第二章-统计图表
- 格式:pptx
- 大小:442.62 KB
- 文档页数:45

现代心理与教育统计学复习资料第一章心理与教育统计学基础知识1、数据类型称名数据计数数据离散型数据顺序数据等距数据测量数据连续型数据比率数据2、变量、随机变量、观测值变量就是可以挑相同值的量。
统计数据观测的指标都就是具备变异的指标。
当我们用一个量则表示这个指标的观测结果时,这个指标就是一个变量。
用来表示随机现象的变量,称为随机变量。
一般用大写的x或y表示随机变量。
随机变量所取得的值,称为观测值。
一个随机变量可以有许多个观测值。
3、总体、个体和样本须要研究的同质对象的全体,称作总体。
每一个具体内容研究对象,称作一个个体。
从总体中抽出的用以推测总体的部分对象的集合称为样本。
样本中包含的个体数,称为样本的容量n。
通常把容量n≥30的样本称作大样本;而n<30的样本称作大样本。
4、统计数据量和参数统计数据指标平均数标准差相关系数回归系数统计数据量srb参数μσρβ5、统计误差误差就是测量得值与真值之间的差值。
测出数值=真值+误差统计误差归纳起来可分为两类:测量误差与抽样误差。
由于采用的仪器、测量方法、读数方法等问题导致的测出值与真值之间的误差,称作测量误差。
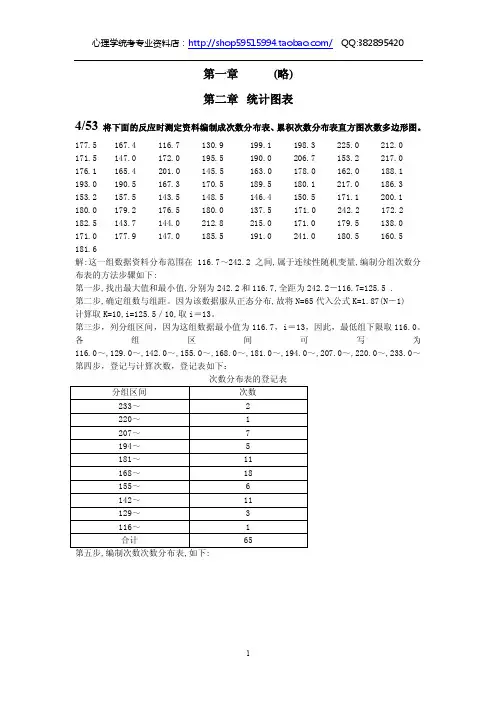
由于随机抽样造成的样本统计量与总体参数间的差别,称为抽样误差第二章统计图表一、数据的整理在展开整理时,如果没充裕的理由证明某数据就是由实验中的过错导致的,就无法轻而易举将其确定。
对于个别极端数据与否该剔出,应当遵从三个标准差法则。
二、次数原产表中(一)简单次(频)数分布表(二)相对次数分布表将次数原产表各组的实际次数转变为相对次数,即为用频数比率(f/n)或百分比f)去则表示次数,就可以做成相对次数原产表中(?100%n(三)累加次数分布表(四)双列次数分布表双列次数原产表中又称有关次数原产表中,就是对存有联系的两列变量用同一个表中则表示其次数原产。
所谓有联系的两列变量,一般是指同一组被试中每个被试两种心理能力的分数或两种心理特点的指标,或同一组被试在两种实验条件下获得的结果。


现代心理与教育统计学(张厚粲)课后习题答案第一章绪论(略)第二章统计图表(略)第三章集中量数4、平均数约为36.14;中位数约为36.635、总平均数为91.726、平均联想速度为5.27、平均增加率约为11%;10年后的毕业人数约有3180人8、次数分布表的平均数约为177.6;中位数约为177.5;原始数据的平均数约为176.7第四章差异量数5、标准差约为1.37;平均数约为1.196、标准差为26.3;四分位差为16.037、5cm组的差异比10cm组的离散程度大8、各班成绩的总标准差是6.039、次数分布表的标准差约为11.82;第一四分位为42.89;第三四分位为58.41;四分位差为7.76第五章相关关系5、应该用肯德尔W系数。
6、r=0.8;r R=0.79;这份资料只有10对数据,积差相关的适用条件是有30对以上数据,因此这份资料适用等级相关更合适。
7、这两列变量的等级相关系数为0.97。
8、上表中成绩与性别有很强的相关,相关系数为0.83。
9、r b=0.069小于0.2.成绩A与成绩B的相关很小,成绩A与成绩B的变化几乎没有关系。
10、测验成绩与教师评定之间有一致性,相关系数为0.87。
11、9名被试的等级评定具有中等强度的相关,相关系数为0.48。
12、肯德尔一致性叙述为0.31。
第六章概率分布4、抽得男生的概率是0.355、出现相同点数的概率是0.1676、抽一黑球与一白球的概率是0.24;两次皆是白球与黑球的概率分别是0.36和0.167、抽一张K的概率是4/54=0.074;抽一张梅花的概率是13/54=0.241;抽一张红桃的概率是13/54=0.241;抽一张黑桃的概率是13/54=0.241;抽不是J、Q、K的黑桃的概率是10/54=0.1858、两个正面,两个反面的概率p=6/16=0.375;四个正面的概率p=1/16=0.0625;三个反面的概率p=4/16=0.25;四个正面或三个反面的概率p=0.3125;连续掷两次无一正面的概率p=0.18759、二项分布的平均数是5,标准差是210、(1)Z≥1.5,P=0.5-0.43=0.07(2)Z≤1.5,P=0.5-0.43=0.07(3)-1.5≤Z≤1.5,p=0.43+0.43=0.86(4)p=0.78,Z=0.77,Y=0.30(5)p=0.23,Z=0.61,Y=0.33(6)1.85≤Z≤2.10,p=0.482—0.467=0.01511、(1)P=0.35,Z=1.04(2)P=0.05,Z=0.13(3)P=0.15,Z=-0.39(4)P=0.077,Z=-0.19(5)P=0.406,Z=-1.3212、(1)P=0.36,Z=-1.08(2)P=0.12,Z=0.31(3)P=0.125,Z=-0.32(4)P=0.082,Z=-0.21(5)P=0.229,Z=0.6113、各等级人数为23,136,341,341,136,2314、T分数为:73.3、68.5、64.8、60.8、57、53.3、48.5、46.4、38.2、29.515、三次6点向上的概率为0.054,三次以上6点向上的概率为0.06316、回答对33道题才能说是真会不是猜测17、答对5至10到题的概率是0.002,无法确定答对题数的平均数18、说对了5个才能说看清了而不是猜对的19、答对5题的概率是0.015;至少答对8题的概率为0.1220、至少10人被录取的概率为0.1821、(1)t0.05=2.060,t0.01=2.784(2)t0.05=2.021,t0.01=2.704(3)t0.05=2.048,t0.01=2.76322、(1)χ20.05=43.8,χ20.0,1=50.9(2)χ20.05=7.43,χ20.0,1=10.923、(1)F0.05=2.31,F0.01=3.03(2)F0.05=6.18,F0.01=12.5324、Z值为3,大于Z的概率是0.0013525、大于该平均数以上的概率为0.0826、χ2以上的概率为0.1;χ2以下的概率为0.927、χ2是20.16,小于该χ2值以下概率是0.8628、χ2值是12.32,大于这个χ2值的概率是0.2129、χ2值是15.92,大于这个χ2值的概率是0.0730、两方差之比比小于F0.05第七章参数估计5、该科测验的真实分数在78.55—83.45之间,估计正确的概率为95%,错误概率为5%。


第一章绪论1.描述统计(descriptive statistics)主要研究如何将实验或调查得到的大量数据进行图表整理或简缩成有代表性的数字(即统计量数),使其能客观、全面地反映这组数据的全貌,将其所提供的信息充分显现出来,为进一步统计分析和推论提供可能。
2.描述统计只限于对试验样本所得观测数据的统计分析,不考察其总体的特性。
3.推论统计(inferential statistics)是以描述统计为基础,从而解决由局部到全体的推论问题,即通过对一组统计量的计算分析,推论该组数据所代表的总体特性。
4.变量(variables):一个可以取不同数值的物体属性/事件。
5.事前无法预期结果的变量——随机变量6.观测值(原始取值):事后测定的某一结果。
7.概念理解:[涉及“实验”] 自变量(及其各水平)& 因变量(及相应的反应指标);[涉及“调查”,粗略对应于] 属性变量& 反应变量8.计数资料(count data):计算个数的数据,(如人口数,学校数,男女数等)9.计量资料(measurement data):借助于一定的测量工具或一定的测量标准而获得的数据(如分数,身高,体重,IQ)10.称名数据(nominal data):只区分属性或类别上的不同,只可计数,不能排序(性别,学科,职业)11.等级/顺序数据(ordinal data):可排序,但无相等单位,不能加减。
(等级评定,受教育程度,职称)12.等距数据(interval data):具有相等单位,无绝对零的数据,能加减不能乘除。
13.比率数据(ratio data):既表明量的大小,又具有相等单位,可以加减乘除,具有绝对零点。
14.称名数据和顺序数据合称为离散数据。
15.等距数据和比率数据合称为连续数据。
16.离散数据(discrete data)又称为不连续数据,这类数据在任何两个数据点之间所取的数据的个数是有限的。
17.连续数据(continuous data)指任意两个数据点之间都可以细分出无限多个大小不同的数值。

考研真题和强化习题详解第一章绪论一、单选题1 .三位研究者评价人们对四种速食面品牌的喜好程度。
研究者甲让评定者先挑出最喜欢的品牌,然后挑出剩下三种品牌中最喜欢的,最后再挑出剩下两种品牌中比较喜欢的。
研究者乙让评定者将四种品牌分别给予 l~5 的等级评定, ( l 表示非常不喜欢, 5 表示非常喜欢),研究者丙只是让评定者挑出自己最喜欢的品牌。
研究者甲、乙、丙所使用的数据类型分别是: ( )A .类目型―顺序型―计数型B .顺序型―等距型―类目型C .顺序型―等距型―顺序型D .顺序型―等比型―计数型2 .调查了n =200 个不同年龄组的被试对手表显示的偏好程度,如下:该题自变量与因变量的数据类型分别是: ( )A .类目型―顺序型B .计数型―等比型C .顺序型―等距型D .顺序型―命名型3 .这个数的上限是()。
A . 157 . 75B . 157 . 65C . 157 . 55D . 158 . 54 .随机现象的数量化表示称为()。
A .自变量B .随机变量C .因变量D .相关变量5 .实验或研究对象的全体被称之为()。
A .总体B .样本点C .个体D .元素6 .下列数据中,哪个数据是顺序变量? ( )A .父亲的月工资为 1300 元B .小明的语文成绩为 80 分C .小强 100 米跑得第 2 名D .小红某项技能测试得 5 分7、比较时只能进行加减运算而不能使用乘除运算的数据是【】。
A .称名数据B .顺序数据C .等距数据D .比率数据参考答案: 1 . B 2 . D 3 . C 4 . B 5 . A 6 . C二、概念题1.描述统计(吉林大学 2002 研)答:描述统计指研究如何整理心理教育科学实验或调查的数据,描述一组数据的全貌,表达一件事物的性质的统计方法。
比如整理实验或调查来的大量数据,找出这些数据分布的特征,计算集中趋势、离中趋势或相关系数等,将大量数据简缩,找出其中所传递的信息。

心理统计学第一章概述描述统计定义:研究如何把心理与教育科学实验或调查得来的大量数据科学的科学的加以整理概括和表述作用:使杂乱无章的数字更好的显示出事物的某些特征,有助于说明问题的实质。
具体内容:1数据分组:采用图与表的形式。
2计算数据的特征值:集中量数(平均数中数)离散量数(方差)3计算量事物间的相关关系:积差相关(2列 3列多列)推断统计定义:主要研究如何利用局部数据(样本数据)所提供的信息,依据数理统计提供的理论和方法,推论总体情形。
作用:用样本推论总体。
具体内容:1如何对假设进行检验。
2如何对总体参数特征值进行估计。
3各种非参数的统计方法。
心理与教育统计基础概念数据类型一从数据来源来划分1计数数据:计算个数或次数而获得的数据。
(都是离散数据)2测量数据:借助一定测量工具或测量标准而获得的数据。
(连续数据)二根据数据所反映的测量水平1称名数据(分类)定义:指用数字代表事物或数字对事物进行分类的数据。
特点:数字只是事物的符号,而没有任何数量意义。
统计方法:百分数次数众数列联相关卡方检验等。
(非参检验)2顺序数据(分类排序)定义:指代事物类别,能够表明不同食物的大小等级或事物具有的某种特征的程度的数据。
(年级)特点:没有相等单位没有绝对零点。
不表示事物特征的真正数量.统计方法:中位数百分位数等级相关肯德尔和谐系数以及常规的非参数检验方法。
3等距数据(分类排序加减(相等单位))(真正应用最广泛的数据)定义:不仅能够指代物体的类别等级,而且具有相等的单位的数据。
(成绩温度)特点:真正的数量,能进行加减运算,没有绝对零点,不能进行乘除计算。
统计方法:平均数标准差积差相关 Z检验 t检验 F检验等。
4比率数据(分类排序加减法乘除法(绝对零点))定义:表明量的大小,也具有相等单位,同时具有绝对零点。
(身高反应时)特点:真正的数字,有绝对零点,可以进行加减乘除运算。
在统计中处理的数据大多是顺序数据和等距数据。

心理统计学第一章概述描述统计定义:研究如何把心理与教育科学实验或调查得来的大量数据科学的科学的加以整理概括和表述作用:使杂乱无章的数字更好的显示出事物的某些特征,有助于说明问题的实质。
具体内容:1数据分组:采用图与表的形式。
2计算数据的特征值:集中量数(平均数中数)离散量数(方差)3计算量事物间的相关关系:积差相关(2列3列多列)推断统计定义:主要研究如何利用局部数据(样本数据)所提供的信息,依据数理统计提供的理论和方法,推论总体情形。
作用:用样本推论总体。
具体内容:1如何对假设进行检验。
2如何对总体参数特征值进行估计。
3各种非参数的统计方法。
心理与教育统计基础概念数据类型一从数据来源来划分1计数数据:计算个数或次数而获得的数据。
(都是离散数据)2测量数据:借助一定测量工具或测量标准而获得的数据。
(连续数据)二根据数据所反映的测量水平1称名数据(分类)定义:指用数字代表事物或数字对事物进行分类的数据。
特点:数字只是事物的符号,而没有任何数量意义。
统计方法:百分数次数众数列联相关卡方检验等。
(非参检验)2顺序数据(分类排序)定义:指代事物类别,能够表明不同食物的大小等级或事物具有的某种特征的程度的数据。
(年级)特点:没有相等单位没有绝对零点。
不表示事物特征的真正数量。
统计方法:中位数百分位数等级相关肯德尔和谐系数以及常规的非参数检验方法。
3等距数据(分类排序加减(相等单位))(真正应用最广泛的数据)定义:不仅能够指代物体的类别等级,而且具有相等的单位的数据。
(成绩温度)特点:真正的数量,能进行加减运算,没有绝对零点,不能进行乘除计算。
统计方法:平均数标准差积差相关Z检验t检验F检验等。
4比率数据(分类排序加减法乘除法(绝对零点))定义:表明量的大小,也具有相等单位,同时具有绝对零点。
(身高反应时)特点:真正的数字,有绝对零点,可以进行加减乘除运算。
在统计中处理的数据大多是顺序数据和等距数据。
三按照数据是否具有连续性离散数据连续数据变量观测值随机变量变量:指心理与教育实验观察调查种想要获得的数据。


完整版)统计学名词解释统计学名词解释第一章绪论在统计学上,随机变量指的是取值之间不能预料到的变量。
总体,又称母全体或全域,是指具有某种特征的一类事物的全体。
构成总体的每个基本单元称为个体。
从总体中抽取的一部分个体称为样本。
次数指的是某一事件在某一类别中出现的数目,又称为频数。
频率,又称相对次数,指某一事件发生的次数被总的事件数目除,即某一数据出现的次数被这一组数据总个数去除。
概率指某一事物或某一情在某一总体中出现的比率。
一旦确定了某个值,就称这个值为某一变量的观测值。
参数,又称为总体参数,是描述一个总体情况的统计指标。
样本的那些特征值叫做统计量,又称特征值。
第二章统计图表统计表是由纵横交叉的线条绘制,并将数据按照一定的要求整理、归类、排列、填写在内的一种表格形式。
一般由表号、名称、标目、数字、表注组成。
统计图一般采用直角坐标系,通常横轴表示事物的组别或自变量x,称为分类轴。
纵轴表示事物出现的次数或因变量,称为数值轴。
一般由图号及图题、图目、图尺、图形、图例、图组成。
简单次数分布表适合数据个数和分布范围比较小的时候用,它是依据每一个分数值在一列数据中出现的次数或总计数资料编制成的统计表。
而分组次数分布表适合数据个数和分布范围比较大的时候用。
数据量很大时,应该把所有的数据先划分在若干区间,然后将数据按其数值大小划归到相应区域的组别内,分别统计各个组别中包括的数据个数,再用列表的形式呈现出来。
分组次数分布表的编制步骤包括求全距、定组距和组数、列出分组组距、登记次数和计算次数。
相对次数分布表用频数比率或百分数来表示次数,而累加次数分布表则把各组的次数由下而上或由上而下加在一起。
最后一组的累加次数等于总次数。
双列次数分布表用同一个表表示有联系的两列变量的次数分布。
而不等距次数分布表则适用于像工资级别和年龄分组这样的不等距数据。
需要注意的是,归组效应是分组次数分布表的缺点之一,因为原始数据不见了,从而依据这样的统计表算出的平均值会与用原始数据算出的值有出入,出现误差。
统计学--常用图表
常用图表
一. 图表的基本概念
图表包括统计图和统计表
1-1. 统计图
概念:统计图是根据统计数字,用几何图形、事物形象和地图等绘制的各种图形。
它具有直观、形象、生动、具体等特点。
塔夫特认为的一张好图应具由的基本特征:
•显示数据
•避免歪曲
•强调数据之间的比较
•服务于一个明确的目的
•有对图形的统计描述和文字说明
•让读者把注意力集中在图形的内容上,而不是制作图形的程序上
塔夫特提出的五条鉴别图形优劣的准则:
•一张好图应当精心设计,有助于洞察问题的实质
•一张好图应当使复杂的观点得到建明、确切、高效的阐述
•一张好图应当能在最短的时间内以最少的笔墨给读者提供最大量的信息
•一张好图应当是多维的
•一张好图应当表述数据的真实情况
1-2. 统计表
概念:统计表是反映统计资料的表格,它一般由四个主要部分组成,即表头、行标题、列标题和数据资料。
设计和使用统计表要注意的几点:
•首先,要合理安排统计表的结构。
由于强调的问题不同,行标题和列标题可以互换,但应使统计表的横竖长度比例适当,避免出现过高或过宽的表格形
式
•其次,表头一般应包括表号、总标题和表中数据的单位等内容
•再次,表中的上下两条横线一般用粗线,中间的其他线用细线。
《心理统计学》重要知识点第二章 统计图表简单次数分布表的编制:Excel 数据透视表列联表(交叉表):两个类别变量或等级变量的交叉次数分布,Excel 数据透视表直方图(histogram ):直观描述连续变量分组次数分布情况,可用Excel 图表向导的柱形图来绘制 散点图(Scatter plot ):主要用于直观描述两个连续性变量的关系状况和变化趋向。
条形图(Bar chart ):用于直观描述称名数据、类别数据、等级数据的次数分布情况。
简单条形图:用于描述一个样组的类别(或等级)数据变量次数分布。
复式条形图:用于描述和比较两个或多个样组的类别(或等级)数据的次数分布。
圆形图(circle graph )、饼图(pie graph ):用于直观描述类别数据或等级数据的分布情况。
线形图(line graph ):用于直观描述不同时期的发展成就的变化趋势;第三章 集中量数● 集中趋势和离中趋势是数据分布的两个基本特征。
● 集中趋势:就是数据分布中大量数据向某个数据点集中的趋势。
● 集中量数:描述数据分布集中趋势的统计量数。
● 离中趋势:是指数据分布中数据分散的程度。
● 差异量数:描述数据分布离中趋势(离散程度)的统计量数 ● 常用的集中量数有:算术平均数、众数(M O )、中位数(M d ) 1.算术平均数(简称平均数,M 、X 、Y ):nx X i∑= Excel 统计函数AVERAGE算术平均数的重要特性:(1)一组数据的离均差(离差)总和为0,即0)(=-∑x x i(2)如果变量X 的平均数为X ,将变量X 按照公式bx a y +=转换为Y 变量后,那么,变量Y 的平均数X b a Y +=2.中位数(median ,M d ):在一组有序排列的数据中,处于中间位置的数值。
中位数上下的数据出现次数各占50%。
3.众数(mode ,M O ):一组数据中出现次数最多的数据。