方面有着重要的影响。
五、认知发展理论认知发展理论是由心理学家皮亚杰提出的,旨在解释人类认知能力的发展和变化过程。
根据认知发展理论,人类的认知能力会随着年龄的增长不断发展,成熟和变化。
虽然皮亚杰的认知发展理论主要是针对儿童认知的,但其对于理解认知过程的发展规律以及认知与行为之间的关系仍然具有重要的意义。

模式识别的含义及其主要理论(实用版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的实用资料,如职业道德、时事政治、政治理论、专业基础、说课稿集、教资面试、综合素质、教案模板、考试题库、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor.I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!In addition, this shop provides you with various types of practical materials, such as professional ethics, current affairs and politics, political theory, professional foundation, lecture collections, teaching interviews, comprehensive qualities, lesson plan templates, exam question banks, other materials, etc. Learn about different data formats and writing methods, so stay tuned!模式识别的含义及其主要理论在心理学记忆的分类中,按照记忆内容保持的时间长短可以将记忆分成瞬时记忆、短时记忆和长时记忆,而在瞬时记忆的影响因素中我们常常会看到模式识别这一名词,这里主要来介绍一下模式识别的含义以及其相关理论。
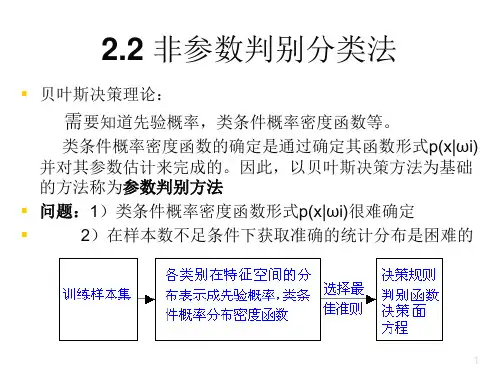


十种模式识别认知理论简介导引人们在认知景物时,常常寻找它与其它事物的相同与不同之处,根据使用目的进行分类,人脑的这种思维能力就构成了模式和识别的能力。
所谓模式,是指若干元素或成分按一定关系形成某种刺激结构,也可以说模式是刺激的组合。
当人们能够确认他所知觉的某个模式是什么时,将它与其他模式区分开来,这就是模式识别。
例如,有人想把一大批图片分成人物、动物、风景、建筑物、其他等五种类型分别保管,上述五种类型就是五个类别,也就是五个不同的模式,分类的过程叫做模式识别。
模式有简有繁,繁杂的模式往往是由多个子模式组成。
认知心理学家西蒙认为:“人们在解决数学问题时,大多数是通过模式识别来解决的,首先要识别眼前的问题属于哪一类,然后以此为索引在记忆储存中提取相应的知识,这就是模式识别。
我们之所以关心模式识别认知理论,是因为它是建立图像(景物)理解数学模型的思想源泉。
例如:传统的模式识别理论有人把它分为五类:模板匹配模式;原型匹配模式;特征分析模式;结构描述模式;傅里叶模式。
现在图像理解中主要的数学处理方法,几乎都是源于五种传统模式识别理论而建立的,或是基于它们的变形。
近二十多年来新提出的模式识别理论有人把它分为五种:视觉计算理论;注意的特征整合理论;成分识别理论;相互作用激活理论;视觉拓扑理论。
其中,马尔(Marr)的视觉计算理论是当前计算机(机器人)视觉的主流理论。
其它的理论,也被众多探索者们作为创新的源泉。
然而,无论上述那一种模式识别理论,都存在着或多或少的片面性,迄今为止尚未形成一个较具有说服力的、普遍认可的模式识别理论。
这正是制约图像识别(计算机视觉)数学模型发展的根本所在。
下面我们将各种模式识别理论分别介绍之。
模板匹配模式(传统模式识别之一)这个模型最早是针对机器的模式识别而提出来的,后来被用来解释人的模式识别。
它的核心思想是认为在人的长时记忆中,贮存着许多各式各样的过去在生活中形成的外部模式的袖珍复本。

模式识别理论及其应用综述
模式识别是指通过对已知模式的学习,从输入数据中自动识别并分类相似的模式或对象。
它是一种基于统计和机器学习的技术,可以应用于多个领域,例如图像处理、语音识别、自然语言处理等。
在模式识别中,最常用的技术是机器学习算法。
机器学习算法是一种通过对大量训练数据的学习,从中发现规律和模式,然后应用这些规律和模式来解决问题的方法。
常用的机器学习算法包括支持向量机、决策树、神经网络等。
在图像处理领域,模式识别可以用于图像分类和目标检测。
例如,当我们要对图像库中的图像进行分类时,可以使用模式识别技术来自动识别和分类不同类型的图像。
在目标检测方面,模式识别可以帮助我们在图像中快速准确地检测和定位目标。
在语音识别领域,模式识别可以用于语音识别和语音合成。
语音识别是将语音信号转化为文本或命令的过程,而语音合成则是将文本转化为语音信号的过程。
模式识别可以通过对大量语音数据的学习,发现语音信号的特征和模式,从而实现准确的语音识别和语音合成。
在自然语言处理领域,模式识别可以用于文本分类和信息提取。
文本分类是将文本数据根据其内容分类到不同的类别中,例如将新闻文章分类到不同的主题类别中。
信息提取是从大量文本中提取出指定信息的过程,例如从新闻文章中提取出人物、地点和事件等信息。
模式识别可以通过对大量文本数据的学习,发现文本的特征和模式,从而实现准确的文本分类和信息提取。
总之,模式识别是一种基于统计和机器学习的技术,可以应用于多个领域,例如图像处理、语音识别、自然语言处理等。
它可以通过对大量数据的学习,发现数据中的规律和模式,从而实现准确的模式识别和分类。
关于知觉认知的几种主要模式识别理论中模式表征方式的分析肖玉浩( 东北师范大学教育科学学院08心理学系1013408010 ) 认知心理学中,一般把知觉看作是感觉信息的组织和解释,也就是获得感觉信息的意义的过程。
认知心理学的知觉研究主要涉及模式识别,特别是视觉的模式识别,进而形成了模式识别理论。
常见的模式识别的理论模型或假说一般认为,模式识别过程是感觉信息与长时记忆中的有关信息进行比较,再决定它与哪个长时记忆中的项目有着最佳匹配的过程。
模式识别的过程就是对信息进行转换,使之获得适合于人的各种信息加工系统形式,也就是通过编码获得在大脑中的表征的过程。
模式识别理论经过长时间的发展,尤其是受人工智能的影响,常见的模式识别理论,如模板说、原型说、特征说由简单、视觉计算理论等在模式表征方式上形成了各自的特点,共同促进了对模式识别理论研究的深入。
在教育心理学中,一般认为只存在命题表征,在模式识别理论中,表征的方式存在争议,即是单一的命题表征,还是在单一编码说之外同样存在表象表征。
几种常见的模式识别理论在表征方式上形成了各有特色的看法。
由对机器的模式识别做出解释提出的模板说,它的核心思想认为在人的长时记忆里储存了许多各式各样的过去生活中形成的外部模式的袖珍复本,这些复本与外部的模板有一一对应的关系,编码的过程就是获得模板与复本获得最佳匹配的过程。
因此,模板匹配说模型是一种自下而上的加工模型,是单一编码说的代表,而这种单一编码说是只存在表象表征。
显然,模板说有他的缺陷,如大脑缺乏如此繁多的复本以识别客观事物,在无法获得绝对匹配时对模板如何解释,还有就是这一理论主要针对视觉研究而言,缺少更大的外部价值。
随着最初模板说的修订,模板说修正理论提出了预加工过程以使模板和复本能够更好匹配。
预加工就是在匹配之前根据经验将刺激标准化,因此难免会出现自上而下的加工。
综上,模板说支持双重编码说,在命题表征外存在表象表征,并以表象表征为主。
知觉认知中几种主要的模式识别理论表征与加工分析知觉认知是指人类通过感觉器官对外界信息进行接收、加工和理解的过程。
在此过程中,模式识别理论表征与加工起着重要的作用。
模式识别是指通过对现实世界的事物、事件、现象等进行观察、分析和比较,从而发现其中的规律和模式。
在认知过程中,模式识别理论表征与加工可分为几种主要的模式。
第一种模式是感知模式。
感知是人类通过感觉器官对外界信息进行接收、加工和理解的过程。
感知模式是指在感知过程中形成的针对感觉的一系列模式。
感知模式的形成受到人们的感觉器官的刺激和大脑对于这些刺激的加工和处理的影响。
感知模式在认知过程中起到了重要的作用,它能够帮助人们对外界信息进行分类、识别和理解。
第二种模式是注意模式。
注意是指人们在认知过程中对某些信息进行有意识的关注和选择。
注意模式是指在注意过程中形成的针对注意的一系列模式。
注意模式的形成与人们的认知目标、认知任务、认知能力等相关。
注意模式可以帮助人们将注意力集中在最重要和最有意义的信息上,提高认知效果和资源利用率。
第三种模式是记忆模式。
记忆是指人们在经历过的事物、经历和知识等方面形成和保存的信息。
记忆模式是指在记忆过程中形成的针对记忆的一系列模式。
记忆模式的形成与人们的记忆机制和记忆能力有关。
记忆模式可以帮助人们在认知过程中通过回忆、复述和应用等方式利用已有的记忆,提高认知速度和效果。
第四种模式是思维模式。
思维是指人们在认知过程中对信息进行推理、判断、解决问题等方面的活动。
思维模式是指在思维过程中形成的针对思维的一系列模式。
思维模式的形成与人们的思维方式、思维规律和思维能力等相关。
思维模式可以帮助人们在认知过程中通过逻辑、分析和创造等方式对信息进行有意识的处理和运用,提高认知效果和质量。
在以上几种模式识别理论表征与加工中,它们相互交织、相互影响,并在认知过程中起到了重要的作用。
模式识别理论表征与加工的研究不仅有助于深入理解人类认知的本质和机制,还为应用领域如教育、医学、工程等提供了有益的参考和指导。
基础心理学认知心理学主要理论心理学是研究人类心理过程和行为的科学领域,而认知心理学则是探究人类思维、记忆、学习和知觉等认知过程的分支学科。
在认知心理学中存在着一些主要的理论,本文将重点介绍这些理论并进行详细解析。
一、信息处理模型信息处理模型是认知心理学的核心理论之一,它描述了人类感知、思考和决策的过程。
根据这一模型,人类的思维过程可以类比为计算机的信息处理过程。
这个模型包含了输入、处理和输出三个主要的步骤。
在输入阶段,人们通过感觉器官接收外界的刺激信息,比如光线和声音等。
这些信息会被转换为可处理的形式,进入到认知系统中进行加工。
在处理阶段,人们对接收到的信息进行解码和分析,构建起对外界的理解和认知。
这个过程中,涉及到注意、记忆、推理和问题解决等认知能力。
在输出阶段,人们将处理好的信息再转化为行为和反应,以表达自己的想法和意图。
信息处理模型的独特之处在于它强调了思维过程中信息的处理和转化。
这个模型的提出使得认知心理学能够更好地解释人们的认知能力和行为表现。
二、模式识别理论模式识别理论是认知心理学的另一个重要理论,它关注人类的感知和认知是如何对外界的模式和结构进行识别和理解的。
该理论认为,人们通过对感知到的刺激进行组织和分类,从中提取出一些重要的特征和结构来进行认知。
在模式识别的过程中,人们会使用自己已有的知识和经验,将新的信息与之进行对比和匹配,从而得出有关对象或事件的认知结论。
这个过程可以包括对形状、颜色、纹理、语义等多种特征的分析和整合。
模式识别理论对于理解人类的感知和认知过程有着重要的意义。
它帮助我们解释了人们为什么能够准确识别物体、理解语言和形成概念等认知能力。
三、连接主义理论连接主义理论是认知心理学的另一种重要理论,它强调神经元之间的相互连接和信息传递对于人类认知的影响。
该理论认为,人类的思维和认知能力是由大量的神经元之间的相互作用所构成的网络而产生的。
在连接主义理论中,神经元之间的连接是通过权重来表示的。