数据库系统chp6
- 格式:ppt
- 大小:371.50 KB
- 文档页数:111

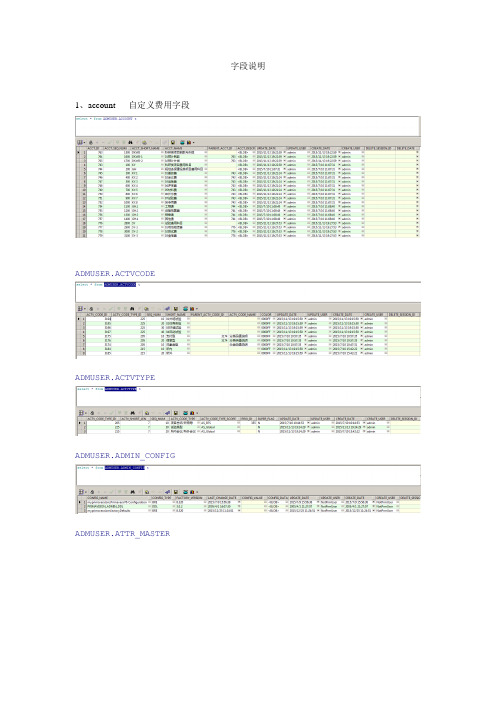
字段说明1、account 自定义费用字段ADMUSER.ACTVCODEADMUSER.ACTVTYPEADMUSER.ADMIN_CONFIGADMUSER.ATTR_MASTERADMUSER.BASETYPEADMUSER.BGPLOGADMUSER.BRE_REGISTRYADMUSER.CALENDARADMUSER.COSTTYPEADMUSER.CURRTYPE 货币ADMUSER.DASHBOARD 仪表盘ADMUSER.DOCCATGADMUSER.DOCSTAT 文档状态ADMUSER.DOCUMENTADMUSER.FACTORADMUSER.FACTVALADMUSER.FILTPROPADMUSER.FUNDSRCADMUSER.GCHANGEADMUSER.JOBLOGADMUSER.JOBSVCADMUSER.MEMOTYPEADMUSER.NEXTKEYADMUSER.NONWORKADMUSER.OBSADMUSER.OBSPROJADMUSER.PCATTYPEADMUSER.PCATVALADMUSER.PC_PROCESS_STATADMUSER.PFOLIOADMUSER.PHASEADMUSER.PKXREFADMUSER.PRMQUEUEADMUSER.PROFILEADMUSER.PROFPRIVADMUSER.PROJCOSTADMUSER.PROJECT 项目总体信息ADMUSER.PROJFUNDADMUSER.PROJWBSADMUSER.PRPFOLIOADMUSER.PUBUSERADMUSER.QUERYLIBADMUSER.REFRDELADMUSER.REITTYPEADMUSER.RISKTYPEADMUSER.RPTADMUSER.RPTBATCHADMUSER.RPTGROUPADMUSER.RPTLISTADMUSER.RSRCADMUSER.RSRCCURVADMUSER.RSRCRATEADMUSER.SETTINGSADMUSER.SHIFTADMUSER.SHIFTPERADMUSER.TASKADMUSER.THRSPARMADMUSER.TRAKVIEWADMUSER.UDFCODEADMUSER.UDFTYPEADMUSER.UDFVALUEERCOLERDATA被锁定的账户也在这个表中,删除即可ERENGEROBSEROPENERSERSETESSAUDROPNVALADMUSER.VIEWPREFADMUSER.VIEWPROPADMUSER.VWPREFDATAADMUSER.WBRSCATADMUSER.WBSMEMO1.项目作业数量统计:获取项目编号select proj_id from ADMUSER.PROJECT where project_flag='Y';获取项目下任务select * from ADMUSER.TASK where proj_id='539',获取其总计数量;CREATE OR REPLACE VIEW prjTaskCounts as select a.proj_short_name,count(*) as TaskSumCount from ADMUSER.PROJECTa,ADMUSER.TASK b where a.project_flag='Y' and a.proj_id=b.proj_id group by a.proj_short_name;创建存储过程:create or replace PROCEDURE p_prjTaskCountsasbeginselect * from prjTaskCounts;end;2.不同类型项目数量统计获取项目类型(统计)select udf_type_id from ADMUSER.UDFTYPE where udf_type_label='项目类型'select udf_text from ADMUSER.UDFVALUE where udf_type_id='230',获取当前项目类型(统计)的值;CREATE OR REPLACE VIEW diffTypePrjCounts as select d.proj_catg_name as proj_type,count(*) as proj_sumcount from ADMUSER.PROJECT a,ADMUSER.PCATTYPE b,ADMUSER.PROJPCAT c,ADMUSER.PCATVAL dwhere a.project_flag='Y' and d.proj_catg_id=c.proj_catg_id and a.proj_id=c.proj_id and c.proj_catg_type_id=b.proj_catg_type_id and b.proj_catg_type='项目类型' group by d.proj_catg_name;创建存储过程:create or replace PROCEDURE p_diffTypePrjCountsasbeginselect * from diffTypePrjCounts;end;3.不同部门项目数量统计获取项目编号(多个值)select proj_id from ADMUSER.PROJECT where project_flag='Y';获取管理部门的idselect proj_catg_type_id from ADMUSER.PCATTYPE where proj_catg_type='管理部门'根据该ID,再寻找项目取的值的idselect proj_cate_id from ADMUSER.PROJPCAT where proj_id='569'andproj_catg_type_id='37'根据id最终获取管理部门的值select proj_catg_name from ADMUSER.PCATVAL where proj_catg_id='112'status_code:TK_NotStart: 未开始TK_Active:已开始,未完成TK_Complete:已完成获取主管领导的内部码select udf_type_id from ADMUSER.UDFTYPE where udf_type_label='主管领导'select udf_text from ADMUSER.UDFVALUE where udf_type_id='230',获取当前领导工号;不同领导应该看到不同的统计结果;CREATE OR REPLACE VIEW diffDeptPrjCounts as select d.proj_catg_name as proj_department,count(*) as proj_sumcount from ADMUSER.PROJECT a,ADMUSER.PCATTYPE b,ADMUSER.PROJPCAT c,ADMUSER.PCATVAL dwhere a.project_flag='Y' and d.proj_catg_id=c.proj_catg_id anda.proj_id=c.proj_id and c.proj_catg_type_id=b.proj_catg_type_id andb.proj_catg_type='管理部门' group by d.proj_catg_name;创建存储过程:create or replace PROCEDURE p_diffDeptPrjCountsasbeginselect * from diffDeptPrjCounts;end;。


第三章Primavera 5.0数据库安装说明一、本章前言●本章讲述怎样安装Primavera5.0应用程序数据库,完成本章数据库的安装之后,请参考《注册数据库》。
●Primavera 5.0支持MS SQL SERVER2000(sp3)和ORACLE9.2.0.5/ORACLE10.1.0.3两种类型的数据库。
●数据库安装分两个步骤,创建数据库结构和加载应用程序数据到数据库中。
●Primavera5.0数据库的创建可以用光盘本身提供的数据库安装向导进行数据库结构的创建及应用程序数据的加载全过程。
但安装向导是在windows环境下运行。
●Primavera5.0数据库的创建也可以用光盘提供的数据库创建脚本文件进行数据库结构的创建,然后通过Primavera5.0安装向导加载应用程序数据到数据库中。
●请根据用户实际情况,选择下列一种方法安装数据库:1.如果用户的数据库环境为MS SQL Server,那么请参考本章第三节《创建Primavera5.0的MS SQL Server2000的数据库》。
2.如果用户的数据库环境为windows操作系统下的Oracle,并且计划将ProjectManagement和Methodology Management数据库安装在同一个实例上,那么请参考本章第四节《创建Primavera 5.0的windows操作系统上 Oracle的数据库(一个实例)》。
3.如果用户的数据库环境为Unix或Linux操作系统下的Oracle,建议将ProjectManagement和Methodology Management数据库安装在同一个实例上,那么请参考本章第五节《创建Primavera 5.0的非windows操作系统上 Oracle的数据库(一个实例)》。
4.如果用户的数据库环境为windows操作系统下的Oracle,并且计划将ProjectManagement和Methodology Management数据库分别安装成PMDB和MMDB两个实例,那么请参考本章第六节《创建Primavera5.0的windows操作系统上 Oracle的数据库(两个实例)》。


CH6 存储结构介绍这一章的内容在ch1的时候,已经粗略介绍过,这里主要对表空间和数据文件的概念重新声明一遍,再细化一下。
表空间:基于数据库的逻辑概念,好处是屏蔽了不同操作系统对数据库存储带来的影响。
一个表空间只能属于一个数据库。
数据文件:只能属于一个表空间,在操作系统中实际存储数据的单元。
单个数据库最多包含65536个数据文件,这个参数在数据库创建的时候,create database 命令里面有。
关于表空间的存储管理,有两类,DICTIONARY MANAGED TABLESPACE:传统数据字典管理表空间,所有可用区间的信息都在数据字典的对应表中记录,当为表分配区间的时候,需要向数据字典表进行提交更改。
LOCALLY MANAGED TABLESPACE:本地表空间,这是从8i以后开始推的一种表空间,特点是在表空间里自己记录可用区间的信息,使用位图的形式存储可用区间的映像,位图表中的每个位,表示一个数据块,或者一个区间的状态,用位图的值来表示已经使用,或者未使用。
本地表空间的使用,实际是分散集中式管理的需要,降低数据字典读写冲突的概率。
也是ORACLE后来ASM发展最初的萌芽。
因为我们知道,一般数据库的开销,大多数出现在查询统计,而查询统计里磁盘读写是关键,相对其他在内存中完成的操作而言,依赖机械转动读取数据的磁盘往往是关键的瓶颈,在使用LOCALLY MANAGED TABLESPACE的时候,降低的是对数据字典读写的冲突,使用多个DBWR同时写磁盘,提高写数据的效率。
单是单位时间内读取的数据量终究是有限的,而实际查询中返回的数据大多数都是无效的,因此如何提高读取效率,是ORACLE改进的方向,以前我们是通过优化SQL查询的代码(例如:查询时尽量不要用SELECT * FROM TBL_NAME,而是尽量使用准确的查询select id from tbl_name,先缩小范围,然后再select username,useradd,…from tbl_name where id=123;这样定位,可以极大降低数据的读取量,提高效率。