朴素贝叶斯分类算法代码实现
- 格式:wps
- 大小:66.50 KB
- 文档页数:10

朴素贝叶斯分类器详解及中⽂⽂本舆情分析(附代码实践)本⽂主要讲述朴素贝叶斯分类算法并实现中⽂数据集的舆情分析案例,希望这篇⽂章对⼤家有所帮助,提供些思路。
内容包括:1.朴素贝叶斯数学原理知识2.naive_bayes⽤法及简单案例3.中⽂⽂本数据集预处理4.朴素贝叶斯中⽂⽂本舆情分析本篇⽂章为基础性⽂章,希望对你有所帮助,如果⽂章中存在错误或不⾜之处,还请海涵。
同时,推荐⼤家阅读我以前的⽂章了解基础知识。
▌⼀. 朴素贝叶斯数学原理知识朴素贝叶斯(Naive Bayesian)是基于贝叶斯定理和特征条件独⽴假设的分类⽅法,它通过特征计算分类的概率,选取概率⼤的情况,是基于概率论的⼀种机器学习分类(监督学习)⽅法,被⼴泛应⽤于情感分类领域的分类器。
下⾯简单回顾下概率论知识:1.什么是基于概率论的⽅法?通过概率来衡量事件发⽣的可能性。
概率论和统计学是两个相反的概念,统计学是抽取部分样本统计来估算总体情况,⽽概率论是通过总体情况来估计单个事件或部分事情的发⽣情况。
概率论需要已知数据去预测未知的事件。
例如,我们看到天⽓乌云密布,电闪雷鸣并阵阵狂风,在这样的天⽓特征(F)下,我们推断下⾬的概率⽐不下⾬的概率⼤,也就是p(下⾬)>p(不下⾬),所以认为待会⼉会下⾬,这个从经验上看对概率进⾏判断。
⽽⽓象局通过多年长期积累的数据,经过计算,今天下⾬的概率p(下⾬)=85%、p(不下⾬)=15%,同样的 p(下⾬)>p(不下⾬),因此今天的天⽓预报肯定预报下⾬。
这是通过⼀定的⽅法计算概率从⽽对下⾬事件进⾏判断。
2.条件概率若Ω是全集,A、B是其中的事件(⼦集),P表⽰事件发⽣的概率,则条件概率表⽰某个事件发⽣时另⼀个事件发⽣的概率。
假设事件B发⽣后事件A发⽣的概率为:设P(A)>0,则有 P(AB) = P(B|A)P(A) = P(A|B)P(B)。
设A、B、C为事件,且P(AB)>0,则有 P(ABC) = P(A)P(B|A)P(C|AB)。

朴素贝叶斯算法及其代码实现朴素贝叶斯朴素贝叶斯是经典的机器学习算法之⼀,也是为数不多的基于概率论的分类算法。
在机器学习分类算法中,朴素贝叶斯和其他绝多⼤的分类算法都不同,⽐如决策树,KNN,逻辑回归,⽀持向量机等,他们都是判别⽅法,也就是直接学习出特征输出Y和特征X之间的关系,要么是决策函数,要么是条件分布。
但是朴素贝叶斯却是⽣成⽅法,这种算法简单,也易于实现。
1.基本概念朴素贝叶斯:贝叶斯分类是⼀类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
⽽朴素贝叶斯分类时贝叶斯分类中最简单,也是最常见的⼀种分类⽅法。
贝叶斯公式:先验概率P(X):先验概率是指根据以往经验和分析得到的概率。
后验概率P(Y|X):事情已经发⽣,要求这件事情发⽣的原因是由某个因素引起的可能性的⼤⼩,后验分布P(Y|X)表⽰事件X已经发⽣的前提下,事件Y发⽣的概率,叫做事件X发⽣下事件Y的条件概率。
后验概率P(X|Y):在已知Y发⽣后X的条件概率,也由于知道Y的取值⽽被称为X的后验概率。
朴素:朴素贝叶斯算法是假设各个特征之间相互独⽴,也是朴素这词的意思,那么贝叶斯公式中的P(X|Y)可写成:朴素贝叶斯公式:2,贝叶斯算法简介 贝叶斯⽅法源域它⽣前为解决⼀个“逆概”问题写的⼀篇⽂章。
其要解决的问题: 正向概率:假设袋⼦⾥⾯有N个⽩球,M个⿊球,你伸⼿进去摸⼀把,摸出⿊球的概率是多⼤ 逆向概率:如果我们事先不知道袋⼦⾥⾯⿊⽩球的⽐例,⽽是闭着眼睛摸出⼀个(或者好⼏个)球,观察这些取出来的球的颜⾊之后,那么我们可以就此对袋⼦⾥⾯的⿊⽩球的⽐例做出什么样的推测。
那么什么是贝叶斯呢?1,现实世界本⾝就是不确定的,⼈类的观察能⼒是有局限性的2,我们⽇常观察到的只是事物表明上的结果,因此我们需要提供⼀个猜测 NaiveBayes算法,⼜称朴素贝叶斯算法。
朴素:特征条件独⽴;贝叶斯:基于贝叶斯定理。
属于监督学习的⽣成模型,实现监督,没有迭代,并有坚实的数学理论(即贝叶斯定理)作为⽀撑。

机器学习:贝叶斯分类器(⼆)——⾼斯朴素贝叶斯分类器代码实现⼀⾼斯朴素贝叶斯分类器代码实现⽹上搜索不调⽤sklearn实现的朴素贝叶斯分类器基本很少,即使有也是结合⽂本分类的多项式或伯努利类型,因此⾃⼰写了⼀遍能直接封装的⾼斯类型NB分类器,当然与真正的源码相⽐少了很多属性和⽅法,有兴趣的可以⾃⼰添加。
代码如下(有详细注释):class NaiveBayes():'''⾼斯朴素贝叶斯分类器'''def __init__(self):self._X_train = Noneself._y_train = Noneself._classes = Noneself._priorlist = Noneself._meanmat = Noneself._varmat = Nonedef fit(self, X_train, y_train):self._X_train = X_trainself._y_train = y_trainself._classes = np.unique(self._y_train) # 得到各个类别priorlist = []meanmat0 = np.array([[0, 0, 0, 0]])varmat0 = np.array([[0, 0, 0, 0]])for i, c in enumerate(self._classes):# 计算每个种类的平均值,⽅差,先验概率X_Index_c = self._X_train[np.where(self._y_train == c)] # 属于某个类别的样本组成的“矩阵”priorlist.append(X_Index_c.shape[0] / self._X_train.shape[0]) # 计算类别的先验概率X_index_c_mean = np.mean(X_Index_c, axis=0, keepdims=True) # 计算该类别下每个特征的均值,结果保持⼆维状态[[3 4 6 2 1]]X_index_c_var = np.var(X_Index_c, axis=0, keepdims=True) # ⽅差meanmat0 = np.append(meanmat0, X_index_c_mean, axis=0) # 各个类别下的特征均值矩阵罗成新的矩阵,每⾏代表⼀个类别。

朴素贝叶斯原理、实例与Python实现初步理解⼀下:对于⼀组输⼊,根据这个输⼊,输出有多种可能性,需要计算每⼀种输出的可能性,以可能性最⼤的那个输出作为这个输⼊对应的输出。
那么,如何来解决这个问题呢?贝叶斯给出了另⼀个思路。
根据历史记录来进⾏判断。
思路是这样的:1、根据贝叶斯公式:P(输出|输⼊)=P(输⼊|输出)*P(输出)/P(输⼊)2、P(输⼊)=历史数据中,某个输⼊占所有样本的⽐例;3、P(输出)=历史数据中,某个输出占所有样本的⽐例;4、P(输⼊|输出)=历史数据中,某个输⼊,在某个输出的数量占所有样本的⽐例,例如:30岁,男性,中午吃⾯条,其中【30岁,男性就是输⼊】,【中午吃⾯条】就是输出。
⼀、条件概率的定义与贝叶斯公式⼆、朴素贝叶斯分类算法朴素贝叶斯是⼀种有监督的分类算法,可以进⾏⼆分类,或者多分类。
⼀个数据集实例如下图所⽰:现在有⼀个新的样本, X = (年龄:<=30, 收⼊:中,是否学⽣:是,信誉:中),⽬标是利⽤朴素贝叶斯分类来进⾏分类。
假设类别为C(c1=是或 c2=否),那么我们的⽬标是求出P(c1|X)和P(c2|X),⽐较谁更⼤,那么就将X分为某个类。
下⾯,公式化朴素贝叶斯的分类过程。
三、实例下⾯,将下⾯这个数据集作为训练集,对新的样本X = (年龄:<=30, 收⼊:中,是否学⽣:是,信誉:中) 作为测试样本,进⾏分类。
我们可以将这个实例中的描述属性和类别属性,与公式对应起来,然后计算。
参考python实现代码#coding:utf-8# 极⼤似然估计朴素贝叶斯算法import pandas as pdimport numpy as npclass NaiveBayes(object):def getTrainSet(self):dataSet = pd.read_csv('F://aaa.csv')dataSetNP = np.array(dataSet) #将数据由dataframe类型转换为数组类型trainData = dataSetNP[:,0:dataSetNP.shape[1]-1] #训练数据x1,x2labels = dataSetNP[:,dataSetNP.shape[1]-1] #训练数据所对应的所属类型Yreturn trainData, labelsdef classify(self, trainData, labels, features):#求labels中每个label的先验概率labels = list(labels) #转换为list类型labelset = set(labels)P_y = {} #存⼊label的概率for label in labelset:P_y[label] = labels.count(label)/float(len(labels)) # p = count(y) / count(Y)print(label,P_y[label])#求label与feature同时发⽣的概率P_xy = {}for y in P_y.keys():y_index = [i for i, label in enumerate(labels) if label == y] # labels中出现y值的所有数值的下标索引for j in range(len(features)): # features[0] 在trainData[:,0]中出现的值的所有下标索引x_index = [i for i, feature in enumerate(trainData[:,j]) if feature == features[j]]xy_count = len(set(x_index) & set(y_index)) # set(x_index)&set(y_index)列出两个表相同的元素pkey = str(features[j]) + '*' + str(y)P_xy[pkey] = xy_count / float(len(labels))print(pkey,P_xy[pkey])#求条件概率P = {}for y in P_y.keys():for x in features:pkey = str(x) + '|' + str(y)P[pkey] = P_xy[str(x)+'*'+str(y)] / float(P_y[y]) #P[X1/Y] = P[X1Y]/P[Y]print(pkey,P[pkey])#求[2,'S']所属类别F = {} #[2,'S']属于各个类别的概率for y in P_y:F[y] = P_y[y]for x in features:F[y] = F[y]*P[str(x)+'|'+str(y)] #P[y/X] = P[X/y]*P[y]/P[X],分母相等,⽐较分⼦即可,所以有F=P[X/y]*P[y]=P[x1/Y]*P[x2/Y]*P[y] print(str(x),str(y),F[y])features_label = max(F, key=F.get) #概率最⼤值对应的类别return features_labelif__name__ == '__main__':nb = NaiveBayes()# 训练数据trainData, labels = nb.getTrainSet()# x1,x2features = [8]# 该特征应属于哪⼀类result = nb.classify(trainData, labels, features)print(features,'属于',result)#coding:utf-8#朴素贝叶斯算法贝叶斯估计,λ=1 K=2, S=3;λ=1 拉普拉斯平滑import pandas as pdimport numpy as npclass NavieBayesB(object):def__init__(self):self.A = 1 # 即λ=1self.K = 2self.S = 3def getTrainSet(self):trainSet = pd.read_csv('F://aaa.csv')trainSetNP = np.array(trainSet) #由dataframe类型转换为数组类型trainData = trainSetNP[:,0:trainSetNP.shape[1]-1] #训练数据x1,x2labels = trainSetNP[:,trainSetNP.shape[1]-1] #训练数据所对应的所属类型Yreturn trainData, labelsdef classify(self, trainData, labels, features):labels = list(labels) #转换为list类型#求先验概率P_y = {}for label in labels:P_y[label] = (labels.count(label) + self.A) / float(len(labels) + self.K*self.A)#求条件概率P = {}for y in P_y.keys():y_index = [i for i, label in enumerate(labels) if label == y] # y在labels中的所有下标y_count = labels.count(y) # y在labels中出现的次数for j in range(len(features)):pkey = str(features[j]) + '|' + str(y)x_index = [i for i, x in enumerate(trainData[:,j]) if x == features[j]] # x在trainData[:,j]中的所有下标 xy_count = len(set(x_index) & set(y_index)) #x y同时出现的次数P[pkey] = (xy_count + self.A) / float(y_count + self.S*self.A) #条件概率#features所属类F = {}for y in P_y.keys():F[y] = P_y[y]for x in features:F[y] = F[y] * P[str(x)+'|'+str(y)]features_y = max(F, key=F.get) #概率最⼤值对应的类别return features_yif__name__ == '__main__':nb = NavieBayesB()# 训练数据trainData, labels = nb.getTrainSet()# x1,x2features = [10]# 该特征应属于哪⼀类result = nb.classify(trainData, labels, features)print(features,'属于',result)参考链接:https:///ten_sory/article/details/81237169。
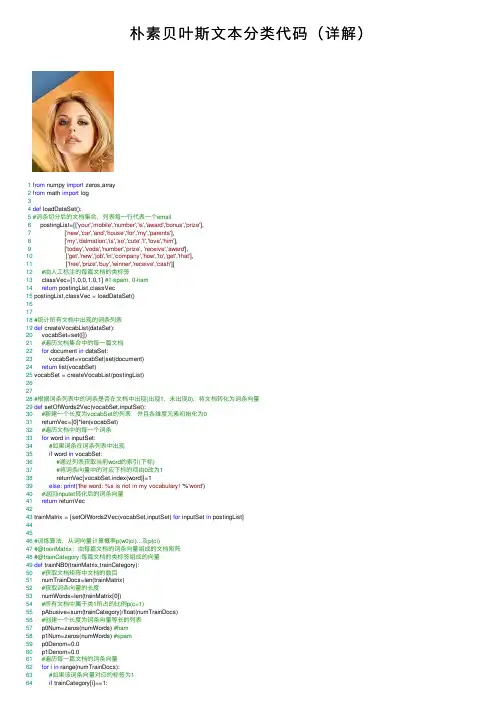
朴素贝叶斯⽂本分类代码(详解)1from numpy import zeros,array2from math import log34def loadDataSet():5#词条切分后的⽂档集合,列表每⼀⾏代表⼀个email6 postingList=[['your','mobile','number','is','award','bonus','prize'],7 ['new','car','and','house','for','my','parents'],8 ['my','dalmation','is','so','cute','I','love','him'],9 ['today','voda','number','prize', 'receive','award'],10 ['get','new','job','in','company','how','to','get','that'],11 ['free','prize','buy','winner','receive','cash']]12#由⼈⼯标注的每篇⽂档的类标签13 classVec=[1,0,0,1,0,1] #1-spam, 0-ham14return postingList,classVec15 postingList,classVec = loadDataSet()161718#统计所有⽂档中出现的词条列表19def createVocabList(dataSet):20 vocabSet=set([])21#遍历⽂档集合中的每⼀篇⽂档22for document in dataSet:23 vocabSet=vocabSet|set(document)24return list(vocabSet)25 vocabSet = createVocabList(postingList)262728#根据词条列表中的词条是否在⽂档中出现(出现1,未出现0),将⽂档转化为词条向量29def setOfWords2Vec(vocabSet,inputSet):30#新建⼀个长度为vocabSet的列表,并且各维度元素初始化为031 returnVec=[0]*len(vocabSet)32#遍历⽂档中的每⼀个词条33for word in inputSet:34#如果词条在词条列表中出现35if word in vocabSet:36#通过列表获取当前word的索引(下标)37#将词条向量中的对应下标的项由0改为138 returnVec[vocabSet.index(word)]=139else: print('the word: %s is not in my vocabulary! '%'word')40#返回inputet转化后的词条向量41return returnVec4243 trainMatrix = [setOfWords2Vec(vocabSet,inputSet) for inputSet in postingList]444546#训练算法,从词向量计算概率p(w0|ci)...及p(ci)47#@trainMatrix:由每篇⽂档的词条向量组成的⽂档矩阵48#@trainCategory:每篇⽂档的类标签组成的向量49def trainNB0(trainMatrix,trainCategory):50#获取⽂档矩阵中⽂档的数⽬51 numTrainDocs=len(trainMatrix)52#获取词条向量的长度53 numWords=len(trainMatrix[0])54#所有⽂档中属于类1所占的⽐例p(c=1)55 pAbusive=sum(trainCategory)/float(numTrainDocs)56#创建⼀个长度为词条向量等长的列表57 p0Num=zeros(numWords) #ham58 p1Num=zeros(numWords) #spam59 p0Denom=0.060 p1Denom=0.061#遍历每⼀篇⽂档的词条向量62for i in range(numTrainDocs):63#如果该词条向量对应的标签为164if trainCategory[i]==1:65#统计所有类别为1的词条向量中各个词条出现的次数66 p1Num+=trainMatrix[i]67#统计类别为1的词条向量中出现的所有词条的总数68#即统计类1所有⽂档中出现单词的数⽬69 p1Denom+=sum(trainMatrix[i])70else:71#统计所有类别为0的词条向量中各个词条出现的次数72 p0Num+=trainMatrix[i]73#统计类别为0的词条向量中出现的所有词条的总数74#即统计类0所有⽂档中出现单词的数⽬75 p0Denom+=sum(trainMatrix[i])76print(p1Num, p1Denom, p0Num,p0Denom )77#利⽤NumPy数组计算p(wi|c1)78 p1Vect=p1Num/p1Denom #为避免下溢出问题,需要改为log()79#利⽤NumPy数组计算p(wi|c0)80 p0Vect=p0Num/p0Denom #为避免下溢出问题,需要改为log()81return p0Vect,p1Vect,pAbusive8283 p0Vect,p1Vect,pAbusive= trainNB0(trainMatrix,classVec)848586#朴素贝叶斯分类函数87#@vec2Classify:待测试分类的词条向量88#@p0Vec:类别0所有⽂档中各个词条出现的频数p(wi|c0)89#@p0Vec:类别1所有⽂档中各个词条出现的频数p(wi|c1)90#@pClass1:类别为1的⽂档占⽂档总数⽐例91def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1):92#根据朴素贝叶斯分类函数分别计算待分类⽂档属于类1和类0的概率93 p1=sum(vec2Classify*p1Vec)+log(pClass1)94 p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1)95if p1>p0:96return'spam'97else:98return'not spam'99100101102 testEntry=['love','my','job']103 thisDoc=array(setOfWords2Vec(vocabSet,testEntry))104print(testEntry,'classified as:',classifyNB(thisDoc,p0Vect,p1Vect,pAbusive))。

高校计算机专业数据挖掘算法实现代码详解数据挖掘算法在现代计算机科学中扮演着至关重要的角色。
随着大数据时代的到来,高校计算机专业需要培养具备数据挖掘算法实现能力的人才。
本文将详细介绍几种常用的数据挖掘算法,并附上相应的实现代码。
一、决策树算法决策树算法是一种常用的分类算法,通过构建一颗树状结构来进行分类。
具体的实现代码如下:```def create_decision_tree(dataset, labels):classList = [example[-1] for example in dataset]if classList.count(classList[0]) == len(classList):return classList[0]if len(dataset[0]) == 1:return majority_count(classList)best_feature = choose_best_feature_to_split(dataset)best_feature_label = labels[best_feature]my_tree = {best_feature_label: {}}del(labels[best_feature])feature_values = [example[best_feature] for example in dataset]unique_values = set(feature_values)for value in unique_values:sub_labels = labels[:]my_tree[best_feature_label][value] =create_decision_tree(split_dataset(dataset, best_feature, value), sub_labels) return my_tree```二、朴素贝叶斯算法朴素贝叶斯算法是一种常用的概率推断算法,适用于分类和文本分类等任务。

数据挖掘朴素贝叶斯算法r的实现朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,其核心思想是通过已知的训练数据集学习一个分类器,对新数据进行分类。
下面是一个简单的R语言实现朴素贝叶斯算法的示例:```r导入必要的库library(e1071)生成训练数据(123)train_data <- (feature1 = rnorm(100),feature2 = rnorm(100),feature3 = rnorm(100),class = sample(c("A", "B"), 100, replace = TRUE))将特征向量和类别合并成一个矩阵train_matrix <- (train_data[1:3])train_factor <- (train_data$class)训练朴素贝叶斯分类器nb_model <- naiveBayes(train_matrix, train_factor, laplace = 1)生成测试数据test_data <- (feature1 = rnorm(10),feature2 = rnorm(10),feature3 = rnorm(10))对测试数据进行预测predicted_classes <- predict(nb_model, newdata = (test_data))print(predicted_classes)```在上面的示例中,我们首先导入了e1071包,它包含了朴素贝叶斯算法的实现。
然后,我们生成了一个包含三个特征和两个类别的训练数据集。
接着,我们将特征向量和类别合并成一个矩阵,并使用naiveBayes函数训练了一个朴素贝叶斯分类器。
最后,我们生成了一个包含三个特征的测试数据集,并使用predict函数对新数据进行分类。

Python与朴素贝叶斯分类的应用导言Python是一种高级的、内容丰富的编程语言,最早由荷兰人Guido van Rossum在1989年创造。
Python与许多其他编程语言一样,可以用于各种任务,例如Web开发、数据分析、科学计算等等。
Python还广泛应用于人工智能领域,朴素贝叶斯分类就是Python中常用的一种算法。
朴素贝叶斯分类是一个简单而高效的机器学习模型,用于处理分类问题。
该算法的核心思想是基于特征和类别的条件概率对未知数据进行分类。
本文将探讨Python与朴素贝叶斯分类的应用,介绍朴素贝叶斯算法的基本概念,以及如何使用Python实现朴素贝叶斯算法进行分类。
朴素贝叶斯算法的基本概念朴素贝叶斯算法是一种基于贝叶斯定理的分类算法,该算法假设数据集中所有特征都是独立的,从而简化了计算。
算法的核心思想是,根据先验概率和条件概率,计算出后验概率,以此来判断数据属于哪个类别。
在朴素贝叶斯算法中,我们需要计算先验概率、条件概率和后验概率。
其中,先验概率是在不知道数据属于哪个类别的情况下,每种类别的概率。
条件概率是在已知某种类别的情况下,数据拥有某个特征的概率。
后验概率是在知道特征和类别的情况下,数据属于某个类别的概率。
贝叶斯定理将这些概率联系在一起:P(Y|X) = P(X|Y) * P(Y) / P(X)其中,P(Y|X)是后验概率,即在已知特征和类别的情况下,数据属于某个类别的概率;P(X|Y)是条件概率,即在已知某种类别的情况下,数据拥有某个特征的概率;P(Y)是先验概率,即每种类别的概率;P(X)是样本空间中数据拥有某个特征的概率。
在分类问题中,我们需要计算出所有类别的后验概率,然后选择最大值作为分类结果。
因为贝叶斯定理假设每个特征是独立的,所以朴素贝叶斯算法的名称中含有“朴素”这个词。
如何使用Python实现朴素贝叶斯算法进行分类Python中有多个库可用于机器学习,其中就包括用于分类的朴素贝叶斯算法。

用python实现鸢尾花数据集的朴素贝叶斯算法Python是一种功能强大的编程语言,广泛应用于数据科学和机器学习领域。
朴素贝叶斯算法是一种常见的建模方法,可以用于分类问题。
在这篇文章中,我们将使用Python实现朴素贝叶斯算法来处理鸢尾花数据集。
首先,我们需要导入一些必要的库。
在Python中,有很多强大的数据处理和机器学习库可供选择,例如NumPy、Pandas和Scikit-Learn。
这些库可以帮助我们加载和处理数据,以及构建机器学习模型。
我们首先导入NumPy和Pandas库,用于数据处理和分析。
pythonimport numpy as npimport pandas as pd接下来,我们将使用Pandas库加载鸢尾花数据集。
鸢尾花数据集是一个常用的机器学习数据集,其中包含150个样本,每个样本有四个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
鸢尾花数据集由三个类别组成:Setosa、Versicolor和Virginica。
我们可以使用Pandas库的read_csv函数从CSV文件中加载数据集。
pythondata = pd.read_csv('iris.csv')数据集加载完成后,我们可以使用head()函数查看前几行数据,确保数据正确加载。
pythonprint(data.head())现在,我们已经成功加载了鸢尾花数据集。
接下来,我们将进行数据预处理,以准备数据用于训练朴素贝叶斯分类器。
首先,我们需要将数据集拆分为特征和目标变量。
特征是我们用来预测目标变量的变量,而目标变量是我们希望预测的变量。
pythonX = data.drop('species', axis=1)y = data['species']在实施朴素贝叶斯算法之前,我们需要将特征进行标准化处理。
标准化可以确保数据具有相似的范围和分布,有助于提高算法的性能。
我们可以使用Scikit-Learn库中的StandardScaler进行标准化处理。


朴素贝叶斯分类算法python代码朴素贝叶斯分类算法是一种基于概率的统计分类算法,该算法的主要实现思想是对预测对象进行特征提取、概率计算和分类判断,以实现对对象的分类识别。
本文将重点介绍朴素贝叶斯分类算法在Python中的应用与实现,以帮助读者更好地理解该算法。
首先,我们需要了解Bayes理论,在Bayes理论中,条件概率是指在已知某些条件的情况下,某一事件发生的概率。
朴素贝叶斯分类算法是基于该理论的,以此为基础,实现了对预测对象的分类。
具体来说,朴素贝叶斯分类算法的过程如下:1. 建立分类模型:在统计学习中,首先需要建立一种分类模型,这种模型在朴素贝叶斯分类算法中是基于特征集的贝叶斯定理来定义的。
2. 提取特征:在对预测对象进行分类前,需要先对对象进行特征提取,将其转化为数值型特征,以便后续计算分析。
常用的特征提取方法包括文本处理技术、特征选择等。
3. 计算概率:得到特征集后,基于该特征集进行预测。
可以利用训练集中的概率分布计算当前对象的概率分布。
其中,朴素贝叶斯分类算法中的“朴素”指假设特征之间是独立的,即每个特征对目标类别的影响是相互独立的,这使得计算概率分布更为简单和快速。
4. 进行分类:根据最大化概率的准则,将对象分类到概率最高的类别中。
例如,若某对象概率最高的类别为“正常”,则将该对象分类到“正常”类别中。
在Python中,可以借助于sklearn包来实现朴素贝叶斯分类算法。
下面进行一些示例代码来对其进行解释:''' import numpy as np from sklearn.naive_bayes import GaussianNB from sklearn.model_selection import train_test_split from sklearn import datasets# 读取iris数据集 iris = datasets.load_iris() X = iris.data y = iris.target# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3) # 建立高斯朴素贝叶斯分类器 gnb = GaussianNB() gnb.fit(X_train, y_train) # 训练模型# 对测试集进行预测 y_pred = gnb.predict(X_test)# 输出结果 print('Accuracy:', np.sum(y_pred == y_test) / len(y_test)) '''这段代码演示了如何使用sklearn包中的高斯朴素贝叶斯分类器进行分类。
clcclearclose alldata=importdata('data.txt');wholeData=data.data;%交叉验证选取训练集和测试集cv=cvpartition(size(wholeData,1),'holdout',0.04);%0.04表明测试数据集占总数据集的比例cvpartition(n,'holdout',p)创建一个随机分区,用于在n个观测值上进行保持验证。
该分区将观察分为训练集和测试(或保持)集。
参数p必须是标量,当0<p<1时,cvpartition为测试集随机选择大约p*n个观测值。
当p是整数时,cvpartition为测试集随机选择p个观测值。
p的默认值是0.1trainData=wholeData(training(cv),:);testData=wholeData(test(cv),:);label=data.textdata;attributeNumber=size(trainData,2);size(A,2):获取矩阵A的列数。
attributeValueNumber=5;%将分类标签转化为数据(因为在分类数据集中有3个类别,分别是R、B、L所以将类别转换为数字)sampleNumber=size(label,1);labelData=zeros(sampleNumber,1);for i=1:sampleNumber(测试集的行数)if label{i,1}=='R'labelData(i,1)=1;elseif label{i,1}=='B'labelData(i,1)=2;elselabelData(i,1)=3;endendtrainLabel=labelData(training(cv),:);trainSampleNumber=size(trainLabel,1);testLabel=labelData(test(cv),:);%计算每个分类的样本的概率labelProbability=tabulate(trainLabel);tabulate函数的功能是创建向量X信息数据频率表。
第五篇:朴素贝叶斯分类算法原理分析与代码实现前⾔本⽂介绍机器学习分类算法中的朴素贝叶斯分类算法并给出伪代码,Python代码实现。
词向量朴素贝叶斯分类算法常常⽤于⽂档的分类,⽽且实践证明效果挺不错的。
在说明原理之前,先介绍⼀个叫词向量的概念。
--- 它⼀般是⼀个布尔类型的集合,该集合中每个元素都表⽰其对应的单词是否在⽂档中出现。
⽐如说,词汇表只有三个单词:'apple', 'orange', 'melo',某⽂档中,apple和melo出现过,那么其对应的词向量就是 {1, 0, 1}。
这种模型通常称为词集模型,如果词向量元素是整数类型,每个元素表⽰相应单词在⽂档中出现的次数(0表⽰不出现),那这种模型就叫做词袋模型。
如下部分代码可⽤于由⽂档构建词向量以及测试结果:1#====================================2# 输⼊:3# 空4# 输出:5# postingList: ⽂档列表6# classVec: 分类标签列表7#====================================8def loadDataSet():9'创建测试数据'1011# 这组数据是从斑点狗论坛获取的12 postingList=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],13 ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],14 ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],15 ['stop', 'posting', 'stupid', 'worthless', 'garbage'],16 ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],17 ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]1819# 1 表⽰带敏感词汇20 classVec = [0,1,0,1,0,1]2122return postingList,classVec2324#====================================25# 输⼊:26# dataSet: ⽂档列表27# 输出:28# list(vocabSet): 词汇表29#====================================30def createVocabList(dataSet):31'创建词汇表'3233 vocabSet = set([])34for document in dataSet: # 遍历⽂档列表35# ⾸先将当前⽂档的单词唯⼀化,然后以交集的⽅式加⼊到保存词汇的集合中。
贝叶斯分类器代码贝叶斯分类器是一种基于贝叶斯定理的机器学习算法,它可以用于分类、预测等任务。
在实际应用中,我们通常需要编写代码来实现贝叶斯分类器。
以下是一个简单的贝叶斯分类器代码示例:```import numpy as npclass NaiveBayesClassifier:def __init__(self):self.classes = Noneself.class_priors = Noneself.mean = Noneself.variance = Nonedef fit(self, X, y):self.classes = np.unique(y)n_classes = len(self.classes)# 计算每个类别的先验概率class_counts = np.zeros(n_classes)for i in range(n_classes):class_counts[i] = np.sum(y == self.classes[i])self.class_priors = class_counts / len(y)# 计算每个类别下每个特征的均值和方差n_features = X.shape[1]self.mean = np.zeros((n_classes, n_features)) self.variance = np.zeros((n_classes, n_features))for i in range(n_classes):X_i = X[y == self.classes[i], :]self.mean[i, :] = np.mean(X_i, axis=0)self.variance[i, :] = np.var(X_i, axis=0)def predict(self, X):n_samples, n_features = X.shapey_pred = np.zeros(n_samples)for i in range(n_samples):posteriors = []# 计算每个类别的后验概率for j in range(len(self.classes)):prior = np.log(self.class_priors[j])likelihood = np.sum(np.log(self._gaussian_pdf(X[i, :], self.mean[j, :], self.variance[j, :])))posterior = prior + likelihoodposteriors.append(posterior)# 选择后验概率最大的类别作为预测结果y_pred[i] = self.classes[np.argmax(posteriors)]return y_preddef _gaussian_pdf(self, x, mean, variance):exponent = -0.5 * ((x - mean) ** 2 / variance)coeff = 1.0 / np.sqrt(2.0 * np.pi * variance)return coeff * np.exp(exponent)```该代码实现了一个简单的高斯朴素贝叶斯分类器。
朴素贝叶斯算法简介朴素贝叶斯算法(Naive Bayes)是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。
朴素贝叶斯算法在文本分类、垃圾邮件过滤、情感分析等领域广泛应用。
贝叶斯定理贝叶斯定理是概率论中的一个基本公式,用于计算在已知一些先验条件下,某个事件的后验概率。
对于两个事件A和B,贝叶斯定理可以表示为:P(A|B) = (P(B|A) * P(A)) / P(B)其中, - P(A|B) 是事件B发生时事件A发生的概率(后验概率); - P(B|A) 是事件A发生时事件B发生的概率; - P(A) 是事件A发生的概率(先验概率); - P(B) 是事件B发生的概率。
朴素贝叶斯算法原理朴素贝叶斯算法基于条件独立性假设,在给定类别C的情况下,假设所有特征之间相互独立。
根据这个假设,可以使用以下公式计算后验概率:P(C|X) = (P(X|C) * P(C)) / P(X)其中, - P(C|X) 是给定特征向量X的情况下,类别C的后验概率; - P(X|C) 是在类别C的情况下,特征向量X的条件概率; - P(C) 是类别C的先验概率; - P(X) 是特征向量X的概率。
由于朴素贝叶斯算法假设所有特征之间相互独立,因此可以将条件概率分解为各个特征的边缘概率之积:P(X|C) = P(x1|C) * P(x2|C) * … * P(xn|C)其中,x1, x2, …, xn 是特征向量X中的各个特征。
朴素贝叶斯算法步骤朴素贝叶斯算法包括以下步骤:1.收集数据集:收集带有已知类别标签的训练样本。
2.准备数据:将数据转换为适合计算机处理的格式。
3.分析数据:使用可视化工具对数据进行初步分析。
4.训练模型:根据训练样本计算各个类别的先验概率和条件概率。
5.测试模型:使用测试样本评估模型的准确性。
6.使用模型:使用训练好的模型进行分类预测。
朴素贝叶斯算法应用示例:垃圾邮件过滤下面以垃圾邮件过滤为例,演示朴素贝叶斯算法的应用。
朴素贝叶斯分类器是一种常用的机器学习算法,它基于贝叶斯定理和特征条件独立假设来进行分类。
它在文本分类、垃圾邮件过滤、情感分析等领域有着广泛的应用。
本文将介绍如何使用Matlab实现朴素贝叶斯分类器进行二分类,并附上相应的代码示例。
一、朴素贝叶斯分类器原理简介1. 贝叶斯定理贝叶斯定理是基于条件概率的一个重要公式,在朴素贝叶斯分类器中扮演着核心的角色。
其数学表达式为:P(c|x) = P(x|c) * P(c) / P(x)其中,P(c|x)表示在给定特征x的条件下,类别c的概率;P(x|c)表示在类别c的条件下,特征x的概率;P(c)表示类别c的先验概率;P(x)表示特征x的先验概率。
2. 特征条件独立假设朴素贝叶斯分类器的另一个核心假设是特征条件独立假设,即假设每个特征相互独立。
虽然这个假设在现实中不一定成立,但在实际应用中,朴素贝叶斯分类器仍然表现出色。
二、朴素贝叶斯分类器二分类matlab代码示例在Matlab中,可以利用已有的函数库和工具箱来实现朴素贝叶斯分类器。
下面是一个简单的二分类示例代码:```matlab% 1. 准备数据data = [3.393533211,2.331273381,0;3.110073483,1.781539638,0;1.343808831,3.368360954,0;3.582294042,4.679179110,0;2.280362439,2.866990263,0;7.423436942,4.696522875,1;5.745051997,3.533989803,1;9.172168622,2.511101045,1;7.792783481,3.424088941,1;7.939820817,0.791637231,1;];% 2. 训练模型X = data(:, 1:2);Y = data(:, 3);model = fib(X, Y);% 3. 预测新样本new_sample = [8, 3];label = predict(model, new_sample);disp(['The label of the new sample is: ', num2str(label)]);```以上代码实现了一个简单的二分类朴素贝叶斯分类器。
使用贝叶斯算法预测双色球的python代码一、贝叶斯算法概述贝叶斯算法是一种基于概率统计的机器学习算法,它通过对已知数据的统计分析,利用概率论的知识来预测未知数据。
在彩票预测领域,贝叶斯算法可以通过分析历史开奖数据,预测下一次开奖号码的概率分布,从而为彩票投注提供参考。
二、Python代码实现```pythonimport numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.naive_bayes import GaussianNB# 读取历史开奖数据data = pd.read_csv('lottery_history.csv')# 提取号码和对应频数balls = data[['ball1', 'ball2']]freq = data['freq']# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(balls, freq, test_size=0.2, random_state=42)# 使用高斯朴素贝叶斯分类器进行预测gnb = GaussianNB()gnb.fit(X_train, y_train)y_pred = gnb.predict(X_test)# 输出预测结果和真实结果进行对比print('预测结果:', y_pred)print('真实结果:', y_test)```这段代码的主要步骤如下:1. 首先,我们使用pandas库读取历史双色球开奖数据,并将其存储为DataFrame格式。
我们需要从数据中提取出开奖号码和对应频数。
2. 然后,我们将历史数据划分为训练集和测试集,其中80%的数据用于训练模型,20%的数据用于测试模型的预测能力。