信息论-信息论第7次课ch3--信源熵
- 格式:pptx
- 大小:1.06 MB
- 文档页数:22

信源熵的名词解释信源熵(Source Entropy)是信息论中一个重要的概念,用于衡量信息源的不确定性和信息的平均编码长度。
在信息论中,信息可以被看作是从一个信源中获取的,而信源熵用来描述这个信源的不确定性大小。
信源熵的计算方法是根据信源可能产生的符号的概率分布来进行的。
具体来说,如果一个信源有n个可能取值(符号)S1,S2,...,Sn,并且每个符号出现的概率分别为P1,P2,...,Pn,那么信源的熵H(S)可以通过下面的公式计算得出:H(S) = -P1log(P1) - P2log(P2) - ... - Pnlog(Pn)其中,log是以2为底的对数,P1,P2,...,Pn是概率分布。
信源熵的含义是,对于一个不确定性较大的信源,需要更长的编码长度来表示每一个符号,所以熵值越大,说明信息的平均编码长度越长。
相反,当一个信源的不确定性较小,即各个符号出现的概率分布较平均时,信息的平均编码长度较短,熵值较小。
以一个简单的例子来说明信源熵的概念。
假设有一个只有两个符号的信源,分别记为S1和S2,它们出现的概率分别为P1和P2。
如果这两个符号的概率分布相等(即P1 = P2 = 0.5),那么信源的熵就是最大的,因为这两个符号的不确定性相同,需要同样长度的编码来表示它们。
而如果其中一个符号的概率接近于1,另一个符号的概率接近于0,那么信源的熵就是最小的,因为其中一个符号的信息是确定的,只需要很短的编码来表示它。
这个例子可以帮助我们理解信源熵与不确定性之间的关系。
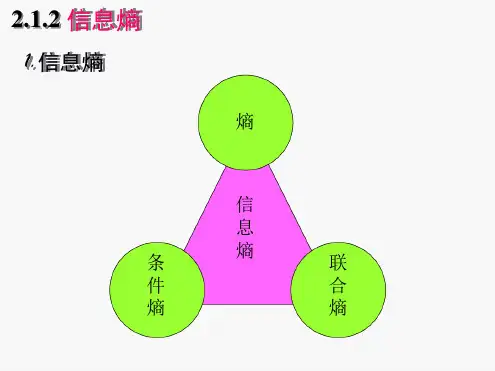
除了信源熵,信息论中还有一个重要的概念是条件熵(Conditional Entropy)。
条件熵是在已知一定的背景条件下,信源的不确定性大小,即在给定前提条件下的平均编码长度。
条件熵可以通过信源和条件之间的联合概率分布来计算,其公式为:H(S|T) = -ΣΣP(s, t)log(P(s|t))其中,P(s, t)表示符号s和条件t联合发生的概率。





信源熵的原理及应用1. 介绍信源熵是信息论中一个重要的概念,它描述了一个随机信源所具有的信息量的平均度量。
信源的熵越大,表示信息的不确定性越高,需要更多的信息来描述。
本文将介绍信源熵的原理,并探讨其在通信、数据压缩以及密码学等领域的应用。
2. 信源熵的定义信源熵是正信息论中一个重要概念,它用来度量一个随机信源所具有的信息量的平均度量。
对于一个离散随机变量X,它的概率分布为P(X),则信源的熵定义如下:equationequation其中,xi是随机变量X的取值,P(xi)是xi对应的概率。
3. 信源熵的性质•信源熵的取值范围:信源的熵是非负的,即H(X) ≥ 0。
•最大熵原理:对于一个离散信源,当它的概率分布均匀时,即每个xi的概率相等时,信源熵达到最大值。
•如果一个信源越复杂,即其概率分布越不均匀,那么它的熵就越小。
4. 信源熵的应用4.1 通信系统在通信系统中,信源熵可以用来度量信道所传输信息的平均编码长度。
根据香农定理,信道传输的平均编码长度L与信源熵H(X)满足以下关系:equationequation当信道编码满足L = H(X)时,信道编码称为最优编码,即编码的平均长度等于信源熵。
4.2 数据压缩信源熵还可以应用于数据压缩领域。
数据压缩的目的是使用更少的位数来存储或传输数据。
通过统计一个数据源的概率分布,可以将出现概率低的数据编码为较长的二进制位,而出现概率高的数据编码为较短的二进制位。
信源熵提供了压缩算法的理论基础。
4.3 密码学在密码学中,信源熵用于度量消息或密码的随机性。
如果一个密码是完全随机的,并且每个密钥都是等概率选择的,那么这个密码的熵将达到最大值。
信源熵可以用来评估一个密码系统的安全性,以及密码生成算法的随机性。
5. 总结本文介绍了信源熵的原理及其应用。
信源熵是衡量信息量的重要度量指标,它在通信、数据压缩以及密码学等领域具有多种应用。
通过明确信源熵的定义和性质,我们可以更好地理解和应用它。


信源熵公式
信源熵是信息论中的一个重要概念,它是用来度量消息的丰富性和
复杂性的一种度量方法。
它的概念源于 Shannon 在 1948 年出版的文章Information Theory。
一、信源熵是什么
信源熵(即 Shannon 熵)是指数据量的复杂性程度的度量,即信息量
在消息中不确定性的度量。
它可以帮助我们测量消息中内容丰富程度,以及消息是否具有冗余性。
通俗来说,信源熵是一种度量消息中有多
少信息和无规律性的度量方法。
二、信源熵的计算公式
信源熵的计算公式是: H(p) = -∑p(i)logp(i) 。
其中,H(p)是具有信息量
p的信息源的熵,p(i)是每一种信息量的概率。
它很好地反映了消息的复杂性,但它不能用来衡量消息的可靠性,因
此不能按照 Shannon 熵来评估消息的独特性。
三、信源熵的应用
信源熵有很多应用,最重要的是在信号处理、声音分析、密码学、数
据库设计和模式分析等领域有广泛的应用。
例如在压缩文件时,可以
使用信源熵来确定哪些数据需要进行压缩处理,从而减小数据的量。
另外,信源熵也可以用来度量信号的复杂性,比如机器学习算法中的模型复杂度因子,可以使用信源熵来衡量模型的复杂度。
四、总结
信源熵是由 Shannon 在 1948 年提出的一种度量方法,它可以度量消息的复杂性和冗余性,可以帮助我们评估消息的信息量。
它被广泛应用于信号处理、声音分析、密码学、数据库设计和模式分析等领域,可以用来度量信号的复杂性,以及机器学习算法中的模型复杂度因子。


通信的基本问题,是在通信系统的一端精确地或者近似地复现另一端选择的消息概念消息:由信源发出,具有随机性信息量:消息所包含的不确定性的度量信息的量化1. 在南极大陆,今天的气温为-25°C2. 在南极大陆,今天的气温为38°C在一般情况下,这两条消息哪一条包含的信息量更大呢?一条消息所携带的信息量的大小,和它带给接收者的“surprise”有关。
在数学上,我们可以用事件的发生概率来表示一个事件发生所引起的surprise。
{}r x x x X ,,,21 =Xs s s s x t t ∈=)(10 )()Pr(i i i x P x p =={}r X p p p P ,,,21 =∑==ri ip 11信源符号集合:信源从时刻0开始发出的符号序列为:信源中每个信源符号的发生概率:信源的概率分布为:∑==⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡n i i n n p where p p p a a a X P X 121211,,,,,,)( 离散信源的概率模型自信息 :当信源发出这个符号时所发出的信息量。
)(log )(1log )(i i i x P x P x I -==单位: 取决于所用的对数的底。
当使用以2为底的对数时,信息量的单位是比特(bit );当使用以10为底的对数时,信息量的单位是哈特莱(Hartley );当使用以e 为底的对数(自然对数)时,信息量的单位是奈特(nat )。
1 nat = 1.44 bit例题某门课程的学生成绩分布如下,求每个成绩等级代表符号A, B, C, D, F所包含的信息量。
A B C D F25%50%12.5%10% 2.5%解:符号概率p自信息 log(1/p)A0.25 2 比特B0.5 1 比特C0.125 3 比特D0.1 3.32 比特F0.025 5.32 比特合计:1例题某门课程的学生成绩分布如下,求每个成绩等级代表符号A, B, C, D, F所包含的信息量。