带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树
- 格式:doc
- 大小:28.50 KB
- 文档页数:6

哪些算法是分类算法---------------------------------------------------------------------- 下边是总结的几种常见分类算法,这里只是对几种分类算法的初步认识。
所谓分类,简单来说,就是根据文本的特征或属性,划分到已有的类别中。
常用的分类算法包括:决策树分类法,朴素的贝叶斯分类算法(native Bayesian classifier)、基于支持向量机(SVM)的分类器,神经网络法,k-最近邻法(k-nearest neighbor,kNN),模糊分类法等等1、决策树决策树是一种用于对实例进行分类的树形结构。
一种依托于策略抉择而建立起来的树。
决策树由节点(node)和有向边(directed edge)组成。
节点的类型有两种:内部节点和叶子节点。
其中,内部节点表示一个特征或属性的测试条件(用于分开具有不同特性的记录),叶子节点表示一个分类。
一旦我们构造了一个决策树模型,以它为基础来进行分类将是非常容易的。
具体做法是,从根节点开始,地实例的某一特征进行测试,根据测试结构将实例分配到其子节点(也就是选择适当的分支);沿着该分支可能达到叶子节点或者到达另一个内部节点时,那么就使用新的测试条件递归执行下去,直到抵达一个叶子节点。
当到达叶子节点时,我们便得到了最终的分类结果。
从数据产生决策树的机器学习技术叫做决策树学习, 通俗点说就是决策树,说白了,这是一种依托于分类、训练上的预测树,根据已知预测、归类未来。
分类理论的太过抽象,下面举两个浅显易懂的例子:决策树分类的思想类似于找对象。
现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:女儿:多大年纪了?母亲:26。
女儿:长的帅不帅?母亲:挺帅的。
女儿:收入高不?母亲:不算很高,中等情况。
女儿:是公务员不?母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。

机器学习常见算法分类机器学习算法主要可以分为监督学习、无监督学习和强化学习三大类。
在这三大类下,又可以进一步细分为多个具体的算法。
1.监督学习算法:- 线性回归(Linear Regression): 基于线性模型,通过最小化预测与实际值之间的差距进行训练。
- 逻辑回归(Logistic Regression): 用于二分类问题,通过建立逻辑回归模型,将输入映射到一个概率值。
- 决策树(Decision Tree): 通过一系列判断节点和叶节点的组合,建立一个树形结构的分类模型。
- 支持向量机(Support Vector Machine,SVM): 通过寻找最大间隔来划分不同类别之间的边界。
- 随机森林(Random Forest): 基于多个决策树的集成算法,通过投票选择最终结果。
- K近邻算法(K-Nearest Neighbors,KNN): 根据新样本与训练样本之间的距离来确定分类。
2.无监督学习算法:无监督学习是指从输入数据中寻找隐藏结构或模式,而不需要预先标记的训练数据。
常见的无监督学习算法包括:- 聚类算法(Clustering): 将数据分成不同的簇,使得同一簇内的数据相似度较高,不同簇间的数据差异较大。
- K均值算法(K-Means): 将数据分成K个簇,每个簇中的数据与该簇的中心点距离最近。
-DBSCAN:根据数据点的密度划分簇,具有自动确定簇个数的能力。
- 关联规则学习(Association Rule Learning): 发现数据中的关联规则,例如购物篮分析等。
3.强化学习算法:强化学习是一种与环境进行交互的学习方式,通过试错而不是通过标记的训练数据进行学习。
常见的强化学习算法包括:- Q学习(Q-Learning): 通过探索和利用的方式学习到一个动作值函数,用于选择在给定状态下的最优动作。
- 深度强化学习(Deep Reinforcement Learning): 结合深度神经网络和强化学习的方法,用于处理高维、复杂的任务。
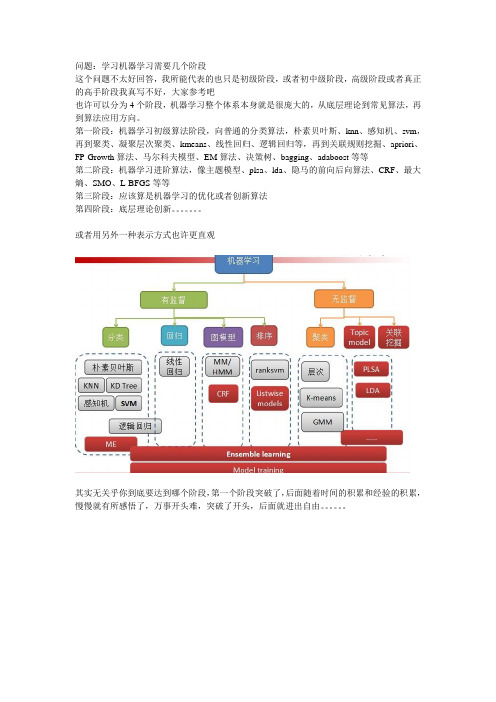
问题:学习机器学习需要几个阶段
这个问题不太好回答,我所能代表的也只是初级阶段,或者初中级阶段,高级阶段或者真正的高手阶段我真写不好,大家参考吧
也许可以分为4个阶段,机器学习整个体系本身就是很庞大的,从底层理论到常见算法,再到算法应用方向。
第一阶段:机器学习初级算法阶段,向普通的分类算法,朴素贝叶斯、knn、感知机、svm,再到聚类、凝聚层次聚类、kmeans、线性回归、逻辑回归等,再到关联规则挖掘、apriori、FP-Growth算法、马尔科夫模型、EM算法、决策树、bagging、adaboost等等
第二阶段:机器学习进阶算法,像主题模型、plsa、lda、隐马的前向后向算法、CRF、最大熵、SMO、L-BFGS等等
第三阶段:应该算是机器学习的优化或者创新算法
第四阶段:底层理论创新。
或者用另外一种表示方式也许更直观
其实无关乎你到底要达到哪个阶段,第一个阶段突破了,后面随着时间的积累和经验的积累,慢慢就有所感悟了,万事开头难,突破了开头,后面就进出自由。

通常将分类算法分为以下七种:决策树、朴素贝叶斯、逻辑回归、K-最近邻、支持向量机、神经网络和集成学习。
这些算法都有各自的特点和应用场景。
1. 决策树:它利用树形结构,根据样本属性划分节点,直到达到叶子节点,叶子节点即为类别。
其优点包括易于理解和解释,对于数据的准备往往是简单或者不必要的,能够同时处理数据型和常规型属性,是一个白盒模型等。
2. 朴素贝叶斯:基于贝叶斯定理与特征条件独立假设的算法,该算法是一种有监督的学习模型,主要用于解决分类问题。
3. 逻辑回归:虽然名字中有“回归”,但它实际上是一种分类算法,用于解决二分类问题。
4. K-最近邻(KNN):这是一个基于距离度量的算法,主要适用于数值型数据。
5. 支持向量机(SVM):这是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机。
6. 神经网络:它是一种模拟人脑神经元工作原理的算法,可以处理大量非线性数据。
7. 集成学习:通过组合多个基学习器的预测结果来进行分类,常见的方法有Bagging和Boosting。

机器学习常见算法分类汇总机器学习无疑是当前数据分析领域的一个热点内容。
很多人在平时的工作中都或多或少会用到机器学习的算法。
这里IT经理网为您总结一下常见的机器学习算法,以供您在工作和学习中参考。
机器学习的算法很多。
很多时候困惑人们都是,很多算法是一类算法,而有些算法又是从其他算法中延伸出来的。
这里,我们从两个方面来给大家介绍,第一个方面是学习的方式,第二个方面是算法的类似性。
学习方式根据数据类型的不同,对一个问题的建模有不同的方式。
在机器学习或者人工智能领域,人们首先会考虑算法的学习方式。
在机器学习领域,有几种主要的学习方式。
将算法按照学习方式分类是一个不错的想法,这样可以让人们在建模和算法选择的时候考虑能根据输入数据来选择最合适的算法来获得最好的结果。
监督式学习:在监督式学习下,输入数据被称为“训练数据”,每组训练数据有一个明确的标识或结果,如对防垃圾邮件系统中“垃圾邮件”“非垃圾邮件”,对手写数字识别中的“1“,”2“,”3“,”4“等。
在建立预测模型的时候,监督式学习建立一个学习过程,将预测结果与“训练数据”的实际结果进行比较,不断的调整预测模型,直到模型的预测结果达到一个预期的准确率。
监督式学习的常见应用场景如分类问题和回归问题。
常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)非监督式学习:在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
常见的应用场景包括关联规则的学习以及聚类等。
常见算法包括Apriori算法以及k-Means算法。
半监督式学习:在此学习方式下,输入数据部分被标识,部分没有被标识,这种学习模型可以用来进行预测,但是模型首先需要学习数据的内在结构以便合理的组织数据来进行预测。
应用场景包括分类和回归,算法包括一些对常用监督式学习算法的延伸,这些算法首先试图对未标识数据进行建模,在此基础上再对标识的数据进行预测。

轻松看懂机器学习十大常用算法通过本篇文章可以对ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题。
每个算法都看了好几个视频,挑出讲的最清晰明了有趣的,便于科普。
以后有时间再对单个算法做深入地解析。
今天的算法如下:1.决策树2.随机森林算法3.逻辑回归4.SVM5.朴素贝叶斯6.K最近邻算法7.K均值算法8.Adaboost 算法9.神经网络10.马尔可夫1. 决策树根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。
这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
2. 随机森林视频在源数据中随机选取数据,组成几个子集S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别由 S 随机生成 M 个子矩阵这 M 个子集得到 M 个决策树将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果3. 逻辑回归视频当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好那么怎么得到这样的模型呢?这个模型需要满足两个条件大于等于0,小于等于1大于等于0 的模型可以选择绝对值,平方值,这里用指数函数,一定大于0 小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了再做一下变形,就得到了 logistic regression 模型通过源数据计算可以得到相应的系数了最后得到 logistic 的图形4. SVMsupport vector machine要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1点到面的距离根据图中的公式计算所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题举个栗子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1)得到 weight vector 为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和截矩 w0 的值,进而得到超平面的表达式。
14种分类算法
1.决策树算法:将数据集划分为不同的类别,并且利用树形结构进行分类。
2. 朴素贝叶斯算法:基于贝叶斯定理,通过观察已知类别的数据来进行分类。
3. K-近邻算法:利用距离度量,找出与新数据最接近的K个数据,根据这K个数据的类别进行分类。
4. 支持向量机算法:通过寻找最优的超平面将不同的数据进行分类。
5. 线性分类器算法:通过建立线性模型来进行分类。
6. 神经网络算法:模拟生物神经网络,通过训练来识别模式并进行分类。
7. 随机森林算法:通过构建多个决策树来进行分类,最终将多个分类结果汇总得出最终分类结果。
8. AdaBoost算法:通过逐步调整数据权重,构建多个分类器,最终将多个分类结果汇总得出最终分类结果。
9. Logistic回归算法:通过建立逻辑回归模型来进行分类。
10. 梯度提升树算法:通过构建多个决策树,并通过梯度下降算法来更新模型参数,最终得到最优模型进行数据分类。
11. 最近中心点算法:通过计算距离来确定数据分类,将数据分为K个簇,并根据簇中心进行分类。
12. 高斯混合模型算法:将数据看做是由多个高斯分布组成的混
合模型,并通过最大期望算法来求解模型参数,最终得到数据分类结果。
13. 模糊聚类算法:将数据划分为不同的簇,并通过模糊理论来确定数据与簇的隶属度,最终得到数据分类结果。
14. 深度学习算法:通过建立多层神经网络,对大量数据进行训练,得到最优模型进行数据分类。
2.2:监督学习的基本分类模型(KNN、决策树、朴素贝叶斯)K近邻分类器(KNN)KNN:通过计算待分类数据点,与已有数据集中的所有数据点的距离。
取距离最⼩的前K个点,根据“少数服从多数“的原则,将这个数据点划分为出现次数最多的那个类别。
sklearn中的K近邻分类器在sklearn库中,可以使⽤sklearn.neighbors.KNeighborsClassifier创建⼀个K近邻分类器,主要参数有:• n_neighbors:⽤于指定分类器中K的⼤⼩(默认值为5,注意与kmeans的区别)• weights:设置选中的K个点对分类结果影响的权重(默认值为平均权重“uniform”,可以选择“distance”代表越近的点权重越⾼,或者传⼊⾃⼰编写的以距离为参数的权重计算函数)• algorithm:设置⽤于计算临近点的⽅法,因为当数据量很⼤的情况下计算当前点和所有点的距离再选出最近的k各点,这个计算量是很费时的,所以(选项中有ball_tree、kd_tree和brute,分别代表不同的寻找邻居的优化算法,默认值为auto,根据训练数据⾃动选择)K近邻分类器的使⽤创建⼀组数据 X 和它对应的标签 y:>>> X = [[0], [1], [2], [3]]>>> y = [0, 0, 1, 1]使⽤ import 语句导⼊ K 近邻分类器:>>> from sklearn.neighbors import KNeighborsClassifier参数 n_neighbors 设置为 3,即使⽤最近的3个邻居作为分类的依据,其他参数保持默认值,并将创建好的实例赋给变量 neigh。
>>> neigh = KNeighborsClassifier(n_neighbors=3)调⽤ fit() 函数,将训练数据 X 和标签 y 送⼊分类器进⾏学习。
机器学习算法解析逻辑回归、决策树和支持向量机在机器学习领域中,逻辑回归、决策树和支持向量机是常用的分类算法。
本文将对这三个算法进行解析,介绍其原理、应用场景以及优缺点,帮助读者更好地理解和应用这些算法。
一、逻辑回归(Logistic Regression)逻辑回归是一种广义线性模型,主要用于解决二分类问题,通过构建一个逻辑函数将输入特征映射到一个概率输出。
逻辑回归算法的目标是找到最优的超平面,将不同类别的样本点进行分割。
逻辑回归的优点在于计算简单、容易解释和快速训练。
它也适用于大规模数据集,并且能处理多类别问题。
然而,逻辑回归对数据的线性可分性有一定的要求,对非线性关系的拟合能力相对较弱。
逻辑回归广泛应用于医学、金融、市场营销等领域。
例如,在医学领域,逻辑回归可以预测患者是否患有某种疾病;在市场营销中,逻辑回归可用于预测用户是否购买某个产品。
二、决策树(Decision Tree)决策树是一种基于树结构的分类算法,通过对特征的逐步选择和分割,将数据集划分为不同的类别。
决策树算法的核心是选择最优的特征和分割点,以达到最小的不纯度(如基尼系数、信息增益)。
决策树的优点在于模型的可解释性强,能够处理离散型和连续型数据,不需要对数据进行归一化处理。
此外,决策树可以处理大规模数据集,并且对异常值和缺失值具有较好的鲁棒性。
决策树在金融、医疗、天气预测等领域有着广泛的应用。
例如,在天气预测中,决策树可以通过温度、湿度、风速等特征,预测是否会下雨。
三、支持向量机(Support Vector Machine,SVM)支持向量机是一种二分类模型,通过找到支持向量(训练样本中距离最近的样本点),构建最优的分离超平面,实现对不同类别的样本进行分类。
SVM基于间隔最大化的思想,具有较强的泛化能力。
支持向量机的优点在于对线性可分和非线性可分问题都能有良好的分类效果。
此外,支持向量机通过使用核函数,可以将低维特征映射到高维空间,增强了模型的表达能力。
机器学习中常用的监督学习算法介绍机器学习是人工智能领域的一个重要分支,它致力于研究如何使计算机具有学习能力,从而从数据中获取知识和经验,并用于解决各种问题。
监督学习是机器学习中最常见和基础的学习方式之一,它通过将输入数据与对应的输出标签进行配对,从而训练模型以预测新数据的标签。
在本文中,我们将介绍几种常用的监督学习算法及其特点。
1. 决策树(Decision Tree)决策树是一种基于树状结构来进行决策的监督学习算法。
在决策树中,每个节点表示一个特征,每个分支代表该特征的一个可能取值,而每个叶子节点则代表一个类别或输出。
决策树的优点是易于理解和解释,同时可以处理具有离散和连续特征的数据。
然而,它容易产生过拟合问题,需要进行剪枝等处理。
2. 朴素贝叶斯(Naive Bayes)朴素贝叶斯是一种基于贝叶斯定理和特征条件独立假设的分类算法。
它假设特征之间相互独立,并根据已知数据计算后验概率,从而进行分类。
朴素贝叶斯算法具有较好的可扩展性和高效性,并且对于处理大规模数据集非常有效。
然而,它的假设可能与实际数据不符,导致分类结果不准确。
3. 最近邻算法(K-Nearest Neighbors,KNN)最近邻算法是一种基于实例的学习算法,它通过计算新数据点与训练样本集中各个数据点的距离,然后将新数据点分类为距离最近的K个数据点中的多数类别。
最近邻算法简单易懂,并且可以用于处理多类别问题。
然而,它的计算复杂度高,对于大规模数据集的处理效率较低。
4. 逻辑回归(Logistic Regression)逻辑回归是一种广义线性模型,主要用于解决二分类问题。
它通过将输入数据进行映射,并使用逻辑函数(常用的是sigmoid函数)将输入与输出进行转换。
逻辑回归模型可以用于预测某个样本属于某个类别的概率,并进行分类。
逻辑回归具有较好的可解释性和预测性能,同时支持处理连续和离散特征。
5. 支持向量机(Support Vector Machines,SVM)支持向量机是一种常用的二分类算法,其目标是找到一个可以将不同类别的数据最大程度地分离的超平面。
带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、
决策树
【导读】众所周知,Scikit-learn(以前称为scikits.learn)是一个用于Python 编程语言的免费软件机器学习库。
它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度增强,k-means和DBSCAN,旨在与Python数值和科学库NumPy和SciPy 互操作。
本文将带你入门常见的机器学习分类算法——逻辑回归、朴素贝叶斯、KNN、SVM、决策树。
逻辑回归(Logistic regression)
逻辑回归,尽管他的名字包含"回归",却是一个分类而不是回归的线性模型。
逻辑回归在文献中也称为logit回归,最大熵分类或者对数线性分类器。
下面将先介绍一下sklearn中逻辑回归的接口:
class sklearn.linear_model.LogisticRegression(penalty=l2, dual=False, tol=0.0001, C=1.0, fit_intercept=True, intercept_scaling=1, class_weight=None, random_state=None, solver=warn, max_iter=100, multi_class=warn, verbose=0, warm_start=False, n_jobs=None)
常用参数讲解:
penalty:惩罚项。
一般都是"l1"或者"l2"。
dual:这个参数仅适用于使用liblinear求解器的"l2"惩罚项。
一般当样本数大于特征数时,这个参数置为False。
C:正则化强度(较小的值表示更强的正则化),必须是正的浮点数。
solver:参数求解器。
一般的有{‘newton-cg’, ‘lbfgs’, ‘liblinear’, ‘sag’, ‘saga’}。
multi_class:多分类问题转化,如果使用"ovr",则是将多分类问题转换成多个二分类为题看待;如果使用"multinomial",损失函数则会是整个概率分布的多项式拟合损失。
不常用的参数这里就不再介绍,想要了解细节介绍,可以sklearn的官网查看。
案例:
这里我使用sklearn内置的数据集——iris数据集,这是一个三分类的问题,下面我就使用。